catalogue
1, Introduction to InputFormat
2, Parallelism of slicing and MapTask tasks
3, Job submission process source code
4, InputFormat implementation subclass
5, Slicing mechanism of FileInputFormat
(2) Slice source code analysis
(4) FileInputFormat default slice size parameter configuration
6, Use of TextInputFormat implementation class
(3) Data reading (mapping to key value pairs)
7, Use of CombineTextInputFormat implementation class
(1) The role of the CombineTextInputFormat class
(2) Set the CombineTextInputFormat slicing mechanism
(6) Data reading: createRecordReader()
8, Use of KeyValueInputFormat implementation class
(1) Set KeyValueInputFormat as the slicing mechanism
9, Use of NlineInputFormat implementation class
(1) Set NLineInputFormat as the slicing mechanism
1, Introduction to InputFormat
InputFormat is an abstract class that does not implement how to slice and how to convert. It is implemented by its subclasses. The default implementation class of InputFormat is FileInputFormat, which is also an abstract class without specific implementation. It is finally implemented by the subclass of FileInputFormat. There are five subclasses in total. The fragmentation mechanism of each subclass and the format of data converted into key value pairs are different. By default, textinputformat < K, V > is used
InputFormat is an abstract class with two methods:
- getSplits(JobContext var1): defines how our input file is sliced
- createRecordReader(InputSplit var1, TaskAttemptContext var2): the input in the map phase of MR program is a key value pair. This method defines how MapTask reads slice data into key value pairs when processing slice data after slicing. In other words, this method is used to map the input data into the form of key value pairs of the input in the map phase
The MR program is divided into MapTask stage and ReduceTask stage when running. There can be multiple maptasks and ReduceTask, but there is a problem:
How many maptasks are appropriate?
How many ReduceTask settings are appropriate?
How many MapTask settings are based on? File content or file size?
2, Parallelism of slicing and MapTask tasks
Parallelism: how many MapTask tasks are running simultaneously during MR operation
The parallelism of MapTask determines the concurrency of task processing in the Map phase, and then affects the processing speed of the whole Job.
Data block: block is the physical division of data by HDFS. Hadoop2. In version x, a block block defaults to 128M. Suppose you want to store 200MB of data, it is divided into two blocks: 0-128MB and 128MB-200MB
Data slicing: data slicing is a concept only available when the MR program is running. It represents cutting the file data on HDFS according to some algorithm. Each piece of data cut is called slicing, and in the MR program, a slice needs to be processed by a MapTask task. Slicing is only the logical slicing of input, and it will not be sliced on disk for storage.
MapTask parallelism: MapTask parallelism is determined by the number of slices. The number of slices determines the number of maptasks.
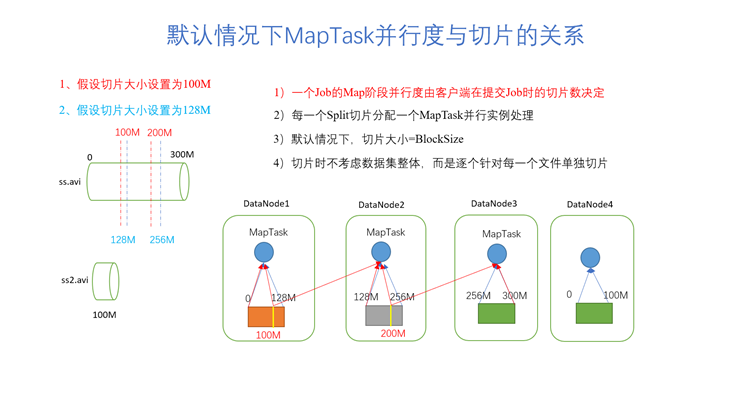
[exercise] suppose you want to process four files. The first file size is 400M, the second file size is 112M, the third file size is 50M, and the fourth file size is 200M. Slice the file (see the parallelism of MapTask). The slice size uses the default size - blocksize: 128M
[answer] there are 8 slices in total, that is, the parallelism of MapTask is 8. The first file has four slices (0-128M, 129-256M, 257-384M, 385-400M), the second file has one slice (0-112M), the third file has one slice (0-50M), and the fourth file has two slices (0-128M, 129-200M)
Notes: when slicing, the data set as a whole is not considered, but each file is sliced separately one by one
[Q1] why slice data?
[answer] the main reason for slicing is to cut a large file into multiple pieces. Each piece starts a MapTask task to process, which is fast and efficient.
[Q2] when to slice? When to define the slicing rules?
