Configure the highly available yum source on [server1] and [server4]
[root@server1 ~]# vim /etc/yum.repos.d/rhel-source.repo
[rhel-source]
name=Red Hat Enterprise Linux $releasever - $basearch - Source
baseurl=http://172.25.40.250/rhel6.5
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.40.250/rhel6.5/HighAvailability
gpgcheck=0
[LoadBalancer]
name=LoadBalancer
baseurl=http://172.25.40.250/rhel6.5/LoadBalancer
gpgcheck=0
[ResilientStorage]
name=ResilientStorage
baseurl=http://172.25.40.250/rhel6.5/ResilientStorage
gpgcheck=0[root@server1 ~]# yum install -y crmsh-1.2.6-0.rc2.2.1.x86_64.rpm pssh-2.3.1-2.1.x86_64.rpm moosefs-master-3.0.97-1.rhsysv.x86_64.rpm[root@server1 ~]# cd /etc/corosync/
[root@server1 corosync]# cp corosync.conf.example corosync.conf
[root@server1 corosync]# vim corosync.conf
10 bindnetaddr: 172.25.40.0
11 mcastaddr: 226.94.1.1
12 mcastport: 5959
....
35 service {
36 name: pacemaker
37 ver: 0
38 }
[root@server1 corosync]# /etc/init.d/corosync start
[root@server1 corosync]# scp corosync.conf server4:/etc/corosyncThe above operations are carried out at the same time on 1 and 4
[server4] open the service
[root@server4 ~]# cd /etc/corosync/
[root@server4 corosync]# ls
corosync.conf corosync.conf.example.udpu uidgid.d
corosync.conf.example service.d
[root@server4 corosync]# /etc/init.d/corosync startView the monitoring on [server1]
[root@server1 corosync]# crm_mon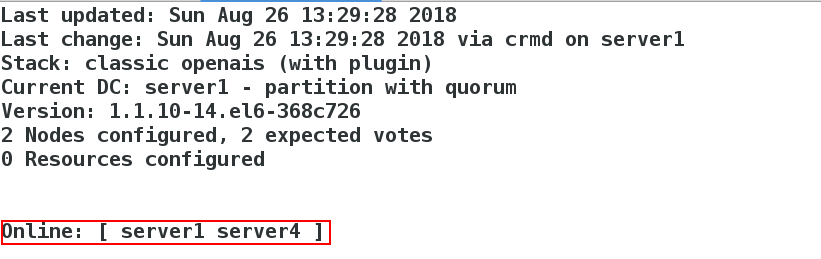
