Recommended reading:
preface
The recent business scenario involves recursive query of database. As we all know, Oracle used by our company has the function of recursive query, so it is very simple to implement.
However, I remember that MySQL has no recursive query function. How should it be implemented in MySQL?
So, there is this article.
Main knowledge points of the article:
- Oracle recursive query, start with connect by prior usage
- find_in_set function
- concat,concat_ws,group_concat function
- MySQL custom function
- Manually implement MySQL recursive query
Oracle recursive query
In Oracle, recursive query is realized through the syntax of start with connect by prior.
According to whether the prior ity keyword is on the child node side or the parent node side, and whether the node of the current query is included, there are four cases.
prior is at the child node side (recursive downward)
The first case: start with child node id = 'query node' connect by prior child node id = parent node ID
select * from dept start with id='1001' connet by prior id=pid;
Here, recursively query the current node and its child nodes according to the condition id = '1001'. The query result includes itself and all child nodes.

The second case: start with parent node id = 'query node' connect by prior child node id = parent node ID
select * from dept start with pid='1001' connect by prior id=pid;
Here, all child nodes of the current node are queried recursively according to the condition pid ='1001 '. The query result only contains all its child nodes, not itself.
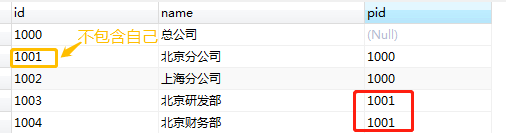
In fact, it's right to think about it, because the starting condition is to take the parent node as the root node and recurse downward, which naturally does not include the current node.
prior is on the parent node side (recursive upward)
The third case: start with child node id = 'query node' connect by prior parent node id = child node ID
select * from dept start with id='1001' connect by prior pid=id;
Here, the current node and its parent node are queried recursively according to the condition id ='1001 '. The query result includes itself and all its parent nodes.