[answer] Job workflow in Driver driver
3, Job submission process source code
Check the Job submission process by debugging the code through debug:
- Create a Cluster object - determine whether the code is running locally or in YARN
- Judge whether the output path exists or not, and report an error if it exists
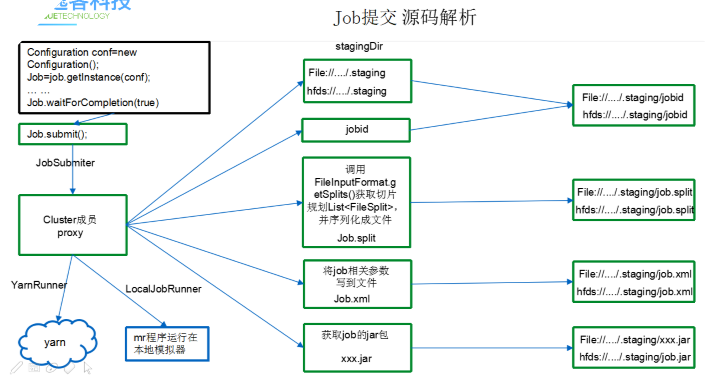
- Create the submission path of MR program resources (Resources: jar package, slice planning file, configuration parameters for job operation) -- the main purpose is to upload all configuration items and slice planning files configured in the job to a resource submission path after the job runs the task. When the job runs, it will find the configuration file under the resource submission path
- Generate jobid (task ID): finally, resources are submitted under the folder path of resource submission path + jobid
-
Call getSplits() in the InputFormat implementation class to generate a slice planning file and put it in the submission path ----- the slice planning of FileInputFormat class
Where int maps = this writeSplits(job, submitJobDir); Method defines the default slicing mechanism for FileInputFormat.
If no InputFormat implementation class is specified, the TextInputFormat implementation class is called by default for slicing
-
Write all Configuration parameters in the Configuration that the job depends on to the job XML file and put it under the submission path
- After all resources are submitted, the job runs the MR program according to the resource file in the submission path
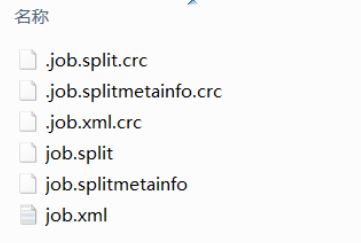
The following files will be generated in the job directory of the job before submission:- job.split: slice information of the current Job. There are several slice objects
- job.splitmetainfo: attribute information of the slice object
- job. XML: configuration of all job attributes
- jar package: only exists in the cluster mode, not in the local running environment
Detailed code process of job submission:
|
waitForCompletion() submit(); //1 establish connection connect(); / / 1) create a job submission agent new Cluster(getConfiguration()); / / (1) judge whether it is local yarn or remote initialize(jobTrackAddr, conf); / / 2. Submit a job submitter.submitJobInternal(Job.this, cluster) / / 1) create a Stag path to submit data to the cluster Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf); / / 2) get jobid and create job path JobID jobId = submitClient.getNewJobID(); / / 3) copy the jar package to the cluster copyAndConfigureFiles(job, submitJobDir); rUploader.uploadFiles(job, jobSubmitDir); //4) calculate slices and generate slice planning files writeSplits(job, submitJobDir); maps = writeNewSplits(job, jobSubmitDir); input.getSplits(job); //5) write an xml configuration file to the Stag path writeConf(conf, submitJobFile); conf.writeXml(out); //6) submit the job and return to the submission status status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials()); |
4, InputFormat implementation subclass
The default implementation subclass of InputFormat is also our most commonly used implementation subclass: FileInputFormat().
FileInputFormat() is also an abstract class, which does not define how we should fragment and read data into key value pairs.
There are five implementation subclasses commonly used by FileInputFormat():
- TextInputFormat<K,V>
- CombineFileInputFormat<K,V>
- KeyValueTextInputFormat<K,V>
- NLineInputFormat<K,V>
-
Sequencefileinputformat < K, V > --- only SequenceFile files can be processed
5, Slicing mechanism of FileInputFormat
During the operation of the job submission task, a section needs to call the getSplits() method of the InputFormat implementation class to implement the slice planning, write the slice planning to a slice planning file (job.split) and submit it to the resource path
There are many InputFormat implementation classes. Different implementation classes have different slicing mechanisms and input mapping methods to become key value pairs. If the implementation class of InputFormat is not specified when running the program, the slicing mechanism and mapping method in TextInputFormat are used by default.