Add a disk to [server2] 
[root@server2 ~]# yum install -y scsi-*
[root@server2 ~]# vim /etc/tgt/targets.conf
38 <target iqn.2018-08.com.example:server.target1>
39 backing-store /dev/vdb
40 </target>
[root@server2 ~]# /etc/init.d/tgtd startInstall iscsi on [server1] and [server4]
[root@server1 corosync]# yum install -y iscsi-*
[root@server4 corosync]# yum install -y iscsi-*[server1]
[root@server1 corosync]# iscsiadm -m discovery -t st -p 172.25.40.2
Starting iscsid: [ OK ]
172.25.40.2:3260,1 iqn.2018-08.com.example:server.target1
[root@server1 corosync]# iscsiadm -m node -l
On [server1], you can view the disks added by server2
[root@server1 corosync]# fdisk -l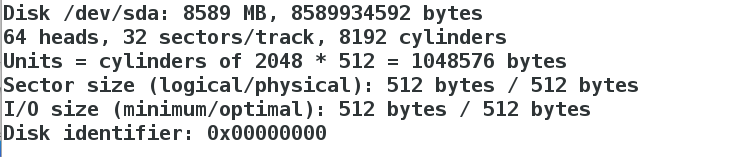
Create partition on [server1]
[root@server1 corosync]# fdisk -cu /dev/sda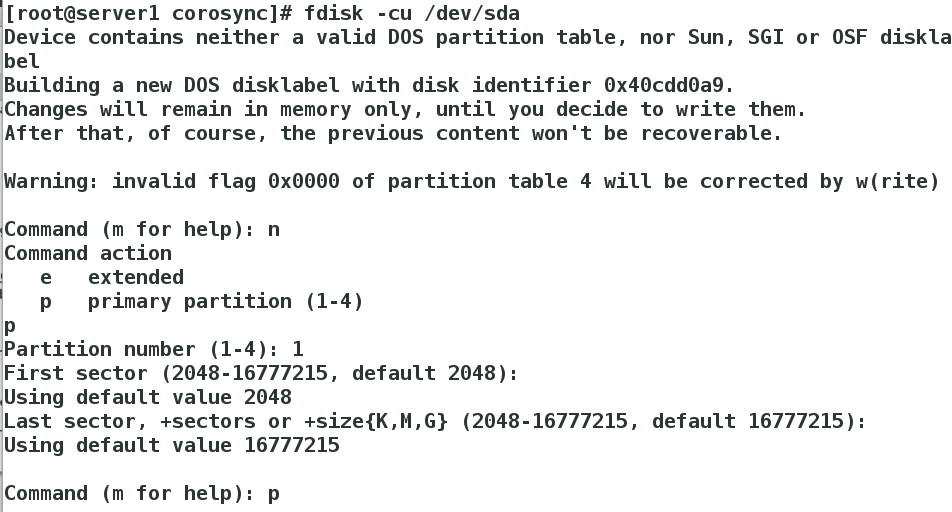
After setting up the partition, ask wq to save and exit 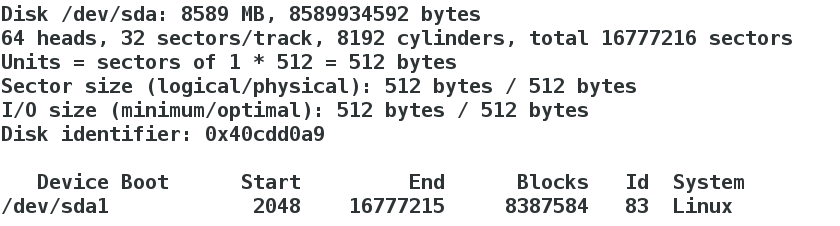
format partition
[root@server1 corosync]# mkfs.ext4 /dev/sda1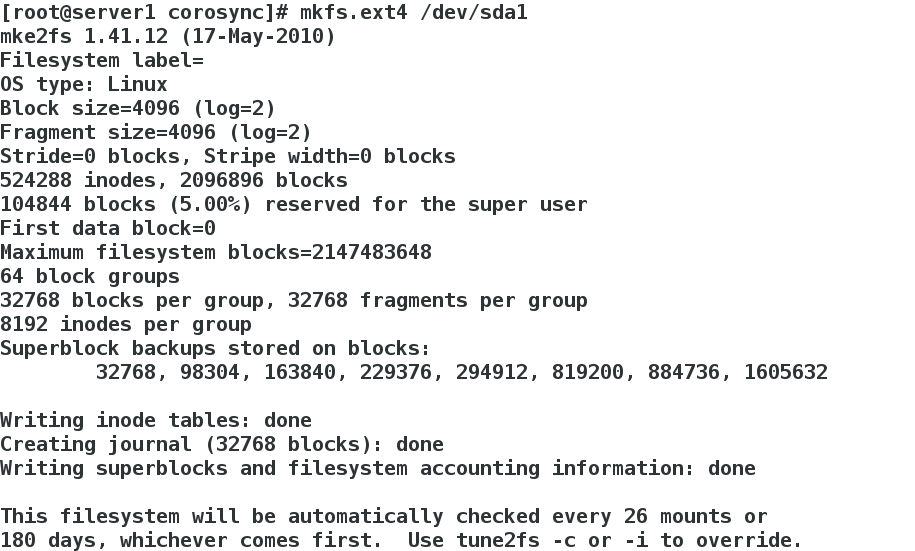
[server4]
[root@server4 corosync]# iscsiadm -m discovery -t st -p 172.25.40.2
[root@server4 corosync]# iscsiadm -m node -l
[root@server4 corosync]# fdisk -l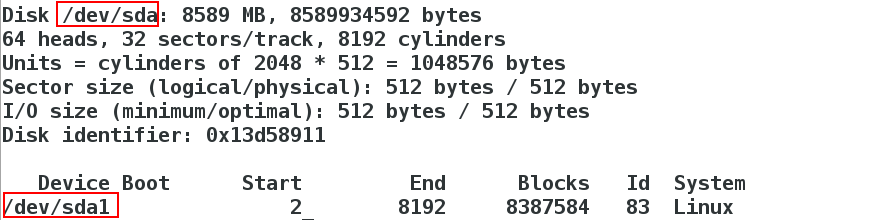
[root@server1 corosync]# /etc/init.d/moosefs-master stop
Stopping mfsmaster: [ OK ]
[root@server1 corosync]# cd /var/lib/mfs/
[root@server1 mfs]# mount /dev/sda1 /mnt/
[root@server1 mfs]# cp -p * /mnt/
