Int8 quantification process
- Collect histograms of activation values;
- Generate different quantization distributions based on different thresholds;
- Then calculate the relative entropy between each distribution and the original distribution, and then select the one with the least entropy, that is, the one most similar to the original distribution.
MNN quantitative code analysis
Quantization code entry
int main(int argc, const char* argv[]) {
if (argc < 4) {
DLOG(INFO) << "Usage: ./quantized.out src.mnn dst.mnn preTreatConfig.json\n";
return 0;
}
const char* modelFile = argv[1];
const char* preTreatConfig = argv[3];
const char* dstFile = argv[2];
DLOG(INFO) << ">>> modelFile: " << modelFile;
DLOG(INFO) << ">>> preTreatConfig: " << preTreatConfig;
DLOG(INFO) << ">>> dstFile: " << dstFile;
// Load the model to be quantified
std::unique_ptr<MNN::NetT> netT;
{
std::ifstream input(modelFile);
std::ostringstream outputOs;
outputOs << input.rdbuf();
netT = MNN::UnPackNet(outputOs.str().c_str());
}
// temp build net for inference
flatbuffers::FlatBufferBuilder builder(1024);
auto offset = MNN::Net::Pack(builder, netT.get());
builder.Finish(offset);
int size = builder.GetSize();
auto ocontent = builder.GetBufferPointer();
// model buffer for creating mnn Interpreter
std::unique_ptr<uint8_t> modelForInference(new uint8_t[size]);
memcpy(modelForInference.get(), ocontent, size);
std::unique_ptr<uint8_t> modelOriginal(new uint8_t[size]);
memcpy(modelOriginal.get(), ocontent, size);
netT.reset();
netT = MNN::UnPackNet(modelOriginal.get());
// quantize model's weight
DLOG(INFO) << "Calibrate the feature and quantize model...";
// Build the Calibration object, which is responsible for quantification
std::shared_ptr<Calibration> calibration(
new Calibration(netT.get(), modelForInference.get(), size, preTreatConfig));
// Perform quantization and update the parameter to int8
calibration->runQuantizeModel();
// Write the quantized parameters to the json file
calibration->dumpTensorScales(dstFile);
DLOG(INFO) << "Quantize model done!";
// Save the quantized model
flatbuffers::FlatBufferBuilder builderOutput(1024);
builderOutput.ForceDefaults(true);
auto len = MNN::Net::Pack(builderOutput, netT.get());
builderOutput.Finish(len);
{
std::ofstream output(dstFile);
output.write((const char*)builderOutput.GetBufferPointer(), builderOutput.GetSize());
}
return 0;
}
Building Calibration objects
When quantifying, you need to pass in a json configuration file, as shown below.
{"format":"RGB",
"mean":[127.5,127.5,127.5],
"normal":[0.00784314,0.00784314,0.00784314],
"width":224,
"height":224,
"path":"path/to/images/",
"used_image_num":500,
"feature_quantize_method":"KL",
"weight_quantize_method":"MAX_ABS"
}
Calibration constructor
There are three main steps:
1. Parse the json configuration file.
2. Initialize session
3. Initialize tensor map
Calibration::Calibration(MNN::NetT* model, const uint8_t* modelBuffer, const int bufferSize, const std::string& configPath)
: _originaleModel(model) {
// when the format of input image is RGB/BGR, channels equal to 3, GRAY is 1
int channles = 3;
// Parsing the json configuration file
rapidjson::Document document;
{
std::ifstream fileNames(configPath.c_str());
std::ostringstream output;
output << fileNames.rdbuf();
auto outputStr = output.str();
document.Parse(outputStr.c_str());
if (document.HasParseError()) {
MNN_ERROR("Invalid json\n");
return;
}
}
auto picObj = document.GetObject();
ImageProcess::Config config;
config.filterType = BILINEAR;
config.destFormat = BGR;
{
if (picObj.HasMember("format")) {
auto format = picObj["format"].GetString();
static std::map<std::string, ImageFormat> formatMap{{"BGR", BGR}, {"RGB", RGB}, {"GRAY", GRAY}, {"RGBA", RGBA}, {"BGRA", BGRA}};
if (formatMap.find(format) != formatMap.end()) {
config.destFormat = formatMap.find(format)->second;
}
}
}
switch (config.destFormat) {
case GRAY:
channles = 1;
break;
case RGB:
case BGR:
channles = 3;
break;
case RGBA:
case BGRA:
channles = 4;
break;
default:
break;
}
// Set config according to the parameters in the configuration file
config.sourceFormat = RGBA;
std::string imagePath;
_imageNum = 0;
{
if (picObj.HasMember("mean")) {
auto mean = picObj["mean"].GetArray();
int cur = 0;
for (auto iter = mean.begin(); iter != mean.end(); iter++) {
config.mean[cur++] = iter->GetFloat();
}
}
if (picObj.HasMember("normal")) {
auto normal = picObj["normal"].GetArray();
int cur = 0;
for (auto iter = normal.begin(); iter != normal.end(); iter++) {
config.normal[cur++] = iter->GetFloat();
}
}
if (picObj.HasMember("width")) {
_width = picObj["width"].GetInt();
