Reference from: https://blog.csdn.net/lcx543576178/article/details/45892839
The procedure is slightly modified as follows:
#include<iostream> using namespace std; #include<mpi.h> int main(int argc, char * argv[] ){ double start, stop; int *a, *b, *c, *buffer, *ans; int size = 1000; int rank, numprocs, line; MPI_Init(NULL,NULL); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &numprocs); line = size/numprocs; b = new int [ size * size ]; ans = new int [ size * line ]; start = MPI_Wtime(); if( rank ==0 ){ a = new int [ size * size ]; c = new int [ size * size ]; for(int i=0;i<size; i++) for(int j=0;j<size; j++){ a[ i*size + j ] = i*j; b[ i*size + j ] = i + j; } for(int i=1;i<numprocs;i++){// send b MPI_Send( b, size*size, MPI_INT, i, 0, MPI_COMM_WORLD ); } for(int i=1;i<numprocs;i++){// send part of a MPI_Send( a + (i-1)*line*size, size*line, MPI_INT, i, 1, MPI_COMM_WORLD); } for(int i = (numprocs-1)*line;i<size;i++){// calculate block 1 for(int j=0;j<size;j++){ int temp = 0; for(int k=0;k<size;k++) temp += a[i*size+k]*b[k*size+j]; c[i*size+j] = temp; } } for(int k=1;k<numprocs;k++){// recieve ans MPI_Recv( ans, line*size, MPI_INT, k, 3, MPI_COMM_WORLD, MPI_STATUS_IGNORE); for(int i=0;i<line;i++){ for(int j=0;j<size;j++){ c[ ((k-1)*line + i)*size + j] = ans[i*size+j]; } } } FILE *fp = fopen("c.txt","w"); for(int i=0;i<size;i++){ for(int j=0;j<size;j++) fprintf(fp,"%d\t",c[i*size+j]); fputc('\n',fp); } fclose(fp); stop = MPI_Wtime(); printf("rank:%d time:%lfs\n",rank,stop-start); delete [] a,c; } else{ buffer = new int [ size * line ]; MPI_Recv(b, size*size, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); MPI_Recv(buffer, size*line, MPI_INT, 0, 1, MPI_COMM_WORLD, MPI_STATUS_IGNORE); for(int i=0;i<line;i++) for(int j=0;j<size;j++){ int temp=0; for(int k=0;k<size;k++) temp += buffer[i*size+k]*b[k*size+j]; ans[i*size+j] = temp; } MPI_Send(ans, line*size, MPI_INT, 0, 3, MPI_COMM_WORLD); delete [] buffer; delete [] ans; } delete [] b; MPI_Finalize(); return 0; }
Thread 0 sends matrix b and block matrix of a to other threads, and then does some matrix multiplication by itself, then receives the results of other threads, and then outputs the final answer.
2. Use MPI_Scatter and MPI_Gather. The code is also from https://blog.csdn.net/lcx543576178/article/details/45892839.
Slightly modified as follows:
#include<iostream> using namespace std; #include<mpi.h> int main(){ int my_rank; int num_procs; int size = 1000; double start, finish; MPI_Init(NULL,NULL); MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); MPI_Comm_size(MPI_COMM_WORLD, &num_procs); int line = size / num_procs; cout<<" line = "<<line<<endl; int * local_a = new int [ line * size ]; int * b = new int [ size * size ]; int * ans = new int [ line * size ]; int * a = new int [ size * size ]; int * c = new int [ size * size ]; if( my_rank == 0 ){ start = MPI_Wtime(); for(int i=0;i<size;i++){ for(int j=0;j<size;j++){ a[ i*size + j ] = i*j; b[ i*size + j ] = i + j; } } MPI_Scatter(a, line * size, MPI_INT, local_a, line * size, MPI_INT, 0, MPI_COMM_WORLD ); MPI_Bcast(b, size*size, MPI_INT, 0, MPI_COMM_WORLD); for(int i= 0; i< line;i++){ for(int j=0;j<size;j++){ int temp = 0; for(int k=0;k<size;k++) temp += a[i*size+k] * b[k*size + j]; ans[i*size + j ] = temp; } } MPI_Gather( ans, line * size, MPI_INT, c, line * size, MPI_INT, 0, MPI_COMM_WORLD ); for(int i= num_procs *line; i< size;i++){ for(int j=0;j<size;j++){ int temp = 0; for(int k=0;k<size;k++) temp += a[i*size+k] * b[k*size + j]; c[i*size + j ] = temp; } } FILE *fp = fopen("c2.txt","w"); for(int i=0;i<size;i++){ for(int j=0;j<size;j++) fprintf(fp,"%d\t",c[i*size+j]); fputc('\n',fp); } fclose(fp); finish = MPI_Wtime(); printf(" time: %lf s \n", finish - start ); } else{ int * buffer = new int [ size * line ]; MPI_Scatter(a, line * size, MPI_INT, buffer, line * size, MPI_INT, 0, MPI_COMM_WORLD ); MPI_Bcast( b, size * size, MPI_INT, 0, MPI_COMM_WORLD ); /* cout<<" b:"<<endl; for(int i=0;i<size;i++){ for(int j=0;j<size;j++){ cout<<b[i*size + j]<<","; } cout<<endl; } */ for(int i=0;i<line;i++){ for(int j=0;j<size;j++){ int temp = 0; for(int k=0;k<size;k++) temp += buffer[i*size+k] * b[k*size + j]; //cout<<"i = "<<i<<"\t j= "<<j<<"\t temp = "<<temp<<endl; ans[i*size + j] = temp; } } /* cout<<" ans:"<<endl; for(int i=0;i<line;i++){ for(int j=0;j<size;j++){ cout<<ans[i*size + j]<<","; } cout<<endl; } */ MPI_Gather(ans, line*size, MPI_INT, c, line*size, MPI_INT, 0, MPI_COMM_WORLD ); delete [] buffer; } delete [] a, local_a, b, ans, c; MPI_Finalize(); return 0; }
Process 0 distributes each block matrix of the MPI ﹐ scatter ﹐ a matrix to all processes (including itself), and broadcasts the MPI ﹐ BCAST ﹐ b matrix. Other processes receive the block matrix and b matrix of a, do multiplication, and return the result (MPI_Gather). Process 0 collects all the results (including its own) (MPI ﹣ gather). If there is any left in a matrix block, process 0 will do the relevant multiplication and output all the results.
