MPEG audio coding experiment
1, Experimental requirements
◼ Understand the overall framework of programming
◼ Understand the design idea of perceptual audio coding
Two lines
Contradiction of time-frequency analysis!
◼ Understand the implementation process of psychoacoustic model
Concept of critical frequency band
Idea of masking value calculation
◼ Understand the implementation idea of bit rate allocation
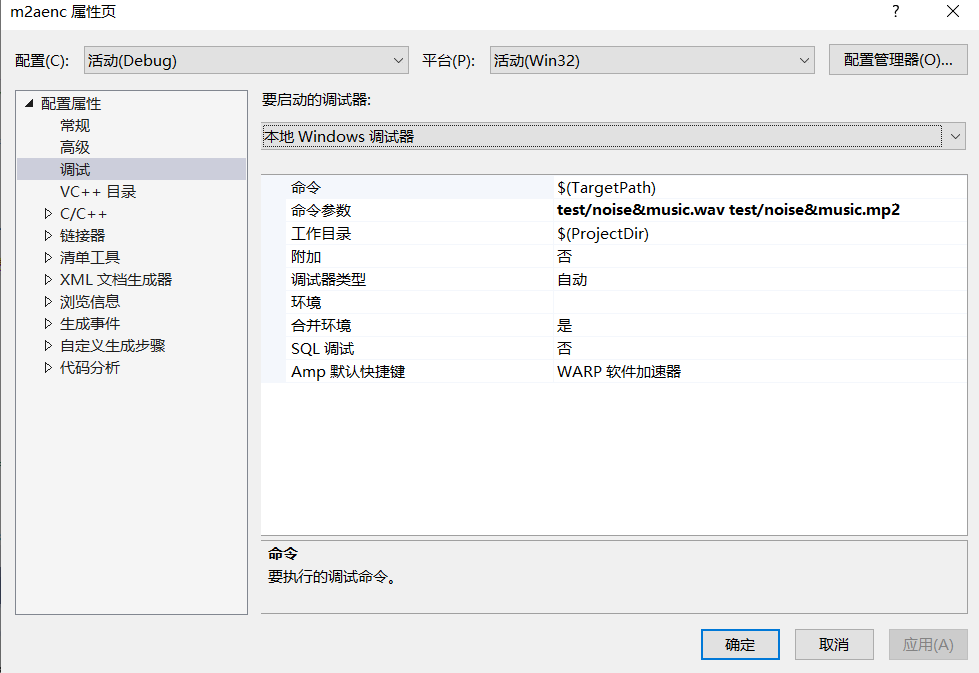
◼ Sample rate and target bit rate of output audio
◼ Select three audio files with different characteristics
Noise (continuous noise, burst noise)
Music
Blend
◼ A data frame, output
Number of bits allocated for this frame
Scale factor of the frame
Bit allocation result of the frame
2, Experimental content
1. Overall framework of program design
Main function comments
int main (int argc, char **argv)
{
typedef double SBS[2][3][SCALE_BLOCK][SBLIMIT];
SBS *sb_sample;
typedef double JSBS[3][SCALE_BLOCK][SBLIMIT];
JSBS *j_sample;
typedef double IN[2][HAN_SIZE];
IN *win_que;
typedef unsigned int SUB[2][3][SCALE_BLOCK][SBLIMIT];
SUB *subband;
frame_info frame; // Frame header
frame_header header; // Frame content header
char original_file_name[MAX_NAME_SIZE]; // Source file name
char encoded_file_name[MAX_NAME_SIZE]; // Encoded output file name
short **win_buf; // Window buffer
static short buffer[2][1152];
static unsigned int bit_alloc[2][SBLIMIT], scfsi[2][SBLIMIT];
static unsigned int scalar[2][3][SBLIMIT], j_scale[3][SBLIMIT];
static double smr[2][SBLIMIT], lgmin[2][SBLIMIT], max_sc[2][SBLIMIT];
// FLOAT snr32[32];
short sam[2][1344]; /* was [1056]; */
int model, nch, error_protection; // Model, channel number, error check flag
static unsigned int crc; // crc error check code
int sb, ch, adb; // Some variables for the for loop count
unsigned long frameBits, sentBits = 0; // Number of frame bits and transmission bits
unsigned long num_samples; // Number of samples
int lg_frame;
int i;
/* Used to keep the SNR values for the fast/quick psy models */
static FLOAT smrdef[2][32];
static int psycount = 0;
extern int minimum;
time_t start_time, end_time;
int total_time;
sb_sample = (SBS *) mem_alloc (sizeof (SBS), "sb_sample");
j_sample = (JSBS *) mem_alloc (sizeof (JSBS), "j_sample");
win_que = (IN *) mem_alloc (sizeof (IN), "Win_que");
subband = (SUB *) mem_alloc (sizeof (SUB), "subband");
win_buf = (short **) mem_alloc (sizeof (short *) * 2, "win_buf");
/* clear buffers */
memset ((char *) buffer, 0, sizeof (buffer));
memset ((char *) bit_alloc, 0, sizeof (bit_alloc));
memset ((char *) scalar, 0, sizeof (scalar));
memset ((char *) j_scale, 0, sizeof (j_scale));
memset ((char *) scfsi, 0, sizeof (scfsi));
memset ((char *) smr, 0, sizeof (smr));
memset ((char *) lgmin, 0, sizeof (lgmin));
memset ((char *) max_sc, 0, sizeof (max_sc));
//memset ((char *) snr32, 0, sizeof (snr32));
memset ((char *) sam, 0, sizeof (sam));
global_init ();
header.extension = 0;
frame.header = &header;
frame.tab_num = -1; /* no table loaded */
frame.alloc = NULL;
