summary
MR distributed computing framework and application scenarios have a common feature: tasks can be decomposed into independent subproblems.
Therefore, the distributed programming method of MR programming model, 5 steps:
- Iteration: traverse the input data and parse it into kv pairs
- Mapping: mapping input kv pairs to other kv pairs
- Grouping: grouping intermediate data according to key
- Reduction: reduce data in groups
- Iteration: the resulting kv pair is saved to the output file

Basic concepts of MR API
- Serialization: two main functions, permanent storage and interprocess communication. The key and value in the input and output data should be serializable. In Hadoop MapReduce, the way to make a Java object serializable is to make its corresponding class implement the Writable interface, but the key is the key for data sorting, so the WritableComparable interface should also be implemented.
- Reporter parameter: used by the application to report progress, set status message and update counter.
- Callback mechanism: a common design pattern that exposes a function in the workflow to external users according to the agreed interface, provides data or requires external users to provide data. For example, MapReduce exposes the interface Mapper to the user. After the user implements Mapper, the MapReduce runtime environment will call it.
Design and implementation of InputFormat interface
Two functions:
- Data segmentation: divide the data into multiple splits to determine the number of map tasks and the corresponding splits
- Provide input data for Mapper: give a split and parse it into kv pairs
public interface InputFormat<K, V> {
/**
* Logically split the set of input files for the job.
*
* <p>Each {@link InputSplit} is then assigned to an individual {@link Mapper}
* for processing.</p>
*
