Record the process of machine learning
git clone problem
git config --global http.lowSpeedLimit 0
git config --global http.lowSpeedTime 999999
git config --global http.postBuffer 50024288000
On January 15, 2020, in order to prepare for the re examination of Xidian and complete the machine learning, since the undergraduate has not studied and has no foundation, it is recorded here. At the same time, the undergraduate projects have been forgotten, which is also to cultivate good habits.
Machine learning pipeline
Data – machine learning algorithm – intelligence
Learning objectives
Install python, IPython notebook, and create
Start ipython notebook
Write variables, functions and loops in python
Using sframe to perform basic data operations in python
Install graphilab create through command line
The last step is to install graph lab create in anaconda prompt
python basic syntax
Import graphic lab in notebook
graphlab canvas
visualization
After importing the dataset, use SF Show() for data visualization
canvas data redirection: redirect visual data to ipython notebook:
graphlab.canvas.set_target('ipynb')
Conversion function apply
A column of data Apply (custom function)
sf['Country'].apply(transform_country)
Recommendation system


Very popular items will drown other effects. For example, if everyone buys diapers, it does not mean that I also need them. It is lack of personalization. It is necessary to normalize the matrix of overly popular items.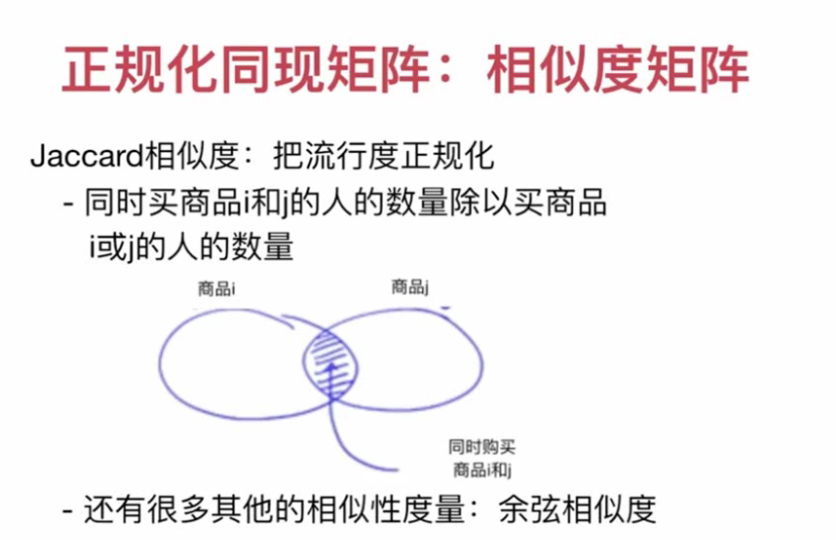




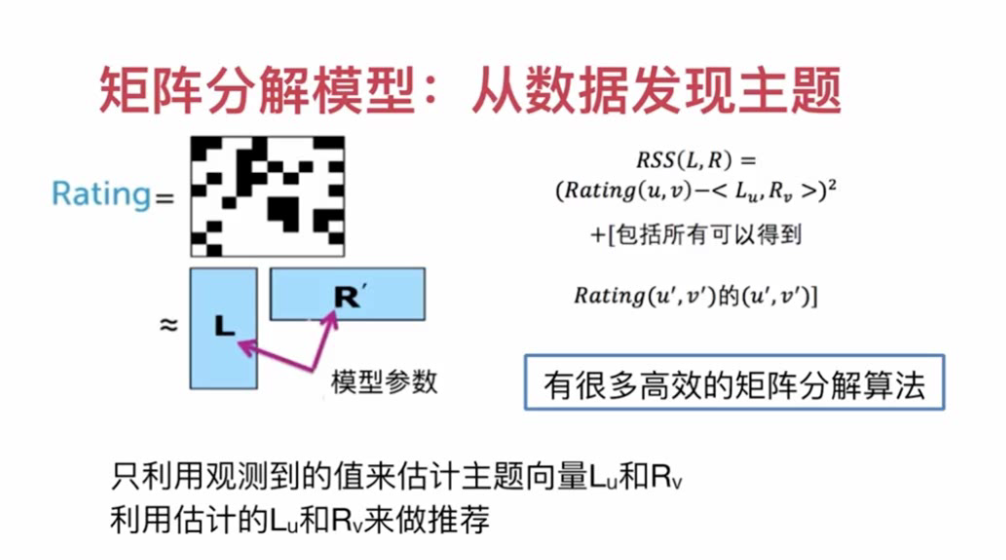

Synthesis = characteristic + matrix decomposition


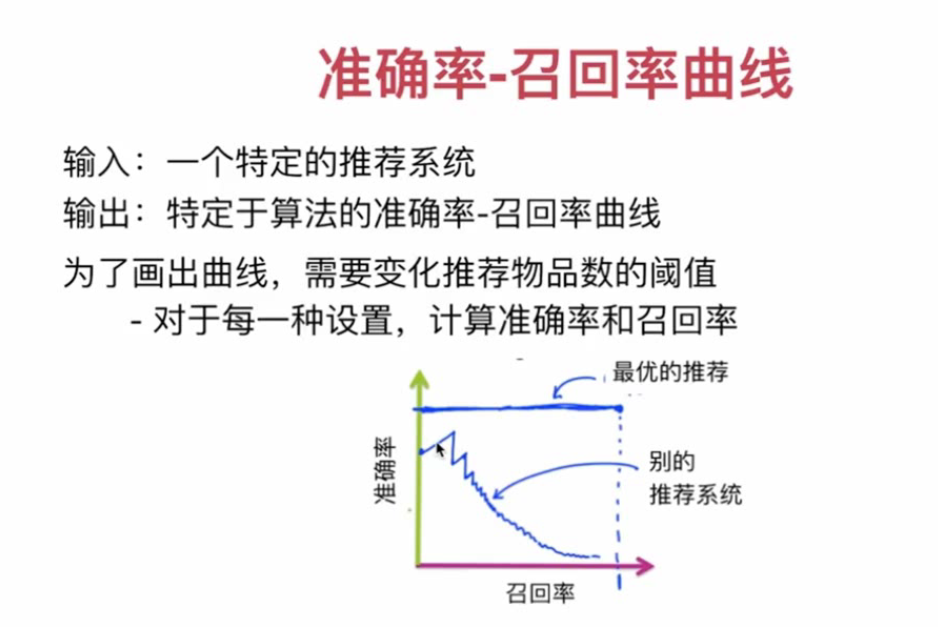
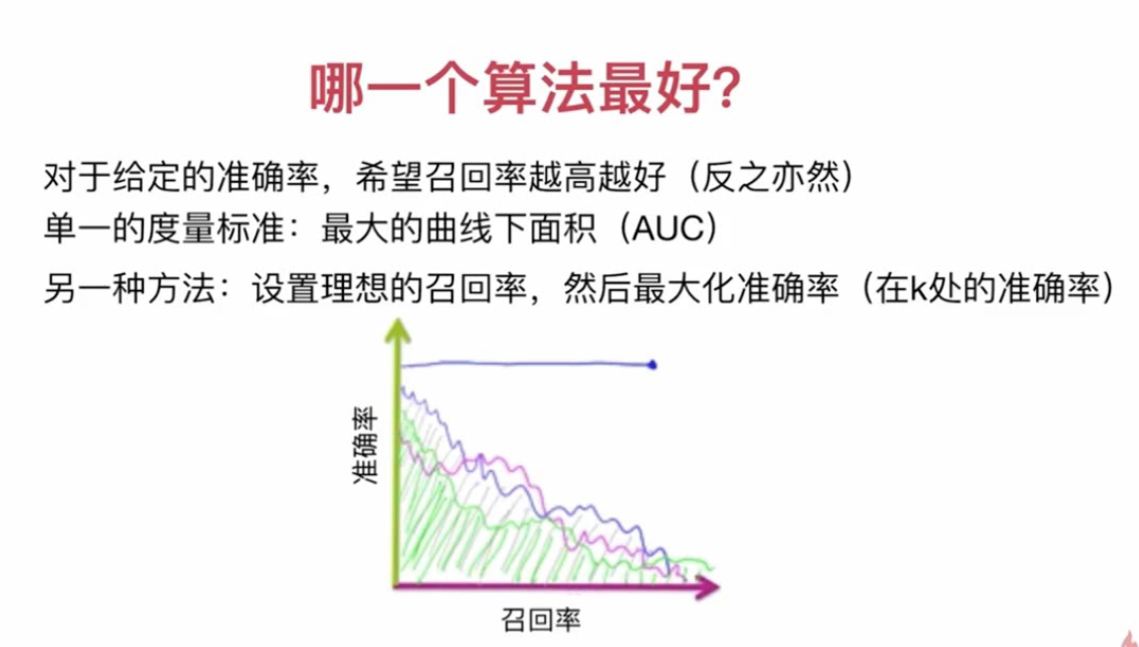
Performance measurement of recommendation system: recall rate and accuracy rate
Recall rate = recommended favorite items / all favorite items
Accuracy = recommended favorite items / recommended items
The accuracy is not ideal when the recall rate is the highest
Best recommendation: recall rate = accuracy rate = 1
import graphlab
song_data = graphlab.SFrame('song_data.gl/')
song_data.head()
song_data['song'].show()
len(song_data)
users=song_data['user_id'].unique()
len(users)
train_data,test_data=song_data.random_split(.8,seed=0)
