Chapter 1 MyBatis quick start
Section I Introduction to MyBatis
1. What is MyBatis?
- MyBatis is an excellent persistence layer framework, which supports custom SQL, stored procedures and advanced mapping.
- MyBatis eliminates almost all JDBC code and the work of setting parameters and obtaining result sets.
- MyBatis can configure and map primitive types, interfaces and Java POJO s (Plain Old Java Objects) to records in the database through simple XML or annotations.
MyBatis is a pan ORM framework
**ORM * * is the abbreviation of object relational mapping. It is generally used to realize the data conversion between different types of systems in object-oriented programming language.
2. Problems solved by mybatis
- The frequent creation and release of database links cause a waste of system resources, which affects the system performance.
Solution: in sqlmapconfig Configure the data link pool in XML and use the connection pool to manage database links. - sql statements are written in the code, which makes the code difficult to maintain. The actual application of sql may change greatly. sql changes need to change the java code.
Solution: configure the Sql statement in xxxxmapper Separate from java code in XML file. - It is troublesome to pass parameters to sql statements, because the where conditions of sql statements are not necessarily many or few, and placeholders need to correspond to parameters.
Solution: Mybatis automatically maps java objects to sql statements, and defines the type of input parameters through parameterType in the statement. - It is troublesome to parse the result set. The change of sql leads to the change of parsing code, and it needs to be traversed before parsing. It is more convenient to parse if the database records can be encapsulated into pojo objects.
Solution: Mybatis automatically maps the sql execution results to java objects, and defines the type of output results through the resultType in the statement.
Section II introduction to MyBatis
If you want to query a database using myuser, you need to define the following table.
create database test01 charset utf8;
create table if not exists user(
id int(11) unsigned not null auto_increment comment 'User number'
,username varchar(32) not null comment 'User name'
,birthday varchar(38) not null comment 'User birthday'
,sex char(2) not null comment 'Gender: 0 male and 1 female'
,address varchar(255) null comment 'User address'
,primary key(id)
)engine=innodb default charset=utf8 comment='User table';
insert into user(username, birthday, sex, address) values('hyx', '1999-09-13', '0', 'Nanshan District, Shenzhen');
commit;
1. Pre preparation
- Suppose you have established a common maven project.
- The entity class corresponding to the User table is generated.
package org.example.model;
import java.io.Serializable;
import java.sql.Date;
public class User implements Serializable {
private Integer id;
private String username;
private Date birthday;
private String sex;
private String address;
// Omit getter/setter and toString methods
}
- And the DAO layer interface has been written
package org.example.dao;
import org.example.model.User;
import java.util.List;
public interface UserDao {
List<User> findAll();
}
If you use the traditional JDBC or JdbcTemplate template, your next step should be to implement the DAO interface and write the specific CURD method. However, after using MyBatis, you don't need to write these cumbersome implementation classes yourself. These MyBatis will help you generate them using dynamic proxy technology. Let’s go and have a look.
2. Dependency import
MyBatis has some necessary dependencies. You can add it to the CLASSPATH path or define its coordinates in the pom file.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>demo01</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!-- MyBatis rely on-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.5</version>
</dependency>
<!-- JDBC drive-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
<scope>runtime</scope>
</dependency>
<!-- Junit For testing-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
If you are using Oracle or SqlServer database, you should switch the following drivers:
<dependency>
<groupId>com.microsoft.sqlserver</groupId>
<artifactId>sqljdbc4</artifactId>
<version>4.0</version>
</dependency>
<dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc14</artifactId>
<version>10.2.0.5.0</version>
</dependency>
3. Master profile
Now we need a configuration file to describe the properties and behavior of MyBatis. If you don't understand, it doesn't matter. We will explain it in detail in the next chapter!
src\main\resources\mybatis-config.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- to configure MyBatis Environment -->
<environments default="mysql">
<!-- to configure mysql Environment -->
<environment id="mysql">
<!-- Configure the type of transaction -->
<transactionManager type="JDBC"></transactionManager>
<!-- Configure the information of connecting to the database: the data source is used(Connection pool) -->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://42.192.223.129:3306/test01"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<!-- inform MyBatis Location of mapping -->
<mappers>
<mapper resource="org/example/dao/UserDao.xml"/>
</mappers>
</configuration>
If you are using Oracle or SqlServer database, the four elements of JDBC connection should be modified as follows:
<property name="driver" value="oracle.jdbc.driver.OracleDriver"/>
<property name="url" value="jdbc:oracle:thin:@127.0.0.1:1521:ORCLONE"/>
<property name="username" value="kbssfms"/>
<property name="password" value="kbssfms"/>
<property name ="driverClassName" value ="com.microsoft.sqlserver.jdbc.SQLServerDriver"></property>
<property name ="url" value ="jdbc:sqlserver://127.0.0.1:1433;DatabaseName=kbssfms"></property>
<property name ="username" value ="sa"></property>
<property name ="password" value ="Sa147741"></property>
4. Mapping profile
In addition to the main configuration file, you also need a mapping configuration file to tell MyBatis what SQL to execute and how to deal with parameters and result sets.
src\main\resources\com\mybatis\demo\dao\UserDao.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.example.dao.UserDao">
<!-- Query all users -->
<select id="findAll" resultType="org.example.model.User">
SELECT * FROM user
</select>
</mapper>
5. Simple test
Now we can test!
package org.example.dao.test;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.example.dao.UserDao;
import org.example.model.User;
import java.io.InputStream;
import java.util.List;
public class MybatisTest {
public static void main(String[] args) throws Exception {
//1. Read the master configuration file
InputStream in = Resources.getResourceAsStream("mybatis-config.xml");
//2. Create SqlSessionFactoryBuilder
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
//3. Build SqlSessionFactory
SqlSessionFactory factory = builder.build(in);
//4. Open session
SqlSession session = factory.openSession();
//5. Get proxy object
UserDao userDao = session.getMapper(UserDao.class);
//6. Use the proxy object to execute all methods of query
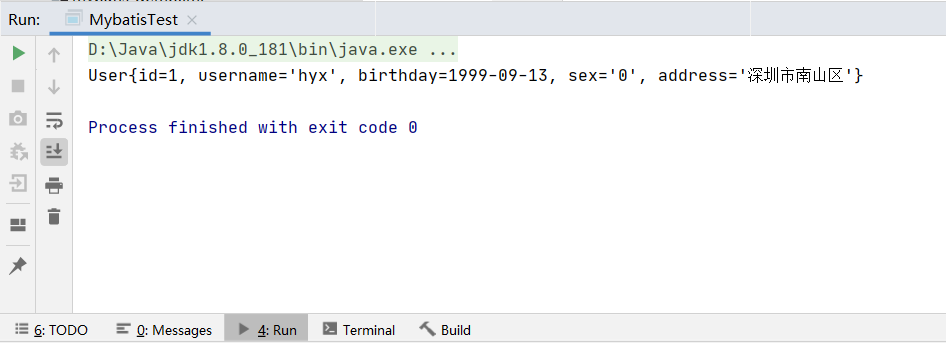
List<User> users = userDao.findAll();
for (User user : users) {
System.out.println(user);
}
//7. Release resources
if (session != null) {
session.close();
}
if (in != null) {
in.close();
}
}
}
The operation results are as follows:
For the complete project code of the above case, please refer to the attachment mybatis demo / Demo01 project!
Section III introduction case expansion
1. SqlSessionFactoryBuilder
To create a Session, you need to use SqlSessionFactory, which must be built by SqlSessionFactoryBuilder. SqlSessionFactoryBuilder has five build() methods, each of which allows you to create an instance of SqlSessionFactory from different resources.
SqlSessionFactory build(InputStream inputStream)
SqlSessionFactory build(InputStream inputStream, String environment)
SqlSessionFactory build(InputStream inputStream, Properties properties)
SqlSessionFactory build(InputStream inputStream, String env, Properties props)
SqlSessionFactory build(Configuration config)
You can see that the first four methods are to obtain the configuration file (mybatis-config.xml) from an InputStream stream stream, then build SqlSessionFactory, and provide different combinations of default parameters for selection. Our introductory case uses this method.
In addition, SqlSessionFactory is also built by receiving a Configuration instance. The Configuration class contains all the contents you may care about for a SqlSessionFactory instance. The following is a simple example of how to manually configure a Configuration instance and pass it to the build() method to create a SqlSessionFactory.
DataSource dataSource = BaseDataTest.createBlogDataSource();
TransactionFactory transactionFactory = new JdbcTransactionFactory();
Environment environment = new Environment("development", transactionFactory, dataSource);
Configuration configuration = new Configuration(environment);
configuration.setLazyLoadingEnabled(true);
configuration.setEnhancementEnabled(true);
configuration.getTypeAliasRegistry().registerAlias(Blog.class);
configuration.getTypeAliasRegistry().registerAlias(Post.class);
configuration.getTypeAliasRegistry().registerAlias(Author.class);
configuration.addMapper(BoundBlogMapper.class);
configuration.addMapper(BoundAuthorMapper.class);
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
SqlSessionFactory factory = builder.build(configuration);
2. SqlSessionFactory
With SqlSessionFactory, we can use it to create SqlSession. It has six overloaded methods for us to use. Which one to use depends on your choice of transaction, connection and actuator type.
SqlSession openSession() SqlSession openSession(boolean autoCommit) SqlSession openSession(Connection connection) SqlSession openSession(TransactionIsolationLevel level) SqlSession openSession(ExecutorType execType, TransactionIsolationLevel level) SqlSession openSession(ExecutorType execType) SqlSession openSession(ExecutorType execType, boolean autoCommit) SqlSession openSession(ExecutorType execType, Connection connection) Configuration getConfiguration();
The parameterless opensseion() method has the following default behavior:
- The transaction scope will be turned on (that is, it will not be committed automatically).
- The transaction isolation level will use the default settings of the driver or data source.
- The Connection object will be obtained from the DataSource instance configured by the current environment.
- Preprocessing statements are not reused, nor are updates processed in batches (using SIMPLE type executors).
In addition, sqlsessionfactory has another method: getConfiguration(). This method will return a Configuration instance, which you can use at runtime to check the Configuration of MyBatis.
Isolation level of things
For the transaction isolation level, MyBatis uses a Java enumeration wrapper called TransactionIsolationLevel. The transaction isolation level supports five JDBC isolation levels (NONE, READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ and SERIALIZABLE), and is consistent with the expected behavior
Actuator type
You may be unfamiliar with the ExecutorType parameter. This enumeration type defines three values:
- ExecutorType.SIMPLE: this type of actuator has no special behavior. It creates a new preprocessing statement for the execution of each statement.
- ExecutorType.REUSE: this type of executor will reuse preprocessing statements.
- ExecutorType.BATCH: this type of executor will execute all update statements in batch. If SELECT is executed among multiple updates, multiple update statements will be executed when necessary.
3. SqlSession
SqlSession is a very powerful class in MyBatis. It contains all the methods for executing statements, committing or rolling back transactions, and obtaining mapper instances. The following is a classified display and introduction.
// 1. Statement execution method
<T> T selectOne(String statement, Object parameter)
<E> List<E> selectList(String statement, Object parameter)
<T> Cursor<T> selectCursor(String statement, Object parameter) // Cursor form: the lazy loading of data can be realized with the help of iterator
<K,V> Map<K,V> selectMap(String statement, Object parameter, String mapKey)
int insert(String statement, Object parameter) // The values returned by the insert, update, and delete methods represent the number of rows affected by the statement
int update(String statement, Object parameter)
int delete(String statement, Object parameter)
// 2. Statement execution method (overloaded form without parameters)
<T> T selectOne(String statement)
<E> List<E> selectList(String statement)
<T> Cursor<T> selectCursor(String statement)
<K,V> Map<K,V> selectMap(String statement, String mapKey)
int insert(String statement)
int update(String statement)
int delete(String statement)
// 3. Advanced version of select method: it allows you to limit the range of returned rows or provide custom result processing logic. It is usually used when the data set is very large.
<E> List<E> selectList (String statement, Object parameter, RowBounds rowBounds)
<T> Cursor<T> selectCursor(String statement, Object parameter, RowBounds rowBounds)
<K,V> Map<K,V> selectMap(String statement, Object parameter, String mapKey, RowBounds rowbounds)
void select (String statement, Object parameter, ResultHandler<T> handler)
void select (String statement, Object parameter, RowBounds rowBounds, ResultHandler<T> handler)
// 4. BATCH update method: when using BATCH executor, you can use this method to clear (execute) the BATCH update statements cached in the JDBC driver class.
List<BatchResult> flushStatements()
// 5. Transaction control method: used to control the transaction scope when using the JDBC transaction manager controlled by the Connection instance. Note: these methods do not apply to external transaction managers.
void commit()
void commit(boolean force)
void rollback()
void rollback(boolean force)
// 6. Clear the local cache (session cache)
void clearCache()
// 7. Close the session
void close()
// 8. Get Configuration instance
Configuration getConfiguration()
// 9. Get mapper: compared with the above CURD method, the biggest advantage of mapper is that it conforms to type safety and is more friendly to IDE and unit testing.
<T> T getMapper(Class<T> type)
There are more detailed explanations about RowBounds and ResultHandler on the official website. You can click here: https://mybatis.org/mybatis-3/zh/java-api.html .
4. Mapper instance
The insert, update, delete and select methods in SqlSeesion are powerful, but they are also cumbersome. They do not comply with type safety and are not so friendly to your IDE and unit testing. Therefore, it is more common to use mapper classes to execute mapping statements.
We have seen an example of using a mapper in the previous introductory case. A mapper class is an interface that only needs to declare methods that match the SqlSession method. The following mapper example shows some method signatures and how they are mapped to SqlSession.
public interface AuthorMapper {
Author selectAuthor(int id); // (Author) selectOne("selectAuthor",5);
List<Author> selectAuthors(); // (List<Author>) selectList("selectAuthors")
@MapKey("id")
Map<Integer, Author> selectAuthors(); // (Map<Integer,Author>) selectMap("selectAuthors", "id")
int insertAuthor(Author author); // insert("insertAuthor", author)
int updateAuthor(Author author); // updateAuthor("updateAuthor", author)
int deleteAuthor(int id); // delete("deleteAuthor",5)
}
In summary, each mapper method signature has a SqlSession method associated with it.
