01. Nacos
1. Introduction
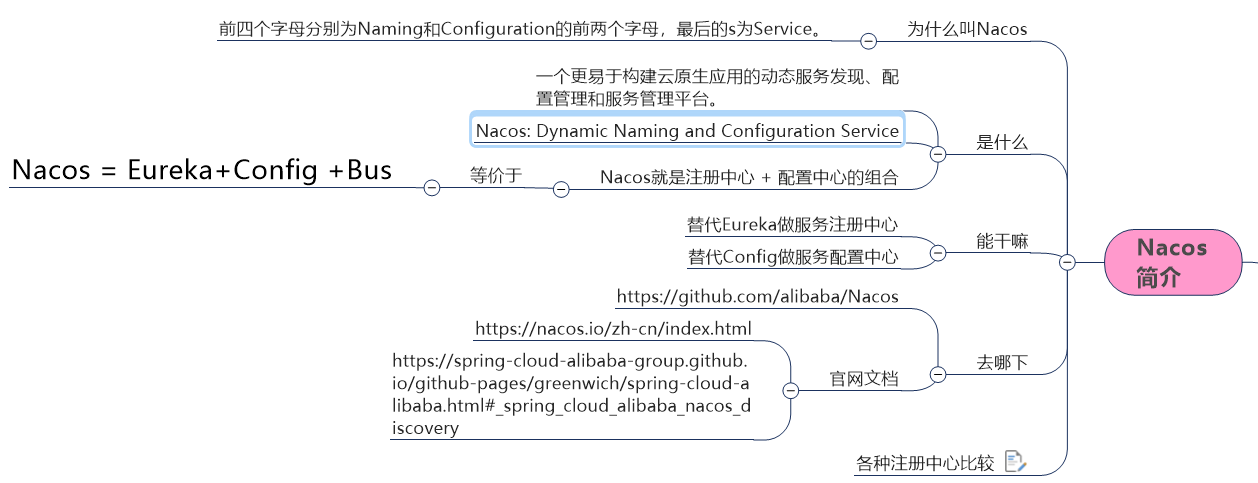
It is said that Nacos has more than 100000 instances running inside Alibaba, which has passed the test of various large traffic such as double 11
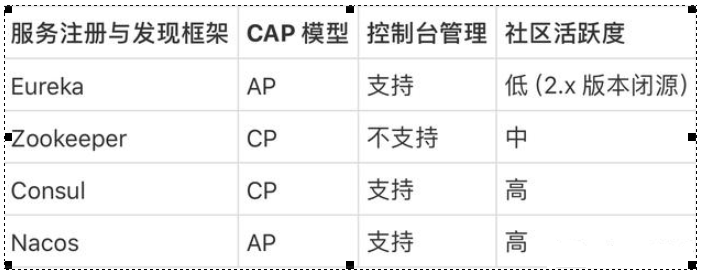
C: Consistency: all nodes see the same data at the same time
A: Availability: all requests receive a response
P: Partition tolerance:
CPA theory focuses on the granularity of data rather than the strategy of overall system design.
At most, two can be satisfied at the same time.
The core of CAP theory is that a distributed system cannot meet the three requirements of consistency, availability and partition fault tolerance at the same time,
Therefore, according to the CAP principle, NoSQL database is divided into three categories: meeting the CA principle, meeting the CP principle and meeting the AP principle:
CA - single point cluster, a system that meets consistency and availability, is usually not very powerful in scalability.
CP - systems that meet consistency and partition tolerance, usually have low performance.
AP - a system that meets the requirements of availability and partition tolerance. Generally, it may have lower requirements for consistency.
2. Installation
install
docker pull nacos/nacos-server:1.1.4
function
docker run -d -p 8848:8848 -e MODE=standalone -e PREFER_HOST_MODE=hostname --restart always --name nacos nacos/nacos-server:1.1.4
3. Integrate nacos
1. Create project
Version limit
<dependencyManagement>
<!--spring cloud alibaba 2.1.0.RELEASE-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.1.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencyManagement>
2. Introduction and dependence
<!--SpringCloud alibaba nacos -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
3. Write yml
server:
port: 9001
spring:
application:
name: nacos-payment-provider
cloud:
nacos:
discovery:
server-addr: 47.98.251.199:8848 #Configure Nacos address
management:
endpoints:
web:
exposure:
include: '*'
4. Main startup
@EnableDiscoveryClient //nacos discovery
@SpringBootApplication
public class PaymentMain9001 {
public static void main(String[] args) {
SpringApplication.run(PaymentMain9001.class,args);
}
}
Multiple instances of a project:
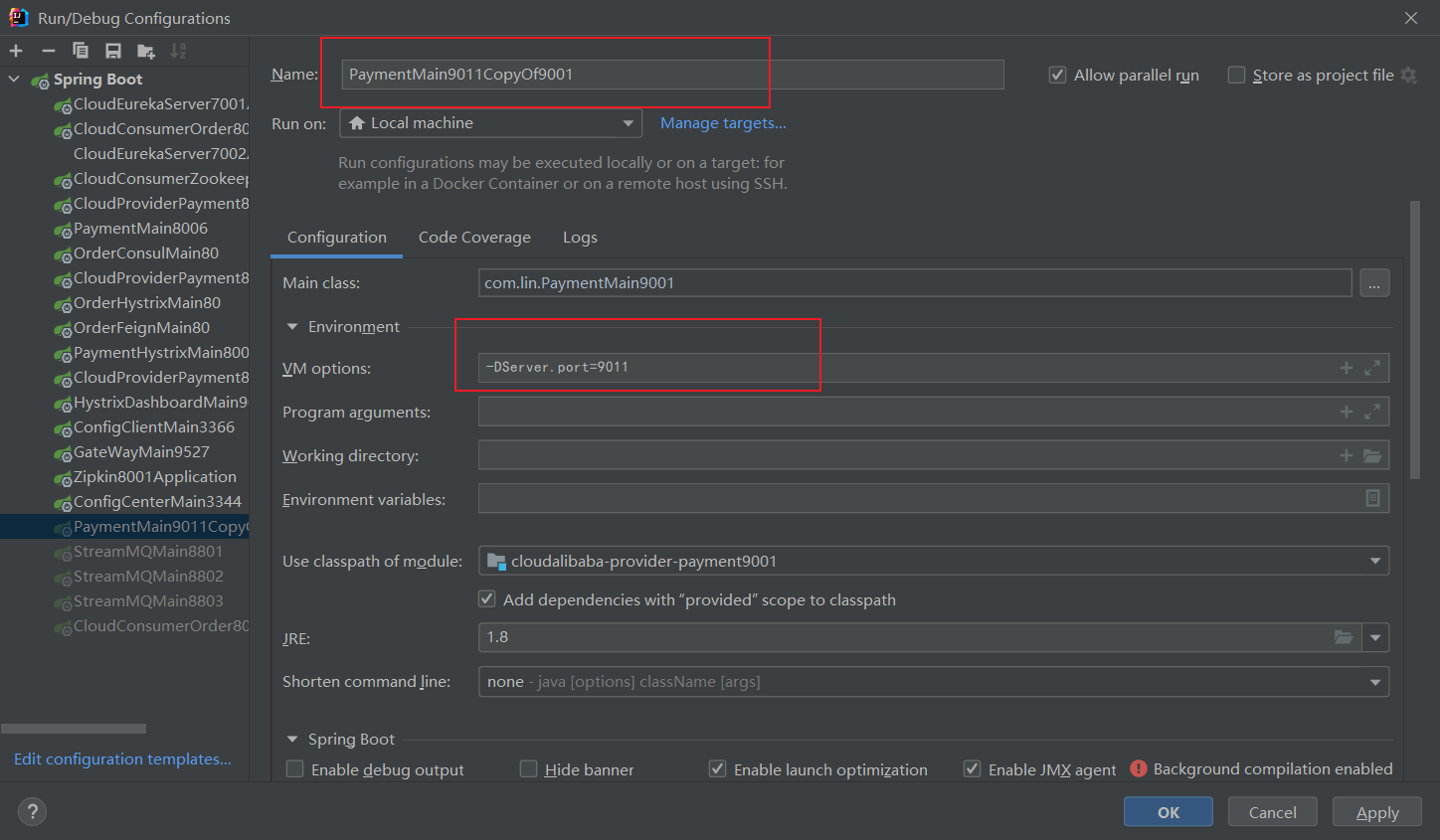
4. Load balancing
Why can Nacos load balance? You can see Netflix by looking at the package structure ribbon
5. nacos and CPA
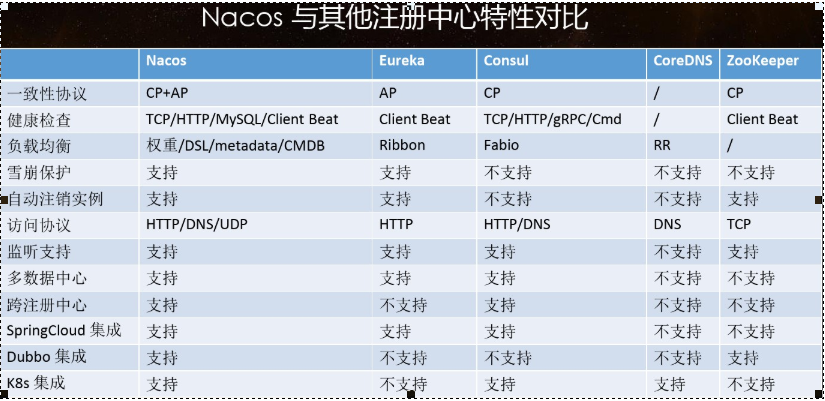
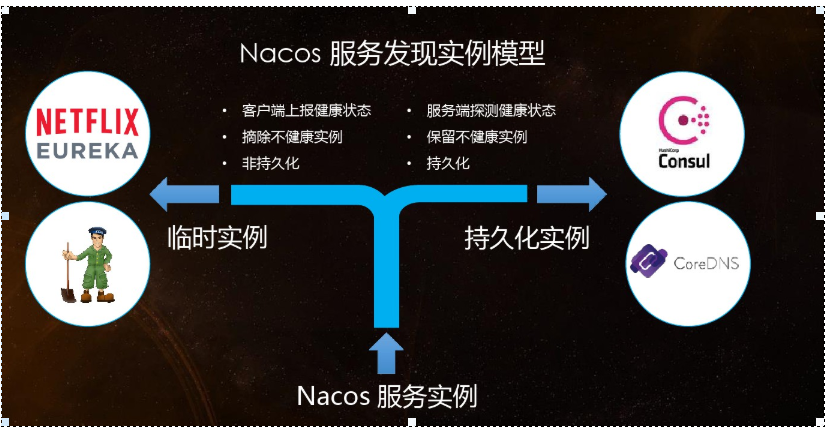
CP and ConAs mode switching support
C is that all nodes see the same data at the same time; The definition of A is that all requests will receive A response.
When to choose which mode to use?
In general,
