Customize the data set and model, and call the image classification project of pb model compiled by tensorflow with QT and c + +
Step 1: This article
Step 2: Read the custom TFRecord data set, train the convolution network and save the pb model
Step 3: opencv reads the customized pb model, customizes softmax and argmax functions, and outputs image classification results
flow chart

Reference is as follows:
Using c + + to call tensorflow trained model under Windows
flower_ Photo dataset
flower dataset Download
flower_ The photos folder contains five folders. The name of each sub folder is the name of a flower, representing different categories (daisy Daisy: 633, dandelion: 898, Rose: 641, sunflowers: 699, tulips: 799). On average, each flower has 734 pictures. Each picture is in RGB color mode and has different sizes. Here, the flower dataset can be used to simulate the actual project.

Save as tfrecord file
Pay attention to flower_ The txt file in the photos folder should be deleted, otherwise an error will be reported.
1.get_ The files function actually gets the file name list and label list of the picture. If the arrangement is not disordered, it will be found that the data set and verification set are divided in order. Here, in order to ensure the distribution of data sets and validation sets, we first divide each folder proportionally. For example, there are five folders with 100 pictures in each folder. We first take 80 pictures in each folder. Five 80 pictures together are the training set, and five 20 pictures together are the verification set.
2. In image2tfrecord, you can see that after reading the image by file name, the size of the image resize s to 100.
3. The names of the last saved training set and verification set are flower respectively_ Tra100.tfrecords and flower_val100.tfrecords.
We may train with different models later, and the input tensors are also different. For example, some models require the input image to be 224x224x3. Here, in the image2tfrecord function, change the size of the image resize to 224x224 and the generated file name to flower_tra224.tfrecords and flower_val224.tfrecords. The generated files can be reused to meet different needs.
"""
The picture here is the picture of the flower set. First convert the picture into tfrecorder Format.
Here are pictures of 5 kinds of flowers. Each flower is placed in the same folder
"""
import os
import numpy as np
from PIL import Image
import tensorflow as tf
def get_files(file_dir, ratio = 0.8):
"""Get the image list and label list of training set and verification set. The default division ratio is 0.8"""
daisy = []
label_daisy = []
dandelion = []
label_dandelion = []
roses = []
label_roses = []
sunflowers = []
label_sunflowers = []
tulips = []
label_tulips = []
for file in os.listdir(file_dir):
pp=os.path.join(file_dir,file)
for pic in os.listdir(pp):
pic_path=os.path.join(pp,pic)
if file=="daisy":
daisy.append(pic_path)#Read location name
