Subquery (Continued)
Comparison operator (Continued)
Demonstration: how to use comparison operators in multivalued subqueries
- Example A: query all orders with product category No. 1 and return all field data of the order
Subquery
select *
from sales.orders
where orderid in
(
select orderid
from sales.orderdetails
where productid in
(
select productid
from Production.Products
where categoryid = 1
)
);
association
select o.*
from sales.orders o
join sales.orderdetails od on od.orderid = o.orderid
join Production.Products p on p.productid = od.productid
where p.categoryid = 1;
- Example B: query which customers have not placed orders, and return custid and CompanyName
Subquery 1
select CustID, CompanyName
from sales.Customers
where custid not in
(
select distinct custid
from sales.orders
);
Connection 1
select c.CustID, c.CompanyName
from sales.customers c
left join sales.orders o on o.custid = c.custid
where o.custid is null;
go
Subquery 2 (All data returned by customers)
select *
from sales.Customers
where custid not in
(
select distinct custid
from sales.orders
);
Connection 2 (Change and return all field data of the customer)
select *
from sales.customers c
left join sales.orders o on o.custid = c.custid
where o.custid is null;
go
Subquery 3 (Use existing test operator instead)
select CustID, CompanyName
from Sales.Customers c
where not exists
(
select *
from Sales.Orders o
where c.custid=o.custid
);
Subquery 4 (change to the use of sth. COUNT(*) = 0)
select CustID, CompanyName
from Sales.Customers c
where
(
select count(*)
from Sales.Orders o
where c.custid=o.custid
) = 0;
Precautions: Subquery 3 and subquery 4 must use the writing method of interrelated subqueries to be more meaningful, which will be explained in subsequent courses If you only care about whether the sub query has or does not have data, use EXISTS The existence of test operators is a good choice use COUNT(*) = 0 A similar effect can be achieved
- Example C: query employees whose salary is higher than 3 employees such as employee No. 5 or 6 or 7, and return all fields of employees
Subquery
select *
from hr.Employees
where salary > any
(
select salary
from hr.Employees
where empid in (5, 6, 7)
);
- Example D: query all order data of Supplier STUAZ before joining the supply chain, and return all field data of the order
Subquery 1
select *
from sales.orders
where orderid < all
(
select orderid
from sales.OrderDetails
where productid in
(
select productid
from Production.Products
where supplierid =
(
select supplierid
from Production.Suppliers
where companyname = 'Supplier STUAZ'
)
)
);
Subquery 2
select *
from sales.orders
where orderid < all
(
select orderid
from sales.OrderDetails
where productid in
(
select productid
from Production.Products
where supplierid =
(
select supplierid
from Production.Suppliers
where companyname = 'Supplier STUAZ'
)
)
order by orderid
offset 0 rows
fetch next 1 rows only
);
Subquery 3 + association
select *
from sales.orders
where orderid < all
(
select od.orderid
from sales.OrderDetails od
join Production.Products p on p.productid = od.productid
join Production.Suppliers s on s.supplierid = p.supplierid
where s.companyname = 'Supplier STUAZ'
order by od.orderid
offset 0 rows
fetch next 1 rows only
);
- Example E: if the following goods have just been purchased (the following insert instruction must be executed first), query the records of the same goods but the purchase cost is relatively low, and return all the field data of the products
INSERT INTO Production.Products(productname, supplierid, categoryid, listprice, discontinued, InStock) VALUES(N'Product LUNZZ', 15, 2, 13.30, 0, 10);
Subquery
select *
from Production.Products
where listprice < any
(
select listprice
from Production.Products
where productname = N'Product LUNZZ'
) and productname = N'Product LUNZZ';
Connection 1 (Self connection Self-Join)
select p2.*
from Production.Products p1 join
Production.Products p2 on p2.productname = p1.productname
where p2.listprice < p1.listprice
and p1.productname = N'Product LUNZZ';
Connection 2 (Self connection Self-Join)
select p2.*
from Production.Products p1 join
Production.Products p2 on p2.productname = p1.productname
where p2.listprice < p1.listprice
and p1.productname = N'Product LUNZZ'
and p2.productname = N'Product LUNZZ';
Connection 3 (Self connection Self-Join)
select p2.*
from Production.Products p1 join
Production.Products p2 on p2.productname = p1.productname
where p2.listprice < p1.listprice;
