explain
- Detailed implementation ideas and experimental principles are provided here, and most of the code at the skeleton level is provided. Not all codes are provided.
- Complete code. If you really need it, please send a private letter or leave a message.
Overall architecture
- The overall experimental description of lab4 is very lengthy. We need to read it in detail to fully understand what we need to build. If you don't say much, go straight to the figure above:
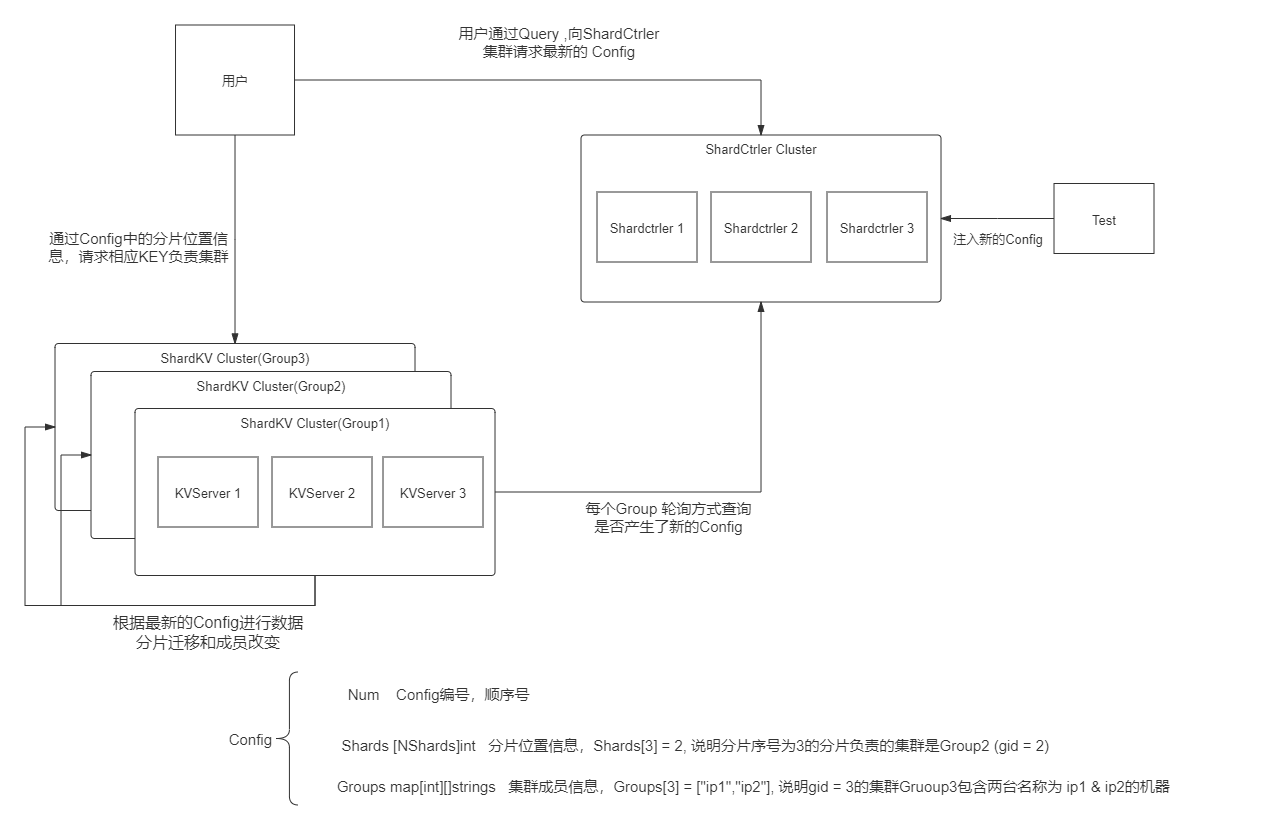
- In this experiment, we want to create a "distributed key value database service that has fragmentation function, can join and exit members, and can synchronously migrate data according to the configuration".
- In Lab4A, we need to construct ShardCtrler. At runtime, multiple ShardCtrler Servers form a Raft managed cluster, which jointly maintains an array [] Config. A Config represents the tester's "latest configuration instruction" to the whole service cluster. The specific understanding of Config is shown in figure. At the same time, shardctrler/client provides an interface to Query the cluster Config information. Therefore, users and subsequent ShardKVCluster can obtain the latest cluster Config information through this interface.