}
if (picObj.HasMember("height")) {
_height = picObj["height"].GetInt();
}
if (picObj.HasMember("path")) {
imagePath = picObj["path"].GetString();
}
if (picObj.HasMember("used_image_num")) {
_imageNum = picObj["used_image_num"].GetInt();
}
if (picObj.HasMember("feature_quantize_method")) {
std::string method = picObj["feature_quantize_method"].GetString();
if (Helper::featureQuantizeMethod.find(method) != Helper::featureQuantizeMethod.end()) {
_featureQuantizeMethod = method;
} else {
MNN_ERROR("not supported feature quantization method: %s\n", method.c_str());
return;
}
}
if (picObj.HasMember("weight_quantize_method")) {
std::string method = picObj["weight_quantize_method"].GetString();
if (Helper::weightQuantizeMethod.find(method) != Helper::weightQuantizeMethod.end()) {
_weightQuantizeMethod = method;
} else {
MNN_ERROR("not supported weight quantization method: %s\n", method.c_str());
return;
}
}
DLOG(INFO) << "Use feature quantization method: " << _featureQuantizeMethod;
DLOG(INFO) << "Use weight quantization method: " << _weightQuantizeMethod;
if (picObj.HasMember("feature_clamp_value")) {
float value = (int)picObj["feature_clamp_value"].GetFloat();
if (value < 0.0f || value > 127.0f) {
MNN_ERROR("feature_clamp_value should be in (0, 127], got: %f\n", value);
return;
}
_featureClampValue = value;
}
if (picObj.HasMember("weight_clamp_value")) {
float value = (int)picObj["weight_clamp_value"].GetFloat();
if (value < 0.0f || value > 127.0f) {
MNN_ERROR("weight_clamp_value should be in (0, 127], got: %f\n", value);
return;
}
_weightClampValue = value;
}
DLOG(INFO) << "feature_clamp_value: " << _featureClampValue;
DLOG(INFO) << "weight_clamp_value: " << _weightClampValue;
if (picObj.HasMember("skip_quant_op_names")) {
auto skip_quant_op_names = picObj["skip_quant_op_names"].GetArray();
for (auto iter = skip_quant_op_names.begin(); iter != skip_quant_op_names.end(); iter++) {
std::string skip_quant_op_name = iter->GetString();
_skip_quant_ops.emplace_back(skip_quant_op_name);
DLOG(INFO) << "skip quant op name: " << skip_quant_op_name;
}
}
if (picObj.HasMember("debug")) {
_debug = picObj["debug"].GetBool();
}
}
std::shared_ptr<ImageProcess> process(ImageProcess::create(config));
_process = process;
// read images file names
Helper::readImages(_imgaes, imagePath.c_str(), &_imageNum);
_initMNNSession(modelBuffer, bufferSize, channles);
_initMaps();
}
- Initialize MNN Session
The reasoning process is the same as MNN, so I won't introduce it here.
Here, two interpreter s and two session s will be created. One is the reasoning of the original model, and the other is used for quantification.
void Calibration::_initMNNSession(const uint8_t* modelBuffer, const int bufferSize, const int channels) {
_interpreterOrigin.reset(MNN::Interpreter::createFromBuffer(modelBuffer, bufferSize));
MNN::ScheduleConfig config;
_sessionOrigin = _interpreterOrigin->createSession(config);
_inputTensorOrigin = _interpreterOrigin->getSessionInput(_sessionOrigin, NULL);
// Initially quantify the weight and inverse quantify
_fake_quant_weights();
flatbuffers::FlatBufferBuilder builder(1024);
auto offset = MNN::Net::Pack(builder, _originaleModel);
builder.Finish(offset);
int size = builder.GetSize();
auto buffer = builder.GetBufferPointer();
_interpreter.reset(MNN::Interpreter::createFromBuffer(buffer, size));
_session = _interpreter->createSession(config);
_inputTensor = _interpreter->getSessionInput(_session, NULL);
_inputTensorDims.resize(4);
auto inputTensorDataFormat = MNN::TensorUtils::getDescribe(_inputTensor)->dimensionFormat;
if (inputTensorDataFormat == MNN::MNN_DATA_FORMAT_NHWC) {
_inputTensorDims[0] = 1;
_inputTensorDims[1] = _height;
_inputTensorDims[2] = _width;
_inputTensorDims[3] = channels;
} else {
_inputTensorDims[0] = 1;
_inputTensorDims[1] = channels;
_inputTensorDims[2] = _height;
_inputTensorDims[3] = _width;
}
if (_featureQuantizeMethod == "KL") {
_interpreter->resizeTensor(_inputTensor, _inputTensorDims);
_interpreter->resizeSession(_session);
_interpreterOrigin->resizeTensor(_inputTensorOrigin, _inputTensorDims);
_interpreterOrigin->resizeSession(_sessionOrigin);
} else if (_featureQuantizeMethod == "ADMM") {
DCHECK((_imageNum * 4 * _height * _width) < (INT_MAX / 4)) << "Use Little Number of Images When Use ADMM";
_inputTensorDims[0] = _imageNum;
_interpreter->resizeTensor(_inputTensor, _inputTensorDims);
_interpreter->resizeSession(_session);
_interpreterOrigin->resizeTensor(_inputTensorOrigin, _inputTensorDims);
_interpreterOrigin->resizeSession(_sessionOrigin);
}
}
Focus on Introduction_ fake_quant_weights() function.