- Exercises: use and implement multiple valued subqueries
- Query the first three orders of the sales staff whose LastName is Funk's order volume sum (qty * unit price) in 2007, and return the OrderID
ANSWER: select top 3 orderid from sales.OrderDetails where orderid IN ( select orderid from sales.orders where empid = ( select empid from hr.Employees where lastname = N'Funk' ) and year(orderdate) = 2007 ) group by orderid order by SUM(qty * unitprice) desc
- Supplier SVIYA, assuming that the supplier's products were defective in May 2007, the current demand is:
-
Return all field data of the order
-
Orders for products with problems should be tracked continuously (orders after defective products)
-
It must be an order for the supplier's products
-
Find out the high-risk orders in the past four months (June to September) after the outbreak of defective products
NSWER: select * from sales.Orders where orderid IN ( select distinct orderid from sales.OrderDetails where productid IN ( select productid from Production.Products where supplierid = ( select supplierid from [Production].[Suppliers] where [companyname] = N'Supplier SVIYA' ) ) ) and orderdate >= '20070601' and orderdate < '20071001'
Explore subqueries in depth
According to the classification of design logic, it can be divided into the following two types:
-
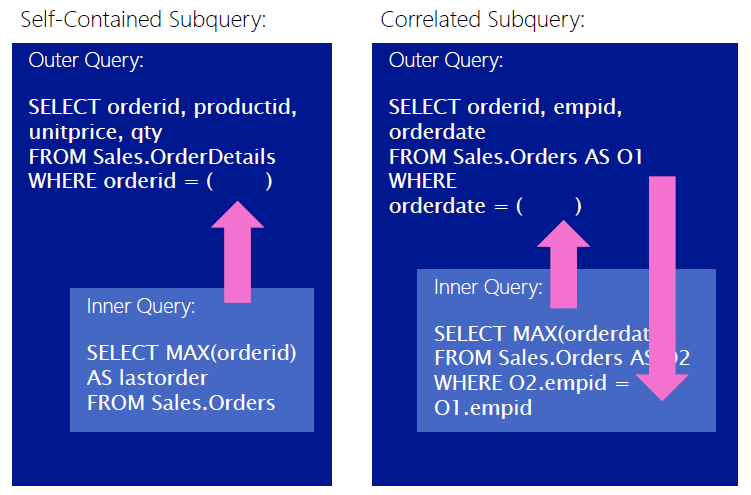
Self contained subqueries (also known as independent subqueries):
- The advantage is that it is easy to debug, because the results of internal queries can be checked independently, and the performance is usually better than that of joins
- The disadvantage is that there are many nested levels and the grammar cannot be simplified
- In terms of writing, the field of external query does not need to appear in internal query. On the contrary, the field of internal query cannot appear in external query
-
Correlated Subqueries:
- The advantage is to decompose the complex join query, making it easy to understand and dimension
- The disadvantage is that it is not easy to debug, because the results of internal queries cannot be viewed independently
- Most of them can be transformed into the design logic of JOIN
- In terms of writing, the fields of external query must appear in internal query. On the contrary, the fields of internal query cannot appear in external query
Precautions: The nesting level cannot exceed 32 levels, which will still depend on the available memory and the complexity of other expressions in the query
Execution times of subquery
-
Self contained subqueries
- External queries and internal queries may not consider the reference integrity of the data table (FK -- > PK)
- The content of the previous course is of this type and will not be repeated here
- The internal query is executed only once, because most of the filter conditions of the internal query are based on a specified value (constant value or calculated fixed value) as the condition to search data, which means that the sub query will not be executed repeatedly
- In other words, for each record selected in the external query, the internal query is only based on the first result
-
Correlated Subqueries
- Most external and internal queries must consider the reference integrity of the data table (FK -- > PK)
- The internal query is executed more than once, because the filtering conditions of the internal query are based on the field value (variable value) passed in by the external query as the condition to search for data, so the execution times of the internal query depends on the data column selected by the external query, which means that the sub query can be executed repeatedly until the conditions are met
- In other words, if one record is selected in each round of external query, the internal query will be repeated once (round). For example, if the number of qualified external queries and internal queries is 5 and 3 respectively, 15 records will be selected
- External query must compare the source value of the Pass data column with the internal query, so in terms of writing, the field of external query must appear in the internal query
- Another option of "JOIN"
