catalogue
1, Problem description
Merge multiple input files, eliminate the duplicate contents, and output the duplicated contents to one file.
Main idea: according to the process characteristics of reduce, the input value set will be automatically calculated according to the key, and the data will be output to reduce as a key. No matter how many times the data appears, the key can only be output once in the final result of reduce.
1. Each data in the instance represents a line of content in the input file. The map phase adopts the default job input mode of Hadoop. Set value to key and output directly. The key of the map output data is data, and the value is set to null
2. In the MapReduce process, the map output < key, value > is aggregated into < key, value list > through the shuffle process and then handed over to reduce
3. In the reduce phase, no matter how many values each key has, it directly copies the input key into the output key and outputs it (the value in the output is set to null). If a row is used as the key and the value is empty, there will still be only one key in "summary" during reduce, that is, one row and the value is still empty. So the weight is removed.
2, Specific code
package Test;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class FileMerge {
//Custom Mapper class
public static class MyMapper extends Mapper<Object, Text, Text, Text>{
// Create a new Text type object to store accounts
private Text text = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
text = value;
context.write(text, new Text(""));
}
}
// Custom Reducer class
public static class MyReducer extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// New configuration class object
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf,args)).getRemainingArgs();
if(otherArgs.length<2){
System.err.println("Usage:CrossTest <in> [..<in>] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf,"Merge and de duplicate the data in the two files");
job.setJarByClass(FileMerge.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
for(int i = 0; i <otherArgs.length - 1;i++){
FileInputFormat.addInputPath(job,new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,new Path(otherArgs[otherArgs.length -1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}3, Specific operation
① Package the written java file into a jar package and upload it to the virtual machine. Here, eclipse is used as an example
Right click the written item and click export
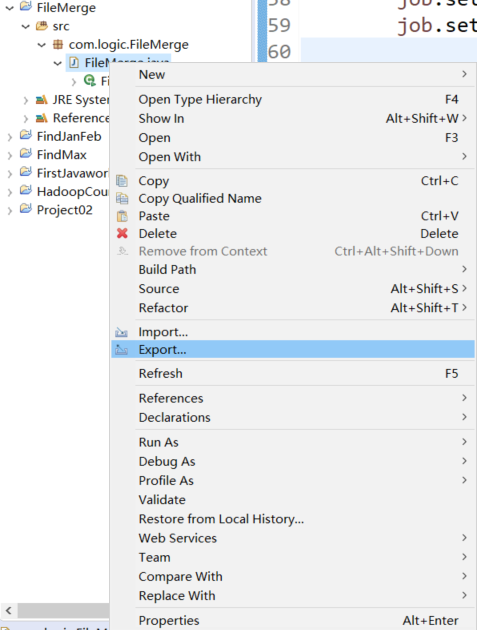
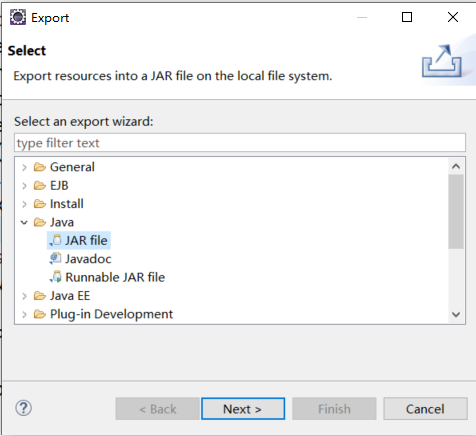
Find Java, double-click to open it, select JAR file, and click next
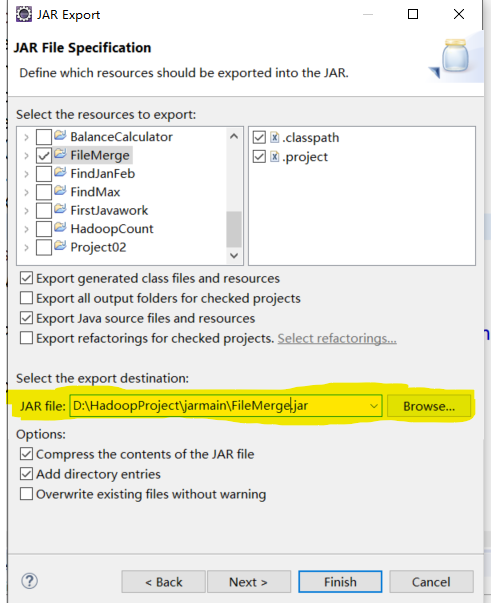
Check the file to be marked as a jar package, check Export generated class files and resources and Export Java source files and resources, check the Comepress the contents of the JAR file and add directory entries in Options, and select the path to store the jar package (highlighted in yellow, and the last FileMerge.jar is the jar package name). Click finish to generate the jar package
② Put the two files to be de duplicated into the same folder, upload them to the virtual machine and upload them to the hdfs directory
③ Execute command
hadoop jar FileMerge.jar /user/root/xyz /user/root/zz
Among them, FileMerge.jar is changed according to the jar package name you typed, / user/root/xyz is the path of the uploaded folder that needs to be removed, and / user/root/zz is the directory to be output by hdfs.
④ Find and view the results in the hdfs directory system