void Calibration::_fake_quant_weights() {
// Find the lamda function of the maximum value (absolute value) in the weight
auto findAbsMax = [&] (const float* weights, const int size) {
float absMax = 0;
for (int i = 0; i < size; i++) {
if (std::fabs(weights[i]) > absMax) {
absMax = std::fabs(weights[i]);
}
}
return absMax;
};
for (const auto& op : _originaleModel->oplists) {
// Skip specifying OPS that do not require quantification, and non revolution
std::vector<std::string>::iterator iter = std::find(_skip_quant_ops.begin(), _skip_quant_ops.end(), op->name);
if (iter != _skip_quant_ops.end()) {
continue;
}
const auto opType = op->type;
if (opType != MNN::OpType_Convolution && opType != MNN::OpType_ConvolutionDepthwise) {
continue;
}
auto param = op->main.AsConvolution2D();
const int kernelNum = param->common->outputCount;
std::vector<float> weights = param->weight;
const int weightSize = weights.size();
const int kernelSize = weightSize / kernelNum;
// Quantify each kernel
for (int i = 0; i < kernelNum; i++) {
const int offset = i * kernelSize;
float absMax = findAbsMax(weights.data() + offset, kernelSize);
float scale = absMax / _weightClampValue; // Calculates the scaling factor based on the maximum value
if (absMax < 1e-6f) {
scale = absMax;
}
for (int j = 0; j < kernelSize; j++) {
float value = weights[offset + j];
float quantValue = std::round(value / scale); // Value quantized to int8
float clampedValue = std::max(std::min(quantValue, _weightClampValue), -_weightClampValue); // For parts less than - 127, saturation is mapped to - 127
float dequantValue = scale * clampedValue;
param->weight[offset + j] = dequantValue; // Inverse quantization
}
}
}
}
- Initialize tensor map
void Calibration::_initMaps() {
_featureInfo.clear();
_featureInfoOrigin.clear();
_opInfo.clear();
_tensorMap.clear();
// run mnn once, initialize featureMap, opInfo map
// Assign tensirstatistical objects to input and output tensor s and build mapping relationships
MNN::TensorCallBackWithInfo before = [&](const std::vector<MNN::Tensor*>& nTensors, const MNN::OperatorInfo* info) {
std::string opName = info->name();
std::vector<std::string>::iterator iter = std::find(_skip_quant_ops.begin(), _skip_quant_ops.end(), opName);
if (iter != _skip_quant_ops.end()) {
return false;
}
_opInfo[opName].first = nTensors;
if (Helper::gNeedFeatureOp.find(info->type()) != Helper::gNeedFeatureOp.end()) {
int i = 0;
for (auto t : nTensors) {
if (_featureInfo.find(t) == _featureInfo.end()) {
_featureInfo[t] = std::shared_ptr<TensorStatistic>(
new TensorStatistic(t, _featureQuantizeMethod, opName + " input_tensor_" + flatbuffers::NumToString(i), _featureClampValue));
}
i++;
}
}
return false;
};
MNN::TensorCallBackWithInfo after = [this](const std::vector<MNN::Tensor*>& nTensors,
const MNN::OperatorInfo* info) {
std::string opName = info->name();
std::vector<std::string>::iterator iter = std::find(_skip_quant_ops.begin(), _skip_quant_ops.end(), opName);
if (iter != _skip_quant_ops.end()) {
return true;
}
_opInfo[opName].second = nTensors;
if (Helper::gNeedFeatureOp.find(info->type()) != Helper::gNeedFeatureOp.end()) {
int i = 0;
for (auto t : nTensors) {
if (_featureInfo.find(t) == _featureInfo.end()) {
_featureInfo[t] =
std::shared_ptr<TensorStatistic>(new TensorStatistic(t, _featureQuantizeMethod, opName + " output_tensor_" + flatbuffers::NumToString(i), _featureClampValue));
}
i++;
}
}
return true;
};
_interpreter->runSessionWithCallBackInfo(_session, before, after);
MNN::TensorCallBackWithInfo beforeOrigin = [&](const std::vector<MNN::Tensor*>& nTensors, const MNN::OperatorInfo* info) {
std::string opName = info->name();
std::vector<std::string>::iterator iter = std::find(_skip_quant_ops.begin(), _skip_quant_ops.end(), opName);
if (iter != _skip_quant_ops.end()) {
return false;
}
if (Helper::gNeedFeatureOp.find(info->type()) != Helper::gNeedFeatureOp.end()) {
int i = 0;
for (auto t : nTensors) {
if (_featureInfoOrigin.find(t) == _featureInfoOrigin.end()) {
_featureInfoOrigin[t] = std::shared_ptr<TensorStatistic>(
new TensorStatistic(t, _featureQuantizeMethod, opName + " input_tensor_" + flatbuffers::NumToString(i), _featureClampValue));
}
i++;
}
}
return false;
};
MNN::TensorCallBackWithInfo afterOrigin = [this](const std::vector<MNN::Tensor*>& nTensors,
const MNN::OperatorInfo* info) {
std::string opName = info->name();
std::vector<std::string>::iterator iter = std::find(_skip_quant_ops.begin(), _skip_quant_ops.end(), opName);
if (iter != _skip_quant_ops.end()) {
return true;
}
if (Helper::gNeedFeatureOp.find(info->type()) != Helper::gNeedFeatureOp.end()) {
int i = 0;
for (auto t : nTensors) {
if (_featureInfoOrigin.find(t) == _featureInfoOrigin.end()) {
_featureInfoOrigin[t] =
std::shared_ptr<TensorStatistic>(new TensorStatistic(t, _featureQuantizeMethod, opName + " output_tensor_" + flatbuffers::NumToString(i), _featureClampValue));
}
i++;
}
}
return true;
};
_interpreterOrigin->runSessionWithCallBackInfo(_sessionOrigin, beforeOrigin, afterOrigin);
for (auto& op : _originaleModel->oplists) {
if (_opInfo.find(op->name) == _opInfo.end()) {
continue;
}
for (int i = 0; i < op->inputIndexes.size(); ++i) {
_tensorMap[op->inputIndexes[i]] = _opInfo[op->name].first[i];
}
for (int i = 0; i < op->outputIndexes.size(); ++i) {
_tensorMap[op->outputIndexes[i]] = _opInfo[op->name].second[i];
}
}
if (_featureQuantizeMethod == "KL") {
// set the tensor-statistic method of input tensor as THRESHOLD_MAX
auto inputTensorStatistic = _featureInfo.find(_inputTensor);
if (inputTensorStatistic != _featureInfo.end()) {
inputTensorStatistic->second->setThresholdMethod(THRESHOLD_MAX);
}
}
}
It can be seen from the code that the session of the original model and the session used for quantization are executed respectively, and the callback functions before and after execution are allocated, and an additional tensorstatic is allocated to each tensor. The difference is that the quantized session will fill the input and output tensors into the tensorMap.
