Catalog
MyBatis is an excellent persistence framework that supports customized SQL, stored procedures, and advanced mapping. It mainly accomplishes two things:
1. Encapsulating JDBC operations;
2. Make use of radiation to get through the conversion between Java classes and SQL statements.
The main design purpose of MyBatis is to make the management of input and output more convenient when we execute the SQL statement. Therefore, the core competitiveness of MyBatis is to write out the SQL conveniently and obtain the execution result of the SQL conveniently.
Configuration of MyBatis
Like most other frameworks, the MyBatis framework needs a configuration file, which is roughly as follows:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<setting name="cacheEnabled" value="true"/>
<setting name="lazyLoadingEnabled" value="false"/>
<!--<setting name="logImpl" value="STDOUT_LOGGING"/> <!– Print log information –>-->
</settings>
<typeAliases>
<typeAlias type="com.luo.dao.UserDao" alias="User"/>
</typeAliases>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/> <!--Transaction management type-->
<dataSource type="POOLED">
<property name="username" value="luoxn28"/>
<property name="password" value="123456"/>
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://192.168.1.150/ssh_study"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="userMapper.xml"/>
</mappers>
</configuration>Among the above configurations, the most important is the configuration of database parameters, such as user name, password, and the type of driver loaded. If the mapper file corresponding to the data table is configured, it needs to be added to the < mappers > node.
Major Members of MyBatis
- Configuration. All configuration information for MyBatis is stored in the Configuration object, where most of the configuration in the configuration file is stored.
- As the main top-level API of MyBatis, SqlSession represents the session when interacting with the database and completes the necessary database addition, deletion and modification functions.
- Executor MyBatis Executor, the core of MyBatis scheduling, is responsible for the generation of SQL statements and the maintenance of query cache.
- StatementHandler encapsulates the JDBC Statement operation and is responsible for the operation of JDBC Statement, such as setting parameters, etc.
- ParameterHandler is responsible for converting parameters passed by users into data types corresponding to JDBC Statement
- ResultSetHandler is responsible for converting the ResultSet result set object returned by JDBC into a collection of List type
- TypeHandler is responsible for mapping and transformation between java data types and jdbc data types (also known as data table column types)
- MappedStatement maintains the encapsulation of a < select | update | delete | Insert > node
- SqlSource is responsible for dynamically generating SQL statements according to the parameterObject passed by users, encapsulating information into the BoundSql object and returning it.
- BoundSql represents dynamically generated SQL statements and corresponding parameter information