* <p><i>Note</i>: The split is a <i>logical</i> split of the inputs and the
* input files are not physically split into chunks. For e.g. a split could
* be <i><input-file-path, start, offset></i> tuple.
*
* @param job job configuration.
* @param numSplits the desired number of splits, a hint.
* @return an array of {@link InputSplit}s for the job.
*/
InputSplit[] getSplits(JobConf job, int numSplits) throws IOException;
/**
* Get the {@link RecordReader} for the given {@link InputSplit}.
*
* <p>It is the responsibility of the <code>RecordReader</code> to respect
* record boundaries while processing the logical split to present a
* record-oriented view to the individual task.</p>
*
* @param split the {@link InputSplit}
* @param job the job that this split belongs to
* @return a {@link RecordReader}
*/
RecordReader<K, V> getRecordReader(InputSplit split,
JobConf job,
Reporter reporter) throws IOException;
}
The getSplits method completes the function of data slicing, and divides the input data into numSplits and inputsplits, which have two characteristics (logical slicing and serializability).
The getRecordReader method returns a RecordReader object that parses InputSplit into several kv pairs. During the execution of the Map Task, the MapReduce framework continuously calls the methods in the RecordReader object, iteratively obtains the kv pairs and gives them to the map() function for processing
Various implementations of InputFormat
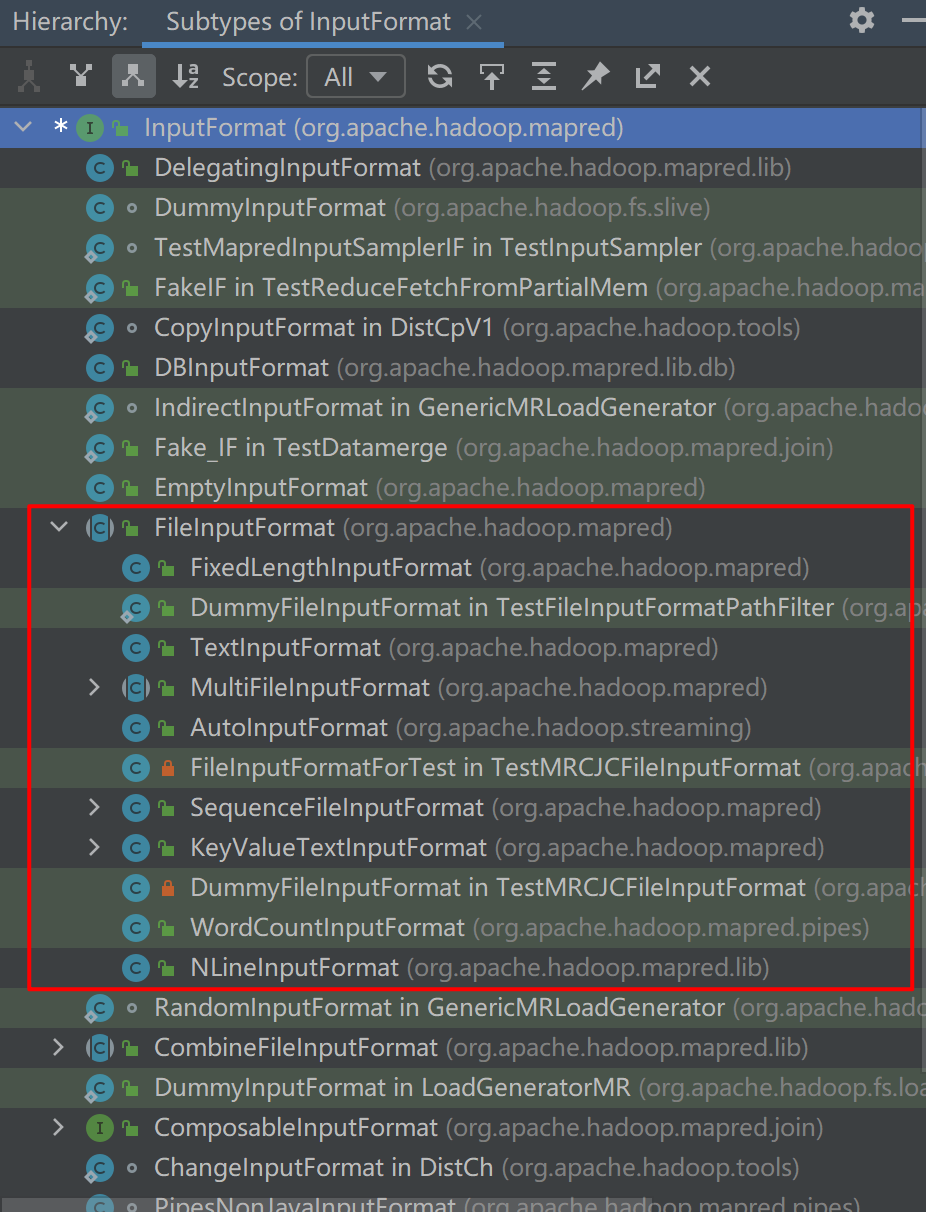
Discuss InputFormat for files. The implemented base classes are FileInputFormat, deriving TextInputFormat, KeyValueInputFormat, etc. (as shown in the figure above).
The design idea of file based InputFormat system is that the public base class FileInputFormat uses a unified method to segment various input files, and each derived InputFormat provides its own mechanism to further analyze InputSplit.
