1, Overview
1.1MapReduce definition
MapReduce is a programming framework for distributed computing programs and the core framework for users to develop "hadoop based data analysis applications".
The core function of MapReduce is to integrate the business logic code written by the user and its own default components into a complete distributed computing program, which runs concurrently on a Hadoop cluster.
1.2MapReduce advantages and disadvantages
advantage
1.MapReduce is easy to program
By simply implementing some interfaces, it can complete a distributed program, which can be distributed to a large number of cheap PC machines. As like as two peas, you write a distributed program, which is exactly the same as writing a simple serial program. This feature makes MapReduce programming very popular.
2. Good scalability
When your computing resources cannot be met, you can simply add machines to expand its computing power.
3. High fault tolerance
The original intention of MapReduce design is to enable the program to be deployed on cheap PC machines, which requires it to have high fault tolerance. For example, if one of the machines hangs, it can transfer the above computing tasks to another node to run, so that the task will not fail. Moreover, this process does not require manual participation, but is completely completed by Hadoop.
4. It is suitable for offline processing of massive data above PB level
It can realize the concurrent work of thousands of server clusters and provide data processing capacity.
shortcoming
1. Not good at real-time calculation
MapReduce cannot return results in milliseconds like MySql.
2. Not good at flow calculation
The input data of streaming computing is dynamic, while the input data set of MapReduce is static and cannot change dynamically. This is because the design characteristics of MapReduce determine that the data source must be static.
3. Not good at DAG calculation
Multiple applications have dependencies, and the input of the latter application is the output of the previous one. In this case, MapReduce is not impossible, but after use, the output results of each MapReduce job will be written to the disk, resulting in a large number of disk IO and very low performance.
1.3 core idea of MapReduce
- Distributed computing programs often need to be divided into at least two stages.
- The MapTask concurrent instances in the first stage run completely in parallel and irrelevant to each other.
- The ReduceTask concurrent instances in the second stage are irrelevant, but their data depends on the output of all MapTask concurrent instances in the previous stage.
- The MapReduce programming model can only contain one Map phase and one Reduce phase. If the user's business logic is very complex, it can only run multiple MapReduce programs in series.
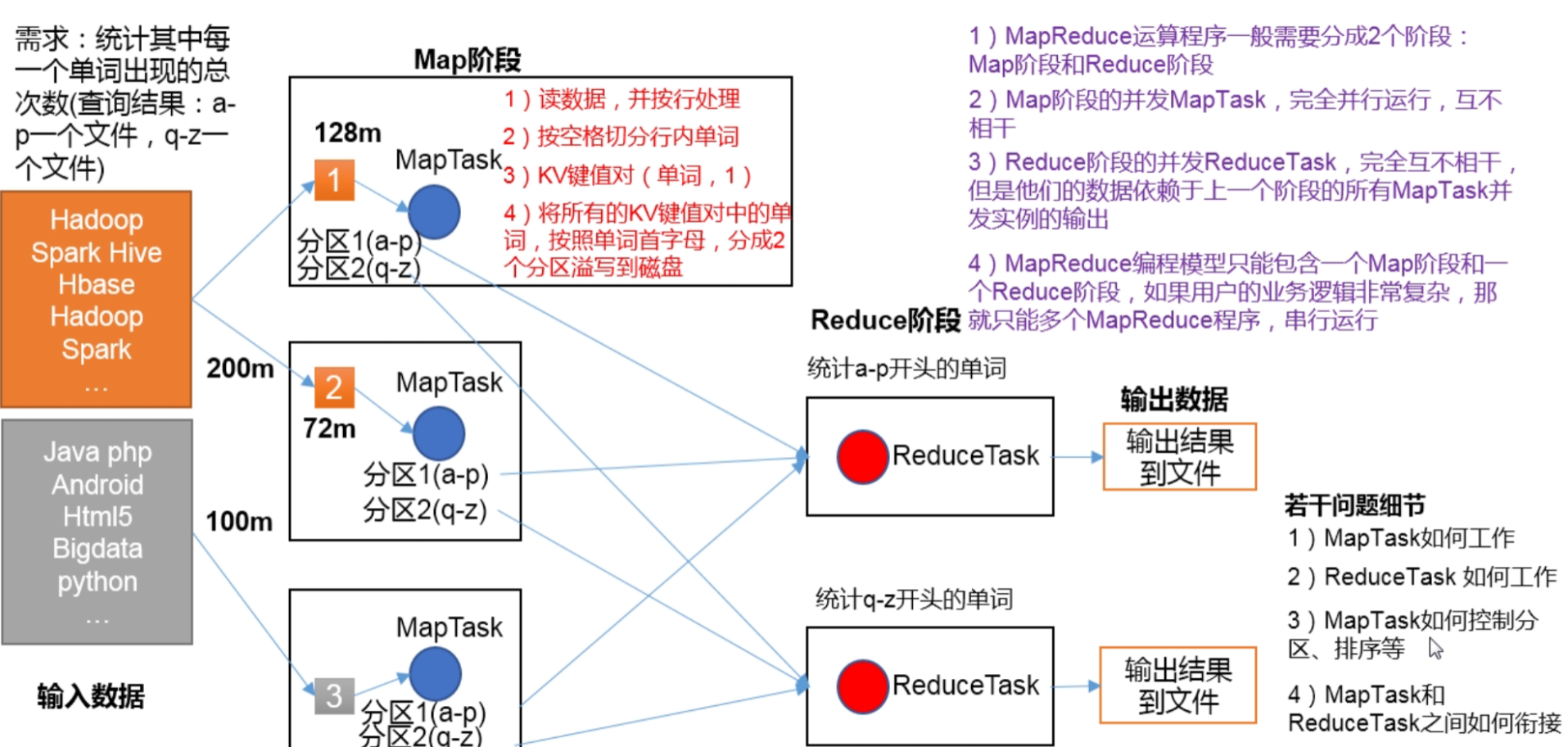
1.4 MapReduce process
A complete MapReduce program has three types of instance processes during distributed operation:
- MrAppMaster: responsible for process scheduling and state coordination of the whole program.
- MapTask: responsible for the entire data processing process in the Map phase.
- ReduceTask: responsible for the entire data processing process in the Reduce phase.
1.5 MapReduce programming
Common data serialization types
| Java type | Hadoop Writable type |
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| String | Text |
| map | MapWritable |
| array | ArrayWritable |
The program written by the user is divided into three parts: Mapper, Reducer and Driver.
1.Mapper stage