If the KL quantization method is used, set the threshold for the statistical method of the input tensor, and the method is THRESHOLD_MAX.
- TensorStatistic
class TensorStatistic {
public:
TensorStatistic(const MNN::Tensor* tensor, std::string method, const std::string& name, float featureClampValue, int binNumber = 2048, GET_THRESHOLD_METHOD thresholdMethod = THRESHOLD_KL);
~TensorStatistic() {
// Do nothing
}
void resetUpdatedDistributionFlag() {
mUpdatedDistributionFlag = false;
}
void resetUpdatedRangeFlags() {
mUpdatedRangeFlags = false;
}
void updateRange();
void resetDistribution();
void updateDistribution();
void setThresholdMethod(GET_THRESHOLD_METHOD thresholdMethod);
void setChannelWise(bool mergeChannel);
std::vector<float> finishAndCompute();
// only this one for ADMM
std::vector<float> computeScaleADMM();
std::string name() {
return mName;
}
bool visited() {
return mVisited;
}
void setVisited(bool visited) {
mVisited = visited;
}
std::pair<std::vector<float>, float> fakeQuantFeature();
float computeDistance(std::vector<float> fakeQuantedFeature);
private:
int _computeThreshold(const std::vector<float>& distribution);
std::vector<std::pair<float, float>> mRangePerChannel;
std::vector<float> mIntervals;
std::vector<bool> mValidChannel;
std::vector<std::vector<float>> mDistribution;
std::shared_ptr<MNN::Tensor> mHostTensor;
const MNN::Tensor* mOriginTensor;
int mBinNumber;
bool mUpdatedDistributionFlag = false;
bool mUpdatedRangeFlags = false;
bool mMergeChannel = true;
std::string mName;
GET_THRESHOLD_METHOD mThresholdMethod = THRESHOLD_KL;
bool mVisited = false;
std::vector<float> mScales;
float mFeatureClampValue = 127.0f;
};
This completes the creation of the Calibration object.
Perform quantification
The entry function executed is runQuantizeModel
void Calibration::runQuantizeModel() {
if (_featureQuantizeMethod == "KL") {
_computeFeatureScaleKL();
} else if (_featureQuantizeMethod == "ADMM") {
_computeFeatureScaleADMM();
}
if (_debug) {
_computeQuantError();
}
_updateScale();
// For operators that do not support quantization, the input is inversely quantized into float32 data and the output is quantized. If the following operators need to be quantized, the output is quantized
_insertDequantize();
}
Calculate the most probable threshold
Take KL quantization method as an example_ computeFeatureScaleKL function.
void Calibration::_computeFeatureScaleKL() {
// The distribution histogram of data on each channel is counted
_computeFeatureMapsRange();
_collectFeatureMapsDistribution();
_scales.clear();
for (auto& iter : _featureInfo) {
AUTOTIME;
_scales[iter.first] = iter.second->finishAndCompute();
}
//_featureInfo.clear();//No need now
}
- Statistical data distribution
First, the data range on each channel is counted.
void Calibration::_computeFeatureMapsRange() {
// feed input data according to input images
int count = 0;
for (const auto& img : _imgaes) {
for (auto& iter : _featureInfo) {
iter.second->setVisited(false);
}
for (auto& iter : _featureInfo) {
iter.second->resetUpdatedRangeFlags();
}
count++;
Helper::preprocessInput(_process.get(), _width, _height, img, _inputTensor);
MNN::TensorCallBackWithInfo before = [&](const std::vector<MNN::Tensor*>& nTensors,
const MNN::OperatorInfo* info) {
for (auto t : nTensors) {
if (_featureInfo.find(t) != _featureInfo.end()) {
if (_featureInfo[t]->visited() == false) {
_featureInfo[t]->updateRange();
}
}
}
return true;
};
MNN::TensorCallBackWithInfo after = [&](const std::vector<MNN::Tensor*>& nTensors,
const MNN::OperatorInfo* info) {
for (auto t : nTensors) {
if (_featureInfo.find(t) != _featureInfo.end()) {
if (_featureInfo[t]->visited() == false) {
_featureInfo[t]->updateRange();
}
}
}
return true;
};
_interpreter->runSessionWithCallBackInfo(_session, before, after);
MNN_PRINT("\rComputeFeatureRange: %.2lf %%", (float)count * 100.0f / (float)_imageNum);
fflush(stdout);
}
MNN_PRINT("\n");
}
Execute the attached callback function through session to count the maximum and minimum values of input and output tensor.