popularity_model=graphlab.popularity_recommender.create(train_data,user_id='user_id',item_id='song')
popularity_model.recommend(users=[users[0]])
personalized_model=graphlab.item_similarity_recommender.create(train_data,user_id='user_id',item_id='song')
personalized_model.recommend(users=[users[0]])
model_performance=graphlab.compare(test_data,[popularity_model,personalized_model],user_sample=0.05)
graphlab.show_comparison(model_performance,[popularity_model,personalized_model])





Netease cloud music UID
http://192.168.3.2:3000/v1/likelist?uid=645954254
Return data to get music ID
{"ids":[18638059,26217117],"checkPoint":1582996860453,"code":200}
Get the daily songs recommended by Netease cloud
Log in first:
http://192.168.3.2:3000/v1/login/cellphone?phone=17772002134&password=614919799
Re acquisition:
http://192.168.3.2:3000/v1/recommend/songs
There is a problem getting song details. You can get similar songs
http://192.168.3.2:3000/v1/simi/song?id=26217117
Alternative API for obtaining song details:
https://api.imjad.cn/cloudmusic.md
https://api.imjad.cn/cloudmusic/?type=detail&id=26217117
Construction of music recommendation system
Recommended system construction 1
Data acquisition
# -*- coding:utf-8 -*-
"""
The crawler crawls the data packet of Netease cloud music song list and saves it as json file
python2.7 environment
"""
import sys
reload(sys)
//Solve the problem of character scrambling
sys.setdefaultencoding('utf-8')
import os
os.environ['NLS_LANG'] = 'Simplified Chinese_CHINA.ZHS16GBK'
import requests
import json
import os
import base64
import binascii
import urllib
import urllib2
from Crypto.Cipher import AES
from bs4 import BeautifulSoup
class NetEaseAPI:
def __init__(self):
self.header = {
'Host': 'music.163.com',
'Origin': 'https://music.163.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0',
'Accept': 'application/json, text/javascript',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded',
}
self.cookies = {'appver': '1.5.2'}
self.playlist_class_dict = {}
self.session = requests.Session()
def _http_request(self, method, action, query=None, urlencoded=None, callback=None, timeout=None):
connection = json.loads(self._raw_http_request(method, action, query, urlencoded, callback, timeout))