If you do not need to store service level information, and the service instance is registered through Nacos client and can maintain heartbeat reporting, you can choose AP mode. The current mainstream services, such as Spring cloud and Dubbo services, are applicable to the AP mode. The AP mode weakens the consistency for the possibility of services. Therefore, only temporary instances can be registered in the AP mode.
If you need to edit or store configuration information at the service level, CP is required, and K8S service and DNS service are applicable to CP mode.
In CP mode, persistent instance registration is supported. At this time, the Raft protocol is used as the cluster operation mode. In this mode, the service must be registered before registering the instance. If the service does not exist, an error will be returned.
curl -X PUT '$NACOS_SERVER:8848/nacos/v1/ns/operator/switches?entry=serverMode&value=CP'
6. Configuration center - basic configuration
Nacos is the same as spring cloud config. During project initialization, it is necessary to ensure that the configuration is pulled from the configuration center first,
The normal startup of the project can be guaranteed only after the configuration is pulled.
There is a priority order for loading configuration files in springboot, and the priority of bootstrap is higher than that of application
Nacos will record the historical version of the configuration file, which is retained for 30 days by default. In addition, there is a one click rollback function, and the rollback operation will trigger the configuration update
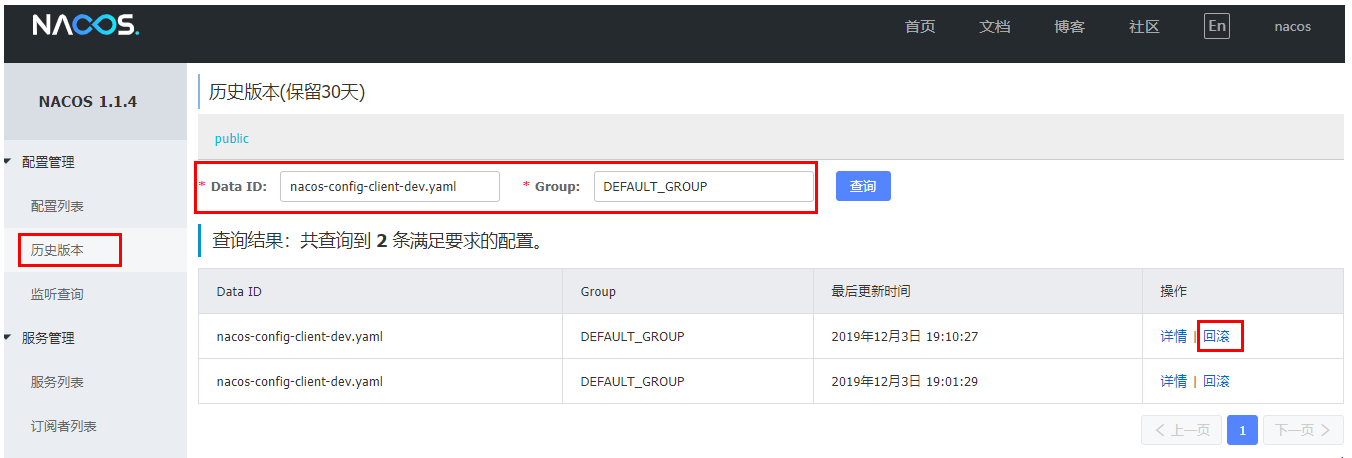
Built in dynamic refresh
Modify the yaml configuration file in Nacos, call the interface to view the configuration again, and you will find that the configuration has been refreshed
Spring cloud needs to send a post request to that... To refresh. Please, this is different. Don't worry about garbled code yet.
7. Configuration center - classified configuration
Question 1:
In actual development, a system is usually prepared
dev development environment
Test test environment
prod production environment.
How to ensure that the service can correctly read the configuration file of the corresponding environment on Nacos when the specified environment is started?
Question 2:
A large-scale distributed microservice system will have many microservice sub projects,
Each micro service project will have a corresponding development environment, test environment, advance environment, formal environment
How to manage these micro service configurations?
1. What is it
Similar to the package name and class name in Java
The outermost namespace can be used to distinguish the deployment environment. Group and DataID logically distinguish two target objects.
2. Three aspects
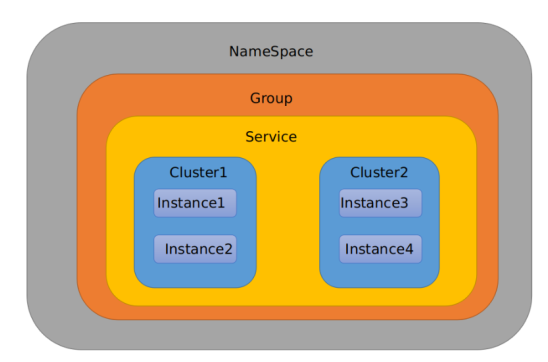
NameSpace,Group,Service
3. Default:
Namespace=public,Group=DEFAULT_GROUP, the default Cluster is default
The default Namespace of Nacos is public, which is mainly used to realize isolation.