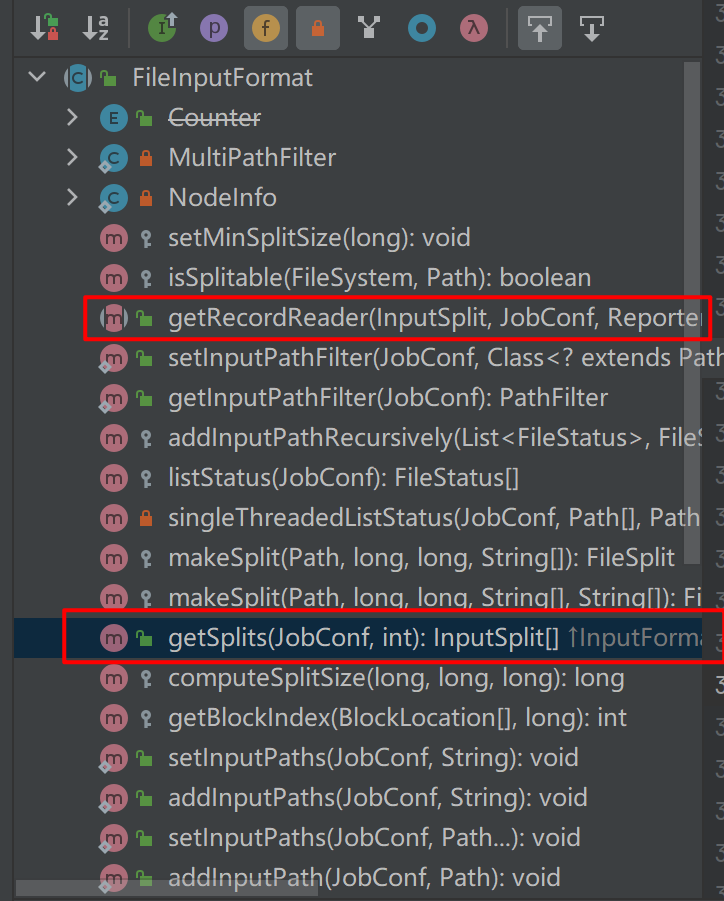
Implementation of FileInputFormat
The most important function is to provide a unified getSplits function for various inputformats. The two core algorithms in the implementation of this function are file segmentation algorithm and host selection algorithm.
File segmentation algorithm
It is used to determine the number of inputsplits and the corresponding data segments of each InputSplit. FileInputFormat generates inputsplits by dividing files. For each file, the corresponding number of inputsplits is determined by three attributes:
- goalSize: calculated according to the InputSplit expected by the user, i.e. total/numSplits
- minSize: the minimum value of InputSplit, which is determined by the configuration parameter mapred.min.split.size. The default value is 1

- blockSize: the block size of the file stored in hdfs. The default is 64MB
These three parameters determine the final size of InputSplit and the calculation formula


splitSize determines that the files are divided into inputsplits of splitSize in turn. Finally, if there is less than one splitSize left, it becomes an inputsplit alone.
host selection algorithm
This step is to determine the metadata information of each inputsplit, which is composed of four parts < file, start, length, hosts > representing the file, starting location, length and host list of inputsplit respectively. The difficulty lies in how to determine the host list, which will directly affect the task locality in the running process.
Because the blocks corresponding to a large file may spread throughout the hadoop cluster, and the division algorithm of inputplit may lead to one inputsplit corresponding to multiple blocks. These blocks may be located on different nodes, making hadoop impossible to achieve complete data locality. Therefore, hadoop divides data locality into three levels according to cost: node locality, rack locality data center locality: during task scheduling, the locality of the three nodes will be considered in turn, giving priority to idle resources to process the data on this node. If there is no processable data on the node, the data on the same rack will be processed. In the worst case, the data on other racks will be processed.
Considering the efficiency of task scheduling, usually all nodes are not added to the host list of inputSplit, but the first few nodes with the largest total amount of inputSplit data are selected as the main credentials to judge whether the task is local during task scheduling. Therefore, FileInputFormat implements a heuristic algorithm
Firstly, sort the rack according to the amount of data contained in the rack, then sort the nodes according to the amount of data contained in each node within the rack, and finally take the host of the first n nodes as the host list of inputSplit, and N is the number of block copies. In this way, when the Task scheduler schedules a Task, as long as the Task is adjusted to the truncation in the host list, it is considered that the Task meets the locality.
Therefore, based on this principle, in order to improve the data locality of Map Task, try to make the InputSplit size the same as the block size.