header.version = MPEG_AUDIO_ID; /* Default: MPEG-1 */
total_time = 0;
time(&start_time);
programName = argv[0];
if (argc == 1) /* no command-line args */
short_usage ();
else
parse_args (argc, argv, &frame, &model, &num_samples, original_file_name,
encoded_file_name);
print_config (&frame, &model, original_file_name, encoded_file_name);
/* this will load the alloc tables and do some other stuff */
hdr_to_frps (&frame);
nch = frame.nch;
error_protection = header.error_protection;
while (get_audio (musicin, buffer, num_samples, nch, &header) > 0) { // Read input audio
if (glopts.verbosity > 1) // Output details
if (++frameNum % 10 == 0)
fprintf (stderr, "[%4u]\r", frameNum);
fflush (stderr);
win_buf[0] = &buffer[0][0];
win_buf[1] = &buffer[1][0];
adb = available_bits (&header, &glopts);
lg_frame = adb / 8;
if (header.dab_extension) {
/* in 24 kHz we always have 4 bytes */
if (header.sampling_frequency == 1)
header.dab_extension = 4;
/* You must have one frame in memory if you are in DAB mode */
/* in conformity of the norme ETS 300 401 http://www.etsi.org */
/* see bitstream.c */
if (frameNum == 1)
minimum = lg_frame + MINIMUM;
adb -= header.dab_extension * 8 + header.dab_length * 8 + 16;
}
{
int gr, bl, ch;
/* New polyphase filter
Combines windowing and filtering. Ricardo Feb'03 */
for( gr = 0; gr < 3; gr++ )
for ( bl = 0; bl < 12; bl++ )
for ( ch = 0; ch < nch; ch++ )
WindowFilterSubband( &buffer[ch][gr * 12 * 32 + 32 * bl], ch,
&(*sb_sample)[ch][gr][bl][0] );
}
#ifdef REFERENCECODE
{
/* Old code. left here for reference */
int gr, bl, ch;
for (gr = 0; gr < 3; gr++)
for (bl = 0; bl < SCALE_BLOCK; bl++)
for (ch = 0; ch < nch; ch++) {
window_subband (&win_buf[ch], &(*win_que)[ch][0], ch);
filter_subband (&(*win_que)[ch][0], &(*sb_sample)[ch][gr][bl][0]);
}
}
#endif
#ifdef NEWENCODE
scalefactor_calc_new(*sb_sample, scalar, nch, frame.sblimit);
find_sf_max (scalar, &frame, max_sc);
if (frame.actual_mode == MPG_MD_JOINT_STEREO) {
/* this way we calculate more mono than we need */
/* but it is cheap */
combine_LR_new (*sb_sample, *j_sample, frame.sblimit);
scalefactor_calc_new (j_sample, &j_scale, 1, frame.sblimit);
}
#else
scale_factor_calc (*sb_sample, scalar, nch, frame.sblimit);
pick_scale (scalar, &frame, max_sc);
if (frame.actual_mode == MPG_MD_JOINT_STEREO) {
/* this way we calculate more mono than we need */
/* but it is cheap */
combine_LR (*sb_sample, *j_sample, frame.sblimit);
scale_factor_calc (j_sample, &j_scale, 1, frame.sblimit);
}
#endif
if ((glopts.quickmode == TRUE) && (++psycount % glopts.quickcount != 0)) {
/* We're using quick mode, so we're only calculating the model every
'quickcount' frames. Otherwise, just copy the old ones across */
for (ch = 0; ch < nch; ch++) {
for (sb = 0; sb < SBLIMIT; sb++)
smr[ch][sb] = smrdef[ch][sb];
}
} else {
/* calculate the psymodel */
switch (model) {
case -1:
psycho_n1 (smr, nch);
break;
case 0: /* Psy Model A */
psycho_0 (smr, nch, scalar, (FLOAT) s_freq[header.version][header.sampling_frequency] * 1000);
break;
case 1:
psycho_1 (buffer, max_sc, smr, &frame);
break;
case 2:
for (ch = 0; ch < nch; ch++) {
psycho_2 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], //snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
}
break;
case 3:
/* Modified psy model 1 */
psycho_3 (buffer, max_sc, smr, &frame, &glopts);
break;
case 4:
/* Modified Psycho Model 2 */
for (ch = 0; ch < nch; ch++) {
psycho_4 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
}
break;
case 5:
/* Model 5 comparse model 1 and 3 */
psycho_1 (buffer, max_sc, smr, &frame);
fprintf(stdout,"1 ");
smr_dump(smr,nch);
psycho_3 (buffer, max_sc, smr, &frame, &glopts);
fprintf(stdout,"3 ");
smr_dump(smr,nch);
break;
case 6:
/* Model 6 compares model 2 and 4 */
for (ch = 0; ch < nch; ch++)
psycho_2 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], //snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"2 ");
smr_dump(smr,nch);
for (ch = 0; ch < nch; ch++)
psycho_4 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"4 ");
smr_dump(smr,nch);
break;
case 7:
fprintf(stdout,"Frame: %i\n",frameNum);
/* Dump the SMRs for all models */
psycho_1 (buffer, max_sc, smr, &frame);
fprintf(stdout,"1");
smr_dump(smr, nch);
psycho_3 (buffer, max_sc, smr, &frame, &glopts);
fprintf(stdout,"3");
smr_dump(smr,nch);
for (ch = 0; ch < nch; ch++)
psycho_2 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], //snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"2");
smr_dump(smr,nch);
for (ch = 0; ch < nch; ch++)
psycho_4 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"4");
smr_dump(smr,nch);
break;
case 8:
/* Compare 0 and 4 */
psycho_n1 (smr, nch);
fprintf(stdout,"0");
smr_dump(smr,nch);
for (ch = 0; ch < nch; ch++)
psycho_4 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"4");
smr_dump(smr,nch);
break;
default:
fprintf (stderr, "Invalid psy model specification: %i\n", model);
exit (0);
}
if (glopts.quickmode == TRUE)
/* copy the smr values and reuse them later */
for (ch = 0; ch < nch; ch++) {
for (sb = 0; sb < SBLIMIT; sb++)
smrdef[ch][sb] = smr[ch][sb];
}
if (glopts.verbosity > 4)
smr_dump(smr, nch);
}
#ifdef NEWENCODE
sf_transmission_pattern (scalar, scfsi, &frame);
main_bit_allocation_new (smr, scfsi, bit_alloc, &adb, &frame, &glopts);
//main_bit_allocation (smr, scfsi, bit_alloc, &adb, &frame, &glopts);
if (error_protection)
CRC_calc (&frame, bit_alloc, scfsi, &crc);
write_header (&frame, &bs);
//encode_info (&frame, &bs);
if (error_protection)
putbits (&bs, crc, 16);
write_bit_alloc (bit_alloc, &frame, &bs);
//encode_bit_alloc (bit_alloc, &frame, &bs);
write_scalefactors(bit_alloc, scfsi, scalar, &frame, &bs);
//encode_scale (bit_alloc, scfsi, scalar, &frame, &bs);
subband_quantization_new (scalar, *sb_sample, j_scale, *j_sample, bit_alloc,
*subband, &frame);
//subband_quantization (scalar, *sb_sample, j_scale, *j_sample, bit_alloc,
// *subband, &frame);
write_samples_new(*subband, bit_alloc, &frame, &bs);
//sample_encoding (*subband, bit_alloc, &frame, &bs);
#else
transmission_pattern (scalar, scfsi, &frame);
