Memory of shared model for JUC learning
- Java Memory Model
- visibility
- Two stage termination mode
- Instruction rearrangement
- Summary of this chapter
- Introduction to preface
The main concern of Monitor is to ensure the atomicity of critical area code when accessing shared variables
In this chapter, we further study the visibility of shared variables among multiple threads and the ordering of multiple instructions
Java Memory Model
JMM is the Java Memory Model, which defines the abstract concepts of main memory and working memory. The bottom layer corresponds to CPU register, cache, hardware memory CPU instruction optimization, etc.
JMM is embodied in the following aspects
- Atomicity - ensures that instructions are not affected by thread context switching
- Visibility - ensures that instructions are not affected by the cpu cache
- Orderliness - ensures that instructions are not affected by cpu instruction parallel optimization
visibility
Unrequitable cycle
Let's take a look at a phenomenon. The modification of the run variable by the main thread is not visible to the t thread, which makes the t thread unable to stop:
package share;
import static java.lang.Thread.sleep;
public class Main
{
static boolean run = true;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while(run){
// ....
}
});
t.start();
sleep(1);
run = false; // The thread t does not stop as expected
}
}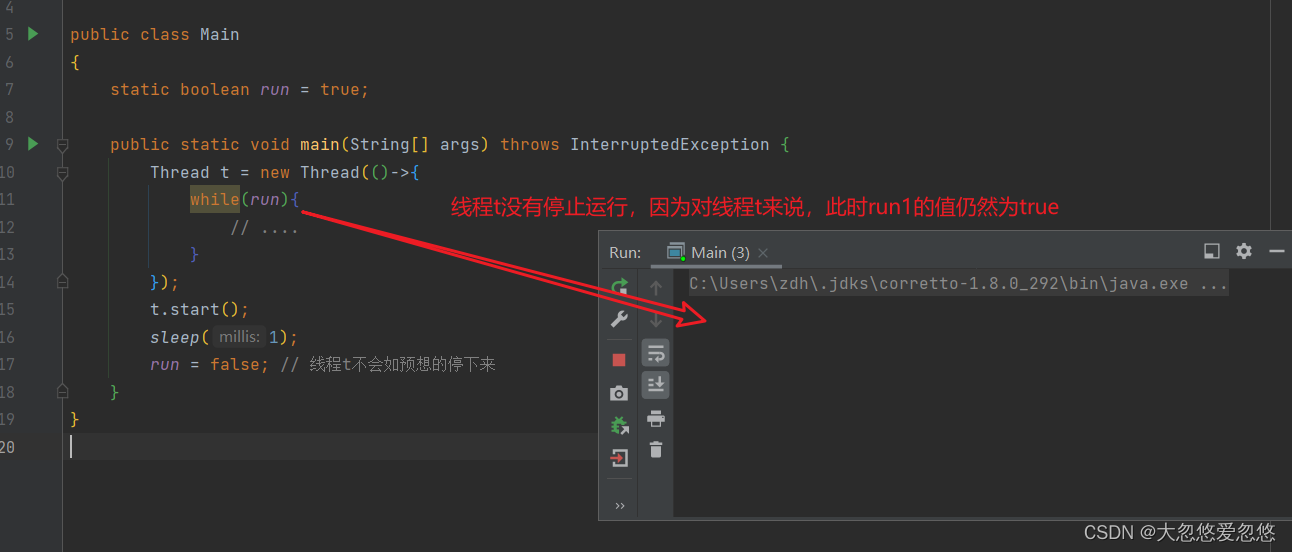
Why? Analyze:
- In the initial state, the t thread just started to read the value of run from the main memory to the working memory.
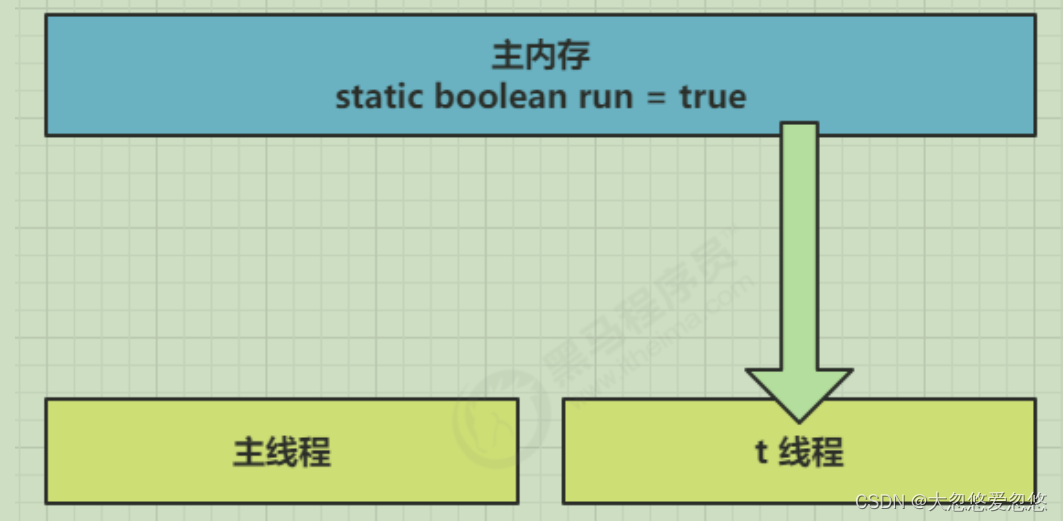
- Because the t thread frequently reads the value of run from the main memory, the JIT compiler will cache the value of run into the cache in its own working memory, Reduce access to run in main memory and improve efficiency
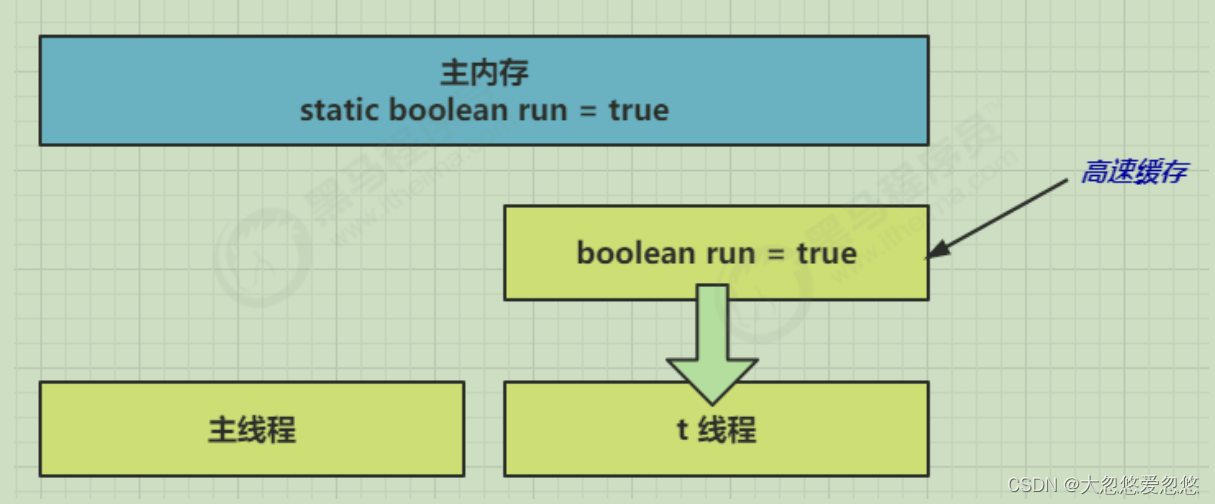
- After one second, the main thread modifies the value of run and synchronizes it to main memory, while t reads the variable from the cache in its working memory The result is always the old value
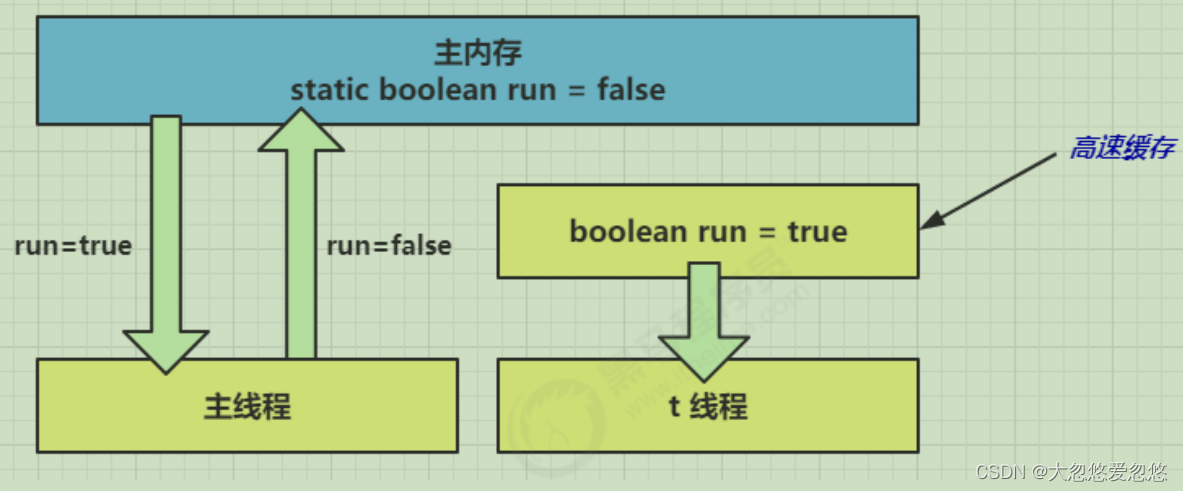
resolvent
Volatile (volatile keyword)
It can be used to modify member variables and static member variables. It can prevent threads from finding the value of variables from their own work cache and must get them from main memory Its value, thread operation and volatile variable are all direct operations on main memory
Two stage termination mode
interrupt implementation
Review interrupt to realize the two-stage termination mode: if a normal thread is interrupted, set the interrupt flag to true, and if a blocked thread is interrupted, an exception will be thrown and the interrupt flag will be cleared
package share;
/**
*interrput Implement two-phase termination mode
*/
public class Main
{
public static void main(String[] args)
{
Thread thread=new Thread(()->{
while(true)
{
//Get current thread
Thread currentThread = Thread.currentThread();
//Whether the break flag is true
if(currentThread.isInterrupted())
{
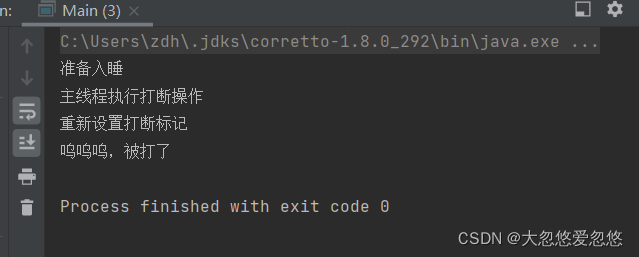
System.out.println("Woo woo, I was beaten");
