In 2018, due to the development of a large water conservancy Province Hydrological data website After the revision, the hydrological data of the province are changed into small pictures with a height of 13px. For example, the three pictures below represent the station name, upstream water level and downstream water level respectively:
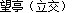
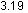
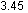
After downloading, open it with picture viewing software as follows (91*13px, transparent background, PNG format):

Recently, when it comes to Python learning, I found that various image recognition technologies under Python have been very mature. Three methods have been tried:
(1) Various clouds, such as Alibaba cloud, baidu cloud and Tencent cloud. After testing, only the high-precision version of Tencent cloud can be recognized more accurately. Baidu cloud and Alibaba cloud do not support pictures with the shortest edge less than 15px. After zooming in with python's pilot module, they still cannot be recognized accurately. However, the image recognition function of Tencent cloud is only limited to enterprise registration, and there is no personal application interface. Personal free use needs to pay attention to the quota limit. This data capture is a large number of small pictures, and the number of identified pictures is large, which is not cost-effective.
(2)tesseract. Tesseract is an open source recognition framework of Google. Tesseract OCR Direct is a cross platform command line tool, which can be run directly and is convenient for debugging and testing. Relevant third-party development tools are also very rich, such as those that can be used under python Pytesseract . However, after testing, the recognition effect is not ideal, especially for Chinese recognition. You need to use the training database to make the ground truth, and there are many methods of online training databases.
(3)cnocr. cnocr It is a Chinese and English OCR toolkit under Python 3. It comes with multiple trained recognition models (the minimum model is only 4.7M), which can be used directly after installation. cnocr v1.2. At present, it includes the following models that can be used directly. The trained models are put in the cnocr models project and can be downloaded and used for free:
| Model name | Local coding | Sequence coding model | Model size | Number of iterations | Test set accuracy | Prediction speed of pictures in the test set (s / piece, environment: single GPU) |
|---|---|---|---|---|---|---|
| conv-lite-fc | conv-lite | fc | 18M | 25 | 98.61% | 0.004191 |
| densenet-lite-gru | densenet-lite | gru | 9.5M | 39 | 99.04% | 0.003349 |
| densenet-lite-fc | densenet-lite | fc | 4.7M | 40 | 97.61% | 0.003299 |
| densenet-lite-s-gru | densenet-lite-s | gru | 9.5M | 35 | 98.52% | 0.002434 |
| densenet-lite-s-fc | densenet-lite-s | fc | 4.7M | 40 | 97.20% | 0.002429 |
First, a preliminary direct test is carried out. After trying several models, it is found that densenet Lite Gru is better, but there are still a lot of errors. I tried to resize the picture, enlarge it 10 times, transparent bottom, and the effect still hasn't changed. It is realized with the function of pilot module.
from PIL import Image Imageurl = 'http://218.94.6.94:88/jsswxxSSI/static/map1/list/0/' + str(num) + '/' + id + '.png' imageData = requests.get(Imageurl).content imgBytes=BytesIO() imgBytes.write(imageData) im = Image.open(imgBytes) im = im.resize((im.size[0] * 10, im.size[1] * 10), Image.ANTIALIAS)
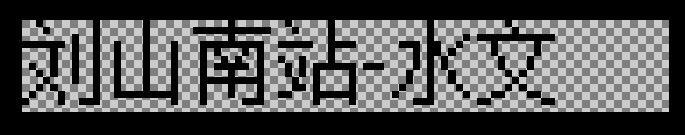
After that, the transparent background is changed to white background, which is realized by the function of pilot module. The recognition effect is still not improved.
im = Image.open(imgBytes)
p = Image.new('RGBA', (im.size[0] , im.size[1] ), (255, 255, 255))
p.paste(im, (3, 3, im.size[0] , im.size[1] ), im)
p.save(r'%s%s.png' % (picPath, id))

Finally, it was found that the problem was that the text was close to the boundary. There is no gap between the text and the picture border, which affects the effect. When you need to change the white background, enlarge the background and paste the text into it.

The final recognition result is only the recognition error of individual symbols, such as brackets (because they are close to the text and cannot be recognized correctly, they will recognize (3) as giant, etc. it can be improved with a little correction. The code quality is relatively rough when using Python for the first time. The complete code is as follows:
# -*- coding: utf-8 -*-
import re
import json
from io import BytesIO
import cnocr.consts
import requests
from PIL import Image
from cnocr import CnOcr
import mxnet as mx
dataList = []
ocr = CnOcr('densenet-lite-gru')
def getImageArr(img):
imgBytes = BytesIO()
imgBytes.write(img)
im = Image.open(imgBytes)
#In the image processing part, considering that the input of cnocr must be file address or image array, the output is improved.