main_bit_allocation (smr, scfsi, bit_alloc, &adb, &frame, &glopts);
if (error_protection)
CRC_calc (&frame, bit_alloc, scfsi, &crc);
encode_info (&frame, &bs);
if (error_protection)
encode_CRC (crc, &bs);
encode_bit_alloc (bit_alloc, &frame, &bs);
encode_scale (bit_alloc, scfsi, scalar, &frame, &bs);
subband_quantization (scalar, *sb_sample, j_scale, *j_sample, bit_alloc,
*subband, &frame);
sample_encoding (*subband, bit_alloc, &frame, &bs);
#endif
/* If not all the bits were used, write out a stack of zeros */
for (i = 0; i < adb; i++)
put1bit (&bs, 0);
if (header.dab_extension) {
/* Reserve some bytes for X-PAD in DAB mode */
putbits (&bs, 0, header.dab_length * 8);
for (i = header.dab_extension - 1; i >= 0; i--) {
CRC_calcDAB (&frame, bit_alloc, scfsi, scalar, &crc, i);
/* this crc is for the previous frame in DAB mode */
if (bs.buf_byte_idx + lg_frame < bs.buf_size)
bs.buf[bs.buf_byte_idx + lg_frame] = crc;
/* reserved 2 bytes for F-PAD in DAB mode */
putbits (&bs, crc, 8);
}
putbits (&bs, 0, 16);
}
frameBits = sstell (&bs) - sentBits;
if (frameBits % 8) { /* a program failure */
fprintf (stderr, "Sent %ld bits = %ld slots plus %ld\n", frameBits,
frameBits / 8, frameBits % 8);
fprintf (stderr, "If you are reading this, the program is broken\n");
fprintf (stderr, "email [mfc at NOTplanckenerg.com] without the NOT\n");
fprintf (stderr, "with the command line arguments and other info\n");
exit (0);
}
sentBits += frameBits;
}
close_bit_stream_w (&bs);
if ((glopts.verbosity > 1) && (glopts.vbr == TRUE)) {
int i;
#ifdef NEWENCODE
extern int vbrstats_new[15];
#else
extern int vbrstats[15];
#endif
fprintf (stdout, "VBR stats:\n");
for (i = 1; i < 15; i++)
fprintf (stdout, "%4i ", bitrate[header.version][i]);
fprintf (stdout, "\n");
for (i = 1; i < 15; i++)
#ifdef NEWENCODE
fprintf (stdout,"%4i ",vbrstats_new[i]);
#else
fprintf (stdout, "%4i ", vbrstats[i]);
#endif
fprintf (stdout, "\n");
}
fprintf (stderr,
"Avg slots/frame = %.3f; b/smp = %.2f; bitrate = %.3f kbps\n",
(FLOAT) sentBits / (frameNum * 8),
(FLOAT) sentBits / (frameNum * 1152),
(FLOAT) sentBits / (frameNum * 1152) *
s_freq[header.version][header.sampling_frequency]);
if (fclose (musicin) != 0) {
fprintf (stderr, "Could not close \"%s\".\n", original_file_name);
exit (2);
}
fprintf (stderr, "\nDone\n");
time(&end_time);
total_time = end_time - start_time;
printf("total time is %d\n", total_time);
exit (0);
}
In general, it includes the following operations:
The sliding window obtains 32 subband samples for each channel;
If it is stereo, mix the left and right channels;
Calculate the scale factor and scale factor selection information;
Calculate the psychoacoustic masking level using the selected psychoacoustic model;
Performing iterative bit allocation for subbands with low masking ratio according to the masking level;
According to error_ CRC verification and error correction by protection;
The bit allocation, scale factor and scale factor are packaged into the bit stream;
The quantization subband is packaged into a bitstream.