Mapper interfaces can inherit from other interfaces. When using XML to bind the mapper interface, just ensure that the statement is in the appropriate namespace. The only limitation is that you cannot have the same method signature in two interfaces with inheritance (this is potentially dangerous and undesirable).
You can also pass multiple parameters to a mapper method. In the case of multiple parameters, they will be named by param plus their position in the parameter list by default, such as: #{param1}, #{param2}. If you want to customize the name of the parameter (when there are multiple parameters), you can use the @ Param("paramName") annotation on the parameter.
In addition, you can also pass a RowBounds instance to the method to limit the query results, etc.
5. Replace the mapper configuration with annotations
MyBatis defines a set of annotations for mapper configuration, which makes it easier for us to configure.
- Annotate the interface and delete userdao XML file (delete the corresponding method configuration).
public interface UserDao {
@Select("SELECT * FROM USER")
List<User> findAll();
}
- Modify MyBatis config XML and let MyBatis scan the annotations.
<!-- inform MyBatis Location of mapping -->
<mappers>
<mapper class="com.mybatis.demo.dao.UserDao"/>
</mappers>
be careful
For the same method, there cannot be two configuration methods: mapping configuration file and annotation. MyBatis will detect and throw an exception!
For annotation use cases, please refer to mybatis-demo02.
// TODO mybatis-demo02
6. Add log output
MyBatis will detect log implementations in the following order at runtime. If these implementations are not found, the logging function will be disabled.
- SLF4J
- Apache commons logging (default log for Tomcat and WebShpere application servers)
- Log4j 2
- Log4j
- JDK logging
Of course, you can also use mybatis config The specified log implementation is displayed in the XML configuration file.
<configuration>
<settings>
...
<setting name="logImpl" value="LOG4J"/>
...
</settings>
</configuration>
The optional values are: SLF4J, LOG4J, LOG4J2 and JDK_LOGGING,COMMONS_LOGGING,STDOUT_LOGGING,NO_LOGGING, or implementing org apache. ibatis. logging. Log interface, and the fully qualified name of the class whose constructor takes string as parameter.
You can also call any other MyBatis method before calling any of the following methods to switch the log implementation:
org.apache.ibatis.logging.LogFactory.useSlf4jLogging(); org.apache.ibatis.logging.LogFactory.useLog4JLogging(); org.apache.ibatis.logging.LogFactory.useJdkLogging(); org.apache.ibatis.logging.LogFactory.useCommonsLogging(); org.apache.ibatis.logging.LogFactory.useStdOutLogging();
Note that the switching of log implementation will take effect only when the log implementation exists in the runtime classpath. Otherwise, the default order will be used to find the log implementation.
You can view the log statements of MyBatis by turning on the log function on the fully qualified name, namespace or fully qualified sentence name of package and mapping class. The specific configuration steps are related to log implementation. Log4J is used as an example below.
First, you should ensure that there is a jar package of Log4J under the class path of the application, or the corresponding maven coordinates are imported.
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.12</version>
</dependency>
Then, add log4j The properties configuration file to the application class path. The simple configuration is as follows.
# Global log configuration log4j.rootLogger=ERROR, stdout # MyBatis log configuration log4j.logger.org.mybatis.example.BlogMapper=TRACE # console output log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n
The above configuration will enable Log4J to print org. In detail mybatis. example. The log of blogmapper only prints error messages for other parts of the application.
You can adjust the granularity of log output as needed, as shown below.
# Print only the log of the statement selectBlog log4j.logger.org.mybatis.example.BlogMapper.selectBlog=TRACE # Print a set of mapper logs log4j.logger.org.mybatis.example=TRACE # You only want to view the SQL statement and ignore the result set, which is generally used in the scenario of returning a large amount of data (because the log level of the SQL statement is DEBUG and the returned result set is TRACE) log4j.logger.org.mybatis.example=DEBUG
Configuration file Log4J The rest of properties is used to configure the appender, which is beyond the scope of this document. For more information about Log4J, please refer to the official website of Log4J.
Chapter II detailed explanation of main configuration file
The MyBatis configuration file contains settings and attribute information that will deeply affect MyBatis behavior. The top-level structure of the configuration document is as follows:
- configuration
- properties
- settings
- typeAliases
- typeHandlers
- objectFactory (object factory)
- plugins
- environments
- Environment (environment variable)
- Transaction manager
- dataSource
- Environment (environment variable)
- databaseIdProvider (database vendor ID)
- mappers
In the development process, you can refer to the DTD constraint in the header of the configuration file for configuration!
Section 1 properties tab
1. Definition and use of property
Property is a key value pair, which can be defined directly inside the properties tag with a property sub tag, or imported from an external resource file, and can be replaced dynamically.
<properties resource="org/mybatis/example/config.properties"> <property name="username" value="dev_user"/> <property name="password" value="F2Fa3!33TYyg"/> </properties>
tips: properties tag can also use url attribute to introduce network resources or local disk files.
The set attributes can be used in the whole configuration file to replace the attribute values that need to be dynamically configured.
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
The placeholders ${username} and ${password} in this example will be replaced by the corresponding values set in the property tag. d r i v e r ∗ ∗ and ∗ ∗ {driver} * * and** driver **** and ****{url} will be configured by config Replace with the corresponding value in the properties file. This provides many flexible options for configuration.
In addition, you can also use sqlsessionfactorybuilder Pass in the attribute value in the build () method. For example:
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader, props); // ... Or SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader, environment, props);
2. Priority of property
If a property is configured in more than one place, MyBatis will be loaded in the following order:
- First read the properties specified in the properties tag body.
- Then read the property file under the classpath according to the resource attribute in the properties element, or read the property file according to the path specified by the url attribute, and overwrite the previously read property with the same name.
- Finally, read the attribute passed as a method parameter and overwrite the previously read attribute with the same name.
Therefore, the attributes passed through the method parameters have the highest priority, followed by the configuration file specified in the resource/url attribute, and the attributes specified in the properties element have the lowest priority.
3. Set the default value of placeholder
Starting with MyBatis 3.4.2, you can specify a default value for placeholders. For example:
<dataSource type="POOLED">
<!-- If attribute 'username' Not configured,'username' The value of the property will be 'ut_user' -->
<property name="username" value="${username:ut_user}"/>
</dataSource>
This feature is off by default. To enable this feature, you need to add a specific property to enable this feature.
<properties resource="org/mybatis/example/config.properties">
<!-- Enable default value property -->
<property name="org.apache.ibatis.parsing.PropertyParser.enable-default-value" value="true"/>
</properties>
Since the separator of the default value of the placeholder is:, by default, if you use the ":" character in the property name (such as db:username), or use the ternary operator of OGNL expression in SQL mapping (such as ${tablename! = null? Tablename: 'global_constants'}), you need to set specific properties to modify the character separating the property name and the default value.
<properties resource="org/mybatis/example/config.properties">
<!-- Modify the separator of the default value -->
<property name="org.apache.ibatis.parsing.PropertyParser.default-value-separator" value="?:"/>
</properties>
<dataSource type="POOLED">
<!-- If attribute 'db:username' Not configured,'db:username' The value of the property will be 'ut_user' -->
<property name="username" value="${db:username?:ut_user}"/>
</dataSource>
Section 2 settings tab
The settings tab is a very important adjustment setting in MyBatis. They will change the runtime behavior of MyBatis. The following table describes the meaning and default values of each setting in the setting.
| Set name | describe | Effective value |
|---|---|---|
| cacheEnabled | Globally turn on or off any cache configured in all mapper profiles. | true | false |
| lazyLoadingEnabled | Global switch for delayed loading. When turned on, all associated objects are loaded late. In a specific association relationship, the switch state of the item can be overridden by setting the fetchType property. | true | false |
| aggressiveLazyLoading | When on, the call of any method will load all the deferred load properties of the object. Otherwise, each deferred load attribute will be loaded on demand (refer to lazyLoadTriggerMethods). | true | false |
| multipleResultSetsEnabled | Whether to allow a single statement to return multiple result sets (database driver support is required). | true | false |
| useColumnLabel | Use column labels instead of column names. The actual performance depends on the database driver, For details, please refer to the relevant documents driven by the database, or observe through comparative test. | true | false |
| useGeneratedKeys | Allow JDBC to support automatic generation of primary keys, which requires database driver support. If set to true, the auto generated primary key is enforced. Although some database drivers do not support this feature, it still works (such as Derby). | true | false |
| autoMappingBehavior | Specify how MyBatis should automatically map columns to fields or attributes. NONE means to turn off automatic mapping; PARTIAL automatically maps only fields that do not have nested result mappings defined. FULL automatically maps any complex result set (whether nested or not). | NONE, PARTIAL, FULL |
| autoMappingUnknown ColumnBehavior | Specifies the behavior of discovering unknown columns (or unknown attribute types) that are automatically mapped to. NONE: no reaction WARNING: output WARNING log ('org.apache.ibatis.session<br />.AutoMappingUnknownColumnBehavior' Log level of must be set to WARN) Failed: mapping failed (sqlsessionexception thrown) | NONE, WARNING, FAILING |
| defaultExecutorType | Configure the default actuator. SIMPLE is an ordinary actuator; The REUSE executor will REUSE the prepared statement; BATCH executors not only reuse statements, but also perform BATCH updates. | SIMPLE REUSE BATCH |
| defaultStatementTimeout | Set the timeout, which determines the number of seconds the database driver waits for a database response. | Any positive integer |
| defaultFetchSize | Set a recommended value for the fetchSize of the driven result set. This parameter can only be overridden in query settings. | Any positive integer |
| defaultResultSetType | Specifies the default scrolling policy for the statement. (added to 3.5.2) | FORWARD_ONLY | SCROLL_SENSITIVE | SCROLL_INSENSITIVE | DEFAULT (equivalent to not set) |
| safeRowBoundsEnabled | Whether paging (rowboundaries) is allowed in nested statements. Set to false if allowed. | true | false |
| safeResultHandler Enabled | Whether to allow the use of result handler in nested statements. Set to false if allowed. | true | false |
| mapUnderscore ToCamelCase | Whether to enable automatic hump naming mapping, that is, underline column name mapping small hump attribute name. | true | false |
| localCacheScope | MyBatis uses a local caching mechanism to prevent circular references and speed up repeated nested queries. The default value is SESSION, which caches all queries executed in a SESSION. If the value is set to state, the local cache will only be used to execute statements, and different queries of the same SqlSession will not be cached. | SESSION | STATEMENT |
| jdbcTypeForNull | When no specific JDBC type is specified for the parameter, the default JDBC type of null value. Some database drivers need to specify the JDBC type of columns. In most cases, they can directly use the general type, such as NULL, VARCHAR or OTHER. | JdbcType constant, common values: NULL, VARCHAR, or OTHER. |
| lazyLoadTriggerMethods | Specifies which methods of the object trigger a deferred load. | Comma separated list of methods. equals,clone,hashCode,toString |
| defaultScriptingLanguage | Specifies the default scripting language used for dynamic SQL generation. | A type alias or fully qualified class name. org.apache.ibatis.scripting .xmltags.XMLLanguageDriver |
| defaultEnumTypeHandler | Specifies the default TypeHandler used by Enum. (added to 3.4.5) | A type alias or fully qualified class name. org.apache.ibatis.type .EnumTypeHandler |
| callSettersOnNulls | Specifies whether to call the setter (put) method of the mapping object when the value in the result set is null, which depends on the map Keyset() or null value is useful for initialization. Note that basic types (int, boolean, etc.) cannot be set to null. | true | false |
| returnInstance ForEmptyRow | When all columns of the returned row are empty, MyBatis returns null by default. When this setting is enabled, MyBatis will return an empty instance. Note that it also applies to nested result sets, such as collections or associations. (added to 3.4.2) | true | false |
| logPrefix | Specifies the prefix that MyBatis adds to the log name. | Any string |
| logImpl | Specify the specific implementation of the log used by MyBatis. If it is not specified, it will be found automatically. | SLF4J | LOG4J | LOG4J2 | JDK_LOGGING | COMMONS_LOGGING | STDOUT_LOGGING | NO_LOGGING |
| proxyFactory | Specifies the proxy tool used by Mybatis to create deferred loading objects. | CGLIB | JAVASSIST |
| vfsImpl | Specify the implementation of VFS | The fully qualified names of the classes implemented by the custom VFS are separated by commas. |
| useActualParamName | It is allowed to use the name in the method signature as the statement parameter name. In order to use this feature, your project must be compiled in Java 8 with the - parameters option. (added to 3.4.1) | true | false |
| configurationFactory | Specify a class that provides an instance of Configuration. The returned Configuration instance is used to load the deferred load property value of the deserialized object. This class must contain a method with the signature static Configuration getConfiguration(). (added to 3.2.3) | A type alias or fully qualified class name. |
| shrinkWhitespacesInSql | Remove extra space characters from SQL. Note that this also affects text strings in SQL. (added to 3.5.5) | true | false |
| defaultSqlProviderType | Specifies an sql provider class that holds provider method (Since 3.5.6). This class apply to the type(or value) attribute on sql provider annotation(e.g. @SelectProvider), when these attribute was omitted. | A type alias or fully qualified class name |
The following is an example of configuring the complete settings element.