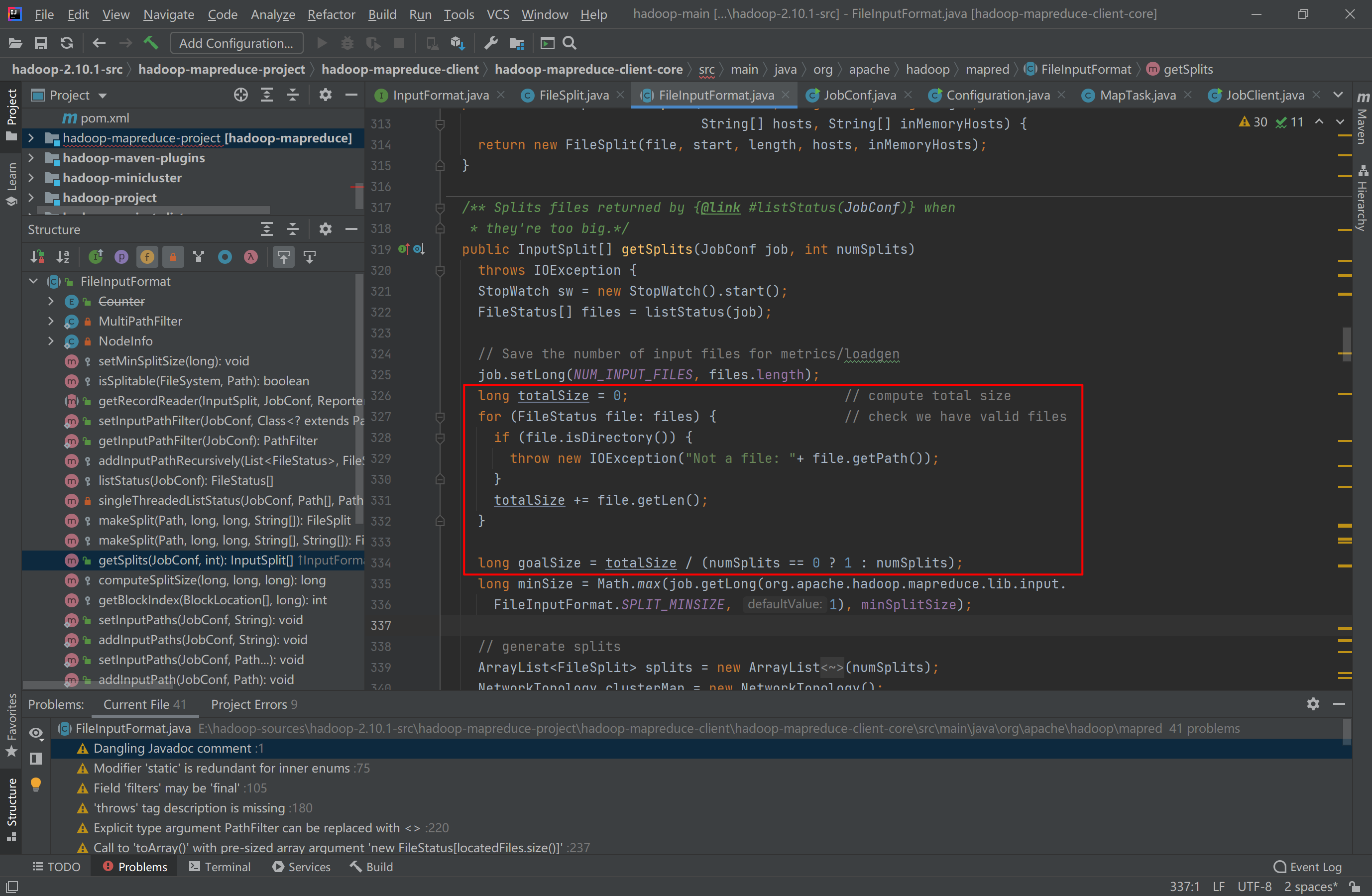
Enter the FileInputFormat function and have a look
/** Splits files returned by {@link #listStatus(JobConf)} when
* they're too big.*/
public InputSplit[] getSplits(JobConf job, int numSplits)
throws IOException {
StopWatch sw = new StopWatch().start();
FileStatus[] files = listStatus(job);
// Save the number of input files for metrics/loadgen
job.setLong(NUM_INPUT_FILES, files.length);
long totalSize = 0; // compute total size
for (FileStatus file: files) { // check we have valid files
if (file.isDirectory()) {
throw new IOException("Not a file: "+ file.getPath());
}
totalSize += file.getLen();
}
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
// generate splits
ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);
NetworkTopology clusterMap = new NetworkTopology();
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
FileSystem fs = path.getFileSystem(job);
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(fs, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,
length-bytesRemaining, splitSize, clusterMap);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
splitHosts[0], splitHosts[1]));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length
- bytesRemaining, bytesRemaining, clusterMap);
splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining,
splitHosts[0], splitHosts[1]));
}
} else {
if (LOG.isDebugEnabled()) {
// Log only if the file is big enough to be splitted
if (length > Math.min(file.getBlockSize(), minSize)) {
LOG.debug("File is not splittable so no parallelization "
+ "is possible: " + file.getPath());
}
}
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,0,length,clusterMap);
splits.add(makeSplit(path, 0, length, splitHosts[0], splitHosts[1]));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits.toArray(new FileSplit[splits.size()]);
}
- The first step is to get the job file information. FileStatus represents the file meta information on the client side, and listStatus(job) returns an array of FileStatus objects.
/** Interface that represents the client side information for a file.
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public class FileStatus implements Writable, Comparable<FileStatus> {
private Path path;
private long length;
private boolean isdir;
private short block_replication;
private long blocksize;
private long modification_time;
private long access_time;
private FsPermission permission;
private String owner;
private String group;
private Path symlink;
public FileStatus() { this(0, false, 0, 0, 0, 0, null, null, null, null); }
//There are many constructors behind, which are not intercepted. You can see that all attributes are meta information around file.
-
Then calculate the total size of all files.
-
Calculate goalsize: long goalsize = totalsize / (numsplits = = 0? 1: numsplits);
-
Calculate minSize: long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input. ORG)
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize); Determined by the configuration parameters, the default is 1. -
Then the fragment splits are officially generated, which involves the host selection algorithm
// generate splits
ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);
NetworkTopology clusterMap = new NetworkTopology(); //Network topology
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
FileSystem fs = path.getFileSystem(job);
