Write in front
In the increasingly complex front-end engineering, the front-end engineering around webpack is particularly important in the front-end project. When it comes to webpack, the Loader mechanism will be mentioned.
Here we will uncover the face of loader layer by layer from application principle implementation. No more nonsense, let's start quickly.
The article will take you step by step around the following three aspects to thoroughly master the Webpack Loader mechanism:
- Loader concept: what is loader? Starting from the foundation, it will take you to get a quick introduction to various configuration methods of loader in daily business.
- Loader principle: interpret the loader module from the source code and implement the Webpack core loader runner library by hand.
- Loader implementation: reproduce the Babel loader that appears frequently, and take you to master the development process of enterprise loader.
Here we will bid farewell to the boring way of reading the source code, and take you to master the core principles of Loader and skillfully apply them to various scenarios.
This article is based on the latest 5.64.1 version of webpack loader-runner 4 Version 2.0 for analysis.
Ok! Let's Do It !
Loader concept
Role of Loader
Let's start with the most basic. The so-called Loader is essentially a function.
Loader is used to convert the source code of the module. Loader allows you to preprocess files when you import or "load" modules. Therefore, loader is similar to the "task" in other construction tools and provides a powerful way to deal with the front-end construction steps. Loader can convert files from different languages (such as TypeScript) to JavaScript or convert inline images to data URL s. Loader even allows you to import CSS files directly into JavaScript modules!
When the module is compiled through the compilation object in webpack, it will first match the loader processing file to get the result (string/buffer), and then output it to webpack for compilation.
Simply put, * * loader is a function through which we can process * * in advance before webpack processes our specific resources (files).
For example, webpack can only recognize JavaScript modules, and we can use Babel loader to write code in advance when using TypeScript The ts suffix file is compiled in advance as JavaScript code, and then handed over to Webapack for processing.
Loader configuration related API
Common basic configuration parameters
Let's take a look at the simplest webpack configuration file:
module.exports = {
module: {
rules: [
{ test: /.css$/, use: 'css-loader',enforce: 'post' },
{ test: /.ts$/, use: 'ts-loader' },
],
},
};I believe you are familiar with this configuration code. We configure the loader through the rules attribute in the module.
Of which:
test parameter
Test is a regular expression. We will match the corresponding resource files according to the rules of test. If it matches, the file will be handed over to the corresponding loader for processing.
use parameter
use indicates which loader rule should be used to match the corresponding file in test. use can be a string or an array.
In addition, if use is an array, it means that multiple loader s process the matched resources in turn, in the order from right to left (from bottom to top).
Enforceparameter
There is an enforce parameter in the loader, which indicates the order of the loader, such as a configuration file:
module.exports = {
module: {
rules: [
{ test: /.css$/, use: 'sass-loader', enforce: 'pre' },
{ test: /.css$/, use: 'css-loader' },
{ test: /.css$/, use: 'style-loader', enforce: 'post' },
],
},
};in the light of. For the resource file at the end of css, we use module. In the packaging process Rules have three matching rules, that is, for the same rule css files need to be processed with three matched loader s.
At this time, if we hope that the order of the three loader s can not be handled according to the order of writing, enforce will show its skill.
enforce has two values: pre and post.
- When the enforce r parameter is not configured for the rules in our rules, it defaults to normal loader.
- When the rules in our rules are configured with the enforce:'pre' parameter, we call it pre loader.
- When the rules in our rules are configured with the enforce:'post' parameter, we call it post loader.
As for the execution order of these three loaders, I think you can guess one or two according to the name. Yes, in the execution stage of normal loaders, the execution order of these three types of loaders is:

Of course, so what is an abnormal loader? We will talk about it in detail later.
Three ways to configure loader in webpack
Usually, we use the loader name directly when configuring, for example:
// webpack.config.js
module.exports = {
...
module: {
rules: [
{
test:/\.js$/,
loader: 'babel-loader'
}
]
}
}In the above configuration file, it is equivalent to telling webpack to use Babel loader to process the files at the end of js. But here we only write a string of Babel loader. How does it find the real content of Babel loader?
With this question in mind, let's take a look at three ways to configure loader s in webpack.
Absolute path
The first method is common when there are some unpublished custom loaders in the project. It directly points to the address of the loader file in the form of absolute path address. For example:
const path = require('path')
// webpack.config.js
module.exports = {
...
module: {
rules: [
{
test:/\.js$/,
// In fact, the. js suffix can be omitted. Later, we will explain how to configure the module search rules of loader
loader: path.resolve(__dirname,'../loaders/babel-loader.js')
}
]
}
}Here, we pass in the form of an absolute path in the loader parameter, and directly go to the path to find the js file where the corresponding loader is located.
resolveLoader.alias
The second method can be configured through the alias of resolveLoader in webpack, such as:
const path = require('path')
// webpack.config.js
module.exports = {
...
resolveLoader: {
alias: {
'babel-loader': path.resolve(__dirname,'../loaders/babel-loader.js')
}
},
module: {
rules: [
{
test:/\.js$/,
loader: 'babel-loader'
}
]
}
}At this time, when webpack uses Babel loader in parsing to loader, it finds the file path with Babel loader defined in alias. The corresponding loader file will be found according to this path, and the file will be used for processing.
Of course, when we define a loader, if each loader needs to define a resolveLoader The words of alias are undoubtedly too redundant. In real business scenarios, we rarely define the resolveLoader option ourselves, but webpack can also automatically help us find the corresponding loader, which will lead to another parameter.
resolveLoader.modules
We can use resolveloader Modules defines the directory that webpack should look for when parsing the loader, such as:
const path = require('path')
// webpack.config.js
module.exports = {
...
resolveLoader: {
modules: [ path.resolve(__dirname,'../loaders/') ]
},
module: {
rules: [
{
test:/\.js$/,
loader: 'babel-loader'
}
]
}
}In the above code, we will resolveloader Modules is configured as path Resolve (_dirname,'.. / loaders / '). At this time, when webpack parses the loader module rules, it will go to path Resolve (_dirname, '.. / loaders /') directory to find the corresponding file.
Of course, resolveloader The default value of modules is ['node_modules']. Naturally, in the default business scenario, the third-party loaders we follow through npm install exist on node_ Modules, so configure mainFields to find the corresponding loader entry file by default.
Some students may be as like as two peas in resolveLoader. They are exactly the same configuration parameters as resolve's normal module parsing. However, resolveloader is relative to the module loading rules of the loader. Please refer to the configuration manual for more details You can see it here.
At the same time, it should be noted that the relative path search rule in the modules field is similar to the Node search 'Node'_ Modules'. For example, modules:['node_modules'], that is to find rules in the current directory by viewing the current directory and the ancestor path (i.e. / node_modules,.. / node_modules, etc.).
loader type and execution sequence
Type of Loader
As mentioned above, loaders can be divided into three types through the enforce parameter of the configuration file: pre loader, normal loader and post norml, which represent three different execution sequences respectively.
Of course, in the configuration file, according to the execution order of loaders, we can divide loaders into three types. At the same time, webpack also supports an inline way to configure loaders. For example, when we reference resource files:
import Styles from 'style-loader!css-loader?modules!./styles.css';
In the above way, we are quoting/ styles. During CSS, CSS loader and style loader are called to process files in advance, and the parameters of modules are passed to CSS loader.
We will quote resources when passing! The method of dividing and using loaders is called * * inline loader * *.
So far, we know that there are four types of loaders: pre loader, normal loader, inline loader and post loader.
There are some special pre parameters for inline loader that you need to know:
By prefixing the inline import statement, you can override all normalloaders, preloaders, and postloaders in the configuration:
Use! Prefix, all configured normal loaders will be disabled
import Styles from '!style-loader!css-loader?modules!./styles.css';
Use!! Prefix, all configured loaders (preLoader, loader, postLoader) will be disabled
import Styles from '!!style-loader!css-loader?modules!./styles.css';
Use -! Prefix, all configured preloaders and loaders will be disabled, but postLoaders will not be disabled
import Styles from '-!style-loader!css-loader?modules!./styles.css';
There is no need to memorize by rote here. After understanding the general usage, you can pass it webpack official website Just check it.
Execution order of Loader
After understanding, we divide loaders into four types: pre loader, normal loader, inline loader and post loader.
In fact, we can also see the execution order of these four loaders by naming them. In the default loader execution stage, these four loaders will execute in the following order:

Before the webpack compiles the file, the resource file matches the corresponding loader:
- Execute pre loader preprocessing file.
- Pass the resource chain after pre loader execution to normal loader for normal loader processing.
- After the normal loader is processed, it is handed over to the inline loader for processing.
- Finally, the file is processed by post loader, and the processed results are handed over to webpack for module compilation.
Note that we emphasize the execution phase of the default loader, so what is non default? Next, let's take a look at the so-called pitch loader stage.
The pitch phase of the loader
The implementation phase of loader is actually divided into two phases:
- Before processing the resource file, you first go through the pitch phase.
- After the end of the pitch, read the contents of the resource file.
- After the pitch processing, the resource file is read, and then the content of the read resource file will be handed over to the loader in the normal stage for processing.
In short, the so-called loader can process file resources in two stages: pitch stage and nomral stage.
Let's look at an example:
// webpack.config.js
module.exports = {
module: {
rules: [
// Ordinary loader
{
test: /\.js$/,
use: ['normal1-loader', 'normal2-loader'],
},
// Front loader
{
test: /\.js$/,
use: ['pre1-loader', 'pre2-loader'],
enforce: 'pre',
},
// Post loader
{
test: /\.js$/,
use: ['post1-loader', 'post2-loader'],
enforce: 'post',
},
],
},
};// In the entry file import something from 'inline1-loader!inline2-loader!./title.js';
Here, we configure three processing rules and six loaders for js files in the webpack configuration file. At the same time, it is imported in the entry file/ title.js uses the inline loader we mentioned earlier.