Precautions:(Comparison of correlated subqueries and joins) In terms of readability of design logic, in multiple data tables (At least 4 data sheets) Part of Association criteria and filter criteria: When developers interpret the design logic of interrelated subqueries, the flow of data will be clearer, because it has the feeling of modularization, which is conducive to future modification operations When developers interpret the design logic of the connection, because they are written together(Huddle together),This comparison is not conducive to future modification operations, and it will take a long time to clarify In terms of execution efficiency, the two are equal, but there is still a chance for interrelated subqueries to surpass the connection
Correlated Subqueries
Basic syntax:
SELECT <select-list>
FROM Table 1
WHERE Table 1.Column name =
(
SELECT <select-list> <-- Returns a single value Scalar Value
FROM Table 2
WHERE Table 2.Column name x = Table 1.Column name x <-- It can be regarded as connection JOIN Association condition of (Column name to column name)
);
Demonstration: how to use Correlated Subqueries
- Example A: query all the orders of each employee in the latest day and return empid, OrderID and OrderDate
Subquery 1
select empid, orderid, orderdate
from Sales.Orders O1
where orderdate =
(
select max(orderdate)
from Sales.Orders O2
where O2.empid = O1.empid
)
order by empid, orderdate;
Subquery 2
select empid, orderid, orderdate
from Sales.Orders O1
where orderdate =
(
select orderdate
from Sales.Orders O2
where O2.empid = O1.empid
order by orderdate desc
offset 0 rows
fetch next 1 rows only
)
order by empid, orderdate;
Precautions From external queries O1.empid,Appear in internal query Note that the alias of the data table is not marked in the whole process There are 10 employees in total, and only 9 employees have received orders
Example B: query the orders with more than 4 orders in the order details in May 2007, and return the OrderID and CompanyName of the customer
Subquery + association
select o.orderid, c.companyname
from sales.orders o
join sales.Customers c on c.custid = o.custid
where o.orderdate between '20070501' and '20070531'
and o.orderid in
(
select od.orderid
from sales.OrderDetails od
where od.orderid = o.orderid
group by od.orderid
having count(*) > 4
);
association
select o.orderid, c.companyname
from sales.orders o
join sales.OrderDetails od on od.orderid = o.orderid
join sales.Customers c on c.custid = o.custid
where o.orderdate between '20070501' and '20070531'
group by o.orderid, c.companyname
having count(*) > 4;
Exercises: use and implement Correlated Subqueries
- Query which orders to order goods whose unit price is directly equal to the recommended product price, and return all the field information of the "order"
ANSWER: select * from sales.Orders where orderid IN ( select orderid from [Sales].[OrderDetails] od where productid IN ( select productid from [Production].[Products] p where p.listprice = od.unitprice --< Atypical ) ) select * from sales.Orders where orderid IN ( select orderid from [Sales].[OrderDetails] od where unitprice = ( select listprice from [Production].[Products] p where p.productid = od.productid --< typical ) )
- Query which order goods whose unit price is directly equal to the recommended product price, and return all the field information of the "supplier"
ANSWER: select * from Production.Suppliers where supplierid IN ( select supplierid from Production.Products p where productid IN ( select productid from sales.OrderDetails od where od.unitprice = p.listprice ) )
Advanced application of subquery
A typical subquery is in the WHERE clause of an external query. In fact, a subquery can be used in a SELECT, INSERT, UPDATE, or DELETE statement, or even in a valid statement of any executable subquery
From the perspective of clauses other than WHERE in the external query, the types of sub queries that can be applied include:
- Replace expression: the subquery is placed in any position of the SELECT where the expression can be used, for example:
- SELECT clause, which is a typical substitution operation, can be used to compare and contrast reports. For example, from the order data, the data of the highest selling price and the lowest selling price of the order details will be brought out
- ORDER BY clause can achieve conditional sorting, such as sorting only the data related to the current month, or automatically ranking the customer's favorite products at the top, so as to achieve the eye-catching effect
- Derived Table: the location where the subquery is placed in the FROM clause of the SELECT
Precautions: Subquery return「Single value」Suitable for「Substitution expression」. Subquery return「Multiple value」Suitable for「Derivative data sheet」.
