1. Introduction Case - WordCount
Requirement: Statistically output the total number of occurrences of each word in a given set of text files
1. Data format preparation
- Create a new file
cd /export/servers
vim wordcount.txt
- Put the following into it and save it
hello,world,hadoop hive,sqoop,flume,hello kitty,tom,jerry,world hadoop
- Upload to HDFS
hdfs dfs -mkdir /wordcount/ hdfs dfs -put wordcount.txt /wordcount/
2. Mapper
/** *LongWritable k1 Type (offset) (should not be Long, for serialization is not bloated) *Text V2 Type (text content) *Text k2 type *LongWritable V2 type *k1,v1--->k2,v2 **/ public class WordCountMapper extends Mapper<LongWritable,Text,Text,LongWritable> { /* key---->k1 value---->v1 context----->Context object */ @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { Text text = new Text(); LongWritable longWritable =new LongWritable(); String line = value.toString(); String[] split = line.split(","); text.set(word); longWritable.set(1); for (String word : split) { //Context: Environment, domain objects, store and take values within a certain range //context.write(new Text(word),new LongWritable(1)); context.write(text,longWritable); } } } //Why serialization? //Data transmission between different node s requires serialization and IO streaming.
3. Reducer
/** *New k2, new v2, k3, v3 *This new k2,v2 is formed by k2,v2 through shuffle partition, sorting, specification, grouping (must have) **/ public class WordCountReducer extends Reducer<Text,LongWritable,Text,LongWritable> { /** * Customize our reduce logic * All key s are our words, and all values are the number of times our words appear. * @param key New k2 * @param values New v2 * @param context context * @throws IOException * @throws InterruptedException */ @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { long count = 0; for (LongWritable value : values) { count += value.get(); } context.write(key,new LongWritable(count)); } }
4. Define the main class, describe Job and submit Job
public class JobMain extends Configured implements Tool { @Override public int run(String[] args) throws Exception { Job job = Job.getInstance(super.getConf(), JobMain.class.getSimpleName()); //When packaged on a cluster, you must add the following configuration to specify the main function of the program job.setJarByClass(JobMain.class); //Step 1: Read the input file and parse it into key, value pairs job.setInputFormatClass(TextInputFormat.class); TextInputFormat.addInputPath(job,new Path("hdfs://192.168.52.250:8020/wordcount")); //Step 2: Setting up our mapper class job.setMapperClass(WordCountMapper.class); //Set the output type after the completion of our map phase job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); //Step three, step four, step five, step six, ellipsis //Step 7: Set up our reduce class job.setReducerClass(WordCountReducer.class); //Set the output type after the completion of our reduce phase job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //Step 8: Set up the output class and output path job.setOutputFormatClass(TextOutputFormat.class); TextOutputFormat.setOutputPath(job,new Path("hdfs://192.168.52.250:8020/wordcount_out")); boolean b = job.waitForCompletion(true); return b?0:1; } /** * Entry Class of main Function of Program * @param args * @throws Exception */ public static void main(String[] args) throws Exception { Configuration configuration = new Configuration(); Tool tool = new JobMain(); int run = ToolRunner.run(configuration, tool, args); System.exit(run); } }
2. Operation mode of MapReduce
2.1 Cluster Operation Mode
- Submit the MapReduce program to the Yarn cluster, distribute it to many nodes and execute it.
- Processing data and output results should be located on the HDFS file system
- Implementation steps of submitting the cluster: type the program into JAR package, upload it, and start it on the cluster with hadoop command
hadoop jar hadoop_hdfs_operate-1.0-SNAPSHOT.jar cn.itcast.mapreduce.JobMain
2.2 Local Running Mode
- MapReduce programs run locally as a single process
- Processing data and output results in the local file system
- Jobs running in local mode do not appear on the job history page
TextInputFormat.addInputPath(job,new Path("file:///E:\\mapreduce\\input")); TextOutputFormat.setOutputPath(job,new Path("file:///E:\\mapreduce\\output"));
3. MapReduce partition
3.1 Partition Overview
In MapReduce, data from the same partition is sent to the same Reduce for processing by specifying partitions.
For example, for the purpose of data statistics, a batch of similar data can be sent to the same Reduce, and the same type of data can be counted in the same Reduce, so that similar data partitioning and statistics can be achieved.
In fact, it is the same type of data, data with common characteristics, sent together for processing. There is only one default partition in Reduce

3.2 Zoning Case - Statistics of Lottery Winning Results
Requirements: Separate processing of the following data
See partition.csv for details. The fifth field represents the value of the prize opening result. It is now necessary to separate the results above 15 and below 15 into two files for preservation.

