1 Definition
Window function, also known as analysis function
Analytic functions compute an aggregate value based on a group of rows. They differ from aggregate functions in that they return multiple rows for each group.
The group of rows is called a window and is defined by the analytic_clause.The window determines the range of rows used to perform the calculations for the current row.
Analytic functions are the last set of operations performed in a query except for the final ORDER BY clause.
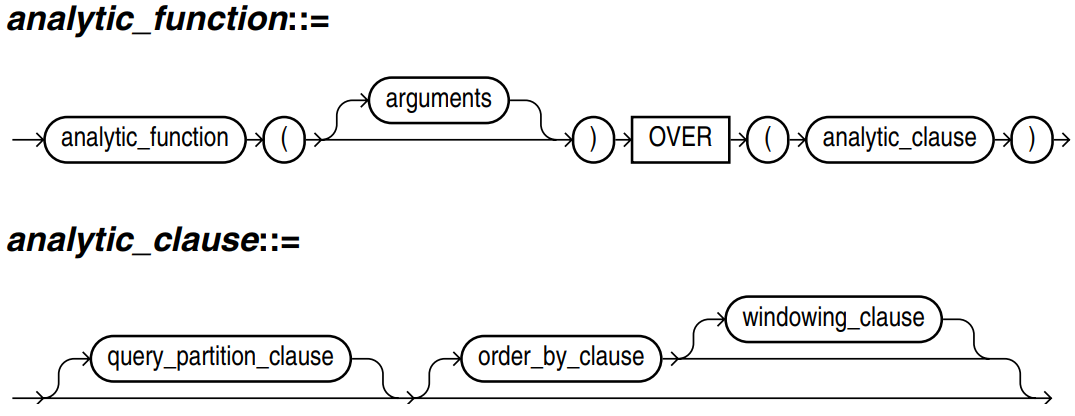
2. WINDOW clause
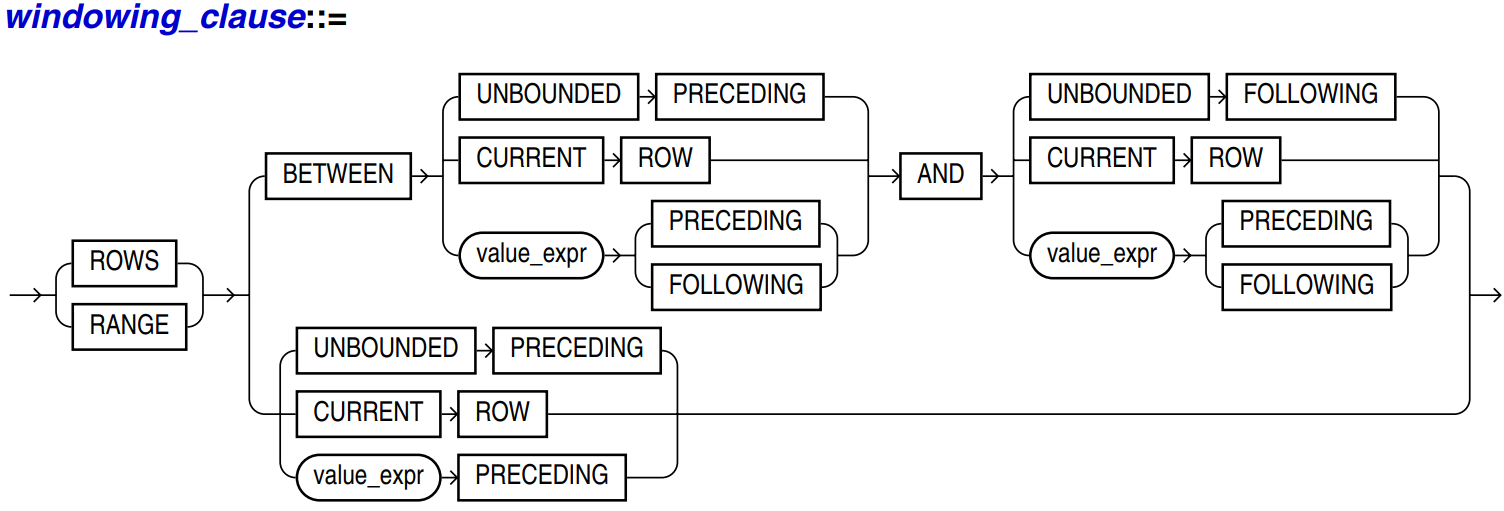
ROWS specifies the window in physical units (rows)
RANGE specifies the window as a logical offset. Defined according to the range of calculated column values, the same row of column values will be combined into the same data for calculation
Analysis function usage and window clause range/rows difference
The difference between ROWS and RANGE modes in PostgreSQL window functions
SQL Server Windowing Functions: ROWS vs. RANGE
BETWEEN ... AND: specify a start point and end point for the window
CURRENT ROW: CURRENT ROW
N forecasting: first n lines
Unbounded forecasting: up to line 1
N FOLLOWING: the last n lines
UNBOUNDED FOLLOWING: up to the last line
-- From start to current line rows between unbounded preceding and current now -- Two ahead to one back rows between 2 preceding and 1 following -- 2 lines ahead to the current line rows between 2 preceding and current row -- Indicates the current line to the end point rows between current row and unbounded following
3 common window functions
https://help.aliyun.com/knowledge_detail/120397.html
https://www.jianshu.com/p/12eaf61cf6e1
https://blog.csdn.net/dingchangxiu11/article/details/83145151
LAG: returns the value of the upper offset line in the window
LEAD: returns the value of the next offset line in the window
LAG(x[, offset[, default_value]])
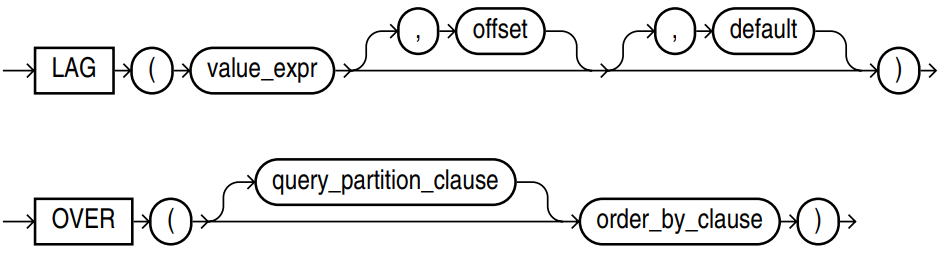
The offset start value is 0, which is the current data row. The offset can be a scalar expression, and the default offset is 1.
If the value of the offset is null or greater than the window length, it returns default value; if no default value is specified, it returns null.
select uname, create_time, pv,
lag(pv,1,-9999) over (partition by uname order by create_time) as lag_1_pv,
lead(pv,1,-9999) over (partition by uname order by create_time) as lead_1_pv
from window_function_temp;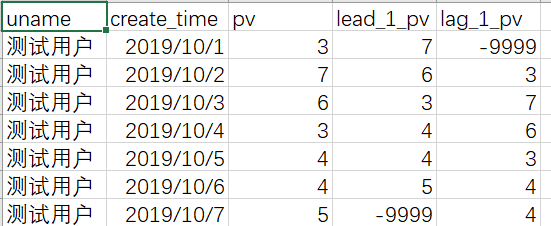
Deny rank: generates the rank of data items in the group. If the rank is equal, no vacancy will be left in the rank