break;
}
System.out.println("Get ready to sleep");
try {
Thread.sleep(3*1000);
} catch (InterruptedException e)
{
System.out.println("Reset break flag");
//Reset break flag to true
currentThread.interrupt();
}
}
},"Dahuyou 1");
thread.start();
//Main thread interrupt
try {
Thread.sleep(2*1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("The main thread performs an interrupt operation");
thread.interrupt();
}
}
volatile implementation
package share;
/**
*volatile is used to ensure the visibility of the variable among multiple threads
* In our example, the main thread changes it to true, which is visible to the t1 thread
*/
public class Main
{
private volatile static boolean stop=false;
public static void main(String[] args)
{
Thread thread=new Thread(()->{
while(true)
{
//Get current thread
Thread currentThread = Thread.currentThread();
//Whether the break flag is true
if(stop)
{
System.out.println("Woo woo, I was beaten");
break;
}
System.out.println("Get ready to sleep");
try {
Thread.sleep(3*1000);
} catch (InterruptedException e)
{
}
}
},"Dahuyou 1");
thread.start();
//Main thread interrupt
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("The main thread performs an interrupt operation");
stop=true;
thread.interrupt();
}
}
Balking in synchronous mode
definition
Balking mode is used when a thread finds that another thread or this thread has done the same thing, then this thread does not need to do it again OK, just end and return
realization
public class MonitorService {
// Used to indicate whether a thread has been started
private volatile boolean starting;
public void start() {
log.info("Attempt to start monitoring thread...");
synchronized (this) {
if (starting) {
return;
}
starting = true;
}
// Actually start the monitoring thread
}
}When the current page clicks the button several times to call start
output
[http-nio-8080-exec-1] cn.itcast.monitor.service.MonitorService - The monitoring thread has started?(false) [http-nio-8080-exec-1] cn.itcast.monitor.service.MonitorService - Monitoring thread started... [http-nio-8080-exec-2] cn.itcast.monitor.service.MonitorService - The monitoring thread has started?(true) [http-nio-8080-exec-3] cn.itcast.monitor.service.MonitorService - The monitoring thread has started?(true) [http-nio-8080-exec-4] cn.itcast.monitor.service.MonitorService - The monitoring thread has started?(true)
Here, the synchronized lock is used to prevent concurrent execution of multiple lines, resulting in instruction interleaving. volatile is used to ensure the visibility of variables to multiple threads, not to deal with the problem of concurrent interleaving
It is also often used to implement thread safe singletons
public final class Singleton {
private Singleton() {
}
private static Singleton INSTANCE = null;
public static synchronized Singleton getInstance() {
if (INSTANCE != null) {
return INSTANCE;
}
INSTANCE = new Singleton();
return INSTANCE;
}
}Compare the protective pause mode: the protective pause mode is used when one thread waits for the execution result of another thread. When the conditions are not met, the thread waits.
