Reading comprehension task based on BERT pre training model
Machine reading comprehension is an important task in natural language processing. The most common is single text extraction reading comprehension. Machine reading comprehension has a wide range of applications, such as customer service robots, which communicate with users through text or voice, and then obtain relevant information and provide accurate and reliable answers. The search engine accurately returns the answer to the question given by the user. In the medical field, automatically read the patient's data to find the corresponding etiology. In the field of education, reading comprehension model is used to automatically give improvement suggestions for students' composition and so on.
learning resource
- For more in-depth learning materials, such as in-depth learning knowledge, paper interpretation, practical cases, etc., please refer to: awesome-DeepLearning
- For more information about the propeller frame, please refer to: Propeller deep learning platform
⭐ ⭐ ⭐ Welcome to order a small one Star , open source is not easy. I hope you can support it~ ⭐ ⭐ ⭐

1, Scheme design
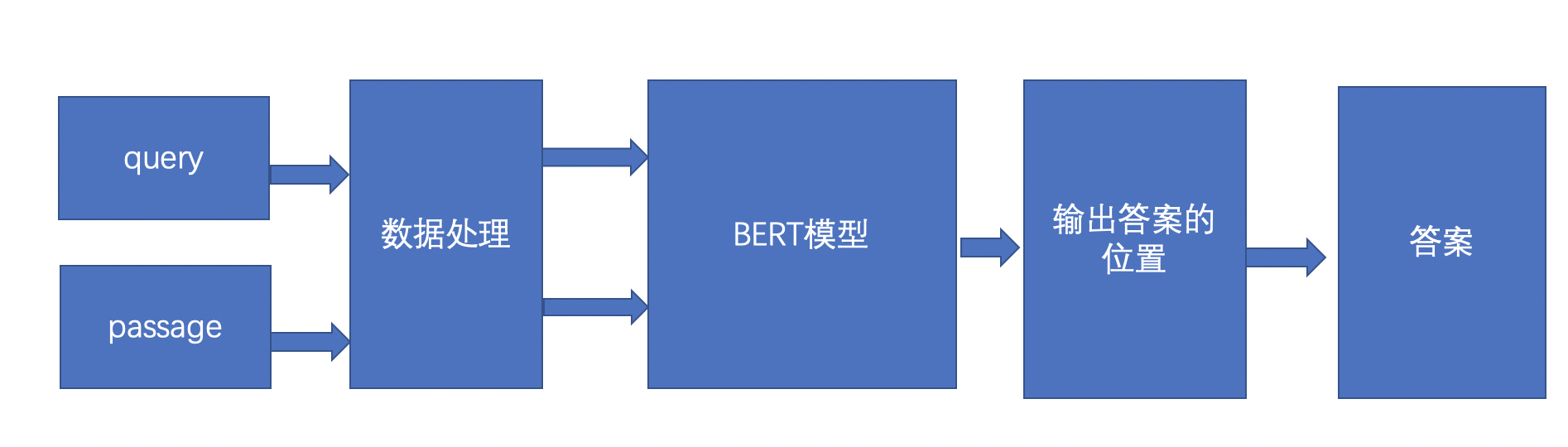
The scheme for reading and understanding is shown in the figure above. First, query represents a question sentence, generally a user's question, passage represents an article, and passage represents that the answer of query should be extracted from passage. After data preprocessing, query and passage get the input in the form of id, and then input the id form of query and passage into the BERT model, The BERT model will output the position of the answer after processing, and the corresponding answer can be obtained after outputting the position.
2, Data processing
The specific task is defined as: for a given question q and a text p, give the answer a to the question according to the text content. Each sample in the dataset is a triple < q, p, a >, for example:
q: how many seasons has Jordan played
Chapter p: Michael Jordan played in the NBA for 15 seasons. He entered the NBA in 84, retired for the first time on October 6, 1993, changed to baseball, returned on March 18, 1995, retired for the second time on January 13, 1999, returned on October 31, 2001, and finally retired in 2003
Reference answer a: ['15', '15 seasons']
The robustness of reading comprehension model is one of the important indicators to measure whether the technology can be implemented on a large scale in practical application. With the progress of current technology, although the models can achieve good performance in some reading comprehension test sets, the robustness of these models is still unsatisfactory in practical application. The dureader robust data set used in this example is the first Chinese data set focusing on the robustness of the reading comprehension model, which aims to investigate the sensitivity, over stability and generalization ability of the model in real application scenarios.
For details of this dataset, refer to the dataset paper , or official Game link.
First, import the library package needed for the experiment.
from paddlenlp.datasets import load_dataset import paddlenlp as ppnlp from utils import prepare_train_features, prepare_validation_features from functools import partial from paddlenlp.metrics.squad import squad_evaluate, compute_prediction import collections import time import json
2.1 dataset loading
PaddleNLP has built-in Chinese and English reading comprehension data sets such as SQuAD and CMRC datasets. load_ The dataset () API can be loaded with one click. This example loads the dureaderoust Chinese reading comprehension dataset. Due to the fact that the dureaderoust dataset adopts the data format of SQuAD, the InputFeature is generated using the sliding window method, that is, an example may correspond to multiple inputfeatures.
The answer extraction task is to predict the starting and ending positions of the answers in the article according to the input questions and articles.