Substitution expression
Subqueries that return a "single value" can be used in almost any clause of T-SQL that allows expressions
-
The sub query located in SELECT can solve the problem that the column of a typical sub query (located in the WHERE clause of an external query) cannot be displayed in the result set of an external query
- Applicable to situations where partial set data values are generated
- A substitution expression can only return one field value. In other words, if there are two field values, you need to write two substitution expressions
-
If the replacement expression returns NULL, unless the source data is NULL, it must be caused by the failure of the filter condition (Association condition) of the interrelated sub query
Basic syntax: SELECT (Subquery) ...ellipsis... ORDER BY (Subquery);
Precautions SELECT When clause has subqueries, you should pay attention to GROUP BY Limitation of ORDER BY Clause uses a subquery, which can make the effect of partial sorting, rather than the whole data table If a subquery returns an empty result set, it will be converted to a null value NULL ORDER BY Null value NULL Sort together and place at the top or end collocation「Correlated subquery (Correlated Subquery)」Will be more meaningful
Demonstration: how to apply subqueries in substitution expressions
- Example A: query all orders and find out the highest selling price of the ordered products, and return OrderID, OrderDate and the highest selling price of the goods
Subquery (Located in SELECT Subquery of)
select O.OrderID,
O.OrderDate,
(
select max(unitprice)
from sales.OrderDetails OD
where OD.orderid = O.orderid
) Maximum selling price
from sales.orders O;
Precautions: Located in SELECT Subquery solvable at WHERE The results of the subquery cannot be displayed in the external query
association
select O.OrderID,
O.OrderDate,
max(OD.unitprice) Maximum selling price
from sales.orders O
join sales.OrderDetails OD on OD.orderid = O.orderid
group by O.OrderID, O.OrderDate;
- Example B: according to the previous example of "Correlated Subquery", query the orders with more than 4 order details in May 2007, and return the OrderID and CompanyName of the customer
Subquery (Located in select The sub query of is completely designed based on the sub query, which is very important)
select o.orderid,
(
select companyname
from sales.customers c
where c.custid = o.custid
) CompanyName
from sales.orders o
where o.orderdate between '20070501' and '20070531'
and o.orderid in
(
select od.orderid
from sales.OrderDetails od
where od.orderid = o.orderid
group by od.orderid
having count(*) > 4
);
- Example C: query the employee data table, but only sort employee numbers 4 to 7, and return Lastname and EmpID
Subquery (Located in order by Subquery of)
select e1.Lastname, e1.EmpID
from hr.Employees e1
order by (
select e2.empid
from hr.Employees e2
where e2.empid = e1.empid
and e2.empid between 4 and 7
);
Precautions: Those records outside the subquery range are returned because NULL And sort in front, this is SQL Server Characteristics of Conditional sorting can be performed through COALESCE() or CASE...WHEN... or IIF() Settle
use IIF() Sort specific employee numbers in ascending order, and others put them at the top select Lastname, EmpID from HR.Employees order by iif(empid between 4 and 7, empid, 0);
Precautions: If you want to set the qualified to the top, just change 0 to a value greater than the existing employee number
Sort supervisor numbers in ascending order and NULL End setting select lastname, mgrid from HR.Employees order by iif(mgrid is null, 999, mgrid);
Precautions: 999 is used because no supervisor number is so large, so it only needs to be greater than the value of the existing supervisor number
Exercises: use and implement subqueries that replace expressions
1. Query the orders of all products from Japan and the information that the unit price in the order details table is less than the unit price in the product data table (ListPrice), and return the (non details) of the order:
- OrderID
- SubTotal (use the original calculation column SubTotal, or self summarize sum (unit price * qty * (1 - discount)))
- OrderDate
ANSWER:
select OrderID,
sum(SubTotal) SubTotal,
(select orderdate
from sales.orders o
where o.orderid = od.orderid) OrderDate
from sales.OrderDetails od
where productid IN
(
select productid
from Production.Products
where supplierid IN
(
select supplierid
from Production.Suppliers
where country = N'Japan'
)
)
and unitprice <
(
select listprice
from Production.Products p
where p.productid = od.productid
)
group by orderid
2. According to the view table sales For the result set returned by emporders, please count the highest and lowest sales performance of each employee in 2007 (statistical val field), and return the following fields:
- The original fields remain unchanged ([empid], [ordermonth], [qty], [Val], [numorders])
- Highest performance
- Minimum performance
ANSWER: declare @y smallint = 2007 select *, ( select max(val) from Sales.EmpOrders e2 where e2.empid = e1.empid and year([ordermonth]) = @y ) Highest performance, ( select min(val) from Sales.EmpOrders e2 where e2.empid = e1.empid and year([ordermonth]) = @y ) Minimum performance from Sales.EmpOrders e1 where year([ordermonth]) = @y order by empid, ordermonth
Derived Table
Subqueries that return "multiple values" can be used in almost any T-SQL that allows < table_ In the clause of source >.