For example, we now have three environments: development, testing and production. We can create three namespaces. Different namespaces are isolated.
Group defaults to DEFAULT_GROUP and group can divide different micro services into the same group
Service is a micro service; A service can contain multiple clusters. The DEFAULT Cluster of Nacos is DEFAULT, and the Cluster is a virtual partition of the specified micro service.
For example, for disaster recovery, Service microservices are deployed in Hangzhou computer room and Guangzhou computer room respectively,
At this time, a cluster name (HZ) can be given to the Service micro Service in Hangzhou computer room,
Give a cluster name (GZ) to the Service microservices in Guangzhou computer room, and try to make the microservices in the same computer room call each other to improve performance.
Finally, Instance is the Instance of micro service.
If you forget it again in the future, go back to the spring cloud video review in Silicon Valley.
8. Cluster construction
I didn't study. I hope that in the future, mysql and nacos can play together to build clusters, and then it involves Nigix. I haven't studied this yet, so I can only give up temporarily and come back to learn it in the future.
02. Sentinel
1. Introduction
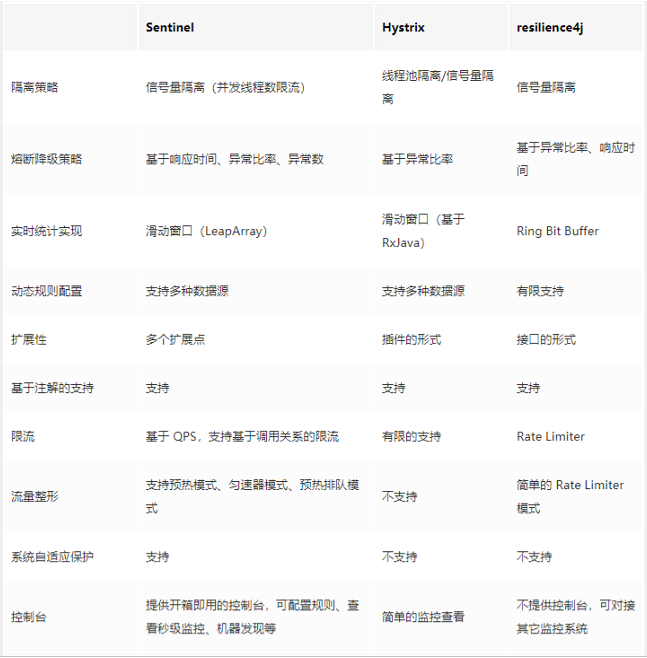
Self statement: like hystrix, do service degradation, service fusing, service current limiting, etc.
Its advantage over hystrix is that the program provides us with an operation interface, and the technology stack it uses is spring boot.
2. Environmental construction
Environment construction:
Here I use the docker installation environment,
docker pull bladex/sentinel-dashboard:1.7.0
docker run --restart=always \ --name sentinel \ -d -p 8858:8858 -d bladex/sentinel-dashboard:1.7.0
You can install it very quickly
Access method: http://47.98.251.199:8858
It will appear that the real-time monitoring page is blank
Even if I have followed the video idea, the same situation still occurs. Finally, I compromised and chose to run the jar package locally to open it
At this time, the access page is http:localhost:8080
3. Initialize the demonstration project
- rely on
<dependencies>
<!--SpringCloud ailibaba nacos -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--SpringCloud ailibaba sentinel-datasource-nacos For subsequent persistence-->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
<!--SpringCloud ailibaba sentinel -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
<!--openfeign-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<!-- SpringBoot integration Web assembly+actuator -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!--Daily general jar Package configuration-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>4.6.3</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
- Some configurations: sentinel configuration
4. Flow control rules
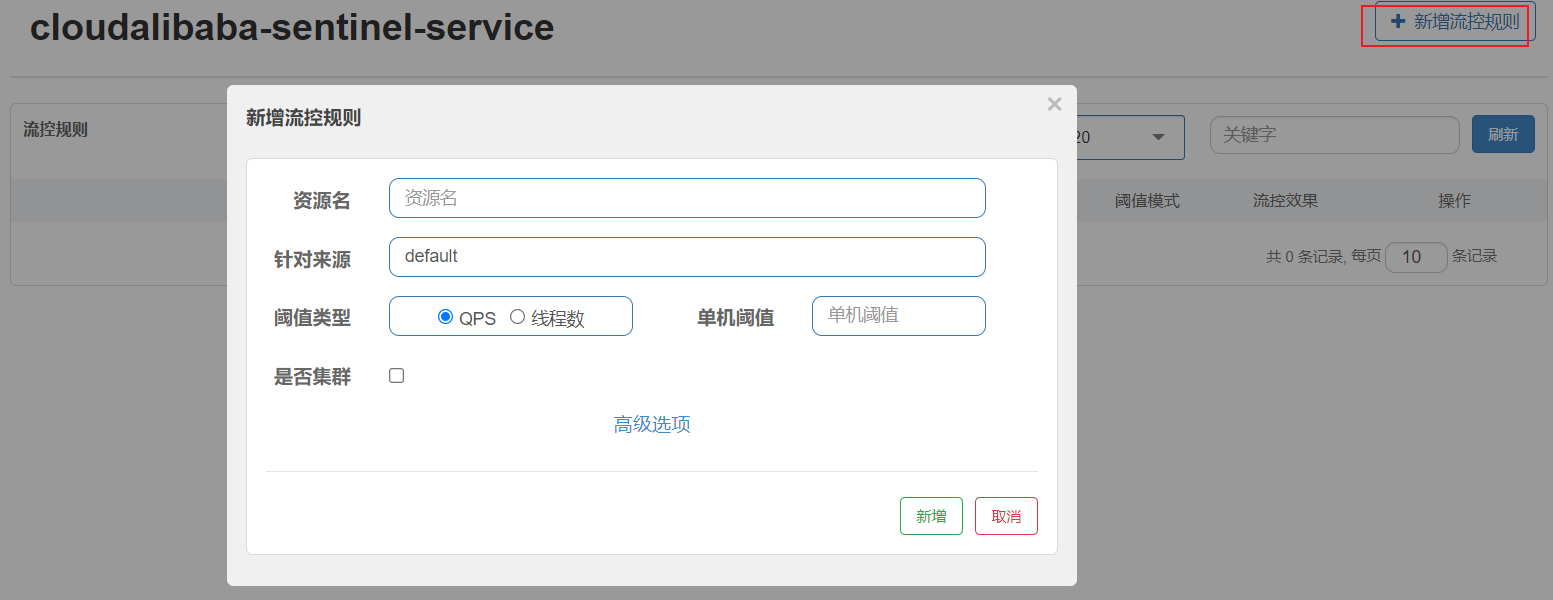
1. Basic introduction
- Resource Name: unique name, default request path
- For source: Sentinel can limit the current for the caller, fill in the micro service name, and the default is default
- Threshold type / single machine threshold:
- QPS (number of requests per second): limit the current when the QPS calling the api reaches the threshold.
- Number of threads: limit the flow when the thread calling the api reaches the threshold
- Cluster: no cluster is required
- Flow control mode:
- Direct: when the api reaches the current limiting condition, the current is limited directly
- Association: when the associated resource reaches the threshold, it limits itself
- Link: only record the traffic on the specified link (the traffic of the specified resource coming in from the entrance resource. If it reaches the threshold, limit the flow [api level for the source])
- Flow control effect:
- Quick failure: direct failure, throw exception
- Warm Up: according to the value of codeFactor (cold loading factor, default 3), the set QPS threshold is reached after preheating time from threshold / codeFactor.