The length of the text may be greater than max due to the problem of adding text to the article_ seq_ Length, the position where the answer appears may appear at the end of the article, so the article cannot be simply truncated.
Then, for the long article, the sliding window is used to divide the article into multiple paragraphs and combine them with the problem respectively. Then the corresponding tokenizer is transformed into a feature acceptable to the model. doc_ The stripe parameter is the distance of each slide. The process of generating InputFeature from sliding window is as follows:
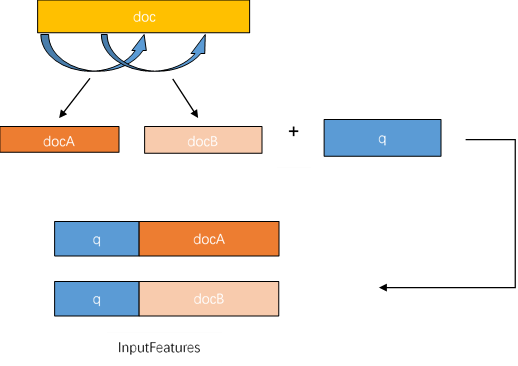
Figure 2: schematic diagram of generating InputFeature by sliding window
train_ds, dev_ds = ppnlp.datasets.load_dataset('dureader_robust', splits=('train', 'dev'))
for idx in range(2):
print(train_ds[idx]['question'])
print(train_ds[idx]['context'])
print(train_ds[idx]['answers'])
print(train_ds[idx]['answer_starts'])
print()
2021-10-29 15:21:06,944 - INFO - unique_endpoints {''}
Fairy sword and chivalry episode 3 what's the heaven
Episode 35 When Xuejian slowly opens his eyes and Jingtian is surprised and happy, Changqing and Zixuan's Fairy boat arrive. They are also very happy to see that everyone is OK. They boarded the ship and tried their best to lose their true Qi and water to her. Xuejian finally woke up, but his face was numb and had no response. They turned to Chang Yin for help, but found that there was no record of life experience in the human world. Changqing asks about Qingwei's life experience. Qingwei says with a pun that there will be an answer when everything goes to heaven. When Changqing drove the fairy boat, they decided to start immediately and go to heaven. When they came to a barren mountain, Changqing pointed out that the demon world was connected with the heaven. Enter from the demon world and ascend to heaven through the well of gods and demons. When they came to the entrance of the demon world, it was like a black bat cave, but they couldn't get in. Later, Huaying found that it could fly in as long as it had wings. So Jingtian and others beat down many crows and made several pairs of winged giants by imitating the wings of Paris polyphylla. Just wearing it, it was sucked into the hole. They fell to the ground and looked up to find the demon world guard. Jingtian made friends with the demons and claimed to be familiar with the devil's tower. The demons ignored and fought.
['Episode 35']
[0]
Which brand of gas water heater is good
When choosing a gas water heater, we must pay attention to these problems: 1. The water outlet stability is good, and there can be no sudden heat and cold phenomenon. 2. Quickly reach the set demand water temperature. 3. The operation should be intelligent and convenient. 4. The safety is good, and the safety alarm device should be installed. There are many brands of gas water heaters in the market, so we need to compare and carefully identify them when purchasing. The magnetized thermostatic water heater featured by Fangtai this year has been comprehensively upgraded in terms of use experience: 9 seconds fast heating, which can quickly enter the bathing mode; The water temperature is long-lasting and stable without sudden heat and cold, and the outlet water temperature is accurately controlled at±0.5℃,It can meet the needs of baby sensitive skin care at home; equipment CO and CH4 Dual gas alarm device is safer (generally in the market) CO Single gas alarm). In addition, this water heater has intelligent WIFI Internet function, just download a mobile phone APP That is, you can remotely operate the water heater with your mobile phone to accurately adjust the water temperature and meet the diversified bathing needs of your family. Of course, the main purpose of Fangtai's magnetization constant temperature series is to increase the magnetization function, which can effectively adsorb small impurities such as rust and iron filings in the water, prevent bacteria from breeding, make the bath water cleaner, and the long-term use of magnetized water is more conducive to health.
['Fotile ']
[110]
ppnlp.transformers.BertTokenizer
Call BertTokenizer for data processing.
The pre training model Bert processes Chinese data in words. PaddleNLP has built-in corresponding tokenizer for various pre training models. You can load the corresponding tokenizer by specifying the model name you want to use.
The function of tokenizer is to transform the original input text into an input data form acceptable to the model.
MODEL_NAME = "bert-base-chinese" tokenizer = ppnlp.transformers.BertTokenizer.from_pretrained(MODEL_NAME)
[2021-10-29 15:21:07,358] [ INFO] - Found /home/aistudio/.paddlenlp/models/bert-base-chinese/bert-base-chinese-vocab.txt
2.2 data processing
Use load_ By default, the dataset read by the dataset () API is a MapDataset object, and MapDataset is a pad io. Enhanced version of dataset. Its built-in map() method is suitable for batch dataset processing. The map() method passes in a function for data processing.