RANK: generate the ranking of data items in the group. If the ranking is equal, the vacancy will be left in the ranking
ROW_NUMBER: starting from 1, generate the sequence of records in the group in order, without repetition
select cookieid, create_time, pv,
row_number() over (partition by cookieid order by pv desc) as rk1,
rank() over (partition by cookieid order by pv desc) as rk2,
dense_rank() over (partition by cookieid order by pv desc) as rk3
from table1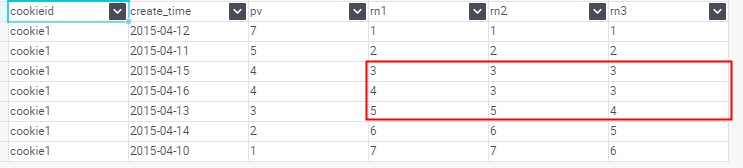
pandas implementation of row ﹣ number
# Hive SQL # Row ou number() over (partition by group field order by sort field sort method) # It assigns a unique number to each row to which it is applied # (either each row in the partition or each row returned by the query) select *, row_number() over (partition by uid order by ts desc) as rk from t_order; # Python # To facilitate sorting, convert the string format of ts column to date format # pandas.to_datetime(arg, errors='raise', dayfirst=False, yearfirst=False, utc=None, format=None, # exact=True, unit=None, infer_datetime_format=False, origin='unix', cache=True) # https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.to_datetime.html?highlight=to_datetime#pandas.to_datetime order['ts_datetime'] = pd.to_datetime(order['ts'], format='%Y-%m-%d %H:%M:%S') # DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last') order.sort_values(by = ['uid','ts_datetime'], ascending=[True,False],inplace=True ) # DataFrame.rank(self: ~FrameOrSeries, axis=0, method: str = 'average', # numeric_only: Union[bool, NoneType] = None, na_option: str = 'keep', ascending: bool = True, pct: bool = False) # If the scores of two people are the same, they occupy the first two places. method='average 'means that both of them are ranked 1.5, and the next one is the third. # method='min': both are the first, and the next is the third. rank() similar to Hive SQL # Method ='deny ': both are first, but the next is second. Deny u rank() similar to Hive SQL # method='max': both are in the second place, and the next is in the third place. # method='first ': ranked first and second respectively in the original order. Row ou number() similar to Hive SQL order['rk'] = order.groupby(['uid'])['ts_datetime'].rank(ascending=False, method='first').astype(int)
NTILE: scatter the data of each window partition into n buckets with bucket numbers from 1 to n. If the number of data rows in the window partition cannot be evenly distributed in each bucket, the remaining value will start from the first bucket, and each bucket will be divided into one row of data
select last_name, salary,
ntile(4) over (order by salary desc) as qquartile