- Queuing: queue at a constant speed to let the request pass at a constant speed. The threshold type must be set to QPS, otherwise it is invalid.
Examples of self attempts:
- Click Configure on the cluster link
- Of course, it can also be configured in the flow control rules. It is recommended to configure it in the cluster link.
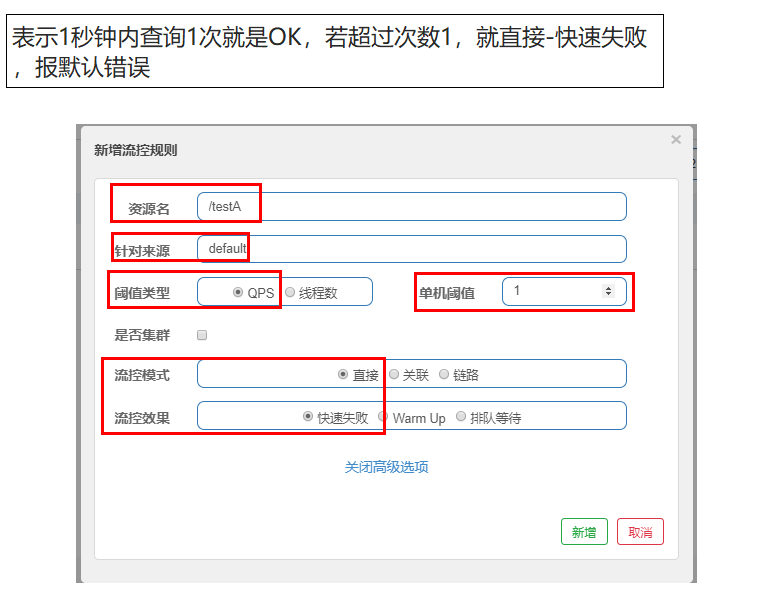
Test results:

On the difference between QPS and the number of threads
- To put it simply and rudely: QPS is blocked outside the door, and the number of threads is beating the dog behind closed doors
QPS will have a door when requesting entry. You can enter as many as you want, and if there is more, you will report an exception
The number of threads is. All requests flow in. There are only as many threads as there are threads. If you can't handle it, you can directly report an error.
We can try it, that is, sleep for a few seconds in the request, and send a few more requests and it will crash directly.
2. Flow control mode
relation
Setting effect (read carefully and don't reverse the primary and secondary)
When the qps threshold of the associated resource / testB exceeds 1, the Rest access address of the current / testA is limited. When the associated resource reaches the threshold, the configured resource name is limited
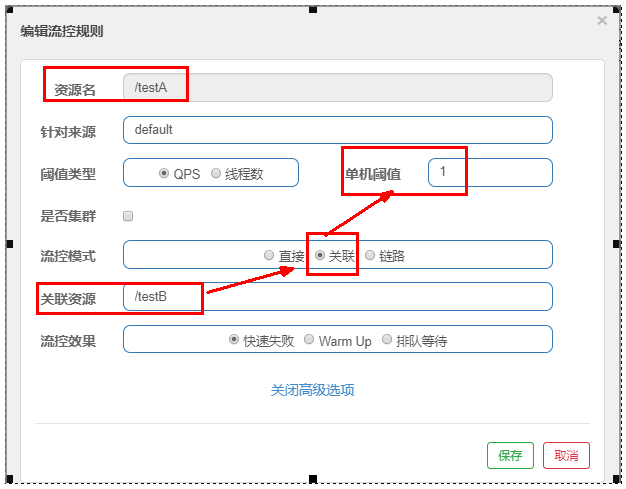
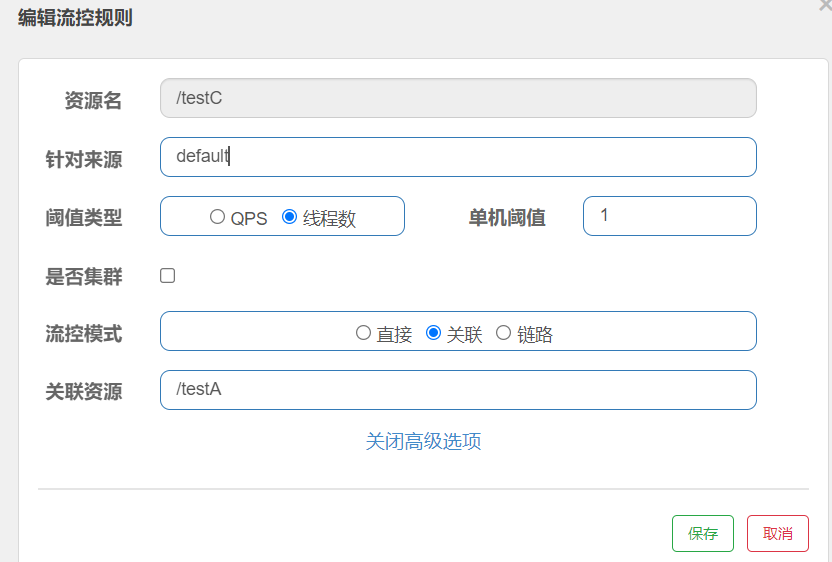
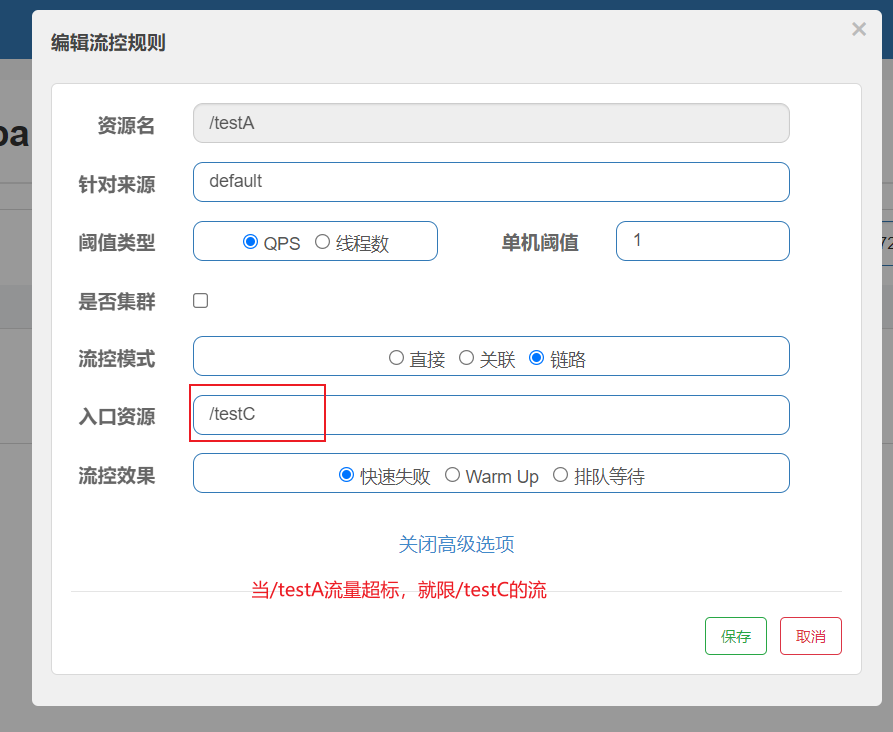
Solution: when / testA cannot handle because there is only one thread, an error will be reported directly when accessing / testC.