The following is the usage of data conversion in dureader robot:
max_seq_length = 512
doc_stride = 128
train_trans_func = partial(prepare_train_features,
max_seq_length=max_seq_length,
doc_stride=doc_stride,
tokenizer=tokenizer)
train_ds.map(train_trans_func, batched=True)
dev_trans_func = partial(prepare_validation_features,
max_seq_length=max_seq_length,
doc_stride=doc_stride,
tokenizer=tokenizer)
dev_ds.map(dev_trans_func, batched=True)
<paddlenlp.datasets.dataset.MapDataset at 0x7fe07c6d7f10>
for idx in range(2):
print(train_ds[idx]['input_ids'])
print(train_ds[idx]['token_type_ids'])
print(train_ds[idx]['overflow_to_sample'])
print(train_ds[idx]['offset_mapping'])
print(train_ds[idx]['start_positions'])
print(train_ds[idx]['end_positions'])
print()
[101, 803, 1187, 1936, 899, 837, 124, 5018, 1126, 7415, 677, 1921, 4518, 102, 5018, 8198, 7415, 7434, 6224, 5353, 5353, 2476, 2458, 4706, 4714, 8024, 3250, 1921, 1348, 2661, 1348, 1599, 722, 7354, 8024, 7270, 1321, 1469, 5166, 5858, 4638, 803, 5670, 7724, 5635, 8024, 6224, 830, 782, 3187, 2610, 8024, 738, 1282, 1146, 7770, 1069, 511, 830, 782, 4633, 5670, 8024, 4500, 2226, 1394, 1213, 2828, 5632, 6716, 4638, 4696, 3698, 1469, 3717, 1146, 6783, 5314, 1961, 511, 7434, 6224, 5303, 754, 7008, 6814, 3341, 749, 8024, 852, 1316, 671, 5567, 3312, 4197, 8024, 1059, 3187, 1353, 2418, 511, 830, 782, 1403, 2382, 5530, 3724, 1221, 8024, 1316, 1355, 4385, 782, 686, 4518, 4994, 3766, 3300, 7434, 6224, 4638, 6716, 686, 5279, 2497, 511, 7270, 1321, 6418, 7309, 3926, 2544, 4638, 6716, 686, 8024, 3926, 2544, 6427, 2372, 1352, 1068, 6432, 671, 1147, 677, 749, 1921, 4518, 912, 3300, 5031, 3428, 511, 7270, 1321, 7730, 7724, 803, 5670, 8024, 830, 782, 1104, 2137, 4989, 7716, 1220, 6716, 8024, 2518, 1921, 4518, 5445, 1343, 511, 830, 782, 3341, 1168, 671, 5774, 2255, 8024, 7270, 1321, 2900, 1139, 8024, 7795, 4518, 1469, 1921, 4518, 4685, 6825, 511, 4507, 7795, 4518, 6822, 1057, 6858, 6814, 4868, 7795, 722, 759, 8024, 912, 1377, 4633, 1921, 511, 830, 782, 5635, 7795, 4518, 1057, 1366, 8024, 820, 5735, 671, 7946, 5682, 4638, 6073, 6075, 3822, 8024, 852, 1993, 5303, 3187, 3791, 6822, 1057, 511, 1400, 3341, 5709, 3516, 1355, 4385, 1372, 6206, 3300, 5420, 5598, 912, 5543, 7607, 1057, 511, 754, 3221, 3250, 1921, 5023, 782, 2802, 678, 6387, 1914, 723, 7887, 8024, 3563, 820, 7028, 3517, 4638, 5420, 5598, 8024, 1169, 868, 3144, 2190, 5420, 5598, 4307, 2342, 4289, 511, 1157, 877, 2785, 1762, 6716, 8024, 912, 6158, 1429, 1057, 3822, 1366, 511, 830, 782, 3035, 5862, 1762, 1765, 8024, 2848, 1928, 1355, 4385, 7795, 4518, 2127, 1310, 511, 3250, 1921, 1469, 830, 7795, 1947, 769, 2658, 8024, 5632, 4917, 1469, 7795, 2203, 7028, 3517, 4685, 4225, 8024, 830, 7795, 679, 4415, 8024, 2802, 749, 6629, 3341, 511, 102] [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] 0 [(0, 0), (0, 1), (1, 2), (2, 3), (3, 4), (4, 5), (5, 6), (6, 7), (7, 8), (8, 9), (9, 10), (10, 11), (11, 12), (0, 0), (0, 1), (1, 3), (3, 4), (4, 5), (5, 6), (6, 7), (7, 8), (8, 9), (9, 10), (10, 11), (11, 12), (12, 13), (13, 14), (14, 15), (15, 16), (16, 17), (17, 18), (18, 19), (19, 20), (20, 21), (21, 22), (22, 23), (23, 24), (24, 25), (25, 26), (26, 27), (27, 28), (28, 29), (29, 30), (30, 31), (31, 32), (32, 33), (33, 34), (34, 35), (35, 36), (36, 37), (37, 38), (38, 39), (39, 40), (40, 41), (41, 42), (42, 43), (43, 44), (44, 45), (45, 46), (46, 47), (47, 48), (48, 49), (49, 50), (50, 51), (51, 52), (52, 53), (53, 54), (54, 55), (55, 56), (56, 57), (57, 58), (58, 59), (59, 60), (60, 61), (61, 62), (62, 63), (63, 64), (64, 65), (65, 66), (66, 67), (67, 68), (68, 69), (69, 70), (70, 71), (71, 72), (72, 73), (73, 74), (74, 75), (75, 76), (76, 77), (77, 78), (78, 79), (79, 80), (80, 81), (81, 82), (82, 83), (83, 84), (84, 85), (85, 86), (86, 87), (87, 88), (88, 89), (89, 90), (90, 91), (91, 92), (92, 93), (93, 94), (94, 95), (95, 96), (96, 97), (97, 98), (98, 99), (99, 100), (100, 101), (101, 102), (102, 103), (103, 