0.5372018.04.22 21:20:07 Word Number 4283 Reading 4842
Mongodb fragmented summary
-
Fragmentation is a method of distributing data across multiple servers. Mongodb uses fragmentation to support deployment of operations with very large datasets and high throughput
-
A database system with large data sets and high throughput applications can challenge the capacity of a single server.
For example, high query rate can deplete the cpu capacity of the server, and the working set size is larger than the I/O capacity of the RAM forced disk drive of the system. -
There are two ways to address system growth: vertical and horizontal scaling.
-
Vertical scaling involves increasing the capacity of a single server, such as using a stronger CPU, adding more RAM, or increasing storage space. Limitations in available technologies may limit the sufficiency of a single machine for a given workload. In addition, cloud-based providers have a hard upper limit based on available hardware configurations. Therefore, there is an actual maximum for vertical scaling.
-
Including the system data and load in multiple servers, add additional servers, need to increase capacity. Although the total speed or capacity of a single machine may not be high, each machine processes a subset of the entire workload, potentially providing better efficiency than a single high-speed, large-capacity server. Expanding deployment capacity requires only additional servers as needed, which can be a lower overall cost than the high-end hardware of a single machine. The trade-off is the maintenance of infrastructure complexity and deployment.
-
-
Mongodb's support level is expanded and fragmented.
1. Fragmentation Purpose
For a single database server, huge data volume and high throughput applications are undoubtedly a huge challenge for it. Frequent CRUD operations can deplete the CPU resources of servers. Rapid data growth will also make hard disk storage powerless. Eventually, memory can not meet the data needs, resulting in a large number of I/O, and heavy load on the host. To solve this problem, there are generally two methods for database systems: vertical expansion and fragmentation (horizontal expansion).
[Vertical Extension]: Adding more CPUs and storage resources to increase system performance. The disadvantage of this method is that high-end machines with large CPU and RAM resources are much more expensive than ordinary PC machines, and a single point of failure will affect the service of the whole system.
Fragmentation: On the contrary, fragmentation distributes large data sets to multiple hosts, each fragment is an independent database, and these fragments constitute a complete logical database as a whole. Fragmentation reduces the amount of data operation on each server. With the growth of cluster, each fragmentation processes fewer and fewer data. As a result, the overall service capability of the system is increased. In addition, fragmentation also reduces the amount of data that each server needs to store.
2. Fragmentation in MongoDB
MongoDB supports fragmentation by configuring fragmentation clusters. A fragmentation cluster consists of the following components: fragmentation, query routing, and configuration server.
- Fragmentation: Used to store data, in order to provide system availability and data consistency, a fragmentation cluster of production environments, usually each fragment is a replica set.
- Query Routing: The path through which client applications access each fragment.
- Configuration server: Stores metadata of the cluster, which contains the mapping relationship between the cluster data set and the fragments. Query routing uses these metadata to perform specified data operations on specific fragments. (Starting with v3.2, the configuration server can also be used as a replica set, but it must be used WiredTiger Storage engine, against using three mirror instances as configuration servers)
Data partition
The data partitioning of MongoDB is based on the collection level. Fragmentation divides the set data by shard key.
- shard key:
To partition the collection, you need to specify a shard key. Shard key can be either an index field for each document in the collection or a composite index field for each document in the collection. MongoDB divides shard keys values into chunks and distributes these chunks evenly across the slices. MongoDB uses range-based partitioning or hash-based partitioning to partition chunks.
- Scope-based division:
MongoDB divides data sets into different ranges through shard key values, which is called range-based partitioning. For numeric shard keys: you can fabricate a line from negative infinity to positive infinity (understood as the x-axis), where each shard key value falls at a point in the line. Then MongoDB divides the line into many smaller chunks without repetition, a chunk being the smallest to the smallest. The range of large values.
- Hash-based partitioning:
MongoDB calculates hash values for each field, and then uses these hash values to create chunks.
- Performance comparison based on range and hash partitioning:
Range partitioning is more efficient for range query. Assuming that range queries are performed on shard key, query routing can easily know which blocks overlap with this range, and then send related queries along this route to slices containing only these chunks. However, it is easy to cause uneven distribution of data based on range partitioning, which will weaken the function of fragmented cluster. For example, when shard key is a field that rises in a straight line, such as time. Then, all requests within a given time range are mapped to the same chunk, that is, the same fragment. In this case, a small part of the fragmentation will bear most of the requests, so the overall expansion of the system is not ideal.
On the contrary, hash-based partitioning can distribute data evenly at the expense of efficient range query, and hash values can ensure that data is randomly distributed to each fragment.
- Use labels to customize data distribution
MongoDB allows DBAs to directly balance data distribution strategies by tagging fragmentation. DBAs can create tags and associate them with the range of shard key values, then assign these tags to each fragment, and eventually the balancer transfers tagged data to the corresponding fragment to ensure that the cluster always follows Data distribution is done as labels describe. Label is the main method to control balancer behavior and block distribution in cluster
4. Maintaining a Balanced Data Distribution
New data and servers will lead to unbalanced distribution of cluster data. MongoDB uses two ways to ensure the balance of data distribution:
- split
Splitting is a background process that prevents blocks from becoming too large. When a block grows to a specified block size, the splitting process is divided into two parts, and the whole splitting process is efficient. It does not involve data migration and other operations.
- balance
Balancer is a background process that manages the migration of blocks. The balancer can run on any mongd instance of the cluster. When the data in the cluster is unevenly distributed, the balancer will migrate more blocks in a slice to slices with fewer blocks until the data slices are balanced. For example, if the set users have 100 blocks in Fragment 1 and 50 blocks in Fragment 2, the balancer will migrate the blocks in Fragment 1 to Fragment 2 until the balance is maintained.
Fragmentation manages the migration of blocks between source fragmentation and target fragmentation by background operation. During migration, blocks in the source slice send all documents to the target slice, and then the target slice captures and applies these changes. Finally, update the metadata about block location on the configuration server.
- Adding and deleting fragments from the cluster
Adding new fragments to the cluster results in data imbalance because there are no blocks in the new fragments. When MongoDB starts migrating data to the new fragments, it may take some time to balance the data fragments.
When deleting a fragment, the balancer will migrate all the blocks in the fragment to another fragment. After completing these migrations and updating metadata, you can safely delete the fragment.
Piecewise Cluster
-
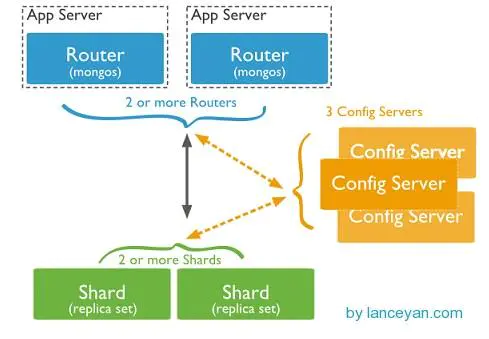
A mongodb fragmented cluster consists of the following components
12.jpg
-
Shard. Each shard contains a subset of fragmented data, and each shard can deploy a replica set
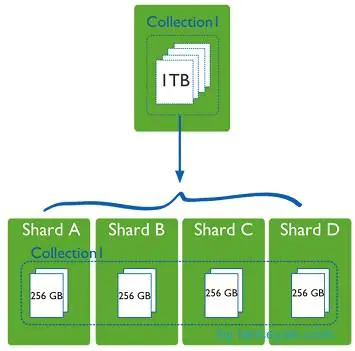
Collection 1, a data table of a machine, stores 1T of data. It's too stressful! After four machines were allocated, each machine was 256G, and the pressure on one machine was shared. Maybe someone asked if a machine's hard disk could be enlarged a little. Why should it be allocated to four machines? Don't just think about storage space. The actual database running also has hard disk reading and writing, network IO, CPU and memory bottlenecks. As long as the fragmentation rules are set up in the mongodb cluster, the corresponding data operation requests can be automatically forwarded to the corresponding fragmentation machine through the mongos operation database. In the production environment, the slicing keys can be well set up, which affects how to distribute data evenly to multiple slicing machines. Do not appear that one machine has 1 T, other machines have not, so it is better not to slice!
13.jpg
- Mongos MongoS acts as a query router, providing the interface between client application program and the fragmented cluster. Mongos acts as the entrance of database cluster requests. All requests are coordinated through mongos. There is no need to add a routing selector to the application program. Mongos itself is a request distribution. The center is responsible for forwarding the corresponding data requests to the corresponding shard server. In the production environment, there are usually multiple monogs as the entrance of the requests to prevent one of them from hanging up all the mongos requests and not being able to operate.
- Configuration servers store metadata and configuration settings for cluster-configured servers. Starting with Mongodb 3.4, configuration servers must be deployed as replication sets. Mongos itself does not physically store fragmented servers and data routing information, but is cached in memory. Configuration servers actually store these data for the first time, Mongos Starting or turning off reboot loads configuration information from config server. If configuration information changes later, it updates its status through all mongos, so that mongs can continue to route accurately. In a production environment, there are usually multiple config server configuration servers, because it stores metadata of fragmented routing, such as If you hang one, the whole mongodb base will hang up.
Chip key
-
Chip key
1. When distributing files in a collection, the collection key used by the partition of mongodb is an immutable or multiple field in each document that exists in the target collection.
2. Select the slice key when partitioning the set, <font color=red size=4> the slice key can not be changed after completion of the slice key </font>, the slice set can only have one slice key, to the non-empty set of the slice key, the set must have an index to start with the slice key, for the empty set, if the set does not have the relevant index of the specified slice key. Mongodb creates an index
3. The choice of splitting keys will affect the performance, efficiency and scalability of the splitting cluster. The best possible hardware can reach the bottleneck through splitting. The choice of splitting keys and their support index can also affect the data splitting, but the cluster can use them.
4. Chip keys determine the distribution of files in a collection in a cluster. Chip key fields must be indexed, and each record in the collection can not be empty. They can be a single field or a composite field.
5. Mongodb uses the range of slice keys to distribute data in slices. Each range, also known as data block, defines a non-overlapping range of slice keys. Mongodb distributes data blocks and documents stored by them into different distributions in the cluster. When the size of a data block exceeds the maximum size of the data block, Mongodb will The range of aggregator keys splits data blocks into smaller data blocks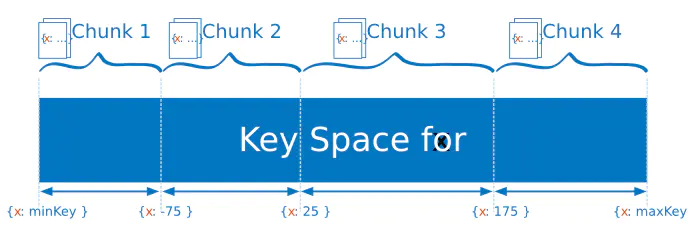
14.png
- Grammar for the Use of Slice Keys
1. In a fragmented set, sh.shardCollection() of the target set and the fragment key must be formulated.
sh.shardCollection(namespace, key)
2. Hash slice keys use single field hash index to distribute data between slices, divisor redundancy and consistency hash
3. Fields selected as slice keys must have sufficient cardinality or different values. For monotonous incremental fields, if ObjectID or timestamp, hash indexing works better.
4. If a hash key is created in an empty set, Mongodb automatically creates and migrates data blocks to ensure that there are two data blocks on each slice. It can also execute shardCollection to specify num Initial Chunks parameters to control the number of data blocks created by Mongodb at initialization, or manually call split command to split on slices. data block
5. Mongodb automatically calculates the hash value when requesting a set that uses hash key fragmentation. The application does not need to parse the hash value.
shard cluster deployment
- Deployment ip planning
172.17.237.33:30001 config1
172.17.237.34:30002 config2
172.17.237.36:30003 config3
172.17.237.37:40000 mongos
172.17.237.38:50000 shard1
172.17.237.39:50001 shard2
172.17.237.40:50002 shard3
172.17.237.41:60000 sha1
172.17.237.42:60001 sha2
172.17.237.43:60002 sha3
Configure config server replica set
- Configure confi1 configuration file
[root@My-Dev db2]# vim config1.conf [root@My-Dev db1]# vim configsvr.conf logpath=/home/mongodb/test/db1/log/db1.log pidfilepath=/home/mongodb/test/db1/db1.pid logappend=true port=30000 fork=true dbpath=/home/mongodb/test/db1/data configsvr=true # Add this to the configuration file oplogSize=512 replSet=config
- Configure confi2 configuration file
[root@My-Dev db2]# vim config2.conf logpath=/home/mongodb/test/db2/log/db2.log pidfilepath=/home/mongodb/test/db2/db2.pid logappend=true port=30001 fork=true dbpath=/home/mongodb/test/db2/data oplogSize=512 replSet=config configsvr=true
- Configure confi3 configuration file
[root@My-Dev db2]# vim config3.conf logpath=/home/mongodb/test/db3/log/db3.log pidfilepath=/home/mongodb/test/db3/db3.pid logappend=true port=30002 fork=true dbpath=/home/mongodb/test/db3/data oplogSize=512 replSet=config configsvr=true
- Start config server
[root@My-Dev bin]# ./mongod -f /home/mongodb/test/db1/config1.conf about to fork child process, waiting until server is ready for connections. forked process: 5260 child process started successfully, parent exiting [root@My-Dev bin]# ./mongod -f /home/mongodb/test/db2/config2.conf about to fork child process, waiting until server is ready for connections. forked process: 5202 child process started successfully, parent exiting [root@My-Dev bin]# ./mongod -f /home/mongodb/test/db3/config3.conf about to fork child process, waiting until server is ready for connections. forked process: 4260 child process started successfully, parent exiting
- Configure config replica set
> use admin switched to db admin > config = { _id:"config",members:[ {_id:0,host:"conf1:30000"}, {_id:1,host:"conf2:30001"}, {_id:2,host:"conf3:30002"}] } #Define replica sets { "_id" : "config", "members" : [ { "_id" : 0, "host" : "conf1:30000" }, { "_id" : 1, "host" : "conf2:30001" }, { "_id" : 2, "host" : "conf3:30002" } ] } > rs.initiate(config) #Initialize replica sets { "ok" : 1 }
Configure mongos
- Add configuration mongos configuration file
Encountered a pit and failed to start mongos. As a result, the version config server after mongodb 3.0 must be a replica set. As a result, my version is the latest version of 3.4, so two config servers need to be added.
[root@My-Dev db4]# vim mongos.conf logpath=/home/mongodb/test/db4/log/db4.log pidfilepath=/home/mongodb/test/db4/db4.pid logappend=true port=40004 fork=true configdb=mongos/172.17.237.33:30000,172.17.237.34:30001,172.17.237.36:30002 #If you have more than one mongo confi, separate it with commas
- Start mongos
[root@My-Dev bin]# ./mongos -f /home/mongodb/test/db4/mongos.conf about to fork child process, waiting until server is ready for connections. forked process: 6268 child process started successfully, parent exiting
shard2 replica set cluster deployment
- Configure sha configuration file
[root@My-Dev db8]# more shard21.conf logpath=/home/mongodb/test/db8/log/db8.log pidfilepath=/home/mongodb/test/db8/db8.pid directoryperdb=true logappend=true port=60000 fork=true dbpath=/home/mongodb/test/db8/data oplogSize=512 replSet=sha shardsvr=true [root@My-Dev db9]# more shard22.conf logpath=/home/mongodb/test/db9/log/db9.log pidfilepath=/home/mongodb/test/db9/db9.pid directoryperdb=true logappend=true port=60001 fork=true dbpath=/home/mongodb/test/db9/data oplogSize=512 replSet=sha shardsvr=true [root@My-Dev db10]# more shard23.conf logpath=/home/mongodb/test/db10/log/db10.log pidfilepath=/home/mongodb/test/db10/db10.pid directoryperdb=true logappend=true port=60002 fork=true dbpath=/home/mongodb/test/db10/data oplogSize=512 replSet=sha shardsvr=true
- Start shard
[root@My-Dev bin]# ./mongod -f /home/mongodb/test/db8/shard21.conf [root@My-Dev bin]# ./mongod -f /home/mongodb/test/db9/shard22.conf [root@My-Dev bin]# ./mongod -f /home/mongodb/test/db10/shard23.conf
- Configure shard2 replica set cluster
> use admin switched to db admin > sha = { _id:"sha",members:[ {_id:0,host:"sha1:60000"}, {_id:1,host:"sha2:60001"}, {_id:2,host:"sha3:60002"}]} { "_id" : "sha", "members" : [ { "_id" : 0, "host" : "sha1:60000" }, { "_id" : 1, "host" : "sha2:60001" }, { "_id" : 2, "host" : "sha3:60002" } ] } > rs.initiate(sha) { "ok" : 1 }
shard1 replica set cluster deployment
- Configure shard Profile
[root@My-Dev db5]# vim shard1.conf logpath=/home/mongodb/test/db5/log/db5.log pidfilepath=/home/mongodb/test/db5/db5.pid directoryperdb=true logappend=true port=50000 fork=true dbpath=/home/mongodb/test/db5/data oplogSize=512 replSet=shard shardsvr=true [root@My-Dev db6]# vim shard2.conf logpath=/home/mongodb/test/db6/log/db6.log pidfilepath=/home/mongodb/test/db6/db6.pid directoryperdb=true logappend=true port=50001 fork=true dbpath=/home/mongodb/test/db6/data oplogSize=512 replSet=shard shardsvr=true [root@My-Dev db7]# vim shard3.conf logpath=/home/mongodb/test/db7/log/db7.log pidfilepath=/home/mongodb/test/db7/db7.pid directoryperdb=true logappend=true port=50002 fork=true dbpath=/home/mongodb/test/db7/data oplogSize=512 replSet=shard shardsvr=true
- Start shard
[root@My-Dev bin]# ./mongod -f /home/mongodb/test/db7/shard1.conf [root@My-Dev bin]# ./mongod -f /home/mongodb/test/db7/shard2.conf [root@My-Dev bin]# ./mongod -f /home/mongodb/test/db7/shard3.conf
- Configure shard2 replica set cluster
> use admin switched to db admin > shard = { _id:"shard",members:[ {_id:0,host:"shard1:50000"}, {_id:1,host:"shard2:50001"}, {_id:2,host:"shard3:50002"}] } { "_id" : "shard", "members" : [ { "_id" : 0, "host" : "shard1:50000" }, { "_id" : 1, "host" : "shard2:50001" }, { "_id" : 2, "host" : "shard3:50002" } ] } > rs.initiate(shard) { "ok" : 1 }
Piecewise configuration
-
Is there data in a fragmented set?
By default, the first shard added is the main shard, and the shard stored without segmentation is the main shard.
When creating a fragment, you must create it in the index. If there is data in the collection, you first create the index and then fragment it. If there is no data in the fragment collection, you don't need to create an index, you can fragment it. -
Log in to mongos configuration fragmentation and add shard server and replica set to partition cluster
[root@My-Dev bin]# ./mongo mongos:40004 #Log in to mongos mongos> sh.status() #View fragmentation status --- Sharding Status --- sharding version: { "_id" : 1, "minCompatibleVersion" : 5, "currentVersion" : 6, "clusterId" : ObjectId("589b0cff36b0915841e2a0a2") } shards: active mongoses: "3.4.1" : 1 autosplit: Currently enabled: yes balancer: Currently enabled: yes Currently running: no Balancer lock taken at Wed Feb 08 2017 20:20:16 GMT+0800 (CST) by ConfigServer:Balancer Failed balancer rounds in last 5 attempts: 0 Migration Results for the last 24 hours: No recent migrations databases:
- Add shard replica set
#The first step is to log in to the Shard replica set to see which is the primary node. This lab uses two shard replica sets sh. addShard ("<replSetName>/IP/port of the primary node"). mongos> sh.addShard("shard/shard1:50000") { "shardAdded" : "shard", "ok" : 1 } mongos> sh.addShard("sha/sha:60000") { "shardAdded" : "shard", "ok" : 1 } mongos> sh.status() #View fragmentation cluster has successfully added shard to fragmentation --- Sharding Status --- sharding version: { "_id" : 1, "minCompatibleVersion" : 5, "currentVersion" : 6, "clusterId" : ObjectId("589b0cff36b0915841e2a0a2") } shards: { "_id" : "sha", "host" : "sha/sha1:60000,sha2:60001,sha3:60002", "state" : 1 } { "_id" : "shard", "host" : "shard/shard1:50000,shard2:50001,shard3:50002", "state" : 1 } active mongoses: "3.4.1" : 1 autosplit: Currently enabled: yes balancer: Currently enabled: yes Currently running: no Balancer lock taken at Wed Feb 08 2017 20:20:16 GMT+0800 (CST) by ConfigServer:Balancer Failed balancer rounds in last 5 attempts: 5 Last reported error: Cannot accept sharding commands if not started with --shardsvr Time of Reported error: Thu Feb 09 2017 17:42:21 GMT+0800 (CST) Migration Results for the last 24 hours: No recent migrations databa
- Specify which database uses fragmentation to create a fragment key
mongos> sh.enableSharding("zhao") #Specify fragmentation in zhao database { "ok" : 1 } mongos> sh.shardCollection("zhao.call",{name:1,age:1}) #Create slice keys with name and age as ascending order in zhao database and call collection { "collectionsharded" : "zhao.call", "ok" : 1 }
- View sh.status() information
mongos> sh.status() --- Sharding Status --- sharding version: { "_id" : 1, "minCompatibleVersion" : 5, "currentVersion" : 6, "clusterId" : ObjectId("589b0cff36b0915841e2a0a2") } shards: { "_id" : "sha", "host" : "sha/sha1:60000,sha2:60001,sha3:60002", "state" : 1 } { "_id" : "shard", "host" : "shard/shard1:50000,shard2:50001,shard3:50002", "state" : 1 } active mongoses: "3.4.1" : 1 autosplit: Currently enabled: yes balancer: Currently enabled: yes Currently running: no Balancer lock taken at Wed Feb 08 2017 20:20:16 GMT+0800 (CST) by ConfigServer:Balancer Failed balancer rounds in last 5 attempts: 5 Last reported error: Cannot accept sharding commands if not started with --shardsvr Time of Reported error: Thu Feb 09 2017 17:56:02 GMT+0800 (CST) Migration Results for the last 24 hours: No recent migrations databases: { "_id" : "zhao", "primary" : "shard", "partitioned" : true } zhao.call shard key: { "name" : 1, "age" : 1 } unique: false balancing: true chunks: shard 1 { "name" : { "$minKey" : 1 }, "age" : { "$minKey" : 1 } } -->> { "name" : { "$maxKey" : 1 }, "age" : { "$maxKey" : 1 } } on : shard Timestamp(1, 0)
- Test batch insertion data validation
mongos> for ( var i=1;i<10000000;i++){db.call.insert({"name":"user"+i,age:i})};
- Check to see if the current shards have been sliced into two shards
mongos> sh.status() --- Sharding Status --- sharding version: { "_id" : 1, "minCompatibleVersion" : 5, "currentVersion" : 6, "clusterId" : ObjectId("589b0cff36b0915841e2a0a2") } shards: { "_id" : "sha", "host" : "sha/sha1:60000,sha2:60001,sha3:60002", "state" : 1 } { "_id" : "shard", "host" : "shard/shard1:50000,shard2:50001,shard3:50002", "state" : 1 } active mongoses: "3.4.1" : 1 autosplit: Currently enabled: yes balancer: Currently enabled: yes Currently running: no Balancer lock taken at Wed Feb 08 2017 20:20:16 GMT+0800 (CST) by ConfigServer:Balancer Failed balancer rounds in last 5 attempts: 5 Last reported error: Cannot accept sharding commands if not started with --shardsvr Time of Reported error: Thu Feb 09 2017 17:56:02 GMT+0800 (CST) Migration Results for the last 24 hours: 4 : Success databases: { "_id" : "zhao", "primary" : "shard", "partitioned" : true } zhao.call shard key: { "name" : 1, "age" : 1 } unique: false balancing: true chunks: #The data has been fragmented into two chunks sha 4 shard 5 { "name" : { "$minKey" : 1 }, "age" : { "$minKey" : 1 } } -->> { "name" : "user1", "age" : 1 } on : sha Timestamp(4, 1) { "name" : "user1", "age" : 1 } -->> { "name" : "user1", "age" : 21 } on : shard Timestamp(5, 1) { "name" : "user1", "age" : 21 } -->> { "name" : "user1", "age" : 164503 } on : shard Timestamp(2, 2) { "name" : "user1", "age" : 164503 } -->> { "name" : "user1", "age" : 355309 } on : shard Timestamp(2, 3) { "name" : "user1", "age" : 355309 } -->> { "name" : "user1", "age" : 523081 } on : sha Timestamp(3, 2) { "name" : "user1", "age" : 523081 } -->> { "name" : "user1", "age" : 710594 } on : sha Timestamp(3, 3) { "name" : "user1", "age" : 710594 } -->> { "name" : "user1", "age" : 875076 } on : shard Timestamp(4, 2) { "name" : "user1", "age" : 875076 } -->> { "name" : "user1", "age" : 1056645 } on : shard Timestamp(4, 3) { "name" : "user1", "age" : 1056645 } -->> { "name" : { "$maxKey" : 1 }, "age" : { "$maxKey" : 1 } } on : sha Timestamp(5, 0)
- To see if the current slice is evenly distributed to multiple shard s, true is evenly distributed
false is not uniform
mongos> sh.getBalancerState() true
Choose Sharks'Notes
- Consider where data should be stored?
- Where should the data be read?
- Sharing key should be the primary key
- Sharing key should ensure that you avoid fragmented queries as much as possible
sharing Advancement
- If sharing fragmentation is not uniform, no fragmentation is uniform.
- Sharing: Add shard and Remove shard
mongos> sh.addShard("sha4/192.168.2.10:21001")
Balancer
- Open Balncer
When Balancer is turned on, chunks automatically equalizes the score
mongos> sh.startBalancer()
- Setting up the Balancer process run time window
By default, in order to reduce the impact of the Balancing process on the system at runtime, the ixaBalancing process can set the running time window of the Balancer process and let the Balancer process operate in the specified time window.
#Setting Time Window db.settings.update({ _id : "balancer" }, { $set : { activeWindow : { start : "23:00", stop : "6:00" } } }, true )
- View the Balancer runtime window
# View the Balancer time window mongos> db.settings.find(); { "_id" : "balancer", "activeWindow" : { "start" : "23:00", "stop" : "6:00" }, "stopped" : false } mongos> sh.getBalancerWindow() { "start" : "23:00", "stop" : "6:00" }
- Delete Balancer Process Runtime Window
mongos> db.settings.update({ "_id" : "balancer" }, { $unset : { activeWindow : 1 }}); mongos> db.settings.find(); { "_id" : "chunksize", "value" : 10 } { "_id" : "balancer", "stopped" : false }
Executing mongodb in shell scripts
[root@My-Dev ~]# echo -e "use zhao \n db.call.find()" |mongo --port 60001
Addition of Mongodb Chip Key
- First enter the admin database of mongos
mongos> use admin switched to db admin mongos> db.runCommand({"enablesharding":"zl"}) #Create a zl Library { "ok" : 1 } mongos> db.runCommand(db.runCommand({"shardcollection":"$ent.t_srvappraise_back","key")
- Fragmentation script
#!/bin/bash url=10.241.96.155 port=30000 ent=test1 ./mongo $url:$port/admin <<EOF db.runCommand({"enablesharding":"$ent"}); db.runCommand({"shardcollection":"$ent.t_srvappraise_back","key":{"sa_seid":"hashed"}}) exit; EOF
Five people complimented

It has 33 drills (about 5.84 yuan)
follow
"Take a walk with little gifts and pay attention to me in a short book."
appreciate

All Comments 0 Look at the Author
In reverse chronological order
Positive chronological order
Income from the following topics found more similar content
 I love programming
I love programming Mongodb Practice
Mongodb Practice mongodb learning
mongodb learning
Recommended reading More exciting content
-
MongoDB Fragmented Cluster Deployment
1. Environment description: 1. Operating system: CentOS Linux release 7.4.1708 2, mongodb version:...
-
Build High Availability MongoDB Cluster (Fragmentation)
Refer to: http://blog.51cto.com/kaliarch/2044423 Mongo...
-
Mongodb 3.4 Fragmentation + Copy Set Example
Configuration server, all set to static address to go to / home directory, create a mongo directory for experiment, we need to create the following directory hierarchy and empty.
-
# Carding # day2 + The Power of Ma Churan's Participation
With the material life becoming more and more abundant, people's living standards continue to improve, and consumption concepts also change. From the past, people only need the practicality of material, to the pursuit of brand consumption, and then...
-
MCmore reveals: how to break through the bottleneck of garment e-commerce development
ABSTRACT: Making a small goal of 100 million yuan can be accomplished in less than three minutes, which makes many clothing experts envious and jealous. Clothing business has a mixed profit and loss. MCmore helps you embrace clothing correctly.
 Zhang Weike
Zhang Weike kaliarch
kaliarch justonlyyo
justonlyyo Dummy pony
Dummy pony