Personal blog
Welcome to personal blog: https://www.crystalblog.xyz/
Alternate address: https://wang-qz.gitee.io/crystal-blog/
1. Differences between hashtable and HashMap
(1), HashMap implementation is out of sync and thread is unsafe Key values in HashMap are stored in Entry
Hashtable thread safety Use synchronized
jdk7 underlying data structure: array + linked list
jdk8 underlying data structure: array + linked list + red black tree
(2) , inheritance is different HashMap inherits abstractmap and hashtable inherits Dictionary class
(3) , the methods in Hashtable are synchronous, while the methods in HashMap are asynchronous by default. In the multi-threaded concurrent environment, you can directly use Hashtable However, to use HashMap, you need to add synchronization processing yourself
(4) , key and value in HashMap are allowed to be null
In Hashtable, neither key nor value is allowed to be null
(5) , the use of hash value is different. HashTable directly uses the hashCode value of the object, and HashMap recalculates the hash value
2. What are the defects of Hashtable? Why is Hashtable rarely used?
The bottom layer of Hashtable uses synchronized to ensure thread safety Thread safety issues: locking
Upgrading process of synchronized lock: bias lock, light lock and heavy lock
(1) , the traditional Hashtable uses synchronized to lock the array in the whole Hashtable, but in the case of multiple threads, only one thread is allowed to access put or get operations, which is very inefficient, but it can ensure thread safety
(2), Jdk officials do not recommend using Hashtable or HashMap in the case of multithreading. It is recommended to use concurrent HashMap to segment HashMap, which is very efficient
Core idea: reduce lock competition under multiple threads and won't access the same Hashtable
(3) , in jdk8, ConcurrentHashMap cancels the segment lock design, and the get method of ConcurrentHashMap has no lock competition; The get method of Hashtable has lock competition
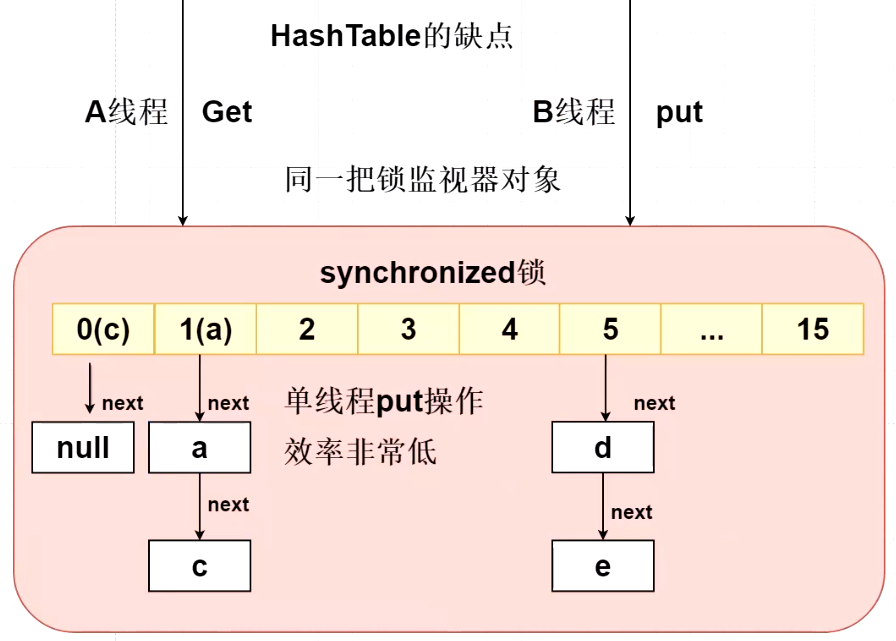
In the above figure, thread A obtains this lock and performs get operation, while thread B's put cannot operate
public class HashtableTest {
public static void main(String[] args) {
// a. If B thread uses the same Hashtable, this lock will compete
Hashtable<Object, Object> hashtable = new Hashtable<>();
// a thread, get operation
new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "---" + hashtable.get("key"));
}
}, "a thread ").start();
// b thread, put operation
new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "---" + hashtable.put("key", "value"));
}
}, "b thread ").start();
}
}
3. Underlying implementation of concurrenthashmap 1.7