2. Design idea of perceptual audio coding
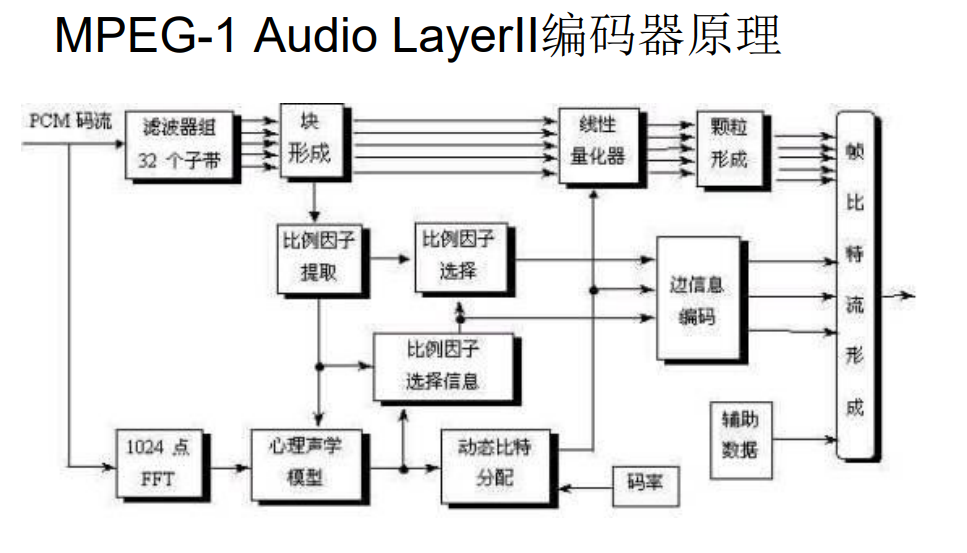
After the code stream is input, it is divided into upper and lower lines. The upper line corresponds to the time domain and the lower line corresponds to the frequency domain.
The code stream is decomposed into 32 subbands in the time domain, and the subband analysis filter bank is used to make the signal have high time resolution, so as to ensure that the encoded sound signal has high enough quality in the case of short impact signal
According to the psychoacoustic model, the frequency domain allocates different quantization bits to the subband according to the auditory effect of human ear, that is, dynamic bit allocation, so as to reduce the audio bit stream data as much as possible. Here, in order to calculate the masking value, we need to have a high frequency resolution, which is in contradiction with the high time resolution in the time domain.
3. Implementation process of psychoacoustic model
1. Transform the sample to frequency domain
FFT is introduced to compensate the problem of insufficient frequency resolution.
Using Hann weighting and DFT:Hann weighting to reduce boundary effect in frequency domain
2. Determine sound pressure level
Subband
n
n
Sound pressure level in n
L
s
b
L_{sb}
Lsb is calculated as follows:
L
s
b
(
n
)
=
max
[
X
(
k
)
,
20
log
10
(
s
c
f
max
(
n
)
∗
32768
)
−
10
]
d
B
L_{sb}(n)=\max[X(k),20\log_{10}(scf_{\max}(n)*32768)-10]dB
Lsb(n)=max[X(k),20log10(scfmax(n)∗32768)−10]dB
3. Consider quiet threshold
That is, the absolute threshold. In the standard, there is a table of "frequency, critical band rate and absolute threshold" compiled according to the sampling rate of the input PCM signal.
This table is obtained by many scientists through many psychoacoustic experiments.
4. Decompose the audio signal into "tones" and "non tones / noise": because the masking ability of the two signals is different
The music component is determined according to the maximum local power of the audio spectrum
The local peak is music, and then the residual spectrum in this critical frequency band is combined to form a representative noise frequency (non adjustable component)
5. Elimination of tonal and non tonal masking components
Using the absolute threshold given in the standard to eliminate the masked components;
Consider that in each critical frequency band, only the component with the highest power is retained in the distance less than 0.5Bark
6. Calculation of single masking threshold
The single masking threshold of tonal component and non tonal component is obtained according to the algorithm given in the standard.
7. Calculation of global masking threshold

The influence of other critical frequency bands should also be considered. One masking signal will produce masking effect on signals in other frequency bands. This masking effect is called masking diffusion.