(1) User defined Mapper inherits its own parent class
(2) Mapper's input data is in the form of KV pairs (the type of KV can be customized)
(3) The business logic in Mapper is written in the map () method
(4) Mapper's output data is in the form of KV pairs (the type of KV can be customized)
(5) The map() method (MapTask process) is called once for each
2.Reducer phase
(1) User defined Reduce should inherit its own parent class
(2) The input data type of Reducer corresponds to the output data type of Mapper, which is also KV
(3) The business logic of the Reducer is written in the reduce() method
(4) The ReduceTask process calls the reduce() method once for each group of the same k
3.Driver stage
The client equivalent to the YARN cluster is used to submit our entire program to the YARN cluster. The submitted job object encapsulates the relevant running parameters of the MapReduce program.
II WordCount case practice
Requirement: count the total number of occurrences of each word in a given text file
Demand analysis: according to MapReduce programming specification, Mapper, Reducer and Driver are written respectively, as shown in the figure

Practical steps:
Create maven project
pom file
<dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.11.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.3.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.3.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>3.3.1</version> </dependency>
1.Map class
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author JLoong
* @date 2022/1/6 21:06
*/
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException {
//1. Get a row
String line = value.toString();
//2. Cutting
String[] words =line.split(" ");
//3. Output
for (String word:words) {
k.set(word);
context.write(k,v);
}
}
}
2.Reduce class
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author JLoong
* @date 2022/1/6 21:14
*/
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//1. Cumulative summation
sum=0;
for (IntWritable count:values){
sum+=count.get();
}
//2. Output
v.set(sum);
context.write(key,v);
}
}
3.Driver class
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author JLoong
* @date 2022/1/7 15:26
*/
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1. Obtain configuration information and encapsulate tasks
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
//2. Set jar loading path
job.setJarByClass(WordCountDriver.class);
//3. Set map and reduce classes
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//4. Set map output
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5. Set the final output kv type
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6. Set input and output paths
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//7. Submission
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}Set program parameters

Operation results

4. Make a jar package and run it on the cluster
Problem: running is super slow and stuck in Running job:
Slightly changed the yarn site The XML parameters are as follows: the speed is greatly improved by adding these new ones, which indicates that the slow speed is caused by insufficient allocated memory and cpu.
III Hadoop serialization
3.1 general
What is serialization?
Serialization is to convert objects in memory into byte sequences (or other data transfer protocols) for storage to disk (persistence) and network transmission.
Deserialization is to receive byte sequence (or other data transfer protocol) or disk persistent data and convert it into an object in memory.
Why serialize?
