Introduction to MongoDB
concept
MongoDB is an open source database system based on distributed file storage. MongoDB is a product between relational database and non relational database. It is the most functional and relational database among non relational databases.
MongoDB is characterized by no Schema restrictions and high flexibility. The data format is BSON. BSON is a binary storage format similar to JSON, called Binary JSON for short. Like JSON, it supports embedded document objects and array objects.
MongoDB Download
MongoDB provides precompiled binary packages for 32-bit and 64 bit systems. You can download and install them from the official website of MongoDB. The download address of MongoDB precompiled binary package is: https://www.mongodb.com/download-center/community
Comparison with relational database concept
| Mysql | MongoDB |
|---|---|
| Database | Database |
| Table | Collection |
| Row | Document |
| Column | Field |
data format
MongoDB stores data as a document in BSON format. It consists of key and value.
{
"_id" : ObjectId("61d6927658c3b5acf4723616"),
"name" : "Hope primary school",
"studentNum" : 10000.0
}
Usage scenario
- Large data storage scenario
MongoDB has its own replica set and sharding, which is naturally suitable for a large number of scenarios. There is no need for developers to divide databases and tables through middleware, which is very convenient.
- Operation log storage
Many times, we need to store some operation logs, which may only need to be stored. For example, in the last month, the general practice is to clean them regularly. There is the concept of fixed set in MongoDB. We can specify the size when creating the set. When the amount of data exceeds the size, the old data will be automatically removed.
- Crawler data storage
There are web pages and data in Json format, which are generally stored in table format. If we use MongoDB, we can directly store the captured Json data in the collection without format restrictions.
- Social data storage
In the social scene, MongoDB is used to store user address and location information, and the nearby people, nearby places, etc. are realized through geographic location index.
- E-commerce commodity storage
Different commodities have different attributes. The common practice is to extract the public attribute table and associate it with SPU. If MongoDB is used, the attributes can be embedded directly in SPU.
CRUD
Insert a single document into a collection
- db.collection.insertOne()
Insert multiple documents into the collection
- db.collection.insertMany()
Single or multiple files are inserted into the collection
- db.collection.insert()
Query data
- db.collection.find( )
Update single
- db.inventory.updateOne()
Update multiple
- db.inventory.updateMany()
Delete a single document
- db.inventory.deleteOne( )
Delete multiple documents
- db.inventory.deleteMany()
Aggregation
Aggregation operation is used for data statistics. For example, Mysql has functions such as count, sum, group by, etc. in MongoDB, the corresponding aggregation operation is aggregation.
Aggregation there are two ways to realize the need for data statistics. One is aggregate and the other is MapReduce.
Aggregation operation is used for data statistics. For example, Mysql has functions such as count, sum, group by, etc. in MongoDB, the corresponding aggregation operation is aggregation.
Aggregation there are two ways to realize the need for data statistics. One is aggregate and the other is MapReduce.
The following figure shows how aggregate works:
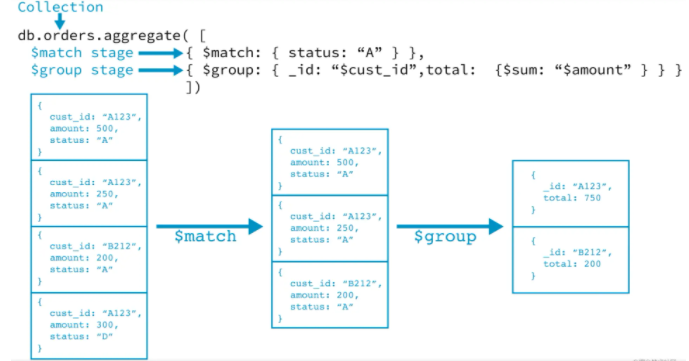
Aggregation has many built-in functions. After using these functions, we can count the data we want.
$project: modify the structure of the input document. It can be used to rename, add, or delete fields, or to create calculation results and nested documents.
$match: used to filter data and output only qualified documents. Match uses MongoDB's standard query operation.
$limit: used to limit the number of documents returned by the MongoDB aggregation pipeline.
$skip: skip the specified number of documents in the aggregation pipeline and return the remaining documents.
$group: groups documents in the collection, which can be used to count results.
$sort: sort the input documents and output them.
$geoNear: output ordered documents close to a geographic location.
$unwind: split an array type field in the document into multiple pieces, each containing a value in the array.
The following figure shows the execution principle of MapReduce:

There are 4 pieces of data in total. Query specifies query criteria and only processes data with status=A.
In the map stage, the data is grouped and aggregated, that is, the effect of the third part is formed, according to cust_id de duplication statistics.
The key in reduce is cust_id and values are the total amount set. Then perform sum operation, and the final result is output to a collection through out.
Transactions
MongoDB does not support transactions at first. In MongoDB, the operation on a single document is atomic. Therefore, when redesigning, embedded documents and arrays can be used to describe the relationship between data, so that there is no need to operate across multiple documents and sets, which eliminates the need for multi document transactions in many practical use cases through single document atomicity.
Everything is limited. In some scenarios, data relationships cannot be completely described in an embedded way, or there will be multiple sets. It is convenient for users using MongoDB to support transactions.
The release of mongodb version 4.0 has brought us native transaction operations.
Indexes
The function of index will not be repeated here. Single index, combined index, full-text index, Hash index, etc.
db.collection.createIndex({user_id: 1, add_time: 1}, {background: true})
Copy code
When creating an index, you should pay special attention to setting background to true. Other database operations will be blocked during the process of creating an index. Background can specify the background method to create an index, which is false by default.
Security
Attention should be paid to the security in MongoDB. At present, it is unknown whether there are mandatory restrictions on startup. In the past, the authentication method can not be specified during startup, that is, access can be obtained without a password. Then, the default port directly used by many people is exposed on the public network, giving opportunities for illegal children, and the data is deleted, There are many cases where bitcoin needs to be used to retrieve data.
You still need to enable security authentication. There are many built-in roles. Different roles have different operational contents, and the control is relatively detailed.
Replication
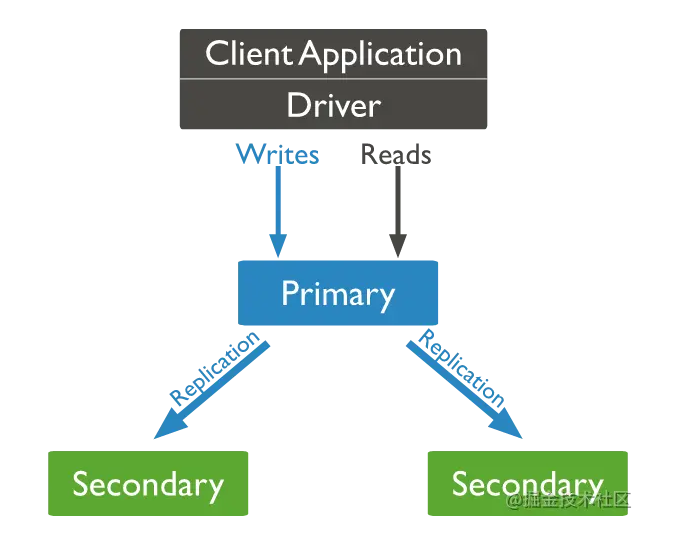
Replica set is a set of MongoDB instances with the same dataset, which stores data in multiple nodes at the same time, improving availability. The master node is responsible for writing and the slave node is responsible for reading, so as to improve the overall performance.
The replica set consists of the following components:
Primary: the primary node receives all write operations.
Secondary nodes: the slave node will copy data from the master node and maintain the same data as the master node. Used for query operations.
Arbiter: the arbitration node itself does not store data, but only participates in the election.
Sharding
Sharding is the absolute highlight of MongoDB, which splits the data horizontally into multiple nodes. MongoDB fragmentation is fully automatic. We only need to configure the fragmentation rules, and it can automatically maintain data and store it in different nodes. MongoDB uses sharding to support large data storage and high-throughput operations.
The following figure shows Mongodb's fragmented cluster architecture:
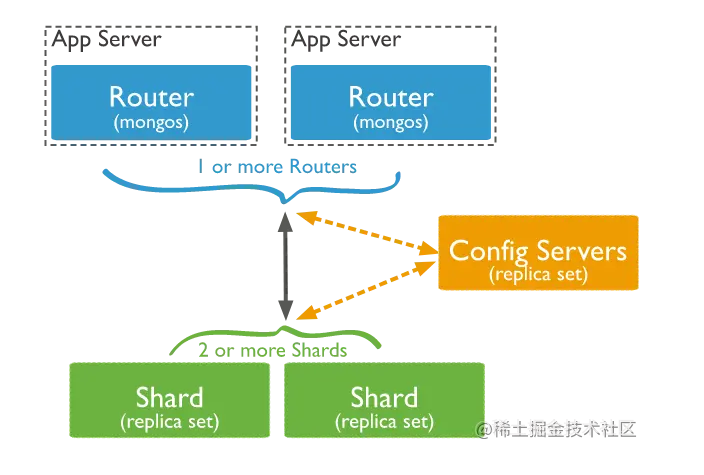
mongoDB partitioned cluster consists of the following components:
Shard: the data of each shard is an independent and complete copy. And can be deployed as a replica set.
Mongos: mongos is a query router. At the middle layer between the client and server, the request will be directly to mongos, which will route to the specific Shard.
Config Servers: stores the routing information of all nodes and fragmented data in the cluster.
GridFS
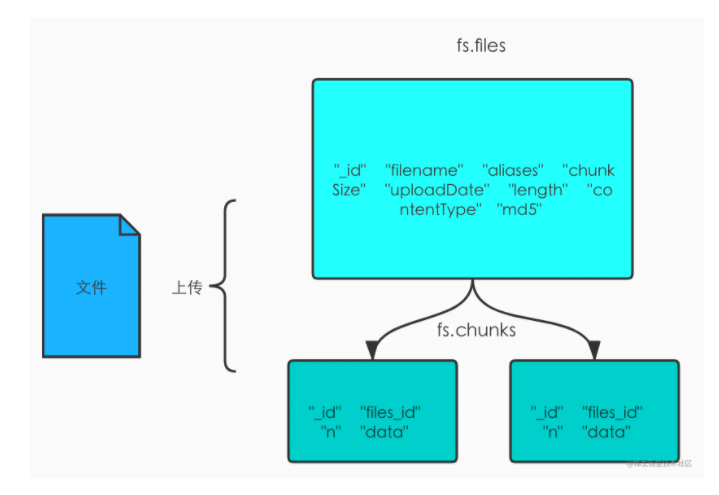
GridFS is a sub module of MongoDB. It is mainly used to store files in MongoDB, which is equivalent to a built-in distributed file system of MongoDB.
In essence, the data of the file is stored in blocks in the collection. By default, the file collection is divided into FS Files and FS chunks.
fs.files is the basic information for storing files, such as file name, size, upload time, md5, etc. fs.chunks is the place where the real data of a file is stored. A file will be divided into multiple chunk s for storage, generally 256k / piece.
If MongoDB is used in your project, you can use GridFS to build a file system, so you don't have to buy third-party storage services.
The advantage of GridFS is that you don't have to build a file system alone. You can directly use the self-contained file system of mongodb. Backup and fragmentation depend on mongodb, which is also convenient to maintain.
Summary of knowledge points
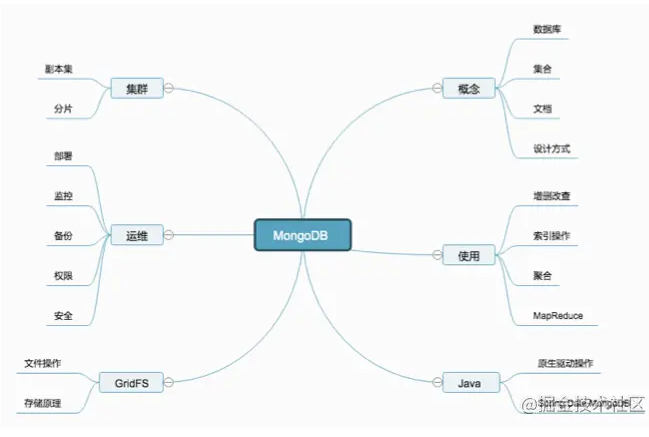
Necessary for development work
Syntax comparison between MongoDB and Mysql


MongoDB integration in Spring Boot
Dependencies for joining MongoDB:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-mongodb</artifactId> </dependency>
Configure MongoDB information:
spring.data.mongodb.database=test spring.data.mongodb.host=localhost spring.data.mongodb.port=27017 // User name, password omitted
You can directly inject MongoTemplate to operate MongoDB:
@Autowired private MongoTemplate mongoTemplate;
Use list
Create an entity class corresponding to the MongoDB collection
@Data
@Document(collection = "article_info")
public class Article {
@Id
@GeneratedValue
private Long id;
@Field("title")
private String title;
@Field("url")
private String url;
@Field("author")
private String author;
@Field("tags")
private List<String> tags;
@Field("visit_count")
private Long visitCount;
@Field("add_time")
private Date addTime;
}
The format finally stored in the data is as follows:
{
"_id" : ObjectId("5e141148473cce6a9ef349c7"),
"title" : "Batch update",
"url" : "http://cxytiandi.com/blog/detail/8",
"author" : "yinjihuan",
"tags" : [
"java",
"mongodb",
"spring"
],
"visit_count" : NumberLong(10),
"add_time" : ISODate("2019-02-11T07:10:32.936+0000")
}
insert data
Article article = new Article();
article.setTitle("MongoTemplate Basic use of ");
article.setAuthor("yinjihuan");
article.setUrl("http://cxytiandi.com/blog/detail/1");
article.setTags(Arrays.asList("java", "mongodb", "spring"));
article.setVisitCount(0L);
article.setAddTime(new Date());
mongoTemplate.save(article);
Database syntax
db.article_info.save({
"title": "Batch update",
"url": "http://cxytiandi.com/blog/detail/8",
"author": "yinjihuan",
"tags": [
"java",
"mongodb",
"spring"
],
"visit_count": NumberLong(10),
"add_time": ISODate("2019-02-11T07:10:32.936+0000")
})
Update data
Query query = Query.query(Criteria.where("author").is("yinjihuan"));
Update update = Update.update("title", "MongoTemplate")
.set("visitCount", 10);
mongoTemplate.updateMulti(query, update, Article.class);
Database syntax
db.article_info.updateMany(
{"author":"yinjihuan"},
{"$set":
{
"title":"MongoTemplate",
"visit_count": NumberLong(10)
}
}
)
Delete data
Query query = Query.query(Criteria.where("author").is("yinjihuan"));
mongoTemplate.remove(query, Article.class);
Database syntax
db.article_info.remove({"author":"yinjihuan"})
Query data
Query query = Query.query(Criteria.where("author").is("yinjihuan"));
List<Article> articles = mongoTemplate.find(query, Article.class);
Database syntax
db.article_info.find({"author":"yinjihuan"})
Storage file
File file = new File("/Users/yinjihuan/Downloads/logo.png");
InputStream content = new FileInputStream(file);
// Store additional information of the file, such as user ID, which can be queried directly when you want to query all files of a user later
DBObject metadata = new BasicDBObject("userId", "1001");
ObjectId fileId = gridFsTemplate.store(content, file.getName(), "image/png", metadata);