Let's use a diagram to describe the execution sequence of the so-called loader:
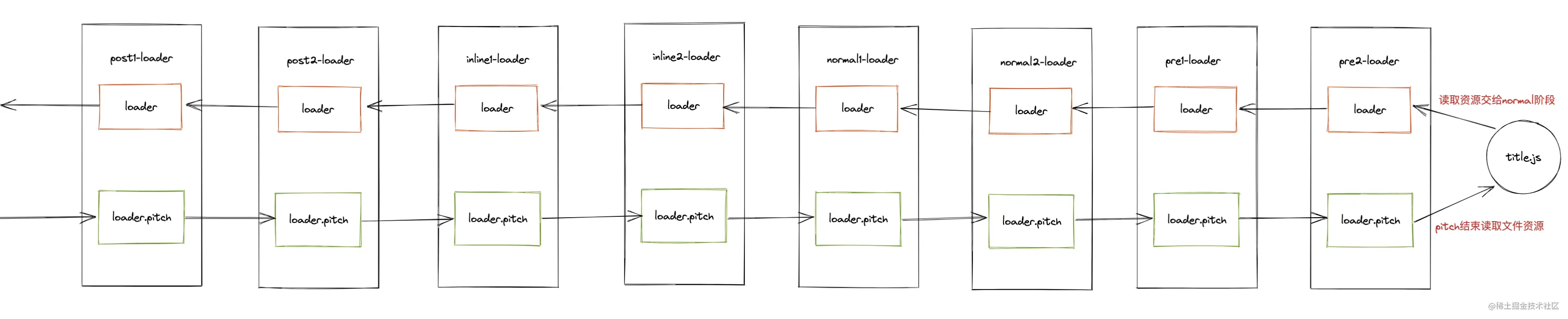
The execution phase of the loader is actually divided into two phases. When using the loader to process resources, the webpack will first pass through the loader In the pitch phase, the file will be read only after the pitch phase is completed, and then the normal phase processing will be carried out.
- Pitching stage: the pitch method on the loader is called in the order of post, inline, normal and pre.
- Normal # stage: the conventional methods on the loader are called in the order of # pre, normal, inline and post.
Please remember the above loader execution flow chart, and then we will use this flow in detail to take you to realize the source code of loader runner.
What is the role of the pitch phase and why webpack designs loader s in this way. Don't worry, the following content will slowly solve these answers for you.
Fusing effect of pitch Loader
Above, we describe the execution sequence of loaders in webpack through a figure. We learned that in addition to the normal loader execution phase, there is an additional loader Pitch phase.
The pitch loader is essentially a function, for example:
function loader() {
// Normal loader execution phase
}
loader.pitch = function () {
// pitch loader
}What needs special attention about the pitch loader is the fusing effect brought by the pitch loader.
Suppose we add a pitch attribute to inline1 loader among the eight loaders configured above, so that it has a pitch function, and we let its pitch function return a non defined value at will.
// inline1-loader normal
function inline1Loader () {
// dosomething
}
// inline1-loader pitch
inline1Loader.pitch = function () {
// do something
return '19Qingfeng'
}Here, we returned a string 19Qingfeng in the inline1 loader pitch stage. As we mentioned above, the loader will execute according to this figure in the execution stage (when all the pitch stages return undefined):
However, once a non undefined value is returned in the pitch order function of a loader, the fuse effect will occur:
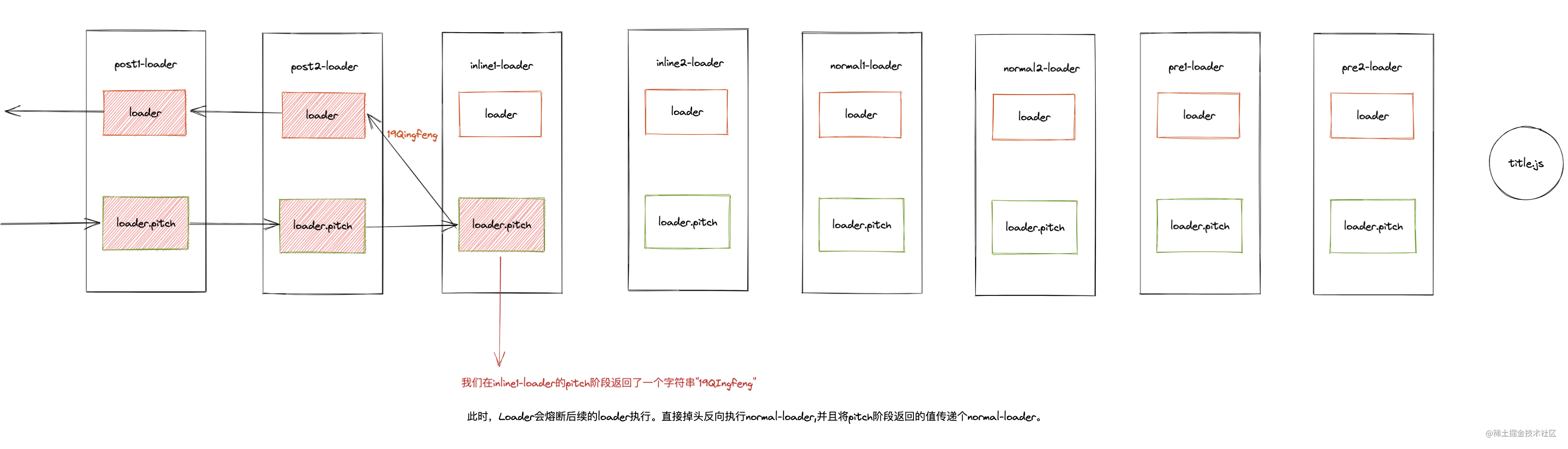
We can see that when we return a string 19Qingfeng in the pitch function of inline1 loader, the execution chain of the loader will be blocked -- immediately turn around, directly turn around and execute the normal phase of the last executed loader, and pass the return value of the pitch to the next normal loader. In short, this is the fuse effect of the loader.
Loader development related API s
Above, we introduced the basic concept and configuration usage of loader. We learned that loader is divided into four types according to the execution stage, and the execution of loader is divided into two stages: pitch and normal.
Next, let's take a look at the related contents of common development loader s:
Impact of execution sequence on loader development
Here, I would like to emphasize with you that loader is essentially a function.
function loader() {
// ...
}
// The pitch attribute is optional
loader.pitch = function () {
// something
}The order of loader execution is determined through the configuration of webpack. In other words, whether a loader is pre, normal, inline or post has nothing to do with the loader development itself.
The execution order only depends on the configuration of the loader when the webpack is applied (or the prefix added when the file is introduced).
Synchronous or asynchronous loader
Synchronous Loader
The loaders listed above are all synchronous loaders. The so-called synchronous loader is very simple. This is to synchronously process the corresponding logic in the loader stage and return the corresponding value:
// Synchronous loader
// The source parameter of loader will be described in detail later. Here you can understand the file content to be processed
function loader(source) {
// ...
// A series of synchronization logic. The final function returns the processed results to the next stage
return source
}
// Synchronization in the pitch phase is the same
loader.pitch = function () {
// After a series of synchronous operation functions are executed, the pitch is executed
}When the synchronous loader returns a value in the normal phase, it can be returned through the return statement inside the function. At the same time, if multiple values need to be returned, it can also be returned through this Callback () means that the loader ends and returns by passing in multiple values, such as this callback(error,value2,...), Note this The first parameter of callback must indicate whether there is an error. Specifically, you can here For more detailed usage.
Asynchronous Loader
When developing loader, in most cases, we can meet our requirements by using synchronous loader, but there are often some special cases. For example, we need to call some remote interfaces or timer operations inside the loader. At this point, the loader can wait for the asynchronous return to finish before proceeding to the next stage:
There are two ways to change a loader into an asynchronous loader:
Return Promise
We can change the loader into an asynchronous loader only by changing the return value of the loader to a Promise. The subsequent steps will wait until the returned Promise becomes resolve.
funciton asyncLoader() {
// dosomething
return Promise((resolve) => {
setTimeout(() => {
// The value of resolve is equivalent to the return value of synchronous loader
resolve('19Qingfeng')
},3000)
})
}Pass this async
Similarly, there is another method, which is also a commonly used asynchronous loader method. We call this inside the loader The async function changes the loader to asynchronous and this Async will return a callback. Only when we call the callback method will we continue to execute the subsequent stage processing.
function asyncLoader() {
const callback = this.async()
// dosomething
// Call callback to tell loader runner that the asynchronous loader ends
callback('19Qingfeng')
}Similarly, the pitch phase of the loader can also become an asynchronous loader through the above two schemes.
Detailed explanation of normal loader & pitch loader parameters
Normal Loader
normal loader accepts a parameter by default, which is the file content to be processed. When there are multiple loaders, its parameters will be affected by the previous loader.
At the same time, there is a return value in nomral loader. This return value will be called to the next loader in a chain as an input parameter. When the last loader is processed, this return value will be returned to webpack for compilation.
// Source is the content of the source file to be processed
function loader(source) {
// ...
// At the same time, the content after this processing is returned
return source + 'hello !'
}As for normal loader, there are actually many attributes attached to this in the function. For example, when we use a loader, we usually pass some parameters externally. At this time, we can use this inside the function Getoptions() method.
this in the loader is called a context object, More attributes you can see here

Pitch Loader
// normal loader
function loader(source) {
// ...
return source
}
// pitch loader
loader.pitch = function (remainingRequest,previousRequest,data) {
// ...
}The Pitch stage of Loader is also a function, which accepts three parameters, namely:
- remainingRequest
- previousRequest
- data
remainingRequest
remainingRequest indicates the absolute path of the remaining loader s to be processed! A string composed of segments.