The data derived FROM the "SELECT" clause can only be used FROM the data derived FROM the "SELECT" clause in the external table.
Basic syntax: SELECT Pick list FROM (Subquery) as Table alias WHERE ...ellipsis...;
Precautions Just add the short name to the result set returned by the sub query to become a virtual data table. The derived data table only exists during the execution of the instruction and does not occupy database space, so it cannot be reused.
Demonstration: how to apply subqueries in derived tables
- Example A: according to the previous example of "Correlated Subquery", query the orders with more than 4 order details in May 2007, and return the OrderID and CompanyName of the customer
Join a derived table
select vt.orderid, c.companyname
from sales.Customers c
join (
select o.orderid, o.custid
from sales.orders o
join sales.OrderDetails od on od.orderid = o.orderid
where o.orderdate between '20070501' and '20070531'
group by o.orderid, o.custid
having count(*) > 4
) vt on vt.custid = c.custid;
- Example B: query the maximum order quantity of each customer's order, return CustID and qty, and sort in ascending order according to CustID
Do not use connection 1
select CustID,
MAX(SubQTY) QTY
from (
select o.CustID,
(
select sum( od.qty )
from sales.OrderDetails od
where od.orderid = o.orderid
) SubQTY
from sales.orders o
) vt
group by custid
order by custid;
Join a derived table 2
select CustID,
MAX(qty) QTY
from (
SELECT O.custid, SUM(OD.qty) AS qty
FROM Sales.Orders AS O
INNER JOIN Sales.OrderDetails AS OD ON OD.orderid = O.orderid
GROUP BY O.custid
) vt
group by custid
order by custid;
Full use of connections (Do not use derivative tables) 3
SELECT o.CustID,
MAX(od.qty) QTY
FROM Sales.Orders o
join Sales.OrderDetails od on od.orderid = o.orderid
GROUP BY custid
order by custid;
Exercises: use and implement subqueries of derived tables
1. According to the previous example of "typical sub query self contained subquery", to query the data of all employees whose salary is higher than the average salary, please design it in the way of "derivative data table" combined with "JOIN" (move the sub query from WHERE to FROM)
ANSWER: select * from hr.Employees e join ( select avg(salary) avgSalary from hr.Employees ) dt on e.salary > dt.avgSalary
2. According to the previous example of "typical sub query self contained subquery", query which orders are generated after the last day of the order with the customer name Customer UMTLM. Return all the field data of those orders. Please design in the way of "derived data table" combined with "JOIN" (move the sub query from WHERE to FROM)
ANSWER:
select *
from sales.orders o
join
(
select max(orderdate) maxOrderdate
from sales.orders
where custid =
(
select custid
from sales.Customers
where companyname = 'Customer UMTLM'
)
) dt on o.orderdate > dt.maxOrderdate
Data table operation formula
What is "table expression":
-
It is not a standard "user defined data table", nor does it store user data. You will find that these objects are only defined by SELECT, so the returned result set is also a table derived from SELECT.
-
It can contain an expression, which is a part of the calculation formula. For example, the basic formula for calculating annual salary salary SALARY * 12. When updating the basic (base) data table, the values in the expression will be evaluated, so it can be regarded as the "data table with an expression".
-
Some also support inputting parameters into data table expressions to meet different operation requirements.
-
Table expressions are named table expressions, that is, they must be given a name.