return connection
def _raw_http_request(self, method, action, query=None, urlencoded=None, callback=None, timeout=None):
if method == 'GET':
request = urllib2.Request(action, self.header)
response = urllib2.urlopen(request)
connection = response.read()
elif method == 'POST':
data = urllib.urlencode(query)
request = urllib2.Request(action, data, self.header)
response = urllib2.urlopen(request)
connection = response.read()
return connection
@staticmethod
def _aes_encrypt(text, secKey):
pad = 16 - len(text) % 16
text = text + chr(pad) * pad
encryptor = AES.new(secKey, 2, '0102030405060708')
ciphertext = encryptor.encrypt(text)
ciphertext = base64.b64encode(ciphertext).decode('utf-8')
return ciphertext
@staticmethod
def _rsa_encrypt(text, pubKey, modulus):
text = text[::-1]
rs = pow(int(binascii.hexlify(text), 16), int(pubKey, 16), int(modulus, 16))
return format(rs, 'x').zfill(256)
@staticmethod
def _create_secret_key(size):
return (''.join(map(lambda xx: (hex(ord(xx))[2:]), os.urandom(size))))[0:16]
def get_playlist_id(self, action):
request = urllib2.Request(action, headers=self.header)
response = urllib2.urlopen(request)
html = response.read().decode('utf-8')
response.close()
soup = BeautifulSoup(html, 'lxml')
list_url = soup.select('ul#m-pl-container li div a.msk')
for k, v in enumerate(list_url):
list_url[k] = v['href'][13:]
return list_url
def get_playlist_detail(self, id):
text = {
'id': id,
'limit': '100',
'total': 'true'
}
text = json.dumps(text)
nonce = '0CoJUm6Qyw8W8jud'
pubKey = '010001'
modulus = ('00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7'
'b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280'
'104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932'
'575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b'
'3ece0462db0a22b8e7')
secKey = self._create_secret_key(16)
encText = self._aes_encrypt(self._aes_encrypt(text, nonce), secKey)
encSecKey = self._rsa_encrypt(secKey, pubKey, modulus)
data = {
'params': encText,
'encSecKey': encSecKey
}
action = 'http://music.163.com/weapi/v3/playlist/detail'
playlist_detail = self._http_request('POST', action, data)
return playlist_detail
if __name__ == '__main__':
nn = NetEaseAPI()