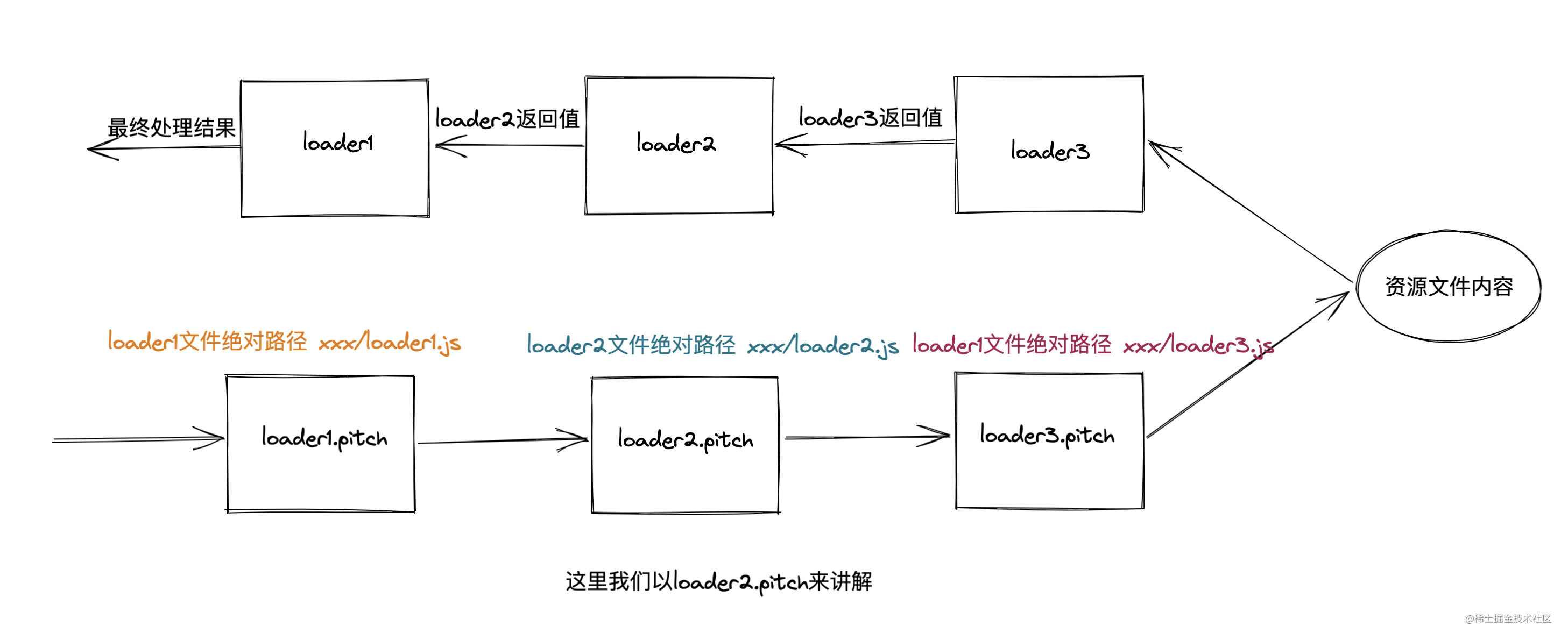
Similarly, we add a pitch attribute to each normal loader in the loader above. We use loader2 Take pitch as an example:
In loader The value of remainingRequest in the pitch function is XXX / loader3 JS. If there are multiple loaders in the follow-up, they will! Split.
It should be noted that the remainingRequest has nothing to do with whether the remaining loaders have the pitch attribute. Whether the pitch attribute exists or not, the remainingRequest will calculate the remaining loaders that have not been processed in the pitch stage.
previousRequest
After understanding the concept of remainingRequest, the second parameter of pitch loader is well understood.
It indicates that the loader that has been iterated in the pitch phase is in accordance with the! A string composed of segments.
Note also that previousRequest has nothing to do with the presence or absence of the pitch attribute. At the same time, both remainingRequest and previousRequest do not include themselves (that is, neither of our examples contains the absolute path of loader2 itself).
data
Now let's take a look at the last parameter of the pitch loader. This parameter defaults to an empty object {}.
The third data parameter is used in the interaction between normalLoader and pitch Loader.
Similarly, let's take loader2 in the above figure as an example:
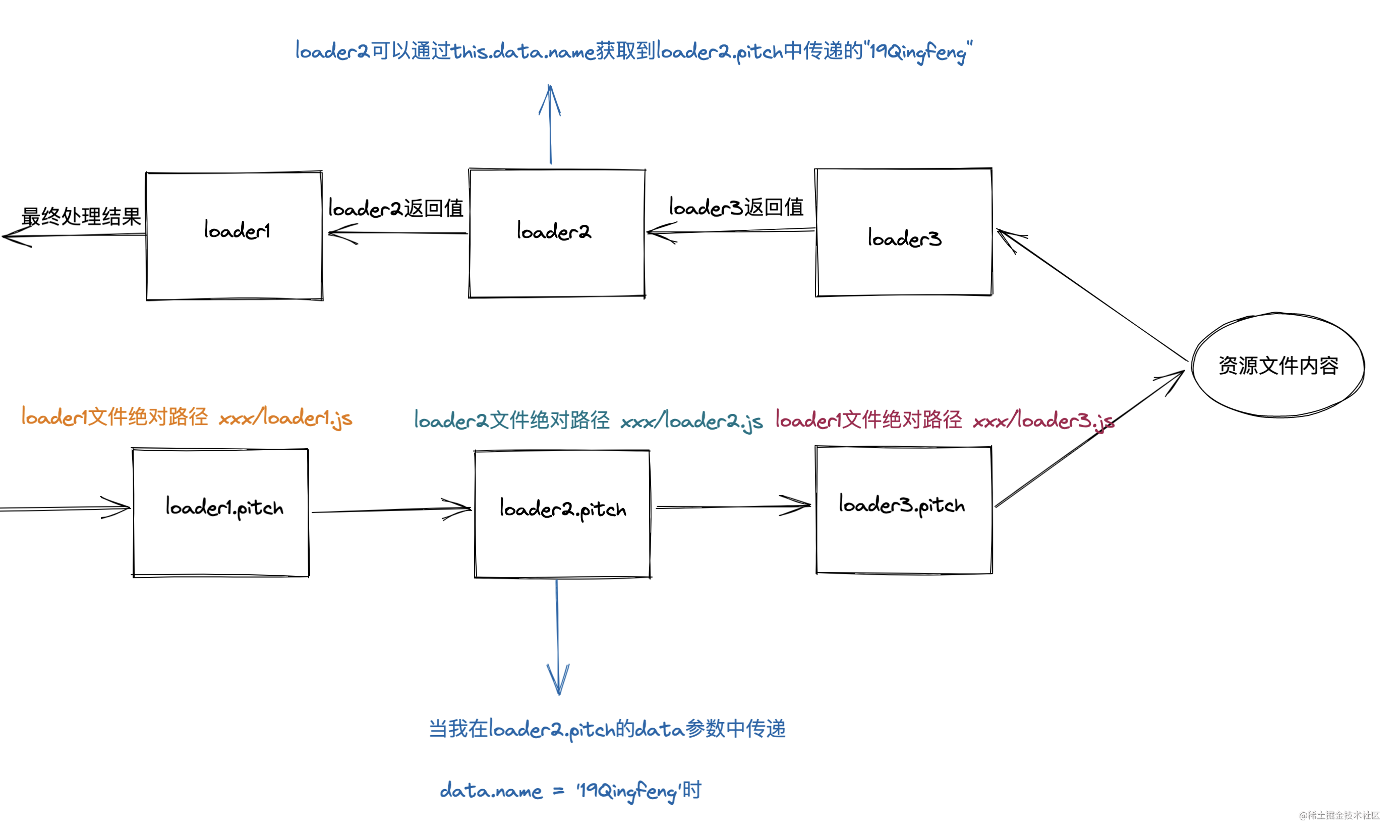
- When we are in loader2 In the pith function, when assigning values to the attributes on the data object, such as data name="19Qingfeng".
- In this case, you can use this. In the loader2 function data. Name gets the 19Qingfeng passed in its own pitch method.
raw attribute of loader
It is worth mentioning that when we develop some loaders, the parameters of normal Loader, as we mentioned, will accept the contents of the corresponding resource file of the pre normal loader or (when it is the first loader and has not been processed by any loader). This content defaults to a string of type string.
However, when we develop some special loader s, such as when we need to deal with image resources, it is obviously unreasonable to turn the image into a string for the image. For image operations, we usually need to read the Buffer type of image resources rather than the string type.
At this point, we can use loader The parameter of raw flag normal loader is Buffer or String:
- When loader When raw is false, the source of normal loader gets a String type, which is also the default behavior.
- When loader When raw is true, the source parameter accepted by the normal function of the loader is a Buffer type.
function loader2(source) {
// At this time, the source is a Buffer type instead of the string type of the model
}
loader2.raw = true
module.exports = loader2Return value of normal loader & pitch loader
In fact, we have talked about the return values of Normal Loader and Pitch Loader in detail.
- In the Normal phase, the return value of the loader function will be passed layer by layer in the loader chain until the last loader is processed, and then the return value will be passed to the webpack.
- In the pitch stage, if the pitch function of any loader returns any value that is not undefined, the fuse effect will occur, and the return value of the pitch will be passed to the function of the loader in the normal stage.
It should be noted that the last loader in the normal phase must return a js code (the code of a module, such as the module.exports statement).
As for the fusing effect, I believe you will understand it if you carefully see it here. If you still have questions about fusing, I strongly suggest you take a look at the two pictures on fusing above.
Loader source code analysis
In the above, we explained the basic contents and concepts of loader in detail. After mastering the above contents, I believe you can handle most loader scenarios in daily business.
However, as a qualified front-end engineer, the use of any tool must be unqualified if it only stays at the convenience of application.
Next, let's start from the source code and master how to implement loader in webpack step by step, so as to have a deeper understanding of the core content of loader and the design philosophy of loader!
Written before source code analysis
The loader mechanism in webpack is independent and becomes a loader runner JS, so it is clear that there is no too much coupling between the logic processed by the loader and the webpack.
First of all, source code analysis is boring for most people. Here I will try to simplify the steps and take you hand-in-hand to implement a loader runner library.
As like as two peas, I want to emphasize a source process rather than a real source. The advantage of this is that it simplifies the processing of many boundary conditions, and can take you to master the design philosophy behind the loader more quickly and conveniently.
However, it does not mean that the loader runner we implemented is not the source code. We will analyze it on the basis of the source code, omit its redundant steps, and put forward my own optimization points for some writing methods in the source code.
(after all, it's the easy to understand version I got from debugger 😼)
preparation in advance
Before entering the loader runner analysis, let's take a look at where the module call is entered in the webpack
When the module is compiled through the compilation object in webpack, the result will be obtained by matching the loader processing file first, and then it will be output to webpack for compilation.
In short, before each module is compiled by webpack, it will first find the corresponding loader according to the corresponding file suffix, and call the loader to process the resource file first, so as to submit the processed results to webpack for compilation.