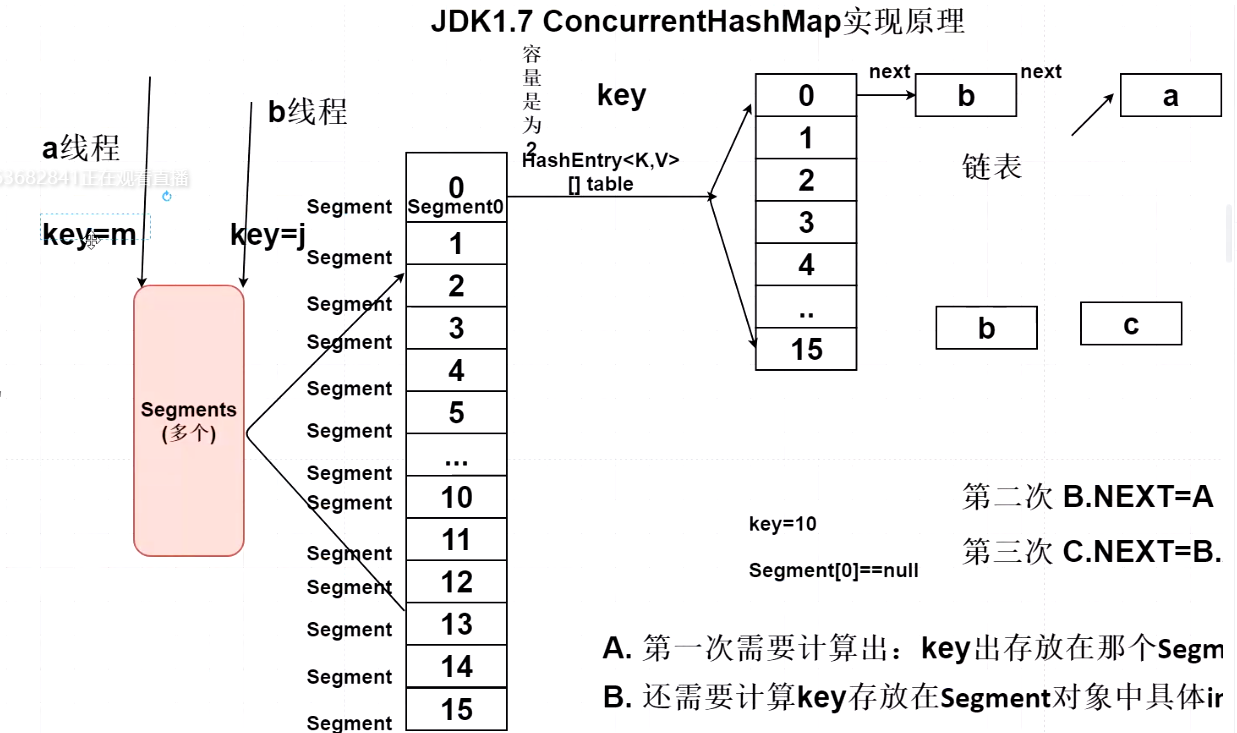
ConcurrentHashMap divides a large HashMap set into n different small hashtables (segments). By default, it is divided into 16 different segments Each Segment has its own independent hashentry < K, V > [] table;
 In the figure above, if the keys written by multiple threads are finally calculated into different small Hashtable sets, multiple threads can write keys at the same time without lock competition However, if the keys written by multiple threads finally land in the same small Hashtable set, lock competition will occur
In the figure above, if the keys written by multiple threads are finally calculated into different small Hashtable sets, multiple threads can write keys at the same time without lock competition However, if the keys written by multiple threads finally land in the same small Hashtable set, lock competition will occur
4. Design of concurrent HashMap section lock
The bottom layer of ConcurrentHashMap adopts subsection lock design, which splits a large Hashtable thread safe set into multiple small Hashtable sets, and initializes 16 small Hashtable sets by default
If the index value finally calculated by 16 threads falls to different small Hashtable sets at the same time, lock competition will not occur. At the same time, 16 threads can access the write operation of ConcurrentHashMap, which is very efficient
In Jdk7, ConcurrentHashMap needs to calculate the index value twice:
The index value is calculated for the first time, and the calculated key is stored in a specific small Hashtable
Calculate the index value for the second time, and calculate the specific index value corresponding to the key stored in the specific small Hashtable
5. How to write a ConcurrentHashMap
public class MyConcurrentHashMap<K, V> {
private Hashtable<K, V>[] hashtables;
public MyConcurrentHashMap() {
// Initialize 16 length Hashtable array
hashtables = new Hashtable[16];
for (int i = 0; i < hashtables.length; i++) {
hashtables[i] = new Hashtable<K, V>();
}
}
// put method
public void put(K k, V v) {
// Calculate the stored index according to hashcode
int hashtableIndex = k.hashCode() % hashtables.length;
hashtables[hashtableIndex].put(k, v);
}
// get method
public V get(K k) {
// Get the index of data storage according to hashcode
int hashtableIndex = k.hashCode() % hashtables.length;
return hashtables[hashtableIndex].get(k);
}
// test
public static void main(String[] args) {
MyConcurrentHashMap<String, String> concurrentHashMap = new MyConcurrentHashMap<>();
concurrentHashMap.put("m", "mv");
concurrentHashMap.put("k", "kv");
System.out.println(concurrentHashMap.get("m") + "--" + concurrentHashMap.get("k"));
}
}