1. Define Mapper
The Mapper program does not do any logic, nor does it make any changes to Key-Value. It just receives data and sends it down.
public class MyMapper extends Mapper<LongWritable,Text,Text,NullWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { context.write(value,NullWritable.get()); } }
2. Custom Partitioner
Here's the main logic, and that's what this case is all about, distributing data to different Reducer s through Partitioner s
/** * The input type here is the same as the output type in our map phase. */ public class MyPartitioner extends Partitioner<Text,NullWritable>{ /** * The return value indicates which partition our data is going to * The return value is just a tag for a partition, marking all the same data to the specified partition */ @Override public int getPartition(Text text, NullWritable nullWritable, int i) { String result = text.toString().split("\t")[5]; if (Integer.parseInt(result) > 15){ return 1; }else{ return 0; } } }
3. Define Reducer Logic
This Reducer does not do any processing, just output the data intact.
public class MyReducer extends Reducer<Text,NullWritable,Text,NullWritable> { @Override protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { //Without grouping, use NullWritable as value context.write(key,NullWritable.get()); } }
4. Setting the number of partition classes and ReduceTask s in the main class
public class PartitionMain extends Configured implements Tool { public static void main(String[] args) throws Exception{ int run = ToolRunner.run(new Configuration(), new PartitionMain(), args); System.exit(run); } @Override public int run(String[] args) throws Exception { Job job = Job.getInstance(super.getConf(), PartitionMain.class.getSimpleName()); job.setJarByClass(PartitionMain.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); TextInputFormat.addInputPath(job,new Path("hdfs://192.168.52.250:8020/partitioner")); TextOutputFormat.setOutputPath(job,new Path("hdfs://192.168.52.250:8020/outpartition")); job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); job.setReducerClass(MyReducer.class); /** * Set up our partition classes and the number of our reducetasks. Note that the number of reducetasks must be in line with ours. * The number of partitions is consistent */ job.setPartitionerClass(MyPartitioner.class); job.setNumReduceTasks(2); boolean b = job.waitForCompletion(true); return b?0:1; } }
4. Counters in MapReduce
Counter is one of the effective means to collect statistical information of operation, which is used for quality control or application-level statistics. The counter can also assist in diagnosing system faults. If you need to transfer log information to a map or reduce task, a better way is usually to see if a counter value can be used to record the occurrence of a particular event. For large distributed jobs, the use of counters is more convenient. In addition to the fact that it is more convenient to get counter values than to output logs, it is much easier to count the number of specific events based on counter values than to analyze a pile of log files.
hadoop built-in counter list
| MapReduce Task Counter | org.apache.hadoop.mapreduce.TaskCounter |
|---|---|
| File System Counter | org.apache.hadoop.mapreduce.FileSystemCounter |
| FileInputFormat counter | org.apache.hadoop.mapreduce.lib.input.FileInputFormatCounter |
| FileOutputFormat counter | org.apache.hadoop.mapreduce.lib.output.FileOutputFormatCounter |
| Job counter | org.apache.hadoop.mapreduce.JobCounter |
After each mapreduce execution, we will see some logs, some of the most important of which are shown in the following screenshot
[External Link Picture Transfer Failure (img-eD8FgX29-1567901621698)(assets/1565967787848.png)]
All of these are the functions of MapReduce counter. Since MapReduce has the function of counter, how can we realize our own counter???
Requirements: Take the above partition code as an example to count the number of data records received by map
The first way
Define counters, which can be retrieved and recorded through context context objects
Use counters on the map side for statistics through context context objects
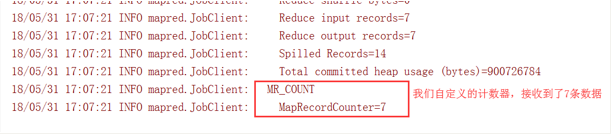
public class PartitionMapper extends Mapper<LongWritable,Text,Text,NullWritable>{ //map method converts K1 and V1 to K2 and V2 @Override protected void map(LongWritable key, Text value, Context context) throws Exception{ Counter counter = context.getCounter("MR_COUNT", "MyRecordCounter"); counter.increment(1L); context.write(value,NullWritable.get()); } }
After running the program, you can see that our custom counter reads seven pieces of data in the map phase.
The second way
Define counters by enum enumeration types
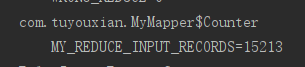
How many key s are input to reduce data?
public class PartitionerReducer extends Reducer<Text,NullWritable,Text,NullWritable> { public static enum Counter{ MY_REDUCE_INPUT_RECORDS,MY_REDUCE_INPUT_BYTES } @Override protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { context.getCounter(Counter.MY_REDUCE_INPUT_RECORDS).increment(1L); context.write(key, NullWritable.get()); } }