void TensorStatistic::updateRange() {
// According to the input calculation results, the maximum and minimum values of each channel of the characteristic graph are obtained
if (mUpdatedRangeFlags) {
return;
}
mUpdatedRangeFlags = true;
mOriginTensor->copyToHostTensor(mHostTensor.get());
int batch = mHostTensor->batch();
int channel = mHostTensor->channel();
int width = mHostTensor->width();
int height = mHostTensor->height();
auto area = width * height;
for (int n = 0; n < batch; ++n) {
auto dataBatch = mHostTensor->host<float>() + n * mHostTensor->stride(0);
for (int c = 0; c < channel; ++c) {
int cIndex = c;
if (mMergeChannel) {
cIndex = 0;
}
auto minValue = mRangePerChannel[cIndex].first;
auto maxValue = mRangePerChannel[cIndex].second;
auto dataChannel = dataBatch + c * mHostTensor->stride(1);
for (int v = 0; v < area; ++v) {
minValue = std::min(minValue, dataChannel[v]);
maxValue = std::max(maxValue, dataChannel[v]);
}
mRangePerChannel[cIndex].first = minValue;
mRangePerChannel[cIndex].second = maxValue;
}
}
mVisited = true;
}
The distribution histogram statistics are carried out according to the tensor value range.
void Calibration::_collectFeatureMapsDistribution() {
for (auto& iter : _featureInfo) {
iter.second->resetDistribution();
}
// feed input data according to input images
MNN::TensorCallBackWithInfo before = [&](const std::vector<MNN::Tensor*>& nTensors, const MNN::OperatorInfo* info) {
for (auto t : nTensors) {
if (_featureInfo.find(t) != _featureInfo.end()) {
if (_featureInfo[t]->visited() == false) {
_featureInfo[t]->updateDistribution();
}
}
}
return true;
};
MNN::TensorCallBackWithInfo after = [&](const std::vector<MNN::Tensor*>& nTensors, const MNN::OperatorInfo* info) {
for (auto t : nTensors) {
if (_featureInfo.find(t) != _featureInfo.end()) {
if (_featureInfo[t]->visited() == false) {
_featureInfo[t]->updateDistribution();
}
}
}
return true;
};
int count = 0;
for (const auto& img : _imgaes) {
count++;
for (auto& iter : _featureInfo) {
iter.second->setVisited(false);
}
for (auto& iter : _featureInfo) {
iter.second->resetUpdatedDistributionFlag();
}
Helper::preprocessInput(_process.get(), _width, _height, img, _inputTensor);
_interpreter->runSessionWithCallBackInfo(_session, before, after);
MNN_PRINT("\rCollectFeatureDistribution: %.2lf %%", (float)count * 100.0f / (float)_imageNum);
fflush(stdout);
}
MNN_PRINT("\n");
}
Firstly, all tensor s in the model used for quantization are traversed, and the data distribution histogram is initialized.
Then, reasoning is performed to calculate all pictures. Similarly, two callback functions are brought in during execution to make data statistics on input and output tensor respectively, and update the data distribution.
Let's first look at histogram initialization. Calculate the histogram interval mapped to 0 ~ 2048 according to the maximum value of data.
void TensorStatistic::resetDistribution() {
for (int i = 0; i < mIntervals.size(); ++i) {
int cIndex = i;
if (mMergeChannel) {
cIndex = 0;
}
// Maximum value on each channel
auto maxValue = std::max(fabsf(mRangePerChannel[cIndex].second), fabsf(mRangePerChannel[cIndex].first));
mValidChannel[cIndex] = maxValue > 0.00001f;
mIntervals[cIndex] = 0.0f;
if (mValidChannel[cIndex]) {
// Mmintervals represents the bins interval corresponding to each number when the original float is uniformly mapped to [0-2048]
// e.g. maxValue = 256.f; intervals = 8; 1.f is in the 8th bins, 2 F is in the 16th bin
mIntervals[cIndex] = (float)mBinNumber / maxValue;
}
}
// The distribution on each channel is initialized to a minimum
for (auto& c : mDistribution) {
std::fill(c.begin(), c.end(), 1.0e-07);
}
// MNN_PRINT("==> %s max: %f\n", mName.c_str(),std::max(fabsf(mRangePerChannel[0].second),
// fabsf(mRangePerChannel[0].first)));
}
In the process of reasoning, the process of updating the data distribution is as follows.
