What is Triton information server?
Its predecessor is nvidia's tensorRT. triton adds reasoning deployment support of mainstream TF, pytorch, onnx and other models on the basis of tensorRT.
It is a very good reasoning model deployment service.
Specific understanding: NVIDIA Triton Inference Server | NVIDIA Developer https://developer.nvidia.com/nvidia-triton-inference-server
https://developer.nvidia.com/nvidia-triton-inference-server
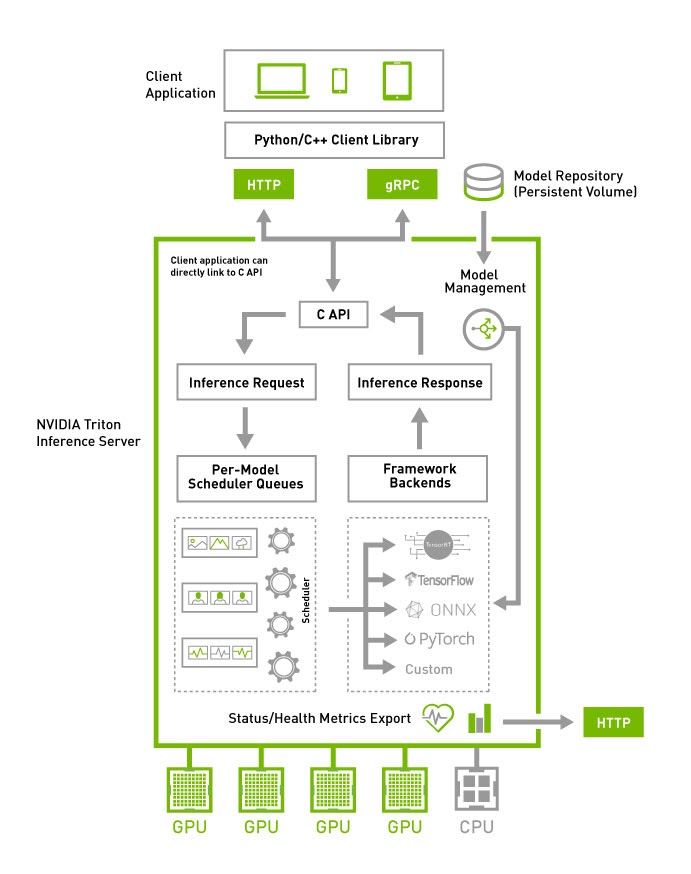
Model deployment and Optimization Practice
pytorch model deployment
The pytorch model needs to provide the model after jit.
The folder hierarchy is:
model_name/
1/model.pt
config.pbtxt
You only need to copy the above folders to the models folder in triton server to take effect (triton can be configured to monitor folder changes and restart automatically if changes occur).
config.pbtxt is the focus of this explanation and the most important thing to learn during deployment.
The following are specific examples:
#this MUST be the same name with the outside folder
name: "ibuddha_chitchat"
# pytorch
platform: "pytorch_libtorch"
# you should limit this ,or else the graphic card will doom...
max_batch_size: 64
input [
{
#pytorch output this 0,1,2 silly name by default
name: "INPUT__0"
#int64 or int32, must be the same as the model define
data_type: TYPE_INT64
#dynamic sequence len, means you can input text len from 1 to 510 typically, or else you should put a fix value here
dims: [-1]
},
{
name: "INPUT__1"
data_type: TYPE_INT64
dims: [-1]
},
{
name: "INPUT__2"
data_type: TYPE_INT64
dims: [-1]
}
]
output [
{
#pytorch silly default name
name: "OUTPUT__0"
data_type: TYPE_FP32
dims: [13088]
}
]
# output only one which has bigger version
version_policy: { latest {num_versions: 1}}
#version_policy: { all {}}
# enable dynamic will improve your performance greatly
dynamic_batching {
}
# enable this will make your inference faster
parameters: {
key: "INFERENCE_MODE"
value: {
string_value:"true"
}
}
# disable this. It is slower than default in my test
#parameters: {
#key: "ENABLE_NVFUSER"
# value: {
# string_value:"true"
# }
#}
#pytorch model only run in graphic card 0 by default
instance_group [
{
count: 1
kind: KIND_GPU
gpus: [ 0 ]
}
]1 stands for version number (it is recommended to start from 1...N, 0 is invalid)
model.pt is the agreed name
Name is the model name, which is required to be consistent with the name of the outer folder, so the outer folder must be changed to ibuddha_chitchat.
ibuddha_chitchat/
1/model.pt
config.pbtxt
The platform of the pytorch model is: pytorch_libtorch
This example uses dynamic batching, which is also an officially recommended optimization method.
dynamic_batching {}
Enabling dynamic batch will effectively improve the efficiency of reasoning system.
max_batch_size needs to be set properly. Too much will cause the graphics card to explode (triton may cause triton to hang and cannot restart automatically) (Note: this option is valid only when dynamic_batching takes effect)
Input represents the input of the model
The bert of pytorch. The typical name is input_0.. input_2
Whether the data type is TYPE_INT64 or TYPE_INT32 depends on the data type used in model training. It is also bert, some INT64 and some INT32, but the three inputs will be of the same type (no specific law has been found at present)
dims: [-1]
Represents a dynamic sequence, indicating that the length of the input text does not need to be a fixed value.
Note that since this is dynamic batching, the - 1 of the first dimension can be omitted.
(if not dynamic batching, dims: [N, -1])
The format of output and input is the same
Because the example here is a GPT model, it will return the probability of 13088 vocab s at each position in the whole sentence (floating point type) (the post-processing will select the token with the highest probability as the output (it will be more complicated in practice)).
version_policy is used to control the version
The example is written in such a way that there is only one version, and triton automatically selects the one with the largest number.
(
If you need to output all versions, you can write as follows:
version_policy: { all {}}
)
instance_group
A count of 1 means that there is only 1 instance
KIND_GPU, as its name implies, runs on the GPU (it can also be configured to run on the CPU)
gpus: [0] stands for only running on graphics card 0
Note: there is a defect in the pytorch model, which can only be fixed on a certain graphics card. By default, it is all graphics card 0 (if there is one that can run on multiple graphics cards, please inform the author)
onnx model deployment
The whole process is very similar to pytorch. Here are only the differences:
The unified model contract name is model.onnx
config.pbtxt is being written:
platform: onnxruntime_onnx
Since pytorch is converted to onnx and input_names can be configured, it is recommended to give the team an agreed name for maintenance:
input_ids, attention_mask, token_type_ids
Since the output of the instance is the average vector of the returned sentence, it is directly a 768 length floating-point array.
onnx model can also be dynamically converted to tensorRT. Whether it can be faster needs your own measurement.
name: "sps_sbert_onnx"
#onnx model
platform: "onnxruntime_onnx"
max_batch_size: 32
#recommend use the same name in your team, input_ids, attention_mask, token_type_ids
input [
{
name: "input_ids"
data_type: TYPE_INT64
dims: [-1]
},
{
name: "attention_mask"
data_type: TYPE_INT64
dims: [-1]
},
{
name: "token_type_ids"
data_type: TYPE_INT64
dims: [-1]
}
]
output [
{
#recommend to use meaningful name
name: "vector"
data_type: TYPE_FP32
dims: [768]
}
]
#version_policy: { all {}}
version_policy: { latest {num_versions: 1}}
dynamic_batching { }
#you should test whether this can be faster
#change onnx
optimization { execution_accelerators {
gpu_execution_accelerator : [ { name : "tensorrt" } ]
}}tensorflow model deployment
The saved_model format is recommended for the tensorflow model
Copy the saved_model folder to the version folder and name it model.savedmodel
1/model.savedmodel
assets
saved_model.pb
variables
config.pbtxt
name: "shansou_rank"
platform: "tensorflow_savedmodel"
max_batch_size: 128
input [
{
name: "input_ids"
data_type: TYPE_INT32
#fix length of input. input should padding to max length or truncate the text over max length
dims: [128]
},
{
name: "input_mask"
data_type: TYPE_INT32
dims: [128]
},
{
name: "segment_ids"
data_type: TYPE_INT32
dims: [128]
}
]
output [
{
name: "output"
data_type: TYPE_FP32
dims: [1]
}
]
dynamic_batching { }
#this will use V100/T4 or better graphic mix precision unit
#always fasters than tensorRT
optimization { execution_accelerators {
gpu_execution_accelerator : [
{ name : "auto_mixed_precision" }
]
}}
version_policy: { latest {num_versions: 1}}nvidia and tensorflow have been polished for the longest time and support the most functions.
For example, you can directly configure tensorRT and dynamically convert the tensorflow model to tensorRT.
The cumbersome process of converting to tensorRT in the past has been changed into an extremely simple configuration process that can take effect (recommended).
If you do not add parameters, the default is lossless FP32 precision
optimization { execution_accelerators {
gpu_execution_accelerator : [ {
name : "tensorrt"
#parameters { key: "precision_mode" value: "FP16" }}]
}}In fact, the author finally chose the mixed accuracy mode.
optimization { execution_accelerators {
gpu_execution_accelerator : [
{ name : "auto_mixed_precision" }
]
}}When the mixed accuracy mode is selected for the tensorflow model, the mixed processing unit with a graphics card capacity of 7 and above can be used (V100, T4 and above can be used).
The graphics card actually has two engines, ordinary FP32 processing unit (Civil Engine) and hybrid precision processing unit (racing engine).
The transformation from tensorflow model to tensorRT is equivalent to the extreme optimization of civil engines, which belongs to software optimization.
tensorflow model adopts mixed accuracy mode, which is equivalent to running on racing engine and belongs to hardware enhancement.
The measured mixing accuracy mode is significantly stronger than tensorRT (the test here is about twice).
At present, it is impossible to make tensorRT and hybrid accuracy model work together (this is the most ideal optimization), and it is expected to be supported in the future.
python code deployment
python code can be deployed like a model, which is essentially input - > handle - > output
models
└── ibuddha_chitchat_bls
├── 1
│ └── model.py
└── config.pbtxtHere we will explain the BLS function (Business Logic Scripting) only available since 21.08
The commonly used chat model adopts GPT model. Each reasoning can only obtain one word, which needs to be repeated, and there are many vectors returned each time (large network transmission time consumption). Therefore, it is very appropriate to put this part of logic into triton's BLS and complete it in the process.
name: "ibuddha_chitchat_bls"
backend: "python"
max_batch_size: 64
input [
{
name: "INPUT__0"
data_type: TYPE_INT64
dims: [ -1 ]
}
]
input [
{
name: "INPUT__1"
data_type: TYPE_INT64
dims: [ -1 ]
}
]
input [
{
name: "INPUT__2"
data_type: TYPE_INT64
dims: [ -1 ]
}
]
output [
{
name: "OUTPUT__0"
data_type: TYPE_INT32
dims: [ -1 ]
}
]
output [
{
name: "OUTPUT__1"
data_type: TYPE_FP32
dims: [ -1 ]
}
]
instance_group [{ kind: KIND_CPU }]
dynamic_batching {
}Because it is python code, it involves the problem of third-party libraries. A new third-party library needs to be added on the basis of the original triton image. Therefore, an additional build image is required.
Here is a key point:
python backend is configured as: instance_group[{ kind: KIND_CPU }]
The specific execution model runs on the GPU.
therefore
infer_response = infer_request.exec()
The result of this sentence after completing the model reasoning is on the GPU and cannot be used directly
You must use pytorch's to_dlpack to put the contents of the GPU into the shared memory, and then use from_dlpack to convert the contents of the shared memory into pytorch's tensor.
logits = from_dlpack(output0.to_dlpack())
There are two ways to convert the variable of triton to the tensor of pytorch:
input_ids = from_dlpack(in_0.to_dlpack())
input_ids = torch.from_numpy(in_0.as_numpy())
Using to_dlpack and from_dlpack has lower consumption.
This is a model.py without code optimization
import triton_python_backend_utils as pb_utils
from torch.utils.dlpack import from_dlpack,to_dlpack
import torch.nn.functional as F
import torch
import json
import numpy as np
class TritonPythonModel:
"""Your Python model must use the same class name. Every Python model
that is created must have "TritonPythonModel" as the class name.
"""
def initialize(self, args):
"""`initialize` is called only once when the model is being loaded.
Implementing `initialize` function is optional. This function allows
the model to intialize any state associated with this model.
Parameters
----------
args : dict
Both keys and values are strings. The dictionary keys and values are:
* model_config: A JSON string containing the model configuration
* model_instance_kind: A string containing model instance kind
* model_instance_device_id: A string containing model instance device ID
* model_repository: Model repository path
* model_version: Model version
* model_name: Model name
"""
# You must parse model_config. JSON string is not parsed here
self.model_config = json.loads(args['model_config'])
input0_config = pb_utils.get_input_config_by_name(
self.model_config, "INPUT__0")
input1_config = pb_utils.get_input_config_by_name(
self.model_config, "INPUT__1")
input2_config = pb_utils.get_input_config_by_name(
self.model_config, "INPUT__2")
output0_config = pb_utils.get_output_config_by_name(
self.model_config, "OUTPUT__0")
output1_config = pb_utils.get_output_config_by_name(
self.model_config, "OUTPUT__1")
# Convert Triton types to numpy types
self.input0_dtype = pb_utils.triton_string_to_numpy(
input0_config['data_type'])
self.input1_dtype = pb_utils.triton_string_to_numpy(
input1_config['data_type'])
self.input2_dtype = pb_utils.triton_string_to_numpy(
input2_config['data_type'])
self.output0_dtype = pb_utils.triton_string_to_numpy(
output0_config['data_type'])
self.output1_dtype = pb_utils.triton_string_to_numpy(
output1_config['data_type'])
#self.cls, self.sep, self.pad, self.speaker1, self.speaker2 = self.tokenizer.convert_tokens_to_ids(["[CLS]", "[SEP]", "[PAD]", "[speaker1]", "[speaker2]"])
#self.special_tokens_ids = [self.cls, self.sep, self.pad, self.speaker1, self.speaker2]
self.special_tokens_ids = [0, 2, 1, 13086, 13087]
self.output_min_length = 1
self.output_max_length = 64 #TODO: change
self.temperature = 0.7
self.top_p = 0.7
self.round = 1
def execute(self, requests):
"""`execute` must be implemented in every Python model. `execute`
function receives a list of pb_utils.InferenceRequest as the only
argument. This function is called when an inference request is made
for this model. Depending on the batching configuration (e.g. Dynamic
Batching) used, `requests` may contain multiple requests. Every
Python model, must create one pb_utils.InferenceResponse for every
pb_utils.InferenceRequest in `requests`. If there is an error, you can
set the error argument when creating a pb_utils.InferenceResponse
Parameters
----------
requests : list
A list of pb_utils.InferenceRequest
Returns
-------
list
A list of pb_utils.InferenceResponse. The length of this list must
be the same as `requests`
"""
responses = []
# Every Python backend must iterate over everyone of the requests
# and create a pb_utils.InferenceResponse for each of them.
for request in requests:
# Get INPUT0
in_0 = pb_utils.get_input_tensor_by_name(request, "INPUT__0")
in_1 = pb_utils.get_input_tensor_by_name(request, "INPUT__1")
in_2 = pb_utils.get_input_tensor_by_name(request, "INPUT__2")
#pytorch_tensor = from_dlpack(in_0.to_dlpack())
#print(pytorch_tensor)
# Get Model Name
#model_name = pb_utils.get_input_tensor_by_name(
# request, "MODEL_NAME")
# Model Name string
#model_name_string = model_name.as_numpy()[0]
model_name_string = "ibuddha_chitchat"
# Create inference request object
# Perform synchronous blocking inference request
# Create InferenceResponse. You can set an error here in case
# there was a problem with handling this inference request.
# Below is an example of how you can set errors in inference
# response:
#
# pb_utils.InferenceResponse(
# output_tensors=..., TritonError("An error occured"))
#
# Because the infer_response of the models contains the final
# outputs with correct output names, we can just pass the list
# of outputs to the InferenceResponse object.
#print(type(infer_response))
output_ids = []
output_confidences = []
for i in range(self.output_max_length):
infer_request = pb_utils.InferenceRequest(
model_name=model_name_string,
requested_output_names=["OUTPUT__0"],
inputs=[in_0, in_1, in_2])
infer_response = infer_request.exec()
if infer_response.has_error():
raise pb_utils.TritonModelException(
infer_response.error().message())
output0 = pb_utils.get_output_tensor_by_name(infer_response, 'OUTPUT__0')
#_logits = output0.as_numpy()
#logits = torch.from_numpy(np.array(_logits))
logits = from_dlpack(output0.to_dlpack())
#print(pytorch_tensor)
#_logits = self.triton_infer(encoded_input)[0]
#logits = torch.from_numpy(np.array(_logits))
logits = logits[0, :] / self.temperature
top_logits = self.top_filtering(logits, self.top_p)
probs = F.softmax(top_logits, dim=-1)
prev = torch.multinomial(probs, num_samples=1)
if i < self.output_min_length and prev.item() in self.special_tokens_ids:
while prev.item() in self.special_tokens_ids:
prev = torch.multinomial(probs, num_samples=1)
output_id = prev.item()
if output_id in self.special_tokens_ids:
break
output_ids.append(output_id)
output_confidences.append(probs[output_id].item())
input_ids = torch.from_numpy(in_0.as_numpy())
attention_mask = torch.from_numpy(in_1.as_numpy())
token_type_ids = torch.from_numpy(in_2.as_numpy())
#input_ids = from_dlpack(in_0.to_dlpack())
#attention_mask = from_dlpack(in_1.to_dlpack())
#token_type_ids = from_dlpack(in_2.to_dlpack())
input_ids = torch.cat((input_ids, torch.LongTensor([[output_id]])), 1)
attention_mask = torch.cat((attention_mask, torch.LongTensor([[1]])), 1)
token_type_ids = torch.cat((token_type_ids, torch.LongTensor([[output_id]])), 1)
in_0 = pb_utils.Tensor("INPUT__0", input_ids.numpy().astype(self.input0_dtype))
in_1 = pb_utils.Tensor("INPUT__1", attention_mask.numpy().astype(self.input1_dtype))
in_2 = pb_utils.Tensor("INPUT__2", token_type_ids.numpy().astype(self.input2_dtype))
#in_0 = pb_utils.Tensor.from_dlpack("INPUT__0", to_dlpack(input_ids))
#in_1 = pb_utils.Tensor.from_dlpack("INPUT__1", to_dlpack(attention_mask))
#in_2 = pb_utils.Tensor.from_dlpack("INPUT__2", to_dlpack(token_type_ids))
#print(infer_response.output_tensors())
output_ids = torch.tensor(output_ids)
output_confidences = torch.tensor(output_confidences)
output_0 = pb_utils.Tensor("OUTPUT__0", output_ids.numpy().astype(self.output0_dtype))
output_1 = pb_utils.Tensor("OUTPUT__1", output_confidences.numpy().astype(self.output1_dtype))
#output_0 = pb_utils.Tensor.from_dlpack("OUTPUT__0", to_dlpack(output_ids))
#output_1 = pb_utils.Tensor.from_dlpack("OUTPUT__1", to_dlpack(output_confidences))
inference_response = pb_utils.InferenceResponse(
output_tensors=[output_0, output_1])
#print(type(inference_response))
responses.append(inference_response)
# You should return a list of pb_utils.InferenceResponse. Length
# of this list must match the length of `requests` list.
return responses
def top_filtering(self, logits, top_p=0.0, threshold=-float('Inf'), filter_value=-float('Inf')):
#assert logits.dim() == 1 # Only work for batch size 1 for now - could update but it would obfuscate a bit the code
if top_p > 0.0:
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
cumulative_probabilities = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
sorted_indices_to_remove = cumulative_probabilities > top_p
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
sorted_indices_to_remove[..., 0] = 0
indices_to_remove = sorted_indices[sorted_indices_to_remove]
logits[indices_to_remove] = filter_value
indices_to_remove = logits < threshold
logits[indices_to_remove] = filter_value
return logits
def finalize(self):
"""`finalize` is called only once when the model is being unloaded.
Implementing `finalize` function is OPTIONAL. This function allows
the model to perform any necessary clean ups before exit.
"""
print('Cleaning up...')You can refer to the examples in python_backend.