The main members mentioned above will basically involve in one database operation. In SQL operation, the key concerns are when the SQL parameters are set and how the result set is converted into JavaBean objects. These two processes correspond to the processing logic in StatementHandler and ResultSetHandler classes.
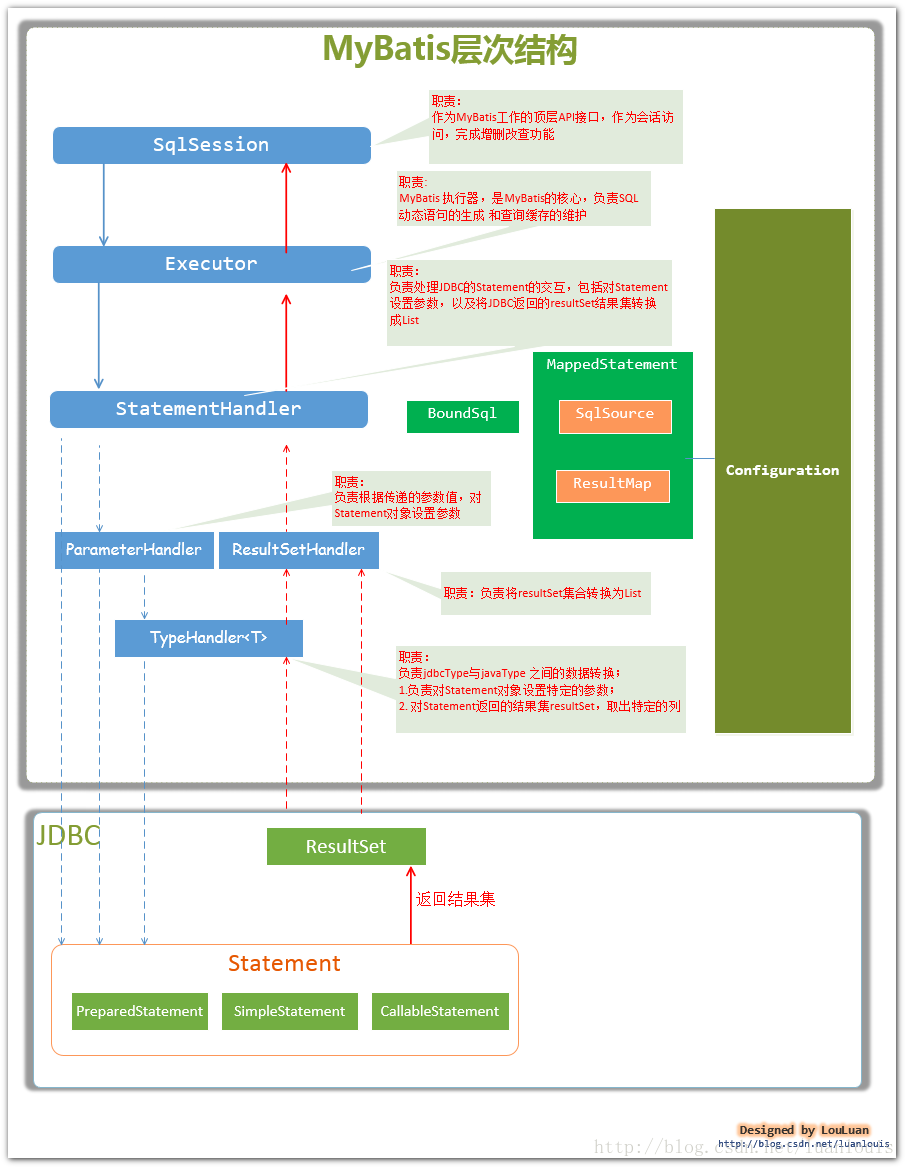
(Pictures from Architecture Design and Example Analysis of MyBatis in Deep Understanding of MyBatis Principle)
Initialization of MyBatis
MyBatis initialization starts with parsing configuration files and initializing Configuration. MyBatis initialization can be expressed in the following lines of code:
String resource = "mybatis.xml";
// Load the mybatis configuration file (it also loads the associated mapping file)
InputStream inputStream = null;
try {
inputStream = Resources.getResourceAsStream(resource);
} catch (IOException e) {
e.printStackTrace();
}
// Construction of the factory of sqlSession
sessionFactory = new SqlSessionFactoryBuilder().build(inputStream);(The builder design pattern is used here)
The SqlSessionFactory builder object is created first, and then it is used to create the SqlSessionFactory. The constructor pattern is used here. The simplest understanding of the constructor pattern is not to create new objects manually, but to create objects by other classes.
// SqlSessionFactoryBuilder class
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
return build(parser.parse()); // It's time to start parsing.
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
inputStream.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}The XMLConfigBuilder object parses the XML configuration file, which is actually the parsing operation of the configuration node.
// XMLConfigBuilder class
public Configuration parse() {
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}
private void parseConfiguration(XNode root) {
try {
//issue #117 read properties first
propertiesElement(root.evalNode("properties"));
Properties settings = settingsAsProperties(root.evalNode("settings"));
loadCustomVfs(settings);
typeAliasesElement(root.evalNode("typeAliases"));
pluginElement(root.evalNode("plugins"));
objectFactoryElement(root.evalNode("objectFactory"));
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
reflectorFactoryElement(root.evalNode("reflectorFactory"));
settingsElement(settings);
// read it after objectFactory and objectWrapperFactory issue #631
/* Processing Environment Node Data */
environmentsElement(root.evalNode("environments"));
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
typeHandlerElement(root.evalNode("typeHandlers"));
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}Under the configuration node, node configurations such as properties/settings/.../mappers are resolved in turn. When parsing environment nodes, transaction managers are created according to the configuration of transactionManager, and DataSource objects are created according to the configuration of dataSource, which contains information about database login. When parsing a mappers node, all mapper files under that node are read and parsed, and the parsed results are stored in the configuration object.