index = 1
for flag in range(1, 38):
if flag > 1:
page = (flag - 1) * 35
url = 'http://music.163.com/discover/playlist/?order=hot&cat=%E5%85%A8%E9%83%A8&limit=35&offset=' + str(
page)
else:
url = 'http://music.163.com/discover/playlist'
playlist_id = nn.get_playlist_id(url)
for item_id in playlist_id:
playlist_detail = nn.get_playlist_detail(item_id)
with open('data/{0}.json'.format(index), 'w') as file_obj:
json.dump(playlist_detail, file_obj, ensure_ascii=False)
index += 1
print("write in json File:", item_id)
Feature Engineering and data preprocessing to extract the useful feature information of my recommendation system this time
# -*- coding:utf-8-*-
"""
For all song list crawlers in Netease cloud json File data preprocessing csv file
python3.6 environment
"""
import io
from __future__ import (absolute_import, division, print_function, unicode_literals)
import json
def parse_playlist_item():
"""
:return: Parse into userid itemid rating timestamp Line format
"""
file = io.open("neteasy_playlist_recommend_data.csv", 'a', encoding='utf8')
for i in range(1, 1292):
with io.open("{0}.json".format(i), 'r', encoding='UTF-8') as load_f:
load_dict = json.load(load_f)
try:
for item in load_dict['playlist']['tracks']:
# playlist id # song id # score # datetime
line_result = [load_dict['playlist']['id'], item['id'], item['pop'], item['publishTime']]
for k, v in enumerate(line_result):
if k == len(line_result) - 1:
file.write(str(v))
else:
file.write(str(v) + ',')
file.write('\n')
except Exception:
print(i)
continue
file.close()
def parse_playlist_id_to_name():
file = io.open("neteasy_playlist_id_to_name_data.csv", 'a', encoding='utf8')
for i in range(1, 1292):
with io.open("{0}.json".format(i), 'r', encoding='UTF-8') as load_f:
load_dict = json.load(load_f)
try:
line_result = [load_dict['playlist']['id'], load_dict['playlist']['name']]
for k, v in enumerate(line_result):
if k == len(line_result) - 1:
file.write(str(v))
else:
file.write(str(v) + ',')
file.write('\n')
except Exception:
print(i)
continue
file.close()
def parse_song_id_to_name():
file = io.open("neteasy_song_id_to_name_data.csv", 'a', encoding='utf8')
for i in range(1, 1292):
with io.open("{0}.json".format(i), 'r', encoding='UTF-8') as load_f:
load_dict = json.load(load_f)
try:
for item in load_dict['playlist']['tracks']:
# playlist id # song id # score # datetime
line_result = [item['id'], item['name'] + '-' + item['ar'][0]['name']]
for k, v in enumerate(line_result):
if k == len(line_result) - 1:
file.write(str(v))
else:
file.write(str(v) + ',')
file.write('\n')
except Exception:
print(i)
continue
file.close()
parse_playlist_item()
parse_playlist_id_to_name()
parse_song_id_to_name()
Surprise recommendation Library (recommended song list)
# -*- coding:utf-8-*-
"""
utilize surprise Recommendation Library KNN Collaborative filtering algorithm recommends Netease cloud song list
python2.7 environment
"""
from __future__ import (absolute_import, division, print_function, unicode_literals)
import os
import csv
from surprise import KNNBaseline, Reader, KNNBasic, KNNWithMeans
from surprise import Dataset
def recommend_model():
file_path = os.path.expanduser('neteasy_playlist_recommend_data.csv')
# Specify file format
reader = Reader(line_format='user item rating timestamp', sep=',')
# Read data from file
music_data = Dataset.load_from_file(file_path, reader=reader)
# Calculate the similarity between songs
train_set = music_data.build_full_trainset()
print('Start using collaborative filtering algorithm to train recommendation model...')
algo = KNNBasic()
algo.fit(train_set)
return algo
def playlist_data_preprocessing():
csv_reader = csv.reader(open('neteasy_playlist_id_to_name_data.csv'))
id_name_dic = {}
name_id_dic = {}
for row in csv_reader:
id_name_dic[row[0]] = row[1]
name_id_dic[row[1]] = row[0]
return id_name_dic, name_id_dic
def song_data_preprocessing():
csv_reader = csv.reader(open('neteasy_song_id_to_name_data.csv'))
id_name_dic = {}
name_id_dic = {}
for row in csv_reader:
id_name_dic[row[0]] = row[1]
name_id_dic[row[1]] = row[0]
return id_name_dic, name_id_dic
def playlist_recommend_main():
print("Load song list id Dictionary mapping to song single name...")
print("Load song list name to song list id Dictionary mapping for...")
id_name_dic, name_id_dic = playlist_data_preprocessing()
print("Dictionary mapping succeeded...")
print('Building data sets...')
algo = recommend_model()
print('End of model training...')
