Reference link 1
Reference link 2
The code comes from link 2 and has been modified by yourself. The level is limited. I hope to point out some mistakes.
hadoop3. 2.1 write code under centos 7 window, package and submit it to Hadoop cluster on centos for operation.
ideas:
put the picture on hdfs, and then write the path of each image to be processed in a TXT text. When running the MR program, pass in the txt file as input, and find the image to be processed through the image path in the file to achieve the purpose of processing the image.
1, Picture path txt file, put it on hdfs. Note: the mouse cursor at the end of the file must be immediately followed by the last character, and line breaks are not allowed!!! Otherwise, it will report an error!!!
Txt file path: / SST / MR / input / imgpath / srcimgpathcolor txt
hdfs://Host IP of your namenode: 8020 / SST / MR / image / srcimgcolor / 1 jpg hdfs://Host IP of your namenode: 8020 / SST / MR / image / srcimgcolor / 2 jpg hdfs://Host IP of your namenode: 8020 / SST / MR / image / srcimgcolor / 3 jpg
2, Code
the idea of the code is to convert the image read through the path into SequenceFile, and then read the sequence file to operate the image.
1. Convert the read pictures into sequence files
Paste code directly:
package com.createSequenceFile;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.net.URI;
import java.net.URISyntaxException;
/**
* So our map / reduce job will include only a map that will read one file at a time and write it to a sequence file by using SequenceFileOutputFormat.
* It uses a FileSystem object in order to open the HDFS file and FSDataInputStream in order to read from it.
* The byte array is being written to the context as a bytewritable.
* Since the output format of the job is SequenceFileOutputFormat class, the output of the map is being written to a sequence file.
* <p>
* <p>
* Target:generate sequence file (key:filename value:BytesWritable)
*/
public class BinaryFilesToHadoopSequenceFile {
//private static Logger logger = Logger.getLogger(BinaryFilesToHadoopSequenceFile.class);
private static Configuration conf = new Configuration();
private static URI urifs;
private static FileSystem fs;
private static OutputStream out;
private static String hdfsUri = "hdfs://Host IP of your namenode: 8020 ";
public static class BinaryFilesToHadoopSequenceFileMapper extends Mapper<Object, Text, Text, BytesWritable> {
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//Get hdfs instance
try {
urifs = new URI(hdfsUri);
} catch (URISyntaxException e) {
e.printStackTrace();
}
try {
fs = FileSystem.get(urifs, conf, "root");//root: the user who gets the file system instance
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
// logger.info("map method called..");
//Read the photos on HDFS through the URI in the file
String uri = value.toString();//Get picture URI
FSDataInputStream in = null;
try {
in = fs.open(new Path(uri));
ByteArrayOutputStream bout = new ByteArrayOutputStream();
byte[] buffer = new byte[480 * 640];//Byte array for storing pictures
while (in.read(buffer, 0, buffer.length) >= 0) {
bout.write(buffer);
}
context.write(value, new BytesWritable(bout.toByteArray()));//The key output from context is the path of the image, and the value is imagebytes
} finally {
IOUtils.closeStream(in);
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: BinaryFilesToHadoopSequenceFile <in Path for url file> <out pat for sequence file>");
System.exit(2);
}
Job job = new Job(conf, "BinaryFilesToHadoopSequenceFile");
job.setJarByClass(BinaryFilesToHadoopSequenceFile.class);
job.setMapperClass(BinaryFilesToHadoopSequenceFileMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);//Set the output file format to SequenceFile
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Running program:
Package and submit the code to hadoop cluster for operation.
ImageProj-1.0-SNAPSHOT.jar: the jar package of the project packaged from the ide, and upload it to linux. The command is entered under the path where the jar package is located. Package by using Maven shade plugin in pom and specify the main class BinaryFilesToHadoopSequenceFile.
/sst/mr/input/imgpath/srcimgpathcolor.txt: the path of the image file on dfs (input path)
/sst/mr/result_1: Path to the generated sequence file (output path)
Note: result_1. The file cannot exist in advance, otherwise an error will be reported!!!
hadoop jar ImageProj-1.0-SNAPSHOT.jar /sst/mr/input/imgpath/srcimgpathcolor.txt /sst/mr/result_1
Operation results:
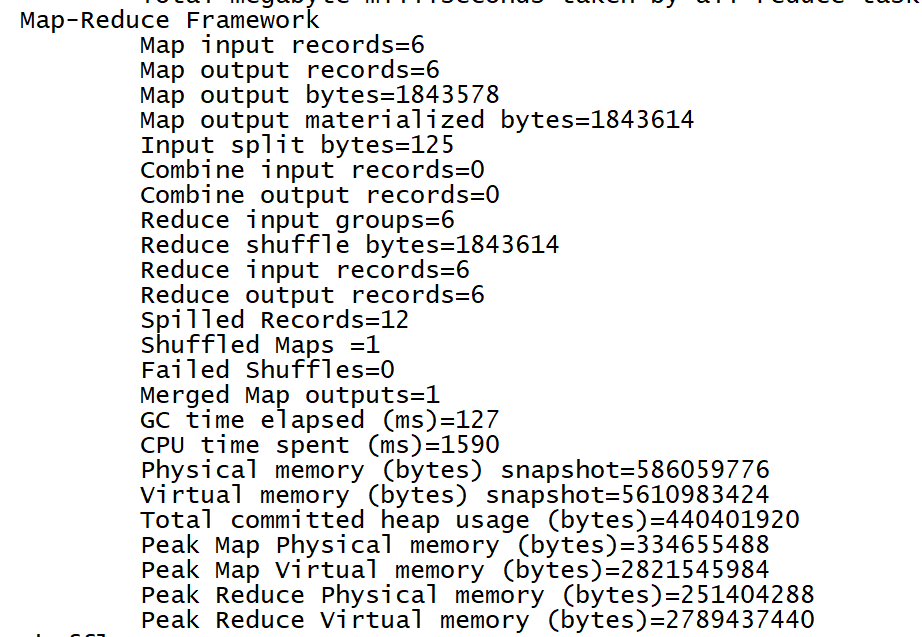
Execute the following command to see the output file:
hdfs dfs -ls /sst/mr/result_1

part-r-00000 is the result we need.