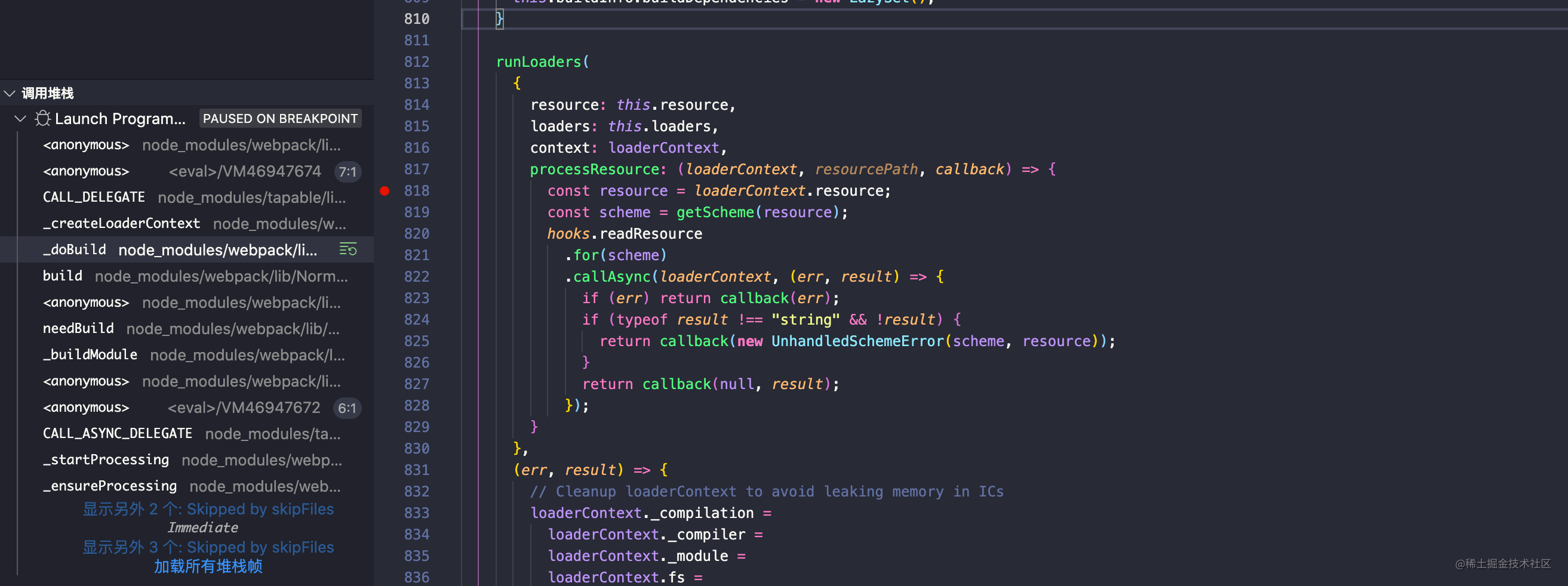
In webpack_ The runLoaders method is called in the doBuild function, and the runLoaders method comes from the loader-runner library.
In short, webpack will be called when the module is compiled_ doBuild: call the loader processing module by calling the runLoaders method inside the doBuild method.
runLoader parameter
Before actually entering the runLoader method, let's take a look at the four parameters passed in by the runLoader method.
Here, in order to understand loader more simply, we take out these four parameters alone and will not try to decouple them from the compilation process of webpack.
- Resource: the resource parameter indicates the path of the resource to be loaded.
- loaders: indicates that the absolute path of the loader to be processed is spliced into a string, with! division.
- context: loader context object. webpack will create a series of attributes before entering the loader, mount them on an object, and then pass them to the loader.
For example, we talked about this The getOptions () method obtains the configuration options parameter of the loader, that is, before entering the runLoader function, the webpack defines the getOptions method in the loaderContext object and passes it to the context parameter.
Here you can understand that this parameter is the context object of the loader. In short, we use this in the loader function. In order to better understand the loader runner, we will not involve the processing of the context object by webpack.
- processResource: method to read the resource file.
Similarly, processResource in the source code involves a lot of logic related to plugin hooks. Here you can simply understand it as a FS Just use the readfile method. In essence, the core of this parameter is to read our resource file according to the path through the processResource method.
Construction scene
The so-called sharpening knife does not pay for firewood cutting. After understanding the webpack source code and passing the four parameters when calling the loader function, let's simulate these four parameters.
Directory construction
First, let's create a folder named loader runner. Secondly, under loader runner, we create a folder named loader runner / loaders and a folder named loader runner / index js two files store our loader and the corresponding simulation entry file respectively: at the same time, let's create a title under loader runner js, which stores the contents of js files that need to be compiled by loader:
// title.js
require('inline1-loader!inline2-loader!./title.js');At this point, we should have such a directory:
Create Loader
Next, let's add some loaders to loader runner / loaders. Here I create eight loaders for loader runner / loaders:
Their content is very simple and similar. For example, in inline1 loader:
// There are corresponding normal loader and pitch loader in each loader file
// Print a file name in normal loader: normal and the corresponding accepted parameters
// Print a file name in the pitch loader
function loader(source) {
console.log('inline1: normal', source);
return source + '//inline1';
}
loader.pitch = function () {
console.log('inline1 pitch');
};
module.exports = loader;Similarly, in POST1 loader:
function loader(source) {
console.log('post1: normal', source);
return source + '//post1';
}
loader.pitch = function () {
console.log('post2 pitch');
};
module.exports = loader;The specific contents of the remaining documents are the same. Please create them yourself ~
I strongly suggest that you follow the article step by step.
At this point, we have created the eight loader s we need to use.
Create entry file
As mentioned above, in the webpack source code, it is called during compilation through compilation_ The doBild method creates parameters and calls the runLoaders method.
Here, in order to decouple the webpack construction process as much as possible, we first build the parameters required by the runLoaders function.
// loader-runner/index.js
// Entry file
const fs = require('fs');
const path = require('path');
const { runLoaders } = require('loader-runner');
// Module path
const filePath = path.resolve(__dirname, './title.js');
// Contents and of simulation module title.js as like as two peas.
const request = 'inline1-loader!inline2-loader!./title.js';
// Simulate webpack configuration
const rules = [
// Ordinary loader
{
test: /\.js$/,
use: ['normal1-loader', 'normal2-loader'],
},
// Front loader
{
test: /\.js$/,
use: ['pre1-loader', 'pre2-loader'],
enforce: 'pre',
},
// Post loader
{
test: /\.js$/,
use: ['post1-loader', 'post2-loader'],
},
];
// Extract the inline loader from the file import path, and transfer -! Delete the rules such as the inline loader flag
const parts = request.replace(/^-?!+/, '').split('!');
// Get file path
const sourcePath = parts.pop();
// Get inlineLoader
const inlineLoaders = parts;
// Handling loader rules in rules
const preLoaders = [],
normalLoaders = [],
postLoaders = [];
rules.forEach((rule) => {
// If there is a match
if (rule.test.test(sourcePath)) {
switch (rule.enforce) {
case 'pre':
preLoaders.push(...rule.use);
break;
case 'post':
postLoaders.push(...rule.use);
break;
default:
normalLoaders.push(...rule.use);
break;
}
}
});
/**
* Filter the required loader s according to the rules of inlineLoader
* https://webpack.js.org/concepts/loaders/
* !: Single! At the beginning, exclude all normal loaders
* !!: Two!! Only inline loader remains at the beginning, excluding all (pre,normal,post)
* -!: -!At the beginning, all pre and normal loaders will be disabled, and the rest of post and normal loaders will be disabled
*/
let loaders = [];
if (request.startsWith('!!')) {
loaders.push(...inlineLoaders);
} else if (request.startsWith('-!')) {
loaders.push(...postLoaders, ...inlineLoaders);
} else if (request.startsWith('!')) {
loaders.push(...postLoaders, ...inlineLoaders, ...preLoaders);
} else {
loaders.push(
...[...postLoaders, ...inlineLoaders, ...normalLoaders, ...preLoaders]
);
}
// Convert the loader to the file path where the loader is located
// By default, the path of the resolveLoader in the configuration is resolved in the webpack. Here, we omit the path resolution in the webpack for simulation
const resolveLoader = (loader) => path.resolve(__dirname, './loaders', loader);
// Get the loaders path that needs to be processed
loaders = loaders.map(resolveLoader);
runLoaders(
{
resource: filePath, // Loaded module path
loaders, // loader array to be processed
context: { name: '19Qingfeng' }, // Context object passed
readResource: fs.readFile.bind(fs), // Method of reading file
// The processResource parameter is ignored first
},
(error, result) => {
console.log(error, 'Existing error');
console.log(result, 'result');
}
);Here we use loader runner / index JS to simulate the parameters passed to runLoader in loader runner during webpack compilation.
Here are a few points to note:
- filePath is title JS module path, in other words, we handle this title through loader JS file.
- Request is our simulated title JS, which is actually the same as title JS file content is as like as two peas. Here we are going to directly simulate title.'s webpack processing rules to facilitate loader simulation. JS file content is placed in the request string.
- Here, the attributes corresponding to the first parameter in runLoaders are:
- resource indicates the path of the module that needs to be compiled by the loader.
- Loaders indicates which loaders are needed for this loader processing. (it is an array of all loader file paths that need to be processed)
- Context refers to the context object of the loader. In the real source code, webpack will perform additional processing on this object before entering the runLoaders method. We don't do too much here. It is the this context in the loader.
- The parameter readResource indicates that the runLoaders method will use the parameter we passed in to read the file path that the resource needs to load to get the file content.
- The second parameter of the runLoaders function passes in a callback, indicating the result of this loader processing.
The order of the loaders parameters passed in here is intentional. It is processed according to the execution order of the pitch stage: Post - > inline - > normal - > pre.
Here we call the original loader-runner processing in the above code. Let's look at the original results first.

We can see that in the original loader runner, the second parameter called back passed in by runLoaders will get two parameters after processing.
- Error: if an error is encountered during the execution of the runLoaders function, this parameter will become the error content, otherwise it will be null.
- Result: if the runLoaders function is executed without any errors, the result will have the following properties:
- result: it is an array used to represent the contents of the file after being processed by all loaders this time.
- resourceBuffer: it is a Buffer content, which represents the result of converting the original content of our resource file into Buffer.
- Other parameters are related to the parameters during the construction and caching of webpack. We can not concern these parameters here.
Process combing
After knowing the parameters accepted by the original runLoaders method and the returned results, let's implement our own runLoaders method.
First, let's start by creating a directory step by step!