current_playlist_id = id_name_dic.keys()[102]//Song list id
print('Current song list id: ' + current_playlist_id)
current_playlist_name = id_name_dic[current_playlist_id]
print("Current song list name:")
print(current_playlist_name)
playlist_inner_id = algo.trainset.to_inner_uid(current_playlist_id)
print('Current song list internal id: ' + str(playlist_inner_id))
playlist_neighbors = algo.get_neighbors(playlist_inner_id, k=10)
playlist_neighbors_id = (algo.trainset.to_raw_uid(inner_id) for inner_id in playlist_neighbors)
# Convert song id to song name
playlist_neighbors_name = (id_name_dic[playlist_id] for playlist_id in playlist_neighbors_id)
print("And song list<", current_playlist_name, '> The closest 10 songs are:\n')
for playlist_name in playlist_neighbors_name:
print(playlist_name, name_id_dic[playlist_name])
playlist_recommend_main()
Operation results
Load song list id Dictionary mapping to song single name... Load song list name to song list id Dictionary mapping for... Dictionary mapping succeeded... Building data sets... Start using collaborative filtering algorithm to train recommendation model... Computing the msd similarity matrix... Done computing similarity matrix. End of model training... Current song list id: 4879924824 Current song list name: [Good doctor episode BGM Season 2 Current song list internal id: 812 And song list< [Good doctor episode BGM Season 2 > The closest 10 songs are: good doctor BGM 3195822488 4869100193 4875075726 Children chasing stars always have endless stars in their dreams City pop ‖ Urban enjoyment 3133725493 [Medieval ballad] bard and Elegy of the times 89963967 Early spring advertisement | Warm male voice, sunshine flowing into the bottom of my heart 3186322538 Private radar|Create 3136952023 for you according to the listening records Get up 3079182188 [Private customization in Europe and America] Know your European and American recommendations best. Update 35 songs every day 2829816518 「pure tone」Find a corner of clean, flowers from the dust 3066614455
Recommended system construction 2
Netease cloud music song recommendation system based on Word2Vec
# -*- coding:utf-8-*-
import os
import json
from random import shuffle
import multiprocessing
import gensim
import csv
def train_song2vec():
"""
:return: All song lists song2Vec Model training and preservation
"""
songlist_sequence = []
# Read the original data of Netease cloud music
for i in range(1, 1292):
with open("{0}.json".format(i), 'r') as load_f:
load_dict = json.load(load_f)
parse_songlist_get_sequence(load_dict, songlist_sequence)
# Multiprocess computing
cores = multiprocessing.cpu_count()
print('Using all {cores} cores'.format(cores=cores))
print('Training word2vec model...')
model = gensim.models.Word2Vec(sentences=songlist_sequence, size=150, min_count=3, window=7, workers=cores)
print('Save model..')
model.save('songVec.model')
def parse_songlist_get_sequence(load_dict, songlist_sequence):
"""
Analyze the songs in each song list id information
:param load_dict: Contains an original list of all songs in a song list
:param songlist_sequence: All given in a song list id sequence
:return:
"""
song_sequence = []
for item in load_dict['playlist']['tracks']:
try:
song = [item['id'], item['name'], item['ar'][0]['name'], item['pop']]
song_id, song_name, artist, pop = song
song_sequence.append(str(song_id))
except:
print('song format error')
for i in range(len(song_sequence)):
shuffle(song_sequence)