<settings> <setting name="cacheEnabled" value="true"/> <setting name="lazyLoadingEnabled" value="true"/> <setting name="multipleResultSetsEnabled" value="true"/> <setting name="useColumnLabel" value="true"/> <setting name="useGeneratedKeys" value="false"/> <setting name="autoMappingBehavior" value="PARTIAL"/> <setting name="autoMappingUnknownColumnBehavior" value="WARNING"/> <setting name="defaultExecutorType" value="SIMPLE"/> <setting name="defaultStatementTimeout" value="25"/> <setting name="defaultFetchSize" value="100"/> <setting name="safeRowBoundsEnabled" value="false"/> <setting name="mapUnderscoreToCamelCase" value="false"/> <setting name="localCacheScope" value="SESSION"/> <setting name="jdbcTypeForNull" value="OTHER"/> <setting name="lazyLoadTriggerMethods" value="equals,clone,hashCode,toString"/> </settings>
Section 3 typeAliases label
1. Configure the alias of JavaBean
Type alias sets an abbreviated name for a Java type. It is only used for XML configuration and is intended to reduce redundant fully qualified class name writing. For example:
<typeAliases> <typeAlias alias="Author" type="domain.blog.Author"/> <typeAlias alias="Blog" type="domain.blog.Blog"/> </typeAliases>
When configured in this way, blog can be used in any domain blog. Blog place.
You can also specify a package name. MyBatis will search for the required Java beans under the package name, such as:
<typeAliases> <package name="domain.blog"/> </typeAliases>
Each one is in the package domain The Java Bean in the blog will use the initial lowercase unqualified class name of the bean as its alias without annotation. For example, domain blog. The alias of author is author; If there is an annotation, the alias is its annotation value. See the following example:
@Alias("author")
public class Author {
...
}
2. Built in type alias
Here are some built-in type aliases for common Java types. They are case insensitive. Note that in order to deal with the naming repetition of the original type, a special naming style is adopted.
| alias | Type of mapping |
|---|---|
| _byte | byte |
| _long | long |
| _short | short |
| _int | int |
| _integer | int |
| _double | double |
| _float | float |
| _boolean | boolean |
| string | String |
| byte | Byte |
| long | Long |
| short | Short |
| int | Integer |
| integer | Integer |
| double | Double |
| float | Float |
| boolean | Boolean |
| date | Date |
| decimal | BigDecimal |
| bigdecimal | BigDecimal |
| object | Object |
| map | Map |
| hashmap | HashMap |
| list | List |
| arraylist | ArrayList |
| collection | Collection |
| iterator | Iterator |
Section 4 typehandlers label
1. Default processor type
When MyBatis sets the parameters in the prepared statement or takes a value from the result set, it will use the type processor to convert the obtained value into Java type in an appropriate way. The following table describes some of the default processor types
| Type processor | Java type | JDBC type |
|---|---|---|
| BooleanTypeHandler | java.lang.Boolean, boolean | Database compatible BOOLEAN |
| ByteTypeHandler | java.lang.Byte, byte | Database compatible NUMERIC or BYTE |
| ShortTypeHandler | java.lang.Short, short | Database compatible NUMERIC or SMALLINT |
| IntegerTypeHandler | java.lang.Integer, int | Database compatible NUMERIC or INTEGER |
| LongTypeHandler | java.lang.Long, long | Database compatible NUMERIC or BIGINT |
| FloatTypeHandler | java.lang.Float, float | Database compatible NUMERIC or FLOAT |
| DoubleTypeHandler | java.lang.Double, double | Database compatible NUMERIC or DOUBLE |
| BigDecimalTypeHandler | java.math.BigDecimal | Database compatible NUMERIC or DECIMAL |
| StringTypeHandler | java.lang.String | CHAR, VARCHAR |
| ClobReaderTypeHandler | java.io.Reader | - |
| ClobTypeHandler | java.lang.String | CLOB, LONGVARCHAR |
| NStringTypeHandler | java.lang.String | NVARCHAR, NCHAR |
| NClobTypeHandler | java.lang.String | NCLOB |
| BlobInputStreamTypeHandler | java.io.InputStream | - |
| ByteArrayTypeHandler | byte[] | Database compatible byte stream type |
| BlobTypeHandler | byte[] | BLOB, LONGVARBINARY |
| DateTypeHandler | java.util.Date | TIMESTAMP |
| DateOnlyTypeHandler | java.util.Date | DATE |
| TimeOnlyTypeHandler | java.util.Date | TIME |
| SqlTimestampTypeHandler | java.sql.Timestamp | TIMESTAMP |
| SqlDateTypeHandler | java.sql.Date | DATE |
| SqlTimeTypeHandler | java.sql.Time | TIME |
| ObjectTypeHandler | Any | OTHER or unspecified type |
| EnumTypeHandler | Enumeration Type | VARCHAR, or any compatible string type, is used to store the name of the enumeration (not the index order value) |
| EnumOrdinalTypeHandler | Enumeration Type | Any compatible NUMERIC or DOUBLE type used to store the ordinal value (not the name) of the enumeration. |
| SqlxmlTypeHandler | java.lang.String | SQLXML |
| InstantTypeHandler | java.time.Instant | TIMESTAMP |
| LocalDateTimeTypeHandler | java.time.LocalDateTime | TIMESTAMP |
| LocalDateTypeHandler | java.time.LocalDate | DATE |
| LocalTimeTypeHandler | java.time.LocalTime | TIME |
| OffsetDateTimeTypeHandler | java.time.OffsetDateTime | TIMESTAMP |
| OffsetTimeTypeHandler | java.time.OffsetTime | TIME |
| ZonedDateTimeTypeHandler | java.time.ZonedDateTime | TIMESTAMP |
| YearTypeHandler | java.time.Year | INTEGER |
| MonthTypeHandler | java.time.Month | INTEGER |
| YearMonthTypeHandler | java.time.YearMonth | VARCHAR or LONGVARCHAR |
| JapaneseDateTypeHandler | java.time.chrono.JapaneseDate | DATE |
tips: starting from 3.4.5, MyBatis supports JSR-310 (date and time API) by default
2. Custom type processor
You can create your own type processor or override existing type processors to handle unsupported or non-standard types. Just need to implement org apache. ibatis. type
. TypeHandler interface, or inherit a convenient class org apache. ibatis. type. Basetypehandler and optionally map it to a JDBC type.
// ExampleTypeHandler.java maps java type String to JDBC type VARCHAR
@MappedJdbcTypes(JdbcType.VARCHAR)
public class ExampleTypeHandler extends BaseTypeHandler<String> {
@Override
public void setNonNullParameter(PreparedStatement ps, int i, String parameter, JdbcType jdbcType) throws SQLException {
ps.setString(i, parameter);
}
@Override
public String getNullableResult(ResultSet rs, String columnName) throws SQLException {
return rs.getString(columnName);
}
@Override
public String getNullableResult(ResultSet rs, int columnIndex) throws SQLException {
return rs.getString(columnIndex);
}
@Override
public String getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {
return cs.getString(columnIndex);
}
}
If you want this type of processor to take effect, you must configure it in the typehandlers tag of the main configuration file so that the interceptor chain can be called.
<!-- mybatis-config.xml -->
<typeHandlers>
<!-- Register custom type processor -->
<typeHandler handler="org.mybatis.example.ExampleTypeHandler"/>
<!-- You can also use the auto find type processor(Note: at this time JDBC The type of can only be specified by annotation) -->
<!-- <package name="org.mybatis.example"/> -->
</typeHandlers>
Using the above type processor will overwrite the existing type processor that handles the properties of Java String type and the parameters and results of VARCHAR type** Note that MyBatis will not determine which type to use by detecting the database meta information, so you must indicate that the field is of VARCHAR type in the parameter and result mapping so that it can be bound to the correct type processor** This is because MyBatis does not know the data type until the statement is executed.
Through the generics of the type processor, MyBatis can know the Java types handled by the type processor, but this behavior can be changed in two ways:
- Add a javaType attribute (for example, javaType="String") on the configuration element (typeHandler element) of the type processor;
- Add a @ MappedTypes annotation on the class of the type processor to specify the list of Java types associated with it. If the property specified in the javaType configuration is also ignored.
You can also specify the associated JDBC type in two ways:
- Add a jdbcType attribute on the configuration element of the type processor (for example: jdbcType="VARCHAR");
- Add a @ MappedJdbcTypes annotation on the class of the type processor to specify the list of JDBC types associated with it. If it is also specified in the jdbcType attribute, the configuration on the annotation will be ignored.
When deciding which type of processor to use in the ResultMap, the Java type is known (obtained from the result type), but the JDBC type is unknown. Therefore, Mybatis uses a combination of javaType=[Java type] and JDBC type = null to select a processor type. This means that using the @ MappedJdbcTypes annotation limits the scope of the type processor and ensures that the type processor will not take effect in the ResultMap unless explicitly set. If you want to use the type processor implicitly in the ResultMap, you can set the includeNullJdbcType=true of the @ MappedJdbcTypes annotation. However, starting from Mybatis 3.4.0, if a Java type has only one registered type processor, even if includeNullJdbcType=true is not set, this type processor will also be the default processor when ResultMap uses Java type.
3. Generic type processor
You can create generic type processors that can handle multiple classes. In order to use a generic type processor, you need to add a constructor that accepts the class of this class as a parameter, so MyBatis will pass in a specific class when constructing a type processor instance.
//GenericTypeHandler.java
public class GenericTypeHandler<E extends MyObject> extends BaseTypeHandler<E> {
private Class<E> type;
public GenericTypeHandler(Class<E> type) {
if (type == null) throw new IllegalArgumentException("Type argument cannot be null");
this.type = type;
}
...
EnumTypeHandler and EnumOrdinalTypeHandler are both generic type processors, which we will discuss in detail in the next section.
If you want to map Enum type, you need to select one from EnumTypeHandler or EnumOrdinalTypeHandler to use.
- EnumTypeHandler
For example, we want to store the rounding pattern used when taking approximate values. By default, MyBatis will use EnumTypeHandler to convert Enum value to corresponding name.
Note that EnumTypeHandler is special in a sense. Other processors only target a specific class. Unlike it, it will handle any class that inherits Enum.
- EnumOrdinalTypeHandler
However, we may not want to store names. Instead, our DBA will insist on using integer value code. That's just as simple: add EnumOrdinalTypeHandler to typeHandlers in the configuration file, so that each RoundingMode will be mapped to the corresponding integer value through their ordinal value.
<!-- mybatis-config.xml --> <typeHandlers> <typeHandler handler="org.apache.ibatis.type.EnumOrdinalTypeHandler" javaType="java.math.RoundingMode"/> </typeHandlers>
But what if you want to map Enum to a string in one place and an integer value in another? Auto mapper will automatically select EnumOrdinalTypeHandler to handle enumeration types, so if we want to use ordinary EnumTypeHandler, we must explicitly set the type processor to be used for those SQL statements.
<!-- stay resultMap Enumeration type processor specified in -->
<resultMap type="org.apache.ibatis.submitted.rounding.User" id="usermap2">
<id column="id" property="id"/>
<result column="name" property="name"/>
<result column="funkyNumber" property="funkyNumber"/>
<result column="roundingMode" property="roundingMode"
typeHandler="org.apache.ibatis.type.EnumTypeHandler"/>
</resultMap>
<!-- Specifies the enumeration type processor in the inline parameter mapping -->
<insert id="insert2">
insert into users2 (id, name, funkyNumber, roundingMode) values (
#{id}, #{name}, #{funkyNumber}, #{roundingMode, typeHandler=org.apache.ibatis.type.EnumTypeHandler}
)
</insert>
Section V objectFactory label
Every time MyBatis creates a new instance of the result object, it uses an object factory instance to complete the instantiation. The default object factory only needs to instantiate the target class, either through the default parameterless construction method, or through the existing parameter mapping to call the construction method with parameters. If you want to override the default behavior of the object factory, you can create your own object factory. For example:
// ExampleObjectFactory.java
public class ExampleObjectFactory extends DefaultObjectFactory {
public Object create(Class type) {
return super.create(type);
}
public Object create(Class type, List<Class> constructorArgTypes, List<Object> constructorArgs) {
return super.create(type, constructorArgTypes, constructorArgs);
}
public void setProperties(Properties properties) {
super.setProperties(properties);
}
public <T> boolean isCollection(Class<T> type) {
return Collection.class.isAssignableFrom(type);
}}
<!-- mybatis-config.xml --> <objectFactory type="org.mybatis.example.ExampleObjectFactory"> <property name="someProperty" value="100"/> </objectFactory>
The ObjectFactory interface is very simple. It contains two methods for creating instances. One is to deal with the default parameterless construction method, and the other is to deal with the construction method with parameters. In addition, the setProperties method can be used to configure ObjectFactory. After initializing your ObjectFactory instance, the properties defined in the ObjectFactory element body will be passed to the setProperties method.
Section 6 plugins label
MyBatis allows you to intercept calls at some point during the execution of mapping statements. By default, MyBatis allows the use of plug-ins to intercept method calls, including:
- Executor (update, query, flushStatements, commit, rollback, getTransaction, close, isClosed)
- ParameterHandler (getParameterObject, setParameters)
- ResultSetHandler (handleResultSets, handleOutputParameters)
- StatementHandler (prepare, parameterize, batch, update, query)
The details of the methods in these classes can be found by viewing the signature of each method, or directly viewing the source code in the MyBatis distribution package. If you want to do more than just monitor method calls, you'd better have a good understanding of the behavior of the method to be rewritten. Because when trying to modify or rewrite the behavior of existing methods, it is likely to destroy the core module of MyBatis. These are lower level classes and methods, so be careful when using plug-ins.
Through the powerful mechanism provided by MyBatis, using the plug-in is very simple. You only need to implement the Interceptor interface and specify the method signature you want to intercept.
// ExamplePlugin.java
@Intercepts({@Signature(
type= Executor.class,
method = "update",
args = {MappedStatement.class,Object.class})})
public class ExamplePlugin implements Interceptor {
private Properties properties = new Properties();
public Object intercept(Invocation invocation) throws Throwable {
// implement pre processing if need
Object returnObject = invocation.proceed();
// implement post processing if need
return returnObject;
}
public void setProperties(Properties properties) {
this.properties = properties;
}
}
<!-- mybatis-config.xml -->
<plugins>
<plugin interceptor="org.mybatis.example.ExamplePlugin">
<property name="someProperty" value="100"/>
</plugin>
</plugins>
The above plug-in will intercept all "update" method calls in the Executor instance, where the Executor is the internal object responsible for executing the underlying mapping statement.
