catalogue
The so-called "simplicity" means that each attribute is independent of each other.
2, Text categorization using Python
3, Spam filtering using naive Bayes
1, Naive Bayes
1. Conditional probability knowledge: the occurrence probability of event A under the condition that another event B has occurred. The conditional probability is expressed as P (A|B), which is read as "the probability of A under condition B.


If P(A|B) is known and P(B|A) is required, there are:
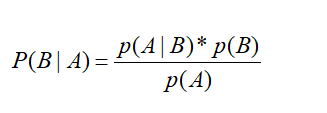
Full probability formula: Means that if events A1, A2,..., An form a complete event group and all have positive probability, the formula holds for any event B.
Bayesian formula is to bring the full probability formula into the conditional probability formula. For event A and event B:

For P(Ai ∣ B), the denominator is fixed, so only the comparator can be used.
The so-called "simplicity" means that each attribute is independent of each other.
Naive Bayes formula:
(including: Is a priori probability, xi represents the ith attribute)
Is a priori probability, xi represents the ith attribute)
2, Text categorization using Python
1. Prepare data:
import numpy as np
import random
import re
def loadDataSet():
postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0, 1, 0, 1, 0, 1] #1 stands for insulting words and 0 stands for normal speech
return postingList, classVec
def createVocabList(dataSet):
vocabSet = set([]) #Create an empty set
for document in dataSet:
vocabSet = vocabSet | set(document) #Creates the union of two sets
return list(vocabSet)
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else: print("the word: %s is not in my Vocabulary!" % word)
return returnVec
if __name__ == '__main__':
postingList,classVec = loadDataSet()
print("postingList:\n",postingList)
myVocabList = createVocabList(postingList)
print('myVocabList:\n',myVocabList)
trainMat = []
for postingLIst in postingList:
trainMat.append(setOfWords2Vec(myVocabList,postingLIst))
print('trainMat:\n',trainMat)
Operation results:
2. Calculate probability from word vector
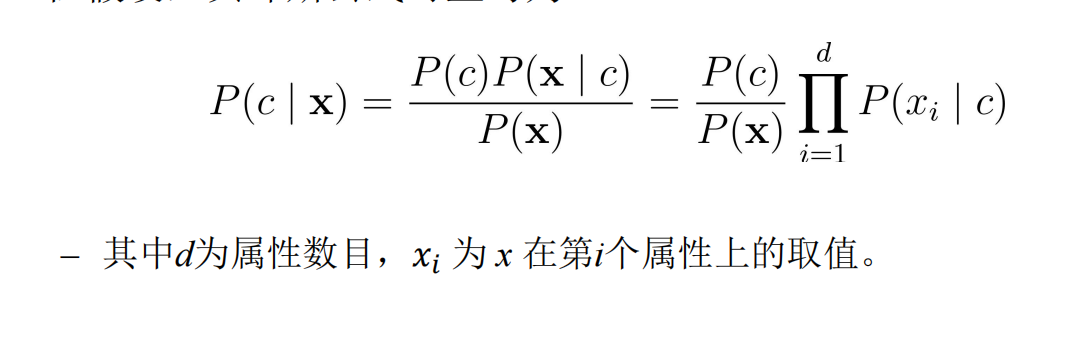
At this point, x is a vector, that is, it consists of multiple values
Code implementation:
def trainNB0(trainMatrix, trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
p0Num = np.zeros(numWords); p1Num = np.zeros(numWords)
p0Denom = 0.0; p1Denom = 0.0 #Initialization probability