104), (104, 105), (105, 106), (106, 107), (107, 108), (108, 109), (109, 110), (110, 111), (111, 112), (112, 113), (113, 114), (114, 115), (115, 116), (116, 117), (117, 118), (118, 119), (119, 120), (120, 121), (121, 122), (122, 123), (123, 124), (124, 125), (125, 126), (126, 127), (127, 128), (128, 129), (129, 130), (130, 131), (131, 132), (132, 133), (133, 134), (134, 135), (135, 136), (136, 137), (137, 138), (138, 139), (139, 140), (140, 141), (141, 142), (142, 143), (143, 144), (144, 145), (145, 146), (146, 147), (147, 148), (148, 149), (149, 150), (150, 151), (151, 152), (152, 153), (153, 154), (154, 155), (155, 156), (156, 157), (157, 158), (158, 159), (159, 160), (160, 161), (161, 162), (162, 163), (163, 164), (164, 165), (165, 166), (166, 167), (167, 168), (168, 169), (169, 170), (170, 171), (171, 172), (172, 173), (173, 174), (174, 175), (175, 176), (176, 177), (177, 178), (178, 179), (179, 180), (180, 181), (181, 182), (182, 183), (183, 184), (184, 185), (185, 186), (186, 187), (187, 188), (188, 189), (189, 190), (190, 191), (191, 192), (192, 193), (193, 194), (194, 195), (195, 196), (196, 197), (197, 198), (198, 199), (199, 200), (200, 201), (201, 202), (202, 203), (203, 204), (204, 205), (205, 206), (206, 207), (207, 208), (208, 209), (209, 210), (210, 211), (211, 212), (212, 213), (213, 214), (214, 215), (215, 216), (216, 217), (217, 218), (218, 219), (219, 220), (220, 221), (221, 222), (222, 223), (223, 224), (224, 225), (225, 226), (226, 227), (227, 228), (228, 229), (229, 230), (230, 231), (231, 232), (232, 233), (233, 234), (234, 235), (235, 236), (236, 237), (237, 238), (238, 239), (239, 240), (240, 241), (241, 242), (242, 243), (243, 244), (244, 245), (245, 246), (246, 247), (247, 248), (248, 249), (249, 250), (250, 251), (251, 252), (252, 253), (253, 254), (254, 255), (255, 256), (256, 257), (257, 258), (258, 259), (259, 260), (260, 261), (261, 262), (262, 263), (263, 264), (264, 265), (265, 266), (266, 267), (267, 268), (268, 269), (269, 270), (270, 271), (271, 272), (272, 273), (273, 274), (274, 275), (275, 276), (276, 277), (277, 278), (278, 279), (279, 280), (280, 281), (281, 282), (282, 283), (283, 284), (284, 285), (285, 286), (286, 287), (287, 288), (288, 289), (289, 290), (290, 291), (291, 292), (292, 293), (293, 294), (294, 295), (295, 296), (296, 297), (297, 298), (298, 299), (299, 300), (300, 301), (301, 302), (302, 303), (303, 304), (304, 305), (305, 306), (306, 307), (307, 308), (308, 309), (309, 310), (310, 311), (311, 312), (312, 313), (313, 314), (314, 315), (315, 316), (316, 317), (317, 318), (318, 319), (319, 320), (320, 321), (321, 322), (322, 323), (323, 324), (324, 325), (325, 326), (326, 327), (327, 328), (328, 329), (329, 330), (330, 331), (331, 332), (0, 0)] 14 16 [101, 4234, 3698, 4178, 3717, 1690, 1525, 702, 4277, 2094, 1962, 102, 6848, 2885, 4234, 3698, 4178, 3717, 1690, 3198, 8024, 671, 2137, 6206, 1068, 3800, 6821, 1126, 702, 7309, 7579, 8038, 122, 510, 1139, 3717, 4937, 2137, 2595, 6206, 1962, 8024, 679, 5543, 1139, 4385, 2575, 4178, 2575, 1107, 4638, 4385, 6496, 123, 510, 2571, 6862, 1168, 6809, 6392, 2137, 4638, 7444, 3724, 3717, 3946, 124, 510, 3082, 868, 6206, 3255, 5543, 510, 3175, 912, 125, 510, 2128, 1059, 2595, 6206, 1962, 8024, 6206, 6163, 3300, 2128, 1059, 2845, 6356, 6163, 5390, 2356, 1767, 677, 4234, 3698, 4178, 3717, 1690, 1501, 4277, 830, 1914, 8024, 6579, 743, 3198, 6820, 7444, 1914, 1217, 2190, 3683, 1469, 798, 5301, 7063, 1166, 511, 3175, 1922, 791, 2399, 712, 2802, 4638, 4828, 1265, 2608, 3946, 4178, 3717, 1690, 1762, 886, 4500, 860, 7741, 3175, 7481, 976, 749, 1059, 7481, 1285, 5277, 8038, 130, 4907, 6862, 4178, 8024, 1377, 2571, 6862, 6822, 1057, 3819, 3861, 3563, 2466, 8039, 3717, 3946, 2898, 719, 4937, 2137, 8024, 679, 833, 1139, 4385, 2575, 4178, 2575, 1107, 4638, 4385, 6496, 8024, 2400, 6858, 6814, 3717, 7030, 848, 3302, 2825, 3318, 2199, 1139, 3717, 3946, 2428, 5125, 4802, 2971, 1169, 1762, 11349, 119, 9687, 