* [StandardScaler and MinMaxScaler How to choose?](about:blank#StandardScaler__MinMaxScaler__210)
* [Missing value](about:blank#_226)
* * [Missing value filling impute.SimpleImputer](about:blank#_imputeSimpleImputer_244)
* [Handling typing features: coding and dummy variables](about:blank#_370)
* * [preprocessing.LabelEncoder Label specific, which converts classification to classification value](about:blank#preprocessingLabelEncoder___380)
* [preprocessing.OrdinalEncoder Feature specific, which converts classification features into classification values](about:blank#preprocessingOrdinalEncoder__409)
* [preprocessing.OneHotEncoder Single hot coding, creating dummy variables](about:blank#preprocessingOneHotEncoder__422)
* [summary](about:blank#_464)
* [Dealing with continuous features: binarization and segmentation](about:blank#_469)
* * [sklearn.preprocessing.Binarizer Binarize the data according to the threshold](about:blank#sklearnpreprocessingBinarizer__470)
* [preprocessing.KBinsDiscretize](about:blank#preprocessingKBinsDiscretize_484)
Notes catalogue of machine learning sklearn class of vegetables + courseware
I don't understand it. Small head, big question mark
Stories in introduction to data mining
One day you get data on the clinical manifestations of patients from your colleague, a drug researcher. The drug researcher asked you to use the first four columns of data to predict the last column of data. He also said that he would be on a business trip for a few days, so he may not be able to study the data with you. I hope to have a preliminary analysis result after returning from the business trip. So you look at the data. It's very common to predict continuous variables. It's easy to say that you can adjust the random forest regressor, adjust the parameters, adjust the MSE, and run a good result.
A few days later, your colleague came back from a business trip and was ready to have a meeting together. At the meeting, you met a statistician working on the same project as your colleague. When he asked about your analysis results, you said you had achieved little results. The statistician was surprised. He said, "yes, there are too many problems in this group of data, and I can't analyze anything."
You may have a click in your heart and answer nervously, "I haven't heard of any problems with the data."
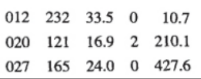
Statistician: "the fourth column of data is very pitiful. The value range of this feature is 1 ~ 10. 0 indicates the missing value. Moreover, they make mistakes when entering data. Many 10 have been entered as 0, and now they can't tell."
You: "
Statistician: "and the data in the second column and the third column are basically the same. The correlation is too strong."
You: "I found this, but these two features are not very important in prediction. No matter how other features go wrong, the results on my side show that the features in the first column are the most important, so it doesn't matter."
Statistician: "what? Isn't the first column the number?"
You: "No."
Statistician: "Oh, I remember! The first column is the number, but the number is compiled after we sort according to the fifth column! The first column and the fifth column are strongly related, but they are meaningless!"
The old blood sprayed a screen, and the data mining engineer died.
The data suck, and the advanced algorithm is useless.
The data provided in the classroom, major machine learning textbooks and sklearn are perfect data sets; The data in reality is eighteen thousand miles worse than the data used for learning at ordinary times. Therefore, it is necessary for us to learn about the process before modeling, data preprocessing and feature engineering.
Data preprocessing and Feature Engineering - Overview
==================================================================================
Five processes of data mining:
-
get data
-
Data preprocessing
Data preprocessing is the process of detecting, correcting or deleting records that are damaged, inaccurate or unsuitable for the model from the data
The possible problems are: different data types, such as some text, some numbers, some time series, some continuous and some intermittent. It is also possible that the quality of the data is not good, with noise, abnormality, loss, data error, different dimensions, duplication, data skewness, and the amount of data is too large or too small
The purpose of data preprocessing is to make the data adapt to the model and match the requirements of the model
-
Characteristic Engineering:
Feature engineering is the process of transforming the original data into features that can better represent the potential problems of the prediction model. It can be realized by selecting the most relevant features, extracting features and creating features. Feature creation is often realized by dimension reduction algorithm.