(/ testC current limited)
link
Only the traffic on the specified link is recorded (if the traffic of the specified resource coming in from the entrance resource reaches the threshold, the flow will be limited [api level for the source])
3. Flow control effect
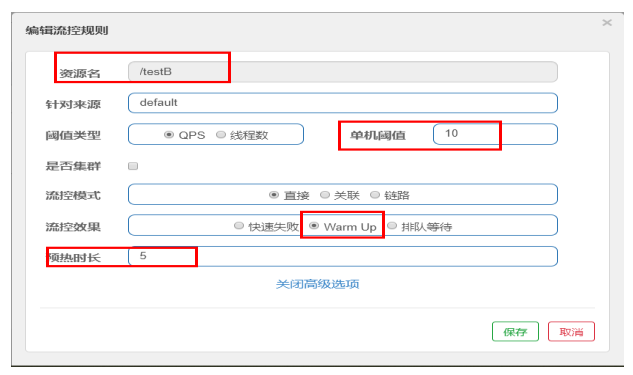
preheat
Formula: divide the threshold value by coldfactor (the default value is 3), and the threshold value will not be reached until it is preheated for a long time
The default coldFactor is 3, that is, how long it takes to warm up the QPS from (threshold / 3) to the set QPS threshold.
In this case, the threshold value is 10 + the preheating duration is set for 5 seconds.
The threshold value of system initialization is 10 / 3, which is about 3, that is, the threshold value is 3 at the beginning; Then it took 5 seconds for the threshold to rise slowly and return to 10
Application scenario
For example, when the second kill system is turned on, there will be a lot of flow, which is likely to kill the system. The preheating method is to slowly put the flow in to protect the system and slowly increase the threshold to the set threshold.
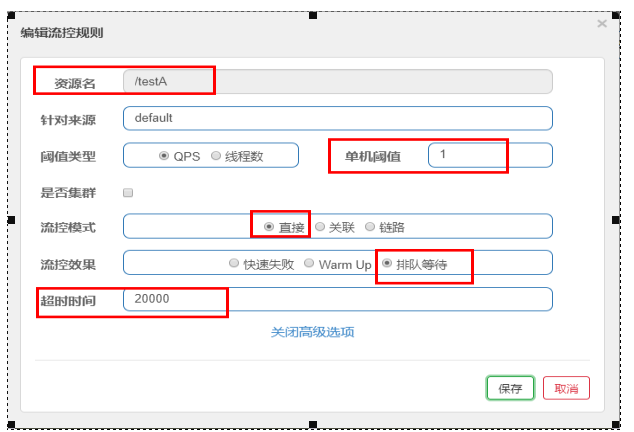
Queue up
Queue at a uniform speed to allow requests to pass at a uniform speed. The threshold type must be set to QPS, otherwise it is invalid.
Setting Meaning: / testA requests once per second. If it exceeds, it will queue up and wait. The waiting timeout is 20000 milliseconds.
At first, I misunderstood the function of overtime waiting. Now I feel that the function of this is to report an error when it needs to wait for 20 seconds.
5. Degradation rules
Basic introduction
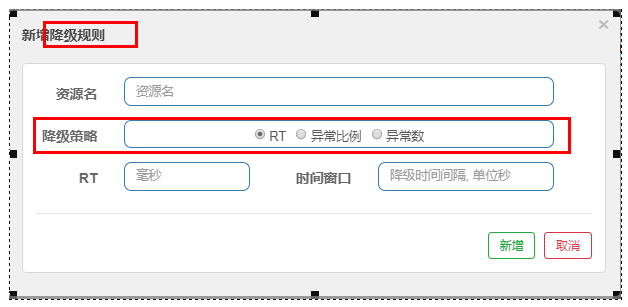
RT (average response time in seconds)
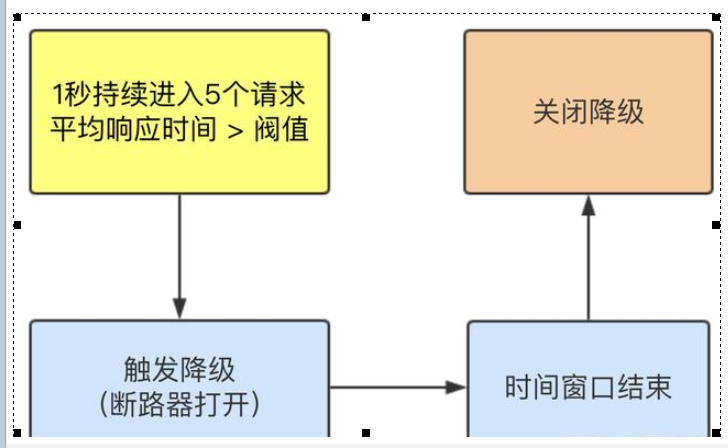
The average response time exceeds the threshold and the request passed within the time window > = 5. The degradation is triggered after the two conditions are met at the same time
After the closing period of the circuit breaker
RT maximum 4900 (larger ones can only take effect through - DCSP. Sentinel. Statistical. Max.rt = XXXX)
Abnormal ratio column (in seconds)
When QPS > = 5 and the abnormal proportion (second level statistics) exceeds the threshold, the degradation is triggered; When the time window is over, turn off the downgrade
Different constant (minute level)
When the abnormal constant (minute Statistics) exceeds the threshold, the degradation is triggered; When the time window is over, turn off the downgrade
Sentinel's circuit breaker is not half open
RT
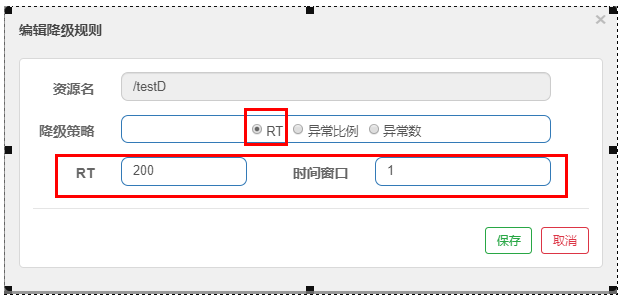
When the average access time for five times is 200ms, the access will report an error during the time window period. When the time window period ends, it will return to normal.

Abnormal proportion

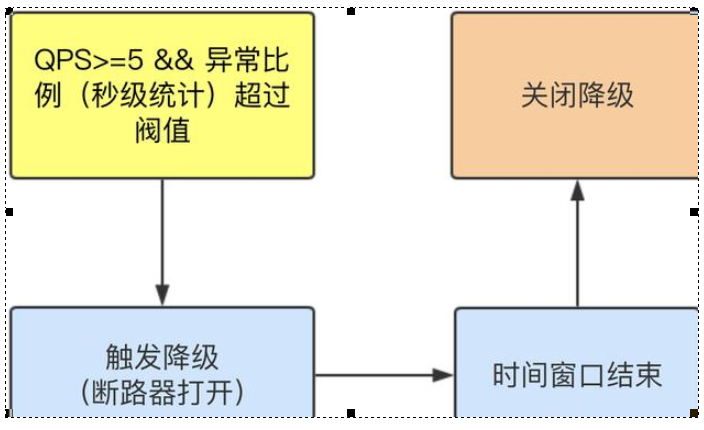
According to the above configuration,
If you visit alone, you must report an error once (int age = 10/0), adjust it once and make an error once;
After jmeter is enabled, the request is sent directly with high concurrency, and the multiple calls meet our configuration conditions.
When the circuit breaker is opened (the fuse trips), the microservice is unavailable, and the error is no longer reported, but the service is degraded.
Different constant

The time window must be greater than or equal to 60 seconds.