The prompt override configuration class can also modify the core behavior of mybatis
In addition to using plug-ins to modify the core behavior of MyBatis, you can also achieve this by completely overriding the configuration class. Just inherit the configuration class, override one of the methods, and then pass it to sqlsessionfactorybuilder Build (myconfig) method. Again, this may greatly affect MyBatis's behavior. Please be careful.
Section 7 environment label
1. Configure environment
The environments tag defines the configuration related to the SQL execution environment, and supports the definition of multiple environment sub tags.
<environments default="development">
<!--Development environment: development-->
<environment id="development">
<transactionManager type="JDBC">
<property name="..." value="..."/>
</transactionManager>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
<!-- other environment Sub tag-->
</environments>
Although multiple environments can be configured, only one can be selected for each SqlSessionFactory instance. To specify which environment to create, you must pass it as an optional parameter to SqlSessionFactoryBuilder. The signatures of the two methods that can accept the environment configuration are as follows. If the environment parameters are ignored, the default environment will be loaded.
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader, environment); SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader, environment, properties);
2. Transaction manager
There are two types of transaction managers in MyBatis:
-
JDBC directly uses JDBC's commit and rollback facilities. It relies on the connection obtained from the data source to manage the transaction scope.
-
MANAGED uses containers to manage the entire lifecycle of transactions. A connection is never committed or rolled back, but it closes the connection by default.
- When the container is closed, the manager does not want to use the default attribute of closed to block the closing of transactions.
- If you are using Spring + MyBatis, there is no need to configure the transaction manager, because the Spring module will use its own manager to override the previous configuration.
JDBC and MANAGED are actually type aliases. In other words, you can replace them with the fully qualified name or type alias of the TransactionFactory interface implementation class.
public interface TransactionFactory {
default void setProperties(Properties props) {
// Empty implementation (starting from 3.5.2, this method is the default method)
}
Transaction newTransaction(Connection conn);
Transaction newTransaction(DataSource dataSource, TransactionIsolationLevel level, boolean autoCommit);
}
After the Transaction manager is instantiated, all the properties configured in the XML will be passed to the setProperties() method. Your implementation also needs to create an implementation class of the Transaction interface, which is also very simple:
public interface Transaction {
Connection getConnection() throws SQLException;
void commit() throws SQLException;
void rollback() throws SQLException;
void close() throws SQLException;
Integer getTimeout() throws SQLException;
}
Using these two interfaces, you can completely customize the transaction processing of MyBatis.
3. Data source
The dataSource tag uses the standard JDBC data source interface to configure the resources of the JDBC connection object. There are three types of built-in data sources:
- The implementation of UNPOOLED data source will open and close the connection every time it is requested.
- Driver this is the fully qualified name of the JDBC driven Java class (not the data source class that may be included in the jdbc driver).
- url this is the JDBC URL address of the database.
- username user name to log in to the database.
- Password the password to log in to the database.
- The default transaction isolation level of the transactiondefaulttransaction.
- defaultNetworkTimeout the default network timeout (in milliseconds) that waits for a database operation to complete.
Optionally, you can also pass attributes to the database driver. Just add "driver." to the attribute name Prefix, for example: driver encoding=UTF8. This will be via drivermanager The getconnection (URL, driverproperties) method passes the encoding property with the value of utf8 to the database driver.
-
The implementation of POOLED data source uses the concept of "pool" to organize JDBC connection objects, avoiding the necessary initialization and authentication time when creating new connection instances. In addition to the above mentioned attributes under UNPOOLED, there are more attributes to configure the data source of POOLED:
- poolMaximumActiveConnections maximum number of active connections. Default value: 10.
- poolMaximumIdleConnections the maximum number of free connections.
- poolMaximumCheckoutTime is the time when connections in the pool are checked out before being forcibly returned. The default value is 20000 milliseconds.
- poolTimeToWait gets the connection timeout. After the timeout, print the error log and try to get the connection again. The default value is 20000 milliseconds.
- poolPingEnabled whether to enable detection query. Default value: false.
- poolPingQuery detects the query statement, which is used to check whether the connection works normally and is ready to accept the request. The default is "NO PING QUERY SET".
- poolPingConnectionsNotUsedFor the frequency of detecting queries. The default value is 0 (all connections are detected at every moment, which is generally consistent with poolTimeToWait).
- poolMaximumLocalBadConnectionTolerance is the underlying setting of bad connection tolerance. The default value is 3 (added to 3.4.5).
-
The implementation of JNDI data source is to be used in containers such as EJB or application server. The container can configure the data source centrally or externally, and then place a data source reference of JNDI context. This data source configuration requires only two attributes:
- initial_ The context attribute is used to find the context in the InitialContext (that is, initialContext.lookup(initial_context)).
This is an optional attribute. If it is ignored, data will be found directly from InitialContext_ Source attribute. - data_source this is the context path that references the location of the data source instance.
Initial is provided_ When the context is configured, it will be found in the returned context. If it is not provided, it will be found directly in InitialContext.
- initial_ The context attribute is used to find the context in the InitialContext (that is, initialContext.lookup(initial_context)).
Similar to other data source configurations, you can add the prefix "env." Pass the property directly to InitialContext. For example: env encoding=UTF8. This will pass the encoding attribute with the value of utf8 to its constructor when initializcontext is instantiated.
You can implement the interface org apache. ibatis. datasource. Datasourcefactory to use third-party data sources to implement:
public interface DataSourceFactory {
void setProperties(Properties props);
DataSource getDataSource();
}
org.apache.ibatis.datasource.unpooled.UnpooledDataSourceFactory can be used as a parent class to build a new data source adapter, such as the following code necessary to insert C3P0 data source:
import org.apache.ibatis.datasource.unpooled.UnpooledDataSourceFactory;
import com.mchange.v2.c3p0.ComboPooledDataSource;
public class C3P0DataSourceFactory extends UnpooledDataSourceFactory {
public C3P0DataSourceFactory() {
this.dataSource = new ComboPooledDataSource();
}
}
In order to make it work, remember to add corresponding properties to each setter method you want MyBatis to call in the configuration file. The following is an example of connecting to a PostgreSQL database:
<dataSource type="org.myproject.C3P0DataSourceFactory"> <property name="driver" value="org.postgresql.Driver"/> <property name="url" value="jdbc:postgresql:mydb"/> <property name="username" value="postgres"/> <property name="password" value="root"/> </dataSource>
Prompt data source configuration is optional, but if you want to enable the delayed load feature, you must configure the data source.
Section 8 databaseIdProvider label
MyBatis can execute different statements according to different database vendors. This multi vendor support is based on the databaseId attribute in the mapping statement. MyBatis loads statements with and without the databaseId attribute that match the current database. If the same statement with and without databaseId is found at the same time, the latter will be discarded.
To support the multi vendor feature, just click mybatis config Add databaseIdProvider to the XML file:
<databaseIdProvider type="DB_VENDOR" />
DB corresponding to databaseIdProvider_ Vendor implementation will set databaseId to the string returned by DatabaseMetaData#getDatabaseProductName(). Since these strings are usually very long and different versions of the same product will return different values, you may want to shorten them by setting the property alias:
<databaseIdProvider type="DB_VENDOR"> <property name="SQL Server" value="sqlserver"/> <property name="DB2" value="db2"/> <property name="Oracle" value="oracle" /> </databaseIdProvider>
When a property alias is provided, the DB of databaseIdProvider_ Vendor implementation will set databaseId to the value that matches the first name in the database product name and attribute. If there is no matching attribute, it will be set to "null". In this example, if getDatabaseProductName() returns "Oracle (DataDirect)", databaseId will be set to "oracle".
You can implement the interface org apache. ibatis. mapping. DatabaseIdProvider and in mybatis config Register in XML to build your own DatabaseIdProvider:
public interface DatabaseIdProvider {
default void setProperties(Properties p) {
// Empty implementation (starting from 3.5.2, this method is the default method)
}
String getDatabaseId(DataSource dataSource) throws SQLException;
}
Section 9 mappers label
Now that the behavior of MyBatis has been configured by the above elements, we will now define the SQL mapping statement. But first, we need to tell MyBatis where to find these statements. Java does not provide a good solution for automatically finding resources, so the best way is to directly tell MyBatis where to find the mapping file. You can use resource references relative to the classpath, or fully qualified resource locators (including URL s in the form of file: / / / or class and package names).
<!-- Use resource references relative to Classpaths --> <mappers> <mapper resource="org/mybatis/builder/AuthorMapper.xml"/> <mapper resource="org/mybatis/builder/BlogMapper.xml"/> <mapper resource="org/mybatis/builder/PostMapper.xml"/> </mappers> <!-- Use fully qualified resource locators( URL) --> <mappers> <mapper url="file:///var/mappers/AuthorMapper.xml"/> <mapper url="file:///var/mappers/BlogMapper.xml"/> <mapper url="file:///var/mappers/PostMapper.xml"/> </mappers> <!-- Use the mapper interface to implement the fully qualified class name of the class --> <mappers> <mapper class="org.mybatis.builder.AuthorMapper"/> <mapper class="org.mybatis.builder.BlogMapper"/> <mapper class="org.mybatis.builder.PostMapper"/> </mappers> <!-- Register all the mapper interface implementations in the package as mappers --> <mappers> <package name="org.mybatis.builder"/> </mappers>
These configurations will tell MyBatis where to find the mapping file. The remaining details should be each SQL mapping file, which is what we will discuss next.
Chapter 3 detailed explanation of mapping configuration file
The real power of MyBatis lies in its statement mapping, which is its magic. Because of its extraordinary power, the XML file of the mapper is relatively simple. If you compare it with JDBC code with the same function, you will immediately find that nearly 95% of the code is saved. MyBatis is committed to reducing the use cost and enabling users to focus more on SQL code.
The SQL mapping file has only a few top-level elements (listed in the order that they should be defined):
- Cache – the cache configuration for this namespace.
- Cache ref – refers to the cache configuration of other namespaces.
- resultMap – describes how to load objects from the database result set. It is the most complex and powerful element.
- parameterMap – old style parameter mapping. This element has been discarded and may be removed in the future! Please use inline parameter mapping. This element is not described in the document.
- sql – other sentences that can be quoted.
- Insert – map insert statements.
- Update – map update statements.
- Delete – map delete statements.
- select – map query statements.
The details of each element will be described below, starting with the statement itself.
Section 1 statement definition label
1. select tag
The select tag is one of the most commonly used tags in MyBatis. Here is a simple example of a select tag.
<!-- according to ID Query user -->
<select id="findById" parameterType="int" resultType="org.example.model.User">
SELECT * FROM user WHERE id = #{id}
</select>
This statement, named findById, accepts an int (or Integer) parameter and returns an org. Org example. model. Object of type user. Based on this information and some preset default values, MyBatis will create a PreparedStatement and use? To identify the parameters to be passed in. The equivalent JDBC code is as follows:
String findById = "SELECT * FROM user WHERE id = ?"; PreparedStatement ps = conn.prepareStatement(findById); ps.setInt(1,id);
Of course, the function of the select tag is far more than that. The following is an attribute configuration list of the select tag, which is described in detail.
| attribute | describe |
|---|---|
| id | A unique identifier in the namespace that can be used to reference this statement. |
| parameterType | The fully qualified name or alias of the class that will be passed into the parameters of this statement. This property is optional because MyBatis can infer the parameters of the specific incoming statement through the type handler. The default value is unset. |
| parameterMap | The property used to reference external parameterMap has been discarded. Please use inline parameter mapping and parameterType attribute. |
| resultType | The fully qualified name or alias of the class that you expect to return results from this statement. Note that if a collection is returned, it should be set to the type contained in the collection, not the type of the collection itself. Only one can be used between resultType and resultMap at the same time. |
| resultMap | A named reference to an external resultMap. Result mapping is the most powerful feature of MyBatis. If you understand it thoroughly, many complex mapping problems can be solved. Only one can be used between resultType and resultMap at the same time. |
| flushCache | When it is set to true, as long as the statement is called, the local cache and L2 cache will be emptied. The default value is false. |
| useCache | Setting it to true will cause the result of this statement to be cached by the secondary cache. The default value is true for the select element. |
| timeout | This setting is the number of seconds the driver waits for the database to return the requested result before throwing an exception. The default value is unset (database driven). |
| fetchSize | This is a recommended value for the driver. Try to make the number of result lines returned by the driver in batch each time equal to this setting value. The default value is unset (dependent drive). |
| statementType | Optional status, PREPARED or CALLABLE. This will make MyBatis use statement, PreparedStatement or CallableStatement respectively. The default value is PREPARED. |
| resultSetType | FORWARD_ONLY,SCROLL_ SENSITIVE, SCROLL_ Either intrinsic or DEFAULT (equivalent to unset). The DEFAULT value is unset (dependent on database driver). |
| databaseId | If the database vendor ID (databaseIdProvider) is configured, MyBatis will load all statements without databaseId or matching the current databaseId; If there are statements with and without, the statements without will be ignored. |
| resultOrdered | This setting is only applicable to nested result select statements: if it is true, it will be assumed that nested result sets or groups are included. When a main result row is returned, there will be no reference to the previous result set. This makes it possible to get nested result sets without running out of memory. Default: false. |
| resultSets | This setting applies only to multiple result sets. It will list the result sets returned after the statement is executed, and give each result set a name, with multiple names separated by commas. |
The following is an example of a complex select tag attribute configuration. Only for demonstration and actual use, you can select the configuration according to your needs.