BlockLocation[] blkLocations;
//BlockLocation represents the network location of the block, information about the host containing the copy of the block, and other block metadata (for example, the file offset, length, corruption, and so on associated with the block)
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
//If this file is an instance of the FileStatus class that contains the file block location, call the getBlockLocations function directly to get the file block location
} else {
blkLocations = fs.getFileBlockLocations(file, 0, length);
//Otherwise, use the file system to call getFileBlockLocations to get the file block location
}
if (isSplitable(fs, path)) {
long blockSize = file.getBlockSize(); //Get configuration parameters
long splitSize = computeSplitSize(goalSize, minSize, blockSize); //Calculate splitSize
/*
protected long computeSplitSize(long goalSize, long minSize,long blockSize) {
return Math.max(minSize, Math.min(goalSize, blockSize));
}
*/
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
//This should be the slot on TaskTracker
//If the file length / splitSize is greater than slot
//Then enter the host selection algorithm
//getSplitHostsAndCachedHosts this function identifies and returns the host that contributes the most to a given split. In order to calculate the contribution, the rack locality is considered to be the same as the host locality, so the host from the rack with the largest contribution takes precedence over the host on the rack with less contribution
//Sort the tracks based on their contribution to this split in getSplitHostsAndCachedHosts. At the same time, Sort the hosts in this rack based on their contribution. To put it bluntly, it is a heuristic algorithm. First, the rack is sorted according to the amount of data contained in the rack, and then the nodes are sorted according to the amount of data contained in each node within the rack,
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,
length-bytesRemaining, splitSize, clusterMap);
//Returns a two-dimensional array
/*
return new String[][] { identifyHosts(allTopos.length, racksMap),
new String[0]}; //This string[0] doesn't understand anything
*/
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
splitHosts[0], splitHosts[1]));
bytesRemaining -= splitSize;
}
//If you can't just cut it
if (bytesRemaining != 0) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length
- bytesRemaining, bytesRemaining, clusterMap);
splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining,
splitHosts[0], splitHosts[1]));
}
} else {
if (LOG.isDebugEnabled()) {
// Log only if the file is big enough to be splitted
if (length > Math.min(file.getBlockSize(), minSize)) {
LOG.debug("File is not splittable so no parallelization "
+ "is possible: " + file.getPath());
}
}
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,0,length,clusterMap);
splits.add(makeSplit(path, 0, length, splitHosts[0], splitHosts[1]));
}
} else {
//If length==0
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits.toArray(new FileSplit[splits.size()]);
}
getRecordReader function
This function implements the function similar to iterator, and resolves an InputSplit into kv pairs. Two points shall be considered in the specific implementation:
- Locate record boundary: in order to identify a complete record, some synchronization identifiers should be added between records. For TextInputFormat, there is a line break between each two records; For SequenceFileInputFormat, a fixed length synchronization string is added every few records. Through line feed and synchronous character production, it is easy to locate the starting position of a complete record. At the same time, in order to solve the problem of reading records across InputSplit, RecordReader stipulates that the first incomplete record of each InputSplit is transferred to the previous InputSplit for processing.
- Parsing kv pairs: after locating a new record, the discipline is decomposed into key and value. For TextInputFormat, the content of each line is value, and the offset of this line in the file is key.
For example, the getRecordReader function of TextInputFormat
public RecordReader<LongWritable, Text> getRecordReader(
InputSplit genericSplit, JobConf job,
Reporter reporter)
throws IOException {
reporter.setStatus(genericSplit.toString());
String delimiter = job.get("textinputformat.record.delimiter");
byte[] recordDelimiterBytes = null;
if (null != delimiter) {
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
}
return new LineRecordReader(job, (FileSplit) genericSplit,
recordDelimiterBytes);
}
Design and implementation of OutputFormat interface
package org.apache.hadoop.mapred;
import java.io.IOException;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.util.Progressable;
/**
* <code>OutputFormat</code> describes the output-specification for a
* Map-Reduce job.
*
* <p>The Map-Reduce framework relies on the <code>OutputFormat</code> of the
* job to:<p>
* <ol>
* <li>
* Validate the output-specification of the job. For e.g. check that the
* output directory doesn't already exist.
* <li>
* Provide the {@link RecordWriter} implementation to be used to write out
* the output files of the job. Output files are stored in a
* {@link FileSystem}.
* </li>
* </ol>
*
* @see RecordWriter
* @see JobConf
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public interface OutputFormat<K, V> {
/**
* Get the {@link RecordWriter} for the given job.
*
* @param ignored
* @param job configuration for the job whose output is being written.
* @param name the unique name for this part of the output.
* @param progress mechanism for reporting progress while writing to file.
* @return a {@link RecordWriter} to write the output for the job.
* @throws IOException
*/
RecordWriter<K, V> getRecordWriter(FileSystem ignored, JobConf job,
String name, Progressable progress)
throws IOException;
/**
* Check for validity of the output-specification for the job.
*
* <p>This is to validate the output specification for the job when it is
* a job is submitted. Typically checks that it does not already exist,
* throwing an exception when it already exists, so that output is not
* overwritten.</p>
*
* @param ignored
* @param job job configuration.
* @throws IOException when output should not be attempted
*/
void checkOutputSpecs(FileSystem ignored, JobConf job) throws IOException;
}
Select file output format to analyze
The base class FileOutputFormat needs to provide public functions implemented by all file based outputformats, mainly including two:
- Implement the checkOutputSpecs interface: the default function is to check whether the output directory configured by the user exists. If so, throw an exception to prevent the previous data from being overwritten.