# The list() here must be added, or the songs in songlist are not randomly disordered sequences at all, but all the same sequences
songlist_sequence.append(list(song_sequence))
def song_data_preprocessing():
"""
song id Mapping to song names
:return: song id Mapping dictionary to song name, song name to song id Mapping dictionary for
"""
csv_reader = csv.reader(open('neteasy_song_id_to_name_data.csv'))
id_name_dic = {}
name_id_dic = {}
for row in csv_reader:
id_name_dic[row[0]] = row[1]
name_id_dic[row[1]] = row[0]
return id_name_dic, name_id_dic
train_song2vec()
model_str = 'songVec.model'
# Load word2vec model
model = gensim.models.Word2Vec.load(model_str)
id_name_dic, name_id_dic = song_data_preprocessing()
#song_id_list = list(id_name_dic.keys())[4000:5000:200]
song_id_list = id_name_dic.keys()[1000:1500:50]//Data selection, interval 50
for song_id in song_id_list:
result_song_list = model.most_similar(song_id)
print(song_id)
print(json.dumps(id_name_dic[song_id],encoding='UTF-8',ensure_ascii=False))
print('\n Similar songs and similarities are:')
for song in result_song_list:
print(json.dumps(id_name_dic[song[0]],encoding='UTF-8', ensure_ascii=False))
print(song[1])
#print('\t' + id_name_dic[song[0]].encode('utf-8'), song[1])
print('\n')
Operation results
Using all 4 cores Training word2vec model... Save model.. 420513125 "レイディ・ブルース-LUCKY TAPES" Similar songs and similarities are: "key word-Lin Junjie" 0.626468360424 "Mercury-Guo Ding" 0.621081233025 "Fish larvae( Cover: Lu Guangzhong)-It's your Yao" 0.619691371918 "Arrogance-en" 0.617167830467 "The beauty of the world is linked with you-Cypress pine" 0.615520179272 "hobby-Yan Renzhong" 0.614804267883 "Big sleep (Full version)-Little LEGO" 0.613656818867 "It's all you-DP Dragon pig" 0.612156033516 "blue-Shi Baiqi" 0.612105309963 "I Know You Know I Love You-Sunset Rollercoaster " 0.61181396246 1422705673 "Past Lives(Cover: BØRNS)-Sun Zhenhan" Similar songs and similarities are: "I still miss her( Cover: Lin Junjie)-Uu" 0.590772628784 "All thoughts are stars-CMJ" 0.578336238861 "blue-Shi Baiqi" 0.576055586338 "Love songs in the past few years-AY Yang aosan" 0.575863420963 "You have to believe that this is not the last day-Hua Chenyu" 0.56902128458 "Seven days seven days-Ono Road ono" 0.567467391491 "The truth that you leave-Pianoboy PianoBoy " 0.562936365604 "Toon-Shen Yicheng" 0.560849130154 "The beauty of the world is linked with you-Cypress pine" 0.559100747108 "Kepler -Sun Yanzi" 0.55870193243 18790760 "Wildest Moments-Jessie Ware" Similar songs and similarities are: "third person-Todd Li" 0.542654037476 "MELANCHOLY-White Cherry" 0.536370813847 "10%-SynBlazer" 0.53133648634 "Roundabout-Yes" 0.531289100647 "1%-Oscar Scheller" 0.528999328613 "later-Liu Ruoying" 0.526810228825 "Creep-Gamper & Dadoni" 0.523189365864 "Kitarman-Ghulamjan Yakup" 0.521900355816 "Big sleep (Full version)-Little LEGO" 0.521808922291 "I want to be with you in the century-Prism" 0.520630300045 4898223 "Universe Song-Toki Asako " Similar songs and similarities are: "Adagio for Summer Wind-Shimizu Zhunyi" 0.671902596951 "Uninhabited island-Still" 0.653309166431 "DJ DJ Give me one K (DJ Tiktok)-An xiaoleng" 0.653192460537 "Something Just Like This (Megamix)-AnDyWuMUSICLAND" 0.650882899761 "My Heart Will Go On-Man Shuke" 0.649816930294 "Summer-Long stone" 0.649288952351 "hibernation-si'nan" 0.645800054073 "I Want You To Know (Hella x Pegato Remix) -Pegato" 0.641312420368 "All thoughts