<select id="selectPerson" parameterType="int" parameterMap="deprecated" resultType="hashmap" resultMap="personResultMap" flushCache="false" useCache="true" timeout="10" fetchSize="256" statementType="PREPARED" resultSetType="FORWARD_ONLY">
2. insert/update and delete Tags
The implementation of insert/update and delete tags used in the data modification statement is very close, and the configurable attributes are very similar.
| attribute | describe |
|---|---|
| id | A unique identifier in the namespace that can be used to reference this statement. |
| parameterType | The fully qualified name or alias of the class that will be passed into the parameters of this statement. This property is optional because MyBatis can infer the parameters of the specific incoming statement through the type handler. The default value is unset. |
| parameterMap | The property used to reference external parameterMap has been discarded. Please use inline parameter mapping and parameterType attribute. |
| flushCache | When it is set to true, as long as the statement is called, the local cache and L2 cache will be emptied. The default value is (for insert, update and delete statements) true. |
| timeout | This setting is the number of seconds the driver waits for the database to return the requested result before throwing an exception. The default value is unset (database driven). |
| statementType | Optional status, PREPARED or CALLABLE. This will make MyBatis use statement, PreparedStatement or CallableStatement respectively. The default value is PREPARED. |
| useGeneratedKeys | (only applicable to insert and update) this will make MyBatis use the getGeneratedKeys method of JDBC to retrieve the primary key generated inside the database (such as the auto increment field of relational database management systems such as MySQL and SQL Server). The default value is false. |
| keyProperty | (only applicable to insert and update) specify the attribute that can uniquely identify the object. MyBatis will use the return value of getGeneratedKeys or the selectKey sub element of the insert statement to set its value. The default value is unset. If there is more than one generated column, you can separate multiple attribute names with commas. |
| keyColumn | (only applicable to insert and update) set the column name of the generated key value in the table. In some databases (such as PostgreSQL), it must be set when the primary key column is not the first column in the table. If there is more than one generated column, you can separate multiple attribute names with commas. |
| databaseId | If the database vendor ID (databaseIdProvider) is configured, MyBatis will load all statements without databaseId or matching the current databaseId; If there are statements with and without, the statements without will be ignored. |
The following are some configuration examples of insert, update and delete statements:
<insert id="insertAuthor">
insert into Author (id,username,password,email,bio)
values (#{id},#{username},#{password},#{email},#{bio})
</insert>
<update id="updateAuthor">
update Author
set username = #{username},
password = #{password},
email = #{email},
bio = #{bio}
where id = #{id}
</update>
<delete id="deleteAuthor">
delete from Author where id = #{id}
</delete>
3. Auto increment of primary key
There are some additional attributes and sub elements in the insert statement to deal with the generation of primary keys, and a variety of generation methods are provided.
- Use the primary key auto increment function of the database
First, if your database supports fields that automatically generate primary keys (such as MySQL and SQL Server), you can set useGeneratedKeys = "true" and then set keyProperty as the target property. For example, if the above Author table has used automatic generation on the id column, the statement can be modified to:
<insert id="insertAuthor" useGeneratedKeys="true" keyProperty="id">
insert into Author (username,password,email,bio)
values (#{username},#{password},#{email},#{bio})
</insert>
If your database also supports multi row insertion, you can also pass in an Author array or collection and return the automatically generated primary key.
<insert id="insertAuthor" useGeneratedKeys="true" keyProperty="id">
insert into Author (username, password, email, bio) values
<foreach item="item" collection="list" separator=",">
(#{item.username}, #{item.password}, #{item.email}, #{item.bio})
</foreach>
</insert>
- Use the selectKey tag to auto increment the primary key
For databases that do not support automatic generation of primary key columns and JDBC drivers that may not support automatic generation of primary keys, MyBatis has another method to generate primary keys. Here is a simple (and silly) example that can generate a random ID as the primary key.
<insert id="insertAuthor">
<selectKey keyProperty="id" resultType="int" order="BEFORE">
select CAST(RANDOM()*1000000 as INTEGER) a from SYSIBM.SYSDUMMY1
</selectKey>
insert into Author (id, username, password, email,bio, favourite_section)
values (#{id}, #{username}, #{password}, #{email}, #{bio}, #{favouriteSection,jdbcType=VARCHAR})
</insert>
In the above example, the statement in the selectKey element will be run first and the id of the Author will be set, and then the insert statement will be called. This enables the database to automatically generate the behavior similar to the primary key, while maintaining the simplicity of Java code.
The more detailed properties of the selectKey tag are described as follows:
| attribute | describe |
|---|---|
| keyProperty | The target attribute to which the result of the selectKey statement should be set. If there is more than one generated column, you can separate multiple attribute names with commas. |
| keyColumn | Returns the column name of the generated column property in the result set. If there is more than one generated column, you can separate multiple attribute names with commas. |
| resultType | Type of result. Usually MyBatis can be inferred, but for more accuracy, there will be no problem in writing. MyBatis allows any simple type to be used as the type of primary key, including string. If you generate more than one column, you can use an Object or Map that contains the desired attributes. |
| order | Can be set to BEFORE or AFTER. If it is set to BEFORE, it will first generate the primary key, set the keyProperty, and then execute the insert statement. If it is set to AFTER, the insert statement is executed first, and then the statement in the selectKey - this is similar to the behavior of Oracle database. There may be embedded index calls inside the insert statement. |
| statementType | As before, MyBatis supports mapping statements of state, PREPARED and CALLABLE types, representing Statement, PreparedStatement and CallableStatement types respectively. |
4. sql tag
This element can be used to define reusable SQL code fragments for use in other statements. Parameters can be determined statically (when loading), and different parameter values can be defined in different include elements. For example:
<sql id="userColumns"> ${alias}.id,${alias}.username,${alias}.password </sql>
This SQL fragment can be used in other statements, for example:
<select id="selectUsers" resultType="map">
select
<include refid="userColumns"><property name="alias" value="t1"/></include>,
<include refid="userColumns"><property name="alias" value="t2"/></include>
from some_table t1
cross join some_table t2
</select>
You can also use the attribute value in the refid attribute or internal statement of the include element, for example:
<sql id="sometable">
${prefix}Table
</sql>
<sql id="someinclude">
from
<include refid="${include_target}"/>
</sql>
<select id="select" resultType="map">
select
field1, field2, field3
<include refid="someinclude">
<property name="prefix" value="Some"/>
<property name="include_target" value="sometable"/>
</include>
</select>
Section 2 parameter mapping configuration
1. parameterType
All the statements I've seen before use simple parameter forms. But in fact, parameters are very powerful elements of MyBatis. For most simple usage scenarios, you do not need to use complex parameters, such as:
<select id="selectUsers" resultType="User">
select id, username, password
from users
where id = #{id}
</select>
The above example illustrates a very simple named parameter mapping. Since the parameter type will be automatically set to int, this parameter can be named at will. Primitive types or simple data types (such as Integer and String) use their values as parameters because they have no other properties.
However, if you pass in a complex object, the behavior will be a little different. For example:
<insert id="insertUser" parameterType="User">
insert into users (id, username, password)
values (#{id}, #{username}, #{password})
</insert>
If a parameter object of User type is passed into the statement, the id, username and password attributes are looked up, and their values are passed into the parameters of the preprocessing statement.
- If there is only one parameter in SQL, there is no need to pay attention to the parameter name. It's OK to write #{id} as #{uid} in the first example of this section.
- Parameter supports OGNL expression and can be used Number to use members of internal objects. Such as #{user.sex}.
2. In line parameter setting
Each parameter can be configured in #{} more detail, such as java type, jdbc type, type processor and the number of decimal places reserved for the parameter.
#{age,javaType=int,jdbcType=NUMERIC,typeHandler=MyTypeHandler,numericScale=2}
MyBatis can almost always determine the javaType based on the type of parameter object, unless the object is a HashMap. At this time, you need to explicitly specify javaType to ensure that the correct type handler is used.
**Prompt * * JDBC requires that if a column allows null values and will use null parameters, the JDBC type must be specified. Read Preparedstatement Setnull() to get more information.
IN addition to the above configuration, you can also use the mode attribute to specify each parameter as an IN, OUT or INOUT parameter.
- If the mode of the parameter is OUT or INOUT, the property value of the parameter object will be modified to return as an output parameter.
- If the mode is OUT (or INOUT) and the JDBC type is CURSOR (that is, Oracle's REFCURSOR), you must specify a ResultMap reference to map the result set ResultMap to the type of the parameter. Note that the javaType attribute here is optional. If it is left blank and the JDBC type is CURSOR, it will be automatically set to ResultMap.
#{department, mode=OUT, jdbcType=CURSOR, javaType=ResultSet, resultMap=departmentResultMap}
MyBatis also supports many advanced data types, such as structures, but when using the out parameter, you must explicitly set the name of the type. For example (prompt again, in practice, it should be like this, and line breaks are not allowed):
#{middleInitial, mode=OUT, jdbcType=STRUCT, jdbcTypeName=MY_TYPE, resultMap=departmentResultMap}
Although the above options are powerful, most of the time, you only need to specify the attribute name simply, and specify the JDBC type for the column that may be empty at most. The rest is left to MyBatis to infer. Here are some examples that are commonly used.
#{firstName}
#{middleInitial,jdbcType=VARCHAR}
#{lastName}
3. Use of ${}
By default, when using #{} parameter syntax, MyBatis creates a placeholder for the PreparedStatement parameter and sets the parameter safely through the placeholder (just like using?). This is safer and faster, which is usually the first choice, but sometimes you just want to insert a non escaped string directly into the SQL statement. For example, in the ORDER BY clause, you can:
ORDER BY ${columnName}
In this way, MyBatis will not modify or escape the string.
String replacement is very useful when the metadata (such as table name or column name) in SQL statement is generated dynamically.
@Select("select * from user where ${column} = #{value}")
User findByColumn(@Param("column") String column, @Param("value") String value);
Where ${column} will be directly replaced, and #{value} will use? Pretreatment. This method is also applicable to the case of replacing table names.
Warning it is unsafe to accept user input in this way and use it as a statement parameter, which will lead to potential SQL injection attacks. Therefore, the user is either not allowed to enter these fields, or escape and verify these parameters.
Section 3 result mapping configuration
1. ResultType
- Map to base type. When SQL returns a single column result set, it can be mapped directly to the basic type.
<!-- Get the total number of user records -->
<select id="findTotal" resultType="int">
select count(id) from user;
</select>
- Map to HashMap object. Mapping result sets to HashMap objects is supported in most cases.
<select id="selectUsers" resultType="map">
select id, username, hashedPassword from some_table where id = #{id}
</select>
- Mapping to Java beans. Mapping to JavaBean s is a better choice.
<select id="selectUsers" resultType="com.someapp.model.User">
select id, username, hashedPassword from some_table where id = #{id}
</select>
You can use mybatis config The TypeAliases tag in the XML file configures the type alias so that you don't have to enter the fully qualified name of the class.
<!-- mybatis-config.xml in -->
<typeAlias type="com.someapp.model.User" alias="User"/>
<!-- SQL mapping XML in -->
<select id="selectUsers" resultType="User">
select id, username, hashedPassword
from some_table
where id = #{id}
</select>
In these cases, MyBatis will automatically create a ResultMap behind the scenes, and then map the columns to the properties of the JavaBean according to the property name. If the column name and attribute name cannot match, you can set the column alias (which is a basic SQL feature) in the SELECT statement to complete the matching. For example:
<select id="selectUsers" resultType="User">
select user_id as "id", user_name as "userName", hashed_password as "hashedPassword"
from some_table where id = #{id}
</select>
2. ResultMap
The resultMap tag is used to deal with complex result mapping. The attribute list and sub tag structure are as follows.
| attribute | describe |
|---|---|
| id | A unique identifier in the current namespace that identifies a result mapping. |
| type | The fully qualified name of the class, or a type alias, maps the result set to the Java class or collection of Java classes. |
| autoMapping | Enable or disable automatic mapping. Default value: unset. Override the global attribute autoMappingBehavior after setting. |
Let's see what happens if we explicitly use an external resultMap in the example just now, which is another way to solve the column name mismatch.
<resultMap id="userResultMap" type="User"> <id property="id" column="user_id" /> <result property="username" column="user_name"/> <result property="password" column="hashed_password"/> </resultMap>
Then set the resultMap attribute in the statement referring to it (note that we have removed the resultType attribute).
<select id="selectUsers" resultMap="userResultMap"> select user_id, user_name, hashed_password from some_table where id = #{id} </select>The result and id tags in the above case are the basis of result mapping. Both id and result elements map the value of a column to an attribute or field of a simple data type (String, int, double, Date, etc.). Two elements have the same attributes:
attribute describe property A field or property mapped to a column result. If a JavaBean has a property with this name, it will be used first. Otherwise, MyBatis will look for the field with the given name. In either case, you can use the common dotted form to navigate complex attributes. For example, you can map something simple like "username" or something complex like "address.street.number". column The column name in the database, or the alias of the column. In general, this and is passed to resultset The parameters of the getString (columnname) method are the same. javaType The fully qualified name of a Java class or a type alias (for built-in type aliases, refer to the table above). If you map to a JavaBean, MyBatis can usually infer types. However, if you are mapping to a HashMap, you should explicitly specify a javaType to ensure that the behavior is consistent with expectations. jdbcType JDBC type. For the supported JDBC types, see "supported JDBC types" after this table. You only need to specify the JDBC type on columns that may perform inserts, updates, and deletions and allow null values. This is the requirement of JDBC, not MyBatis. If you are programming directly for JDBC, you need to specify this type for columns that can be null. typeHandler We discussed the default type processor earlier. Using this property, you can override the default processor type. This property value is the fully qualified name of a type processor implementation class, or the type alias. The only difference between the two is that the attribute corresponding to the id element is marked as the identifier of the object and used when comparing object instances. This can improve the overall performance, especially when caching and nested result mapping (that is, connection mapping).
The following are all supported JDBC types. For possible use scenarios in the future, MyBatis supports the following JDBC types through the built-in JDBC type enumeration types.