// XMLConfigBuilder class
private void environmentsElement(XNode context) throws Exception {
if (context != null) {
if (environment == null) {
environment = context.getStringAttribute("default");
}
for (XNode child : context.getChildren()) {
String id = child.getStringAttribute("id");
if (isSpecifiedEnvironment(id)) {
/* Create a transaction manager */
TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));
DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));
DataSource dataSource = dsFactory.getDataSource();
/* Builder pattern design pattern */
Environment.Builder environmentBuilder = new Environment.Builder(id)
.transactionFactory(txFactory)
.dataSource(dataSource);
configuration.setEnvironment(environmentBuilder.build());
}
}
}
}
// Parsing individual mapper files
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
if ("package".equals(child.getName())) {
String mapperPackage = child.getStringAttribute("name");
configuration.addMappers(mapperPackage);
} else {
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
if (resource != null && url == null && mapperClass == null) {
ErrorContext.instance().resource(resource);
InputStream inputStream = Resources.getResourceAsStream(resource);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
mapperParser.parse(); // Start parsing mapper files:)
} else if (resource == null && url != null && mapperClass == null) {
ErrorContext.instance().resource(url);
InputStream inputStream = Resources.getUrlAsStream(url);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url == null && mapperClass != null) {
Class<?> mapperInterface = Resources.classForName(mapperClass);
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}After parsing the MyBatis configuration file, the configuration is initialized, and then SqlSession is created based on the configuration object. By this time, the initialization of MyBatis is over.
// SqlSessionFactoryBuilder class
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}MyBatis's SQL Query Process
The execution of the SQL statement is the important responsibility of MyBatis. This process is to encapsulate JDBC for operation, and then use Java reflection technology to complete the conversion between JavaBean objects and database parameters. This mapping relationship is accomplished by the TypeHandler object, which will be saved when the corresponding metadata of the data table is obtained. The database types of all columns in the table are roughly logical as follows:
/* Get resultSet metadata */
ResultSetMetaData metaData = resultSet.getMetaData();
int column = metaData.getColumnCount();
for (int i = 1; i <= column; i++) {
JdbcType jdbcType = JdbcType.forCode(metaData.getColumnType(i));
typeHandlers.add(TypeHandlerRegistry.getTypeHandler(jdbcType));
columnNames.add(metaData.getColumnName(i));
}Use the following code for SQL query operations:
sqlSession = sessionFactory.openSession();
User user = sqlSession.selectOne("com.luo.dao.UserDao.getUserById", 1);
System.out.println(user);The process of creating sqlSession is actually to create the corresponding class according to the configuration in the configuration, and then return the sqlSession object created. Call the selectOne method for SQL query. The selectOne method finally calls the selectList. In the selectList, the MappedStatement object stored in the configuration is queried. The configuration of an SQL statement in the mapper file corresponds to a MappedStatement object, and then call the executor for query operation.
// DefaultSqlSession class
public <T> T selectOne(String statement, Object parameter) {
// Popular vote was to return null on 0 results and throw exception on too many.
List<T> list = this.<T>selectList(statement, parameter);
if (list.size() == 1) {
return list.get(0);
} else if (list.size() > 1) {
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}In query operation, the executor will first query whether the cache has been hit or not, and the hit will be returned directly, otherwise it will be queried from the database.
// CachingExecutor class
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
/* Get the sql, boundSql of the correlation parameter */
BoundSql boundSql = ms.getBoundSql(parameterObject);
/* Create a cache key value */
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
/* Get a secondary cache instance */
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, parameterObject, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
/**
* Insert a placeholder in the localCache first, where
*/
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
/* Writing data to the cache, that is, caching query results */
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}The real doQuery operation is accomplished by the SimplyExecutor agent. There are two sub-processes in this method, one is the setting of SQL parameters, the other is the encapsulation of SQL query operation and result set.
// SimpleExecutor class
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
/* Subflow 1: Setting of SQL Query Parameters */
stmt = prepareStatement(handler, ms.getStatementLog());
/* Subprocess 2: SQL query operations and result set encapsulation */
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}Subprocess 1 Setting of SQL query parameters:
First get the database connection connection, then prepare the statement, and then set the parameter values in the SQL query. Open a connection connection, not close after use, but store it, and return directly the next time you need to open the connection.