p = Image.new('RGBA', (im.size[0] + 3, im.size[1] + 6), (255, 255, 255))
p.paste(im, (3, 3, im.size[0] + 3, im.size[1] + 3), im)
p = p.convert('RGB')
img_byte_arr = BytesIO()
p.save(img_byte_arr, format='PNG')
return mx.image.imdecode(img_byte_arr.getvalue(), 1)
def NameStrRepair(namestr):
if ('〉' in namestr):
namestr = namestr.replace('〉', ')')
if ('C' in namestr):
namestr = namestr.replace('C', '(')
if ('()' in namestr):
namestr = namestr.replace('()', '(new)')
if (')' in namestr) & ('(' not in namestr):
namestr = namestr[:(namestr.find(')') - 1)] + '(' + namestr[(namestr.find(')') - 1):]
if ('〉' in namestr):
namestr = namestr.replace('〉', ')')
if ('huge' in namestr):
namestr = namestr.replace('huge', 'three')
if ('Guy' in namestr):
namestr = namestr.replace('Guy', 'old')
if ('Seeking ferry(Bridge)' in namestr):
namestr = namestr.replace('Seeking ferry(Bridge)', '(Foraging Bridge)')
if ('titanium' in namestr):
namestr = namestr.replace('titanium', 'too')
if ('Dai' in namestr):
namestr = namestr.replace('Dai', 'Tai')
if ('around(Outside' in namestr):
namestr = namestr.replace('around(Outside', '(Waiwai')
if ('+─' in namestr):
namestr = namestr.replace('+─', 'eleven')
if ('Brocade(Stream' in namestr):
namestr = namestr.replace('Brocade(Stream', '(Jinxi')
if ('Brocade(Stream' in namestr):
namestr = namestr.replace('Brocade(Stream', '(Jinxi')
if ('Jiangdu Pumping' in namestr):
namestr=namestr[:4]+'('+namestr[4]+')'+namestr[-1:]
return namestr
def getImageText(num, id):
Imageurl = 'http://218.94.6.94:88/jsswxxSSI/static/map1/list/0/' + str(num) + '/' + id + '.png'
imageData = requests.get(Imageurl).content
global ocr
txt = ''
try:
if num == 1:
ocr.set_cand_alphabet(None)
txt = ''.join(ocr.ocr_for_single_line(getImageArr(imageData)))
txt=NameStrRepair(txt)
else:
ocr.set_cand_alphabet(cnocr.consts.NUMBERS)
txt = ''.join(ocr.ocr_for_single_line(getImageArr(imageData)))
except:
pass
return txt
def getJSdata():
jsurl = 'http://218.94.6.94:88/jsswxxSSI/static/map/js/sqarea.min.js'
JSres = requests.get(jsurl)
re_json = re.compile(r'\[.*?.}\]')
JSjson = re_json.search(JSres.text).group(0)
JSdata = json.loads(JSjson, strict=False)
for ZDdata in JSdata:
data = {}
data['id'] = ZDdata['id']
data['name'] = getImageText(1, ZDdata['id'])
data['upWL'] = getImageText(2, ZDdata['id'])
data['downWL'] = getImageText(3, ZDdata['id'])
dataList.append(data)
print(data)
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
getJSdata()
The operation will get the following results:
{'id': '001d7e4c39a64d71b032017bb000ee44', 'name': 'Danyang', 'upWL': '3.58', 'downWL': '}
{'id': '013a1c2aeb4146be8cc3f6beb0be5710', 'name': 'hydrology of Liushan South Station', 'upWL': '25.15', 'downWL': '}
{'id': '01a0223240f54009ae55bca5fbb6ff9f', 'name': 'Changshu', 'upWL': '3.22', 'downWL': '}
{'id':'01c24eff884e4a76a6360d589a07b720 ','name':'shixiwei harbor gate ',' upWL ':'3.36','downWL ':'}
{'id':'023e1320526d443c8814051750a43f7f ','name':'funing waist gate ',' upWL ':'6.00','downWL ':'2.51'}
{'id': '02634643f4c4f4f4ae725d867d66f4c0', 'name': 'Dongtai River Gate', 'upWL': '2.37', 'downWL': '}
{'id': '0273bb530b294a8e89c99fc53cde6702', 'name': 'Shaji pumping station', 'upWL': '20.50', 'downWL': '14.16'}
{'id':'02c1a1d249cf4d81a8a45dd2c6686ad7 ','name':'datao pumping station 2 ','upWL':'2.96 ','downWL':'0.75 '}
{'id': '02c3bcdbeaac4d55aefb870753069963', 'name': 'Jiangdu Pumping Station (III),' upWL ':' 6.57 ',' downWL ':' 1.40 '}
{'id': '02eecccefd71441d883bb3280a1c48df', 'name': 'Hanzhuang (micro)', 'upWL': '32.25', 'downWL': '}
{'id':'037f3aa86dfe42059d8fe89570da7385 ','name':'bashan ','upWL':'174.52 ','downWL': '}
{'id': '03d928a5f3c7483f83d4444dba8c7a3c', 'name': 'Wuxi (large)', 'upWL': '3.48', 'downWL': '}
{'id': '044f7507b64c4177a6d1f84126275fba', 'name': 'XiangZhuang', 'upWL': '12.81', 'downWL': '}
{'id': '045b69369a74471e8634d9b563aca8b2', 'name': 'Jiuxian', 'upWL': '3.64', 'downWL': '}
{'id': '04934721a54b452d957b7850dfa0e30b', 'name': 'dushanzha', 'upWL': '3.16', 'downWL': '}
{'id': '04b69a8f3e3a4fec85981f3511707208', 'name': 'Dapukou', 'upWL': '3.21', 'downWL': '}
{'id':'050861887f754a59802d84220935ef93 ','name':'zhongtan rubber dam ',' upWL ':'0.19','downWL ':'}
{'id': '05e2d3bf2238427c9b33e5cf71abb7dc', 'name': 'lunshan reservoir', 'upWL': '48.52', 'downWL': '}
It basically meets our requirements.