Instruction rearrangement
Order
The JVM can adjust the execution order of statements without affecting the correctness. Consider the following code
static int i; static int j; // Perform the following assignment operations in a thread i = ...; j = ...;
It can be seen that whether to execute i or j first will not affect the final result. Therefore, when the above code is actually executed, it can be
i = ...; j = ...;
It can also be
j = ...; i = ...;
This feature is called instruction rearrangement. Instruction rearrangement in multithreading will affect the correctness. Why is there an optimization of rearrangement instructions? Slave CPU Understand the principle of executing instructions
Principle of instruction level parallelism
noun
Clock Cycle Time
- We are familiar with the concept of dominant frequency. The Clock Cycle Time of the CPU is equal to the reciprocal of the dominant frequency, which means the smallest time unit that the CPU can recognize. For example, the Clock Cycle Time of the CPU with 4G dominant frequency is 0.25 ns. For comparison, the Cycle Time of our wall clock is 1s
- For example, it usually takes one clock cycle to run an add instruction
CPI
- Some instructions require more clock cycle time, so the average number of clock cycles of CPI (Cycles Per Instruction) instructions is introduced
IPC
- IPC (Instruction Per Clock Cycle) is the reciprocal of CPI, indicating the number of instructions that can be run in each clock cycle execution time
The CPU execution time of the program, that is, the user + system time mentioned earlier, can be expressed by the following formula
program CPU execution time = Number of instructions * CPI * Clock Cycle Time
The story of canned fish
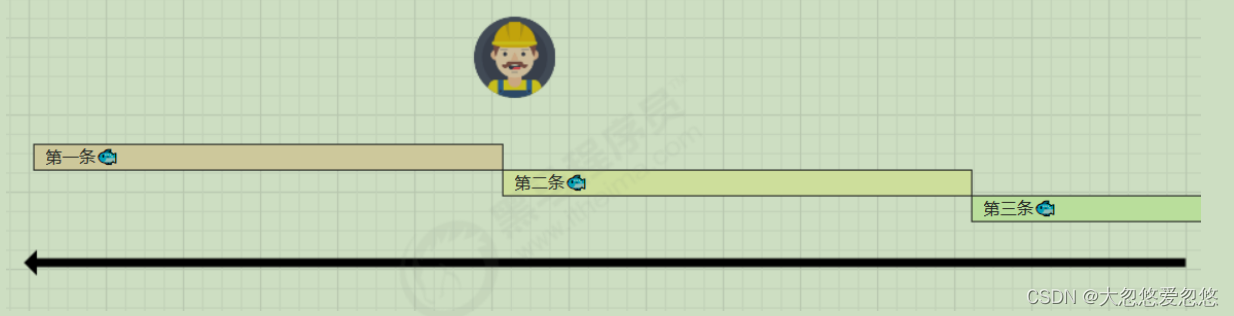
It takes 50 minutes to process a fish. Only one fish can be processed in sequence
The processing process of each canned fish can be divided into five steps:
- Descaling and cleaning for 10 minutes
- Boil and drain for 10 minutes
- Add soup for 10 minutes
- Sterilize and cook for 10 minutes
- Vacuum sealing for 10 minutes
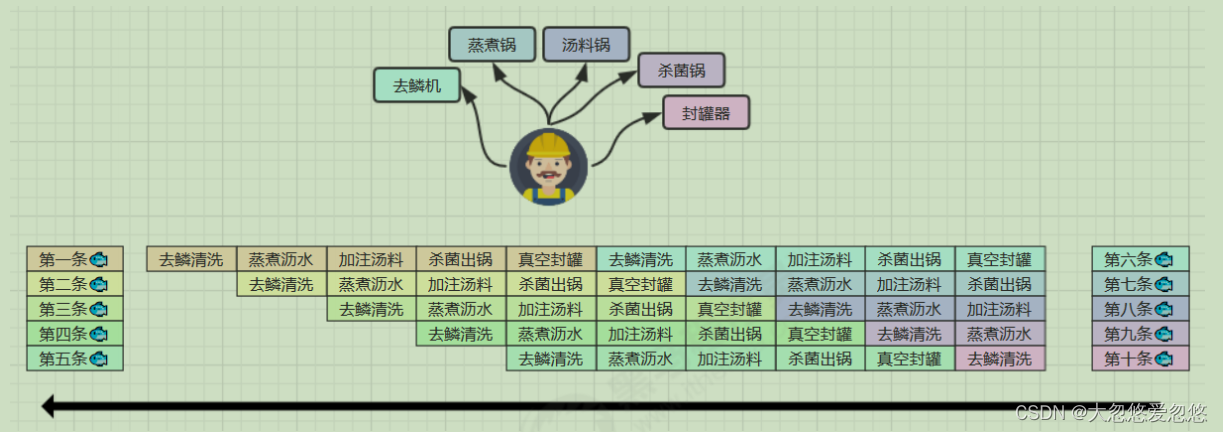
Even if there is only one worker, the ideal situation is that he can do these five things at the same time in 10 minutes, because the vacuum canning of the first fish will not Affect the sterilization of the second fish out of the pot
Instruction reordering optimization
In fact, modern processors are designed to complete one CPU instruction with the longest execution time in one clock cycle. Why do you do that? You can think of instructions It can also be divided into smaller stages. For example, each instruction can be divided into five stages: fetch instruction - instruction decoding - execute instruction - memory access - data write back
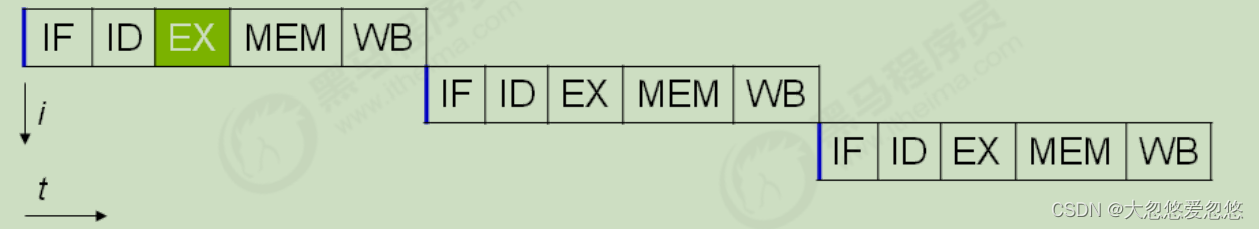
Term reference:
- instruction fetch (IF)
- instruction decode (ID)
- execute (EX)
- memory access (MEM)
- register write back (WB)
Without changing the program results, each stage of these instructions can realize instruction level parallelism by reordering and combining. This technology is in 80's Ye occupies an important position in computing architecture by the middle of 90's.