// SimpleExecutor class
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
/* Get Connection Connection Connection Connection */
Connection connection = getConnection(statementLog);
/* Prepare Statement */
stmt = handler.prepare(connection, transaction.getTimeout());
/* Setting parameter values in SQL queries */
handler.parameterize(stmt);
return stmt;
}
// DefaultParameterHandler class
public void setParameters(PreparedStatement ps) {
/**
* Set the SQL parameter values, read the parameter values and types from the Parameter Mapping, and then set them to the SQL statement
*/
ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings != null) {
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) {
jdbcType = configuration.getJdbcTypeForNull();
}
try {
typeHandler.setParameter(ps, i + 1, value, jdbcType);
} catch (TypeException e) {
throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);
} catch (SQLException e) {
throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);
}
}
}
}
}Subprocess 2 Encapsulation of SQL Query Result Set:
// SimpleExecutor class
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
// Perform query operations
ps.execute();
// Execution result set encapsulation
return resultSetHandler.<E> handleResultSets(ps);
}
// DefaultReseltSetHandler class
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
final List<Object> multipleResults = new ArrayList<Object>();
int resultSetCount = 0;
/**
* Get the first ResultSet and the MetaData data of the database, including the column name of the data table, the type of the column, the class number, and so on.
* This information is stored in ResultSetWrapper
*/
ResultSetWrapper rsw = getFirstResultSet(stmt);
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
ResultMap resultMap = resultMaps.get(resultSetCount);
handleResultSet(rsw, resultMap, multipleResults, null);
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
return collapseSingleResultList(multipleResults);
}ResultSetWrapper is the wrapper class of ResultSet. It calls the getFirstResultSet method to get the first ResultSet. At the same time, it obtains the MetaData data of the database, including column name, column type, class serial number, etc. These information are stored in the ResultSetWrapper class. The handleResultSet method is then called to encapsulate the result set.
// DefaultResultSetHandler class
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults, ResultMapping parentMapping) throws SQLException {
try {
if (parentMapping != null) {
handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping);
} else {
if (resultHandler == null) {
DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory);
handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null);
multipleResults.add(defaultResultHandler.getResultList());
} else {
handleRowValues(rsw, resultMap, resultHandler, rowBounds, null);
}
}
} finally {
// issue #228 (close resultsets)
closeResultSet(rsw.getResultSet());
}
}The handleRowValues method is called here to set the result value.
// DefaultResultSetHandler class
public void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
if (resultMap.hasNestedResultMaps()) {
ensureNoRowBounds();
checkResultHandler();
handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
} else {
// Encapsulation of data
handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
}
}
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping)
throws SQLException {
DefaultResultContext<Object> resultContext = new DefaultResultContext<Object>();
skipRows(rsw.getResultSet(), rowBounds);
while (shouldProcessMoreRows(resultContext, rowBounds) && rsw.getResultSet().next()) {
ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(rsw.getResultSet(), resultMap, null);
Object rowValue = getRowValue(rsw, discriminatedResultMap);
storeObject(resultHandler, resultContext, rowValue, parentMapping, rsw.getResultSet());
}
}
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap) throws SQLException {
final ResultLoaderMap lazyLoader = new ResultLoaderMap();
// createResultObject is the newly created object, the class corresponding to the data table
Object rowValue = createResultObject(rsw, resultMap, lazyLoader, null);
if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
final MetaObject metaObject = configuration.newMetaObject(rowValue);
boolean foundValues = this.useConstructorMappings;
if (shouldApplyAutomaticMappings(resultMap, false)) {
// Here the data is filled in, and the metaObject contains the resultObject information.
foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, null) || foundValues;
}
foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, null) || foundValues;
foundValues = lazyLoader.size() > 0 || foundValues;
rowValue = (foundValues || configuration.isReturnInstanceForEmptyRow()) ? rowValue : null;
}
return rowValue;
}
private boolean applyAutomaticMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, String columnPrefix) throws SQLException {
List<UnMappedColumnAutoMapping> autoMapping = createAutomaticMappings(rsw, resultMap, metaObject, columnPrefix);
boolean foundValues = false;
if (autoMapping.size() > 0) {
// The for loop call is made here, because there are seven columns in the user table, so there are seven calls.
for (UnMappedColumnAutoMapping mapping : autoMapping) {
// Here, the query results in the esultSet are converted to the corresponding actual types
final Object value = mapping.typeHandler.getResult(rsw.getResultSet(), mapping.column);
if (value != null) {
foundValues = true;
}
if (value != null || (configuration.isCallSettersOnNulls() && !mapping.primitive)) {
// gcode issue #377, call setter on nulls (value is not 'found')
metaObject.setValue(mapping.property, value);
}
}
}
return foundValues;
}Map. typeHandler. getResult retrieves the actual type of the query result value, such as the ID field in our user table as int type, which corresponds to the Integer type in Java, and then gets its int value by calling statement.getInt("id"), which is Integer type. The metaObject.setValue method sets the acquired Integer value to the corresponding field in the Java class.