The fourth case: start with parent node id = 'query node' connect by prior parent node id = child node ID
select * from dept start with pid='1001' connect by prior pid=id;
Here, the first generation child nodes of the current node and its parent nodes are queried recursively according to the condition pid ='1001 '. The query result includes its first generation of child nodes and all parent nodes. (including myself)
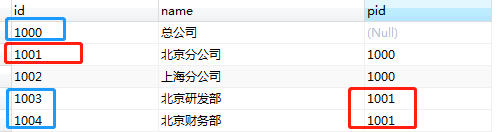
In fact, this situation is easy to understand, because the query start condition takes the # parent node as the root node and recurses upward. Naturally, it is necessary to include the first level child nodes of the current parent node.
At first glance, the above four situations may be confusing and easy to remember. In fact, they are not.
We only need to remember that if the position of {prior is on the child node, it will recurse downward and on the parent node, it will recurse upward.
- If the start condition is a child node, it naturally includes its own node.
- If the start condition is the parent node, the current node will not be included in the downward recursion. Upward recursion needs to include the current node and its first generation child nodes.
MySQL recursive query
It can be seen that it is very convenient for Oracle to implement recursive query. However, it doesn't help us in MySQL, so we need to manually implement recursive query.
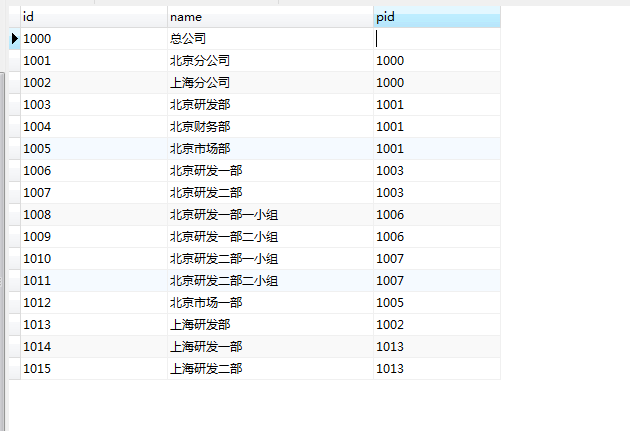
For convenience, we create a department table and insert several pieces of data that can form a recursive relationship.
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`id` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`pid` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1000', 'headquarters', NULL);
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1001', 'Beijing Branch', '1000');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1002', 'Shanghai Branch', '1000');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1003', 'Beijing R & D department', '1001');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1004', 'Beijing Finance Department', '1001');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1005', 'Beijing Marketing Department', '1001');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1006', 'Beijing R & D department 1', '1003');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1007', 'Beijing R & D Department II', '1003');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1008', 'Group 1 of Beijing R & D department 1', '1006');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1009', 'Group 2 of Beijing R & D department 1', '1006');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1010', 'Group 1 of Beijing R & D department 2', '1007');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1011', 'Group 2 of Beijing R & D department 2', '1007');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1012', 'Beijing Marketing Department 1', '1005');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1013', 'Shanghai R & D department', '1002');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1014', 'Shanghai R & D department 1', '1013');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1015', 'Shanghai R & D Department II', '1013');
Yes, Oracle recursion just used this table.
In addition, before that, we need to review several functions in MYSQL, which will be used later.
find_in_set function
Function syntax: find_in_set(str,strlist)
str represents the string to be queried. strlist is a comma separated string, such as ('a,b,c ').
This function is used to find the position of str string in strlist, and the return result is 1 ~ n. If not found, 0 is returned.
Take chestnuts for example:
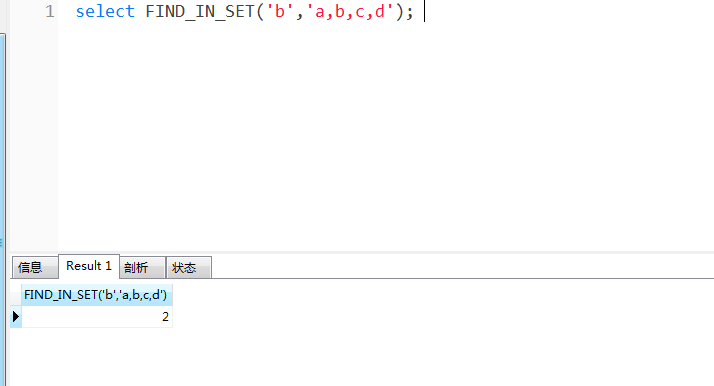
select FIND_IN_SET('b','a,b,c,d');
The result returns 2. Because the position of b is the second substring position.
In addition, it has another usage when querying table data, as follows:
select * from dept where FIND_IN_SET(id,'1000,1001,1002');
The result returns all records with ID in strlist, i.e. three records with id = '1000', id = '1001', id = '1002'.

Seeing this, I wonder if you have any inspiration for the recursive query we want to solve.
Take the downward recursive query of all child nodes as an example. I wonder if you can find a comma concatenated string strlist containing the current node and all child nodes and pass it into find_in_set function. You can query all the required recursive data.
Now, the problem is how to construct such a string strlist.
This requires the following string splicing function.
concat,concat_ws,group_concat function
1, concat is the most basic string splicing function. It is used to connect N strings, such as,
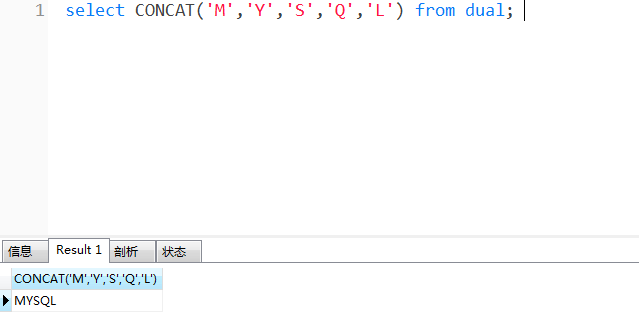
select CONCAT('M','Y','S','Q','L') from dual;
The result is' MYSQL 'string.
2, Concat is a comma as the default separator, and concat_ws, you can specify the delimiter. The first parameter passes in the delimiter, such as separated by an underscore.