label_daisy.append(0)#labels label is 0
elif file=="dandelion":
dandelion.append(pic_path)#Read location name
label_dandelion.append(1)#labels label is 1
elif file=="roses":
roses.append(pic_path)#Read location name
label_roses.append(2)#labels label is 2
elif file=="sunflowers":
sunflowers.append(pic_path)#Read location name
label_sunflowers.append(3)#labels label is 3
elif file=="tulips":
tulips.append(pic_path)#Read location name
label_tulips.append(4)#labels label is 4
print("There are %d daisy \nThere are %d dandelion "
"\nThere are %d roses \nThere are %d sunflowers "
"\nThere are %d tulips"
%(len(daisy),len(dandelion),len(roses),len(sunflowers),len(tulips)))
# When a multidimensional array is arranged randomly, the first dimension, that is, the column dimension, is randomly scrambled by default
np.random.shuffle(daisy)
np.random.shuffle(dandelion)
np.random.shuffle(roses)
np.random.shuffle(sunflowers)
np.random.shuffle(label_tulips)
# Divide the training set and verification set proportionally
s1 = np.int(len(daisy) * ratio) # 633 * 0.8 = 506.4
s2 = np.int(len(dandelion) * ratio) # 898 * 0.8 = 718.4
s3 = np.int(len(roses) * ratio) # 641 * 0.8 = 512.8
s4 = np.int(len(sunflowers) * ratio) # 699 * 0.8 = 559.2
s5 = np.int(len(label_tulips) * ratio) # 799 * 0.8 = 639.2
# np.hstack(): tile horizontally; np.vstack(): stack vertically
# 506 + 718 + 515 + 559 + 639 = 2934
# 633 + 898 + 641 + 699 + 799 - 736
tra_image_list = np.hstack(
(daisy[:s1],dandelion[:s2],roses[:s3],sunflowers[:s4],tulips[:s5]))#Row 1, column 2934
tra_label_list = np.hstack(
(label_daisy[:s1],label_dandelion[:s2],label_roses[:s3],
label_sunflowers[:s4],label_tulips[:s5]))#Row 1, column 2934
val_image_list = np.hstack(
(daisy[s1:],dandelion[s2:],roses[s3:],sunflowers[s4:],tulips[s5:]))#1 row 736 columns
val_label_list = np.hstack(
(label_daisy[s1:],label_dandelion[s2:],label_roses[s3:],
label_sunflowers[s4:],label_tulips[s5:]))#1 row 736 columns
print("There are %d tra_image_list \nThere are %d tra_label_list \n"
"There are %d val_image_list \nThere are %d val_label_list \n"
%(len(tra_image_list),len(tra_label_list),len(val_image_list),
len(val_label_list)))
#2 rows and 2934 columns, the first row is the image list, and the second row is the label list
tra_temp = np.array([tra_image_list, tra_label_list])
#There are 2 rows and 736 columns. The first row is the image list, and the second row is the label list
val_temp = np.array([val_image_list, val_label_list])
# For two-dimensional ndarray, transfer defaults to matrix transpose without specifying parameters. Transpose does not work for one - dimensional shape s
tra_temp = tra_temp.transpose()# After transposing, it becomes 2934 rows and 2 columns. The first column is the image list and the second column is the label list
val_temp = val_temp.transpose()# After transposing, it becomes 736 rows and 2 columns. The first column is the image list and the second column is the label list