2. Read the picture bytes from the sequence file, add watermark to the picture, and then save the picture to hdfs.
code:
package com.readsuquencefile;
import com.utils.ChangeImgFormt;
import com.utils.ImageUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.io.OutputStream;
import java.net.URI;
import java.net.URISyntaxException;
public class ReadeSequence2Img {
private static Configuration conf = new Configuration();
private static URI uri;
private static FileSystem fs;
private static OutputStream out;
private static String hdfsUri = "hdfs://your namenode IP:8020";
//key of map input: path of picture value: byte array of picture (read from sequence file)
public static class Sequence2ImgMapper extends Mapper<Text, BytesWritable, Text, NullWritable> {
@Override
protected void setup(Context context) throws IOException{
//Get FileSystem operation instance
try {
uri = new URI(hdfsUri);
} catch (URISyntaxException e) {
e.printStackTrace();
}
try {
fs = FileSystem.get(uri, conf, "root");//root: the user who gets the file system instance
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
protected void map(Text key, BytesWritable value, Context context) throws IOException, InterruptedException {
//Get picture byte stream
byte[] b = value.getBytes();
//Add a text watermark to each picture
BufferedImage srcBuff = ChangeImgFormt.bytes2bufImg(b);
BufferedImage waterBuff = ImageUtils.waterMarkImage(srcBuff, "let me down");
byte[] byteWater = ChangeImgFormt.bufImg2Bytes(waterBuff);
//Get the name of the currently processed picture through the picture path
String imguri = key.toString();
String imgname = imguri.substring(imguri.lastIndexOf("/") + 1, imguri.lastIndexOf("."));
//Save the picture to hdfs in jpg format
String file = hdfsUri + "/img3/" + imgname + "_result" + ".jpg";
out = fs.create(new Path(file));
out.write(byteWater, 0, byteWater.length);
out.close();
//map output: storage path of processed pictures
context.write(new Text(file), NullWritable.get());
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
conf = new Configuration();
Job job = Job.getInstance();
job.setJarByClass(Sequence2ImgMapper.class);
job.setInputFormatClass(SequenceFileInputFormat.class);//The input file of map is a SequenceFile file
job.setMapperClass(Sequence2ImgMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Running program:
ImageProj-1.0-SNAPSHOT.jar: the main class is different from the jar package in the previous step. The main class in the jar package is ReadeSequence2Img, which is packaged and specified through Maven shade plugin.
/sst/mr/result_1/part-r-00000: the path of the order file generated in the previous step
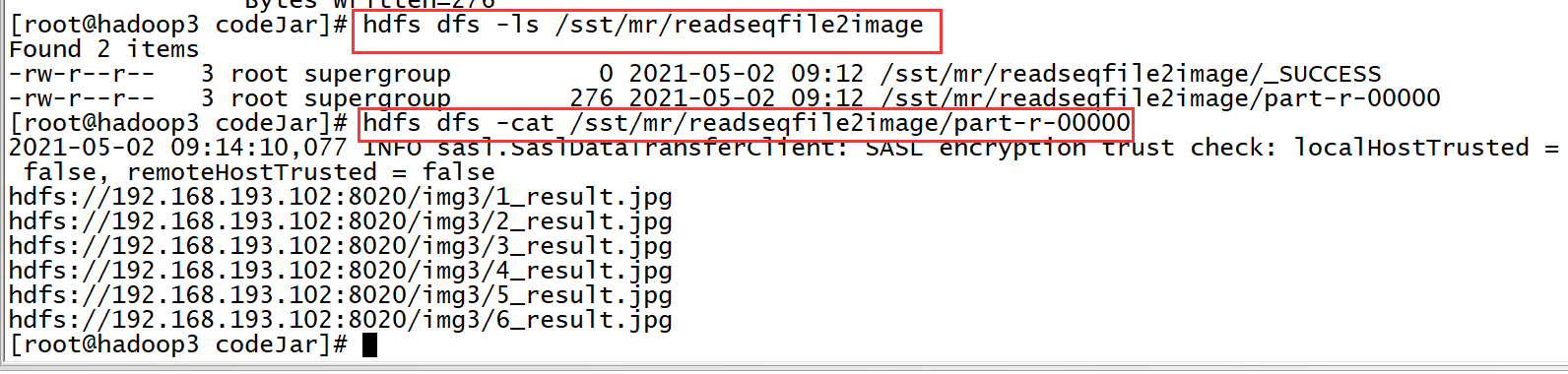
/sst/mr/readseqfile2image: output file. (the path of processed pictures is stored)
hadoop jar ImageProj-1.0-SNAPSHOT.jar /sst/mr/result_1/part-r-00000 /sst/mr/readseqfile2image
Operation results:
linux:

3,