Tips: Phased division of labor is the key to improving efficiency!
The premise of instruction rearrangement is that the rearrangement instruction cannot affect the result, such as
// Examples that can be rearranged int a = 10; // Instruction 1 int b = 20; // Instruction 2 System.out.println( a + b ); // Examples that cannot be rearranged int a = 10; // Instruction 1 int b = a - 5; // Instruction 2
Pipelined processor
Modern CPU s support multi-level instruction pipeline, such as simultaneous execution of instruction fetching, instruction decoding, instruction execution, memory access and data writeback It can be called five level instruction pipeline. At this time, the CPU can run different stages of five instructions at the same time (equivalent to one clock cycle) In essence, pipelining technology can not shorten the execution time of a single instruction, but it improves the throughput of instructions in a disguised way.
Tips: Pentium 4 supports up to 35 stages of pipeline, but it is abandoned due to high power consumption
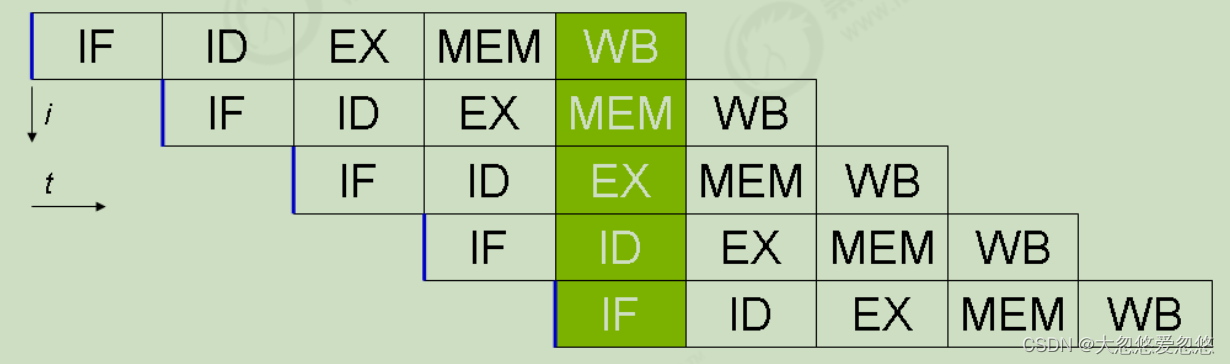
SuperScalar processor
Most processors contain multiple execution units, not all computing functions are concentrated together, and can be subdivided into integer operation units and floating-point operation units In this way, multiple instructions can be obtained and decoded in parallel. The CPU can execute more than one instruction in one clock cycle, that is, IPC > 1


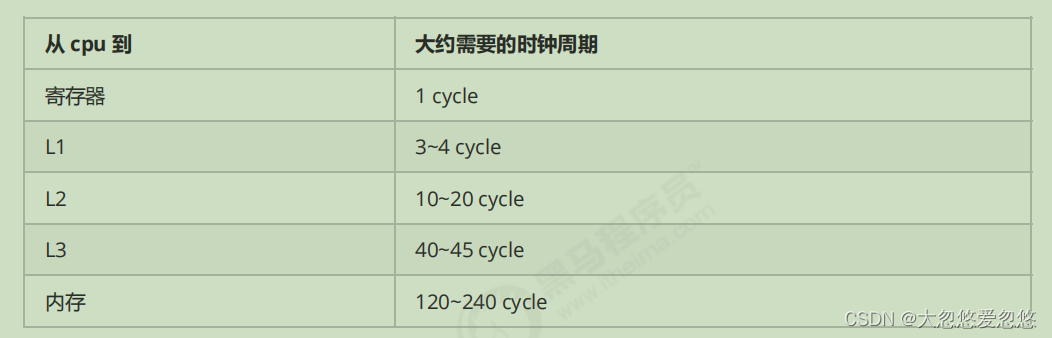
CPU cache structure principle
1. CPU cache structure

View cpu cache
⚡ root@yihang01 ~ lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 1 On-line CPU(s) list: 0 Thread(s) per core: 1 Core(s) per socket: 1 Socket(s): 1 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 142 Model name: Intel(R) Core(TM) i7-8565U CPU @ 1.80GHz Stepping: 11 CPU MHz: 1992.002 BogoMIPS: 3984.00 Hypervisor vendor: VMware Virtualization type: full L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 8192K NUMA node0 CPU(s): 0
Speed comparison
View cpu cache lines
⚡ root@yihang01 ~ cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size 64
The format of the memory address obtained by the cpu is as follows
[High level group mark][Low index][Offset]
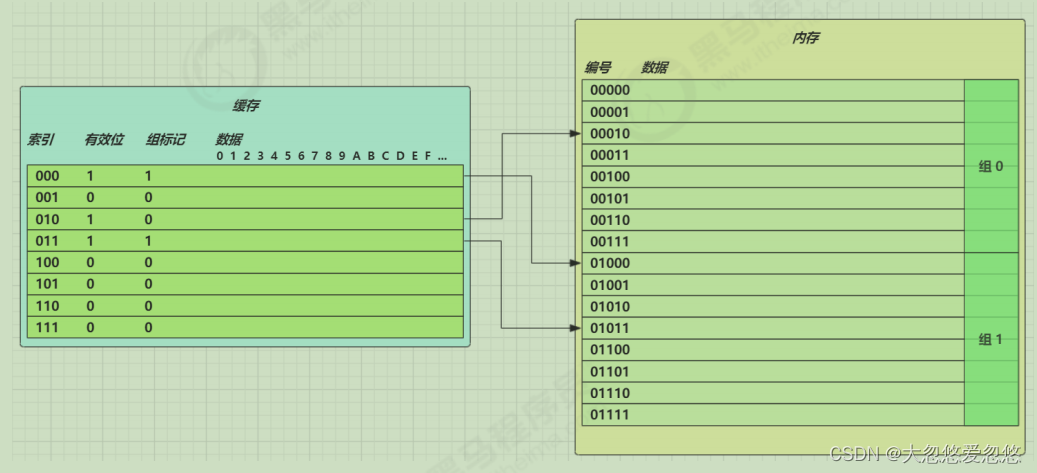
2.CPU cache read
The data reading process is as follows
- Calculates the index in the cache based on the low order
- Judge whether it is effective
0 goes to memory to read new data and update cache rows 1. Check whether the marks of the high level group are consistent
- Consistent, returns cached data according to the offset
- Inconsistent. Go to memory to read new data and update the cache line
3. CPU cache consistency
MESI protocol
- E. Cache lines in S and M states can meet CPU read requests
- If there is a write request for the cache line in E state, the state will be changed to M. at this time, the write to main memory will not be triggered
- For a cache line in E status, you must listen to the read operation of the cache line. If any, it must change to S status
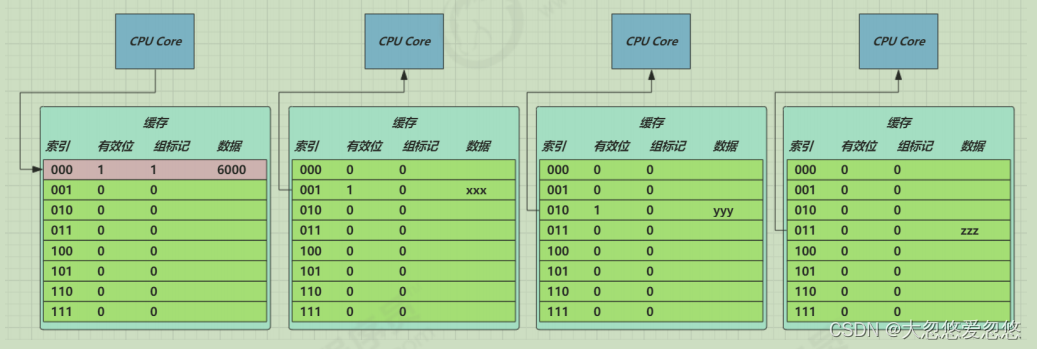
- For a cache line in M state, you must listen to the read operation of the cache line. If any, first change the cache line in other caches (S state) to I state (i.e. the process of 6), write it to main memory, and change it to S state
- Cache line in S status, with write request, go to 4 Process of
- For a cache line in S status, you must listen for the invalidation operation of the cache line. If any, it will change to I status
- The cache line in I status has a read request and must be read from main memory

Strange results
boolean ready = false;
int num = 0;
// Thread 1 executes this method
public void actor1(I_Result r) {
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
// Thread 2 executes this method
public void actor2(I_Result r) {
num = 2;
ready = true;
}I_Result is an object with an attribute r1 to save the result. Q: how many possible results are there?