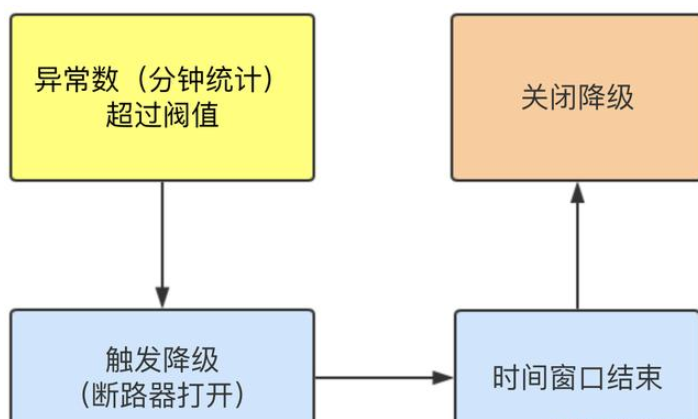
6. Current limiting
What is it?
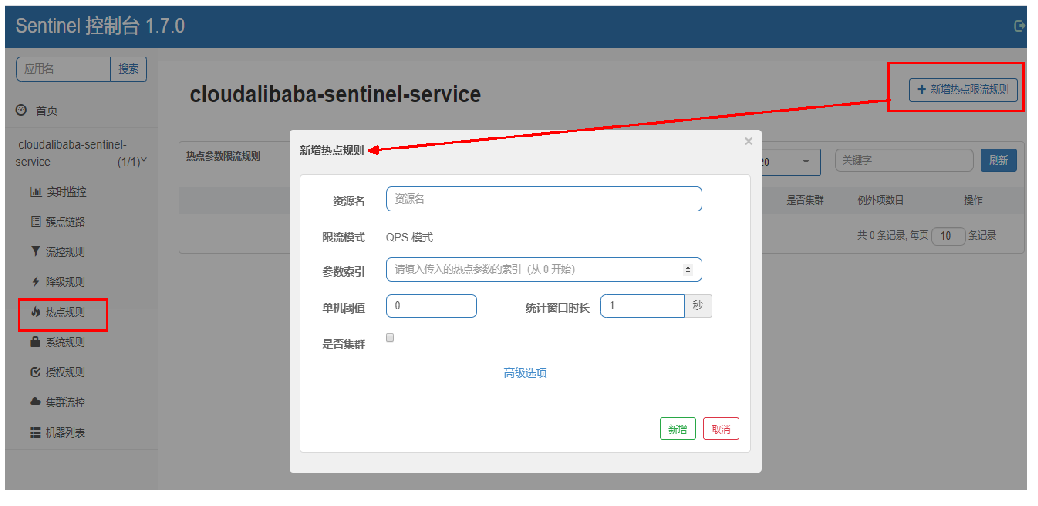
The second is recommended:

Configuration and testing
@GetMapping("/testHotKey")
@SentinelResource(value = "testHotKey",blockHandler = "deal_testHotKey")
public String testHotKey(@RequestParam(value = "p1",required = false)String p1
, @RequestParam(value = "p2",required = false)String p2) {
return "testHotKey,"+"p1: "+p1+",p2: "+p2;
}
public String deal_testHotKey(String p1, String p2, BlockException blockException) {
return "testHotKey,"+"p1: "+p1+",p2: "+p2+",error!!!!";
}
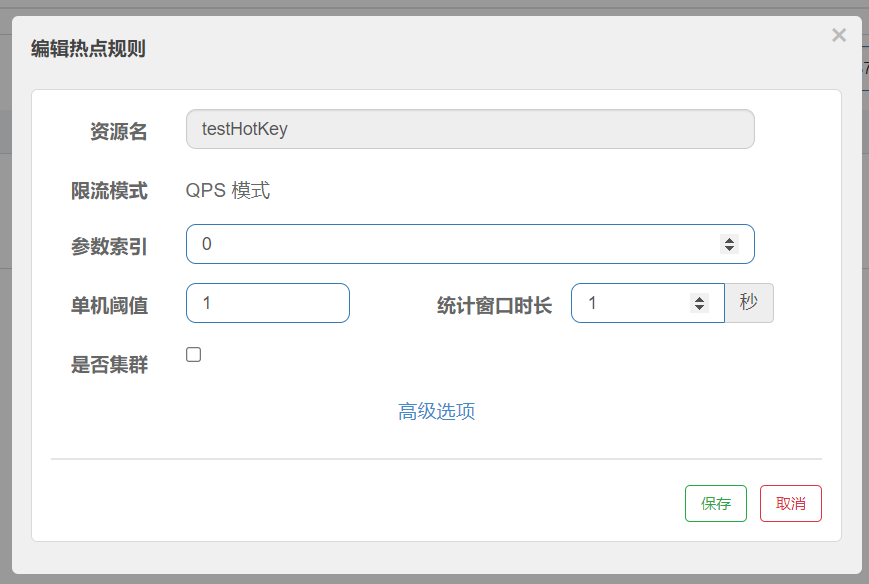
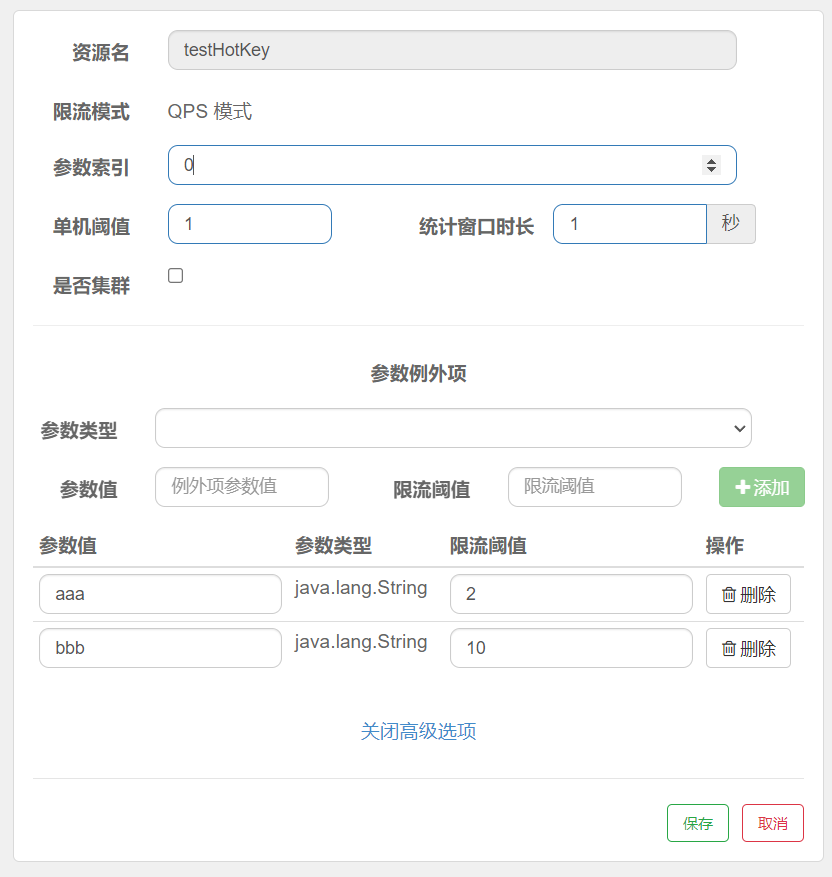
Parameter exceptions
7. System rules
What is it?