Here, we create a core / index. In the loader runner directory JS as the loader runner module we will implement.
After creating the directory, let's review this figure:
What I want to emphasize here is that the core logic of the whole runLoaders function is to accept the path of the resource file to be processed. According to the incoming Loaders, first read the content of the resource file through the pitch stage, then process the content of the resource file through the normal stage, and finally get the return result.
Grasp such a core execution process and deal with the remaining boundary conditions. I believe it is a letter case for everyone!
Next, let's formally enter the implementation of the runLoaders method.
Enter the source code
Create loaders object
// loader-runner
const fs = require('fs')
function runLoaders(options, callback) {
// Absolute path of resource to be processed
const resource = options.resource || ''
// The absolute path array composed of all loaders to be processed
let loaders = options.loaders || []
// Loader execution context object. This in each loader will point to this loaderContext
const context = options.context || {}
// Method of reading resource content
const readResource = options.readResource || fs.readFile.bind(fs);
// Create loaders object from loaders path array
loaders = loaders.map(createLoaderObject);
}First, in the first step, we saved the parameters in the externally passed in options in the runLoaders function. Careful students may have found that we map the passed in loaders through the createLoaderObject method.
The createLoaderObject method is very simple. In fact, it modifies each path in the original loaders path array into an object. Let's implement this method:
/**
*
* Create a loader object from the absolute path address of the loader
* @param {*} loader loader Absolute path address of
*/
function createLoaderObject(loader) {
const obj = {
normal: null, // loader normal function itself
pitch: null, // loader pitch function
raw: null, // Indicates whether the normal loader needs to convert the content into a buffer object when processing the file content
// In the pitch phase, assign a value to data and in the normal phase, this The data value is used to save the passed data
data: null,
pitchExecuted: false, // The pitch function of this loader has been executed when it is marked
normalExecuted: false, // Indicates whether the normal phase of the loader has been executed
request: loader, // Save the absolute path of the current loader resource
};
// Load the loader module according to the path. In the real source code, loading through loadLoader also supports ESM module. We only support CJS syntax here
const normalLoader = require(obj.request);
// assignment
obj.normal = normalLoader;
obj.pitch = normalLoader.pitch;
// Buffer / string is required during conversion. When raw is true, it is buffer. When false, it is string
obj.raw = normalLoader.raw;
return obj;
}Here, we use createLoaderObject to convert the absolute path address of the loader into the loader object, and assign some core attributes such as normal, pitch, raw, data, etc.
Assign loaderContext and process the context object
After converting the path into a loader object through the createLoaderObject function, let's go back to the runLoaders function and deal with the context object loaderContext in the loader:
function runLoaders(options, callback) {
// Absolute path of resource to be processed
const resource = options.resource || '';
// The absolute path array composed of all loaders to be processed
let loaders = options.loaders || [];
// Loader execution context object. This in each loader will point to this loaderContext
const loaderContext = options.context || {};
// Method of reading resource content
const readResource = options.readResource || fs.readFile.bind(fs);
// Create loaders object from loaders path array
loader = loader.map(createLoaderObject);
// Handle the loaderContext, that is, the this object in the loader
loaderContext.resourcePath = resource; // Resource path absolute address
loaderContext.readResource = readResource; // Method of reading resource file
loaderContext.loaderIndex = 0; // We execute the corresponding loader through loaderIndex
loaderContext.loaders = loaders; // All loader objects
loaderContext.data = null;
// Object properties that mark asynchronous loader s
loaderContext.async = null;
loaderContext.callback = null;
// request saves all loader paths and resource paths
// Here we convert it all into the form of inline loader (string concatenated "!" Split form)
// Note that the resource path is spliced at the end
Object.defineProperty(loaderContext, 'request', {
enumerable: true,
get: function () {
return loaderContext.loaders
.map((l) => l.request)
.concat(loaderContext.resourcePath || '')
.join('!');
},
});
// Save the remaining requests without containing their own resource paths (delimited by LoaderIndex)
Object.defineProperty(loaderContext, 'remainingRequest', {
enumerable: true,
get: function () {
return loaderContext.loaders
.slice(loaderContext + 1)
.map((i) => i.request)
.concat(loaderContext.resourcePath)
.join('!');
},
});
// Save the remaining requests, including themselves and resource paths
Object.defineProperty(loaderContext, 'currentRequest', {
enumerable: true,
get: function () {
return loaderContext.loaders
.slice(loaderContext)
.map((l) => l.request)
.concat(loaderContext.resourcePath)
.join('!');
},
});
// The processed loader request does not contain its own resource path
Object.defineProperty(loaderContext, 'previousRequest', {
enumerable: true,
get: function () {
return loaderContext.loaders
.slice(0, loaderContext.index)
.map((l) => l.request)
.join('!');
},
});
// The third parameter in the pitch method can be modified through this in normal Data can obtain the data operated by the pitch method of the corresponding loader
Object.defineProperty(loaderContext, 'data', {
enumerable: true,
get: function () {
return loaderContext.loaders[loaderContext.loaderIndex].data;
},
});
}Here, we define a series of attributes on the loaderIndex context object. For example, we use loaderIndex to control the number of loaders in the current loaders list, as well as the current data, async, callback and other attributes.
In fact, I believe you have a sense of deja vu about these parameter attributes. As we mentioned earlier, we flexibly configure the loader through this context object in the loader. The loaderContext we define here is exactly this object.
As for the meaning of these parameters of the context object, we have roughly talked about the usage and meaning of the corresponding API in the loader development stage above. If you forget, you can go back and review it again.
Here, we only define these attributes. At the same time, I hope that when seeing the current definition of attributes, students can think of the corresponding usage of each API.
After defining the loaderContext attribute, let's go back to the runLoaders method again:
function runLoaders(options, callback) {
...
// It is used to store the binary content of the read resource file (the content of the original file before conversion)
const processOptions = {
resourceBuffer: null,
};
// After processing the loaders object and loaderContext context object
// According to the process, we need to start iterating loaders -- starting from the pitch phase
// Iterate the pitch in the order of post inline normal pre
iteratePitchingLoaders(processOptions, loaderContext, (err, result) => {
callback(err, {
result,
resourceBuffer: processOptions.resourceBuffer,
});
});
}Let's review the print value of result in the callback method passed in by runLoaders:
The resourceBuffer in processOptions defined here is exactly the resourceBuffer in result: the Buffer object of the original (not processed by the loader) resource file content.
iteratePitchingLoaders
After creating the loader object and assigning the loaderContext attribute, follow the previous flowchart. We need to enter the pitch execution phase of each loader.
Above, we defined the iteratePitchingLoaders function and passed in three parameters:
- processOptions: the object defined above has a resourceBuffer attribute, which is used to save the contents of the Buffer type resource file before being processed by the loader.
- loaderContext: loader context object.
- The callback: method internally calls the callback imported from the runLoaders method to invoke the result of the final runLoaders method in the callback function.
After knowing the parameters passed in, let's take a look at the implementation of iteratePitchingLoaders.
/**
* Iterative pitch loaders
* Core idea: execute the pitch of the first loader and iterate successively. If the last one ends, start reading the file
* @param {*} options processOptions object
* @param {*} loaderContext loader this object in
* @param {*} callback runLoaders callback function in
*/
function iteratePitchingLoaders(options, loaderContext, callback) {
// Exceeding the number of loader s means that all pitch es have ended. At this time, you need to start reading the contents of the resource file
if (loaderContext.loaderIndex >= loaderContext.loaders.length) {
return processResource(options, loaderContext, callback);
}
const currentLoaderObject = loaderContext.loaders[loaderContext.loaderIndex];
// The current loader's pitch has been executed. Continue to recursively execute the next one
if (currentLoaderObject.pitchExecuted) {
loaderContext.loaderIndex++;
return iteratePitchingLoaders(options, loaderContext, callback);
}
const pitchFunction = currentLoaderObject.pitch;
// Mark that the current loader pitch has been executed
currentLoaderObject.pitchExecuted = true;
// If the current loader does not have a pitch phase
if (!currentLoaderObject.pitch) {
return iteratePitchingLoaders(options, loaderContext, callback);
}
// There is a pitch stage and the current pitch loader has not executed the pitch function calling the loader
runSyncOrAsync(
pitchFunction,
loaderContext,
[
currentLoaderObject.remainingRequest,
currentLoaderObject.previousRequest,
currentLoaderObject.data,
],
function (err, ...args) {
if (err) {
// There is an error. Calling callback directly indicates that runLoaders has completed execution
return callback(err);
}
// Judge whether to continue to execute the next pitch acc or ding to the return value
// The return value of the pitch function exists - > fuse and turn around to execute normal loader
// The return value of the pitch function does not exist - > continue to iterate over the next iteratePitchLoader
const hasArg = args.some((i) => i !== undefined);
if (hasArg) {
loaderContext.loaderIndex--;
// You can directly return to call normal loader
iterateNormalLoaders(options, loaderContext, args, callback);
} else {
// After the execution of this pitch loader, continue to call the next loader
iteratePitchingLoaders(options, loaderContext, callback);
}
}
);
}Let me show you a little bit about the iteratePitchingLoaders method. It does very simple things, * * essentially through loadercontext Loaderindex to recursively iterate the pitch method of each loader object.
Here are some tips:
- After reading the contents of the resource file in the process diagram above, we need to follow the process method of the resource file.
- The runSyncOrAsync method is a method to call the loader function. There are two ways to execute the loader: synchronous / asynchronous. Here is the unified processing through this method.
- The iteratenormallloaders method is a method that iterates over the normal loader.
You don't need to care about the implementation details of the above three methods. You just need to know the process of iteratePitchingLoaders.