- Lab4B requires us to implement piecewise KeyValue service. The number of slices specified by the system is NShards = 10 We will build multiple shardkv clusters (that is, a Group distinguished by gid), and each Group is responsible for several slices (at least one).
- The shards that each Group is responsible for will vary according to the Config information. Therefore, after having a new Config, these groups need to migrate to each other according to their needs. During the migration process, the corresponding partition cannot provide external services.
- The client obtains the Shard to which the KEY to be operated belongs according to the hash function. After querying the Config information, the client can get which Group the Shard belongs to is responsible for. Then go to the corresponding Group Raft Leader to request operation data.
Several integral problems
-
One important thing is that Lab4 and seperately B test will consume CPU resources, and Goroutine has an 8128 limit in go race mode. Therefore, we should try to reduce the RPC traffic in the program and avoid unnecessary and redundant communication. The most important thing about this is that many things, such as SendDataToOtherGroup, try to do it alone through the Leader, and then synchronize the results to everyone after success.
-
The whole experiment is actually an extended version of Lab3. The operations include get, put and append, which extend to JOIN, LEAVE, MOVE and the Command type you define later. The common processing flow of these commands is:
-
- All staff monitor, but can only be triggered at the Leader. The trigger method may be receiving a Client request or triggered by other function calls in the local procedure.
-
- The Leader detects the trigger conditions and execution conditions. If they are met, the Op is handed over to Raft for synchronization. According to the situation, WaitChan can be set to wait for the synchronization result.
-
- Raft apply Command can be received by every Server in group. Each Server performs [Duplicate Detection] - [ExeCommandWithArgs] - [snapshotraft stateifneed] - [SendMessageToWaitChanIfNeed] separately according to the Command
-
- The Leader receives the execution result information sent by his RaftCommandApplier to WaitChan and returns it to the client or retry.
-
-
Whether it is the pull of NewConfig or data migration, it is essentially such a process. It's just that Lab3 defines two for you and Lab4 lets you design two by yourself.
Lab4A
whole
- Here we are going to implement the "configuration management service" part of the cluster. First, let's understand the meaning of several operations:
- Join: new Group information.
- Leave: which groups are leaving.
- Move: assign Shard to GID's Group, no matter where it was originally.
- Query: query the latest Config information.
- In fact, it can be seen here that it is very similar to Lab3 we have implemented Join, leave and move are actually putappend and query is Get Therefore, we only need to modify the code logic of Lab3. The main modifications are:
- Replace several major operations.
- After joining and leaving, rebalance the load according to the partition distribution In fact, each cluster is responsible for roughly the same number of slices, and data migration is carried out as little as possible.
- Some details.
- For the rest, there are quite a few such as "repeated command detection". Therefore, we can copy the code of lab3B first. Only through the test of lab4A, we don't need to implement snapshot.
Client
- Almost no modification is required, which is the same as lab3. Add ClientID and requestid to detect duplicate, or record the LeaderId of the last successful visit for access optimization. Let's take Join as an example. The code is:
func (ck *Clerk) Join(servers map[int][]string) {
ck.requestId++
server := ck.recentLeaderId
args := &JoinArgs{Servers: servers,ClientId: ck.clientId,Requestid: ck.requestId}
for {
reply := JoinReply{}
ok := ck.servers[server].Call("ShardCtrler.Join", args, &reply)
if !ok || reply.Err == ErrWrongLeader {
server = (server+1)%len(ck.servers)
continue
}
// try each known server.
if reply.Err == OK {
ck.recentLeaderId = server
return
}
time.Sleep(RequsetIntervalTime * time.Millisecond)
}
}
Server
- The logic is the same as that of Lab3. After receiving the Client request, the Server delivers the Raft and specifies the Channel to wait for the result. The Raft continues to apply the command, performs response operations and de duplication, and then returns the result to the Wati Channel, so as to return it to the user.
- When specifying the Wait Channel, you need to set the timeout mechanism.