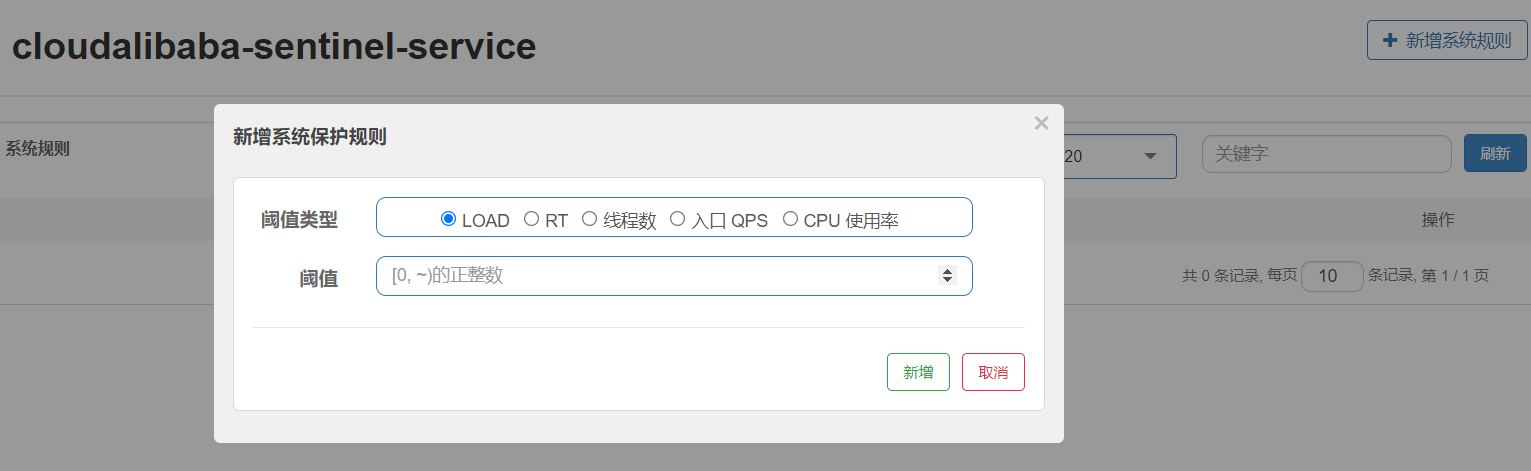
Rule introduction
The system protection rule is to control the entrance flow at the application level, and monitor the application indicators from the dimensions of load, cpu utilization, average RT, entrance QPS and concurrent threads of a single machine, so as to make the system run at the maximum throughput and ensure the overall stability of the system.
System protection rules apply to the overall dimension, not the resource dimension, and are only effective for inlet traffic. Portal traffic refers to the traffic entering the application, such as the requests received by Web services or Dubbo servers, which belong to portal traffic.
System rules support the following modes:
- Load adaptation (only valid for Linux / Unix like machines): load1 of the system is used as the startup index for adaptive system protection. When the system load1 exceeds the set startup value and the current concurrent thread of the system exceeds the estimated system capacity, the maxQPS * minRT estimation of the system will be triggered. The setting reference value is generally: CPU cores * 2.5
- CPU usage (version 1.5.0 +): when the system CPU usage exceeds the threshold, the system protection is triggered (value range: 0.0-1.0), which is sensitive
- Average RT: when the average RT of all inlet flows on a single machine reaches the threshold, the system protection is triggered, and the unit is milliseconds.
- Number of concurrent threads: when the number of concurrent threads of all inlet traffic on a single machine reaches the threshold, the system protection is triggered.
- Inlet QPS: when the QPS of all inlet flows on a single machine reaches the threshold, the system protection is triggered.
8. @SentinelResource
1. The system is default and does not reflect our own business requirements.
2 according to the existing conditions, our customized processing method is coupled with the business code, which is not intuitive.
3 each business method adds a bottom-up, which aggravates the code inflation.
4. The overall unified processing method is not reflected.
1. Customer defined current limiting processing logic
-
Create a CustomerBlockHandler class to customize the flow limiting processing logic
-
Custom current limiting processing class
-
import com.alibaba.csp.sentinel.slots.block.BlockException; import com.lin.entities.CommonResult; public class CustomerBlockHandler { public static CommonResult handleException(BlockException exception){ return new CommonResult(2020,"Customized current limiting processing information......CustomerBlockHandler"); } } -
@GetMapping("/rateLimit/customerBlockHandler") @SentinelResource(value = "customerBlockHandler" ,blockHandlerClass = CustomerBlockHandler.class ,blockHandler = "handleException") public CommonResult customerBlockHandler() { return new CommonResult(200, "Customized current limiting processing logic by customer"); }
9. Service fuse function
fallback method
Close the service degradation method
import com.alibaba.csp.sentinel.annotation.SentinelResource;
import com.alibaba.csp.sentinel.slots.block.BlockException;
import com.lin.entities.CommonResult;
import com.lin.entities.Payment;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
import javax.annotation.Resource;
@RestController
public class CircleBreakerController {
public static final String SERVICE_URL = "http://nacos-payment-provider";
@Resource
private RestTemplate restTemplate;
/**
* Here we first demonstrate the case of fallback
* We have a blockHandler in front of us
* */
@GetMapping("/consumer/fallback/{id}")
@SentinelResource(value = "fallback"
, fallback = "handlerFallback"
,blockHandler = "blockHandler"
,exceptionsToIgnore = {IllegalArgumentException.class}) //fallback is responsible for business exceptions
public CommonResult<Payment> fallback(@PathVariable Long id) {
CommonResult<Payment> result = restTemplate.getForObject(SERVICE_URL + "/paymentSQL/" + id, CommonResult.class, id);
if (id == 4) {
throw new IllegalArgumentException("IllegalArgumentException,Illegal parameter exception....");
} else if (result.getData() == null) {
throw new NullPointerException("NullPointerException,Should ID No corresponding record,Null pointer exception");
}
return result;
}
public CommonResult handlerFallback(@PathVariable Long id, Throwable e) {
Payment payment = new Payment(id, "null");
return new CommonResult<>(444, "Fundus abnormality handlerFallback,exception content " + e.getMessage(), payment);
}
public CommonResult blockHandler(@PathVariable("id") Long id, BlockException blockException) {
Payment payment = new Payment(id,"null");
return new CommonResult(445,"blockHandler-sentinel Current limiting,No such flow: blockException "+blockException.getMessage(),payment);
}
}
Contrast, I haven't seen it yet
10. Rule persistence
1. What is it
Once we restart the application, sentinel rules will disappear, and the production environment needs to persist the configuration rules
2. How to play
Persist the flow restriction configuration rules into Nacos and save them. As long as you refresh a rest address of 8401, you can see the flow control rules on sentinel console. As long as the configuration in Nacos is not deleted, the flow control rules on sentinel on 8401 will remain valid
3. Configuration
spring:
application:
name: cloudalibaba-sentinel-service
cloud:
nacos:
discovery:
#Nacos service registry address
server-addr: 47.98.251.199:8848
sentinel:
transport:
#Configure Sentinel dashboard address
dashboard: localhost:8080
#The default port is 8719. If it is occupied, it will automatically start + 1 scanning from 8719 until the unoccupied port is found
port: 8719
datasource:
ds1:
nacos:
server-addr: 47.98.251.199:8848
dataId: cloudalibaba-sentinel-service
groupId: DEFAULT_GROUP
data-type: json
rule-type: flow
- Just look at the datasource.
Nacos is configured as follows:
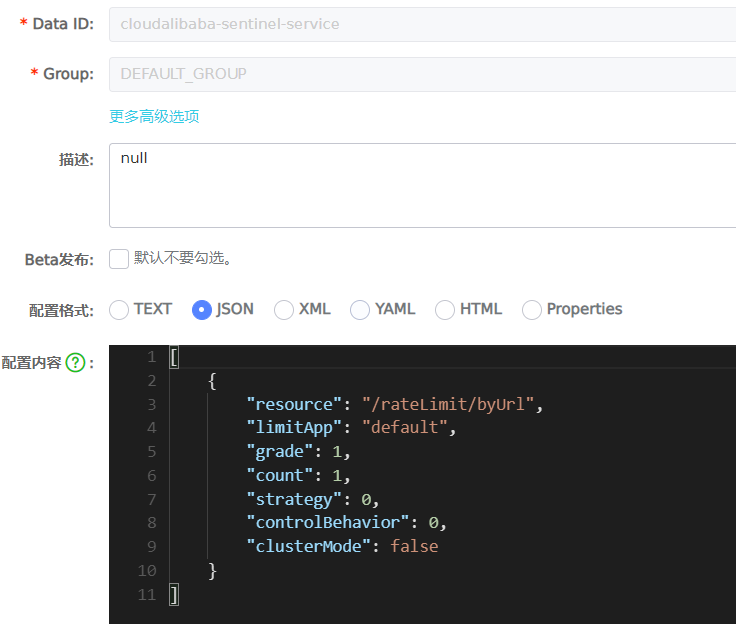
[
{
"resource": "/rateLimit/byUrl",
"limitApp": "default",
"grade": 1,
"count": 1,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
}
]
resource: Resource name; limitApp: Source application; grade: Threshold type, 0 indicates the number of threads and 1 indicates the number of threads QPS; count: Single machine threshold; strategy: Flow control mode, 0 indicates direct, 1 indicates association, and 2 indicates link; controlBehavior: Flow control effect, 0 indicates rapid failure, 1 indicates Warm Up,2 Indicates waiting in line; clusterMode: Cluster or not.