8. Masking threshold of each subband
Select the minimum threshold in this subband as the subband threshold
9. Calculate the signal to mask ratio (SMR) of each subband
SMR = signal energy / masking threshold
4. Implementation idea of bit rate allocation
Before adjusting to a fixed code rate, determine the number of effective bits that can be used for sample value coding. This value depends on the scale factor and the scale factor selection letter
Number of bits required for information, bit allocation information and auxiliary data
The masking noise ratio is calculated for each subband
M
N
R
MNR
MNR is the signal-to-noise ratio
S
N
R
SNR
SNR – signal to mask ratio
S
M
R
SMR
SMR, i.e
M
N
R
=
S
N
R
–
S
M
R
MNR = SNR–SMR
MNR=SNR–SMR,
N
M
R
=
S
M
R
−
S
N
R
NMR=SMR-SNR
NMR=SMR−SNR
5. Sampling rate and target code rate of output audio
void print_config (frame_info * frame, int *psy, char *inPath,
char *outPath)
{
frame_header *header = frame->header;
if (glopts.verbosity == 0)
return;
fprintf (stderr, "--------------------------------------------\n");
fprintf (stderr, "Input File : '%s' %.1f kHz\n",
(strcmp (inPath, "-") ? inPath : "stdin"),
s_freq[header->version][header->sampling_frequency]);
fprintf (stderr, "Output File: '%s'\n",
(strcmp (outPath, "-") ? outPath : "stdout"));
fprintf (stderr, "%d kbps ", bitrate[header->version][header->bitrate_index]);
fprintf (stderr, "%s ", version_names[header->version]);
if (header->mode != MPG_MD_JOINT_STEREO)
fprintf (stderr, "Layer II %s Psycho model=%d (Mode_Extension=%d)\n",
mode_names[header->mode], *psy, header->mode_ext);
else
fprintf (stderr, "Layer II %s Psy model %d \n", mode_names[header->mode],
*psy);
fprintf (stderr, "[De-emph:%s\tCopyright:%s\tOriginal:%s\tCRC:%s]\n",
((header->emphasis) ? "On" : "Off"),
((header->copyright) ? "Yes" : "No"),
((header->original) ? "Yes" : "No"),
((header->error_protection) ? "On" : "Off"));
fprintf (stderr, "[Padding:%s\tByte-swap:%s\tChanswap:%s\tDAB:%s]\n",
((glopts.usepadbit) ? "Normal" : "Off"),
((glopts.byteswap) ? "On" : "Off"),
((glopts.channelswap) ? "On" : "Off"),
((glopts.dab) ? "On" : "Off"));
if (glopts.vbr == TRUE)