- It should be noted that the order of loaders we pass in the simulation entry file is [... post,...inline,...normal,...pre]. So internally, we use loadercontext Loaderindex iterates from subscript 0, just in line with the pitch stage.
runSyncOrAsync
After understanding how iteratePitchingLoaders iterate over the pitch loader, let's take a look at the method runSyncOrAsync:
/**
*
* Execute loader synchronous / asynchronous
* @param {*} fn Functions to be executed
* @param {*} context loader Context object for
* @param {*} args [remainingRequest,previousRequest,currentLoaderObj.data = {}]
* @param {*} callback External incoming callback (formal parameter of runloaders method)
*/
function runSyncOrAsync(fn, context, args, callback) {
// Whether to synchronize the default synchronization loader indicates that the current loader will automatically execute iteratively after execution
let isSync = true;
// Indicates whether the incoming fn has been executed, which is used to mark repeated execution
let isDone = false;
// Define this callback
// At the same time, this Async calls innerCallback through closure access to indicate that the asynchronous loader has completed execution
const innerCallback = (context.callback = function () {
isDone = true;
// When calling this The return of the loader function cannot be marked during callback
isSync = false;
callback(null, ...arguments);
});
// Define asynchronous this async
// Each loader call will execute runSyncOrAsync and redefine a context Async method
context.async = function () {
isSync = false; // Change this synchronization to asynchronous
return innerCallback;
};
// Call pitch loader to pass this as loaderContext and pass three parameters at the same time
// Return the return value of the pitch function to determine whether to fuse
const result = fn.apply(context, args);
if (isSync) {
isDone = true;
if (result === undefined) {
return callback();
}
// If the loader returns a Promise asynchronous loader
if (
result &&
typeof result === 'object' &&
typeof result.then === 'function'
) {
// Similarly, wait for the fuse to blow directly after the Promise is completed, otherwise Reject will directly call back an error
return result.then((r) => callback(null, r), callback);
}
// The non Promise switch is fused according to the execution result
return callback(null, result);
}
}runSyncOrAsync accepts four parameters:
- fn function to be called
- context this pointer inside fn function called
- args is the parameter passed in by fn of the called function
- Callback is used to denote callback function called after loader(fn) is executed.
Its implementation is very simple. The content realizes asynchronous this through closures and isSync variables async/this. Callback is the implementation of the two loader API s.
Finally, after the loader is executed, the runSyncOrAsync method will pass the return value of the loader after execution to the second parameter of the callback function.
runSyncOrAsync is implemented. After understanding how to execute the loader, let's go back and analyze the runSyncOrAsync method in iteratePitchingLoaders.
In the iteratePitchingLoaders function, we execute the corresponding pitch loader through runSyncOrAsync, and pass in these four parameters respectively:
- pitchFunction is used as fn to be executed.
- loaderContext represents this context object in the pitch loader function.
- [currentLoaderObject.remainingRequest,currentLoaderObject.previousRequest,currentLoaderObject.data]. As mentioned above, the pitch loader function will accept three parameters: the remaining laoder requests, the processed loader requests and the data passed to the normal stage.
- The fourth parameter is a callback function, which means that this callback will be called after the execution of the pitch loader function. If the pitch loader has a return value, its second parameter will receive the return value after the execution of the pitch loader.
Here I want to highlight the fourth callback functions introduced in iteratePitchingLoaders when runSyncOrAsync is executing loader.
runSyncOrAsync(
pitchFunction,
loaderContext,
[
currentLoaderObject.remainingRequest,
currentLoaderObject.previousRequest,
currentLoaderObject.data,
],
function (err, ...args) {
if (err) {
// There is an error. Calling callback directly indicates that runLoaders has completed execution
return callback(err);
}
// Judge whether to continue to execute the next pitch acc or ding to the return value
// The return value of the pitch function exists - > fuse and turn around to execute normal loader
// The return value of the pitch function does not exist - > continue to iterate over the next iteratePitchLoader
const hasArg = args.some((i) => i !== undefined);
if (hasArg) {
loaderContext.loaderIndex--;
// You can directly return to call normal loader
iterateNormalLoaders(options, loaderContext, args, callback);
} else {
// After the execution of this pitch loader, continue to call the next loader
iteratePitchingLoaders(options, loaderContext, callback);
}
}
);As mentioned above, the fourth parameter will be called after the execution of the pitch loader function or after an error is reported.
If there is an error, call the callback(err) passed in by runLoaders directly.
If there is no error, here we judge the remaining parameters except the first parameter indicating the error. We know that this parameter represents the return value after the loader is executed. Let's review the flow chart of the pitch stage again:
If the pitch phase of any loader returns any value that is not undefined, the loader will have the effect of fusing: immediately turn around and execute the normal loader and pass the return value of the pitch phase to the normal loader.
So here we judge from the callback that if there is any non defined return value in args. Then the loadercontext The loaderindex decrements to start the iteration of normal loader.
If the return value does not exist or undefind is returned after the operation of the pitch loader, the next pitch loader will continue to be called recursively at this time.
For the general process of pitch loader, we'll come to an end here. If you have any questions, you can review them or discuss them in the comment area. In fact, after mastering the loader execution process, I believe it is not difficult for you to understand the code logic alone, which is why I will spend a lot of time talking about the basic usage of loader.
processResource
After the iteratePitchingLoaders are finished, the iteration completes all the pitch loader s. What's next?
If you forget, you should look through the execution flow chart of the loader. At this time, you should read the content of the resource file, that is, the processResource method we haven't completed above.
What this method does is very simple:
- Read the contents of the file according to the incoming method, and save the contents of the Buffer type of the obtained file into processoptions In resourcebuffer.
- After getting the file content, transfer the file content to normal loader, and then execute iteratenormallloaders iteration to execute normal loader.
/**
*
* Read file method
* @param {*} options
* @param {*} loaderContext
* @param {*} callback
*/
function processResource(options, loaderContext, callback) {
// Reset out of bounds loadercontext loaderIndex
// Flashback execution pre - > normal - > inline - > post
loaderContext.loaderIndex = loaderContext.loaders.length - 1;
const resource = loaderContext.resourcePath;
// Read file contents
loaderContext.readResource(resource, (err, buffer) => {
if (err) {
return callback(err);
}
// The buffer that saves the contents of the original file is equivalent to processoptions resourceBuffer = buffer
options.resourceBuffer = buffer;
// At the same time, pass the read file contents into iteratenormallloaders for iteration ` normal loader`
iterateNormalLoaders(options, loaderContext, [buffer], callback);
});
}Its code is actually easy to understand. Here are three points to pay attention to:
- loaderIndex will enter the processResource method only when it exceeds the limit in the iterative pitch loader (that is, it is equal to loaderContext.loaders.length), so we will use loadercontext loaderIndex * * reset to loadercontext loaders. lenth -1**.
- Iteratenormallloaders additionally passes in an array representing the contents of the resource file [buffer], which is deliberately done. Here I buy a pass first, and later you will find out why I do this.
- Remember we were in loadercontext The order of loaders saved in loaders is saved in the order of post - > inline - > normal - > pre, so at this time, as long as we iterate in the reverse order of loaderIndex, we can get the order of normal loader s.
iterateNormalLoaders
After reading the contents of the file by processResource, the iteratenormallloaders - the function of iterative normal loader, which we use in processResource and iteratePitchingLoaders methods, has not been implemented.
Next, let's take a look at the implementation of this function:
/**
* Iterative normal loaders iterates according to the value of loaderIndex
* Core idea: after the iteration completes the pitch loader, read the file and iterate to execute the normal loader
* Or if there is a return value in the pitch loader, execute normal loader
* @param {*} options processOptions object
* @param {*} loaderContext loader this object in
* @param {*} args [buffer/any]
* When there is no return value in the pitch phase, this is the resource file to be processed
* When there is a return value in the pitch phase, it is the return value of the pitch phase
* @param {*} callback runLoaders callback function in
*/
function iterateNormalLoaders(options, loaderContext, args, callback) {
// The out of bounds element determines that the out of bounds indicates that all normal loader s have finished processing and directly call callback to return
if (loaderContext.loaderIndex < 0) {
return callback(null, args);
}
const currentLoader = loaderContext.loaders[loaderContext.loaderIndex];
if (currentLoader.normalExecuted) {
loaderContext.loaderIndex--;
return iterateNormalLoaders(options, loaderContext, args, callback);
}
const normalFunction = currentLoader.normal;
// Mark as executed
currentLoader.normalExecuted = true;
// Check whether it has been carried out
if (!normalFunction) {
return iterateNormalLoaders(options, loaderContext, args, callback);
}
// Format the source according to the raw value in the loader
convertArgs(args, currentLoader.raw);
// Execute loader
runSyncOrAsync(normalFunction, loaderContext, args, (err, ...args) => {
if (err) {
return callback(err);
}
// Continue the iteration. Note that the args here is the processed args
iterateNormalLoaders(options, loaderContext, args, callback);
});
}In fact, carefully read the code of iteratenormallloaders, which is similar to iteratePitchingLoaders. Their core is based on loadercontext The loaderindex subscript iterates. The loaders object runs the corresponding pitch or normal functions respectively.
The only difference is that iteratePitchingLoaders only accepts three parameters, and iterateNormalLoaders accepts an args parameter to represent the [Buffer] of the resource file object (or the return value of the pitch loader in case of fuse). This is because the parameters when the pitch loader is called can be obtained through the loaderContext (remainingRequest attribute, etc.), while the parameters of the normal loader need to pass the processed content layer by layer.
At the same time, why do we process the file contents into an array [Buffer] above? It is precisely because the third parameter passed to the runSyncOrAsync method is an array (representing the parameter passed to the loader function when calling the loader function). Because it is called through apply, unified processing into an array will make the code more convenient and concise.
Careful students will find that there is a call to convertArgs function in iterateNormalLoaders. Let's take a look at the content of this function first:
/**
*
* Convert the format of resource source
* @param {*} args [Resources]
* @param {*} raw Boolean Whether Buffer is required
* raw true indicates that a Buffer is required
* raw false indicates that Buffer is not required
*/
function convertArgs(args, raw) {
if (!raw && Buffer.isBuffer(args[0])) {
// I don't need a buffer
args[0] = args[0].toString();
} else if (raw && typeof args[0] === 'string') {
// The Buffer resource file is required to be of string type, which is called Buffer
args[0] = Buffer.from(args[0], 'utf8');
}
}convertArgs method * * determines whether the loader needs to accept the content of the resource file in the normal phase is Buffer or String * * according to the raw attribute of the loader.
As we mentioned above, each loader has a raw attribute through loader Raw marks whether the parameter of normal loader is Buffer or String. This method converts the parameters before the normal loader is executed.
be accomplished
At this point, we have fully implemented the core logic of the runLoaders method in the loader runner.