[root@server1 mfs]# cd /mnt/
[root@server1 mnt]# cd
[root@server1 ~]# umount /mnt/
[root@server1 ~]# ll -d /var/lib/mfs/
drwxr-xr-x 3 root root 4096 Aug 26 13:57 /var/lib/mfs/
[root@server1 ~]# chown mfs.mfs /var/lib/mfs/
[root@server1 ~]# mount /dev/sda1 /var/lib/mfs
[root@server1 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup-lv_root 19134332 1032768 17129584 6% /
tmpfs 380140 37152 342988 10% /dev/shm
/dev/vda1 495844 33474 436770 8% /boot
/dev/sda1 8255928 153108 7683444 2% /var/lib/mfs[server4]
[root@server4 ~]# ll -d /var/lib/mfs/
drwxr-xr-x 2 mfs mfs 4096 Aug 26 13:17 /var/lib/mfs/
[root@server4 ~]# /etc/init.d/moosefs-master start
[root@server4 ~]# /etc/init.d/moosefs-master stopAuto recover moosefs master exception
Modify the script on [server4] and [server1]
[root@server1 ~]# /etc/init.d/moosefs-master start
[root@server1 ~]# vim /etc/init.d/moosefs-master
31 $prog start >/dev/null 2>&1 || $prog -a >/dev/null 2>&1 && success || f ailure #When the moosefs master is shut down abnormally, the script will automatically return to normal and turn on the masterTest:
Shut down moosefs master under abnormal conditions
[root@server1 ~]# ps ax
1606 ? S< 0:02 mfsmaster start
[root@server1 ~]# kill -9 1606 #End processNo error will be reported when moosefs master is turned on at this time 
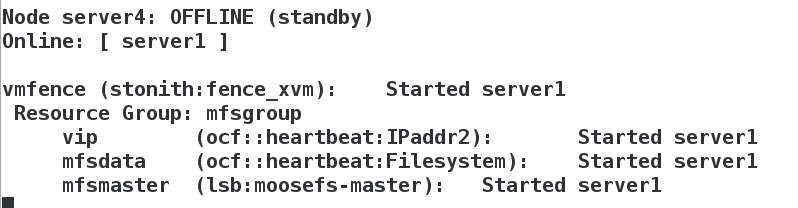
Fence mechanism
Download fence on [server1] and [server4]