Some students analyze it like this
- Case 1: thread 1 executes first. At this time, ready = false, so the result of entering the else branch is 1
- Case 2: thread 2 executes num = 2 first, but does not have time to execute ready = true. Thread 1 executes, or enters the else branch. The result is 1
- Case 3: thread 2 executes to ready = true, and thread 1 executes. This time, it enters the if branch, and the result is 4 (because num has already been executed)
But I tell you, the result could be 0 😁😁😁, Believe it or not!
In this case, thread 2 executes ready = true, switches to thread 1, enters the if branch, adds 0, and then switches back to thread 2 to execute num = 2
I believe many people have fainted 😵😵😵
This phenomenon is called instruction rearrangement, which is some optimization of JIT compiler at run time. This phenomenon can be repeated only after a large number of tests:
With the help of java Concurrent pressure measurement tool jcstress
3. jcstress, the test tool for JUC to organize notes 3 Simple tutorial for jcstress high concurrency testing framework in Java
mvn archetype:generate -DinteractiveMode=false -DarchetypeGroupId=org.openjdk.jcstress - DarchetypeArtifactId=jcstress-java-test-archetype -DarchetypeVersion=0.5 -DgroupId=cn.dhy- DartifactId=ordering -Dversion=1.0
Create maven project and provide the following test classes
@JCStressTest
@Outcome(id = {"1", "4"}, expect = Expect.ACCEPTABLE, desc = "ok")
@Outcome(id = "0", expect = Expect.ACCEPTABLE_INTERESTING, desc = "!!!!")
@State
public class ConcurrencyTest {
int num = 0;
boolean ready = false;
@Actor
public void actor1(I_Result r) {
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
@Actor
public void actor2(I_Result r) {
num = 2;
ready = true;
}
}implement
mvn clean install java -jar target/jcstress.jar
We will output the results we are interested in and extract one of the results:
*** INTERESTING tests Some interesting behaviors observed. This is for the plain curiosity. 2 matching test results. [OK] test.ConcurrencyTest (JVM args: [-XX:-TieredCompilation]) Observed state Occurrences Expectation Interpretation 0 1,729 ACCEPTABLE_INTERESTING !!!! 1 42,617,915 ACCEPTABLE ok 4 5,146,627 ACCEPTABLE ok [OK] test.ConcurrencyTest (JVM args: []) Observed state Occurrences Expectation Interpretation 0 1,652 ACCEPTABLE_INTERESTING !!!! 1 46,460,657 ACCEPTABLE ok 4 4,571,072 ACCEPTABLE ok
It can be seen that there are 638 times when the result is 0. Although the number is relatively small, it appears after all.
resolvent
volatile modified variable, which can disable instruction rearrangement
@JCStressTest
@Outcome(id = {"1", "4"}, expect = Expect.ACCEPTABLE, desc = "ok")
@Outcome(id = "0", expect = Expect.ACCEPTABLE_INTERESTING, desc = "!!!!")
@State
public class ConcurrencyTest {
int num = 0;
volatile boolean ready = false;
@Actor
public void actor1(I_Result r) {
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
@Actor
public void actor2(I_Result r) {
num = 2;
ready = true;
}
}The result is:
*** INTERESTING tests Some interesting behaviors observed. This is for the plain curiosity. 0 matching test results.
volatile principle
The underlying implementation principle of volatile is Memory Barrier (Memory Fence)
- The write barrier will be added after the write instruction to the volatile variable
- The read barrier will be added before the read instruction of volatile variable
Memory barrier
Memory Barrier(Memory Fence)
visibility
- The write barrier (sfence) ensures that changes to shared variables before the barrier are synchronized to main memory
- The lfence ensures that after the barrier, the latest data in main memory is loaded for the reading of shared variables
Order
- The write barrier ensures that the code before the write barrier is not placed after the write barrier when the instruction is reordered
- The read barrier ensures that the code behind the read barrier does not rank before the read barrier when the instruction is reordered
1. How to ensure visibility
- The write barrier (sfence) ensures that changes to shared variables before the barrier are synchronized to main memory
private int num;
private volatile boolean ready;
public void actor2(I_Result r) {
num = 2;
ready = true; // ready is a volatile assignment with a write barrier
// Write barrier
}Here, not only the ready variable will be synchronized to main memory, but also the variable operations before the ready variable will be synchronized to main memory. Here, the ready and num variables are included. Therefore, the num variable does not need to be preceded by the volatile keyword, but only needs to be preceded by the ready variable
- The lfence ensures that after the barrier, the latest data in main memory is loaded for the reading of shared variables
private int num;
private volatile boolean ready;
public void actor1(I_Result r) {
// Read barrier
// ready is a volatile read value with a read barrier
if(ready) {
r.r1 = num + num;
}
else {
r.r1 = 1;
}
}As above, the volatile keyword is added in front of ready, which is equivalent to establishing a read barrier. Therefore, the variables from the ready variable to the end of method execution are read from the latest data in main memory, which refers to the ready and num variables

2. How to ensure order
- The write barrier ensures that the code before the write barrier is not placed after the write barrier when the instruction is reordered
public void actor2(I_Result r) {
num = 2;
ready = true; // ready is a volatile assignment with a write barrier
// Write barrier
}- The read barrier ensures that the code behind the read barrier does not rank before the read barrier when the instruction is reordered
public void actor1(I_Result r) {
// Read barrier
// ready is a volatile read value with a read barrier
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
volatile cannot solve the problem of instruction interleaving
In the same sentence, instruction interleaving cannot be solved:
- The write barrier only guarantees that subsequent reads can read the latest results, but it does not guarantee that reads will run in front of it
- The guarantee of order only ensures that the relevant code in this thread is not reordered

Double checked locking problem
Take the famous double checked locking single instance mode as an example
public final class Singleton {
private Singleton() {
}
private static Singleton INSTANCE = null;
public static Singleton getInstance() {
if (INSTANCE == null) { // t2
// The first access is synchronized, but the subsequent use is not synchronized
synchronized (Singleton.class) {
if (INSTANCE == null) { // t1
INSTANCE = new Singleton();
}
}
}
return INSTANCE;
}
}The above implementation features are:
- Lazy instantiation
- Only when getInstance() is used for the first time can synchronized locking be used. No locking is required for subsequent use
- There is an implicit but critical point: the first if uses the INSTANCE variable, which is outside the synchronization block
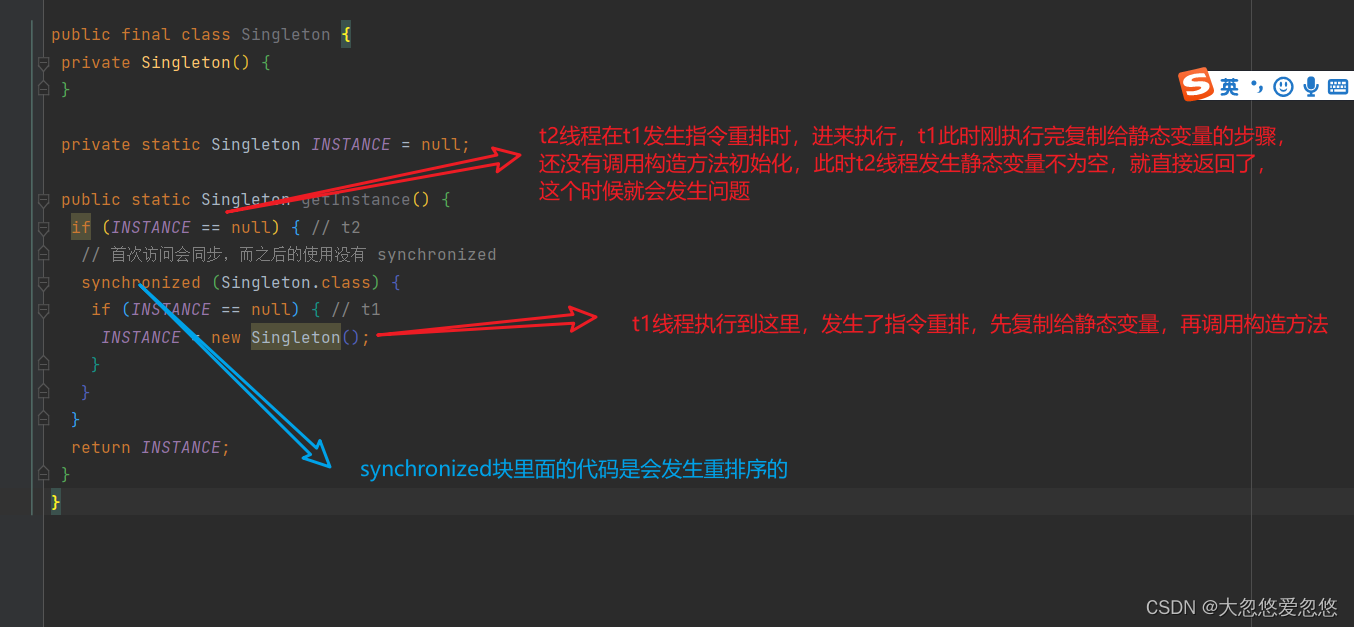
However, in a multithreaded environment, the above code is problematic. The byte code corresponding to the getInstance method is:
0: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; // Get static variable instance 3: ifnonnull 37 //Judge whether it is empty. If it is empty, skip to line 37 directly 6: ldc #3 // class cn/itcast/n5/Singleton / / get class objects 8: dup //Copy reference address --- for recovery after unlocking 9: astore_0 //Store the reference address copied above 10: monitorenter //Create monitor - lock 11: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; // Get static variable instance 14: ifnonnull 27 //Judge whether it is empty. If it is empty, skip to line 27 directly 17: new #3 / / class CN / itcast / N5 / singleton / / new an object 20: dup //Copy object reference address 21: invokespecial #4 / / method "< init >": () V / / call the construction method through the copied reference address 24: putstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; // Copy the reference address directly to the static variable instance 27: aload_0 //Get the reference address stored in line 9 - required for unlocking 28: monitorexit //Unlock 29: goto 37 //Go to line 37 32: astore_1 33: aload_0 34: monitorexit 35: aload_1 36: athrow 37: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; // Get static variable 40: areturn //return
among
- 17 means to create an object and reference the object into the stack. / / new Singleton
- 20 means to copy an object reference address
- 21 means to call the construction method using an object reference address
- 24 means that an object reference address is used to assign a value to static INSTANCE
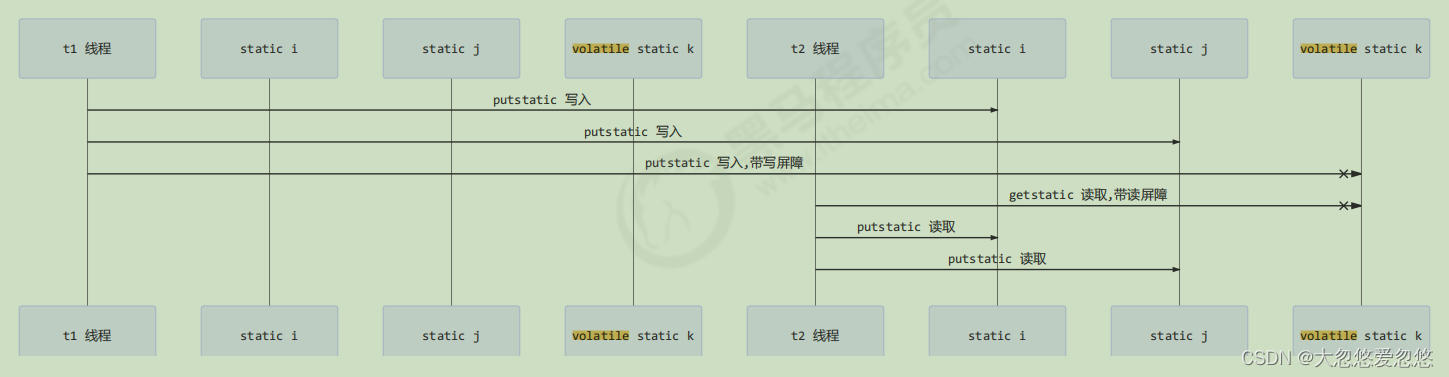
Maybe the jvm will be optimized to execute 24 first and then 21. If two threads t1 and t2 execute in the following time series:

The key is that the line 0: getstatic is outside the control of monitor. It is like the irregular person in the previous example, and can be read across monitor The value of the INSTANCE variable