Verify execution results
Let's now load runner / core / index JS, and in the simulation entry file loader runner / index JS is replaced by our own module:
// loader-runner/core/index.js
...
module.exports = {
runLoaders
}
// loader-runner/index.js
// Entry file
const fs = require('fs');
const path = require('path');
const { runLoaders } = require('./core/index');
...
runLoaders(
{
resource: filePath, // Loaded module path
loaders, // loader array to be processed
context: { name: '19Qingfeng' }, // Context object passed
readResource: fs.readFile.bind(fs), // Method of reading file
// The processResource parameter is ignored first
},
(error, result) => {
console.log(error, 'Existing error');
console.log(result, 'result');
}
);Next, let's execute our loader runner / index js:

In the result parameter object in the callback we printed out:
- The value of the result attribute is an array, and its first element is the file content processed by all our loader s.
- The value of resourceBuffer attribute is a Buffer. Its content is the content of the original resource file without conversion. Interested friends can have a look at toString().
At this stage, as like as two peas, the results of our normal phase are basically the same as those of the original runLoaders method.
Fuse effect verification
At this point, let's verify the fusing effect again.
First, let's modify loader runner / loaders / inline2 loader. We return a string in the pitch function of inline2 loader:
function loader(source) {
console.log('inline2: normal', source);
return source + '//inline2';
}
loader.pitch = function () {
console.log('inline2 pitch');
return '19Qingfeng';
};
module.exports = loader;Execute our loader runner / core / index. Again js:

As we expected ~ everything is normal!
So far, I have brought you all to realize the core source code of runLoaders.
I believe that the code itself is not difficult to understand. Reading the source code itself requires some patience. If you have any questions about the code or the original source code, you are welcome to harass me in the comment area
I sincerely thank every friend who sees here for learning the loader source code. I hope you can take this as a starting point and make more in-depth exploration in the follow-up and start to optimize the whole process system. (after all, to be honest, some parts of the runLoaders method are rough 🐶).
Full code address in the article You can see it here.
Enterprise Loader application
After refining the knowledge system of the source code, let's talk about some easier topics.
Next, let's implement an enterprise class loader application, and lead you to really master and master the ideas of loader developers in open source tools.
Babel loader process
Usual ~ first, let's sort out the process of developing Babel loader.
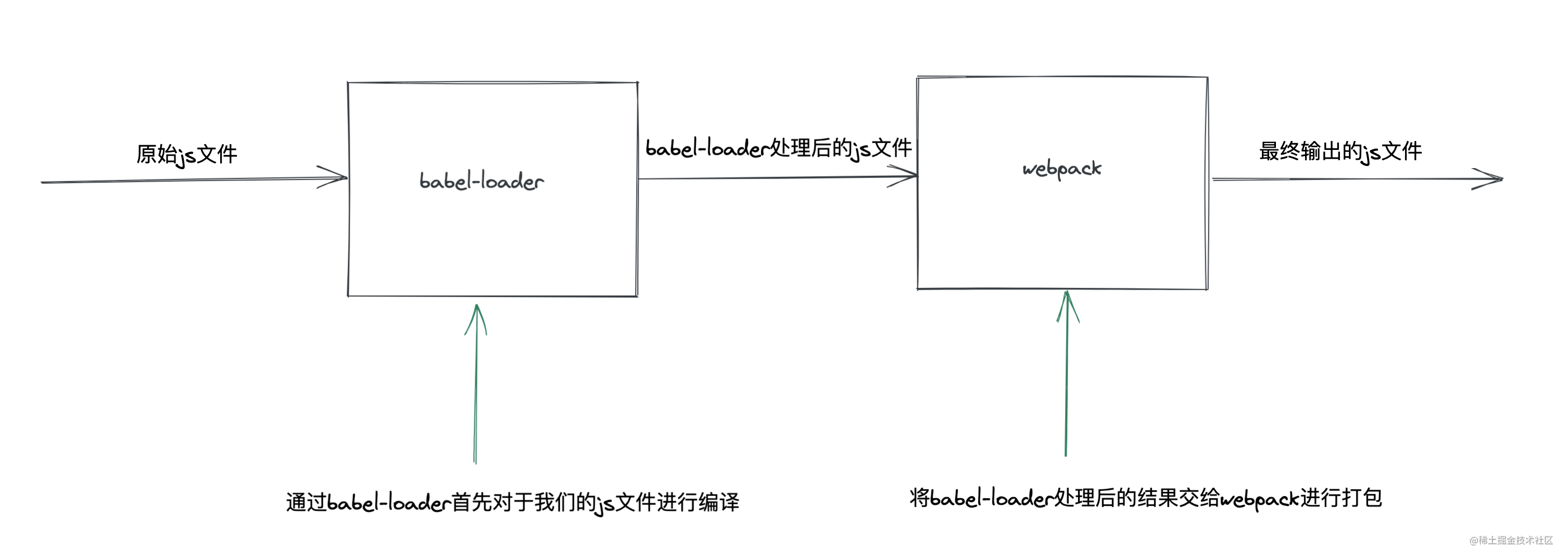
Let's sort it out according to this picture.
The function of the so-called Babel loader is particularly simple. In essence, it is to convert our js file through the Babel loader function and the corresponding parameters when configuring the loader. In short, this is the function that Babel loader needs to realize.
Of course, the content processed by Babel loader needs to be handed over to webapck for compilation.
Implementation of Babel loader
const core = require('@babel/core');
/**
*
* @param {*} source Source code content
*/
function babelLoader(source) {
// Get loader parameters
const options = this.getOptions() || {};
// Transform by transform method
const { code, map, ast } = core.transform(source, options);
// Call this Callback indicates that the loader has finished executing
// Pass multiple parameters to the next loader at the same time
this.callback(null, code, map, ast);
}
module.exports = babelLoader;It seems very simple. Here are some points to note:
- If you don't know about babel's api, you can check my previous articles, "Front end infrastructure" takes you to travel in Babel's world.
Here we pass the core Transform converts the source js code into ast, and processes the conversion of AST nodes through the options option passed externally, so as to convert the js code into the converted code according to the external incoming rules.
- This is where we pass The getoptions method obtains the parameters passed by the external loader.
When calling the runLoaders method, webpack has added the implementation of this getOptions in the loaderContext, so the processed loaderContext parameter is passed in when calling the runLoaders method.
This did not exist before webpack5 For the getoptions method, you need to obtain the external loader configuration parameters through the loader utils package.
The implementation of this method is very simple. In the source code, webpack / lib / normalmodule JS, interested friends can browse by themselves.
Next, let's verify it a little.
Verify Babel loader
First, let's rebuild a development directory webpack Babel folder:
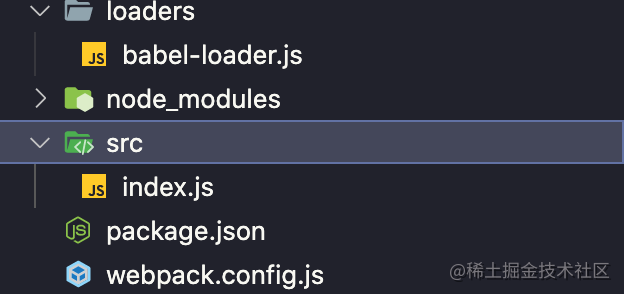
- The Babel loaders defined by ourselves are stored in the loaders / Babel loaders directory.
- src/index.js stores the entry file.
- webpack.config.js is the webpack configuration file.
// src/index.js
// Here we use the syntax of ES6
const arrowFunction = () => {
console.log('hello');
};
console.log(arrowFunction);// webpack.config.js
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
module.exports = {
entry: './src/index.js',
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].js',
},
devtool: 'eval-source-map',
resolveLoader: {
modules: [path.resolve(__dirname, './loaders')],
},
module: {
rules: [
{
test: /\.js/,
loader: 'babel-loader',
options: {
presets: ['@babel/preset-env'],
},
},
],
},
plugins: [new HtmlWebpackPlugin()],
};// package.json
{
...
// Here we define two scripts, one for dev in the development environment
// A package command for build
"scripts": {
"dev": "webpack serve --mode developmen",
"build": "webpack --config ./webpack.config.js"
},
}Don't forget to install the packages we need.
yarn add webpack webpack-cli @babel/core @babel/preset-env html-webpack-plugin webpack-dev-server
Next, let's run yarn build together and take a look at the js output after packaging:
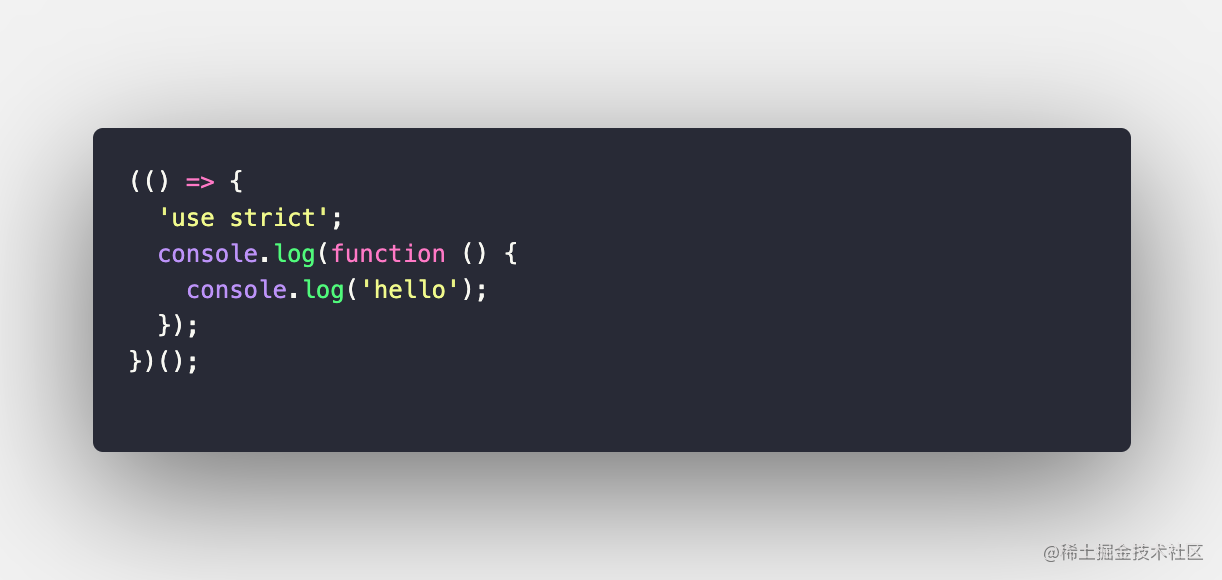
It can be seen that after yarn build, the original arrow function of the code packaged in the production environment has been transformed into an ordinary function. In other words, our customized Babel loader function has taken effect.