[root@server1 ~]# yum install -y fence-virt
[root@server1 ~]# mkdir /etc/cluster
----------------------------------------------
[root@server4 ~]# yum install -y fence-virt
[root@server4 ~]# stonith_admin -I
[root@server4 ~]# mkdir /etc/cluster[root@foundation40 ~]# systemctl start fence_virtd
[root@foundation40 ~]# systemctl status fence_virtd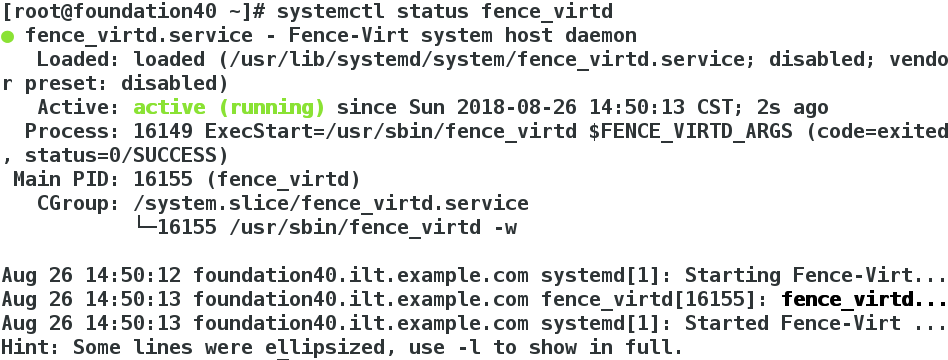
[root@foundation40 cluster]# scp fence_xvm.key root@172.25.40.1:/etc/cluster
[root@foundation40 cluster]# scp fence_xvm.key root@172.25.40.4:/etc/clusterOn [server1]
[root@server1 ~]# /etc/init.d/moosefs-master stop
[root@server1 ~]# crm
crm(live)# configure
crm(live)configure# property no-quorum-policy=ignore
crm(live)configure# commit
crm(live)configure# property stonith-enabled=true
crm(live)configure# commit
crm(live)configure# primitive vmfence stonith:fence_xvm params pcmk_host_map="sever1:v1;server4:v4" op monitor interval=1min
crm(live)configure# commit
crm(live)configure# primitive vip ocf:heartbeat:IPaddr2 params ip=172.25.40.100 cidr_netmask=32 op monitor interval=30s
crm(live)configure# commit
crm(live)configure# primitive mfsdata ocf:heartbeat:Filesystem params device=/dev/sda1 directory=/var/lib/mfs fstype=ext4 op monitor interval=1min
crm(live)configure# primitive mfsmaster lsb:moosefs-master op monitor interval=30s
crm(live)configure# group mfsgroup vip mfsdata mfsmaster
crm(live)configure# commitMonitoring on [server4] 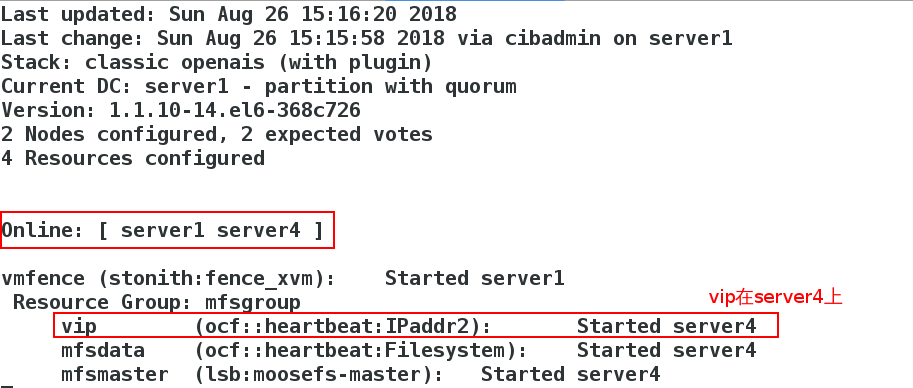