8024, 1377, 4007, 6639, 2157, 7027, 2140, 6564, 3130, 2697, 5491, 5502, 3819, 2844, 7444, 3724, 8039, 6981, 1906, 100, 1469, 100, 1352, 3698, 860, 2845, 6356, 6163, 5390, 3291, 2128, 1059, 8020, 2356, 1767, 677, 671, 5663, 1914, 711, 100, 1296, 3698, 860, 2845, 6356, 8021, 511, 1369, 1912, 8024, 6821, 3621, 4178, 3717, 1690, 6820, 3300, 3255, 5543, 100, 757, 5468, 1216, 5543, 8024, 1372, 7444, 678, 6770, 702, 2797, 3322, 100, 1315, 1377, 4500, 2797, 3322, 6823, 4923, 3082, 868, 4178, 3717, 1690, 8024, 2141, 4385, 5125, 1114, 6444, 5688, 3717, 3946, 8024, 4007, 6639, 2157, 782, 1914, 3416, 1265, 4638, 3819, 3861, 7444, 3724, 511, 2496, 4197, 3175, 1922, 4638, 4828, 1265, 2608, 3946, 5143, 1154, 712, 6206, 4638, 3221, 1872, 1217, 4828, 1265, 1216, 5543, 8024, 1377, 809, 3300, 3126, 1429, 7353, 3717, 704, 4638, 7188, 7224, 510, 7188, 2244, 5023, 2544, 2207, 3325, 6574, 8024, 7344, 3632, 5301, 5826, 3996, 4495, 8024, 886, 3759, 3861, 3717, 6574, 3291, 3815, 1112, 8024, 7270, 3309, 886, 4500, 4828, 1265, 3717, 3759, 3861, 3291, 1164, 754, 6716, 860, 978, 2434, 511, 102] [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] 1 [(0, 0), (0, 1), (1, 2), (2, 3), (3, 4), (4, 5), (5, 6), (6, 7), (7, 8), (8, 9), (9, 10), (0, 0), (0, 1), (1, 2), (2, 3), (3, 4), (4, 5), (5, 6), (6, 7), (7, 8), (8, 9), (9, 10), (10, 11), (11, 12), (12, 13), (13, 14), (14, 15), (15, 16), (16, 17), (17, 18), (18, 19), (19, 20), (20, 21), (21, 22), (22, 23), (23, 24), (24, 25), (25, 26), (26, 27), (27, 28), (28, 29), (29, 30), (30, 31), (31, 32), (32, 33), (33, 34), (34, 35), (35, 36), (36, 37), (37, 38), (38, 39), (39, 40), (40, 41), (41, 42), (42, 43), (43, 44), (44, 45), (45, 46), (46, 47), (47, 48), (48, 49), (49, 50), (50, 51), (51, 52), (52, 53), (53, 54), (54, 55), (55, 56), (56, 57), (57, 58), (58, 59), (59, 60), (60, 61), (61, 62), (62, 63), (63, 64), (64, 65), (65, 66), (66, 67), (67, 68), (68, 69), (69, 70), (70, 71), (71, 72), (72, 73), (73, 74), (74, 75), (75, 76), (76, 77), (77, 78), (78, 79), (79, 80), (80, 81), (82, 83), (83, 84), (84, 85), (85, 86), (86, 87), (87, 88), (88, 89), (89, 90), (90, 91), (91, 92), (92, 93), (93, 94), (94, 95), (95, 96), (96, 97), (97, 98), (98, 99), (99, 100), (100, 101), (101, 102), (102, 103), (103, 104), (104, 105), (105, 106), (106, 107), (107, 108), (108, 109), (109, 110), (110, 111), (111, 112), (112, 113), (113, 114), (114, 115), (115, 116), (116, 117), (117, 118), (118, 119), (119, 120), (120, 121), (121, 122), (122, 123), (123, 124), (124, 125), (125, 126), (126, 127), (127, 128), (128, 129), (129, 130), (130, 131), (131, 132), (132, 133), (133, 134), (134, 135), (135, 136), (136, 137), (137, 138), (138, 139), (139, 140), (140, 141), (141, 142), (142, 143), (143, 144), (144, 145), (145, 146), (146, 147), (147, 148), (148, 149), (149, 150), (150, 151), (151, 152), (152, 153), (153, 154), (154, 155), (155, 156), (156, 157), (157, 158), (158, 159), (159, 160), (160, 161), (161, 162), (162, 163), (163, 164), (164, 165), (165, 166), (166, 167), (167, 168), (168, 169), (169, 170), (170, 171), (171, 172), (172, 173), (173, 174), (174, 175), (175, 176), (176, 177), (177, 178), (178, 179), (179, 180), (180, 181), (181, 182), (182, 183), (183, 184), (184, 185), (185, 186), (186, 187), (187, 188), (188, 189), (189, 190), (190, 191), (191, 193), (193, 194), (194, 196), (196, 197), (197, 198), (198, 199), (199, 200), (200, 201), (201, 202), (202, 203), (203, 204), (204, 205), (205, 206), (206, 207), (207, 208), (208, 209), (209, 210), (210, 211), (211, 212), (212, 213), (213, 214), (214, 215), (215, 217), (217, 218), (218, 221), (221, 222), (222, 223), (223, 224), (224, 225), (225, 226), (226, 227), (227, 228), (228, 229), (229, 230), (230, 231), (231, 232), (232, 233), (233, 234), (234, 235), (235, 236), (236, 237), (237, 238), (238, 239), (239, 241), (241, 242), (242, 243), (243, 244), (244, 245), (245, 246), (246, 247), (247, 248), (248, 249), (249, 250), (250, 251), (251, 252), (252, 253), (253, 254), (254, 255), (255, 256), (256, 257), (257, 258), (258, 259), (259, 260), (260, 264), (264, 265), (265, 266), (266, 267), (267, 268), (268, 269), (269, 270), (270, 271), (271, 272), (272, 273), (273, 274), (274, 275), (275, 276), (276, 279), (279, 280), (280, 281), (281, 282), (282, 283), (283, 284), (284, 285), (285, 286), (286, 287), (287, 288), (288, 289), (289, 290), (290, 291), (291, 292), (292, 293), (293, 294), (294, 295), (295, 296), (296, 297), (297, 298), (298, 299), (299, 300), (300, 301), (301, 302), (302, 303), (303, 304), (304, 305), (305, 306), (306, 307), (307, 308), (308, 309), (309, 310), (310, 311), (311, 312), (312, 313), (313, 314), (314, 315), (315, 316), (316, 317), (317, 318), (318, 319), (319, 320), (320, 321), (321, 322), (322, 323), (323, 324), (324, 325), (325, 326), (326, 327), (327, 328), (328, 329), (329, 330), (330, 331), (331, 332), (332, 333), (333, 334), (334, 335), (335, 336), (336, 337), (337, 338), (338, 339), (339, 340), (340, 341), (341, 342), (342, 343), (343, 344), (344, 345), (345, 346), (346, 347), (347, 348), (348, 349), (349, 350), (350, 351), (351, 352), (352, 353), (353, 354), (354, 355), (355, 356), (356, 357), (357, 358), (358, 359), (359, 360), (360, 361), (361, 362), (362, 363), (363, 364), (364, 365), (365, 366), (366, 367), (367, 368), (368, 369), (369, 370), (370, 371), (371, 372), (372, 373), (373, 374), (374, 375), (375, 376), (376, 377), (377, 378), (378, 379), (379, 380), (380, 381), (381, 382), (382, 383), (383, 384), (384, 385), (385, 386), (386, 387), (387, 388), (388, 389), (0, 0)] 121 122
As can be seen from the above results, the example in the dataset has been converted into feature s that the model can receive, including input_ids,token_type_ids, the starting position of the answer, etc.
Of which:
- input_ids: token ID representing the input text.
- token_type_ids: indicates whether the corresponding token belongs to the entered question or answer. (Transformer pre training model supports single sentence and sentence pair input).
- overflow_ to_ Sample: the number of the example corresponding to the feature.
- offset_mapping: the index corresponding to the start character and end character of each token in the original text (used to generate the answer text).
- start_positions: the starting position of the answer in this feature.
- end_positions: the end position of the answer in this feature.
2.3 construct Dataloader
Use the pad io. The dataloader interface loads data asynchronously through multiple threads. Also use paddlenlp The methods provided in data form feature s into batch
import paddle
from paddlenlp.data import Stack, Dict, Pad
batch_size = 8
train_batch_sampler = paddle.io.DistributedBatchSampler(
train_ds, batch_size=batch_size, shuffle=True)
train_batchify_fn = lambda samples, fn=Dict({
"input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id),
"token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
"start_positions": Stack(dtype="int64"),
"end_positions": Stack(dtype="int64")
}): fn(samples)
train_data_loader = paddle.io.DataLoader(
dataset=train_ds,
batch_sampler=train_batch_sampler,
collate_fn=train_batchify_fn,
return_list=True)
dev_batch_sampler = paddle.io.BatchSampler(
dev_ds, batch_size=batch_size, shuffle=False)
dev_batchify_fn = lambda samples, fn=Dict({
"input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id),
"token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id)
}): fn(samples)
dev_data_loader = paddle.io.DataLoader(
dataset=dev_ds,
batch_sampler=dev_batch_sampler,
collate_fn=dev_batchify_fn,
return_list=True)
Three, model building
Reading comprehension is essentially an answer extraction task. Paddelnlp has built-in fine tune network for downstream task answer extraction for various pre training models.
The following project takes BERT as an example to introduce how to complete the answer extraction task with the pre training model fine tune.