sourcemap perfect Babel loader
There are really no problems in the production environment, but what about the development environment. Here we try Src / index JS debugger:
// src/index.js
const arrowFunction = () => {
console.log('hello');
};
debugger;
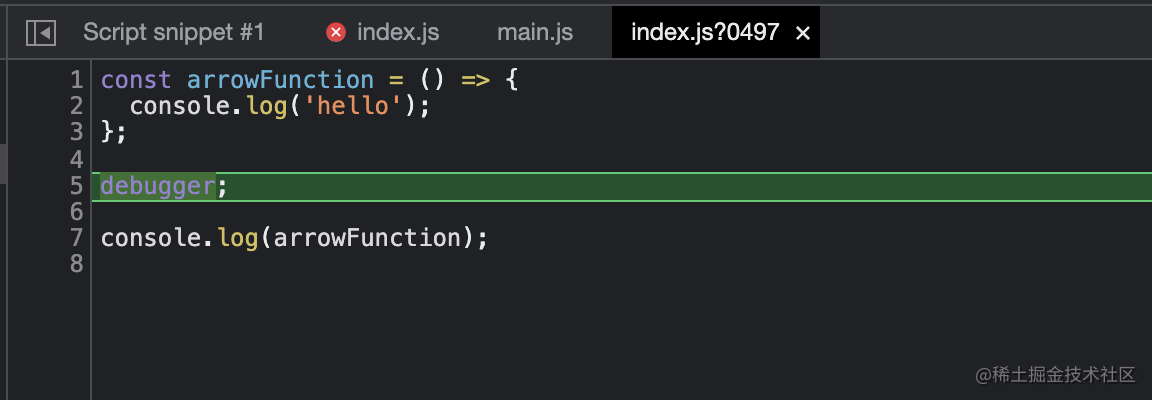
console.log(arrowFunction);At this point, we execute yarn dev, open the generated html page and enter the debugger:
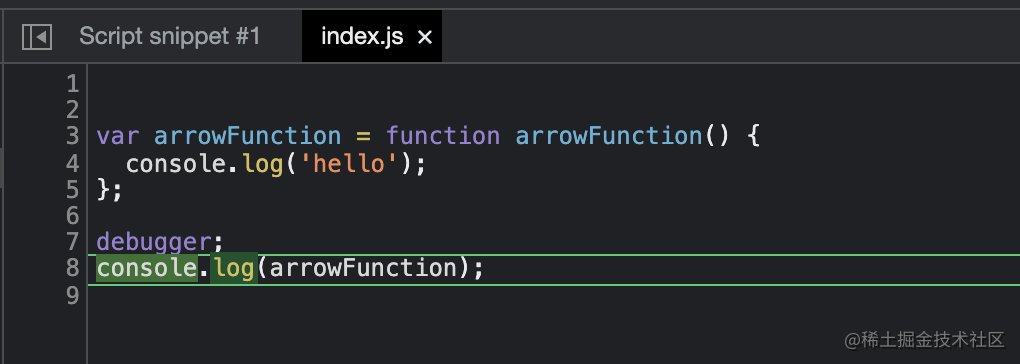
The code in debugger is not our real source code at this time, but the code translated by babel, which is undoubtedly a disaster for daily development. Here is our Src / index JS file content is very simple, only an arrow function. However, when the code in the project becomes more and more complex, this situation is undoubtedly a nightmare for us to debug the code.
In fact, the reason for this problem is very simple. In the Babel loader compilation stage, we do not carry any sourceMap mapping. In the webpack compilation stage, even if sourceMap mapping is enabled, only the compiled code of webpack can be mapped to the code before webpack processing in debugger, that is, it has been processed by Babel loader.
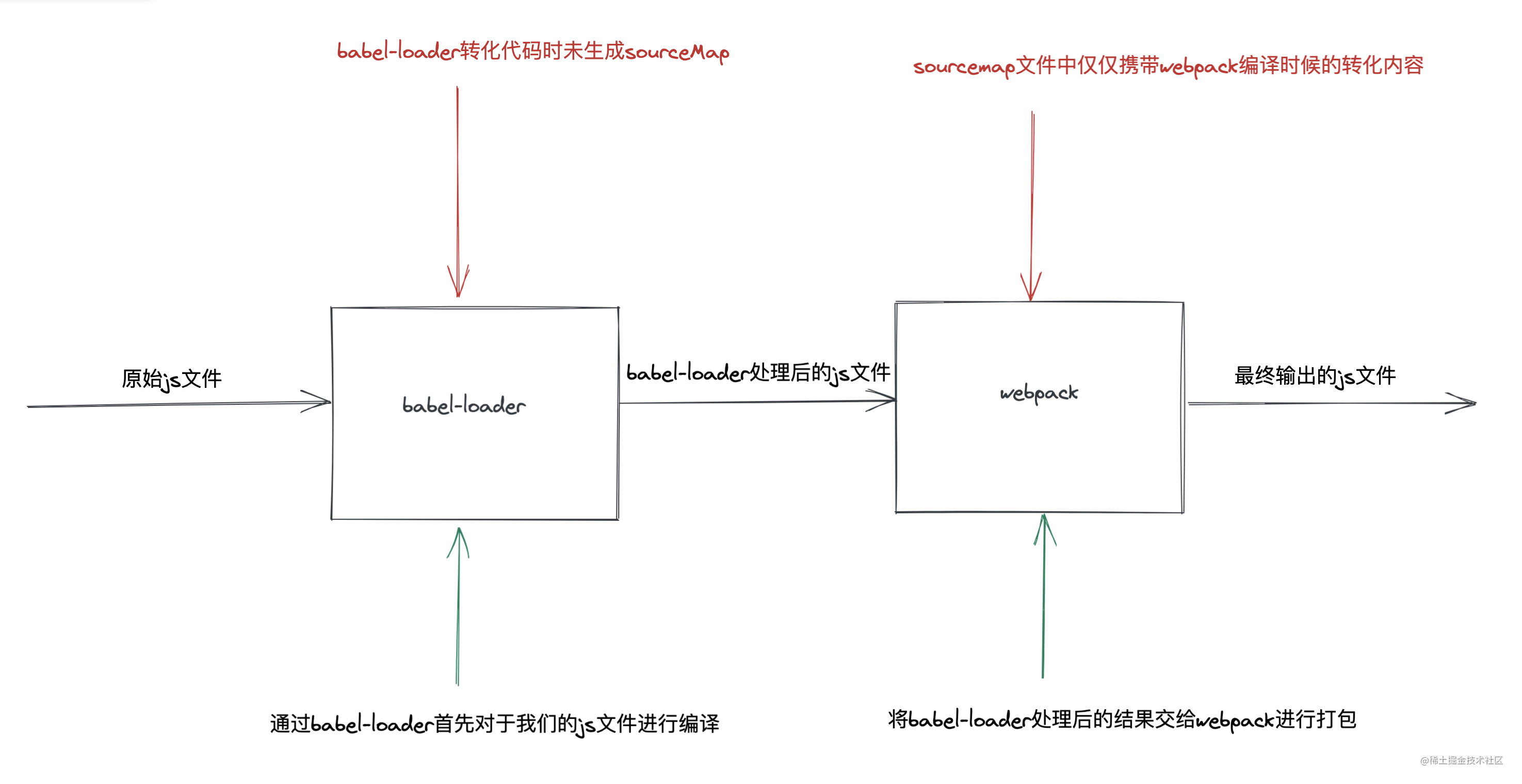
At this time, all we need to do is to add the corresponding sourcemap during the conversion of Babel loader and return it to the webpack compilation stage. When we carry the sourcemap generated by Babel loader, we can achieve the desired effect.
Let's do it:
const core = require('@babel/core');
/**
*
* @param {*} source Source code content
*/
function babelLoader(source, sourceMap, meta) {
// Get loader parameters
const options = this.getOptions() || {};
// Generate sourcemap for babel translation phase
options.sourceMaps = true;
// The sourceMap passed in by the loader before saving
options.inputSourceMap = sourceMap;
// Get the processed resource file name. When babel generates a sourcemap, you need to configure the filename
options.filename = this.request.split('!').pop().split('/').pop();
// Transform by transform method
const { code, map, ast } = core.transform(source, options);
console.log(map, 'map');
// Call this Callback indicates that the loader has finished executing
// Pass multiple parameters to the next loader at the same time
// Return the sourceMap generated by the transform API to the next loader (or webpack compilation stage) for processing
this.callback(null, code, map, ast);
}
module.exports = babelLoader;Here, we received the soureMap result (if any) passed by the last loader on babel's tranform method.
Also call options Sourcemaps tells babel to generate sourceMap during translation.
Finally, the generated source is in this Returned in callback.
At this time, we also generated the sourcemap in our babel translation stage, and finally passed the generated sourcemap to the webpack through the loader chain.
At the same time, pay extra attention to the configuration of devtool in webpack. If sourceMap is closed, you will not see any source code information ~
Next, let's run yarn build again and open the browser to have a look:
be accomplished! So far, our development of Babel loader has stopped. Here I hope that this small example can lead you into the world of loader developers.
Back to the beginning, loader is essentially a function. It's just that we link multiple loaders together through the loader chain and execute them in a certain order and rules.
I believe that after reading here, you have learned about the basis and principle of loader. Such small examples are handy for everyone. In fact, there are only some more parameter verification and boundary processing in real open source loader than here.
Implementation code of Babel loader You can see it here.
Write at the end
Thank you to everyone who sees here. The sharing article on webpack loader is coming to an end here.
I hope you can take this as a starting point and go further and further on the road of exploring loader!
In fact, the source code is not so obscure. I believe that the design concept in the runLoaders source code will be helpful to you, which is why I spend a lot of time in the chapter of source code analysis. I hope to bring you not only about how to implement webpack loader, but also to lead you to master a way to read the source code.
In fact, if you look at the small partners here carefully, you will find that some contents in the runLoaders method are indeed written, but so are they. There are many optimization points, ha ha ~
If you have any questions about the loader, you can also leave your questions in the comment area. We can discuss them together ~