3. Result object construction
Generally speaking, MyBatis creates the result object through nonparametric construction, and then assigns values through getter/setter methods. However, for some special requirements, such as mapping to immutable classes that do not provide getter/setter methods, we want to initialize them by constructing methods. MyBatis provides a constructor tag for this scenario. The following is a list of properties of the constructor tag:
attribute describe column The column name in the database, or the alias of the column. In general, this and is passed to resultset The parameters of the getString (columnname) method are the same. javaType The fully qualified name of a Java class, or a type alias (for built-in type aliases, refer to the table above). If you map to a JavaBean, MyBatis can usually infer types. However, if you are mapping to a HashMap, you should explicitly specify a javaType to ensure that the behavior is consistent with expectations. jdbcType JDBC type. For the supported JDBC types, see "supported JDBC types" before this table. You only need to specify the JDBC type on columns that may perform inserts, updates, and deletions and allow null values. This is the requirement of JDBC, not MyBatis. If you program directly for JDBC, you need to specify this type for columns that may have null values. typeHandler We discussed the default type processor earlier. Using this property, you can override the default processor type. This property value is the fully qualified name of a type processor implementation class, or a type alias. select The ID of the mapping statement used to load the complex type attribute. It will retrieve data from the column specified in the column attribute and pass it to the select statement as a parameter. Please refer to related elements for details. resultMap The ID of the result map can map the nested result set to an appropriate object tree. It can be used as an alternative to using additional select statements. It can map the results of multi table join operations into a single ResultSet. Such a ResultSet will contain duplicate or partially duplicate result sets. In order to correctly map result sets to nested object trees, MyBatis allows you to "concatenate" result maps to solve the problem of nested result sets. For more information, please refer to the associated elements below. name The name of the constructor parameter. Starting with version 3.4.3, you can write arg elements in any order by specifying specific parameter names. See the explanation above. Suppose we want to map the result set to the following User object through the construction method.
public class User { //... public User(Integer id, String username, int age) { //... } //... }Then the following configuration needs to be made in the resultMap, and the order of arg tags must be consistent with the construction method parameters.
<constructor> <idArg column="id" javaType="int"/> <arg column="username" javaType="String"/> <arg column="age" javaType="_int"/> </constructor>
It is suggested that MyBatis supports the injection of private attributes through violent reflection, but this is not advocated.
When you are dealing with a constructor with multiple formal parameters, it is easy to confuse the order of arg elements. After version 3.4.3, you can reference construction method parameters by name, provided that you add the @ Param annotation, or use the '- parameters' compilation option and enable the useActualParamName option (on by default) to compile the project.
<constructor> <idArg column="id" javaType="int" name="id" /> <arg column="age" javaType="_int" name="age" /> <arg column="username" javaType="String" name="username" /> </constructor>
If there are attributes with the same name and type, javaType can also be omitted.
4. One to one mapping
**The association * * tag handles a relationship of type "has one". For example, in our example, a blog has a user. association result mapping works in much the same way as other types of mapping. You need to specify the target attribute name and the javaType of the attribute (MyBatis can infer it by itself in many cases). You can also set the JDBC type if necessary. If you want to override the process of obtaining the result value, you can also set the type processor.
The difference between associations is that you need to tell MyBatis how to load associations. MyBatis loads associations in two different ways:
- Nested Select query: load the desired complex type by executing another SQL mapping statement.
- Nested result mapping: use nested result mapping to handle duplicate subsets of connected results.
First, let's look at the properties of this element. You will find that compared with the ordinary result mapping, it is only different in the select and resultMap properties.
attribute describe property A field or property mapped to a column result. If the JavaBean used to match has a property with the given name, it will be used. Otherwise, MyBatis will look for the field with the given name. In either case, you can use the usual dot separated form for complex attribute navigation. For example, you can map something simple like "username" or something complex like "address.street.number". javaType The fully qualified name of a Java class, or a type alias (for built-in type aliases, refer to the table above). If you map to a JavaBean, MyBatis can usually infer types. However, if you are mapping to a HashMap, you should explicitly specify a javaType to ensure that the behavior is consistent with expectations. jdbcType JDBC type. For the supported JDBC types, see "supported JDBC types" before this table. You only need to specify the JDBC type on columns that may perform inserts, updates, and deletions and allow null values. This is the requirement of JDBC, not MyBatis. If you program directly for JDBC, you need to specify this type for columns that may have null values. typeHandler We discussed the default type processor earlier. Using this property, you can override the default processor type. This property value is the fully qualified name of a type processor implementation class, or a type alias. Nested Select query
attribute describe column The column name in the database, or the alias of the column. In general, this and is passed to resultset The parameters of the getString (columnname) method are the same. Note: when using composite primary key, you can use the syntax of column="{prop1=col1,prop2=col2}" to specify multiple column names passed to nested Select query statements. This will cause prop1 and prop2 as parameter objects to be set as parameters corresponding to nested Select statements. select The ID of the mapping statement used to load the complex type attribute. It will retrieve data from the column specified by the column attribute and pass it to the target select statement as a parameter. Please refer to the following examples for details. Note: when using composite primary key, you can use the syntax of column="{prop1=col1,prop2=col2}" to specify multiple column names passed to nested select query statements. This will cause prop1 and prop2 as parameter objects to be set as parameters corresponding to nested select statements. fetchType Optional. Valid values are lazy and eager. When a property is specified, the global configuration parameter lazyloading enabled is ignored in the mapping and the value of the property is used. Example:
<resultMap id="blogResult" type="Blog"> <association property="author" column="author_id" javaType="Author" select="selectAuthor"/> </resultMap> <select id="selectBlog" resultMap="blogResult"> SELECT * FROM BLOG WHERE ID = #{id} </select> <select id="selectAuthor" resultType="Author"> SELECT * FROM AUTHOR WHERE ID = #{id} </select>It's that simple. We have two select query statements: one is used to load the Blog and the other is used to load the author, and the result mapping of the Blog describes the author attribute that should be loaded with the select author statement.
All other properties will be loaded automatically as long as their column names match the property names.
Although this method is very simple, it does not perform well on large data sets or large data tables. This problem is called "N+1 query problem". Generally speaking, the N+1 query problem is like this:
- You execute a separate SQL statement to get a list of results (that is "+ 1").
- For each record returned from the list, you execute a select query statement to load the details (i.e. "N") for each record.
This problem can cause hundreds of SQL statements to be executed. Sometimes we don't want the consequences.
The good news is that MyBatis can delay loading such queries, so it can spread the overhead of running a large number of statements at the same time. However, if you traverse the list to get nested data immediately after loading the record list, all delayed loading queries will be triggered, and the performance may become very poor.
So there's another way.
nested result mappings
attribute describe resultMap The ID of the result mapping, which can map the associated nested result set to an appropriate object tree. It can be used as an alternative to using additional select statements. It can map the results of multi table join operations into a single ResultSet. Some of the data in such a ResultSet is duplicate. In order to correctly map result sets to nested object trees, MyBatis allows you to "concatenate" result maps to solve the problem of nested result sets. An example of using nested result mapping is after the table. columnPrefix When connecting multiple tables, you may have to use column aliases to avoid duplicate column names in the ResultSet. Specifying the columnPrefix column name prefix allows you to map columns with these prefixes to an external result map. For details, please refer to the following examples. notNullColumn By default, child objects are created only when at least one column mapped to an attribute is not empty. You can change the default behavior by specifying non empty columns on this attribute. After specifying, Mybatis will create a sub object only when these columns are non empty. You can specify multiple columns using comma separation. Default: unset. autoMapping If this property is set, MyBatis will turn on or off automatic mapping for this result mapping. This attribute overrides the global attribute autoMappingBehavior. Note that this attribute is not valid for external result mapping, so it cannot be used with select or resultMap elements. Default: unset. Previously, you have seen a very complex example of nested associations. The following example is a very simple example to demonstrate how nested result mapping works. Now let's connect the blog table and the author table together instead of executing a separate query statement, like this:
<select id="selectBlog" resultMap="blogResult"> select B.id as blog_id, B.title as blog_title, B.author_id as blog_author_id, A.id as author_id, A.username as author_username, A.password as author_password, A.email as author_email, A.bio as author_bio from Blog B left outer join Author A on B.author_id = A.id where B.id = #{id} </select>Pay attention to the connection in the query and the alias we set to ensure that the result can have a unique and clear name. This makes mapping very simple. Now we can map this result:
<resultMap id="blogResult" type="Blog"> <id property="id" column="blog_id" /> <result property="title" column="blog_title"/> <association property="author" column="blog_author_id" javaType="Author" resultMap="authorResult"/> </resultMap> <resultMap id="authorResult" type="Author"> <id property="id" column="author_id"/> <result property="username" column="author_username"/> <result property="password" column="author_password"/> <result property="email" column="author_email"/> <result property="bio" column="author_bio"/> </resultMap>
In the above example, you can see that the associated element of the Blog author entrusts the result map named "authorResult" to load the instance of the author object.
Important: id element plays a very important role in nested result mapping. You should always specify one or more attributes that uniquely identify the result. Although MyBatis works even if this attribute is not specified, it will cause serious performance problems. You only need to specify the minimum attributes that can uniquely identify the result. Obviously, you can choose a primary key (or a composite primary key).
Now, the above example uses external result mapping elements to map associations. This allows the Author's result mapping to be reused. However, if you don't intend to reuse it, or you prefer to put all your result mappings in a descriptive result mapping element. You can directly nest the result mapping as child elements. Here is an equivalent example of using this method:
<resultMap id="blogResult" type="Blog"> <id property="id" column="blog_id" /> <result property="title" column="blog_title"/> <association property="author" javaType="Author"> <id property="id" column="author_id"/> <result property="username" column="author_username"/> <result property="password" column="author_password"/> <result property="email" column="author_email"/> <result property="bio" column="author_bio"/> </association> </resultMap>What if a blog has a co author? The select statement will look like this:
<select id="selectBlog" resultMap="blogResult"> select B.id as blog_id, B.title as blog_title, A.id as author_id, A.username as author_username, A.password as author_password, A.email as author_email, A.bio as author_bio, CA.id as co_author_id, CA.username as co_author_username, CA.password as co_author_password, CA.email as co_author_email, CA.bio as co_author_bio from Blog B left outer join Author A on B.author_id = A.id left outer join Author CA on B.co_author_id = CA.id where B.id = #{id} </select>Recall that the result mapping of Author is defined as follows:
<resultMap id="authorResult" type="Author"> <id property="id" column="author_id"/> <result property="username" column="author_username"/> <result property="password" column="author_password"/> <result property="email" column="author_email"/> <result property="bio" column="author_bio"/> </resultMap>
Because the column names in the result are different from those in the result map. You need to specify columnPrefix to reuse the result map to map the results of co author.
<resultMap id="blogResult" type="Blog"> <id property="id" column="blog_id" /> <result property="title" column="blog_title"/> <association property="author" resultMap="authorResult" /> <association property="coAuthor" resultMap="authorResult" columnPrefix="co_" /> </resultMap>Multiple result sets
attribute describe column When using multiple result sets, this attribute specifies the columns in the result set that match the foreignColumn (multiple column names are separated by commas) to identify the parent and child types in the relationship. foreignColumn Specify the column name corresponding to the foreign key. The specified column will match the column given by column in the parent type. resultSet Specifies the name of the result set used to load complex types. Starting from version 3.2.3, MyBatis provides another way to solve the N+1 query problem.
Some databases allow stored procedures to return multiple result sets, or execute multiple statements at once, and each statement returns a result set. We can use this feature to access the database only once without using a connection.
In the example, the stored procedure executes the following query and returns two result sets. The first result set returns the results of the Blog, and the second returns the results of the Author.
SELECT * FROM BLOG WHERE ID = #{id} SELECT * FROM AUTHOR WHERE ID = #{id}In the mapping statement, you must specify a name for each result set through the resultSets property, and multiple names are separated by commas.
<select id="selectBlog" resultSets="blogs,authors" resultMap="blogResult" statementType="CALLABLE"> {call getBlogsAndAuthors(#{id,jdbcType=INTEGER,mode=IN})} </select>Now we can specify to use the data of the "authors" result set to populate the "author" Association:
<resultMap id="blogResult" type="Blog"> <id property="id" column="id" /> <result property="title" column="title"/> <association property="author" javaType="Author" resultSet="authors" column="author_id" foreignColumn="id"> <id property="id" column="id"/> <result property="username" column="username"/> <result property="password" column="password"/> <result property="email" column="email"/> <result property="bio" column="bio"/> </association> </resultMap>You have seen how to deal with the "have a" type of association above. But how to deal with the "many" type of association? This is our introduction.
5. One to many mapping
Set tags and associated tags are almost the same. They are so similar that it is unnecessary to introduce the similar parts of set tags. So let's focus on their differences. Let's continue with the above example. A Blog has only one author. But a Blog has many posts. In the Blog class, this can be expressed in the following way:
private List<Post> posts;
To map nested result collections into a List like the above, you can use collection elements. As with associated elements, we can use nested Select queries or nested result mapping collections based on joins.
Nested Select query
First, let's look at how to use nested Select queries to load posts for blogs.
<resultMap id="blogResult" type="Blog"> <collection property="posts" javaType="ArrayList" column="id" ofType="Post" select="selectPostsForBlog"/> </resultMap> <select id="selectBlog" resultMap="blogResult"> SELECT * FROM BLOG WHERE ID = #{id} </select> <select id="selectPostsForBlog" resultType="Post"> SELECT * FROM POST WHERE BLOG_ID = #{id} </select>You may notice several differences immediately, but most of them are very similar to the related elements we learned above. First, you'll notice that we use collection elements. Next you will notice a new "ofType" attribute. This property is very important. It is used to distinguish the type of JavaBean (or field) property from the type of collection storage. So you can read the mapping as follows:
<collection property="posts" javaType="ArrayList" column="id" ofType="Post" select="selectPostsForBlog"/>
It reads: "posts is an ArrayList collection that stores posts."
