·Reading summary:
this paper proposes a classical Seq2Seq model, which is applied to the field of machine translation. However, Seq2Seq is applicable to many fields, such as multi label text classification.
·References:
[1] Sequence to Sequence Learning with Neural Networks
[Note 1]: the Seq2Seq model proposed in this paper has triggered a series of articles based on Seq2Seq model. Its status is similar to TextCNN published by Kim in 2014 and Transformer published by Google in 2017.
[Note 2]: the content of the paper is relatively simple, and the key point is to explain the principle of Seq2Seq. This blog will explain how to understand Seq2Seq with code logic from the perspective of implementing Seq2Seq by pytorch.
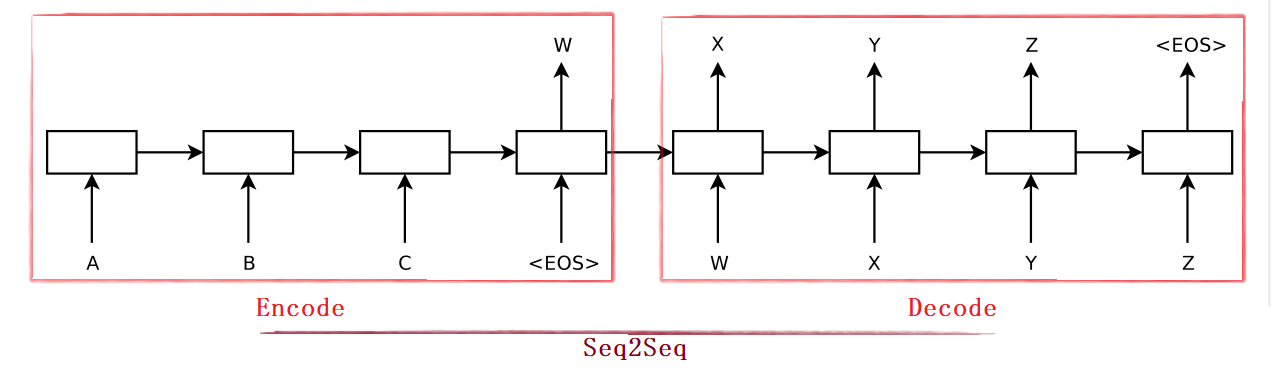
[1] Seq2Seq model diagram
as shown in the figure below, the Encoder is on the left, which mainly converts a sequence into a fixed size hidden layer vector after multi-layer LSTM
H
H
H. On the right is the Decoder, which is also a deep LSTM. Its input is the word generated each time
y
i
y_i
yi and encoder output
H
H
H. The decoder generates one word at a time until the generated word is < EOS >.
[2] Encoder
the code is as follows:
In the code, the parameter src is the source sequence and the parameter trg is the target sequence
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
#src = [src len, batch size]
embedded = self.dropout(self.embedding(src))
#embedded = [src len, batch size, emb dim]
outputs, (hidden, cell) = self.rnn(embedded)
#outputs = [src len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#outputs are always from the top hidden layer
return hidden, cell
Encoder is an ordinary bidirectional LSTM model, which is relatively simple.
normally, we use the last layer, the output of each time step.
here, the Encoder returns the output hidden and the intermediate parameter cell of each time step of each layer. Hidden and the intermediate parameter cell are used as inputs to the Decoder.
[3] Decoder
the code is as follows:
In the code, the parameter src is the source sequence and the parameter trg is the target sequence
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
input = input.unsqueeze(0)
#input = [1, batch size]
embedded = self.dropout(self.embedding(input))
#embedded = [1, batch size, emb dim]
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
#output = [seq len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
prediction = self.fc_out(output.squeeze(0))
#prediction = [batch size, output dim]
return prediction, hidden, cell
the Decoder is still an LSTM layer. Its input is the last output hidden and cell and the word vector input of the last generated word.
[Note 3]: when running the Decoder for the first time, it uses the word vector of the output hidden and cell of the Encoder and the start character < sta >.
there are still many questions here, including:
1. The Decoder jumps out word by word. For the visibility of the Decoder, we should use a loop to traverse. How to write this loop;
2. How to convert word vectors into words? Since the converted words should be sent to the Decoder immediately, this conversion operation should be completed in the model and should not be used as output for external conversion.
3. The model should return the output of the full connection layer, which is a vector for subsequent loss calculation;
4. If the first word of the Decoder is wrong, the whole sentence of the Decoder is wrong. How to prevent this situation.
[4] Seq2Seq
it is successful to finally integrate Encoder and Decoder. The code is as follows:
In the code, the parameter src is the source sequence and the parameter trg is the target sequence
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
assert encoder.hid_dim == decoder.hid_dim, \
"Hidden dimensions of encoder and decoder must be equal!"
assert encoder.n_layers == decoder.n_layers, \
"Encoder and decoder must have equal number of layers!"
def forward(self, src, trg, teacher_forcing_ratio = 0.5):
#teacher_forcing_ratio is probability to use teacher forcing
#e.g. if teacher_forcing_ratio is 0.75 we use ground-truth inputs 75% of the time
batch_size = trg.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
#tensor to store decoder outputs
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
#last hidden state of the encoder is used as the initial hidden state of the decoder
hidden, cell = self.encoder(src)
#first input to the decoder is the <sos> tokens
input = trg[0,:]
for t in range(1, trg_len):
#insert input token embedding, previous hidden and previous cell states
#receive output tensor (predictions) and new hidden and cell states
output, hidden, cell = self.decoder(input, hidden, cell)
#place predictions in a tensor holding predictions for each token
outputs[t] = output
#decide if we are going to use teacher forcing or not
teacher_force = random.random() < teacher_forcing_ratio
#get the highest predicted token from our predictions
top1 = output.argmax(1)
#if teacher forcing, use actual next token as next input
#if not, use predicted token
input = trg[t] if teacher_force else top1
return outputs
seeing the above model, we can solve the problem left in step [3]. First, the output is obtained by the encoder, and then the decoder is executed successively in a for loop.
[Note 4]: self The output of the decoder passes through the full connection layer, which means probability. Next, execute output Argmax (1) is to find out the serial number corresponding to the maximum probability, so that you can find it in the dictionary / tag set.
[Note 5]: teacher_force is a very good mechanism to prevent the decoder from making mistakes again and again, and randomly fill in the words in the target sequence as input for correction. In the retraining phase, we can use teacher_force mechanism, but use teacher in verification and testing_ The force mechanism is wrong. We need to set the formal parameter teacher of the model_ forcing_ ratio=0.
[Note 6]: the outputs of the final return of the model go through the full connection layer! It means probability! It calculates loss as input to the loss function.
[5] Ending
in fact, sometimes it's easier to understand code than paper, but good code is hard to find.
full code reference: https://github.com/bentrevett/pytorch-seq2seq/blob/master/1%20-%20Sequence%20to%20Sequence%20Learning%20with%20Neural%20Networks.ipynb