for i in range(numTrainDocs):
if trainCategory[i] == 1: #Vector addition
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = p1Num/p1Denom #Convert to log
p0Vect = p0Num/p0Denom
return p0Vect, p1Vect, pAbusive
if __name__ == '__main__':
postingList,classVec = loadDataSet()
print("postingList:\n",postingList)
myVocabList = createVocabList(postingList)
print('myVocabList:\n',myVocabList)
trainMat = []
for postingLIst in postingList:
trainMat.append(setOfWords2Vec(myVocabList,postingLIst))
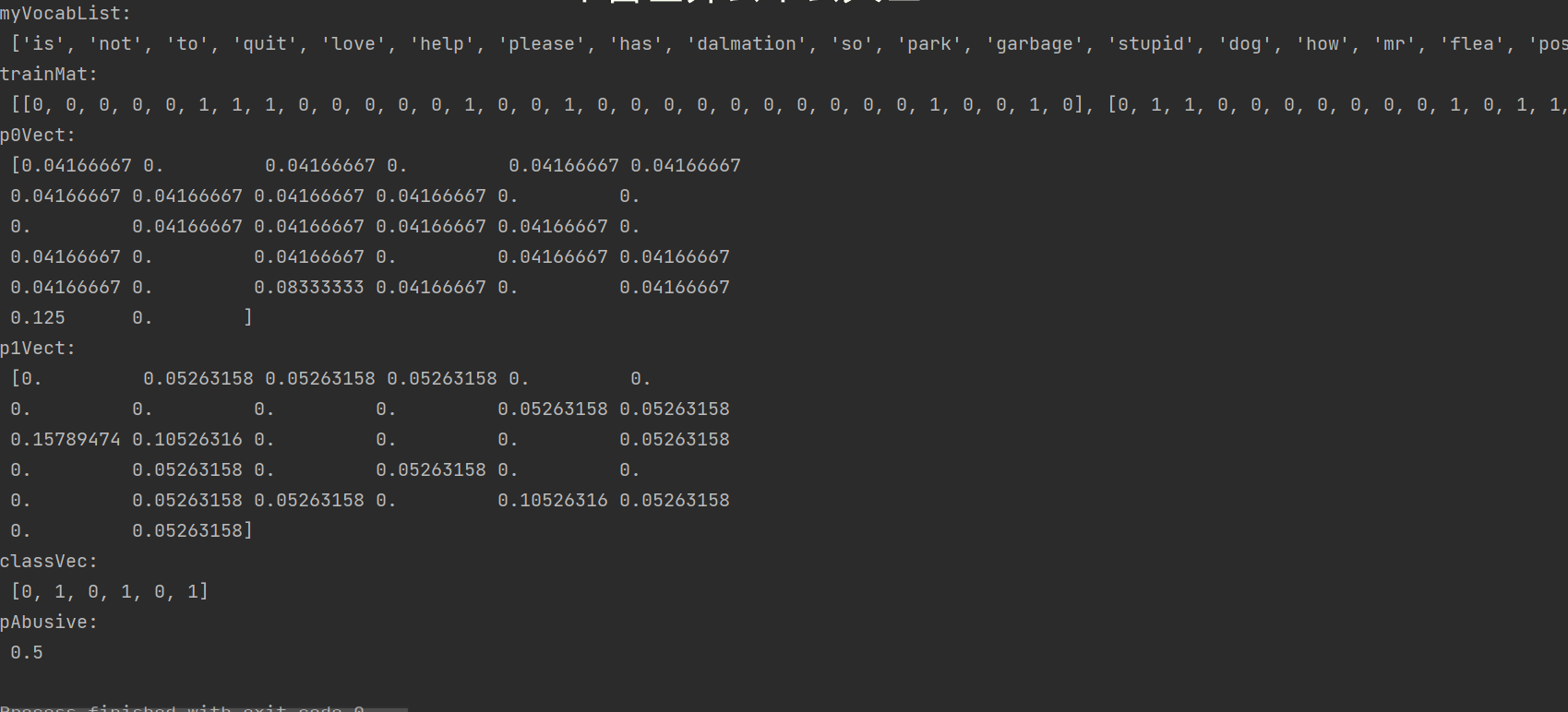
p0V, p1V, pAb = trainNB0(trainMat, classVec)
print('trainMat:\n', trainMat)
print('p0Vect:\n', p0V) #Probability of normal speech
print('p1Vect:\n', p1V) #Probability of insulting words
print('classVec:\n', classVec)
print('pAbusive:\n', pAb) #Probability of insulting words in the total sample
Operation results:
3. Naive Bayesian classification function
Code implementation:
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + np.log(pClass1) #element-wise mult
p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
def testingNB():
listOPosts, listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)
trainMat = []
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V, p1V, pAb = trainNB0(np.array(trainMat), np.array(listClasses))
testEntry = ['love', 'my', 'dalmation']
thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry))
if classifyNB(thisDoc,p0V,p1V,pAb):
print(testEntry,'It belongs to insulting vocabulary')
else:
print(testEntry,'It belongs to non insulting vocabulary')
testEntry = ['stupid', 'garbage']
thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry))
if classifyNB(thisDoc, p0V, p1V, pAb):
print(testEntry, 'It belongs to insulting vocabulary')
else:
print(testEntry, 'It belongs to non insulting vocabulary')Result display:

4. Prepare data: document word bag model
So far, we take the occurrence of each word as a feature, which can be described as a set of words model. If - a word appears in the document more than once, it may mean that it contains some information that cannot be expressed by whether the word appears in the document. This method is called bag of words model . in the word bag, each word can appear multiple times, while in the word set, each word can only appear once. To adapt to the word bag model, the function setofWords2Vec() needs to be slightly modified. The modified function is called bagOfWords2Vec().