Generally speaking, "live" objects only exist in memory and disappear after power off. Moreover, "live" objects can only be used by local processes and cannot be sent to another computer on the network. However, serialization can store "live" objects and send "live" objects to remote computers.
Why not use Java serialization?
Java serialization is a heavyweight Serializable framework. After an object is serialized, it will carry a lot of additional information (various verification information, Header, inheritance system, etc.), which is not convenient for efficient transmission in the network. Therefore, Hadoop has developed its own serialization mechanism (Writable).
Hadoop serialization features:
(1) Compact: efficient use of storage space.
(2) Fast: the extra cost of reading and writing data is small.
(3) Scalability: upgrade with the upgrade of communication protocol.
(4) Interoperability: support multi language interaction.
3.2 implementing serialization interface (Writable) with custom bean object
The basic serialization types commonly used in enterprise development can not meet all requirements. For example, if a bean object is passed within the Hadoop framework, the object needs to implement the serialization interface.
Steps to implement bean object serialization:
- The Writable interface must be implemented
- When deserializing, the null parameter constructor needs to be called by reflection, so there must be an empty parameter construct
- Override serialization method
- Override deserialization method
- Note that the order of deserialization is exactly the same as that of serialization
- To display the results in the file, you need to rewrite toString(), which can be separated by "\ t" for subsequent use.
- If you need to transfer the customized bean s in the key, you also need to implement the Comparable interface, because the shuffle process in the MapReduce box requires that the keys must be sorted.
3.3 serialization case practice
1. Demand:
Count the total uplink traffic, downlink traffic and total traffic consumed by each mobile phone number
Input data format
7 13560436666 120.196.100.99 1116 954 200 id phone number network ip Uplink traffic Downlink traffic Network status code
Expected output data format:
13560436666 1116 954 2070 phone number Uplink traffic Total downstream flow
2. Demand analysis

3. Write MapReduce program
3.1 bean object
/**
* @author JLoong
* @date 2022/1/8 17:34
*/
public class FlowBean implements Writable {
//1. Implement Writable interface
private long upFlow;
private long downFlow;
private long sumFlow;
//2 when deserializing, you need to call the null parameter constructor by reflection
public FlowBean() {
}
public FlowBean(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
//3. Write serialization method
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
dataOutput.writeLong(sumFlow);
}
//4. Write deserialization method
//5. The sequence should be consistent with the write serialization method
@Override
public void readFields(DataInput dataInput) throws IOException {
this.upFlow = dataInput.readLong();
this.downFlow = dataInput.readLong();
this.sumFlow = dataInput.readLong();
}
//6.toString method
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
public void set(long downFlow, long upFlow) {
this.downFlow = downFlow;
this.upFlow = upFlow;
sumFlow = downFlow + upFlow;
}
}3.2 Mapper class
/**
* @author JLoong
* @date 2022/1/8 18:00
*/
public class FlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
FlowBean v = new FlowBean();
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1. Get a row
String line = value.toString();
//2. Cutting field
String[] fields = line.split("\t");
//3. Encapsulation object
//Take out the mobile phone number
String phoneNum = fields[1];
//Take out the uplink and downlink traffic
long upFlow = Long.parseLong(fields[fields.length - 3]);
long downFlow = Long.parseLong(fields[fields.length - 2]);
k.set(phoneNum);
v.set(downFlow, upFlow);
//4. Write
context.write(k, v);
}
}3.3 Reducer class
/**
* @author JLoong
* @date 2022/1/8 18:24
*/
public class FlowCountReducer extends Reducer<Text,FlowBean,Text,FlowBean> {
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
long sumUpFlow =0;
long sumDownFlow =0;
//1. Traverse each bean and accumulate traffic
for(FlowBean flowBean:values){
sumUpFlow +=flowBean.getUpFlow();
sumDownFlow+=flowBean.getDownFlow();
}
//2. Sub packaging object
FlowBean resultBean = new FlowBean(sumUpFlow,sumDownFlow);
//3. Write object
context.write(key,resultBean);
}
}3.4 Driver class
/**
* @author JLoong
* @date 2022/1/8 18:30
*/
public class FlowCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
args = new String[]{"d:/work/input", "d:/output"};
//1. Get job instance
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
//2. Set jar loading path
job.setJarByClass(FlowCountDriver.class);
//3. Set Map class and Reduce class
job.setMapperClass(FlowCountMapper.class);
job.setReducerClass(FlowCountReducer.class);
//4. Set Map output
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
//5. Set the final output kv type
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//6. Set input and output paths
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//7. Submission
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}