// MetaObject class
public void setValue(String name, Object value) {
PropertyTokenizer prop = new PropertyTokenizer(name);
if (prop.hasNext()) {
MetaObject metaValue = metaObjectForProperty(prop.getIndexedName());
if (metaValue == SystemMetaObject.NULL_META_OBJECT) {
if (value == null && prop.getChildren() != null) {
// don't instantiate child path if value is null
return;
} else {
metaValue = objectWrapper.instantiatePropertyValue(name, prop, objectFactory);
}
}
metaValue.setValue(prop.getChildren(), value);
} else {
objectWrapper.set(prop, value);
}
}The metaValue.setValue method finally calls the set method of the corresponding data domain in the Java class, thus completing the Java class encapsulation process of the SQL query result set. Finally, paste a snapshot of the call stack reaching the set method of the Java class:
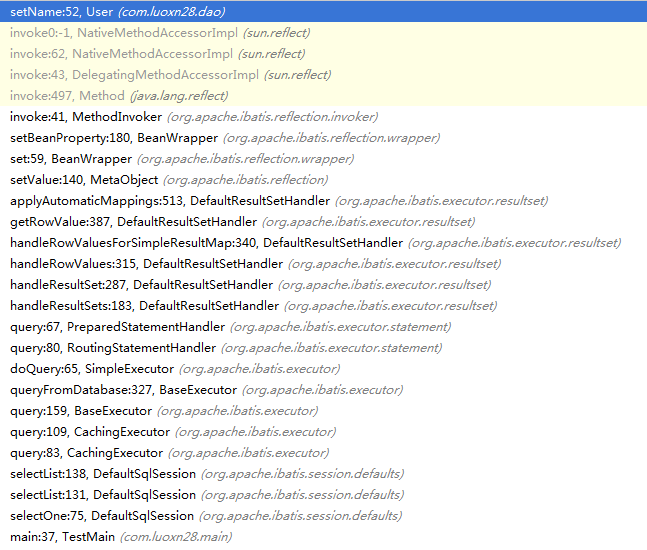
MyBatis Cache
MyBatis provides query caching to alleviate database pressure and improve performance. MyBatis provides a first-level cache and a second-level cache.
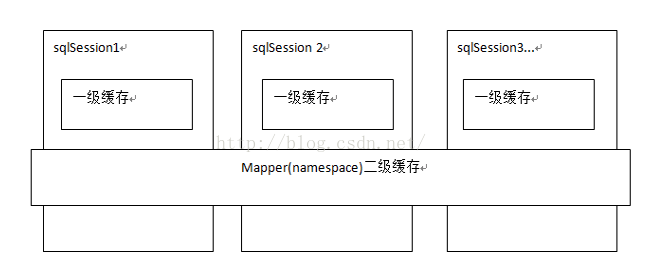
The first level cache is the SqlSession level cache. Each SqlSession object has a hash table for caching data. Caches between different SqlSession objects are not shared. The same SqlSession object executes the same SQL query twice, and caches the results after the first query is executed, so that the second query does not need to query the database, but directly returns the cached results. MyBatis turns on level 1 caching by default.
Secondary cache is mapper level cache. Secondary cache is across SqlSession. Multiple SqlSession objects can share the same secondary cache. Different SqlSession objects execute the same SQL statement twice. The query results will be cached for the first time, and the results of the second query will be returned directly to the secondary cache. MyBatis does not open secondary cache by default. You can use the following configuration in the configuration file to open secondary cache:
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>When the SQL statement is updated (delete/add/update), the corresponding cache is emptied to ensure that all the data stored in the cache is up-to-date. MyBatis's secondary cache is not friendly to fine-grained data-level caching, such as the following requirements: caching commodity information, because of the large amount of commodity information query visits, but requires users to query the latest commodity information every time. At this time, if using mybatis's secondary cache, it will not be able to achieve when a commodity changes. Only the cached information of the commodity is refreshed while the information of other commodities is not refreshed, because the secondary cached area of mybaits is divided into mapper units. When a commodity information changes, the cached data of all commodity information will be emptied. To solve this kind of problem, we need to cache the data according to the needs of the business layer, and implement the specific business.