void TensorStatistic::updateDistribution() {
if (mUpdatedDistributionFlag) {
return;
}
mUpdatedDistributionFlag = true;
mOriginTensor->copyToHostTensor(mHostTensor.get());
int batch = mHostTensor->batch();
int channel = mHostTensor->channel();
int width = mHostTensor->width();
int height = mHostTensor->height();
auto area = width * height;
for (int n = 0; n < batch; ++n) {
auto dataBatch = mHostTensor->host<float>() + n * mHostTensor->stride(0);
for (int c = 0; c < channel; ++c) {
int cIndex = c;
if (mMergeChannel) {
cIndex = 0;
}
if (!mValidChannel[cIndex]) {
continue;
}
auto multi = mIntervals[cIndex];
auto target = mDistribution[cIndex].data(); // Data distribution histogram
auto dataChannel = dataBatch + c * mHostTensor->stride(1); // raw data
for (int v = 0; v < area; ++v) {
auto data = dataChannel[v];
if (data == 0) {
continue;
}
int index = static_cast<int>(fabs(data) * multi);
// Find the original value and map it to the specific bin of 2048 bins
index = std::min(index, mBinNumber - 1);
target[index] += 1.0f; // Add 1 to the number of specific bin
}
}
}
}
- Calculate quantization threshold
std::vector<float> TensorStatistic::finishAndCompute() {
std::vector<float> scaleValue(mDistribution.size(), 0.0f);
if (mMergeChannel) {
if (!mValidChannel[0]) {
return scaleValue;
}
float sum = 0.0f;
auto& distribution = mDistribution[0];
std::for_each(distribution.begin(), distribution.end(), [&](float n) { sum += n; });
std::for_each(distribution.begin(), distribution.end(), [sum](float& n) { n /= sum; });
auto threshold = _computeThreshold(distribution);
auto scale = ((float)threshold + 0.5) / mIntervals[0] / mFeatureClampValue;
// MNN_PRINT("==> %s == %d, %f, %f\n", mName.c_str(),threshold, 1.0f / mIntervals[0], scale * mFeatureClampValue);
std::fill(scaleValue.begin(), scaleValue.end(), scale);
mScales = scaleValue;
return scaleValue;
}
for (int c = 0; c < mDistribution.size(); ++c) {
if (!mValidChannel[c]) {
continue;
}
float sum = 0.0f;
auto& distribution = mDistribution[c];
// Count the total data in each bin
std::for_each(distribution.begin(), distribution.end(), [&](float n) { sum += n; });
// The number of n/sum in each bin is equivalent to the probability of each data distribution
std::for_each(distribution.begin(), distribution.end(), [sum](float& n) { n /= sum; });
auto threshold = _computeThreshold(distribution);
// According to the calculated threshold, the scaling ratio of each tensor is calculated
scaleValue[c] = ((float)threshold + 0.5) / mIntervals[c] / mFeatureClampValue;
}
return scaleValue;
}
As can be seen from the code, first calculate the probability distribution of the data, and then_ computeThreshold calculates the mapping threshold.
int TensorStatistic::_computeThreshold(const std::vector<float>& distribution) {
const int targetBinNums = 128;
int threshold = targetBinNums;
if (mThresholdMethod == THRESHOLD_KL) {
float minKLDivergence = 10000.0f;
float afterThresholdSum = 0.0f;
// Count the number of afterThresholdSum exceeding 128 (exceeding the threshold)
std::for_each(distribution.begin() + targetBinNums, distribution.end(),
[&](float n) { afterThresholdSum += n; });
for (int i = targetBinNums; i < mBinNumber; ++i) { // From 128 to 2048, find the new threshold
std::vector<float> quantizedDistribution(targetBinNums);
std::vector<float> candidateDistribution(i);
std::vector<float> expandedDistribution(i);
// The distribution of 0 ~ i-1, and the subsequent data are added to i-1 for saturation mapping
std::copy(distribution.begin(), distribution.begin() + i, candidateDistribution.begin());
candidateDistribution[i - 1] += afterThresholdSum;
afterThresholdSum -= distribution[i];
// Size i, bin interval when remapping to targetBinNums
const float binInterval = (float)i / (float)targetBinNums;
// merge i bins to target bins
// The distribution between [0, j] is merged into a space of [0, targetbinnum] and saved in quantized distribution
for (int j = 0; j < targetBinNums; ++j) {
// [start, end] is the data mapped to the j-th bin in the 128 length histogram
const float start = j * binInterval;
const float end = start + binInterval;
// The data beyond the left and right range is accumulated into the current bin according to the distance from both ends as a coefficient
const int leftUpper = static_cast<int>(std::ceil(start));
if (leftUpper > start) {
const float leftScale = leftUpper - start;
quantizedDistribution[j] += leftScale * distribution[leftUpper - 1];
}
const int rightLower = static_cast<int>(std::floor(end));
if (rightLower < end) {
const float rightScale = end - rightLower;
quantizedDistribution[j] += rightScale * distribution[rightLower];
}
// Count and accumulate data within the range
std::for_each(distribution.begin() + leftUpper, distribution.begin() + rightLower,
[&](float n) { quantizedDistribution[j] += n; });
}
// expand target bins to i bins
// Inverse mapping 0~targetBinNums space to 0~i space
for (int j = 0; j < targetBinNums; ++j) {
const float start = j * binInterval;
const float end = start + binInterval;