// Defines the default implementation class for InputFormat. If not defined, TextInputFormat is used by default job.setInputFormatClass(TextInputFormat.class);
The default slicing mechanism for FileInputFormat is in jobsubmitter Int maps of Java = this writeSplits(job, submitJobDir); Method.
(1) Slicing mechanism:
- Gets the minimum minSize(1B) and maximum maxSize(long.MAX_VALUE) of the slice defined in FileInputFormat
- Get all files under the input file path
- Under the default slicing mechanism, a file needs to be sliced once
- After getting a file, first judge whether the file can be sliced. If not, the file is mostly just a slice. (in MR, some compressed packages do not support fragmentation, for example, tar.gz file cannot be fragmented)
- Continue to judge that if the size of the file does not exceed 1.1 times the default defined slice size, no slice will be made
-
If the file can be sliced and exceeds 1.1 times the defined minimum slice size, it will be sliced according to the slicing rules.
For example, splitSize=100M, file 120M, slice: 0-100M, 100-120M
- Calculation rules for SplitSize:
FileInputFormat.class: Math.max(minSize, Math.min(maxSize, blockSize))
(2) Slice source code analysis
JobSubmitter.class: 224 line ----- define slicing rules

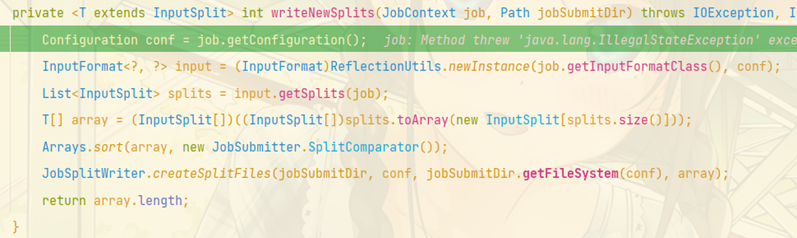
getSplits(job):
while(true) {
while(true) {
while(i$.hasNext()) {
FileStatus file = (FileStatus)i$.next();
Path path = file.getPath(); // Get file path
long length = file.getLen(); // Get file length
if (length != 0L) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus)file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0L, length);
}
if (this.isSplitable(job, path)) { // Determine whether the file can be sliced
long blockSize = file.getBlockSize(); // Gets the size of the block
long splitSize = this.computeSplitSize(blockSize, minSize, maxSize); // Calculate slice size
long bytesRemaining;
int blkIndex;
for(bytesRemaining = length; (double)bytesRemaining / (double)splitSize > 1.1D; bytesRemaining -= splitSize) {
// Judge whether the file size exceeds 1.1 times of the default partition size. If so, perform the following slicing
blkIndex = this.getBlockIndex(blkLocations, length - bytesRemaining);
splits.add(this.makeSplit(path, length - bytesRemaining, splitSize, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts()));
}
if (bytesRemaining != 0L) {
blkIndex = this.getBlockIndex(blkLocations, length - bytesRemaining);
splits.add(this.makeSplit(path, length - bytesRemaining, bytesRemaining, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts()));
}
} else {
splits.add(this.makeSplit(path, 0L, length, blkLocations[0].getHosts(), blkLocations[0].getCachedHosts()));
}
} else {
splits.add(this.makeSplit(path, 0L, length, new String[0]));
}
}
}
}
protected long computeSplitSize(long blockSize, long minSize, long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}(3) Slicing steps


(4) FileInputFormat default slice size parameter configuration

For example:
// Modify the default maximum slice size. The following two methods can be used
conf.set("mapreduce.input.fileinputformat.split.maxsize", "128");
FileInputFormat.setMaxInputSplitSize(job, 128);6, Use of TextInputFormat implementation class
InputFormat has an abstract subclass FileInputFormat: the commonly used implementation classes in InputFormat are subclasses of FileInputFormat
TextInputFormat is the default FilelnputFormat implementation class
(1) Slicing mechanism
According to file slicing, each file is sliced separately without looking at the overall data set. The files are sliced according to the calculation formula
(2) Slicing steps
- Judge whether the slice can be cut: isSplitable(). Generally, compressed files cannot be cut
- Calculate slice size: math max(minSize, Math.min(maxSize, blockSize))
- Is the remaining part of the file after cutting 1.1 times the splitSize? If not, it will not be cut; If yes, cut it into two pieces according to the splitSize size
(3) Data reading (mapping to key value pairs)
createRecordReader(): the record reader reads each record by line. After reading, the Key key is the offset of the starting byte of the line stored in the whole file. It is of LongWritable type. The Value value is the content of this line and does not include any line terminators (line feed and carriage return). It is defined as Text type. This Key Value pair will then be used as Mapper input

7, Use of CombineTextInputFormat implementation class
CombineTextInputFormat is the implementation class of CombineFileInputFormat.