Add resolution. For all hosts in the cluster, including clients, please remove the original resolution. This resolution file will be read from top to bottom
[root@foundation40 cluster]# vim /etc/hosts
172.25.40.250 mfsmaster
[root@server1 cluster]# vim /etc/hosts
172.25.40.100 mfsmaster
[root@server2 ~]# vim /etc/hosts
172.25.40.100 mfsmaster
[root@server3 ~]# vim /etc/hosts
172.25.40.100 mfsmaster
[root@server4 cluster]# vim /etc/hosts
172.25.40.100 mfsmaster[root@server2 ~]# /etc/init.d/moosefs-chunkserver start
[root@server3 ~]# /etc/init.d/moosefs-chunkserver start[root@server4 cluster]# ip addr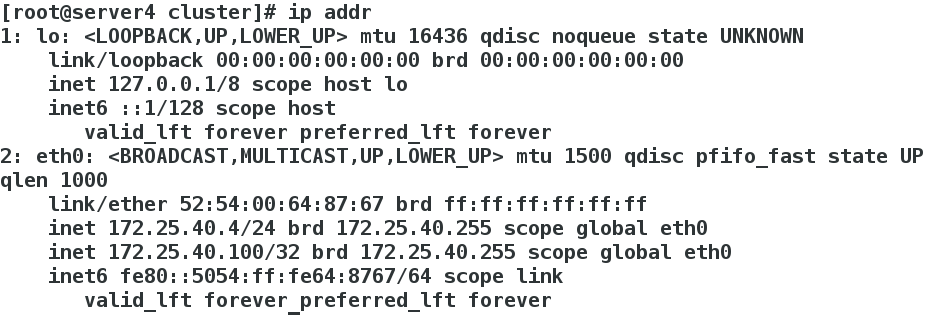
Shut down the server4 node
[root@server4 cluster]# crm node standbyIn server1, server1 takes over server4 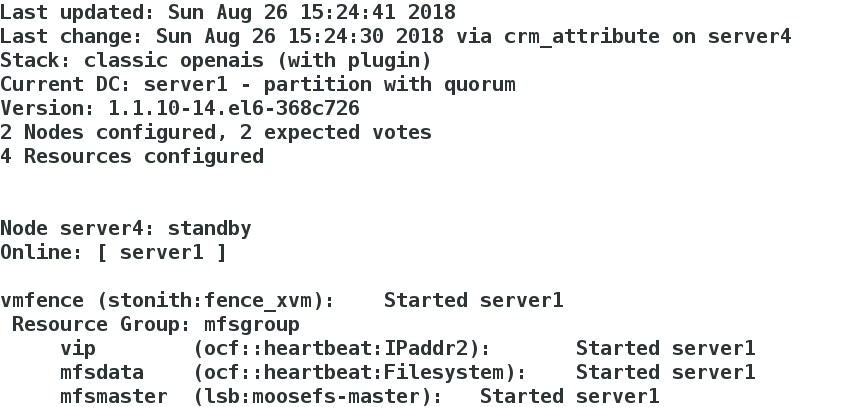
[root@server4 cluster]# crm node online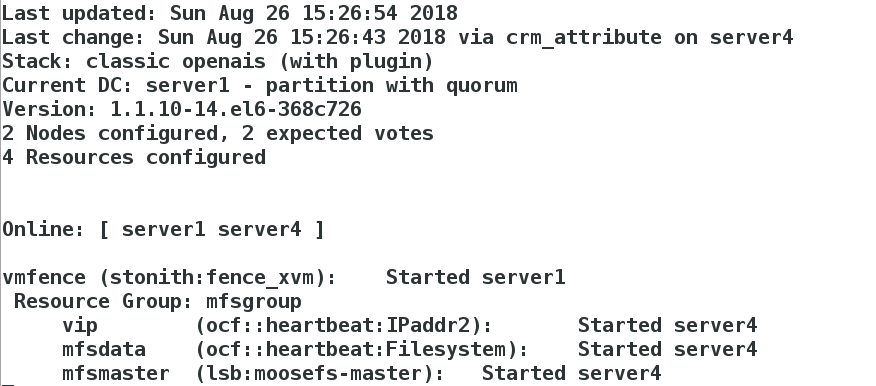
Test:
When writing data, turn off the master to check whether the data can be written normally
[root@foundation40 ~]# cd /mnt/mfs/dir1/
[root@foundation40 dir1]# dd if=/dev/zero of=file1 bs=1M count=2000[root@server4 cluster]# crm node standbyView monitoring 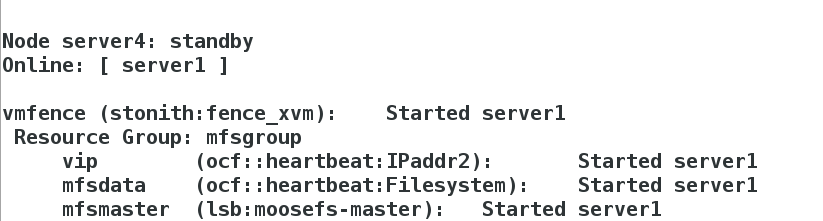
View results
[root@foundation40 dir1]# mfsfileinfo file1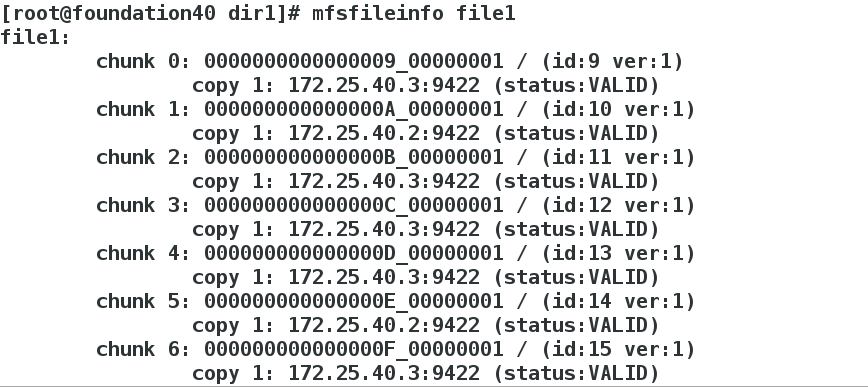
Crash server4
[root@server4 cluster]# echo c > /proc/sysrq-trigger At this time, server4 starts automatically 
Server 1 takes over vip