Mslab (memory local allocation buffer) of HBase
preface
This paper briefly introduces the write cache MemStore and data structure of HBase, as well as the function and source code analysis of MSLAB, which is the main component of write cache. MSLAB is the abbreviation of MemStore local allocation buffer. It carries out reasonable planning and management of MemStore memory and effectively optimizes the GC problem of Java programs.
Introduction to memory
Memory is one of the important data storage components in HBase. HBase data writing first records the WAL on the HLog, and then does not directly write the data to the disk, but returns quickly after writing to the memory, which effectively improves the write throughput of HBase.
Memory data structure
Memstore uses the data structure of jump table to store ordered keyvalues. The KeyValueSkipListSet in memstore has a layer of packaging for the ConcurrentSkipListMap.
Simple diagram of jump table structure (example diagram of ConcurrentSkipListMap annotation):
/*
* Head nodes Index nodes
* +-+ right +-+ +-+
* |2|---------------->| |--------------------->| |->null
* +-+ +-+ +-+
* | down | |
* v v v
* +-+ +-+ +-+ +-+ +-+ +-+
* |1|----------->| |->| |------>| |----------->| |------>| |->null
* +-+ +-+ +-+ +-+ +-+ +-+
* v | | | | |
* Nodes next v v v v v
* +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+
* | |->|A|->|B|->|C|->|D|->|E|->|F|->|G|->|H|->|I|->|J|->|K|->null
* +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+
*/
All data are in the lowest linked list structure, and the nodes in the upper layer are simply understood as index nodes. The data search starts from the Head nodes on the top layer and traverses to the right in the same layer. If the node on the right is larger than the node to be searched, it moves to the next layer until the data is obtained.
In this way, the stored KeyValue ensures the order, which can quickly locate the required data content when the data needs to be obtained, and directly write the data in memory into HFile in order when flush ing.
Meaning of MSLAB
As memory storage, MemStore data may exist in memory for a long time, which will inevitably lead to GC problems in Java programs. KeyValue references stored in MemStore may be held for a long time. After flush ing, MemStore data is written to HFile, and this part of keyValue references can be released naturally. If these keyValue memory allocations are not managed, a large number of memory fragments will be generated after several recoveries, resulting in no continuous memory allocation for Java processes, resulting in FullGC.
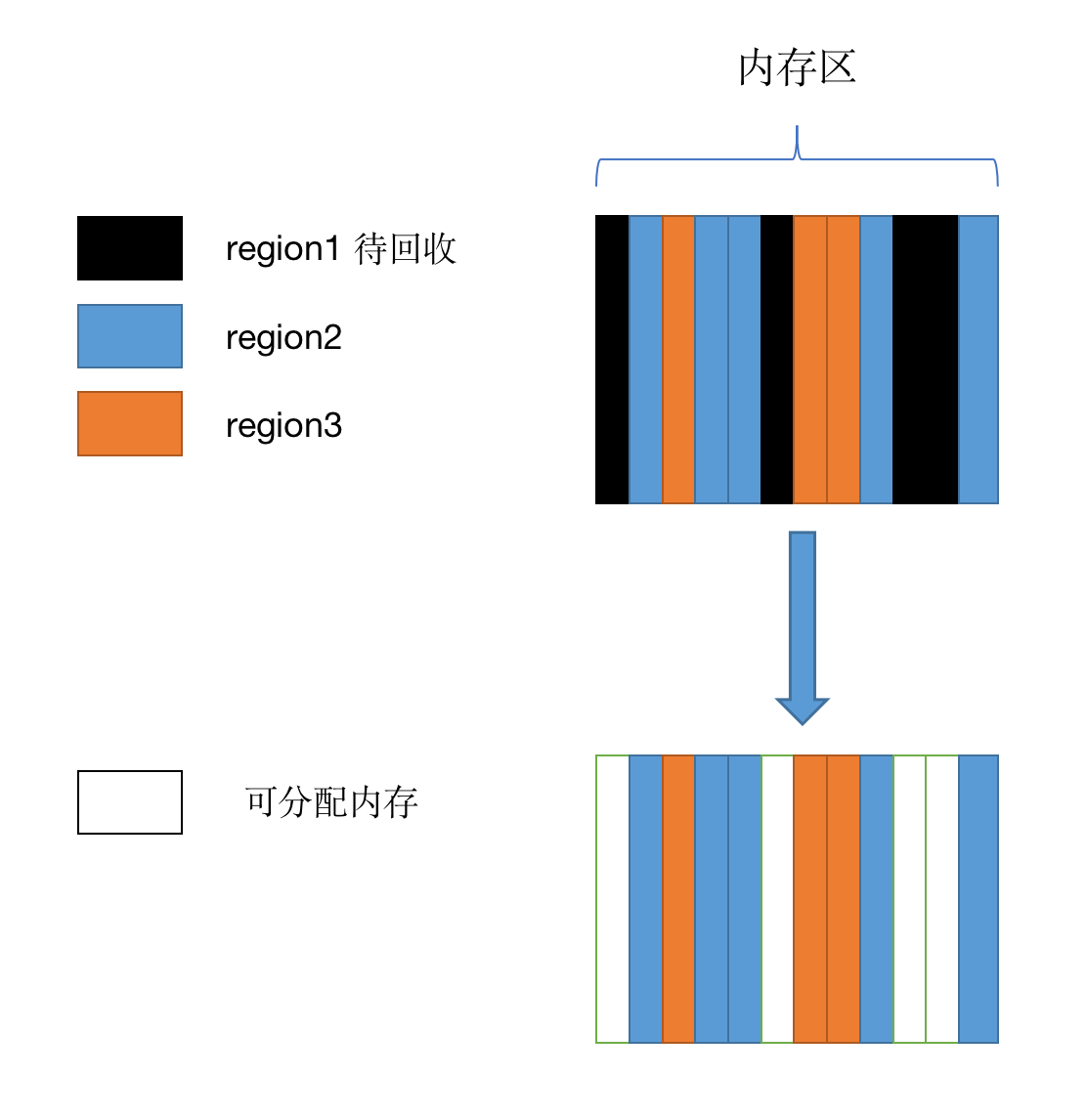
There are multiple regions in a RegionServer process, but the memstores of multiple regions share the same JVM memory for use. The figure above simply illustrates the consequences of fragmentation if memory is not managed in this case.