The main function of this InputFormat implementation class is to merge small files. If the data we want to process has many small files, Then these small files will send a file under the TextInputFormat slicing mechanism (as long as it does not exceed the defined splitSize) into a separate slice. If there are a large number of small files for the processed data, we don't use TextInputFormat implementation class, which is too wasteful of resources. Hadoop provides an implementation class that can slice small files: CombineTextInputFormat
(1) The role of the CombineTextInputFormat class
Small files can be merged into one or more slices to avoid waste of resources
(2) Set the CombineTextInputFormat slicing mechanism
// Define the use of CombineTextInputFormat to implement the slicing mechanism and merge small files job.setInputFormatClass(CombineTextInputFormat.class); // You need to tell the slice processor the size of each slice CombineTextInputFormat.setMaxInputSplitSize(job, 4*1024*1024);
(3) Slicing mechanism
getSplits(). Slice the data set as a whole, rather than a separate slice of each file.
(4) Thought:
The file is divided into two steps in the slicing process:
- Virtual stored procedure: according to a parameter of the size of the incoming merged file, each file is logically partitioned
Compare the sizes of all files in the input directory with the set setMaxInputSplitSize value in turn. If it is not greater than the set maximum value, it will be logically divided into a block. If the input file is greater than the set maximum value and greater than twice, cut a piece with the maximum value; When the remaining data size exceeds the set maximum value and is not more than twice the maximum value, the files are divided into two virtual storage blocks (to prevent too small slices).
For example, if the setMaxInputSplitSize value is 4M and the input file size is 8.02M, it will be logically divided into 4M first. The remaining size is 4.02M. If divided according to 4M logic, a small virtual storage file of 0.02M will appear, so the remaining 4.02M file is divided into two files (2.01M and 2.01M).
- Slice: merge each slice and compare with the parameters to determine the final size of each slice
Because FileInputFormat is to slice each file independently, no matter how small the file is, each file will produce one or more slices separately The CombineTextInputFormat can logically plan multiple small files into one slice, so that it can be handled by only one MapTask
(5) Process:
- Judge whether the file size of virtual storage is greater than setMaxInputSplitSize. If it is greater than or equal to, a separate slice will be formed.
- If not greater than, merge with the next virtual storage file to form a slice.
- Test example: there are four small files with sizes of 1.7M, 5.1M, 3.4M and 6.8M respectively. After virtual storage, six file blocks will be formed, with sizes of 1.7M, (2.55M, 2.55M), 3.4M and (3.4M, 3.4M) respectively. Finally, three slices will be formed, with sizes of: (1.7 + 2.55) M, (2.55 + 3.4) M and (3.4 + 3.4) M respectively

(6) Data reading: createRecordReader()
Like TextInputFormat, the contents of each slice are read by line. The output key is the starting byte offset of the line in the whole file, and value is the content of the line
8, Use of KeyValueInputFormat implementation class
It is mainly used to process data with obvious key value style in the data
(1) Set KeyValueInputFormat as the slicing mechanism
// Set KeyValueTextInputFormat slice form job.setInputFormatClass(KeyValueTextInputFormat.class); // Set the separator. The first half of the separator is key and the second half is value conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " ");
(2) Slicing mechanism
Consistent with FileInputFormat
(3) Data reading
Read by row, and separate the data of each row according to the separator you give (if not specified, it is the tab character by default). The first field is regarded as key and the remaining fields are regarded as value. Therefore, key is of Text type and value is also of Text type

9, Use of NlineInputFormat implementation class
(1) Set NLineInputFormat as the slicing mechanism
// Set NLineInputFormat slice form job.setInputFormatClass(NLineInputFormat.class); // Set the number of delimited lines of the file, that is, several lines are a slice NLineInputFormat.setNumLinesPerSplit(job, 1);
(2) Slicing mechanism
Cut according to the number of lines of the file, no matter how many files there are. Unlike FileInputFormat, it is sliced according to the set number of lines, and each file is sliced separately. 5 files, at least 5 slices.