In general, MyBatis can infer the javaType attribute, so it does not need to be filled in. So many times you can simply say:
<collection property="posts" column="id" ofType="Post" select="selectPostsForBlog"/>
nested result mappings
Now you may have guessed how the nested result mapping of the collection works - except for the new "ofType" attribute, it is exactly the same as the associated one.
First, let's look at the corresponding SQL statement:
<select id="selectBlog" resultMap="blogResult"> select B.id as blog_id, B.title as blog_title, B.author_id as blog_author_id, P.id as post_id, P.subject as post_subject, P.body as post_body, from Blog B left outer join Post P on B.id = P.blog_id where B.id = #{id} </select>We reconnected the blog table and the post table and gave each column a meaningful alias to keep the mapping simple. To map the collection of articles in a blog, it's as simple as this:
<resultMap id="blogResult" type="Blog"> <id property="id" column="blog_id" /> <result property="title" column="blog_title"/> <collection property="posts" ofType="Post"> <id property="id" column="post_id"/> <result property="subject" column="post_subject"/> <result property="body" column="post_body"/> </collection> </resultMap>Again, remember the importance of the id element above. If you don't remember, please read the relevant section of the correlation section.
If you prefer a more detailed and reusable result mapping, you can use the following equivalent form:
<resultMap id="blogResult" type="Blog"> <id property="id" column="blog_id" /> <result property="title" column="blog_title"/> <collection property="posts" ofType="Post" resultMap="blogPostResult" columnPrefix="post_"/> </resultMap> <resultMap id="blogPostResult" type="Post"> <id property="id" column="id"/> <result property="subject" column="subject"/> <result property="body" column="body"/> </resultMap>
Multiple result sets
Like the associated element, we can implement it by executing a stored procedure. It will execute two queries and return two result sets, one is the result set of the blog and the other is the result set of the article:
SELECT * FROM BLOG WHERE ID = #{id} SELECT * FROM POST WHERE BLOG_ID = #{id}In the mapping statement, you must specify a name for each result set through the resultSets property, and multiple names are separated by commas.
<select id="selectBlog" resultSets="blogs,posts" resultMap="blogResult"> {call getBlogsAndPosts(#{id,jdbcType=INTEGER,mode=IN})} </select>We specify that the "posts" collection will be populated with data stored in the "posts" result set:
<resultMap id="blogResult" type="Blog"> <id property="id" column="id" /> <result property="title" column="title"/> <collection property="posts" ofType="Post" resultSet="posts" column="id" foreignColumn="blog_id"> <id property="id" column="id"/> <result property="subject" column="subject"/> <result property="body" column="body"/> </collection> </resultMap>Note that there are no requirements on depth, breadth or combination for the mapping of associations or sets. However, pay attention to performance issues when mapping. In the process of exploring best practices, application unit testing and performance testing will be your good helper. The advantage of MyBatis is that it allows you to change your mind later without introducing major changes to your code, if any.
Advanced association and set mapping is a deep topic. The introduction of the document can only stop here. With a little practice, you will soon understand all the usage. The following is a very complex query mapping case, which can be used as a learning reference.
<!-- Map this query result to an intelligent object model. This object represents a blog, which is written by an author. There are many blog posts, and each blog post has zero or more comments and tags. --> <select id="selectBlogDetails" resultMap="detailedBlogResultMap"> select B.id as blog_id, B.title as blog_title, B.author_id as blog_author_id, A.id as author_id, A.username as author_username, A.password as author_password, A.email as author_email, A.bio as author_bio, A.favourite_section as author_favourite_section, P.id as post_id, P.blog_id as post_blog_id, P.author_id as post_author_id, P.created_on as post_created_on, P.section as post_section, P.subject as post_subject, P.draft as draft, P.body as post_body, C.id as comment_id, C.post_id as comment_post_id, C.name as comment_name, C.comment as comment_text, T.id as tag_id, T.name as tag_name from Blog B left outer join Author A on B.author_id = A.id left outer join Post P on B.id = P.blog_id left outer join Comment C on P.id = C.post_id left outer join Post_Tag PT on PT.post_id = P.id left outer join Tag T on PT.tag_id = T.id where B.id = #{id} </select><!-- Result mapping reference --> <resultMap id="detailedBlogResultMap" type="Blog"> <constructor> <idArg column="blog_id" javaType="int"/> </constructor> <result property="title" column="blog_title"/> <association property="author" javaType="Author"> <id property="id" column="author_id"/> <result property="username" column="author_username"/> <result property="password" column="author_password"/> <result property="email" column="author_email"/> <result property="bio" column="author_bio"/> <result property="favouriteSection" column="author_favourite_section"/> </association> <collection property="posts" ofType="Post"> <id property="id" column="post_id"/> <result property="subject" column="post_subject"/> <association property="author" javaType="Author"/> <collection property="comments" ofType="Comment"> <id property="id" column="comment_id"/> </collection> <collection property="tags" ofType="Tag" > <id property="id" column="tag_id"/> </collection> <discriminator javaType="int" column="draft"> <case value="1" resultType="DraftPost"/> </discriminator> </collection> </resultMap>6. Discriminator
Sometimes, a database query may return multiple different result sets (but there are some connections in general). The discriminator tag is designed to deal with this situation. In addition, it can also deal with other situations, such as the inheritance hierarchy of classes. The concept of discriminator is well understood -- it's much like a switch statement in the Java language.
The definition of a discriminator needs to specify the column and javaType attributes. Column specifies where the MyBatis query is compared. javaType is used to ensure that the correct equality test is used (although in many cases string equality tests work). For example:
<resultMap id="vehicleResult" type="Vehicle"> <id property="id" column="id" /> <result property="vin" column="vin"/> <result property="year" column="year"/> <result property="make" column="make"/> <result property="model" column="model"/> <result property="color" column="color"/> <discriminator javaType="int" column="vehicle_type"> <case value="1" resultMap="carResult"/> <case value="2" resultMap="truckResult"/> <case value="3" resultMap="vanResult"/> <case value="4" resultMap="suvResult"/> </discriminator> </resultMap>In this example, MyBatis takes each record from the result set and compares its vehicle type value. If it matches the case of any discriminator, the result mapping specified by the case will be used. This process is mutually exclusive, that is, the remaining result mapping will be ignored (unless it is extended, which we will discuss later).
If no case can be matched, MyBatis will only use the result mapping defined outside the discriminator block. Therefore, if the statement of carResult is as follows:
<resultMap id="carResult" type="Car"> <result property="doorCount" column="door_count" /> </resultMap>
Then only the doorCount attribute will be loaded. This is so that even the case s of the discriminator can be divided into completely independent groups, although it may have nothing to do with the parent result mapping.
In the above example, we certainly know that there is a relationship between cars and vehicles, that is, Car is a Vehicle. Therefore, we hope that the remaining properties can also be loaded. This requires only a small modification.
<resultMap id="carResult" type="Car" extends="vehicleResult"> <result property="doorCount" column="door_count" /> </resultMap>
Now the properties of vehicleResult and carResult will be loaded.
Some people may feel that the external definition of mapping is a little too lengthy. Therefore, for those who prefer the concise mapping style, there is another syntax to choose from. For example:
<resultMap id="vehicleResult" type="Vehicle"> <id property="id" column="id" /> <result property="vin" column="vin"/> <result property="year" column="year"/> <result property="make" column="make"/> <result property="model" column="model"/> <result property="color" column="color"/> <discriminator javaType="int" column="vehicle_type"> <case value="1" resultType="carResult"> <result property="doorCount" column="door_count" /> </case> <case value="2" resultType="truckResult"> <result property="boxSize" column="box_size" /> <result property="extendedCab" column="extended_cab" /> </case> <case value="3" resultType="vanResult"> <result property="powerSlidingDoor" column="power_sliding_door" /> </case> <case value="4" resultType="suvResult"> <result property="allWheelDrive" column="all_wheel_drive" /> </case> </discriminator> </resultMap>7. Automatic mapping
In a simple scenario, MyBatis can automatically map query results for you. But if you encounter complex scenarios, you need to build a result map. But in this section, you will see that you can mix the two strategies.
-
MyBatis will use the column name returned in the result to match the attribute with the same name in the Java class (ignoring case) and assign a value. This process is automatic mapping.
-
After the automatic mapping is completed, the manual mapping is performed. In the following case, the id and userName columns will be automatically mapped and hashed_ The password column will be mapped according to the configuration.
<resultMap id="userResultMap" type="User"> <result property="password" column="hashed_password"/> </resultMap> <select id="selectUsers" resultMap="userResultMap"> select user_id as "id", user_name as "userName", hashed_password from some_table where id = #{id} </select>Prompt to enable the global setting mapUnderscoreToCamelCase, which can automatically map underlined field names to small hump Java properties.
There are three levels of automatic mapping: none (disable automatic mapping), PARTIAL (map attributes other than nested result mapping defined internally) and full (automatically map all attributes). The default value is PARTIAL.
Warning: when FULL is used for the result of the join query, the join query will get the data of multiple different entities in the same row, which may lead to unexpected mapping. The following example will show this risk:
<resultMap id="blogResult" type="Blog"> <association property="author" resultMap="authorResult"/> </resultMap> <resultMap id="authorResult" type="Author"> <result property="username" column="author_username"/> </resultMap> <select id="selectBlog" resultMap="blogResult"> select B.id, B.title, A.username, from Blog B left outer join Author A on B.author_id = A.id where B.id = #{id} </select>In this result mapping, both Blog and Author will be mapped automatically. However, note that the Author has an id attribute, and there is also a column named id in the ResultSet, so the id of the Author will be filled in with the id of the Blog, which is not the behavior you expect. Therefore, use FULL with caution.
Regardless of the automatic mapping level set, you can enable / disable automatic mapping for the specified result mapping setting by setting the autoMapping property on the result mapping.
<resultMap id="userResultMap" type="User" autoMapping="false"> <result property="password" column="hashed_password"/> </resultMap>
Section 4 cache configuration
Like most persistence frameworks, Mybatis also provides a caching strategy to reduce the number of queries in the database and improve performance. Mybatis uses two kinds of caches: local cache and second level cache.
1. First level cache of mybatis
The L1 cache is a cache in the SqlSession range. It is enabled by default. Whenever a new session is created, MyBatis will create a local cache associated with it. The local cache will be emptied when changes are made, transactions are committed or rolled back, and sessions are closed.
By default, the life cycle of locally cached data is equal to that of the whole session. Cache cannot be completely disabled because it can be used to solve circular reference problems and speed up repeated nested queries. However, you can set localcachescope = state to use the cache only during statement execution.
//TODO verifies the existence and emptying of the L1 cache. You can refer to mybatis demo0x
2. MyBatis L2 cache
The L2 cache is a mapper mapping level cache. Multiple sqlsessions operate sql statements mapped by the same mapper. Multiple sqlsessions can share the L2 cache. The L2 cache is cross sqlsessions.
To enable global L2 caching, just add a line to your SQL mapping file. (Note: the cacheEnabled global setting enabled by default cannot be turned off)
<cache/>
Basically. The effect of this simple statement is as follows:
- The results of all select statements in the mapping statement file will be cached.
- All insert, update, and delete statements in the mapping statement file flush the cache.
- The cache will use the least recently used (LRU) algorithm to clear the unnecessary cache.
- The cache is not refreshed regularly (that is, there is no refresh interval).
- The cache holds 1024 references to a list or object, regardless of what the query method returns.
- The cache is treated as a read / write cache, which means that the acquired object is not shared and can be safely modified by the caller without interfering with potential modifications made by other callers or threads.
Warning * caching only works on statements in the mapping file where the cache tag is located* If you mix Java API and XML mapping files, the statements in the common interface will not be cached by default. You need to use the @ CacheNamespaceRef annotation to specify the cache scope.
The behavior of L2 cache can be modified through the attributes of cache tag. For example:
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
This more advanced configuration creates a FIFO cache, which is refreshed every 60000 milliseconds. It can store up to 512 references of the result object or list, and the returned objects are considered read-only. Therefore, modifying them may cause conflicts among callers in different threads.
Prompt that other values of eviction include SOFT and WEAK.
The L2 cache can also use the attributes of the select/update/insert/delete tag for finer grained behavior control.
- When useCache is true, it means that the configured SQL statement uses L2 cache; otherwise, it means no cache. The default value is true.
- When flushCache is true, it means that the cache is refreshed when the statement is executed; otherwise, it means that there is no need to refresh the cache. The default value of the select tag is false and the other three are true.
For statements with a certain namespace, only the cache of that namespace will be used for caching or refreshing. However, you may want to share the same cache configuration and instances in multiple namespaces. To achieve this requirement, you can use the cache ref element to reference another cache.
<cache-ref namespace="com.someone.application.data.SomeMapper"/>
3. Use custom cache
In addition to the above customized caching methods, you can also completely override the caching behavior by implementing your own caching or creating adapters for other third-party caching schemes.
<cache type="com.domain.something.MyCustomCache"/>
This example shows how to use a custom cache implementation. The class specified by the type attribute must implement org apache. ibatis. cache. Cache interface, and provides a constructor that accepts a String parameter as an id. This interface is one of many complex interfaces in MyBatis framework, but its behavior is very simple.
public interface Cache { String getId(); int getSize(); void putObject(Object key, Object value); Object getObject(Object key); boolean hasKey(Object key); Object removeObject(Object key); void clear(); }To configure your cache, simply add a public JavaBean attribute to your cache implementation, and then pass the attribute value through the cache element. For example, the following example will call a method called setCacheFile(String file) in your cache implementation:
<cache type="com.domain.something.MyCustomCache"> <property name="cacheFile" value="/tmp/my-custom-cache.tmp"/> </cache>
You can use all simple types as the types of JavaBean properties, and MyBatis will convert them. You can also use placeholders (such as ${cache.file}) to replace them with Profile properties The value defined in.