3. Measure the time. The following figure shows the time consumption of the above two methods.
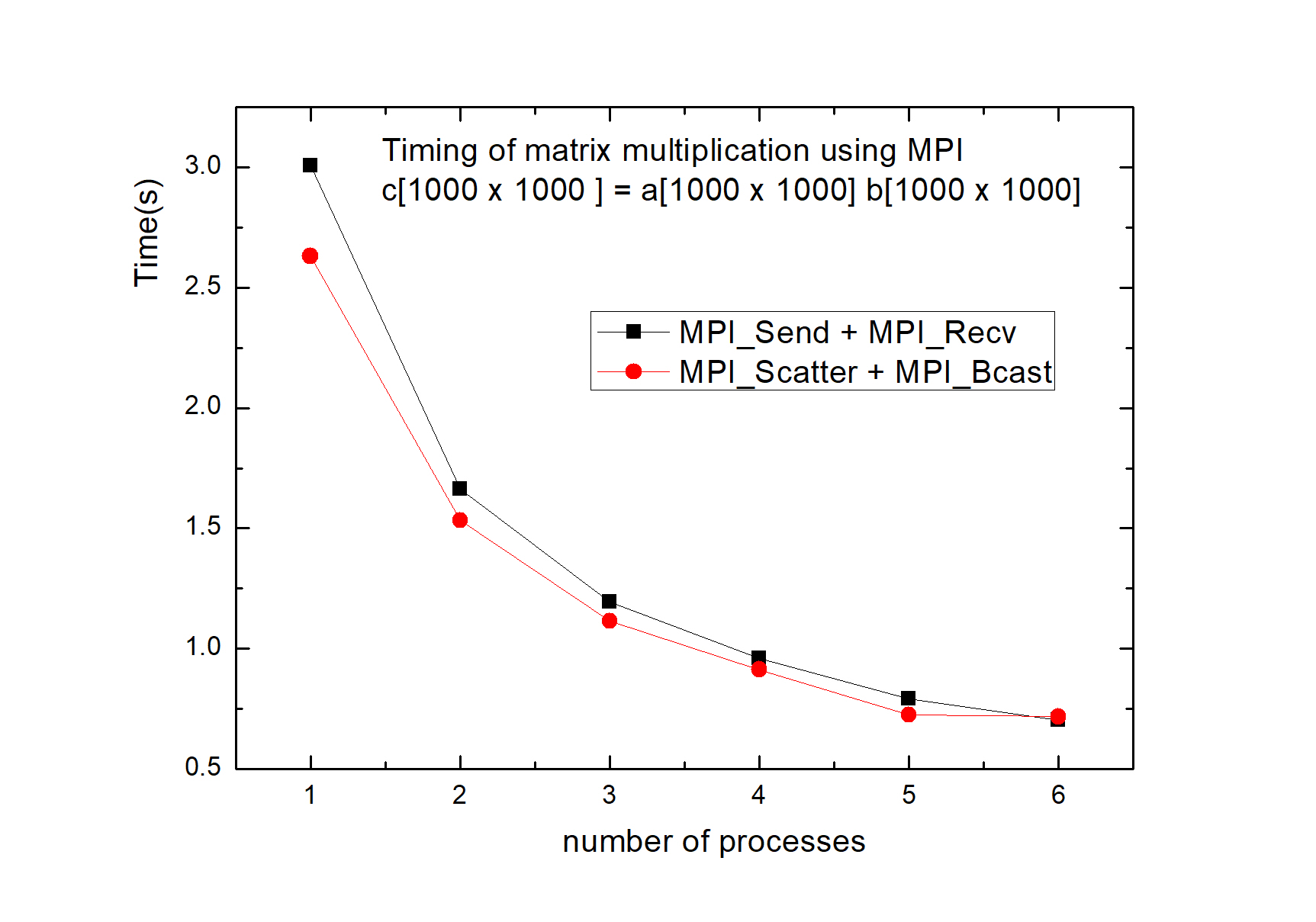
4. Conclusion: ① the more progress, the less time.
② because the cost of message delivery is required, and not every process starts and ends at the same time, the average efficiency of each process decreases with the increase of the number of processes.