The possible problems are: there is correlation between features, features have nothing to do with labels, features are too many or too small, or simply can not show the due data phenomenon or show the real face of data
The purpose of feature engineering is to 1) reduce the calculation cost and 2) improve the upper limit of the model
-
Model, test the model and predict the results
-
Go online to verify the effect of the model
Data preprocessing and Feature Engineering in sklearn
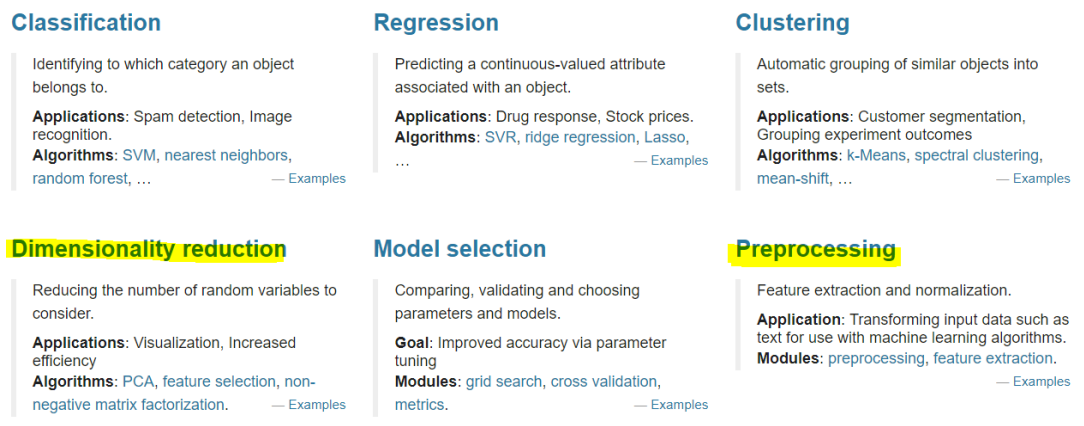
Sklearn contains many modules related to data preprocessing and feature engineering. Two of the six blocks of sklearn are about data preprocessing and feature engineering. The two blocks interact with each other to lay the foundation for all projects before modeling
-
Module preprocessing: it contains almost all the contents of data preprocessing
-
Module impulse: special for filling in missing values
-
Module feature_selection: contains the practice of various methods of feature selection
-
Module decomposition: including dimension reduction algorithm
===============================================================================================
Dimensionless: convert data of different specifications to the same specification, or data of different distributions to a specific distribution
For example, in the algorithms with gradient and matrix as the core, the dimensionless of logistic regression, support vector machine and neural network can speed up the solution speed; In distance models, such as k-nearest neighbors and K-Means clustering, dimensionless can help us improve the accuracy of the model and avoid the impact of a feature with a particularly large value range on distance calculation.
The integration algorithm of decision tree and tree is a special case. We don't need dimensionless decision tree. Decision tree can handle any data well
Dimensionless data can be linear or nonlinear.
Dimensionless linearization includes:
-
Centralized processing (zero centered or mean subcontract)
The essence of centralization is to subtract a fixed value from all records, that is, to translate the sample data to a certain position
-
Scale processing
The essence of scaling is to fix the data in a certain range by dividing by a fixed value (taking logarithm is also a scaling process)
Data normalization preprocessing MinMaxScaler
Data Normalization (also known as min max scaling): when the data (x) is centered according to the minimum value and then scaled according to the range (maximum minimum value), the data moves the minimum value by units and will converge to [0,1].
The normalized data follows the normal distribution, and the formula is as follows:
x ∗ = x − m i n ( x ) m a x ( x ) − m i n ( x ) x^* = \frac {x-min(x)} {max(x) - min(x)} x∗=max(x)−min(x)x−min(x)
Note the distinction between normalization and regularization
Normalization is normalization, not regularization; Regularization is not a means of data preprocessing
In sklearn, we use preprocessing Minmaxscaler to realize the data normalization function.
- It has an important parameter feature_range, which controls the range to which we want to compress data. The default is [0,1]
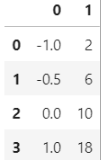
from sklearn.preprocessing import MinMaxScaler data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
#Can you judge the structure of data if you are not familiar with numpy?
#What would it look like to change to a watch?