Starting with version 3.4.2, MyBatis has supported an initialization method after all the properties are set. If you want to use this feature, please implement org. In your custom cache class apache. ibatis. builder. Initializingobject interface.
public interface InitializingObject { void initialize() throws Exception; }Tip: the cache configuration in the previous section (such as purge policy, read / write, etc.) cannot be applied to custom cache.
Section V dynamic SQL
Dynamic SQL is one of the powerful features of MyBatis. If you have used JDBC or other similar frameworks, you should be able to understand how painful it is to splice SQL statements according to different conditions. For example, when splicing, make sure you can't forget to add the necessary spaces and remove the comma of the last column name in the list. Using dynamic SQL, you can completely get rid of this pain.
1. if tag
The most common scenario for using dynamic SQL is to include part of the where clause based on conditions. For example, you want to perform an optional search through the two parameters "title" and "author".
<select id="findActiveBlogLike" resultType="Blog"> SELECT * FROM BLOG WHERE 1 = 1 <if test="title != null"> AND title like #{title} </if> <if test="author != null and author.name != null"> AND author_name like #{author.name} </if> </select>2. choose(when, otherwise) label
Sometimes we want to use more than one condition. In this case, MyBatis provides the choose element, which is a bit like the switch statement in Java.
<select id="findActiveBlogLike" resultType="Blog"> SELECT * FROM BLOG WHERE 1 = 1 <choose> <when test="title != null"> AND title like #{title} </when> <when test="author != null and author.name != null"> AND author_name like #{author.name} </when> <otherwise> AND featured = 1 </otherwise> </choose> </select>3. trim(where, set) label
Returning to the previous "if" example, we found that we had to add 1 = 1 after the where statement, otherwise there would be SQL splicing errors.
MyBatis provides a better solution for this scenario, which is to use the where tag.
- The WHERE tag inserts the "WHERE" clause only if the child element returns anything.
- If the spliced clauses start with "AND" OR ", the where element will also remove them.
<select id="findActiveBlogLike" resultType="Blog"> SELECT * FROM BLOG <where> <if test="state != null"> state = #{state} </if> <if test="title != null"> AND title like #{title} </if> <if test="author != null and author.name != null"> AND author_name like #{author.name} </if> </where> </select>Similarly, for dynamic update statements, MyBatis has a similar solution, that is, the set tag. The set tag can be used to dynamically include columns that need to be updated and ignore other columns that do not need to be updated.
<update id="updateAuthorIfNecessary"> update Author <set> <if test="username != null">username=#{username},</if> <if test="password != null">password=#{password},</if> <if test="email != null">email=#{email},</if> <if test="bio != null">bio=#{bio}</if> </set> where id=#{id} </update>In this example, the SET element will dynamically insert the SET keyword at the beginning of the line and delete the extra comma at the end.
If the above where and set tags can't meet your needs, you can try a more powerful trim tag.
-
The prefix attribute is the prefix inserted in the scene where the clause is not empty.
-
The prefixOverrides/suffixOverrides property ignores text sequences separated by pipe characters (note that spaces are necessary in this example).
The following are trim tags equivalent to where tag and trim tag respectively.
<!-- MyWhere --> <trim prefix="WHERE" prefixOverrides="AND |OR "> ... </trim> <!-- MySet --> <trim prefix="SET" suffixOverrides=","> ... </trim>
The above example will remove all the contents specified in the prefixOverrides/suffixOverrides attribute and insert the contents specified in the prefix attribute.
4. foreach label
Another common use scenario for dynamic SQL is traversal of collections (especially when building IN conditional statements).
<select id="selectPostIn" resultType="domain.blog.Post"> SELECT * FROM POST P WHERE ID in <foreach item="item" index="index" collection="list" open="(" separator="," close=")"> #{item} </foreach> </select>You can pass any iteratable object (such as List, Set, etc.), Map object or array object to foreach as a Set parameter.
- When using iteratable objects or arrays, index is the sequence number of the current iteration, and the value of item is the element obtained in this iteration.
- When using a Map object (or a collection of Map.Entry objects), index is the key and item is the value.
5. script label
To use dynamic SQL in an annotated mapper interface class, you can use the script tag.
@Update({"<script>", "update Author", " <set>", " <if test='username != null'>username=#{username},</if>", " <if test='password != null'>password=#{password},</if>", " <if test='email != null'>email=#{email},</if>", " <if test='bio != null'>bio=#{bio}</if>", " </set>", "where id=#{id}", "</script>"}) void updateAuthorValues(Author author);6. bind tag
The bind element allows you to create a variable outside the OGNL expression and bind it to the current context.
<select id="selectBlogsLike" resultType="Blog"> <bind name="pattern" value="'%' + _parameter.getTitle() + '%'" /> SELECT * FROM BLOG WHERE title LIKE #{pattern} </select>7. More detailed multi database support
If databaseIdProvider is configured, you can use a variable named "_databaseId" in dynamic code to build specific statements for different databases.
<insert id="insert"> <selectKey keyProperty="id" resultType="int" order="BEFORE"> <if test="_databaseId == 'oracle'"> select seq_users.nextval from dual </if> <if test="_databaseId == 'db2'"> select nextval for seq_users from sysibm.sysdummy1" </if> </selectKey> insert into users values (#{id}, #{name}) </insert>8. Insert script language in dynamic SQL
MyBatis supports insert scripting language from version 3.2, which allows you to insert a language driver and write dynamic SQL query statements based on this language. You can insert a language by implementing the following interfaces:
public interface LanguageDriver { ParameterHandler createParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql); SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType); SqlSource createSqlSource(Configuration configuration, String script, Class<?> parameterType); }After implementing the custom language driver, you can use mybatis config Set it as the default language in the XML file:
<typeAliases> <typeAlias type="org.sample.MyLanguageDriver" alias="myLanguage"/> </typeAliases> <settings> <setting name="defaultScriptingLanguage" value="myLanguage"/> </settings>
Alternatively, you can use the lang attribute to specify the language for a specific statement:
<select id="selectBlog" lang="myLanguage"> SELECT * FROM BLOG </select>
Or, add @ Lang annotation on your mapper interface:
public interface Mapper { @Lang(MyLanguageDriver.class) @Select("SELECT * FROM BLOG") List<Blog> selectBlog(); }All the xml tags you saw earlier are provided by the default MyBatis language, which is language driven org apache. ibatis. scripting. xmltags. Provided by xmllanguagedriver (alias xml).
Tips: you can use Apache Velocity as a dynamic language. For more details, please refer to mybatis velocity project.
Section 6 mapper annotation
1. Overview of mapper annotations
MyBatis is an XML driven framework at the beginning of design. The configuration information is based on XML, and the mapping statement is also defined in XML. MyBatis 3 is built on a comprehensive and powerful configuration API based on the Java language. It is the foundation of XML and annotation configuration. Annotations provide a simple and low-cost way to implement simple mapping statements.
The following is a list of all mapper annotations, which will be introduced one by one.
annotation XML equivalent @Insert @Update @Delete @Select @Param N/A @Results @Result , @ConstructorArgs 2. Statement definition annotation
- **@Insert/@Update/@Delete/@Select: * * used to define the SQL statement to be executed.
- value SQL statement string
- databaseId specifies the database vendor of the SQL statement.
@Select(value = "SELECT SYS_GUID() FROM dual", databaseId = "oracle") // oracle @Select(value = "SELECT uuid_generate_v4()", databaseId = "postgres") //postgres @Select("SELECT RANDOM_UUID()") //others String generateId();3. Parameter / result set mapping annotation
-
**@Param: * * Custom mapping parameter name. By default, the formal parameter names obtained by MyBatis through reflection are arg0, arg1... (except for the RowBounds parameter).
- value specifies the parameter name. If @ Param("person") is used, the parameter will be named #{person}
-
**@Results: * * define a result set mapping. Describes how result sets are mapped to Java objects.
- value is an array of @ Result.
- id the name of the result mapping (this annotation becomes a repeatable annotation from version 3.5.4).
-
**@Result: * * defines the mapping of a column. Describes how to map a specific result column to a property or field.
- id boolean indicating whether the attribute is used to uniquely identify and compare objects.
- Column result set column name.
- Javatype a property or field of a Java object.
- JDBC type JDBC type.
- typeHandler specifies the type processor.
- one association mapping, similar to the < Association > tag.
- many set mapping, similar to the < Collection > tag.
@Results(id = "userResult", value = { @Result(property = "id", column = "uid", id = true), @Result(property = "firstName", column = "first_name"), @Result(property = "lastName", column = "last_name") }) @Select("select * from users where id = #{id}") User getUserById(Integer id);-
**@ConstructorArgs: * * a constructor that collects a set of results to pass to a result object.
- value, which is an @ Arg array.
-
**@Arg: * * represents a construction method parameter.
- id boolean indicating whether the attribute is used to uniquely identify and compare objects (this annotation has become a repeatable annotation since version 3.5.4).
- Column result set column name.
- Javatype a property or field of a Java object.
- JDBC type JDBC type.
- typeHandler specifies the type processor.
- select
- resultMap
@Results(id = "companyResults") @ConstructorArgs({ @Arg(column = "cid", javaType = Integer.class, id = true), @Arg(column = "name", javaType = String.class) }) @Select("select * from company where id = #{id}") Company getCompanyById(Integer id);- **@One: * * single attribute mapping for complex types.
- select specifies the fully qualified name of the mapping statement (that is, the mapper method) that can load an instance of the appropriate type.
- fetchType specifies that the global configuration parameter lazyloading enabled is overridden in this mapping.
- resultMap the fully qualified name of the result map. (available since 3.5.5).
- columnPrefix is the column prefix used to group columns in nested result sets (available since 3.5.5).
The annotation API does not support union mapping. This is because Java annotations do not allow circular references.
- **@Many: * * set attribute mapping of complex types.
- select specifies the fully qualified name of the mapping statement (that is, the mapper method) that can load a collection of instances of the appropriate type.
- fetchType specifies that the global configuration parameter lazyloading enabled is overridden in this mapping.
- resultMap the fully qualified name of the result map. (available since 3.5.5).
- columnPrefix is the column prefix used to group columns in nested result sets (available since 3.5.5).
- **@ResultType: * * this annotation is required when the result processor is used.
Since the return type at this time is void, Mybatis needs a method to determine the object type returned in each line. If there is a corresponding result map in XML, please use @ ResultMap annotation. If you do not need to specify the type in the XML element, you do not need to use it in the result. Otherwise, you need to use this annotation. For example, if a method marked with @ Select wants to use the result processor, its return type must be void, and this annotation (or @ ResultMap) must be used. This annotation only takes effect if the method return type is void.
- @ResultMap: specify the id value of / @ Results for the method marked with @ Select, and reuse the existing result set mapping.
If there are @ Results or @ ConstructorArgs annotations in the select annotation of the annotation, these two annotations will be overwritten by this annotation.
-
**@TypeDiscriminator: * * a set of case s that determine which result mapping to use.
- cases an array of @ Case
- column
- javaType
- jdbcType
- typeHandler
-
**@Case: * * indicates a value of a value and its corresponding mapping.
- value
- type
- Results is an array of @ results, so this annotation is actually very similar to ResultMap and is specified by the @ results annotation.
4. Cache related annotations
-
**@CacheNamespace: * * configure cache for mapper.
- Attributes include: implementation, eviction, flushInterval, size, readWrite, blocking, and properties.
-
**@CacheNamespaceRef: * * refers to the cache of another namespace for use.
- value specifies a fully qualified name that can represent the namespace.
- Name directly specifies the name of the namespace (this attribute is only available above MyBatis 3.4.2).
Note that even if the same fully qualified class name is shared, the cache declared in the XML Mapping file is recognized as a separate namespace.
5. Other types of notes
-
@Flush: when calling the annotated method, the flush statements () method of SqlSession is triggered (available above Mybatis 3.3).
-
**@SelectKey: * * before executing SQL statement
- Statement the SQL statement that will be executed
- keyProperty specifies the name of the corresponding property of the object passed in as a parameter, which will be updated with a new value.
- Before boolean indicating whether the SQL statement should be executed before or after the insertion statement.
- resultType specifies the Java type of the keyProperty.
- statementType is used to select the STATEMENT type. You can select one of STATEMENT, PREPARED or CALLABLE. The default value is PREPARED.
- databaseId indicates the database vendor type of the SQL (Available since 3.5.5).
- This annotation can only be used on the methods marked by @ Insert or @ InsertProvider or @ Update or @ UpdateProvider, otherwise it will be ignored.
- If the @ SelectKey annotation is marked, MyBatis will ignore the generated primary key or configuration attribute set by the @ Options annotation.
This example shows how to use the @ SelectKey annotation to read the value of the database sequence before insertion.
@Insert("insert into table3 (id, name) values(#{nameId}, #{name})") @SelectKey(statement="call next value for TestSequence", keyProperty="nameId", before=true, resultType=int.class) int insertTable3(Name name);This example shows how to use the @ SelectKey annotation to read the value of the database auto increment column after insertion.
@Insert("insert into table2 (name) values(#{name})") @SelectKey(statement="call identity()", keyProperty="nameId", before=false, resultType=int.class) int insertTable2(Name name);- **@Options: * * this annotation allows you to specify most switches and configuration options, which usually appear as attributes on mapping statements. Here are some common properties and default values.
Note that Java annotations cannot specify null values. Therefore, once you use the Options annotation, your statement will be affected by the default values of the above attributes. Be careful to avoid unexpected behavior caused by default values.
-
**@Property: * * specify parameter value or placeholder, which can be used by mybatis config XML (available only above MyBatis 3.4.2).
- name
- value
-
**@MapKey: * * annotation for the method whose return value is Map. It uses an attribute of the object as a key to convert the object List into a Map.
- Value specifies the object attribute name as the key value of the Map
-
**@InsertProvider, @ UpdateProvider, @ DeleteProvider, @ SelectProvider: * * dynamic SQL built by referencing SQL build class.
Chapter IV mybatis spring
other
- Mybatis demo case
- Mybatis Spring + Case
- mybatis source code analysis