- ReBalance Shards [] is required after join & leave
- We still take Join as an example:
- Join RPC Handler :
func (sc *ShardCtrler) Join(args *JoinArgs, reply *JoinReply) {
if _,ifLeader := sc.rf.GetState(); !ifLeader {
reply.Err = ErrWrongLeader
return
}
op := Op{Operation: JoinOp, ClientId: args.ClientId, RequestId: args.Requestid, Servers_Join: args.Servers}
raftIndex,_,_ := sc.rf.Start(op)
// create WaitForCh
sc.mu.Lock()
chForRaftIndex, exist := sc.waitApplyCh[raftIndex]
if !exist {
sc.waitApplyCh[raftIndex] = make(chan Op, 1)
chForRaftIndex = sc.waitApplyCh[raftIndex]
}
sc.mu.Unlock()
select {
case <- time.After(time.Millisecond*CONSENSUS_TIMEOUT):
if sc.ifRequestDuplicate(op.ClientId, op.RequestId){
reply.Err = OK
} else {
reply.Err = ErrWrongLeader
}
case raftCommitOp := <-chForRaftIndex:
if raftCommitOp.ClientId == op.ClientId && raftCommitOp.RequestId == op.RequestId {
reply.Err = OK
} else {
reply.Err = ErrWrongLeader
}
}
sc.mu.Lock()
delete(sc.waitApplyCh, raftIndex)
sc.mu.Unlock()
return
}
- RaftCommand Join Handler
func (sc *ShardCtrler) ExecJoinOnController(op Op) {
sc.mu.Lock()
sc.lastRequestId[op.ClientId] = op.RequestId
sc.configs = append(sc.configs,*sc.MakeJoinConfig(op.Servers_Join))
sc.mu.Unlock()
}
func (sc *ShardCtrler) MakeJoinConfig(servers map[int][]string) *Config {
lastConfig := sc.configs[len(sc.configs)-1]
tempGroups := make(map[int][]string)
for gid, serverList := range lastConfig.Groups {
tempGroups[gid] = serverList
}
for gids, serverLists := range servers {
tempGroups[gids] = serverLists
}
GidToShardNumMap := make(map[int]int)
for gid := range tempGroups {
GidToShardNumMap[gid] = 0
}
for _, gid := range lastConfig.Shards {
if gid != 0 {
GidToShardNumMap[gid]++
}
}
if len(GidToShardNumMap) == 0 {
return &Config{
Num: len(sc.configs),
Shards: [10]int{},
Groups: tempGroups,
}
}
return &Config{
Num: len(sc.configs),
Shards: sc.getBalancedShards(GidToShardNumMap,lastConfig.Shards),
Groups: tempGroups,
}
}
Balance Config.Shards[]
- The function of Balance is to Balance the number of Shards managed by each group, and reproduce the modified allocation in a cost-effective manner.
- The Balance requirement is a deterministic algorithm, that is, in a state of Shards [], the Balance method is run multiple times, and multiple Shards [] are the same.
- How to define equilibrium? For example, 4 groups and 10 Shards, I should be 3322
- We have:
// subNum of Groups manange average+1 Shards // length-subNum of Groups manange average Shards length := len(GidToShardNumMap) average := NShards / length subNum := NShards % length
- The overall idea of balance is to sort ShardsNum in the existing Groups. Starting from the most, according to the calculated above indicators, you can refund more and supplement less Shards.
- code:
func (sc *ShardCtrler) getBalancedShards(GidToShardNumMap map[int]int, lastShards [NShards]int) [NShards]int {
length := len(GidToShardNumMap)
average := NShards / length
subNum := NShards % length
// sort Gid to a []int according to ShardNum
realSortNum := realNumArray(GidToShardNumMap)
// Multi retreat
for i := length - 1; i >= 0; i-- {
resultNum := average
if !ifAvg(length,subNum,i){
resultNum = average+1
}
if resultNum < GidToShardNumMap[realSortNum[i]] {
fromGid := realSortNum[i]
changeNum := GidToShardNumMap[fromGid] - resultNum
for shard, gid := range lastShards {
if changeNum <= 0 {
break
}
if gid == fromGid {
lastShards[shard] = 0
changeNum -= 1
}
}
GidToShardNumMap[fromGid] = resultNum
}
}
// Less compensation
for i := 0; i < length; i++ {
resultNum := average
if !ifAvg(length,subNum,i){
resultNum = average+1
}
if resultNum > GidToShardNumMap[realSortNum[i]] {
toGid := realSortNum[i]
changeNum := resultNum - GidToShardNumMap[toGid]
for shard, gid := range lastShards{
if changeNum <= 0 {
break
}
if gid == 0 {
lastShards[shard] = toGid
changeNum -= 1
}
}
GidToShardNumMap[toGid] = resultNum
}
}
return lastShards
}
Lab4B
whole
- The whole is still based on the framework of Lab3 mode, but the original kvDB is divided into multiple groups in the form of Shard. The Client needs to get and put in the corresponding groups.