- Processing side effect file: this file is not the final output file, but has special purposes. Typical applications are speculative tasks. In hadoop, there may be "slow" tasks ", that is, the Task that slows down the execution speed of the whole job. Therefore, in order to optimize, hadoop will start the same Task on another node. This Task is called speculative Task. The calculation result of the first Task is the processing result corresponding to this data. Therefore, in order to prevent conflicts when two tasks write data to an output file at the same time, F Ileoutputformat will create a side effect file for the data of each Task, and temporarily write the generated data to the file. After the Task is completed, it will be moved to the final directory. The specific operation will be completed by OutputCommitter.
Mapper and Reducer parsing
Mapper and Reducer encapsulate the data processing logic of the application. In order to simplify the interface, MapReduce requires that all data stored on the underlying distributed file system be interpreted in the form of key/value and handed over to the map/reduce function in Mapper/Reducer for processing to generate other key / values.
Mapper and Reducer have similar class systems. Analyze mapper.
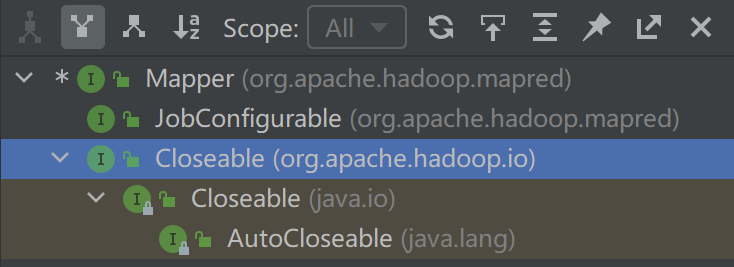
It includes initialization, Map operation and cleaning
- Initialization: Mapper inherits the JobConfigurable interface. The configure method in this interface allows Mapper to be initialized through the JobConf parameter
- Map operation: the MapReduce framework obtains key/value pairs from InputSplit through the RecordReader in InputFormat and gives them to the following map() function for processing. In addition to key and value, the parameters of map() function also include OutputCollector and Reporter parameters, which are respectively used to output results and modify Counter values.
- Clean up: Mapper inherits the Closeable interface, obtains the close method, and cleans up Mapper by implementing this method.
Design and implementation of Partitioner interface
Partition function: partition the intermediate results generated by Mapper to ensure that the same group of data is handed over to the same Reducer for processing, which will directly affect the load balancing in the Reduce phase.
It itself contains a getPartition method for implementation.
int getPartition(K2 key, V2 value, int numPartitions);
For example, hashpartition implements a partition method based on hash value
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public void configure(JobConf job) {}
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K2 key, V2 value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
Another example is TotalOrderPartitioner, which is used in data full sorting. In MR environment, full sorting uses merge sorting, Map stage local sorting and Reduce global sorting. In order to improve the performance of global sorting, MapReduce provides TotalOrderPartitioner, which can divide data into several intervals (fragments) according to size , ensure that all data in the latter interval is greater than that in the previous interval:
Step 1: data sampling
At the Client side, the segmentation points of the slices are obtained by sampling. hadoop comes with several sampling algorithms, such as IntercalSampler, RamdomSampler and SplitSampler.
For example: sampling data: b,abc,abd,bcd,abcd,efg,hii,afd,rrr,mnk; sorted: abc,abcd,abd,afd,b,bcd,efg,hii,mnk,rrr; if the number of reduce tasks is 4, the quarterpoints of sampling data are abd,bcd,mnk.
Step 2: Map phase
There are two components, mapper and Partitioner. Mapper can use IdentityMapper to directly output the input data. The Partitioner selects TotalOrderPartitioner and saves the partition points obtained in step 1 into the trie tree to quickly locate the interval where any record is located. In this way, each Map Task generates R (number of reduce task s) intervals, and the intervals are orderly.
TotalOrderPartitioner finds the corresponding Reduce Task number of each record through the trie tree (a multi fork ordered tree).
Step 3: Reduce phase
Each Reduce sorts the allocated interval data locally, and finally obtains the global sorting.