The essence of answer extraction task is to predict the starting and ending positions of answers in the article according to the input questions and articles. The principle of answer extraction based on BERT is shown in the following figure:
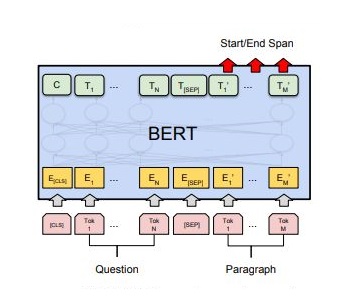
Figure 1: schematic diagram of answer extraction principle based on BERT
paddlenlp.transformers.BertForQuestionAnswering()
One line of code can load the fine tune network of the pre training model BERT for the answer extraction task.
paddlenlp.transformers.BertForQuestionAnswering.from_pretrained()
Specify the model name and the number of categories of text classification you want to use, and complete the network construction in one line of code.
# Set the name of the model you want to use model = ppnlp.transformers.BertForQuestionAnswering.from_pretrained(MODEL_NAME)
[2021-10-29 15:22:02,890] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/bert-base-chinese/bert-base-chinese.pdparams
4, Model configuration
4.1 setting fine tune optimization strategy
The learning rate applicable to Transformer models such as ERNIE/BERT is the dynamic learning rate of warmup.
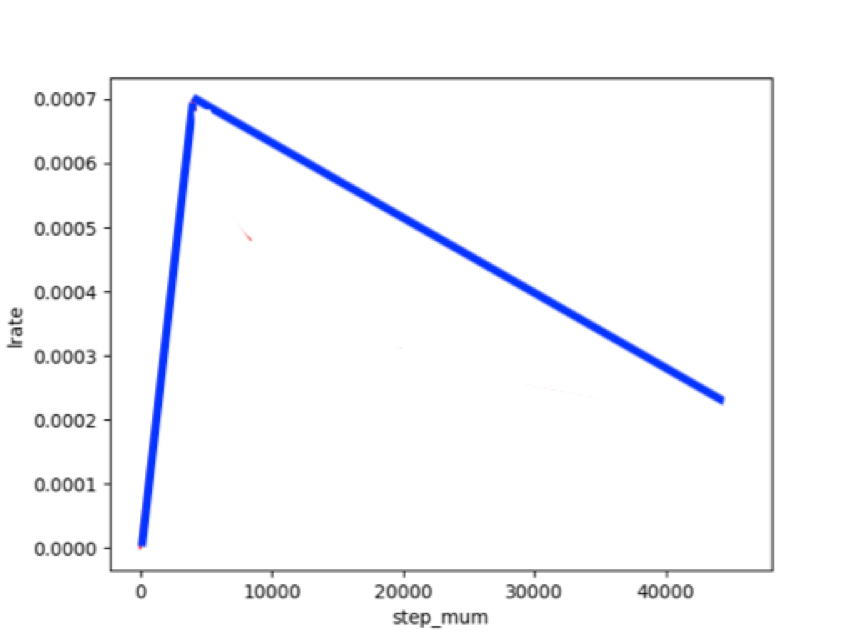
Figure 3: schematic diagram of dynamic learning rate
# Maximum learning rate during training
learning_rate = 3e-5
# Training rounds
epochs = 1
# Learning rate preheating ratio
warmup_proportion = 0.1
# The weight attenuation coefficient is similar to the regular term strategy of the model to avoid over fitting of the model
weight_decay = 0.01
num_training_steps = len(train_data_loader) * epochs
lr_scheduler = ppnlp.transformers.LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
4.2 design loss function
Because the BertForQuestionAnswering model pair will change the sequence of BertModel_ Split output into start_logits and end_logits is output, so the loss of reading comprehension task is also output by start_loss and end_ We need to define our own loss function. The prediction of answer location and end location can be divided into two classification tasks respectively. Therefore, the designed loss function is as follows:
class CrossEntropyLossForSQuAD(paddle.nn.Layer):
def __init__(self):
super(CrossEntropyLossForSQuAD, self).__init__()
def forward(self, y, label):
start_logits, end_logits = y # both shape are [batch_size, seq_len]
start_position, end_position = label
start_position = paddle.unsqueeze(start_position, axis=-1)
end_position = paddle.unsqueeze(end_position, axis=-1)
start_loss = paddle.nn.functional.softmax_with_cross_entropy(
logits=start_logits, label=start_position, soft_label=False)
start_loss = paddle.mean(start_loss)
end_loss = paddle.nn.functional.softmax_with_cross_entropy(
logits=end_logits, label=end_position, soft_label=False)
end_loss = paddle.mean(end_loss)
loss = (start_loss + end_loss) / 2
return loss
5, Model training
The process of model training usually includes the following steps:
- Take out a batch data from the dataloader
- Feed batch data to the model for forward calculation
- Pass the forward calculation result to the loss function to calculate loss.
- loss returns in reverse to update the gradient. Repeat the above steps.
Each time an epoch is trained, the program calls paddlenlp through evaluate () metric. Square in square_ evaluate(), compute_ Predictions() evaluates the effect of the current model training, where:
-
compute_predictions() is used to generate the answers that can be submitted;
-
squad_evaluate() is used to return the evaluation indicator.
Both of them are applicable to all answer extraction tasks that conform to square data format. Such tasks use Rouge-L and exact to assess the similarity between the predicted answer and the real answer.