import pandas as pd
pd.DataFrame(data)
#Realize normalization
scaler = MinMaxScaler() # instantiation
scaler = scaler.fit(data) #fit, where the essence is to generate min(x) and max(x)
result = scaler.transform(data) # exports the result through the interface
result
"""
array([[0. , 0. ],
[0.25, 0.25], [0.5 , 0.5 ], [1. , 1. ]])
"""
result_ = scaler.fit_transform(data) #Training and export results are achieved in one step
result_
"""
array([[0. , 0. ],
[0.25, 0.25],
[0.5 , 0.5 ],
[1. , 1. ]])
"""
scaler.inverse_transform(result) # reverses the normalized result
"""
array([[ 5. , 5. ],
[ 6.25, 6.25], [ 7.5 , 7.5 ], [10. , 10. ]])
"""
#Use the parameter feature of MinMaxScaler_ Range normalizes the data to a range other than [0,1]
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = MinMaxScaler(feature_range=[5,10]) #Still instantiate
result = scaler.fit_transform(data) #fit_transform one step export results
result
"""
array([[ 5. , 5. ],
[ 6.25, 6.25],
[ 7.5 , 7.5 ],
[10. , 10. ]])
"""
```
> When X When the number of features in is very large, fit Will report an error and say: the amount of data is too large for me to calculate
> Use at this time partial\_fit As training interface
>
> ```
> scaler = scaler.partial_fit(data)
> ```
> **use numpy To achieve normalization**
>
> ```
> import numpy as np
> X = np.array([[-1, 2], [-0.5, 6], [0, 10], [1, 18]])
> #normalization
> X_nor = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
> X_nor
> #Reverse normalization
> X_returned = X_nor * (X.max(axis=0) - X.min(axis=0)) + X.min(axis=0)
> X_returned
> ```
### []( https://gitee.com/vip204888/java-p7 )Data standardization preprocessing StandardScaler
**Data standardization(Standardization,also called Z-score normalization)**: When data(x)By mean(μ)After centralization, according to the standard deviation(σ)After scaling, the data will obey the normal distribution (i.e. standard normal distribution) with mean value of 0 and variance of 1. The formula is as follows:
x ∗ = x − μ σ x^\* = \\frac {x - \\mu} {\\sigma} x∗\=σx−μ
```
from sklearn.preprocessing import StandardScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = StandardScaler() # instantiation
scaler.fit(data) #fit, essentially generating mean and variance
scaler.mean_ #View the average attribute mean_ # array([-0.125, 9. ]) scaler.var_ #View the variance attribute var_ # array([ 0.546875, 35. ])
x_std = scaler.transform(data) # exports the result through the interface
x_ The result of std.mean() # export is an array. Use mean() to check the mean value
0.0
x_std.std() # use std() to view variance
#1.0
scaler.fit_transform(data) #Using fit_transform(data) achieves the result in one step
"""
array([[-1.18321596, -1.18321596],
[-0.50709255, -0.50709255],
[ 0.16903085, 0.16903085],
[ 1.52127766, 1.52127766]])
"""
scaler.inverse_transform(x_std) # use inverse_transform reverse standardization
"""
array([[-1. , 2. ],
[-0.5, 6. ], [ 0. , 10. ], [ 1. , 18. ]])
"""
about StandardScaler and MinMaxScaler For example, null NaN Will be regarded as**Missing value**,
* stay fit Ignore when
* stay transform Keep missing when NaN Status display of
Although the de dimensioning process is not a specific algorithm, in fit In the interface, at least two-dimensional arrays are still allowed to be imported, and an error will be reported when importing one-dimensional arrays. Generally speaking, we enter X It will be our characteristic matrix. In real cases, the characteristic matrix is unlikely to be one-dimensional, so this problem will not exist.
### []( https://gitee.com/vip204888/java-p7 )How to select standardscaler and MinMaxScaler?
**It just depends.**
* Most machine learning algorithms will choose StandardScaler Feature scaling because MinMaxScaler Very sensitive to outliers
* stay PCA,Clustering, logistic regression, support vector machines, neural networks, StandardScaler Is often the best choice
MinMaxScaler It is widely used when it does not involve distance measurement, gradient, covariance calculation and data needs to be compressed to a specific interval, such as**Quantized pixel intensity in digital image processing**Will be used when MinMaxScaler Compress data into\[0,1\]In the interval.
I suggest you try it first StandardScaler,The effect is not good. Replace it MinMaxScaler.
except StandardScaler and MinMaxScaler outside, sklearn Various other scaling processes are also provided in (centralization requires only one) pandas Just broadcast and subtract a number, so sklearn (no centralization)
* When we want to compress the data without affecting the sparsity of the data (without affecting the number of values of 0 in the matrix), we will use MaxAbsScaler
* When there are many outliers and the noise is very large, we may choose quantile to dimensionless, and use it at this time RobustScaler
* Please refer to the following list for more details:

[](https://gitee.com/vip204888/java-p7) missing value
----------------------------------------------------------------------
**The data used in machine learning and data mining can never be perfect**. Many features are of great significance for analysis and modeling, but not for those who actually collect data. Therefore, in data mining, there are often many missing values of important fields, but fields can not be abandoned. Therefore, a very important item in data preprocessing is**Processing missing values**.