are stars-CMJ" 0.641280949116 "Neon Rainbow (feat. Anna Yvette)-Rameses B" 0.641224443913 1342678507 "Flying Saucer-Shlump" Similar songs and similarities are: "The Lost Ballerina (Radio Edit)-Fiona Joy Hawkins" 0.587948739529 "Mercury-Guo Ding" 0.582286775112 "Cyka Blyat-DJ Blyatman" 0.579136252403 "Crusade-Marshmello" 0.575079441071 "blue-Shi Baiqi" 0.570292174816 "May the rest of your life be long-Wang Erlang" 0.570254147053 "You have to believe that this is not the last day-Hua Chenyu" 0.566699206829 "Big break running music-Stars" 0.566686093807 "See You Again-Wiz Khalifa" 0.565815865993 "Want freedom-Lin Yujia" 0.563404619694 558572724 "Liu Ruoying-Later (shuixiao) Remix)-Er Gou Cun Gao Fu Shuai" Similar songs and similarities are: "Little Girl (As Featured in \"Unbroken: Path to Redemption\" Film)-Andrea Litkei" 0.561440587044 "Big city little love-Wang Lihong" 0.548691391945 "You Look Lovely-Music therapy" 0.544121265411 "Guanshan liquor-What are you waiting for" 0.543048799038 "A( Chinese Wedding)-Ge Dongqi" 0.53617054224 "red high-heeled shoes-Cai Jianya" 0.534194111824 "The beauty of the world is linked with you-Cypress pine" 0.532548666 "Dancing With Your Ghost-Sasha Sloan" 0.532440066338 "The Way I Still Love You-Reynard Silva" 0.532300829887 "Be My Mistake-The 1975" 0.532189667225 574274427 "Whip Blow-Yuji Kondo" Similar songs and similarities are: "The girl said to me (Full version)-Uu" 0.466711193323 "Che m'importa del mondo-Rita Pavone" 0.460101604462 "Wild soul duel (Live)-Hua Chenyu" 0.444359987974 "Monsters (Live)-Zhou Shen" 0.440917819738 "Jackdaw boy (Live)-Hua Chenyu" 0.43233910203 "Reality-Lost Frequencies" 0.418823868036 "Jackdaw boy-Hua Chenyu" 0.418192714453 "Dream of Xizhou (Siheyuan version)( Cover: It's hard to fall in love with an old friend)-Four roasted wings" 0.4164057374 "Sayama Rain 2?(?Demo)-The Nature Sounds Society Japan" 0.415658026934 "Sacred tree (Live)-Hua Chenyu" 0.410130620003 22637718 "どうかsessionきますように-SMAP" Similar songs and similarities are: "Stardustビーナス-Aimer" 0.52750056982 "There For You-Martin Garrix" 0.522041022778 "Blanc-Sylvain Chauveau" 0.503010869026 "Pyro-Chester Young" 0.50101774931 "21 Miles-MY FIRST STORY" 0.499602258205 ""dewをabsorbうGroup "-Masuda Toshio " 0.498453527689 "I-Zhang Guorong" 0.495759695768 "Manta-Liu Boxin Lexie" 0.495319634676 "ᐇ-Seto" 0.495067447424 "Cyka Blyat-DJ Blyatman" 0.493984639645 1376148033 "Love should be open( Cover: Xiao Xiao)-Little genius duck" Similar songs and similarities are: "The girl said to me (Full version)-Uu" 0.548079669476 "intro (w rook1e)-barnes blvd." 0.540413379669 "Uninhabited island( Cover: (still)-It's your Yao" 0.517935693264 "You Look Lovely-Music therapy" 0.51715862751 "pure imagination-ROOK1E" 0.515536487103 "I Want You To Know (Hella x Pegato Remix) -Pegato" 0.514691889286 "Wonderful World-ChakYoun9" 0.51469117403 "GOOD NIGHT-Lil Ghost Kid" 0.514522790909 "For years-Liu Xin" 0.512091457844 "7 %-XMASwu" 0.511670172215 1407561335 "Go after a deer-Vientiane fanyin" Similar songs and similarities are: "Late summer-Zhou Han" 0.60853689909 "Star tea party-Hui Che" 0.604638457298 "Arrogance-en" 0.602224886417 "Sweetest love song-Red man Pavilion" 0.601751744747 "blue-Shi Baiqi" 0.60148859024 "Monody (Radio Edit)-TheFatRat" 0.601218402386 "My Heart Will Go On-Man Shuke" 0.600651681423 "Just love you too much-Ding Funi" 0.599411010742 "The rain-Vsun" 0.598190009594 "Frisbee-Ahxello" 0.59788608551