- We need to design how to realize the fragment storage of data.
- We need to design how to migrate data efficiently.
- How to coordinate the consistency between multiple groups to ensure that dirty data and old data will not be read during data migration.
Client
- For Server Duplication detection, provide ClientID and requestid, which will not be detailed here. You can read the rest of the code without modification. Note the positional relationship between RPC args and for {}.
func (ck *Clerk) Get(key string) string {
ck.requestId++
for {
args := GetArgs{Key: key,ClientId: ck.clientId, RequestId: ck.requestId, ConfigNum: ck.config.Num}
shard := key2shard(key)
gid := ck.config.Shards[shard]
if servers, ok := ck.config.Groups[gid]; ok {
// try each server for the shard.
for si := 0; si < len(servers); si++ {
srv := ck.make_end(servers[si])
var reply GetReply
ok := srv.Call("ShardKV.Get", &args, &reply)
if ok && (reply.Err == OK || reply.Err == ErrNoKey) {
return reply.Value
}
if ok && (reply.Err == ErrWrongGroup) {
break
}
// ... not ok, or ErrWrongLeader
}
}
time.Sleep(100 * time.Millisecond)
// ask controler for the latest configuration.
ck.config = ck.sm.Query(-1)
}
return ""
}
Server
- Server's work is a superset of Lab3Server's work. It needs to do two additional things:
- Regularly query the new Config of shardctrler. If Num is greater than its existing Config, Apply New Config. However, it is also necessary to synchronize to the cluster through Raft first.
- If New Config Shards [] changes from the past, there may be data migration requirements for itself. Last Config. Shards[x] == kv. me & New. Config. Shards[x] != kv. Me, that is, data migration out, or vice versa. This migration task is executed in an independent thread. After migration, the migration needs to be completed through Raft synchronization.
- Then add several judgment conditions when accepting the Client request. If the Shard does not belong to me, ErrWrongGroup. If it is unavailable (migrating), ErrWrongLeader
type ShardKV struct {
mu sync.Mutex
me int
rf *raft.Raft
dead int32
applyCh chan raft.ApplyMsg
make_end func(string) *labrpc.ClientEnd
gid int // Use config.Shards ==> server contians which shards
ctrlers []*labrpc.ClientEnd
mck *shardctrler.Clerk
maxraftstate int // snapshot if log grows this big
// Your definitions here.
kvDB []ShardComponent // every Shard has it's independent data MAP & ClientSeq MAP
waitApplyCh map[int]chan Op // RaftCommandIndex -> chan Op , Only in Leader
// last SnapShot point , raftIndex
lastSSPointRaftLogIndex int
config shardctrler.Config
// ShardX if migrateing --> true
migratingShard [NShards]bool
}
ApplyNew Config On KVServer Cluster
- According to the above Command common processing flow, we design a Loop to regularly pass through the internal shardctrler The client object queries the new Config. If Config If num is larger than itself, submit a NewConfigOp to Raft to let everyone install the NewConfig together after Raft Apply to ensure consistency.
func (kv *ShardKV) PullNewConfigLoop() {
for !kv.killed(){
kv.mu.Lock()
lastConfigNum := kv.config.Num
_,ifLeader := kv.rf.GetState()
kv.mu.Unlock()
if !ifLeader{
continue
}
newestConfig := kv.mck.Query(lastConfigNum+1)
if newestConfig.Num == lastConfigNum+1 {
// Got a new Config
op := Op{Operation: NEWCONFIGOp, Config_NEWCONFIG: newestConfig}
kv.mu.Lock()
if _,ifLeader := kv.rf.GetState(); ifLeader{
kv.rf.Start(op)
}
kv.mu.Unlock()
}
time.Sleep(CONFIGCHECK_TIMEOUT*time.Millisecond)
}
}
// Apply New Config After Raft Apply it
// imgratingShard[] will be explained after this blog
func (kv *ShardKV) ExecuteNewConfigOpOnServer(op Op){
kv.mu.Lock()
defer kv.mu.Unlock()
newestConfig := op.Config_NEWCONFIG
if newestConfig.Num != kv.config.Num+1 {
return
}
// all migration should be finished
for shard := 0; shard < NShards;shard++ {
if kv.migratingShard[shard] {
return
}
}
kv.lockMigratingShards(newestConfig.Shards)
kv.config = newestConfig
}
Shard Migration between KVServer Clusters
-
The design of data migration mainly considers the following questions, and we give the answers one by one.
