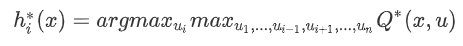Multi-Agent Reinforcement Learning
- The core idea of reinforcement learning is "trial and error": agents optimize iteratively according to the feedback information obtained through interaction with the environment
- Modeling of multi-agent problem -- basis of game theory
- Markov game
- Nash equilibrium
- Equilibrium solving method is the basic method of Multi-Agent Reinforcement Learning. For the problem of multi-agent learning, it combines the classical method of reinforcement learning (such as Q-learning) and the equilibrium concept in game theory, and solves the equilibrium goal through RL method, so as to complete the related tasks of multi-agent.
- Solution of multi-agent problem -- Multi-Agent Reinforcement Learning Algorithm
- independent Q-learning
* Each agent regards other agents as factors in the environment, and still updates the strategy through interaction with the environment in the way of single agent learning
* Simple and easy to implement
* It ignores that other agents also have the ability of decision-making, and the actions of all individuals jointly affect the state of the environment
* It is difficult to learn steadily and achieve good results.
- The relationship between agents is perfect competition (zero sum random game)
- minimax Q-learning algorithm
* For agents i,It needs to be considered in other agents( i-)Action taken( a-)Make yourself( i)Worst return( min)The maximum that can be obtained( max)Expected return
- The relationship between agents is semi cooperative and semi competitive (mixed)
- Nash Q-learning method
- When each agent adopts the ordinary Q-learning method and takes the greedy way, that is, maximizing their respective Q value, this method is easy to converge to the Nash equilibrium strategy
- Nash Q-learning method can be used to deal with multi-agent learning problems with Nash equilibrium as the solution.
- Its goal is to find the Nash equilibrium point of each state, so as to update the Q value based on the Nash equilibrium strategy in the learning process.
- For a single agent i, when updating with Nash Q value, it needs to know not only the global state s and the action a of other agents, but also the Nash equilibrium strategy π corresponding to all other agents in the next state. Further, the current agent needs to know the Q(s') value of other agents, which is usually guessed and calculated according to the observed rewards and actions of other agents. Therefore, Nash Q-learning method has strong assumptions about the information of other agents (including actions, rewards, etc.) that can be obtained by agents. In complex real problems, it generally does not meet such strict conditions, and the scope of application of the method is limited.
- Agents are fully cooperative
- When agents obtain the optimal feedback through cooperation, there is no need for coordination mechanism
- Assuming that there is more than one optimal joint action for all agents {A,B} in the environment, that is, {π A, π B} and {hA,hB}, then A and B need A negotiation mechanism to decide whether to take π or h at the same time; Because if one takes π and the other takes H, the resulting joint action is not necessarily optimal.
- Team Q-learning is a learning method suitable for problems that do not need cooperation mechanism. It proposes that for a single agent i, its optimal action hi can be obtained through the following formula:
- Distributed Q-learning is also a learning method suitable for problems that do not need cooperation mechanism. Unlike Team Q-learning, when selecting the individual optimal action, it needs to know the actions of other agents. In this method, the agent maintains the Q value corresponding to its own action, so as to obtain the individual optimal action.
- Implicit coordination mechanism
In the problem that agents need to negotiate with each other to achieve the optimal joint action, the mutual modeling between individuals can provide a potential coordination mechanism for agent decision-making
- joint action learner (JAL) method
- Agent i will model the strategies of other agents j based on the observed historical actions of other agents j
- Frequency maximum Q-value (FMQ) method
- In the definition of individual Q value, the frequency of the joint action where the individual action is located to obtain the optimal return is introduced, so as to guide the agent to select its own action in the joint action that can obtain the optimal return in the learning process, and the probability of the optimal action combination of all agents will be higher.
- Multi-Agent Reinforcement Learning (mfmarl) method based on mean field theory
- For large-scale group problems
- Combine the traditional reinforcement learning method (Q-learning) and mean field theory. Mean field theory is suitable for modeling complex large-scale systems. It uses a simplified modeling idea: for one individual, the combined action of all other individuals can be defined and measured by an "average"
- Explicit collaboration mechanism
* It is mainly the interaction between human and computer, considering some existing constraints / A priori rules, etc
- Multi-agent deep reinforcement learning
- centralized controller is not necessarily feasible or an ideal decision-making method. If the fully distributed method is adopted, each agent can learn its own value function network and strategy network alone, and can not deal with the instability of the environment well without considering the impact of other agents on itself. Using the characteristics of actor critical framework in reinforcement learning, we can find a coordinated way between these two extreme ways.
- Policy based method
* MADDPG(Multi-Agent Deep Deterministic Policy Gradient
* This method is to determine the strategic gradient in depth( Deep Deterministic Policy Gradient,DDPG)On the basis of the method actor-critic The framework is improved by using the mechanism of centralized training and distributed execution( centralized training and decentralized execution),It provides a general idea for solving multi-agent problems.
* MADDPG A centralized system is established for each agent critic,It can obtain the global information (including the global state and the actions of all agents) and give the corresponding value function Qi(x,a1,...,an),This can alleviate the problem of unstable environment of multi-agent system to a certain extent. On the other hand, each agent's actor Then we only need to make decisions according to the local observation information, which can realize the distributed control of multi-agent.
Based on actor-critic In the process of learning the framework, critic and actor Update method and DDPG similar. about critic,Its optimization objectives are:
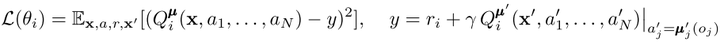
about actor,Consider deterministic strategyμi(ai|oi),The gradient calculation during policy update can be expressed as:
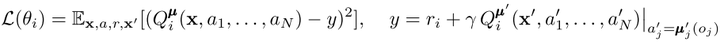
* MADDPG It is further proposed that the strategies of other agents can be estimated by the maintenance strategy approximation function, and the maintenance can be centralized by modeling the behavior of other agents Q It is feasible for a single individual to consider the effect of combined action.
* MADDPG Policy integration is also used to deal with environmental instability( policies ensemble)Skills. Because the strategies of each agent in the environment are iteratively updated, it is easy to see that the strategies of a single agent over fit the strategies of other agents, that is, when the strategies of other agents change, the current optimal strategy may not be well adapted to the strategies of other agents. In order to alleviate the over fitting problem, MADDPG The idea of strategy integration is proposed, that is, for a single agent i,Its strategyμi It consists of multiple sub policiesμi^k A collection of. In a episode Use only one of the sampling strategies to complete the interaction. The goal of maximizing the learning process is the expected return of all sub strategies
* Summary: MADDPG The core of is DDPG Based on the algorithm, the global algorithm is used for each agent Q Value to update the local strategy. This method can achieve good results in the problems of complete cooperation, complete competition and mixed relationship.
* COMA(slightly
- Value based method
- In the policy based method, the centralized value function directly uses the global information for modeling, without considering the characteristics of individuals. When the multi-agent system is composed of large-scale multiple individuals, such value function is difficult to learn or train to convergence, and it is difficult to deduce the ideal strategy. And only relying on local observations, it is impossible to judge whether the current reward is obtained due to their own behavior or the behavior of other teammates in the environment.
- Value decomposition networks (vdn) (omitted)
* Global Q(s,a)Decompose values into parts Qi(si,ai)Each agent has its own local value function.