It is almost the same as the function setOfWords2Vec(). The only difference is that whenever a word is encountered, it increases the corresponding value in the word vector, rather than just setting the corresponding value to 1
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec3, Spam filtering using naive Bayes
Function spamTest() Automate the Bayesian spam classifier. Import the text files under the folders spam and ham and parse them into the vocabulary. Next, build a test set and a training set. The messages in both sets are randomly selected. In this example, there are 50 messages, of which 10 messages are randomly selected as the test set. The probability required by the classifier Calculation refers to using the documents in the training set to complete. The Python variable trainingSet is a list of integers with values from 0 to 49. Next two, randomly select 10 files, and the documents corresponding to the selected numbers are added to the training set and also proposed from the training set. This process of randomly selecting part of the data as the training set and the rest as the test set is called retention Assuming that only one iteration has been completed, in order to estimate the error rate of the classifier more accurately, the average error rate should be obtained after multiple iterations.
The next for loop traverses all the documents of the training set, builds the word vector based on the vocabulary for each message and uses the setOfWords2Vec() function. These words are used in the trainNB0() function to calculate the probability required for classification, and then traverses the test set
def spamTest():
docList = []; classList = []; fullText = []
for i in range(1, 26):
wordList = textParse(open('D:/pycharm/experiment/test/spam/%d.txt' % i,encoding="ISO-8859-1").read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(1) #Mark spam, 1 indicates spam
wordList = textParse(open('D:/pycharm/experiment/test/ham/%d.txt' % i,encoding="ISO-8859-1").read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(0) #Mark non spam, 0 means non spam
vocabList = createVocabList(docList)#create vocabulary
trainingSet = range(50); testSet = [] #create test set
for i in range(10): # From the 50 emails, 40 were randomly selected as the training set and 10 as the test set
randIndex = int(np.random.uniform(0, len(trainingSet)))
testSet.append(trainingSet[randIndex])
del(list(trainingSet)[randIndex])
trainMat = []; trainClasses = []
for docIndex in trainingSet:#train the classifier (get probs) trainNB0
trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex]))
trainClasses.append(classList[docIndex])
p0V, p1V, pSpam = trainNB0(np.array(trainMat), np.array(trainClasses)) #Training naive Bayesian model
errorCount = 0
for docIndex in testSet: #Classify test sets
wordVector = bagOfWords2VecMN(vocabList, docList[docIndex])
if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]: #If the classification is wrong
errorCount += 1 #Number of errors plus one
print("Misclassification test set", docList[docIndex])
print('The error rate is: ', float(errorCount)/len(testSet))
Result display:

Because the function spamTest() outputs the classification error rate of 10 random emails, the results may be different each time. Sometimes the error rate will be 0. When the error rate is 0, it means that there is no error in spam classification; sometimes it is not 0. When the error rate is not 0, the test set with classification error will be output , In this way, you can know which document has the error.
Note: all the codes of this blog are based on machine learning practice