At this time, t1 has not completely executed the construction method. If many initialization operations need to be performed in the construction method, t2 will get an initial value Single case after initialization
Use volatile modification on INSTANCE to disable instruction rearrangement. However, it should be noted that volatile in JDK version 5 or above is really effective
misunderstanding
synchronized can protect the atomicity, visibility and order of shared variables. This sentence is not particularly rigorous:
- Synchronized can't prevent reordering. Only volatile can. However, if the shared variable is completely protected by synchronized, the shared variable will not use atoms, visible and ordering problems in the process of use
Synchronized can protect the atomicity of shared variables. The premise of visibility and order is based on the premise that shared variables are completely protected by synchronized
Double checked locking solution
public final class Singleton {
private Singleton() {
}
private static volatile Singleton INSTANCE = null;
public static Singleton getInstance() {
// An instance is not created before it enters the internal synchronized code block
if (INSTANCE == null) {
synchronized (Singleton.class) { // t2
// Maybe another thread has created an instance, so judge again
if (INSTANCE == null) { // t1
INSTANCE = new Singleton();
}
}
}
return INSTANCE;
}
}The effect of volatile instruction cannot be seen in bytecode
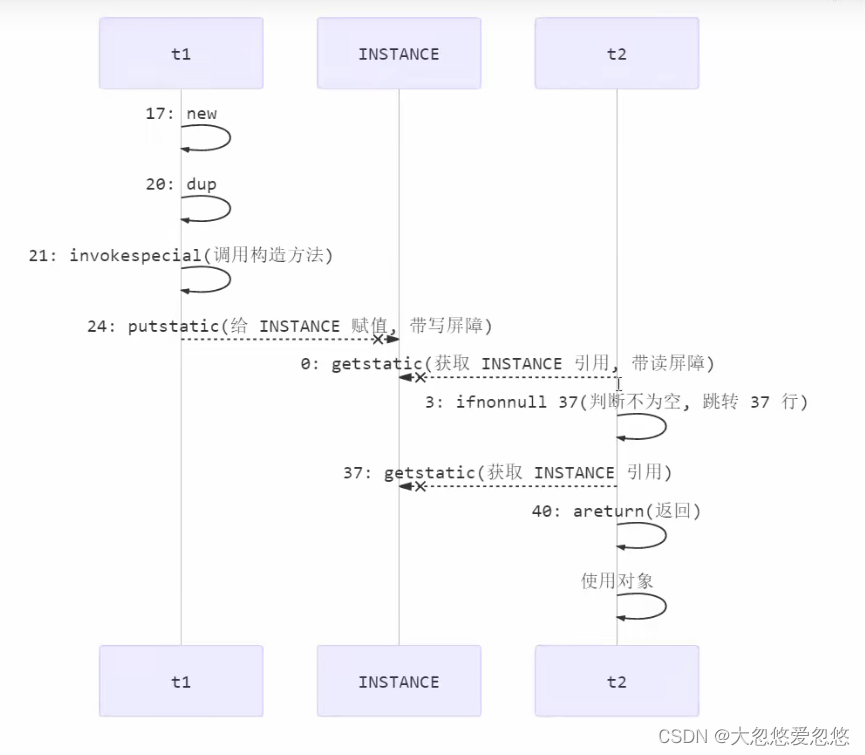
// ------------------------------------->Add a read barrier to the INSTANCE variable 0: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; 3: ifnonnull 37 6: ldc #3 // class cn/itcast/n5/Singleton 8: dup 9: astore_0 10: monitorenter -----------------------> Ensure atomicity and visibility 11: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; 14: ifnonnull 27 17: new #3 // class cn/itcast/n5/Singleton 20: dup 21: invokespecial #4 // Method "<init>":()V 24: putstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; // ------------------------------------->Add a write barrier to the INSTANCE variable 27: aload_0 28: monitorexit ------------------------> Ensure atomicity and visibility 29: goto 37 32: astore_1 33: aload_0 34: monitorexit 35: aload_1 36: athrow 37: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; 40: areturn
The read barrier prevents the code behind the read barrier from jumping to the front The write barrier prevents the code before the write barrier from jumping behind
As shown in the above comments, a Memory Barrier (Memory Fence) will be added when reading and writing volatile variables to ensure the following Two points:
- visibility
The write barrier (sfence) ensures that changes to shared variables before the barrier are synchronized to main memory
The lfence ensures that the shared variables are read t2 after the lfence, and the latest data in main memory is loaded
- Order
The write barrier ensures that the code before the write barrier is not placed after the write barrier when the instruction is reordered
The read barrier ensures that the code behind the read barrier does not rank before the read barrier when the instruction is reordered
The lower layer is to use the lock instruction when reading and writing variables to ensure the visibility and order between multi-core CPU s
happens-before
Happens before specifies that the write operation of shared variables is visible to the read operation of other threads. It is a summary of a set of rules for visibility and ordering With the following happens before rules, JMM does not guarantee that a thread writes to a shared variable, but is visible to other threads' reading of the shared variable
- The write of the variable before the thread unlocks m is visible to the read of the variable by other threads that lock m next
static int x;
static Object m = new Object();
new Thread(()->{
synchronized(m) {
x = 10;
}
},"t1").start();
new Thread(()->{
synchronized(m) {
System.out.println(x);
}
},"t2").start();- When a thread writes a volatile variable, it is visible to other threads reading the variable
volatile static int x;
new Thread(()->{
x = 10;
},"t1").start();
new Thread(()->{
System.out.println(x);
},"t2").start();- The write to the variable before the thread starts is visible to the read to the variable after the thread starts
static int x;
x = 10;
new Thread(()->{
System.out.println(x);
},"t2").start();- The write to the variable before the end of the thread is visible to the read after other threads know that it ends (for example, other threads call t1.isAlive() or T1 Join() wait It ends), because after the thread ends, the cached data is written to main memory
static int x;
Thread t1 = new Thread(()->{
x = 10;
},"t1");
t1.start();
t1.join();
System.out.println(x);- Thread t1 writes to the variable before interrupting T2 (interrupt), which is visible to other threads after they know that T2 is interrupted (through t2.interrupted or t2.isInterrupted)
static int x;
public static void main(String[] args)
{
Thread t2 = new Thread(()->{
while(true) {
if(Thread.currentThread().isInterrupted()) {
System.out.println(x);
break;
}
}
},"t2");
t2.start();
new Thread(()->{
sleep(1);
x = 10;
t2.interrupt();
},"t1").start();
while(!t2.isInterrupted()) {
Thread.yield();
}
System.out.println(x);
}- The writing of the default value of the variable (0, false, null) is visible to the reading of the variable by other threads
- It has transitivity. If x HB - > y and Y HB - > Z, then there is x HB - > Z, combined with volatile anti instruction rearrangement. The following example is given
volatile static int x;
static int y;
new Thread(()->{
y = 10;
x = 20;//The write barrier synchronizes all operations before the write barrier to main memory without reordering
},"t1").start();
new Thread(()->{
// x=20 is visible to t2, and y=10 is also visible to t2
System.out.println(x);
},"t2").start();Variables refer to member variables or static member variables\
case
balking model exercises
You want the doInit() method to be called only once. Is there a problem with the following implementation and why?
