1 problem description
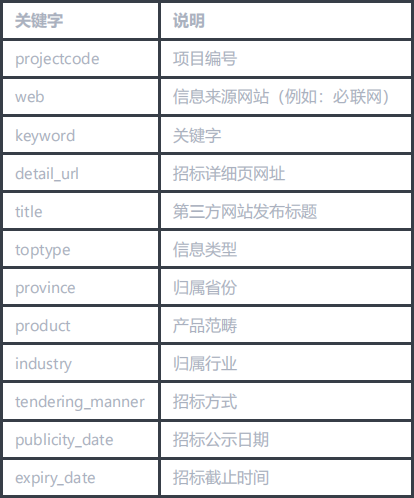
Using the Scrapy framework, complete the collection of bidding information on the Internet. The collection fields are as follows:
2 Tips for problem solving
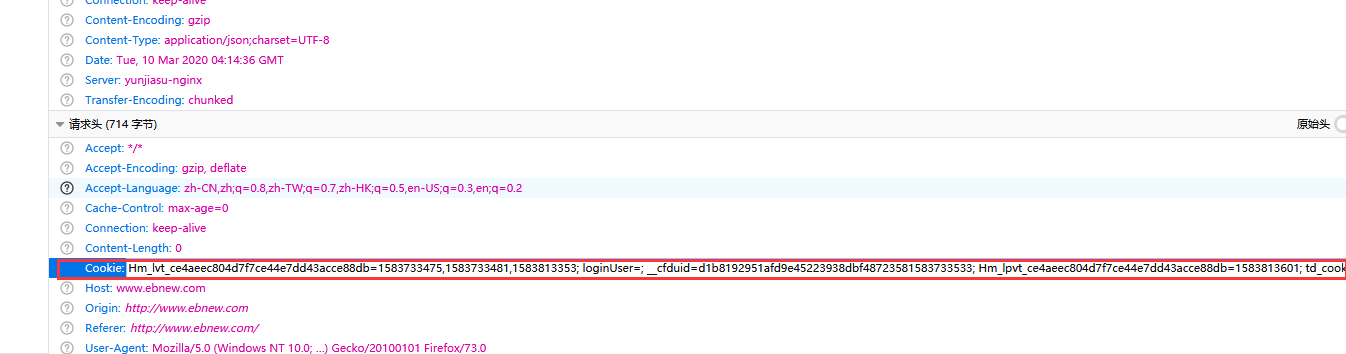
- Some pages of the Internet must be logged in to get response. You need to log in manually and get the Cookie value in the browser. Add the Cookie to the request header
- For data extraction, some regular expressions need to be customized. For example, the item number may be in the text of the detailed page, which cannot be extracted with ordinary XPath. This requires looking at several more pages, doing more tests, and analyzing the data format
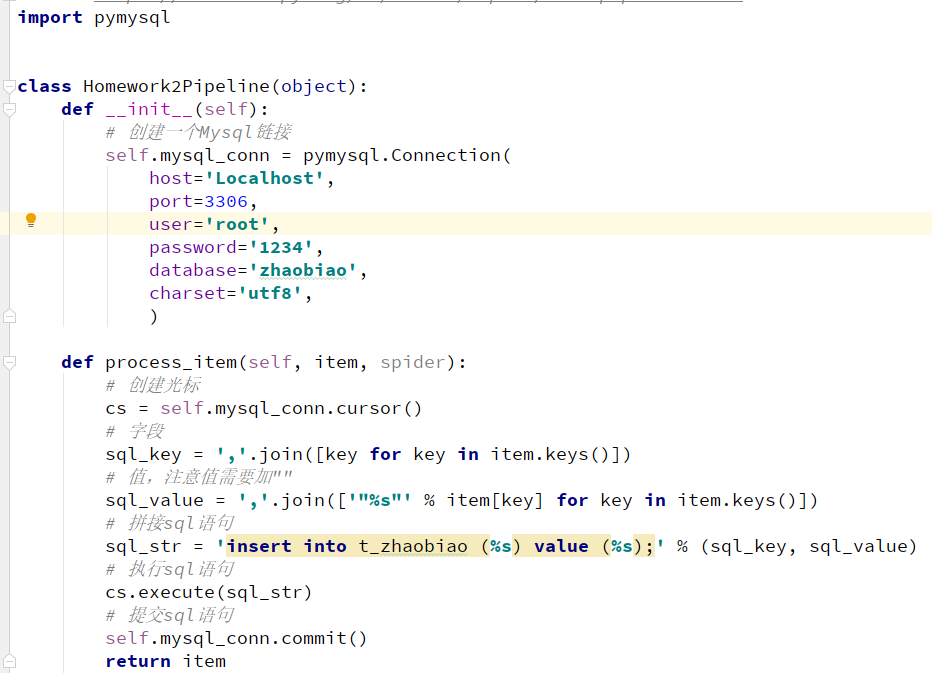
- Data persistence can be done in the pipeline file. Take the example explained in the course, save the bidding information to MySQL database
- The proxy IP should be set in the download middleware. The proxy IP needs to access the interface of the third party. For details, please refer to the steps in recording and broadcasting
3 scoring criteria
- The crawler can collect the bidding data of the must be connected network 20 points
- The accuracy of data extraction, for example, 10 points of bidding number can be extracted more effectively
- Code notes, specification 10 points
4 key points analysis
- register
- cookie
5 implementation steps
- Create a story, spider
- spider file
import scrapy
import re
from copy import deepcopy
class TenderdataSpider(scrapy.Spider):
name = 'tender_data'
# Add ss.ebnew.com to prevent filtering
allowed_domains = ['www.ebnew.com', 'ss.ebnew.com']
# start_urls = ['http://www.ebnew.com/']
# The data mode stored in the database is Dictionary: sql_data
sql_data = dict(
projectcode='', # Item number
web='Must networking', # Information source website (e.g. must be connected to the Internet)
keyword='', # Keyword
detail_url='', # Bidding details page website
title='', # Third party website release title
toptype='', # Information type
province='', # Vested provinces
product='', # Product category
industry='', # Attribution industry
tendering_manner='', # Bidding method
publicity_date='', # Date of bidding announcement
expiry_date='', # Deadline for bidding
)
# Because its submission mode is POST mode, its form data is stored according to the form data of the website
form_data = dict(
infoClassCodes='', #
rangeTyp='', #
projectType='bid', # This value does not change, so it defaults directly
fundSourceCodes='', #
dateType='', #
startDateCode='', #
endDateCode='', #
normIndustry='', #
normIndustryName='', #
zone='', #
zoneName='', #
zoneText='', #
key='', # Keywords entered by router users:
pubDateType='', #
pubDateBegin='', #
pubDateEnd='', #
sortMethod='timeDesc', # This value does not change, so it defaults directly
orgName='', #
currentPage='', # Current page 2
)
keyword_s = ['Router', 'Transformer']
# Set start request
def start_requests(self):
# request needs to submit the form
for keyword in self.keyword_s:
# Because of multithreading, deep copy is needed on storage
form_data = deepcopy(self.form_data)
form_data['key'] = keyword
form_data['currentPage'] = '1'
# Set to FormRequest instead of Request because the form data needs to be submitted
request = scrapy.FormRequest(
url='http://ss.ebnew.com/tradingSearch/index.htm',
formdata=form_data,
# Submit the response to start_parse to get the maximum page number
callback=self.start_parse,
)
# Encapsulate the form? Data data, because start? Parse requires
request.meta['form_data'] = form_data
yield request
# start_parse finds all the page numbers, encapsulates them in the request and submits them to the scheduler for processing
# Loop passes all URLs to the scheduler once
def start_parse(self, response):
# Get list with maximum page number
page_max_s = response.xpath('//form[@id="pagerSubmitForm"]/a/text()').extract()
# re.match find number
page_max = max([int(page_max) for page_max in page_max_s if re.match('\d+', page_max)])
# Test use
# page_max = 2
# Submit the form of each page to parse ﹣ page1
for page in range(1,page_max + 1):
# First get the form data, and deep copy
form_data = deepcopy(response.meta['form_data'])
# The data submitted by the form is str:currentPage = ''
form_data['currentPage'] = str(page)
request = scrapy.FormRequest(
url='http://ss.ebnew.com/tradingSearch/index.htm',
formdata=form_data,
callback=self.parse_page1,
)
request.meta['form_data'] = form_data
yield request
# Parse [page1] extracts the list of the xpath of the first page, and saves some SQL [u data data data]
# detail_url = '', # Bidding details page website
# title='', # Third party website title
# toptype='', # Information type
# province='', # Vested provinces
# product='', # Product category
# tendering_manner='', # Bidding method
# publicity_date='', # Date of bidding announcement
# expiry_date='', # Deadline for bidding
def parse_page1(self, response):
form_data = response.meta['form_data']
# xpath all page div s, which is a list
div_x_s = response.xpath('//div[contains(@class,"abstract-box")]')
for div_x in div_x_s:
# class attribute is referenced for the first time, so self is used
sql_data = deepcopy(self.sql_data)
# sql_data['web '] =' must be connected to the Internet ', which has been defaulted in the class attribute
sql_data['detail_url'] = div_x.xpath('./div[1]/a/@href').extract_first()
sql_data['toptype'] = div_x.xpath('./div[1]/i[1]/text()').extract_first()
sql_data['title'] = div_x.xpath('./div[1]/a/text()').extract_first()
sql_data['province'] = div_x.xpath('./div[2]/div[2]/p[2]/span[2]/text()').extract_first()
sql_data['product'] = div_x.xpath('./div[2]/div[1]/p[2]/span[2]/text()').extract_first()
sql_data['tendering_manner'] = div_x.xpath('./div[2]/div[1]/p[1]/span[2]/text()').extract_first()
sql_data['publicity_date'] = div_x.xpath('./div[1]/i[2]/text()').extract_first()
# Remove 'release date:'
sql_data['publicity_date'] = re.sub('[^0-9\-]', '', sql_data['publicity_date'])
sql_data['expiry_date'] = div_x.xpath('./div[2]/div[2]/p[1]/span[2]/text()').extract_first()
if sql_data['expiry_date']:
sql_data['expiry_date'] = re.sub('[0-9]{2}[:][0-9]{2}[:][0-9]{2}', '', sql_data['expiry_date'])
else:
sql_data['expiry_date'] = ""
sql_data['keyword'] = form_data.get('key')
# print( sql_data['detail_url'],sql_data['toptype'],sql_data['title'])
# Because page2 is a get request, FormRequest is not required
request = scrapy.Request(
url=sql_data['detail_url'],
callback=self.parse_page2,
)
# Encapsulate sql_data in meta and transfer values
request.meta['sql_data'] = sql_data
# print(sql_data)
yield request
# Page 2 deals with other parts of SQL data
# projectcode='', # Item number
# industry='', # Attribution industry
def parse_page2(self, response):
sql_data = response.meta['sql_data']
# print(sql_data)
sql_data['projectcode'] = response.xpath(
'//ul[contains(@class,"ebnew-project-information")]/li[1]/span[2]/text()').extract_first()
# Use regular to find item number in page
if not sql_data['projectcode']:
projectcode_find = re.findall(
'(Item encoding|Item label|Purchase document No|Tender number|Project bidding No|Item number|Bidding Document No|Bidding Document No)[: :]{0,1}\s{0,2}\n*(</span\s*>)*\n*(<span.*?>)*\n*(<u*?>)*\n*([a-zA-Z0-9\-_\[\]]{1,100})',
response.body.decode('utf-8'))
if projectcode_find:
sql_data['projectcode'] = projectcode_find[0][4] if projectcode_find else ""
sql_data['industry'] = response.xpath(
'//ul[contains(@class,"ebnew-project-information")]/li[8]/span[2]/text()').extract_first()
# When SQL ﹣ data is a dictionary, the summary engine automatically judges to pass the SQL ﹣ data to the pipeline
yield sql_data
- middleware

- Connect to database and store data