* * *
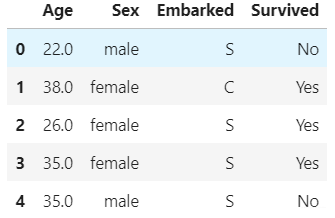
We use the data extracted from the Titanic, which has three characteristics, as follows:
* Age Numerical type
* Sex character
* Embarked character
import pandas as pd
#index_col=0 because the first column in the original data is the index
data = pd.read_csv(r"...\datasets\Narrativedata.csv",index_col=0)
data.head()
 ### []( https://gitee.com/vip204888/java-p7 )Missing value fill in impulse SimpleImputer
class sklearn.impute.SimpleImputer (
missing_values=nan, strategy='mean', fill_value=None, verbose=0, copy=True )
This class is designed to fill in missing values. It includes four important parameters:
* **missing\_values**
tell SimpleImputer,What does the missing value in the data look like? It is null by default np.nan
* **strategy**
We fill in the missing value strategy, the default mean
input"mean"Use mean filling (available only for numeric features)
input"median"Fill with median (available only for numeric features)
input"most\_frequent"Fill with mode (available for both numeric and character features)
input"constant"Indicates that please refer to the parameters"fill\_value"Value in (available for both numeric and character features)
* **fill\_value**
When parameter startegy by"constant"When available, you can enter a string or number to represent the value to be filled, usually 0
* **copy**
Default to True,A copy of the characteristic matrix will be created, otherwise the missing values will be filled into the original characteristic matrix
import pandas as pd
#index_col=0 because the first column in the original data is the index
data = pd.read_csv(r"...\datasets\Narrativedata.csv",index_col=0)
data.head()
data.info() # The operation results show that Age and Embarked have missing values """ <class 'pandas.core.frame.DataFrame'> Int64Index: 891 entries, 0 to 890 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Age 714 non-null float64 1 Sex 891 non-null object 2 Embarked 889 non-null object 3 Survived 891 non-null object dtypes: float64(1), object(3) memory usage: 34.8+ KB """
View data
Age = data.loc[:,“Age”]. values. The characteristic matrix in reshape (- 1,1) #sklearn must be two-dimensional
Age[:20]
"""
array([[22.],
[38.], [26.], [35.], [35.], [nan], [54.],
That's all. It's over
Whether a junior coder, senior programmer or top system architect, they should have a deep understanding of the importance of design patterns.
- First, the design mode can facilitate the communication between professionals, as follows:
Programmer A: Here I use XXX design pattern
Programmer B: then I have a general idea of your program design
- Second, it is easy to maintain
Project Manager: today, the customer has such a demand
Programmer: I see. I use XXX design pattern here, so it changes quickly
- Third, design pattern is the summary of programming experience
Programmer A: B, how did you think of building your code like this
Programmer B: after I learned XXX design pattern, it seems that I naturally feel that writing like this can avoid some problems
- Fourth, learning design patterns is not necessary
Programmer A: B, your code uses XXX design pattern, right?
Programmer B: sorry, I haven't studied design patterns, but my experience tells me that it is written like this
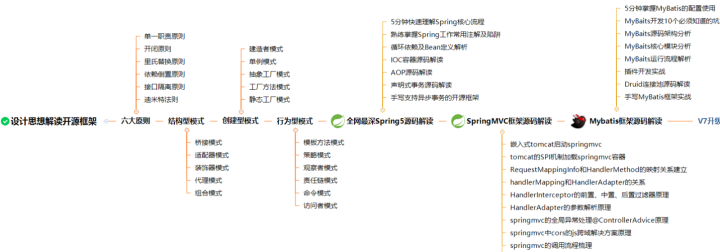
I have collected and sorted out a complete set of open source frameworks from the design idea to the source code interpretation of Spring, Spring5, SpringMVC, MyBatis and so on step by step. The space is limited. This is only a detailed explanation of 23 design modes. The sorted documents are as follows!
Data collection method: click here to download
[35.], [35.], [nan], [54.],
That's all. It's over
Whether a junior coder, senior programmer or top system architect, they should have a deep understanding of the importance of design patterns.
- First, the design mode can facilitate the communication between professionals, as follows:
Programmer A: Here I use XXX design pattern
Programmer B: then I have a general idea of your program design
- Second, it is easy to maintain
Project Manager: today, the customer has such a demand
Programmer: I see. I use XXX design pattern here, so it changes quickly
- Third, design pattern is the summary of programming experience
Programmer A: B, how did you think of building your code like this
Programmer B: after I learned XXX design pattern, it seems that I naturally feel that writing like this can avoid some problems
- Fourth, learning design patterns is not necessary
Programmer A: B, your code uses XXX design pattern, right?
Programmer B: sorry, I haven't studied design patterns, but my experience tells me that it is written like this
[external chain picture transferring... (img-TJJhxqt2-1628595303452)]
I have collected and sorted out a complete set of open source frameworks from the design idea to the source code interpretation of Spring, Spring5, SpringMVC, MyBatis and so on step by step. The space is limited. This is only a detailed explanation of 23 design modes. The sorted documents are as follows!
Data collection method: click here to download
[external chain picture transferring... (img-HdfFSlEc-1628595303454)]
Collecting is time-consuming and laborious. What you can see here is true love!