-
- Storage method of data Shard
We used to store data using a kV DB = map [key] value, and a map[ClientId]LastRequestId is needed to help record the access of each client for de duplication. The storage of fragments is the same, but we need to store multiple fragments. We need an array to store the separate dB and ClientSeq of each fragment. Define a data structure, similar to the following, to represent fragmented data. At different times, the number of shards managed by the Server varies, but because the total number is fixed, we do not apply for variable length arrays, but apply for fixed [10]. It is also possible to use array subscripts to represent ShardIndex.
- Storage method of data Shard
type ShardComponent struct { ShardIndex int KVDBOfShard map[string]string ClientRequestId map[int64]int } // Server memeber keyValueDB [NShards]ShardComponet-
- How to monitor and trigger fragment migration
Fragment migration must take place in the process of adding oldconfig -- > newconfig. Our listening status is:
Whether there is data to be migrated: ifshardxneedmigrate = newconfig Shards[X] != OldConfig. Shards[X]
if NewConfig.Shards[X] == kv.me shows that x is my new responsibility and should be accepted
if OldConfig.Shards[X] == kv.me indicates that x is what I should send to others
Otherwise it has nothing to do with me
Data migration is triggered when the sent data is required
- How to monitor and trigger fragment migration
-
- How to synchronize migration results with Group Follower
Data migration is nothing more than that the Leader does two things: "send the array that no longer belongs to me to its new home, then I delete the data myself, and synchronize the deleted data to everyone" & "accept the data sent to me by others, We need to design a MigrateShards RPC to send and receive fragment data, and we need to synchronize data through Raft.
- How to synchronize migration results with Group Follower
-
- How to ensure denial of service during migration and avoid dirty reading and old data
We designed one
It indicates whether ShardX is in the process of migration. The former one will reject the service request. After the migration is completed, it will be False. Equivalent to a fine-grained lock. Loop listens to this array and migrates data if any data is locked.//Server member isShardMigrateing [NShards]bool
I won't say much about the logic. Just go to the code: - How to ensure denial of service during migration and avoid dirty reading and old data
-
// Triggered when applying new config, the data to be migrated is locked
func (kv *ShardKV) lockMigratingShards(newShards [NShards]int) {
oldShards := kv.config.Shards
for shard := 0;shard < NShards;shard++ {
// new Shards own to myself
if oldShards[shard] == kv.gid && newShards[shard] != kv.gid {
if newShards[shard] != 0 {
kv.migratingShard[shard] = true
}
}
// old Shards not ever belong to myself
if oldShards[shard] != kv.gid && newShards[shard] == kv.gid {
if oldShards[shard] != 0 {
kv.migratingShard[shard] = true
}
}
}
}
func (kv *ShardKV) SendShardToOtherGroupLoop() {
for !kv.killed(){
kv.mu.Lock()
_,ifLeader := kv.rf.GetState()
kv.mu.Unlock()
if !Leader {
time.Sleep(SENDSHARDS_TIMEOUT*time.Millisecond)
continue
}
noMigrateing := true
kv.mu.Lock()
for shard := 0;shard < NShards;shard++ {
if kv.migratingShard[shard]{
noMigrateing = false
}
}
kv.mu.Unlock()
if noMigrateing{
time.Sleep(SENDSHARDS_TIMEOUT*time.Millisecond)
continue
}
ifNeedSend, sendData := kv.ifHaveSendData()
if !ifNeedSend{
time.Sleep(SENDSHARDS_TIMEOUT*time.Millisecond)