from employees
where department_id = 100;
LAST_NAME SALARY QUARTILE
----------- ---------- ----------
Greenberg 12000 1
Faviet 9000 1
Chen 8200 2
Urman 7800 2
Sciarra 7700 3
Popp 6900 4
First value: after sorting within the group, the first value will end at the current row
Last value: after sorting within the group, the last value will end in the current row
select uname, create_time, pv,
first_value(pv) over (partition by uname order by create_time rows between unbounded preceding and current row) as first_value_pv,
last_value(pv) over (partition by uname order by create_time rows between unbounded preceding and current row) as last_value_pv
from window_function_temp;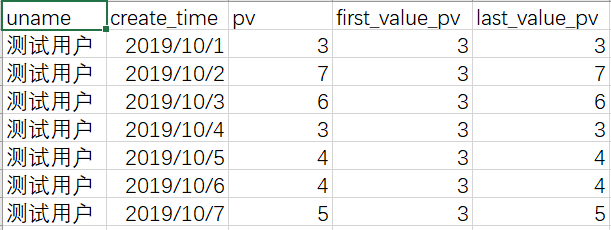
Cume? Dist: number of rows less than or equal to the current value / total number of rows in the group
PERCENT_RANK: RANK value of the current line in the group - 1 / total number of lines in the group - 1
select uname, create_time, pv,
cume_dist() over (partition by uname order by pv) as cume_dist_pv_,
percent_rank() over (partition by uname order by pv) as precent_rank_pv_
from window_function_temp;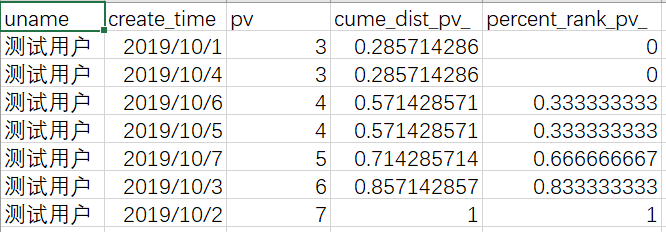
Support aggregate functions: SUM, COUNT, MAX, MIN, AVG
select cookieid, create_time, pv,
sum(pv) over (partition by cookieid order by create_time) as pv1, --Default from start to current row
sum(pv) over (partition by cookieid order by create_time
rows between unbounded preceding and current row) as pv2, --From start to current line (and pv1 Same)
sum(pv) over (partition by cookieid) as pv3, --All rows in group
sum(pv) over (partition by cookieid order by create_time
rows between 3 preceding and current row) as pv4, --Current row+3 lines ahead
sum(pv) over (partition by cookieid order by create_time
rows between 3 preceding and 1 following) as pv5 --Current row+3 lines ahead+1 rows in the future
from table1
4 create table + load data
-- Reference link https://www.yiibai.com/hive/hive_create_table.html -- Syntax for creating tables CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [ROW FORMAT row_format] [STORED AS file_format] -- Create an instance of the table CREATE TABLE `t_order`( `id` int comment "id", `ts` string comment "Order time", `uid` string comment "user id", `orderid` string comment "Order id", `amount` float comment "Order amount" ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE; -- Syntax for loading data LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] -- Loading instances of local data -- overwrite Delete the original data and add new data load data local inpath '/home/Downloads/order.csv' overwrite into table t_order;