# When a multidimensional array is arranged randomly, the first dimension, that is, the column dimension, is randomly scrambled by default
np.random.shuffle(tra_temp)#Random arrangement, pay attention not to use during debugging
np.random.shuffle(val_temp)
tra_image_list = list(tra_temp[:,0])
tra_label_list = list(tra_temp[:,1])
tra_label_list = [int(i) for i in tra_label_list]
val_image_list = list(val_temp[:,0])
val_label_list = list(val_temp[:,1])
val_label_list = [int(i) for i in val_label_list]
# Note, image_ The path of the image file actually stored in the list
return tra_image_list, tra_label_list, val_image_list, val_label_list
def image2tfrecord(image_list,label_list,filename):
# Generate string properties
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
# Generate integer attributes
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
len2 = len(image_list)
print("len=",len2)
# Create a writer to write the TFRecord file. filename is the address of the output TFRecord file
writer = tf.python_io.TFRecordWriter(filename)
for i in range(len2):
# Read picture and decode
image = Image.open(image_list[i])
image = image.resize((100,100))
# Convert to original bytes (tostring() has been removed and replaced with tobytes())
image_bytes = image.tobytes()
# Create dictionary
features = {}
# Use bytes to store image s
features['image_raw'] = _bytes_feature(image_bytes)
# Use int64 to express label
features['label'] = _int64_feature(label_list[i])
# Synthesize all features into features
tf_features = tf.train.Features(feature=features)
# Convert the sample to Example Protocol Buffer and write all the information into this data structure
tf_example = tf.train.Example(features=tf_features)
# Serialized samples
tf_serialized = tf_example.SerializeToString()
# Write serialized samples to trfrecord
writer.write(tf_serialized)
writer.close()
if __name__=="__main__":
path="flower_photos"
tra_img_list,tra_label_list,val_image_list,val_label_list=get_files(path)
image2tfrecord(tra_img_list, tra_label_list, "flower_tra100.tfrecords")
image2tfrecord(val_image_list, val_label_list, "flower_val100.tfrecords")
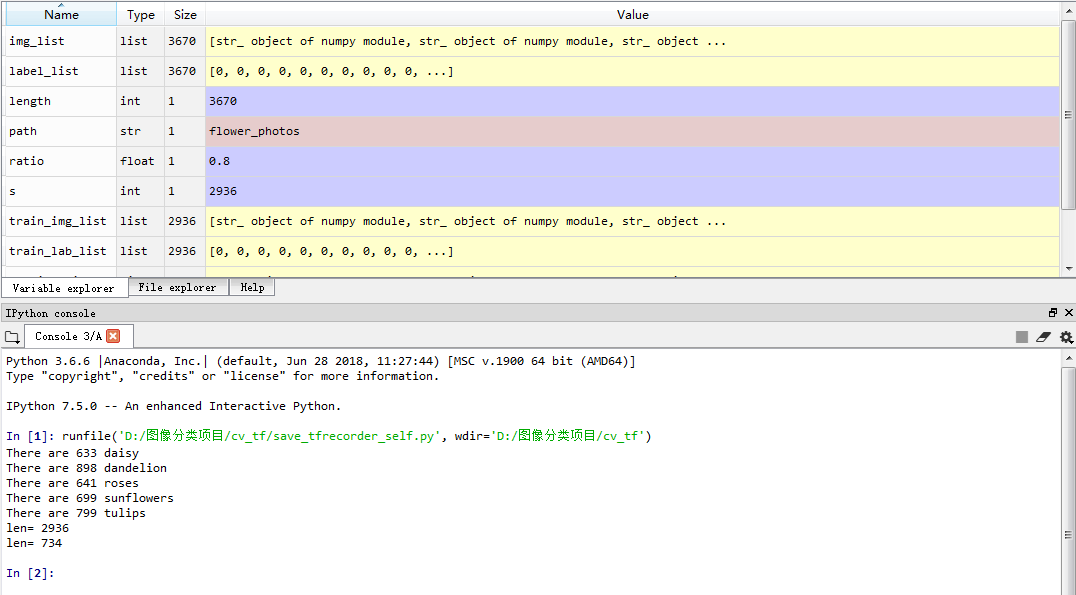
I run the spider under anaconda, and you can see

1. It can be seen that there are 633 + 898 + 641 + 699 + 799 = 3670 photos in the five types, 633x0.8+898x0.8+641x0.8+699x0.8+799x0.8=2934 photos in the training set, and 3670-2934 = 736 photos in the verification set. It can be seen that the verification set is divided successfully.
2. You can see that the first five pictures of the training set are labeled 20301, namely rose, Daisy, sunflower, Daisy and dandelion. The first five pictures in the verification set are labeled 43401, namely tulip, sunflower, tulip, Daisy and dandelion.
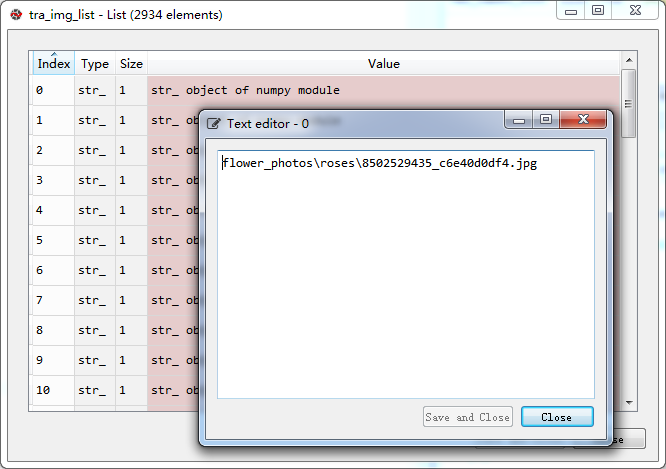
3. Click train in Variable explorer_ img_ List and val_img_list view the training image list and verification image list respectively. You can see that the image list stores the path and file name of the disrupted image.