The operation formula of the data table is divided into: -
Derived Table
-
View view
-
Table valued function (tvf)
-
Common Table Expression (CTE)
Comparison table of data table and operation formula:
| Data table operation formula | Incoming value | Store in database | Reuse | SELECT | INSERT | UPDATE | DELETE |
|---|---|---|---|---|---|---|---|
| Derivative data sheet | Variable, by external DECLARE | N | Y | N | N | N | N |
| View table | None | Y | Y | Y | Y | Y | Y |
| Table valued function (number) | Variable, part of ontology structure | Y | Y | Y | Y | Y | Y |
| General data sheet formula | Variable, by external DECLARE | N | Y | Y | Y | Y | Y |
Precautions: Only one base table is allowed Columns generated from functions are not allowed, for example: for SUM() The column execution of the returned value UPDATE instructions
Derived Table
What is a derived table
- Evolved FROM a typical subquery, a named table operation placed in the FROM clause of an external query and given a table alias, which provides the result set of the table source of the external query. It is also a virtual table (FROM clause + subquery + table alias)
- The scope is only in the defined query, and the life cycle ends at the end of the query, so it is not stored in the database
- Data sources can be customized according to query requirements
Unlike typical subqueries:
- All columns must have a name (alias) and cannot be repeated
- FROM clause of external query
Precautions: It supports the input of parameter values into table expressions by using external declared variables and using them in the expressions of derived tables The derived data sheet has been discussed in the previous course and will not be repeated
View view
The data table is an object designed according to the data model design process, and the view table is designed from the user's point of view. For example, the data viewed by ordinary employees and supervisors must be different. Even ordinary employees in different positions in the same department will see different data. Also, because the view table does not support "input parameter value", in some cases, You must specify different constant values in each view, so there will be more views than tables
-
Because the view does not support "input parameter value", the filter criteria of SELECT query almost always specify "constant", for example: WHERE empid = 3
-
Similarities between views and tables:
- Views are used in the same way as real tables, so they are also called virtual tables
- Similar to a standard user-defined table, a view consists of a set of named columns and columns
- The view also allows DML operations
-
Differences between views and tables:
- The data table has the definition of outline structure, such as column name, data type, column attribute list, etc. in addition, it also stores data (records)
- The view has no definition of outline structure. It is defined by a SELECT query syntax, so it is impossible to store any data (records) by itself
-
The table referenced by the SELECT query syntax in the view supports:
- More than one real data table is also called base table
- Another view (but the underlying is ultimately the base table)
-
Benefits of view:
- You can hide sensitive information, such as salary
- Hiding the entity data table makes it difficult for users to know the actual data structure and reduce the risk of database attack
- Design logic of hiding SELECT query syntax
- Simplify the query, wrap the highly complex query in the view, and the external program only needs to directly access the view to retrieve the required data
- If the view is designed as an updatable view, it can support DML operations, but there are still some restrictions. This part will be described in detail later
Precautions: From the perspective of network management, the view can be regarded as「Firewall」Similarly, only specific network traffic is allowed to pass through, which is equivalent to hiding sensitive fields in the view and displaying only specific fields, so the base table can be protected
- So far, the views introduced are user-defined views, but the original SELECT query definition is covered with the CREATE VIEW framework
Precautions (Comparison of views and derived tables) Derived tables are only unnamed table expressions with the same restrictions as views In terms of using variables: View: variables are not allowed in the query definition Derived tables: variables are allowed to be included in the query definition In terms of the life cycle of an object: View: because it is a specific object and is also stored in the database, it can be reused Derived tables: because they are non-specific objects and are not stored in the database, they cannot be reused
Basic syntax: CREATE VIEW [Structure description name.] View name [WITH Attributes] AS SELECT ...ellipsis... [WITH CHECK OPTION];
WITH Attribute support: [ ENCRYPTION ]: encryption select Definition [ SCHEMABINDING ]: Bind「Base data sheet」,To prevent it from being deleted, making the view inoperable
WITH CHECK OPTION It is mandatory that all data modification statements executed on the view must be followed select_statement Set criteria If this attribute is not specified, UPDATE,DELETE Will still follow select_statement The set filter criteria, but INSERT unrestricted If this attribute is specified, INSERT Will follow select_statement Set filter criteria It can ensure that the modified data can still be seen through the view after being approved
Demonstration: creation and execution of a view
- Example A: A data source is A view of A single table and multiple tables
-- Step 1: Create a view from a single table
-- Select and execute the following to create a simple view
CREATE VIEW HR.EmpPhoneList
AS
SELECT empid, lastname, firstname, phone
FROM HR.Employees;
GO
-- Select from the new view
SELECT empid, lastname, firstname, phone
FROM HR.EmpPhoneList;
GO
-- Step 2: Create views from multiple tables
-- Create a view using a multi-table join
CREATE VIEW Sales.OrdersByEmployeeYear
AS
SELECT emp.empid AS employee ,
YEAR(ord.orderdate) AS orderyear ,
SUM(od.qty * od.unitprice) AS totalsales
FROM HR.Employees AS emp
JOIN Sales.Orders AS ord ON emp.empid = ord.empid
JOIN Sales.OrderDetails AS od ON ord.orderid = od.orderid
GROUP BY emp.empid ,
YEAR(ord.orderdate)
GO
-- Select from the view
SELECT employee, orderyear, totalsales
FROM Sales.OrdersByEmployeeYear
ORDER BY employee, orderyear;
-- Step 3: Clean up
DROP VIEW Sales.OrdersByEmployeeYear;
DROP VIEW HR.EmpPhoneList;
- Example B: using properties supported by the view
-- START: Establish test environment use TSQL2; -- establish「Base data sheet」 HR.Copy_Emp drop table if exists HR.Copy_Emp; SELECT empid, lastname, firstname, phone INTO HR.Copy_Emp FROM HR.Employees; GO -- Inquiry「Base data sheet」 HR.Copy_Emp SELECT * FROM HR.Copy_Emp; GO -- END: Establish test environment -- START: Create an encrypted view -- use ENCRYPTION Property to create an encrypted view HR.EmpPhoneList CREATE OR ALTER VIEW HR.EmpPhoneList WITH ENCRYPTION AS SELECT empid, lastname, firstname, phone FROM HR.Copy_Emp; GO -- Operation: from「Item manager」Observation view HR.EmpPhoneList Encrypted state -- END: Create an encrypted view -- START: Bind「Base data sheet」 -- use SCHEMABINDING Bind「Base data sheet」HR.Copy_Emp CREATE OR ALTER VIEW HR.EmpPhoneList WITH SCHEMABINDING AS SELECT empid, lastname, firstname, phone FROM HR.Copy_Emp; GO -- Attempt to delete「Base data sheet」HR.Copy_Emp DROP TABLE HR.Copy_Emp; GO -- Message: unable to DROP TABLE HR.Copy_Emp,Because objects 'EmpPhoneList' Referring to it. -- Unbind「Base data sheet」 CREATE OR ALTER VIEW HR.EmpPhoneList AS SELECT empid, lastname, firstname, phone FROM HR.Copy_Emp; GO -- Attempt to delete「Base data sheet」HR.Copy_Emp DROP TABLE HR.Copy_Emp; GO -- Message: command completed successfully -- END: Bind「Base data sheet」 -- START: Mandatory compliance select_statement Criteria set in WITH CHECK OPTION -- Establish again「Base data sheet」 HR.Copy_Emp drop table if exists HR.Copy_Emp; SELECT empid, lastname, firstname, phone INTO HR.Copy_Emp FROM HR.Employees; GO -- establish select_statement View with criteria HR.EmpPhoneList CREATE OR ALTER VIEW HR.EmpPhoneList AS SELECT empid, lastname, firstname, phone FROM HR.Copy_Emp WHERE empid between 3 and 5 WITH CHECK OPTION; GO -- Query view HR.EmpPhoneList SELECT * FROM HR.EmpPhoneList; -- Pair view HR.EmpPhoneList Try INSERT INSERT INTO HR.EmpPhoneList (lastname, firstname, phone) VALUES (N'Daming', N'king', N'123-4567') --Message: the attempt to insert or update has failed because the target view is specified WITH CHECK OPTION Or span specified WITH CHECK OPTION And one or more data generated by the operation are listed in CHECK OPTION Unqualified under conditions. -- Pair view HR.EmpPhoneList Try UPDATE UPDATE HR.EmpPhoneList SET phone = N'333-5555' WHERE empid = 8; --Message:(0 Columns affected) -- Pair view HR.EmpPhoneList Try DELETE DELETE HR.EmpPhoneList WHERE empid = 8; --Message:(0 Columns affected) -- Action: try to remove WITH CHECK OPTION Retry editing the view again HR.EmpPhoneList Try INSERT,UPDATE,DELETE -- END: Mandatory compliance select_statement Criteria set in -- Restore changes, not related to this topic DROP VIEW HR.EmpPhoneList; DROP TABLE HR.Copy_Emp;