public class TestVolatile {
volatile boolean initialized = false;
void init() {
if (initialized) {
return;
}
doInit();
initialized = true;
}
private void doInit() {
}
}
The solution is to add synchronization locks instead of abusing the volatile keyword
volatile is generally used for one thread to write and one thread to read, so as to ensure the visibility of variables among multiple threads and prevent instruction reordering in problem processing and double checking
Thread safe single example exercise
There are many implementation methods of singleton mode, such as hungry man, lazy man, static internal class and enumeration class. Try to analyze the thread safety when obtaining singleton object (i.e. calling getInstance) under each implementation, and think about the problems in annotation
Hungry Chinese style: class loading will cause the single instance object to be created Lazy: class loading does not cause the single instance object to be created, but only when the object is used for the first time
Implementation 1:
// Question 1: why add final
// Question 2: if the serialization interface is implemented, what else should be done to prevent deserialization from destroying singletons
public final class Singleton implements Serializable {
// Question 3: why is it set to private? Can reflection be prevented from creating new instances?
private Singleton() {
}
// Question 4: does this initialization ensure thread safety when creating a singleton object?
private static final Singleton INSTANCE = new Singleton();
// Question 5: why do you provide static methods instead of directly setting INSTANCE to public? Tell me the reason you know
public static Singleton getInstance() {
return INSTANCE;
}
public Object readResolve() {
return INSTANCE;
}
}- Problem 1: prevent subclasses from overwriting parent methods and destroying singletons
- Problem 2: deserialization will create a new instance and destroy the singleton pattern. The solution is to add a special method readResolve() to the class. Reason: during deserialization, if the method readResolve returns an object, it will return the object as a result of deserialization instead of a new object created through a bytecode object, This ensures that even if deserialized, a new object will not be returned
- Problem 3: setting the constructor to private prevents other classes from creating objects through the constructor and destroying the singleton mode. However, it cannot prevent reflection from creating new objects, because reflection can create objects by calling setAccessible() method
- Question 4: the initialization process of static member variables is completed in the class loading phase. In the class loading phase, the jvm ensures the thread safety of the code, so the assignment of static variables in the class loading phase is thread safe
- Question 5: better encapsulation and support for generics
Implementation 2:
// Question 1: how does the enumeration singleton limit the number of instances
// Question 2: does the enumeration singleton have concurrency problems when it is created
// Question 3: can enumeration singletons be destroyed by reflection
// Question 4: can enumeration singletons be deserialized to destroy singletons
// Question 5: is the enumerator lazy or hungry
// Question 6: what should I do if I want to add some initialization logic when I create a singleton
enum Singleton {
INSTANCE;
}- Question 1: there are several enumeration objects and several instances in the enumeration class. These enumeration objects are essentially static member variables in the enumeration class.
- Problem 2: because the enumeration singleton is a static member variable, and the creation process is completed in the class loading stage, there is no thread safety problem
- Question 3: No
- Question 4: enum class enum implements the serialization interface, so it can be serialized, but it will not be deserialized to destroy the singleton
- Question 5: hungry Chinese style
- Question 6: it can be implemented in the construction method
Implementation 3:
public final class Singleton {
private Singleton() {
}
private static Singleton INSTANCE = null;
// Analyze the thread safety here and explain the shortcomings
public static synchronized Singleton getInstance() {
if (INSTANCE != null) {
return INSTANCE;
}
INSTANCE = new Singleton();
return INSTANCE;
}
}Thread safe, but the range of locks is too large. Each call needs to be locked, and the performance is relatively low
You cannot add a synchronized synchronization lock to a null value
The lock cannot be loaded on INSTANCE because INSTANCE needs to be re assigned and may be null. Null cannot be locked because synchronized needs to find an object and allocate a monitor lock according to the object. If it is null, there is no associated object
To place a lock on a relatively constant object
Implementation 4: DCL
public final class Singleton {
private Singleton() {
}
// Question 1: explain why volatile is added?
private static volatile Singleton INSTANCE = null;
// Question 2: compare implementation 3 and say the meaning of doing so
public static Singleton getInstance() {
if (INSTANCE != null) {
return INSTANCE;
}
synchronized (Singleton.class) {
// Question 3: why add null judgment here? Haven't you judged it before
if (INSTANCE != null) { // t2
return INSTANCE;
}
INSTANCE = new Singleton();
return INSTANCE;
}
}
}Question 3: if thread 1 just released the lock and thread 2 found that no object was created at the beginning, but the door was locked, it blocked for a while. After getting the lock, enter the synchronization code block and need to judge whether there is an object again, otherwise it will be created repeatedly
volatile prevents instruction rearrangement in the current code block
Implementation 5:
public final class Singleton {
private Singleton() {
}
// Question 1: is it lazy or hungry
private static class LazyHolder {
static final Singleton INSTANCE = new Singleton();
}
// Question 2: is there a concurrency problem when creating
public static Singleton getInstance() {
return LazyHolder.INSTANCE;
}
}- Class loading is lazy. Class loading is always triggered when you are used for the first time. If you do not call getInstance() method, class loading will not be triggered. Therefore, it is lazy
- During class loading, the loading of static variables is thread safe through the jvm, so there is no concurrency problem
Summary of this chapter
This chapter focuses on JMM
- Visibility - caused by JVM cache optimization
- Ordering - caused by JVM instruction reordering optimization
- Happens before rule
- Principle aspect
CPU instruction parallelism
volatile
- Mode aspect
volatile improvement of two-stage termination mode
balking in synchronous mode