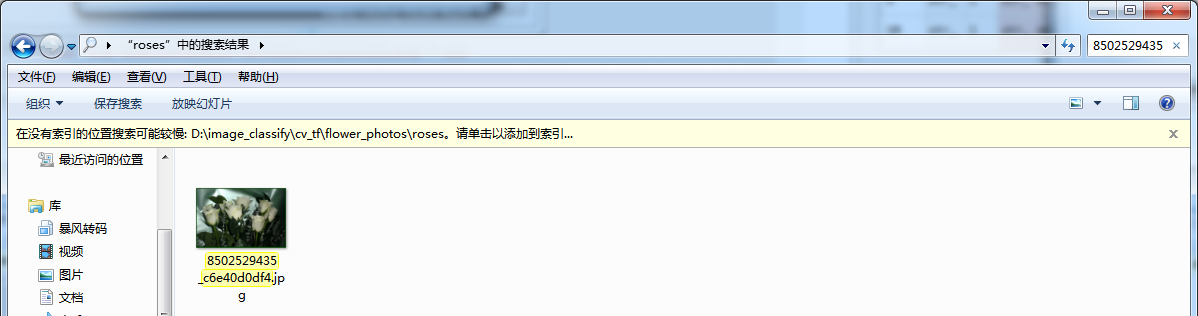
Here, let's look at train first_ img_ The first element of list (subscript 0), pathname flower_photos\roses02529435_c6e40d0df4.jpg, from the train in the above figure_ label_ List, you can see that the label of the first element is 2, corresponding to. Find the picture according to the path.
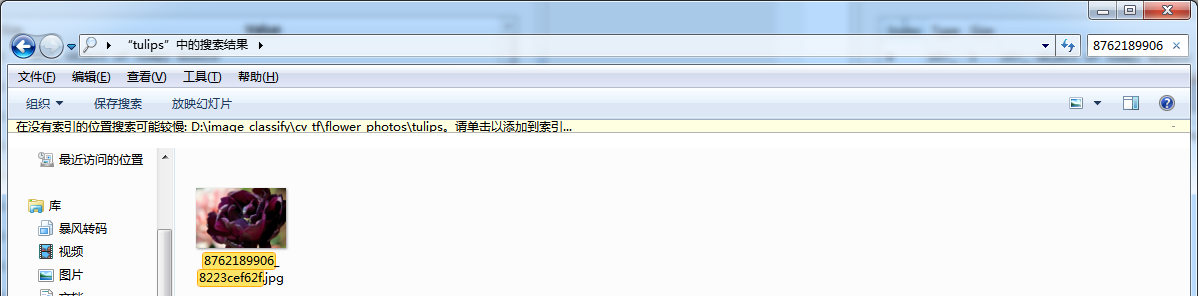
Check Val again_ img_ The first element (subscript 0) of the list, with the pathname flower_photos\tulips62189906_8223cef62f.jpg, from Val in the previous figure_ label_ List can see that the label of the first element is 4, corresponding to. Find the picture according to the path.

3. If get_ Note out np.random.shuffle(temp) in the file function. You can see that the training set and verification set are completely divided in order. GG
Read and display the data in the tfrecord file
"""read TFRecord The data in the file is displayed as a picture"""
import tensorflow as tf
import matplotlib.pyplot as plt
# tf.train.string_ input_ The producer function creates an input queue using the list of files provided during initialization