(3) Data reading
The RecordReader mechanism is consistent with TextInputFormat. key is also of type LongWritable, and value is also of type Text

10, Custom InputFormat
In many cases, we cannot complete all data processing through these four implementation classes. There is always a file slice, so that the four implementation classes of conversion rules cannot be applied to a special file
MapReduce helps us provide another mechanism: you can customize an InputFormat without these implementation classes
Custom InputFormat implements the functions of KeyValueTextInputFormat:
(1) Steps
- Define an InputFormat class that inherits FileInputFormat
-
Override the getSplits() method and the createRecordReader() method
If you don't need to redefine the slicing rules, you don't have to rewrite them
When overriding the createRecordReader() method, we need to return a RecordReader object, which is the encapsulated object of the key value entered by the Map, so we should create a custom RecordReader class to inherit the methods in the RecordReader class and override. There are 5 methods to inherit:
-
initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext)
Initialization method: you need to import a slice and a context object before cutting: in the createRecordReader() method in MyInputFormat, call this method to complete the incoming.
- nextKeyValue()
Core method -- used to determine what value key is and what value value value is.
A slice has a lot of data. If it is read by row, this method will be called for each row to judge whether there is the next row of data. If yes, return true to continue reading; If not, false is returned, and the current slice data reading is completed
-
getCurrentKey()
Get the key value in the currently read primary data
-
getCurrentValue()
Read the value of each read data
-
getProgress()
Current progress - you don't have to write
-
close()
close resource
- In the Driver, through job Setinputformatclass() to specify the custom InputFormat class
-
(2) Code practice
- MyInputFormat.java
/** * Custom InputFormat * @Author: ZYD * @Date: 2021/8/7 11:54 am */ public class MyInputFormat extends FileInputFormat<Text, Text> { /** * If you are not satisfied with the default slicing mechanism, you can override the getSplits() method to specify the slicing rules. If you are satisfied, you don't need to rewrite it * At this point, FileInputFormat calls its default slicing mechanism */ /*@Override public List<InputSplit> getSplits(JobContext job) throws IOException { return super.getSplits(job); }*/ /** * Define how to implement the key value conversion rule for the slice data we read * @param inputSplit------A slice * @param taskAttemptContext-----Context object * @return * @throws IOException * @throws InterruptedException */ @Override public RecordReader<Text, Text> createRecordReader(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException { MyRecordReader myRecordReader = new MyRecordReader(); myRecordReader.initialize(inputSplit, taskAttemptContext); return myRecordReader; } } - MyRecordReader.java
/** * The user-defined core method of converting the bottom input data into key value * @Author: ZYD * @Date: 2021/8/7 12:02 PM */ public class MyRecordReader extends RecordReader<Text, Text> { /** * A property is created. This object is also a RecordReader, but its key is the offset and value is the data of each row * You can use this method to read each row of data in the slice */ LineRecordReader lineRecordReader = new LineRecordReader(); Text key = new Text(); Text value = new Text(); String split = "\t"; /** * Initialization method: you need to import a slice and a context object before cutting: in the createRecordReader() method in MyInputFormat, call this method to complete the incoming. * @param inputSplit: Slice object * @param taskAttemptContext: Slice object data * @throws IOException-IO Flow anomaly * @throws InterruptedException- */ @Override public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException { lineRecordReader.initialize(inputSplit, taskAttemptContext); } /** * Core method - used to determine what value key is and what value value value is * A slice has a lot of data. If it is read by row, this method will be called for each row to judge whether there is data in the next row * If yes, return true to continue reading; If not, false is returned, and the current slice data reading is completed * @return boolean * @throws IOException-IO Flow anomaly * @throws InterruptedException- */ @Override public boolean nextKeyValue() throws IOException, InterruptedException { Text line = null; if (lineRecordReader.nextKeyValue()) { line = lineRecordReader.getCurrentValue(); String[] underSplit = line.toString().split(this.split); key.set(underSplit[0]); int length = underSplit[0].length(); String substring = line.toString().substring(length); value.set(substring); } return line != null; } /** * Get the key value in the currently read primary data * @return key * @throws IOException- * @throws InterruptedException- */ @Override public Text getCurrentKey() throws IOException, InterruptedException { return key; } /** * Read the value of each read data * @return value * @throws IOException * @throws InterruptedException */ @Override public Text getCurrentValue() throws IOException, InterruptedException { return value; } /** * Current progress - you don't have to write * @return float * @throws IOException- * @throws InterruptedException- */ @Override public float getProgress() throws IOException, InterruptedException { return 0; } /** * close resource * @throws IOException- */ @Override public void close() throws IOException { } }