fprintf (stderr, "VBR Enabled. Using MNR boost of %f\n", glopts.vbrlevel);
fprintf(stderr,"ATH adjustment %f\n",glopts.athlevel);
fprintf (stderr, "--------------------------------------------\n");
}
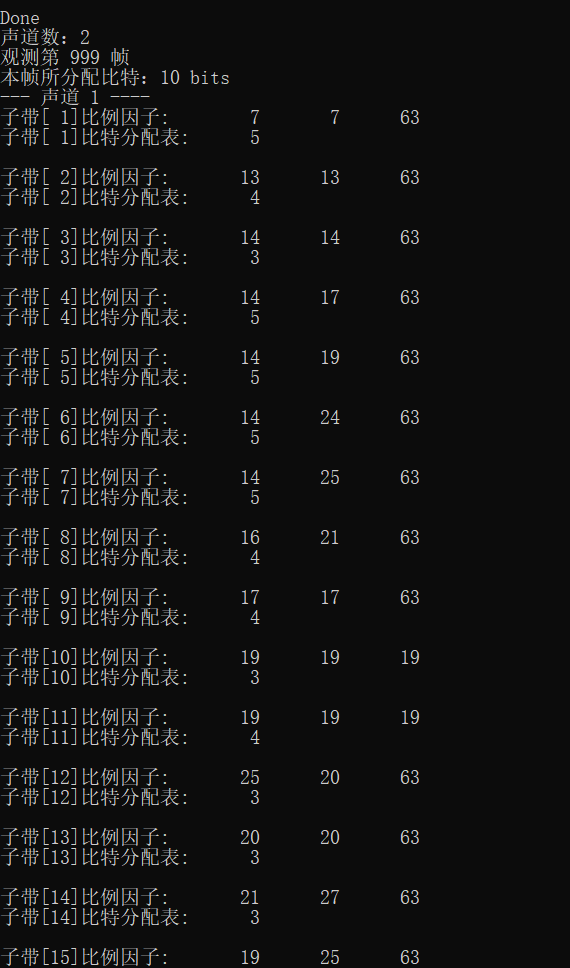
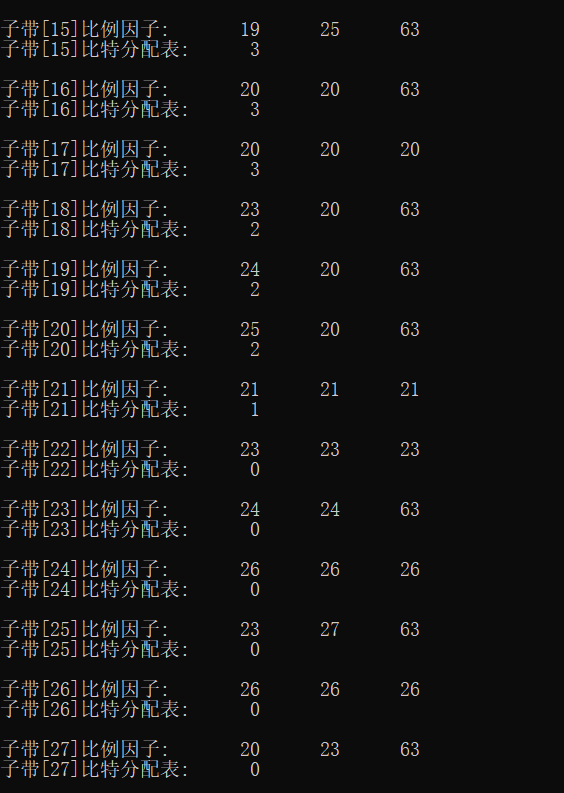
6. Output data frame
Add in the main function
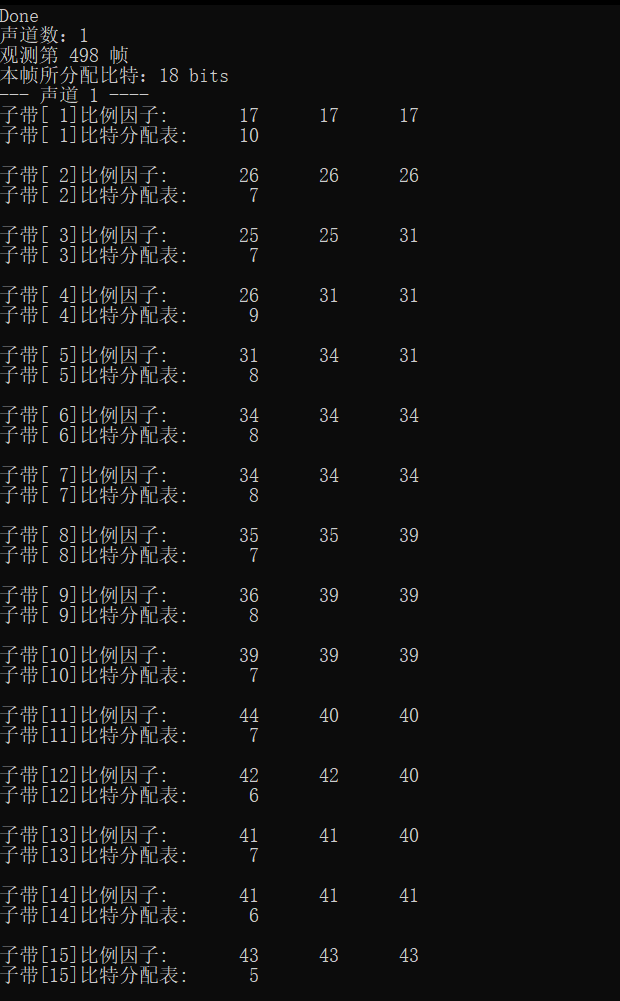
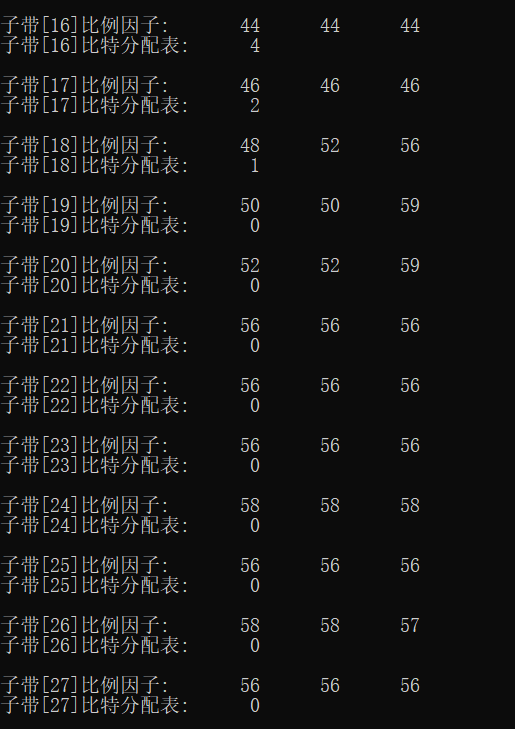
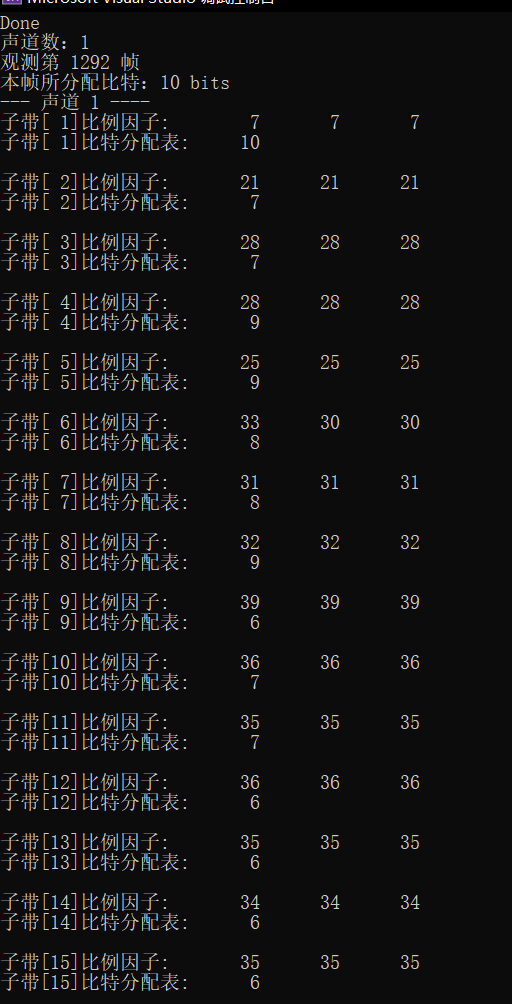
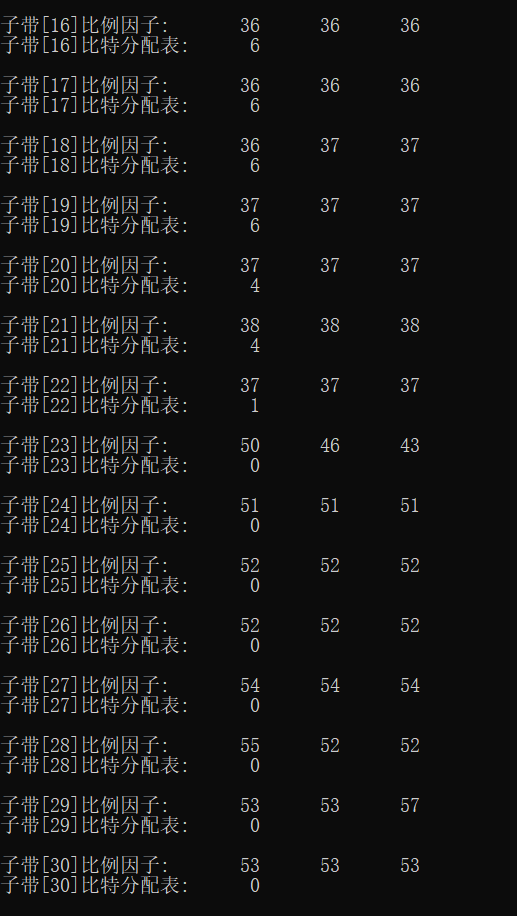
fprintf(stderr, "Number of channels:%d\n", nch);
fprintf(stderr, "Observation section %d frame\n", frameNum);
fprintf(stderr, "Bits allocated in this frame:%d bits\n", adb);
for (ch = 0; ch < nch; ch++)
{
fprintf(stderr, "--- Vocal tract%2d ----\n", ch + 1);
for (sb = 0; sb < frame.sblimit; sb++)
{
fprintf(stderr, "Subband[%2d]Scale factor:\t", sb + 1);
for (gr = 0; gr < 3; gr++)
fprintf(stderr, "%2d\t", scalar[ch][gr][sb]);
fprintf(stderr, "\n");
fprintf(stderr, "Subband[%2d]Bit allocation table:\t%2d\n", sb + 1, bit_alloc[ch][sb]);
fprintf(stderr, "\n");
}
}
3, Experimental results
1. Noise
2. Music
3. Mixing