03. Seata
What is it?
Seata is an open source distributed transaction solution, which is committed to providing high-performance and easy-to-use distributed transaction services under the microservice architecture.
What can you do:
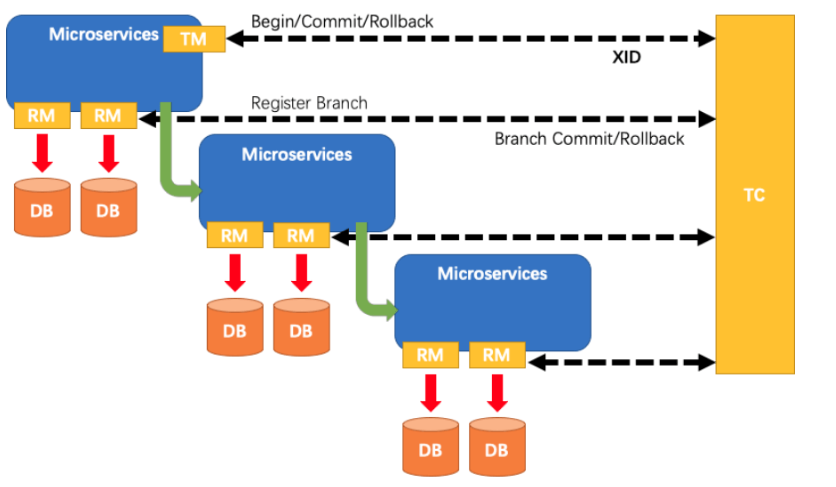
A typical distributed transaction process
- One ID + three component model of distributed transaction processing
Transaction ID XID: globally unique transaction ID
Three component concepts:
- Transaction Coordinator(TC): a transaction coordinator, which maintains the running state of global transactions and is responsible for coordinating and driving global commit or rollback.
- Transaction Manager ™: The protocol that controls the boundary of global transactions, is responsible for starting global transactions and finally initiating global commit or global rollback.
- Resource Manager(RM): controls branch transactions, is responsible for branch registration and status reporting, receives instructions from the transaction coordinator, and drives the submission and rollback of branch (local) transactions.
Processing process
- TM applies to TC to start a global transaction, which is successfully created and generates a globally unique XID;
- XID propagates in the context of microservice invocation link;
- RM registers branch transactions with TC and brings them under the jurisdiction of global transactions corresponding to XID;
- TM initiates a global commit or rollback resolution for XID to TC;
- TC dispatch XID
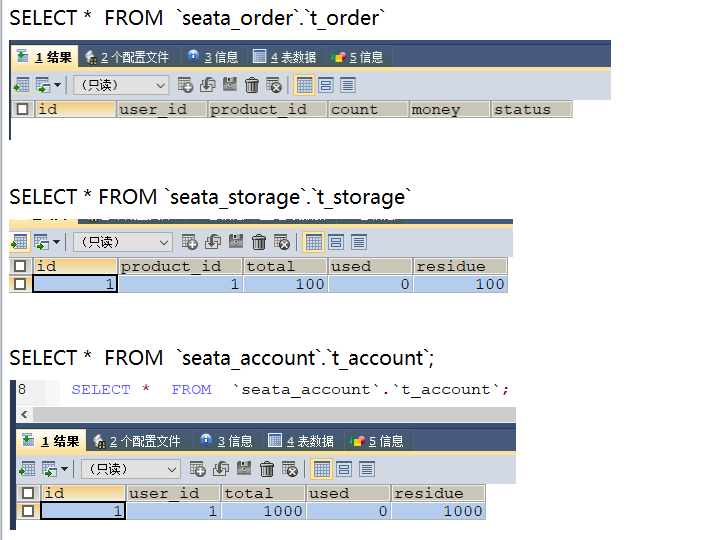
Small project analysis ability
Analyze the database and clarify ideas.
- Imagine that they are on different machines. You don't need to think about all the linked tables
seata's @ GlobalTransactional annotation:
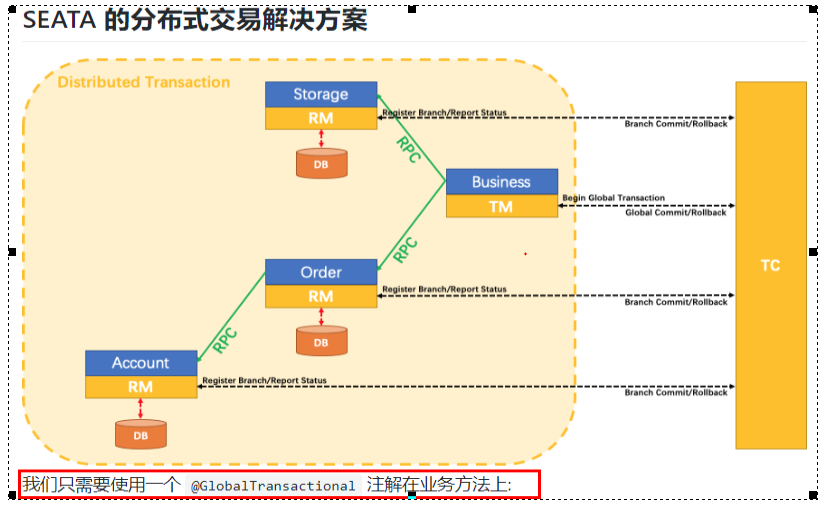
I don't quite understand how to play.
Under config
import com.alibaba.druid.pool.DruidDataSource;
import io.seata.rm.datasource.DataSourceProxy;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.transaction.SpringManagedTransactionFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import javax.sql.DataSource;
@Configuration
public class DataSourceProxyConfig {
@Value("${mybatis.mapperLocations}")
private String mapperLocations;
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource druidDataSource() {
return new DruidDataSource();
}
@Bean
public DataSourceProxy dataSourceProxy(DataSource dataSource) {
return new DataSourceProxy(dataSource);
}
@Bean
public SqlSessionFactory sqlSessionFactoryBean(DataSourceProxy dataSourceProxy) throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSourceProxy);
sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources(mapperLocations));
sqlSessionFactoryBean.setTransactionFactory(new SpringManagedTransactionFactory());
return sqlSessionFactoryBean.getObject();
}
}
cations}")
private String mapperLocations;
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource druidDataSource() {
return new DruidDataSource();
}
@Bean
public DataSourceProxy dataSourceProxy(DataSource dataSource) {
return new DataSourceProxy(dataSource);
}
@Bean
public SqlSessionFactory sqlSessionFactoryBean(DataSourceProxy dataSourceProxy) throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSourceProxy);
sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources(mapperLocations));
sqlSessionFactoryBean.setTransactionFactory(new SpringManagedTransactionFactory());
return sqlSessionFactoryBean.getObject();
}
}