@paddle.no_grad()
def evaluate(model, data_loader):
model.eval()
all_start_logits = []
all_end_logits = []
tic_eval = time.time()
for batch in data_loader:
input_ids, token_type_ids = batch
start_logits_tensor, end_logits_tensor = model(input_ids,
token_type_ids)
for idx in range(start_logits_tensor.shape[0]):
if len(all_start_logits) % 1000 == 0 and len(all_start_logits):
print("Processing example: %d" % len(all_start_logits))
print('time per 1000:', time.time() - tic_eval)
tic_eval = time.time()
all_start_logits.append(start_logits_tensor.numpy()[idx])
all_end_logits.append(end_logits_tensor.numpy()[idx])
all_predictions, _, _ = compute_prediction(
data_loader.dataset.data, data_loader.dataset.new_data,
(all_start_logits, all_end_logits), False, 20, 30)
squad_evaluate(
examples=data_loader.dataset.data,
preds=all_predictions,
is_whitespace_splited=False)
model.train()
# from utils import evaluate
criterion = CrossEntropyLossForSQuAD()
global_step = 0
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
global_step += 1
input_ids, segment_ids, start_positions, end_positions = batch
logits = model(input_ids=input_ids, token_type_ids=segment_ids)
loss = criterion(logits, (start_positions, end_positions))
if global_step % 100 == 0 :
print("global step %d, epoch: %d, batch: %d, loss: %.5f" % (global_step, epoch, step, loss))
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
evaluate(model=model, data_loader=dev_data_loader)
model.save_pretrained('./checkpoint')
tokenizer.save_pretrained('./checkpoint')
More pre training models
PaddleNLP supports not only BERT pre training model, but also ERNIE, RoBERTa, Electra and other pre training models.
The following table summarizes the various pre training models currently supported by PaddleNLP. Users can use the model provided by PaddleNLP to complete Q & A, sequence classification, token classification and other tasks. At the same time, we provide 22 kinds of pre training parameter weights for users, including the pre training weights of 11 Chinese language models.
| Model | Tokenizer | Supported Task | Model Name |
|---|---|---|---|
| BERT | BertTokenizer | BertModel BertForQuestionAnswering BertForSequenceClassification BertForTokenClassification | bert-base-uncased bert-large-uncased bert-base-multilingual-uncased bert-base-cased bert-base-chinese bert-base-multilingual-cased bert-large-cased bert-wwm-chinese bert-wwm-ext-chinese |
| ERNIE | ErnieTokenizer ErnieTinyTokenizer | ErnieModel ErnieForQuestionAnswering ErnieForSequenceClassification ErnieForTokenClassification | ernie-1.0 ernie-tiny ernie-2.0-en ernie-2.0-large-en |
| RoBERTa | RobertaTokenizer | RobertaModel RobertaForQuestionAnswering RobertaForSequenceClassification RobertaForTokenClassification | roberta-wwm-ext roberta-wwm-ext-large rbt3 rbtl3 |
| ELECTRA | ElectraTokenizer | ElectraModel ElectraForSequenceClassification ElectraForTokenClassification | electra-small electra-base electra-large chinese-electra-small chinese-electra-base |
Note: the Chinese pre training models include Bert base Chinese, Bert WwM Chinese, Bert WwM ext Chinese, ernie-1.0, Ernie tiny, Roberta WwM ext, Roberta WwM ext large, rbt3, rbtl3, China electric base, China Electric small, etc.
More pre training model references: https://github.com/PaddlePaddle/models/blob/develop/PaddleNLP/docs/transformers.md
For more usage methods of pre training model fine tune downstream tasks, please refer to examples.
6, Model prediction
@paddle.no_grad()
def do_predict(model, data_loader):
model.eval()
all_start_logits = []
all_end_logits = []
tic_eval = time.time()
for batch in data_loader:
input_ids, token_type_ids = batch
start_logits_tensor, end_logits_tensor = model(input_ids,
token_type_ids)
for idx in range(start_logits_tensor.shape[0]):
if len(all_start_logits) % 1000 == 0 and len(all_start_logits):
print("Processing example: %d" % len(all_start_logits))
print('time per 1000:', time.time() - tic_eval)
tic_eval = time.time()
all_start_logits.append(start_logits_tensor.numpy()[idx])
all_end_logits.append(end_logits_tensor.numpy()[idx])
all_predictions, _, _ = compute_prediction(
data_loader.dataset.data, data_loader.dataset.new_data,
(all_start_logits, all_end_logits), False, 20, 30)
count = 0
for example in data_loader.dataset.data:
count += 1
print()
print('Question:',example['question'])
print('Original text:',''.join(example['context']))
print('answer:',all_predictions[example['id']])
if count >= 2:
break
model.train()
do_predict(model, dev_data_loader)
VII More in-depth learning resources
7.1 one stop deep learning platform awesome-DeepLearning
- Introduction to deep learning
- Deep learning questions

- Characteristic course

- Industrial practice
If you have any questions during the use of paddledu, you are welcome to awesome-DeepLearning For more in-depth learning materials, please refer to Propeller deep learning platform.
Remember to order one Star ⭐ Collection oh~~

7.2 propeller technical communication group (QQ)
At present, 2000 + students in QQ group have studied together. Welcome to join us by scanning the code