Introduction to Mobilenet
Traditional neural network has large memory demand and large amount of computation. Cannot run on mobile and embedded devices. Mobilenet focuses on lightweight CNN networks in mobile terminals or embedded devices (the accuracy is reduced by 0.9% compared with VGG16, but the model parameters are only VGG1/32)
1, MobilenetV1
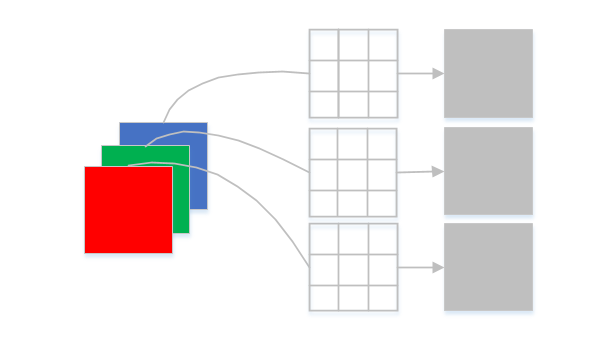
Depth separable convolution
Add super parameter α (number of convolution cores), β (convolution kernel size)
Depth separable convolution graph
Deep separable implementation
Activation function: relu
Most of the dw convolution kernel parameters are 0
2, MobilenetV2
Compared with V1, the network model is smaller and has higher accuracy
Inverted residuals (inverse residual structure) first increases the dimension and then decreases the dimension
Linear botslenecks (linear activation function is used for the first level of inverse residuals)
Activate function Relu6,DW
The last layer of the inverse residual structure uses linear activation, and it is easy to lose low latitude information using Relu
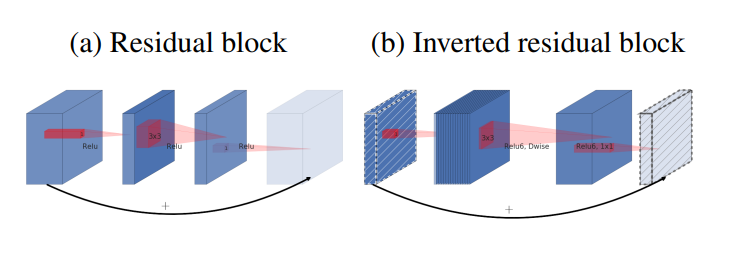
Inverse residual structure
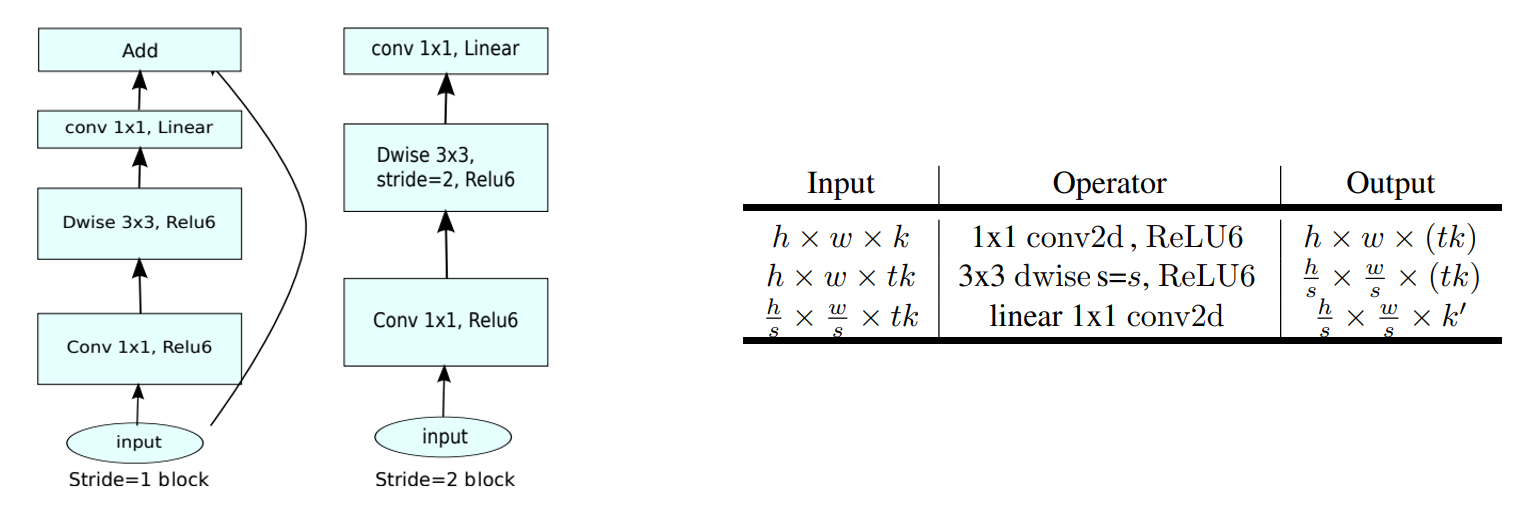
network structure
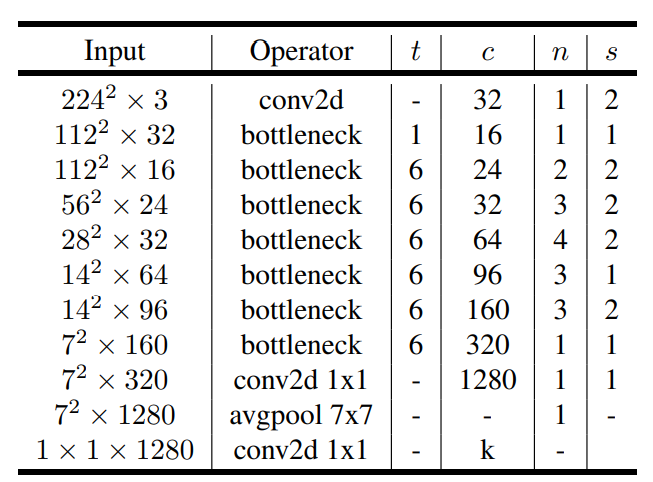
t: Expansion factor, expansion ratio of 1x1 convolution layer in the first layer of inverse residual structure
c: Number of output channels
n:bottleneck repetitions
s: Step distance, first floor, others are 1
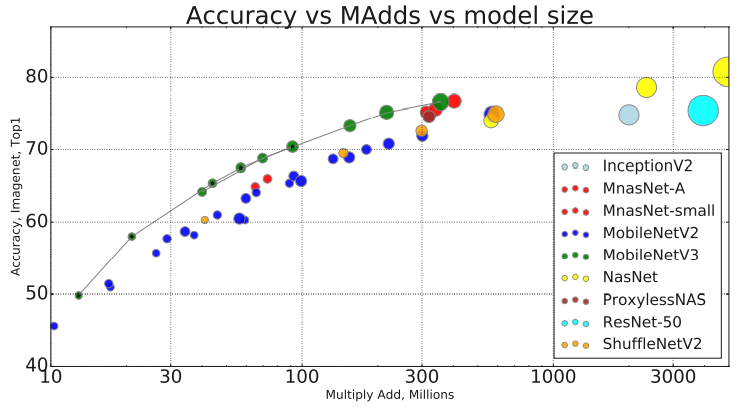
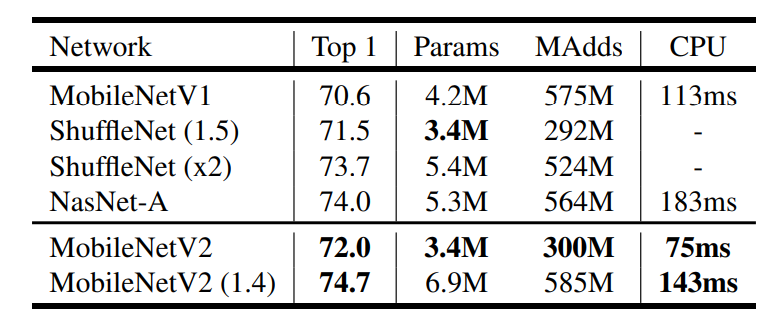
Performance comparison
1) Classification
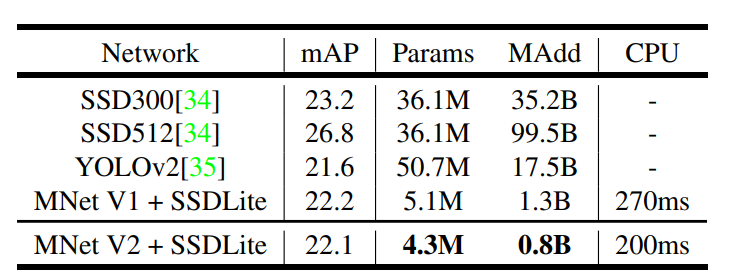
2) Target detection
3, MobilenetV3
Compared with V2 network, it is faster and more efficient, increasing the accuracy by 3.2% and reducing the delay by 20%.
1) Update the block, add the SE module, and update the activation function
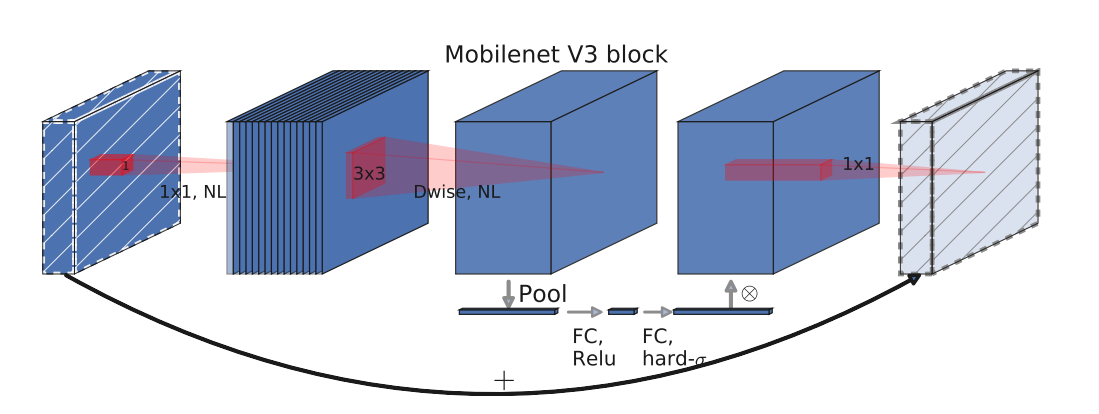
SE understanding: first perform average pooling - > relu - > h-sig - > multiply the factor by the characteristic graph
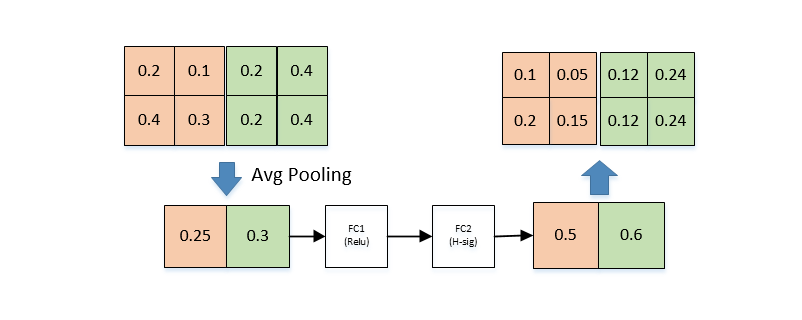
2) Using NAS search parameters
3) Redesign the time-consuming layer structure
-
Reduce the number of convolution cores of the first convolution layer (32 - > 16)

The convolution kernel is reduced from 32 to 16, the accuracy is the same, the time is reduced by 2 milliseconds, and the amount of computation is reduced by 2 million. -
Streamline Last Stage
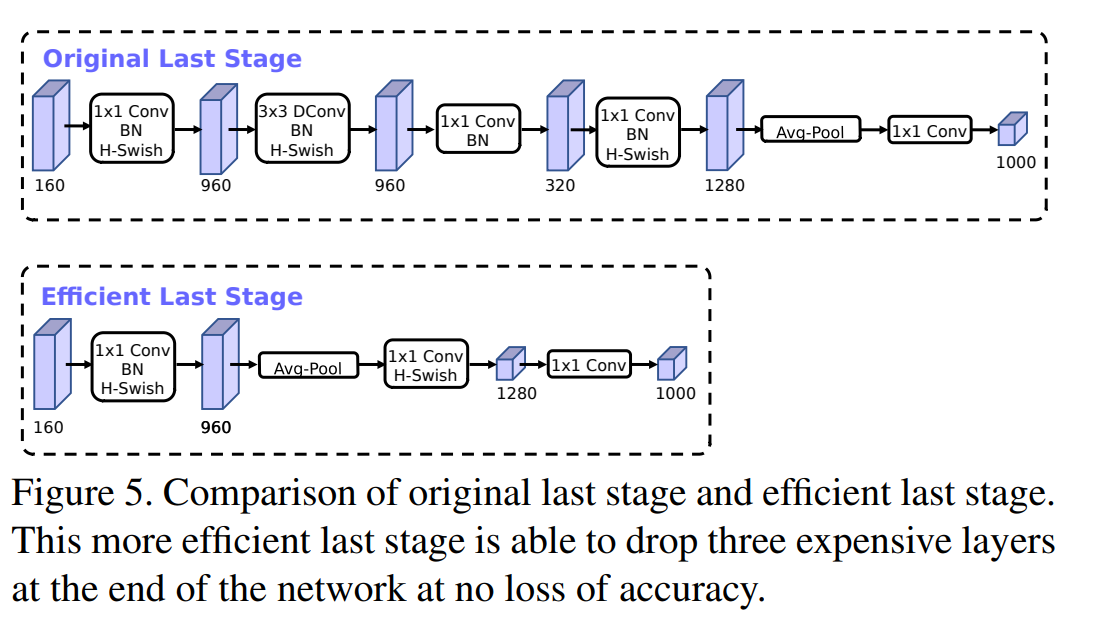
When the accuracy is not reduced, the time is reduced by 7 milliseconds (occupying 11% of the whole reasoning time), and the amount of computation is reduced by 30 million

Redesigned activation function
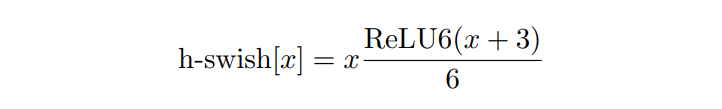
It is friendly to reasoning speed and quantization process
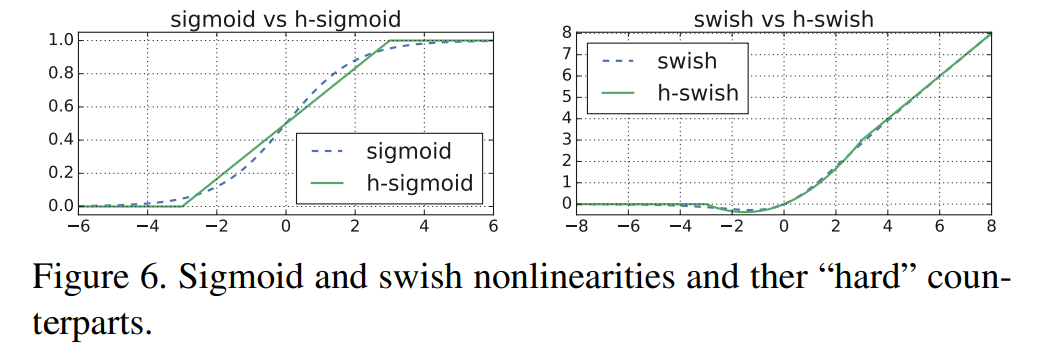
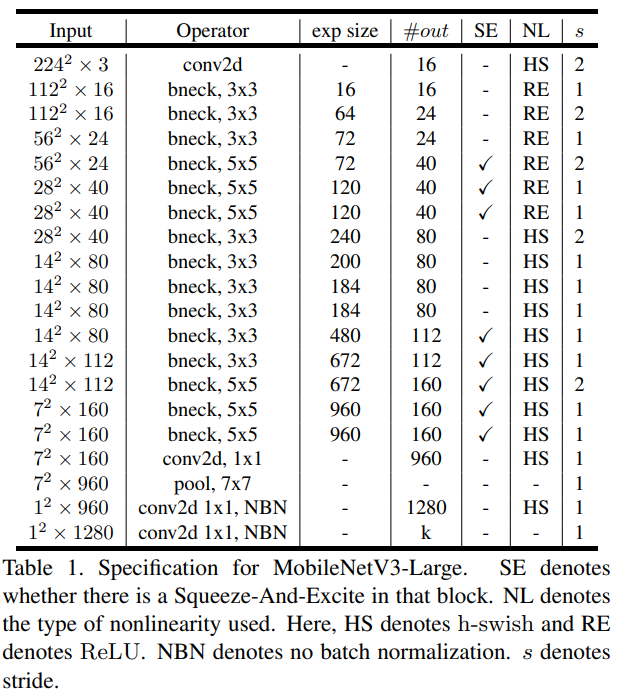
Network structure mobilenetv3 large
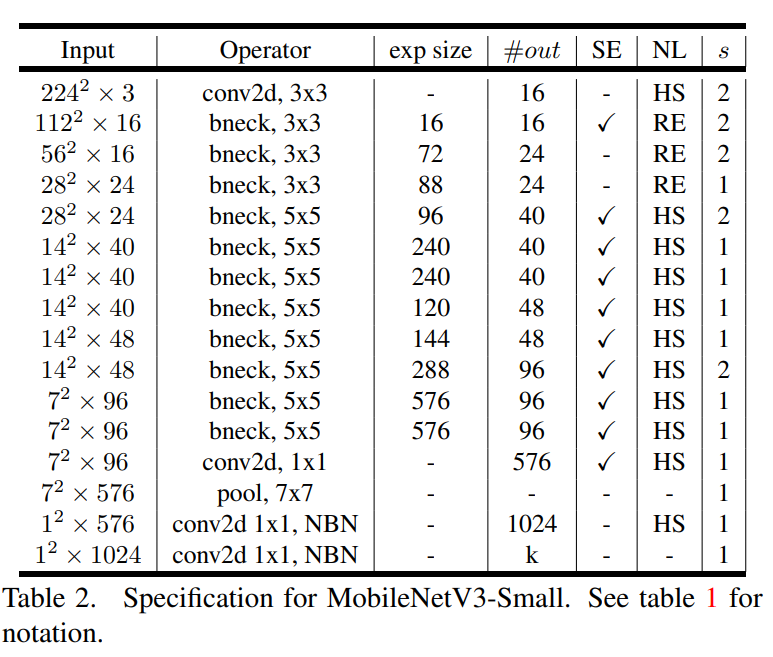
MobilenetV3 Small
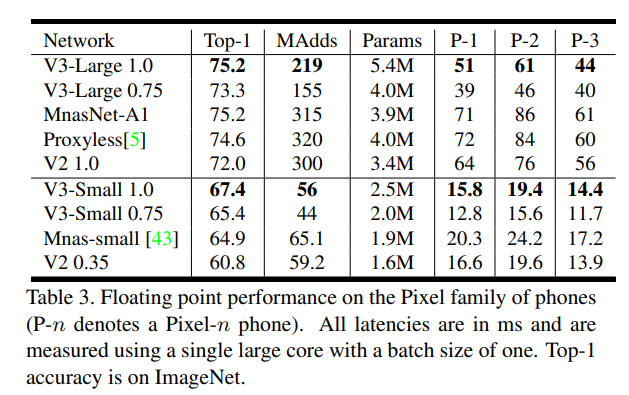
Comparison between Lage and Small networks
program
MobileNetV2
from torch import nn
import torch
def _make_divisible(ch, divisor=8, min_ch=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
class ConvBNReLU(nn.Sequential):
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_channel, out_channel, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU6(inplace=True)
)
class InvertedResidual(nn.Module):
def __init__(self, in_channel, out_channel, stride, expand_ratio):
super(InvertedResidual, self).__init__()
hidden_channel = in_channel * expand_ratio
self.use_shortcut = stride == 1 and in_channel == out_channel
layers = []
if expand_ratio != 1:
# 1x1 pointwise conv
layers.append(ConvBNReLU(in_channel, hidden_channel, kernel_size=1))
layers.extend([
# 3x3 depthwise conv
ConvBNReLU(hidden_channel, hidden_channel, stride=stride, groups=hidden_channel),
# 1x1 pointwise conv(linear)
nn.Conv2d(hidden_channel, out_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel),
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_shortcut:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, alpha=1.0, round_nearest=8):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = _make_divisible(32 * alpha, round_nearest)
last_channel = _make_divisible(1280 * alpha, round_nearest)
inverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
features = []
# conv1 layer
features.append(ConvBNReLU(3, input_channel, stride=2))#
# building inverted residual residual blockes
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * alpha, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
input_channel = output_channel
# building last several layers
features.append(ConvBNReLU(input_channel, last_channel, 1))
# combine feature layers
self.features = nn.Sequential(*features)
# building classifier
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channel, num_classes)#Full connection is convolution
)
# weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)#
x = self.classifier(x)
return x
MobileNet V3
from typing import Callable, List, Optional
import torch
from torch import nn, Tensor
from torch.nn import functional as F
from functools import partial
def _make_divisible(ch, divisor=8, min_ch=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
class ConvBNActivation(nn.Sequential):
def __init__(self,
in_planes: int,
out_planes: int,
kernel_size: int = 3,
stride: int = 1,
groups: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
activation_layer: Optional[Callable[..., nn.Module]] = None):
padding = (kernel_size - 1) // 2
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.ReLU6
super(ConvBNActivation, self).__init__(nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False),
norm_layer(out_planes),
activation_layer(inplace=True))
class SqueezeExcitation(nn.Module):
def __init__(self, input_c: int, squeeze_factor: int = 4):
super(SqueezeExcitation, self).__init__()
squeeze_c = _make_divisible(input_c // squeeze_factor, 8)
self.fc1 = nn.Conv2d(input_c, squeeze_c, 1)
self.fc2 = nn.Conv2d(squeeze_c, input_c, 1)
def forward(self, x: Tensor) -> Tensor:
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))
scale = self.fc1(scale)
scale = F.relu(scale, inplace=True)
scale = self.fc2(scale)
scale = F.hardsigmoid(scale, inplace=True)
return scale * x
class InvertedResidualConfig:
def __init__(self,
input_c: int,
kernel: int,
expanded_c: int,
out_c: int,
use_se: bool,
activation: str,
stride: int,
width_multi: float):
self.input_c = self.adjust_channels(input_c, width_multi)
self.kernel = kernel
self.expanded_c = self.adjust_channels(expanded_c, width_multi)
self.out_c = self.adjust_channels(out_c, width_multi)
self.use_se = use_se
self.use_hs = activation == "HS" # whether using h-swish activation
self.stride = stride
@staticmethod
def adjust_channels(channels: int, width_multi: float):
return _make_divisible(channels * width_multi, 8)
class InvertedResidual(nn.Module):
def __init__(self,
cnf: InvertedResidualConfig,
norm_layer: Callable[..., nn.Module]):
super(InvertedResidual, self).__init__()
if cnf.stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c)
layers: List[nn.Module] = []
activation_layer = nn.Hardswish if cnf.use_hs else nn.ReLU
# expand
if cnf.expanded_c != cnf.input_c:
layers.append(ConvBNActivation(cnf.input_c,
cnf.expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer))
# depthwise
layers.append(ConvBNActivation(cnf.expanded_c,
cnf.expanded_c,
kernel_size=cnf.kernel,
stride=cnf.stride,
groups=cnf.expanded_c,
norm_layer=norm_layer,
activation_layer=activation_layer))
if cnf.use_se:
layers.append(SqueezeExcitation(cnf.expanded_c))
# project
layers.append(ConvBNActivation(cnf.expanded_c,
cnf.out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity))
self.block = nn.Sequential(*layers)
self.out_channels = cnf.out_c
self.is_strided = cnf.stride > 1
def forward(self, x: Tensor) -> Tensor:
result = self.block(x)
if self.use_res_connect:
result += x
return result
class MobileNetV3(nn.Module):
def __init__(self,
inverted_residual_setting: List[InvertedResidualConfig],
last_channel: int,
num_classes: int = 1000,
block: Optional[Callable[..., nn.Module]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None):
super(MobileNetV3, self).__init__()
if not inverted_residual_setting:
raise ValueError("The inverted_residual_setting should not be empty.")
elif not (isinstance(inverted_residual_setting, List) and
all([isinstance(s, InvertedResidualConfig) for s in inverted_residual_setting])):
raise TypeError("The inverted_residual_setting should be List[InvertedResidualConfig]")
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer = partial(nn.BatchNorm2d, eps=0.001, momentum=0.01)
layers: List[nn.Module] = []
# building first layer
firstconv_output_c = inverted_residual_setting[0].input_c
layers.append(ConvBNActivation(3,
firstconv_output_c,
kernel_size=3,
stride=2,
norm_layer=norm_layer,
activation_layer=nn.Hardswish))
# building inverted residual blocks
for cnf in inverted_residual_setting:
layers.append(block(cnf, norm_layer))
# building last several layers
lastconv_input_c = inverted_residual_setting[-1].out_c
lastconv_output_c = 6 * lastconv_input_c
layers.append(ConvBNActivation(lastconv_input_c,
lastconv_output_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Hardswish))
self.features = nn.Sequential(*layers)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.classifier = nn.Sequential(nn.Linear(lastconv_output_c, last_channel),
nn.Hardswish(inplace=True),
nn.Dropout(p=0.2, inplace=True),
nn.Linear(last_channel, num_classes))
# initial weights
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def _forward_impl(self, x: Tensor) -> Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
def mobilenet_v3_large(num_classes: int = 1000,
reduced_tail: bool = False) -> MobileNetV3:
"""
Constructs a large MobileNetV3 architecture from
"Searching for MobileNetV3" <https://arxiv.org/abs/1905.02244>.
weights_link:
https://download.pytorch.org/models/mobilenet_v3_large-8738ca79.pth
Args:
num_classes (int): number of classes
reduced_tail (bool): If True, reduces the channel counts of all feature layers
between C4 and C5 by 2. It is used to reduce the channel redundancy in the
backbone for Detection and Segmentation.
"""
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, False, "RE", 1),
bneck_conf(16, 3, 64, 24, False, "RE", 2), # C1
bneck_conf(24, 3, 72, 24, False, "RE", 1),
bneck_conf(24, 5, 72, 40, True, "RE", 2), # C2
bneck_conf(40, 5, 120, 40, True, "RE", 1),
bneck_conf(40, 5, 120, 40, True, "RE", 1),
bneck_conf(40, 3, 240, 80, False, "HS", 2), # C3
bneck_conf(80, 3, 200, 80, False, "HS", 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1),
bneck_conf(80, 3, 480, 112, True, "HS", 1),
bneck_conf(112, 3, 672, 112, True, "HS", 1),
bneck_conf(112, 5, 672, 160 // reduce_divider, True, "HS", 2), # C4
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),
]
last_channel = adjust_channels(1280 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
def mobilenet_v3_small(num_classes: int = 1000,
reduced_tail: bool = False) -> MobileNetV3:
"""
Constructs a large MobileNetV3 architecture from
"Searching for MobileNetV3" <https://arxiv.org/abs/1905.02244>.
weights_link:
https://download.pytorch.org/models/mobilenet_v3_small-047dcff4.pth
Args:
num_classes (int): number of classes
reduced_tail (bool): If True, reduces the channel counts of all feature layers
between C4 and C5 by 2. It is used to reduce the channel redundancy in the
backbone for Detection and Segmentation.
"""
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, True, "RE", 2), # C1
bneck_conf(16, 3, 72, 24, False, "RE", 2), # C2
bneck_conf(24, 3, 88, 24, False, "RE", 1),
bneck_conf(24, 5, 96, 40, True, "HS", 2), # C3
bneck_conf(40, 5, 240, 40, True, "HS", 1),
bneck_conf(40, 5, 240, 40, True, "HS", 1),
bneck_conf(40, 5, 120, 48, True, "HS", 1),
bneck_conf(48, 5, 144, 48, True, "HS", 1),
bneck_conf(48, 5, 288, 96 // reduce_divider, True, "HS", 2), # C4
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1),
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1)
]
last_channel = adjust_channels(1024 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)