I also tried PS. cnocr's own training model work, and found that there are too many model files to prepare. In addition, I have high requirements for the computing performance of the computer. My old notebook T440 is really incompetent and finally gave up, but some pits can be filled in for you. You can see the specific methods of your own training on the github page of cnocr. You may not understand it for the first time.
(1)train.txt and test Txt file format
Picture 1 png label11 label12 label13…
Picture 2 png label21 label22 label23…
...
The label here refers to the serial number of the text library corresponding to the recognition result text, that is, the recognition Library folder ~ / cnocr/1.2.0/densenet-lite-gru/label_cn.txt is the serial number corresponding to the corresponding text or symbol.
(2) How to quickly prepare train Txt file?
The GitHub page of cnocr does not give a method to quickly prepare the file. If you find it manually one by one, it will be time-consuming, laborious and easy to travel. I handled it this way:
First prepare a prefile file with the following format:
File name recognition result
(since they are all png suffixes, I omitted them) examples are as follows:
01c24eff884e4a76a6360d589a07b720 shixiwei harbor gate
02c3bcdbeaac4d55aefb870753069963 Jiangdu Pumping Station (III)
02eecccefd71441d883bb3280a1c48df Hanzhuang (micro)
07cc368be8b74ba48e592fbbdd1d0c8b Jiangdu Pumping Station (II)
17b1e5ba5d2e483d9243a6198c4ccef1 Dongting West Mountain (III)
1b5b9ed42805414ea68ec746028231f5 Daguanzhuang gate (New)
2335a9568e8d4551a7c28c13a0f42ef9 Wangting (Interchange)
25ed9afc53704b36b74c1f963382bb12 Huibaoling (South)
2552698f2d8149ab88205cd09d6515c5 Hai'an (string)
74f3dd2d57a643578525f270c4b2c998 Changzhou (III)
7a019471354e4ccdac9e9f8daf34bc65 Shao Bo (large)
3e0420d8f29b42ae9917455ada34c94c Gaoyou (large)
4907e5ad311248c8adcfb7390f701a98 Taizhou (Tong)
4d91dd400f6e4297828a6b8bcb207261 Gaoyou (high)
564602d366d24cbabea6d264714d782d Gaoyou (large)
58fbb1e8806347e1995552eb02090309 Yunxi (power station) control gate
5be39f0dc1bb4705952aaa17bde4cc1 Suzhou (foraging ferry bridge)
Then I used a piece of Python code to produce train Txt file.
# -*- coding: utf-8 -*-
#Three required file directories
preFilePath=r'/media/nautilus/Data/Personal/Software/cnocr-1.2.2/cyctrain/prefile'
outputfile=r'/media/nautilus/Data/Personal/Software/cnocr-1.2.2/cyctrain/train.txt'
labelcnFP=r'/home/nautilus/.cnocr/1.2.0/densenet-lite-gru/label_cn.txt'
labeldict={}
with open(labelcnFP) as flabelcn:
k=1
for line in flabelcn.readlines():
labeldata = line.strip()
labeldict[labeldata] = k
k=k+1
print (labeldict)
with open(preFilePath,'r') as f1:
with open(outputfile,'w') as f2:
for line in f1.readlines():
inputstr=line.strip().split(' ')
outputstr=inputstr[0]+'.png'
inputlabel=list(inputstr[1])
for labelchar in inputlabel:
outputstr=outputstr+' '+str(labeldict[labelchar])
f2.write(outputstr+'\n')
test.txt and train Txt is the same and will not be repeated.