# The original elements in the input queue are all files in the file list. You can set the shuffle parameter.
filename_queue = tf.train.string_input_producer(["flower_tra100.tfrecords"])
# Create a reader to read the samples in the TFRecord file
reader = tf.TFRecordReader()
# Read a sample from the file. You can also use read_ up_ The to function reads multiple cases at once
_, serialized_example = reader.read(filename_queue) #Returns the file name and file name
# Parse a sample read in. If you need to parse multiple samples, you can use parse_example function
features = tf.parse_single_example(
serialized_example,
features={
# The result of tf.FixedLenFeature parsing is a tensor
'label': tf.FixedLenFeature([], tf.int64),
'image_raw' : tf.FixedLenFeature([], tf.string),
}) #Take out the feature object containing image and label
# tf.decode_raw can parse the string into an array of pixels corresponding to the image
image = tf.decode_raw(features['image_raw'], tf.uint8)
# Restore the image according to the image size
image = tf.reshape(image, [100 , 100, 3])
# Convert the data format of image into real number type and normalize it
# image = image.astype('float32');image /= 255
image = tf.cast(image, tf.float32) * 1.0/255
label = tf.cast(features['label'], tf.int32)
# Image standardization is the centralized processing of data through de averaging, which is easier to achieve the generalization effect after training
# Scale the image linearly to have a zero mean and a unit norm. Operation calculation (x - mean) / adjusted_stddev
# image = tf.image.per_image_standardization(image)
with tf.Session() as sess: #Start a session
init_op = tf.global_variables_initializer()
sess.run(init_op)
# Use tf.train.Coordinator() to co start threads.
coord=tf.train.Coordinator() #Create a coordinator, which is mainly used to stop together with multiple threads
threads= tf.train.start_queue_runners(coord=coord)#Start QueueRunner, and the file name queue has been queued
for i in range(5):
plt.imshow(image.eval())
plt.show()
# Call request_ After the stop() function, should_ The return value of the stop function will be set to True
# In this way, other threads can stop at the same time
coord.request_stop()
# Wait for all threads to exit
coord.join(threads)
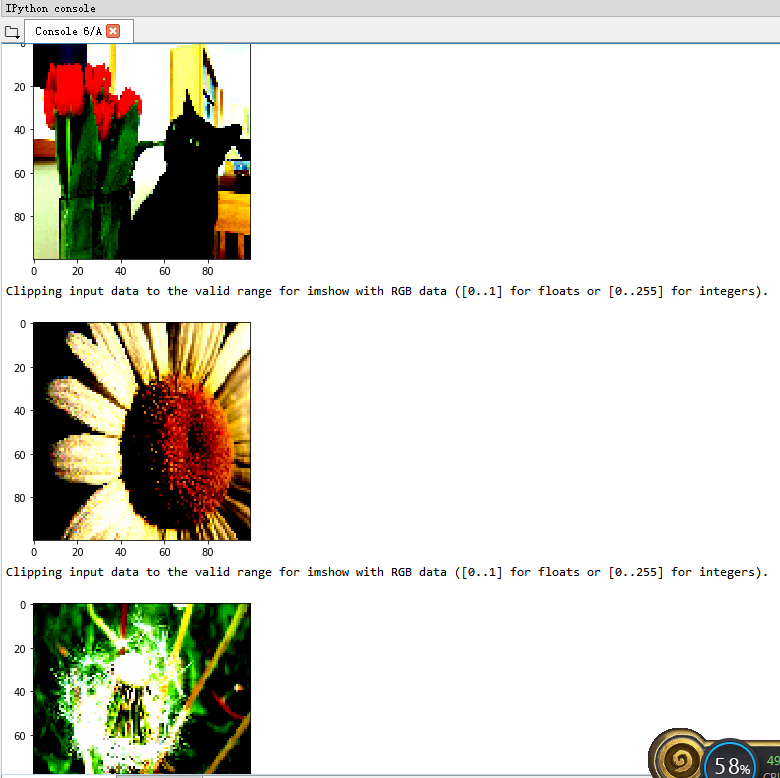
1. First display the first 5 photos in the training set, and the results are as follows. You can see that the first picture is the same as the previous one, and the first five kinds are roses, daisies, sunflowers, daisies and dandelions, one by one corresponding to the previous one. Note that the size of the displayed picture is 100x100.


2. Then read and display the first 5 photos in the verification set, and the results are as follows. You can see that the first picture is the same as the previous one, and the first five kinds are tulips, sunflowers, tulips, daisies and dandelions, corresponding to the previous one by one. Note that the size of the displayed picture is 100x100


3. Uncomment the line of code standardizing the image, i.e. image = tf.image.per_image_standardization(image), you can see that the image features are more generalized.