float count = 0;
const int leftUpper = static_cast<int>(std::ceil(start));
float leftScale = 0.0f;
if (leftUpper > start) {
leftScale = leftUpper - start;
if (distribution[leftUpper - 1] != 0) {
count += leftScale;
}
}
const int rightLower = static_cast<int>(std::floor(end));
float rightScale = 0.0f;
if (rightLower < end) {
rightScale = end - rightLower;
if (distribution[rightLower] != 0) {
count += rightScale;
}
}
std::for_each(distribution.begin() + leftUpper, distribution.begin() + rightLower, [&](float n) {
if (n != 0) {
count += 1;
}
});
if (count == 0) {
continue;
}
const float toExpandValue = quantizedDistribution[j] / count;
if (leftUpper > start && distribution[leftUpper - 1] != 0) {
expandedDistribution[leftUpper - 1] += toExpandValue * leftScale;
}
if (rightLower < end && distribution[rightLower] != 0) {
expandedDistribution[rightLower] += toExpandValue * rightScale;
}
for (int k = leftUpper; k < rightLower; ++k) {
if (distribution[k] != 0) {
expandedDistribution[k] += toExpandValue;
}
}
}
// Calculate the KL divergence of the two spaces and record the minimum
const float curKL = _klDivergence(candidateDistribution, expandedDistribution);
// std::cout << "=====> KL: " << i << " ==> " << curKL << std::endl;
if (curKL < minKLDivergence) {
minKLDivergence = curKL;
threshold = i;
}
}
} else if (mThresholdMethod == THRESHOLD_MAX) {
threshold = mBinNumber - 1;
} else {
// TODO, support other method
MNN_ASSERT(false);
}
// When KL divergence is the smallest, the corresponding threshold is the optimal solution we are looking for
return threshold;
}
update scale
void Calibration::_updateScale() {
for (const auto& op : _originaleModel->oplists) {
std::vector<std::string>::iterator iter = std::find(_skip_quant_ops.begin(), _skip_quant_ops.end(), op->name);
if (iter != _skip_quant_ops.end()) {
continue;
}
const auto opType = op->type;
if (opType != MNN::OpType_Convolution && opType != MNN::OpType_ConvolutionDepthwise &&
opType != MNN::OpType_Eltwise) {
continue;
}
auto tensorsPair = _opInfo.find(op->name);
if (tensorsPair == _opInfo.end()) {
MNN_ERROR("Can't find tensors for %s\n", op->name.c_str());
}
if (opType == MNN::OpType_Eltwise) {
auto param = op->main.AsEltwise();
// Now only support AddInt8
if (param->type != MNN::EltwiseType_SUM) {
continue;
}
const auto& inputScale0 = _scales[tensorsPair->second.first[0]];
const auto& inputScale1 = _scales[tensorsPair->second.first[1]];
const auto& outputScale = _scales[tensorsPair->second.second[0]];
const int outputScaleSize = outputScale.size();
std::vector<float> outputInvertScale(outputScaleSize);
Helper::invertData(outputInvertScale.data(), outputScale.data(), outputScaleSize);
op->type = MNN::OpType_EltwiseInt8;
op->main.Reset();
op->main.type = MNN::OpParameter_EltwiseInt8;
auto eltwiseInt8Param = new MNN::EltwiseInt8T;
auto input0ScaleParam = new MNN::QuantizedFloatParamT;
auto input1ScaleParam = new MNN::QuantizedFloatParamT;
auto outputScaleParam = new MNN::QuantizedFloatParamT;
input0ScaleParam->tensorScale = inputScale0;
input1ScaleParam->tensorScale = inputScale1;
outputScaleParam->tensorScale = outputInvertScale;
eltwiseInt8Param->inputQuan0 = std::unique_ptr<MNN::QuantizedFloatParamT>(input0ScaleParam);
eltwiseInt8Param->inputQuan1 = std::unique_ptr<MNN::QuantizedFloatParamT>(input1ScaleParam);
eltwiseInt8Param->outputQuan = std::unique_ptr<MNN::QuantizedFloatParamT>(outputScaleParam);
op->main.value = eltwiseInt8Param;
continue;
}
// below is Conv/DepthwiseConv
const auto& inputScale = _scales[tensorsPair->second.first[0]];
const auto& outputScale = _scales[tensorsPair->second.second[0]];
auto param = op->main.AsConvolution2D();
const int channles = param->common->outputCount;
const int weightSize = param->weight.size();
param->symmetricQuan.reset(new MNN::QuantizedFloatParamT);
// Quantized param is a reference to param - > symmetricquan
auto& quantizedParam = param->symmetricQuan;
quantizedParam->scale.resize(channles);
quantizedParam->weight.resize(weightSize);
quantizedParam->bias.resize(channles);
if (opType == MNN::OpType_Convolution) {
QuantizeConvPerChannel(param->weight.data(), param->weight.size(), param->bias.data(),
quantizedParam->weight.data(), quantizedParam->bias.data(),
quantizedParam->scale.data(), inputScale, outputScale, _weightQuantizeMethod, _weightClampValue);
op->type = MNN::OpType_ConvInt8;
} else if (opType == MNN::OpType_ConvolutionDepthwise) {
QuantizeDepthwiseConv(param->weight.data(), param->weight.size(), param->bias.data(),
quantizedParam->weight.data(), quantizedParam->bias.data(),
quantizedParam->scale.data(), inputScale, outputScale, _weightQuantizeMethod, _weightClampValue);
op->type = MNN::OpType_DepthwiseConvInt8;
}
if (param->common->relu6) {
param->common->relu = true;
param->common->relu6 = false;
}
// Clear the original weight and bias
param->weight.clear();
param->bias.clear();
}
}
As can be seen from the code, the weight parameters are updated according to the scale calculated above. Take QuantizeConvPerChannel as an example to continue the analysis.