In order to solve the problem of memory fragmentation, MSLAB was born.
MSLAB uses a fixed memory segment Chunk to store KeyValue data, rather than allowing KeyValue to be held for a long time. In this way, when the Region performs flush, it releases a continuous memory occupied by Chunk instead of the scattered memory occupied by KeyValue, which solves the problem of memory fragmentation.
MSLAB source code analysis
Now go directly to the source code. The English notes are the original notes of HBase project, and the Chinese notes are for the convenience of understanding the execution process and logic of the method.
MemStoreLAB#allocateBytes
First, let's look at the main process of allocating Chunk. When MemStore allocates memory space for the newly entered KeyValue, MSLAB is used to obtain the Allocation instance and write the KeyValue data to Chunk.
/**
* Allocate a slice of the given length.
*
* If the size is larger than the maximum size specified for this
* allocator, returns null.
*/
// MemStore calls this method to write the data of KeyValue into the Chunk of MSLAB. size is the byte length of KeyValue, that is, the required space
// The returned Allocation holds the byte array of Chunk, and offset is used to record where to write data of size from
public Allocation allocateBytes(int size) {
Preconditions.checkArgument(size >= 0, "negative size");
// Callers should satisfy large allocations directly from JVM since they
// don't cause fragmentation as badly.
// When the size of KeyValue exceeds maxAlloc, KeyValue will not be stored in Chunk
if (size > maxAlloc) {
return null;
}
while (true) {
// Get a Chunk that is not currently full or create a new Chunk
Chunk c = getOrMakeChunk();
// Try to allocate from this chunk
// Use this Chunk to allocate space of size
int allocOffset = c.alloc(size);
if (allocOffset != -1) {
// We succeeded - this is the common case - small alloc
// from a big buffer
// allocOffset != -1 means that Chunk can still allocate space of size, and directly return the Allocation instance
return new Allocation(c.data, allocOffset);
}
// not enough space!
// try to retire this chunk
// The current Chunk does not have enough space allocation. Remove the current Chunk from the reference of MSLAB
tryRetireChunk(c);
}
}
MemStoreLAB#getOrMakeChunk
Get the current Chunk from the previous code or create a new Chunk
/**
* Get the current chunk, or, if there is no current chunk,
* allocate a new one from the JVM.
*/
private Chunk getOrMakeChunk() {
while (true) {
// Try to get the chunk
// curChunk holds the Chunk currently in use. curChunk is of AtomicReference type, which is convenient for cas operation
Chunk c = curChunk.get();
if (c != null) {
return c;
}
// No current chunk, so we want to allocate one. We race
// against other allocators to CAS in an uninitialized chunk
// (which is cheap to allocate)
// If you enable the pooling function of Chunk, you will allocate reused chunks from the chunkPool. If you do not enable pooling, you will allocate a Chunk instance with the size of chunkSize (2MB by default)
c = (chunkPool != null) ? chunkPool.getChunk() : new Chunk(chunkSize);
if (curChunk.compareAndSet(null, c)) {
// we won race - now we need to actually do the expensive
// allocation step
c.init();
this.chunkQueue.add(c);
return c;
} else if (chunkPool != null) {
chunkPool.putbackChunk(c);
}
// someone else won race - that's fine, we'll try to grab theirs
// in the next iteration of the loop.
}
}
Summary
The write cache strategy of MemStore greatly improves the write performance of HBase. MSLAB skillfully uses the continuous large segment memory allocation strategy to solve the problem of memory fragmentation caused by the recycling of a large number of keyvalues.
I hope these skills of HBase can arouse everyone's thinking.
This article uses hbase source code version 0.98.9