3, Group_ The concat function is more powerful. It can splice fields into strings with specific separators while grouping.
Usage: Group_ Concat ([distinct] field to be connected [order by sort field ASC / desc] [separator 'separator'])
You can see that there are optional parameters. You can de duplicate the field values to be spliced, sort and specify the separator. If not specified, it is separated by commas by default.
For the dept table, we can concatenate all IDS in the table with commas. (if the group by field is not used here, it can be cons id ered that there is only one group.)

MySQL custom function to realize recursive query
It can be found that the above problem of string splicing has also been solved. Then, the problem becomes how to construct a recursive string.
We can customize a function to find all its child nodes by passing in the root node id.
Take downward recursion as an example. (while explaining the writing method of user-defined functions, explain recursive logic)
delimiter $$
drop function if exists get_child_list$$
create function get_child_list(in_id varchar(10)) returns varchar(1000)
begin
declare ids varchar(1000) default '';
declare tempids varchar(1000);
set tempids = in_id;
while tempids is not null do
set ids = CONCAT_WS(',',ids,tempids);
select GROUP_CONCAT(id) into tempids from dept where FIND_IN_SET(pid,tempids)>0;
end while;
return ids;
end
$$
delimiter ;
(1) delimiter $$, which defines the terminator. We know that MySQL's default terminator is a semicolon, indicating that the instruction ends and executes. However, in the function body, sometimes we want to encounter that the semicolon does not end, so we need to temporarily change the terminator to an arbitrary other value. I set it to $$, which means that it ends when $$, and the current statement is executed.
(2)drop function if exists get_child_list$$ . If function get_ child_ If the list already exists, delete it first. Note that you need to end and execute the statement with the currently customized terminator $$. Because it needs to be separated from the function body below.
(3)create function get_child_list create function. In addition, the parameter is passed into the child node id of a root node. Note that the type and length of the parameter must be indicated, such as varchar(10). returns varchar(1000) is used to define the return value parameter type.
(4) The function body is surrounded between begin and end. Used to write specific logic.
(5) Declare is used to declare variables, and you can set the default value with default.
ids defined here, as the return value of the whole function, is used to splice into the comma separated recursive string we finally need.
tempids is to record the string of all child nodes temporarily generated in the while loop spliced with commas.
(6) set is used to assign values to variables. Here, assign the passed in root node to tempids.
(7) while do … end while; Loop statement, including loop logic. Note that a semicolon is required at the end of end while.
In the circulatory system, use concat first_ The WS function concatenates the final result ids and the temporarily generated tempids with commas.
Then use find_ IN_ Set (pid, tempids) > 0 as the condition, traverse all PIDs in tempids, find all child node IDs with this as the parent node, and pass GROUP_CONCAT(id) into tempids concatenates these child node IDs with commas, and overwrites and updates tempids.
When the next loop comes in, ids will be spliced again and all child nodes of all child nodes will be found again. Cycle back and forth, layer by layer downward recursive traversal of child nodes. Until it is judged that tempids is empty, it means that all child nodes have been traversed, and the whole cycle is ended.
Here, take '1000' as an example, that is: (refer to the table data relationship in Figure 1)
First cycle: tempids=1000 ids=1000 tempids=1001,1002 (1000 All child nodes of) Second cycle: tempids=1001,1002 ids=1000,1001,1002 tempids=1003,1004,1005,1013 (1001 And all child nodes of 1002) Third cycle: tempids=1003,1004,1005,1013 ids=1000,1001,1002,1003,1004,1005,1013 tempids=1003 And all child nodes of 1004, 1005 and 1013 ... The last cycle, because the child node cannot be found, tempids=null,The cycle ends.
(8)return ids; Used to return IDs as the return value of the function.
(9) After the end of the function body, remember to use the terminator $$to end the whole logic and execute it.
(10) Finally, don't forget to reset the terminator to the default terminator semicolon.
After the custom function is completed, we can use it to recursively query the data we need. For example, I can query all sub nodes of Beijing R & D department.
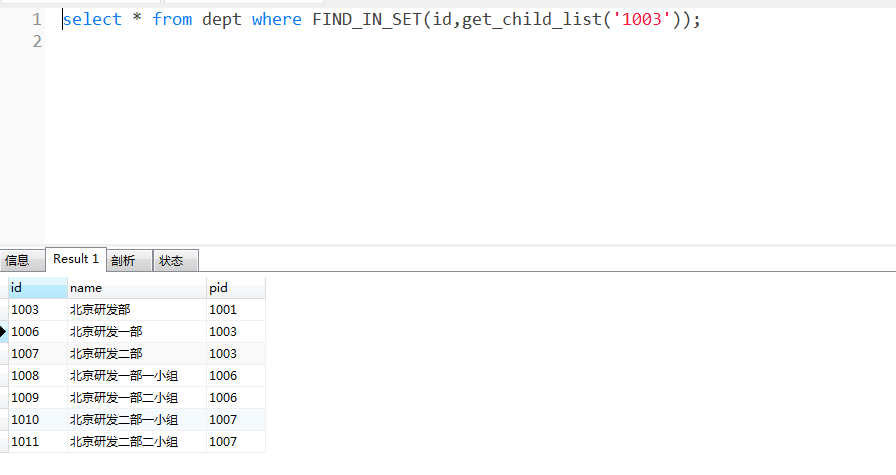
The above is a downward recursive query of all child nodes, and includes the current node. You can also modify the logic to exclude the current node, so I won't demonstrate it.
Manually implement recursive query (recursive up)
Compared with downward recursion, upward recursion is relatively simple.
Because when recursing downward, a parent node in each layer corresponds to multiple child nodes.
When recursing upward, each layer recurses a child node, which only corresponds to a parent node, and the relationship is relatively single.
Similarly, we can define a function get_parent_list to get all the parent nodes of the root node.
delimiter $$
drop function if exists get_parent_list$$
create function get_parent_list(in_id varchar(10)) returns varchar(1000)
begin
declare ids varchar(1000);
declare tempid varchar(10);
set tempid = in_id;
while tempid is not null do
set ids = CONCAT_WS(',',ids,tempid);
select pid into tempid from dept where id=tempid;
end while;
return ids;
end
$$
delimiter ;
Find the first group of Beijing R & D department 2 and its recursive parent node, as follows:

matters needing attention
We used group_ Concat function to splice strings. However, it should be noted that it has a length limit, and the default is 1024 bytes. You can use show variables like "group_concat_max_len"; To see.
Note that the units are bytes, not characters. In MySQL, a single letter takes up one byte, while in utf-8, a Chinese character takes up three bytes.
This is still very fatal for recursive queries. Because in general recursion, the relationship level is relatively deep, which is likely to exceed the maximum length. (although generally spliced are numeric strings, i.e. single bytes)
Therefore, we have two ways to solve this problem:
-
Modify MySQL configuration file my CNF, add {group_concat_max_len = 102400 # the maximum length you want.
-
Execute any of the following statements. SET GLOBAL group_concat_max_len=102400; Or SET SESSION group_concat_max_len=102400;
The difference between them is that global is global, and any new session opened will take effect, but note that the current session already opened will not take effect. Session will only take effect in the current session, and other sessions will not take effect.
The common point is that they will all expire after MySQL is restarted, subject to the configuration in the configuration file. Therefore, it is recommended to modify the configuration file directly. The length of 102400 is generally enough. Assuming that the length of an id is 10 bytes, you can spell 10000 IDs.
In addition, use group_ Another limitation of concat function is that limit cannot be used at the same time. For example,

Originally, I only wanted to check five pieces of data to splice, but it doesn't take effect now.
However, if necessary, it can be realized through sub query,
Thread, database, algorithm, JVM, distributed, micro service, framework, Spring related knowledge
Front line internet P7 interview collection + interview collection of various large factories

Data collection method: stamp here
Study notes and analysis of real interview questions
Chain picture transferring... (img-UPepxagE-1623616098906)]
Originally, I only wanted to check five pieces of data to splice, but it doesn't take effect now.
However, if necessary, it can be realized through sub query,
Thread, database, algorithm, JVM, distributed, micro service, framework, Spring related knowledge
[external chain picture transferring... (img-7BAxlXZ8-1623616098906)]
Front line internet P7 interview collection + interview collection of various large factories
[external chain picture transferring... (IMG ijehurll-1623616098907)]
Data collection method: stamp here
Study notes and analysis of real interview questions