continue
}
kv.sendShardComponent(sendData)
time.Sleep(SENDSHARDS_TIMEOUT*time.Millisecond)
}
}
func (kv *ShardKV) sendShardComponent(sendData map[int][]ShardComponent) {
for aimGid, ShardComponents := range sendData {
kv.mu.Lock()
args := &MigrateShardArgs{ConfigNum: kv.config.Num, MigrateData: make([]ShardComponent,0)}
groupServers := kv.config.Groups[aimGid]
kv.mu.Unlock()
for _,components := range ShardComponents {
tempComponent := ShardComponent{ShardIndex: components.ShardIndex,KVDBOfShard: make(map[string]string),ClientRequestId: make(map[int64]int)}
CloneSecondComponentIntoFirstExceptShardIndex(&tempComponent,components)
args.MigrateData = append(args.MigrateData,tempComponent)
}
go kv.callMigrateRPC(groupServers,args)
}
}
func (kv *ShardKV) callMigrateRPC(groupServers []string, args *MigrateShardArgs){
for _, groupMember := range groupServers {
callEnd := kv.make_end(groupMember)
migrateReply := MigrateShardReply{}
ok := callEnd.Call("ShardKV.MigrateShard", args, &migrateReply)
kv.mu.Lock()
myConfigNum := kv.config.Num
kv.mu.Unlock()
if ok && migrateReply.Err == OK {
// Send to Raft
if myConfigNum != args.ConfigNum || kv.CheckMigrateState(args.MigrateData){
return
} else {
kv.rf.Start(Op{Operation: MIGRATESHARDOp,MigrateData_MIGRATE: args.MigrateData,ConfigNum_MIGRATE: args.ConfigNum})
return
}
}
}
}
MigateShard RPC Handler
func (kv *ShardKV) MigrateShard(args *MigrateShardArgs, reply *MigrateShardReply) {
kv.mu.Lock()
myConfigNum := kv.config.Num
kv.mu.Unlock()
if args.ConfigNum > myConfigNum {
reply.Err = ErrConfigNum
reply.ConfigNum = myConfigNum
return
}
// Out Of Time
if args.ConfigNum < myConfigNum {
reply.Err = OK
return
}
if kv.CheckMigrateState(args.MigrateData) {
reply.Err = OK
return
}
op := Op{Operation: MIGRATESHARDOp, MigrateData_MIGRATE: args.MigrateData, ConfigNum_MIGRATE: args.ConfigNum}
raftIndex, _, _ := kv.rf.Start(op)
// create waitForCh
kv.mu.Lock()
chForRaftIndex, exist := kv.waitApplyCh[raftIndex]
if !exist {
kv.waitApplyCh[raftIndex] = make(chan Op, 1)
chForRaftIndex = kv.waitApplyCh[raftIndex]
}
kv.mu.Unlock()
// timeout
select {
case <-time.After(time.Millisecond * CONSENSUS_TIMEOUT):
kv.mu.Lock()
_, ifLeaderr := kv.rf.GetState()
tempConfig := kv.config.Num
kv.mu.Unlock()
if args.ConfigNum <= tempConfig && kv.CheckMigrateState(args.MigrateData) && ifLeaderr {
reply.ConfigNum = tempConfig
reply.Err = OK
} else {
reply.Err = ErrWrongLeader
}
case raftCommitOp := <-chForRaftIndex:
kv.mu.Lock()
tempConfig := kv.config.Num
kv.mu.Unlock()
if raftCommitOp.ConfigNum_MIGRATE == args.ConfigNum && args.ConfigNum <= tempConfig && kv.CheckMigrateState(args.MigrateData) {
reply.ConfigNum = tempConfig
reply.Err = OK
} else {
reply.Err = ErrWrongLeader
}
}
kv.mu.Lock()
delete(kv.waitApplyCh, raftIndex)
kv.mu.Unlock()
return
}
MigrateData Apply
func (kv *ShardKV) ExecuteMigrateShardsOnServer(op Op){
kv.mu.Lock()
defer kv.mu.Unlock()
myConfig := kv.config
if op.ConfigNum_MIGRATE != myConfig.Num {
return
}
// apply the MigrateShardData On myselt
for _, shardComponent := range op.MigrateData_MIGRATE {
if !kv.migratingShard[shardComponent.ShardIndex] {
continue
}
kv.migratingShard[shardComponent.ShardIndex] = false
kv.kvDB[shardComponent.ShardIndex] = ShardComponent{ShardIndex: shardComponent.ShardIndex,KVDBOfShard: make(map[string]string),ClientRequestId: make(map[int64]int)}
// new shard belong to myself
if myConfig.Shards[shardComponent.ShardIndex] == kv.gid {
CloneSecondComponentIntoFirstExceptShardIndex(&kv.kvDB[shardComponent.ShardIndex],shardComponent)
}
}
}