int QuantizeConvPerChannel(const float* weight, const int size, const float* bias, int8_t* quantizedWeight,
int32_t* quantizedBias, float* scale, const std::vector<float>& inputScale,
const std::vector<float>& outputScale, std::string method, float weightClampValue, bool mergeChannel) {
const int inputChannels = inputScale.size();
const int outputChannels = outputScale.size();
const int icXoc = inputChannels * outputChannels;
DCHECK(size % icXoc == 0) << "Input Data Size Error!";
std::vector<float> quantizedWeightScale(outputChannels);
float inputScalexWeight = 1.0f;
if (mergeChannel) {
if (method == "MAX_ABS"){
SymmetricQuantizeWeight(weight, size, quantizedWeight, quantizedWeightScale.data(), outputChannels, weightClampValue);
}
else if (method == "ADMM") {
QuantizeWeightADMM(weight, size, quantizedWeight, quantizedWeightScale.data(), outputChannels, weightClampValue);
}
inputScalexWeight = inputScale[0];
} else {
const int kernelSize = size / icXoc;
const int ocStride = size / outputChannels;
// Each weight is multiplied by the corresponding scale
std::vector<float> weightMultiByInputScale(size);
for (int oc = 0; oc < outputChannels; ++oc) {
for (int ic = 0; ic < inputChannels; ++ic) {
for (int i = 0; i < kernelSize; ++i) {
const int index = oc * ocStride + ic * kernelSize + i;
weightMultiByInputScale[index] = inputScale[ic] * weight[index];
}
}
}
if (method == "MAX_ABS"){
SymmetricQuantizeWeight(weightMultiByInputScale.data(), size, quantizedWeight, quantizedWeightScale.data(), outputChannels, weightClampValue);
}
else if (method == "ADMM") {
QuantizeWeightADMM(weightMultiByInputScale.data(), size, quantizedWeight, quantizedWeightScale.data(), outputChannels, weightClampValue);
}
}
for (int i = 0; i < outputChannels; ++i) {
if (fabs(outputScale[i]) <= 1e-6) {
scale[i] = 0.0f;
} else {
scale[i] = inputScalexWeight * quantizedWeightScale[i] / outputScale[0];
}
}
if (bias) {
for (int i = 0; i < outputChannels; ++i) {
if (fabs(inputScalexWeight) <= 1e-6 || fabs(quantizedWeightScale[i]) <= 1e-6) {
quantizedBias[i] = 0;
} else {
quantizedBias[i] = static_cast<int32_t>(bias[i] / (inputScalexWeight * quantizedWeightScale[i]));
}
}
}
return 0;
}
int SymmetricQuantizeWeight(const float* weight, const int size, int8_t* quantizedWeight, float* scale,
const int channels, float weightClampValue) {
/** Quantify parameters
* weight Is the weight multiplied by scale,
* quantizedWeight Used to store quantized parameters
* **/
DCHECK((size % channels) == 0) << "weight size error!";
const int channelStride = size / channels;
const int quantizedMaxValue = weightClampValue; // 127
for (int c = 0; c < channels; ++c) { // Quantify each channel separately
const auto weightChannelStart = weight + c * channelStride;
auto quantizedWeightChannelStart = quantizedWeight + c * channelStride;
// Gets the maximum and minimum values in the channel
auto minmaxValue = std::minmax_element(weightChannelStart, weightChannelStart + channelStride);
const float dataAbsMax = std::fmax(std::fabs(*minmaxValue.first), std::fabs(*minmaxValue.second));
float scaleDataToInt8 = 1.0f;
if (dataAbsMax == 0) {
scale[c] = 0.0f;
} else {
// scale for inverse quantization
scale[c] = dataAbsMax / quantizedMaxValue;
// Map to scale on int8 space
scaleDataToInt8 = quantizedMaxValue / dataAbsMax;
}
for (int i = 0; i < channelStride; ++i) {
// After the input weight is multiplied by scale and mapped to int8, set the truncation to - 127 or 127 for those not in the [- 127127] interval
const int32_t quantizedInt8Value = static_cast<int32_t>(roundf(weightChannelStart[i] * scaleDataToInt8));
quantizedWeightChannelStart[i] =
std::min(quantizedMaxValue, std::max(-quantizedMaxValue, quantizedInt8Value));
}
}
return 0;
}
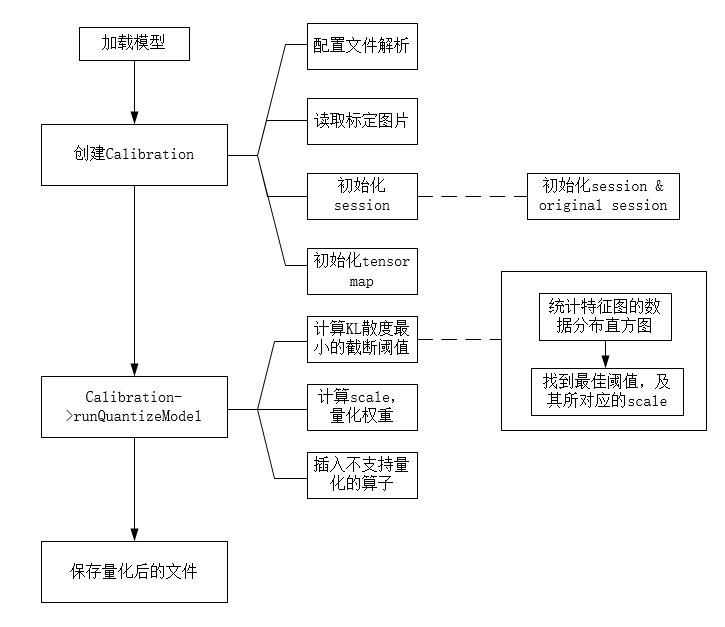
The next step is to format the weight and other information and save it to a file. The overall process is shown in the figure below: