Surprise (Simple Python Recommendation System Engine) is a recommendation system library, which is one of the scikit series. Simple and easy to use, while supporting a variety of recommendation algorithms (basic algorithm, collaborative filtering, matrix decomposition, etc.).
The following purposes are taken into account when designing surprise:
- Let users control their experiments perfectly. To this end, the document is emphasized in particular, trying to be as clear and accurate as possible by pointing out every detail of the algorithm.
- Reduce the pain of data set processing. Users can use built-in data sets (Jester) and their own custom data sets.
- Provide a variety of ready-to-use prediction algorithms, such as baseline algorithm, neighborhood method, matrix factorization (SVD, PMF, SVD ++, NMF) and so on. In addition, various similarity measures (cosine, MSD, Pearson...) are built in.
- New algorithm ideas can be easily realized.
- Provides tools for evaluating, analyzing and comparing the performance of algorithms. Using powerful CV iterators (inspired by excellent scikit-learn ing tools) and detailed searches for a set of parameters, cross validation programs can be run very easily.
1.Surprise installation
pip install numpy pip install scikit-surprise
Make sure that numpy module is installed before installation.
2. Basic Algorithms
| Algorithm class name | Explain |
|---|---|
| random_pred.NormalPredictor | A prediction value is given randomly according to the distribution characteristics of training set. |
| baseline_only.BaselineOnly | Given users and Item, an estimate based on baseline is given |
| knns.KNNBasic | Basic Collaborative Filtering |
| knns.KNNWithMeans | Implementation of Collaborative Filtering Considering the Mean of Each User's Score |
| knns.KNNBaseline | Collaborative filtering considering baseline ratings |
| matrix_factorization.SVD | SVD implementation |
| matrix_factorization.SVDpp | SVD++, LFM+SVD |
| matrix_factorization.NMF | Collaborative filtering based on matrix decomposition |
| slope_one.SlopeOne | A Simple but Accurate Collaborative Filtering Algorithm |
| co_clustering.CoClustering | Collaborative filtering algorithm based on Collaborative clustering |
Neighbor-based method (collaborative filtering) can set different metrics.
| Similarity measure | Description of metrics |
|---|---|
| cosine | Calculate cosine similarity between all user (or item) pairs. |
| msd | Calculate the mean square difference similarity between all users (or items). |
| pearson | Calculate Pearson correlation coefficients between all user (or item) pairs. |
| pearson_baseline | The Pearson correlation coefficients between pairs of users (or items) are calculated, and the baseline is used to center rather than average the Pearson correlation coefficients. |
Supporting different evaluation criteria
| Evaluation criteria | Guidelines specification |
|---|---|
| rmse | RMSE (root mean square error) is calculated. |
| mae | Calculate MAE (mean absolute error). |
| fcp | Calculate FCP (score of coordination pair). |
3.Surprise use
(1) Load the data set that comes with it
#-*- coding:utf-8 -*-
# You can use the various recommendation system algorithms mentioned above
from surprise import SVD
from surprise import Dataset, print_perf
from surprise.model_selection import cross_validate
# Default loading of movielens dataset
data = Dataset.load_builtin('ml-100k')
# K-fold cross validation (k=3), which is now discarded
# data.split(n_folds=3)
# Try SVD Matrix Decomposition
algo = SVD()
# Test the effect on the data set
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3)
#Output result
print_perf(perf)
Operation results:
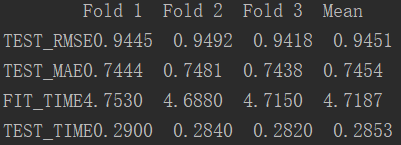
(2) Load your own dataset
from surprise import SVD
from surprise import Dataset, print_perf, Reader
from surprise.model_selection import cross_validate
import os
# Specify the path of the file
file_path = os.path.expanduser('data.csv')
# Tell the text reader what the format of the text is
reader = Reader(line_format='user item rating', sep=',')
# Loading data
data = Dataset.load_from_file(file_path, reader=reader)
algo = SVD()
# Test the effect on the data set
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3)
# Output results
print_perf(perf)
Attention should be paid to:
1. Can not recognize Chinese, if there is Chinese, it needs to be converted into ID number for operation (listed below is a simple conversion method)
2. You can't have a header. You need to remove Chinese columns from the header and metadata.
3. Reader needs to be modified. line_format is the column of data, and sep is the separation mode (the initial division mode of table format is',').
A simple data conversion method:
#-*- coding:utf-8 -*-
# Constructing Item id
import pandas as pd
df = pd.read_csv('train_score.csv', encoding="gbk")
# Read the data in the second column
item_name = df.iloc[:, 1]
item = {}
item_id = []
num = 0
# Associate each different item with id number
for i in item_name:
if i in item:
item_id.append(item[i])
else:
item[i] = num
item_id.append(num)
num += 1
print item_id
df['itemId'] = item_id
df.to_csv("data.csv", encoding="gbk", index=False)
4. Algorithmic parameter adjustment
The algorithm implemented here uses nothing more than SGD and so on, so there are also some hyperparameters that affect the final result. We can also use GridSearchCV, which is commonly used in sklearn s, to select the optimal parameters. A simple example is as follows:
# Define the grid of parameters that need to be optimized
param_grid = {'n_epochs': [5, 10], 'lr_all': [0.002, 0.005],
'reg_all': [0.4, 0.6]}
# Cross-validation using grid search
grid_search = GridSearch(SVD, param_grid, measures=['RMSE', 'FCP'])
# Find the best parameters on the data set
data = Dataset.load_builtin('ml-100k')
data.split(n_folds=3)
grid_search.evaluate(data)
# Output tuning parameter set
# Output the best RMSE results
print(grid_search.best_score['RMSE'])
# >>> 0.96117566386
# Output parameters corresponding to the best RMSE results
print(grid_search.best_params['RMSE'])
# >>> {'reg_all': 0.4, 'lr_all': 0.005, 'n_epochs': 10}
# Best FCP score
print(grid_search.best_score['FCP'])
# >>> 0.702279736531
# Parameters corresponding to the highest FCP score
print(grid_search.best_params['FCP'])
# >>> {'reg_all': 0.6, 'lr_all': 0.005, 'n_epochs': 10}
GridSearchCV method:
# Define the grid of parameters that need to be optimized
param_grid = {'n_epochs': [5, 10], 'lr_all': [0.002, 0.005],
'reg_all': [0.4, 0.6]}
# Cross-validation using grid search
grid_search = GridSearchCV(SVD, param_grid, measures=['RMSE', 'FCP'], cv=3)
# Find the best parameters on the data set
data = Dataset.load_builtin('ml-100k')
# pref = cross_validate(grid_search, data, cv=3)
grid_search.fit(data)
# Output tuning parameter set
# Output the best RMSE results
print(grid_search.best_score)
|
1.estimator Select the classifier to use, and pass in parameters other than those that need to determine the best parameters. Each classifier needs a scoring parameter, or score method: For example, estimator = Random Forest Classifier( min_samples_split=100, min_samples_leaf=20, max_depth=8, max_features='sqrt', random_state=10),
2.param_grid The value of the parameter that needs to be optimized is a dictionary or a list, for example: param_grid =param_test1, param_test1 = {'n_estimators':range(10,71,10)}.
3. scoring=None Model evaluation criteria, default None, need to use score function; or scoring='roc_auc', According to the selected models, the evaluation criteria are different. String (function name), or callable object, Function signatures such as scorer(estimator, X, y) are required; if nonee, estimator's error estimation function is used.
4.n_jobs=1 n_jobs: Parallel Number, int: Number, -1: Consistent with CPU Number, 1: Default Value
5.cv=None
Cross validation parameters, default None, use three fold cross validation. Specify the number of folds by default of 3. It can also be a generator for yield ing training / test data.
6.verbose=0, scoring=None verbose: log redundancy length, int: redundancy length, 0: no output training process, 1: occasional output, > 1: output for each sub-model.
7.pre_dispatch='2*n_jobs' Specifies the total number of parallel tasks to be distributed. When n_jobs is greater than 1, the data will be replicated at each runtime, which may lead to OOM. By setting the pre_dispatch parameter, you can pre-divide the total number of job s so that the data can be copied up to pre_dispatch times.
8.return_train_score='warn' If "False", the cv_results_attribute will not include the training score.
9.refit: By default True, the program will re-run all available training and development sets with the best parameters obtained from cross-validation training sets. As the best model parameter for performance evaluation. That is to say, after the search parameters are finished, all data sets are fit ted again with the best parameter results.
10.iid: The default True, when True, is that the fold probability distribution of each sample is the same, and the error is estimated as the sum of all samples, not the average of each fold.
Common methods and attributes for forecasting grid.fit(): Run grid search grid_scores_: Give the evaluation results under different parameters best_params_: Describes the combination of parameters that have yielded the best results best_score_: Members provide the best reviews observed during the optimization process |
5. Modeling and comparison using different recommendation system algorithms
from surprise import Dataset, print_perf
from surprise.model_selection import cross_validate
data = Dataset.load_builtin('ml-100k')
### Using Normal Predictor
from surprise import NormalPredictor
algo = NormalPredictor()
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3)
print_perf(perf)
### Use BaselineOnly
from surprise import BaselineOnly
algo = BaselineOnly()
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3)
print_perf(perf)
### Collaborative filtering using Base Edition
from surprise import KNNBasic, evaluate
algo = KNNBasic()
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3)
print_perf(perf)
### Using Mean Collaborative Filtering
from surprise import KNNWithMeans, evaluate
algo = KNNWithMeans()
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3)
print_perf(perf)
### Using collaborative filtering baseline
from surprise import KNNBaseline, evaluate
algo = KNNBaseline()
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3)
print_perf(perf)
### Using SVD
from surprise import SVD, evaluate
algo = SVD()
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3)
print_perf(perf)
### Using SVD++
from surprise import SVDpp, evaluate
algo = SVDpp()
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3)
print_perf(perf)
### Using NMF
from surprise import NMF
algo = NMF()
perf = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=3)
print_perf(perf)
6. Recommended examples of movielens
#-*- coding:utf-8 -*-
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import os
import io
from surprise import KNNBaseline
from surprise import Dataset
import logging
logging.basicConfig(level=logging.INFO,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S')
# Training recommendation model steps: 1
def getSimModle():
# Default loading of movielens dataset
data = Dataset.load_builtin('ml-100k')
trainset = data.build_full_trainset()
#Using pearson_baseline method to calculate similarity False calculates similarity between movies based on item
sim_options = {'name': 'pearson_baseline', 'user_based': False}
##Using KNNBaseline algorithm
algo = KNNBaseline(sim_options=sim_options)
#Training model
algo.fit(trainset)
return algo
# Getting id to name mapping steps: 2
def read_item_names():
"""
//Get the mapping of movie name to movie id and movie id to movie name
"""
file_name = (os.path.expanduser('~') +
'/.surprise_data/ml-100k/ml-100k/u.item')
rid_to_name = {}
name_to_rid = {}
with io.open(file_name, 'r', encoding='ISO-8859-1') as f:
for line in f:
line = line.split('|')
rid_to_name[line[0]] = line[1]
name_to_rid[line[1]] = line[0]
return rid_to_name, name_to_rid
# Recommendation steps for related movies based on the previous training model:3
def showSimilarMovies(algo, rid_to_name, name_to_rid):
# Get raw_id of the movie Toy Story (1995)
toy_story_raw_id = name_to_rid['Toy Story (1995)']
logging.debug('raw_id=' + toy_story_raw_id)
#Converting raw_id of a movie to the internal ID of the model
toy_story_inner_id = algo.trainset.to_inner_iid(toy_story_raw_id)
logging.debug('inner_id=' + str(toy_story_inner_id))
#Get Recommended Movies from Model Here are 10
toy_story_neighbors = algo.get_neighbors(toy_story_inner_id, 10)
logging.debug('neighbors_ids=' + str(toy_story_neighbors))
#The internal id of the model is converted to the actual movie id
neighbors_raw_ids = [algo.trainset.to_raw_iid(inner_id) for inner_id in toy_story_neighbors]
#Get a movie id list or a movie recommendation list
neighbors_movies = [rid_to_name[raw_id] for raw_id in neighbors_raw_ids]
print('The 10 nearest neighbors of Toy Story are:')
for movie in neighbors_movies:
print(movie)
if __name__ == '__main__':
# Get the mapping of id to name
rid_to_name, name_to_rid = read_item_names()
# Training Recommendation Model
algo = getSimModle()
##Display related movies
showSimilarMovies(algo, rid_to_name, name_to_rid)
Operation results:
