brief introduction

What is Mybatis?
- MyBatis is an excellent persistence layer framework
- It supports custom SQL, stored procedures, and advanced mapping.
- MyBatis eliminates almost all JDBC code and the work of setting parameters and obtaining result sets.
- MyBatis can configure and map primitive types, interfaces and Java POJO s (Plain Old Java Objects) to records in the database through simple XML or annotations.
- MyBatis was originally a part of apache Open source project It's called iBatis,
- This year in 2010 project Migrated from apache software foundation to [Google Code]( https://baike.baidu.com/item/google Code / 2346604) and renamed MyBatis.
- Moved to in November 2013 Github.
- Official website Chinese documents Click to enter
How to get Mybatis
- Maven warehouse
<!-- https://mvnrepository.com/artifact/org.mybatis/mybatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
- Github :Github download link
Data persistence
-
Persistence is the process of transforming program data in persistent state and transient state.
-
Memory: power loss.
-
Persistence methods include database, IO file persistence, etc.
Why persistence?
- There are some objects and data that cannot be discarded.
- Memory is too expensive.
- ...
Persistent layer
Common layers: Dao layer, Service layer, Controller layer
- Persistent layer Also known as data access layer or DAL layer, it is mainly responsible for the functions database Visits to the;
- Simply put, it refers to SQL statements and other operations (CRUD) on the database through DAL
- That is, the code block that completes the persistence work
- The boundary of layer is very obvious.
Why do you need Mybatis?
-
The helper program stores the data in the database.
-
convenient
-
Traditional JDBC code is too complex. Simplification, framework, automation.
-
Not Mybatis. (there is no difference in technology)
-
Features and advantages:
- Easy to learn: you can completely master its design idea and implementation through documents and source code.
- Flexible: sql is written in xml to facilitate unified management and optimization. All requirements for operating the database can be met through sql statements.
- Decouple sql from program code: by providing DAO layer, business logic and data access logic are separated, sql and code are separated, and maintainability is improved.
- Provide mapping labels to support the mapping of orm fields between objects and databases
- Provide object relationship mapping labels to support object relationship construction and maintenance
- Provide xml tags to support writing dynamic sql.
-
The most important reason: many people use it.
The first Mybatis program
Idea: build environment – > Import jar packages such as mybatis – > write code – > test!
Build environment
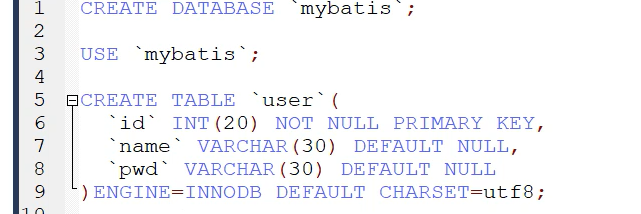
Build database and data table
New project
- Create a normal maven project
- Delete src directory (easy to create parent-child projects)
- Import related dependencies in pom.xml
<!--Import dependency-->
<!--1.mysql Drive dependency-->
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.19</version>
</dependency>
<!--2.mybatis rely on-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
<!--3.Junit rely on-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
Create a module
- Write the core configuration file of Mybatis
<!--configuration Core profile-->
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/> <!--Transaction management is JDBC-->
<dataSource type="POOLED">
<!--Replace each attribute value connected to the database-->
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<!--notes:there&Connector to use&To express,& yes HTML in & Representation of-->
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<!--every last Mapper.xml All need to be in mybatis Register in the core configuration file of-->
<mappers>
<!--Path to use/Split-->
<mapper resource="com/carson/dao/UserMapper.xml"/>
</mappers>
</configuration>
- Write mybatis tool class
//Sqlsessionfactory -- > generates sqlSession
public class MybatisUtils {
//Promote scope
private static SqlSessionFactory sqlSessionFactory;
//The sqlSessionFactory instance is generated by reading the configuration file through SqlSessionFactoryBuilder
static{
try{
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
//Now that we have an instance of SqlSessionFactory, as the name suggests, we can get an instance of SqlSession from it.
//SqlSession provides all the methods required to execute SQL commands in the database.
public static SqlSession getSqlSession(){
return sqlSessionFactory.openSession();
}
}
Write code
- Entity class
package com.carson.pojo;
//Entity class
public class User {
private int id;
private String name;
private String pwd;
public User() {
}
public User(int id, String name, String pwd) {
this.id = id;
this.name = name;
this.pwd = pwd;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPwd() {
return pwd;
}
public void setPwd(String pwd) {
this.pwd = pwd;
}
}
- Dao interface
public interface UserDao {
public List<User> getUserList();
}
- Interface implementation class (from the original UserDaoImpl to a Mapper configuration file)
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace You need to bind a corresponding Dao/Mapper Interface path write complete-->
<mapper namespace="com.carson.dao.UserDao">
<!--select Label correspondence select Query statement-->
<!--id The name of the method corresponding to the interface to be implemented,resultType It corresponds to the return type and the path should be completely written-->
<select id="getUserList" resultType="com.carson.pojo.User">
select * from mybatis.user
</select>
</mapper>
test
Testing with Junit
package com.carson.dao;
import com.carson.pojo.User;
import com.carson.utils.MybatisUtils;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
import java.util.List;
public class UserDaoTest {
@Test
public void test(){
//The first step is to obtain the sqlSession object
SqlSession sqlSession = MybatisUtils.getSqlSession();
//Method 1: getMapper
UserDao userDao = sqlSession.getMapper(UserDao.class);
List<User> userList = userDao.getUserList();
//Method 2: (not recommended)
//List<User> userList = sqlSession.selectList("com.carson.dao.UserDao.getUserList");
for(User user:userList){
System.out.println(user);
}
//Close sqlSession
sqlSession.close();
}
}
Possible problems?
- xml resource export failure often encountered in maven.
The standard Maven project will have a resources directory to store all our resource configuration files, but we often not only put all the resource configuration files in resources, but also in other locations in the project, When the default Maven project is built and compiled, the resource configuration files in other directories will not be exported to the target directory, which will lead to failure in reading our resource configuration files, resulting in errors and exceptions in our project. For example, when we use the MyBatis framework, Often, Mapper.xml configuration files are placed in dao packages together with dao interface classes. When the program is executed, the XML configuration files will fail to be read and will not be generated into Maven's target directory. Therefore, we need to set them in the project's pom.xml file, and I suggest that every new Maven project, Just import this setting into pom.xml file to prevent accidents!!!
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
</resources>
</build>
- Caused by: com.sun.org.apache.xerces.internal.impl.io.malformedbytesequenceexception: byte 1 of UTF-8 sequence of 1 byte is invalid.
- Caused by: com.sun.org.apache.xerces.internal.impl.io.malformedbytesequenceexception: invalid byte 2 of 2-byte UTF-8 sequence.
Solutions to the above two cases (i.e. Chinese garbled code output from xml file):
- When two XML files * * (mybatis-config.xml and UserMapper.xml) * * contain Chinese comments:
- **Remove the - in encoding="UTF-8" in the first line of the two mybatis XML configuration files (mybatis-config.xml and UserMapper.xml), that is, replace it with encoding = "UTF8"**
- Change encoding="UTF-8" to: encoding = "GBK", because JDK will be encoded in the default encoding format of the operating system, and the default encoding of our computer is GBK.
- Change the default JDK code of the computer to UTF-8, and no error will be reported here. Change method: reference link
- When there are no Chinese comments in * * (mybatis-config.xml and UserMapper.xml) * * in the two XML files:
- Since it does not contain Chinese, there will be no Chinese garbled code in the xml file. The configuration file does not need to be changed, that is, encoding="UTF-8" or encoding="UTF-8"
Other possible problems:
- The configuration file that implements the interface is not registered in the core configuration file of mybatis
- Binding interface error
- Wrong method name
- Wrong return type
Step summary:
- Write a tool class to create sqlSessionFactory
- Write the core configuration file of mybatis
- Writing pojo entity classes
- Write interface
- Write the configuration file of the interface implementation
- Write test code
CRUD of Mybatis
Note: all additions, deletions and modifications must be handled.
1.namespace
-
The namespace in the configuration file of the implementation interface shall be consistent with the Dao/Mapper interface name.
-
That is, the namespace is the interface name of the implementation (the full path should be written).
2.select tag
- The id in the select tag in the configuration file that implements the interface represents the method name in the interface that needs to be rewritten.
- resultType: the return value of sql statement execution! (write full path for complex data types)
- parameterType: parameter type
- Writing interface methods
public interface UserMapper {
//Query all users
public List<User> getUserList();
//Query user by Id
public User getUserById(int id);
}
- Write the sql statements in the corresponding mapper configuration file
<mapper namespace="com.carson.dao.UserMapper">
<!--select Label correspondence select Query statement-->
<!--id The name of the method corresponding to the interface to be implemented,resultType It corresponds to the return type and the path should be completely written-->
<select id="getUserList" resultType="com.carson.pojo.User">
select * from mybatis.user;
</select>
<!--select Query statement #Fill in the parameters of sql statement in the form of {variable name} -- >
<select id="getUserById" parameterType="int" resultType="com.carson.pojo.User">
select * from user where id = #{id};
</select>
- Write test code
//Query all users
@Test
public void test(){
//The first step is to obtain the sqlSession object
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
//Method 1: getmapper (get the interface object and call the method)
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
List<User> userList = userMapper.getUserList();
//Method 2: (not recommended)
//List<User> userList = sqlSession.selectList("com.carson.dao.UserDao.getUserList");
for(User user:userList){
System.out.println(user);
}
}catch (Exception e){
e.printStackTrace();
}finally {
//Close sqlSession
sqlSession.close();
}
}
//Query user by id
@Test
public void getUserById(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.getUserById(2);
System.out.println(user);
}catch (Exception e){
e.printStackTrace();
}finally {
sqlSession.close();
}
}
3.insert tag
- Writing interface methods
//Add a user
public int addUser(User user);
- Write the sql statements in the corresponding mapper configuration file
<!--insert Statement correspondence insert label-->
<!--Properties in object,You can take it out directly-->
<insert id="addUser" parameterType="com.carson.pojo.User">
insert into user values(#{id},#{name},#{pwd});
</insert>
- Write test code
//Add a user
@Test
public void addUser(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
int affectedRows = mapper.addUser(new User(5, "test", "111111"));
if(affectedRows>0){
//Since all additions, deletions and modifications must be handled, the transaction must be committed here
sqlSession.commit();
System.out.println("Insert successful!");
}
}catch (Exception e){
//An error occurred and the transaction was rolled back
sqlSession.rollback();
e.printStackTrace();
}finally {
sqlSession.close();
}
}
4.update tab
- Writing interface methods
//Modify a user
public int updateUser(User user);
- Write the sql statements in the corresponding mapper configuration file
<!--update Statement correspondence update label-->
<!--Properties in object,You can take it out directly-->
<update id="updateUser" parameterType="com.carson.pojo.User">
update user set name=#{name},pwd=#{pwd} where id=#{id};
</update>
- Write test code
//Modify a user
@Test
public void updatUser(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
int affectedRows = mapper.updateUser(new User(5,"test0","000000"));
if(affectedRows>0){
//Since all additions, deletions and modifications must be handled, the transaction must be committed here
sqlSession.commit();
System.out.println("Modified successfully!");
}
}catch (Exception e){
//An error occurred and the transaction was rolled back
sqlSession.rollback();
e.printStackTrace();
}finally {
sqlSession.close();
}
}
5.delete tag
- Writing interface methods
//Delete a user
public int delUser(int id);
- Write the sql statements in the corresponding mapper configuration file
<!--delete Statement correspondence delete label-->
<delete id="delUser" parameterType="int">
delete from user where id = #{id};
</delete>
- Write test code
//Delete a user
@Test
public void delUser(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
int affectedRows = mapper.delUser(5);
if(affectedRows>0){
//Since all additions, deletions and modifications must be handled, the transaction must be committed here
sqlSession.commit();
System.out.println("Delete succeeded!");
}
}catch (Exception e){
//An error occurred and the transaction was rolled back
sqlSession.rollback();
e.printStackTrace();
}finally {
sqlSession.close();
}
}
6. Realize fuzzy query

-
Method 1: when the java code is executed, pass the wildcard%% to the argument
Interface method:
//Fuzzy query example public List<User> getUserListLike(String value);
Configuration file of implemented interface method:
<!--Fuzzy query example-->
<select id="getUserListLike" resultType="com.carson.pojo.User">
select * from user where name like #{value };
</select>
Test code:
//Fuzzy query example
@Test
public void getUserListLike(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<User> users = mapper.getUserListLike("%Lee%");
for (User user : users) {
System.out.println(user);
}
}catch (Exception e){
e.printStackTrace();
}finally {
sqlSession.close();
}
}
- Method 2: directly use wildcards in sql splicing!
Interface method:
//Fuzzy query example public List<User> getUserListLike(String value);
Configuration file of implemented interface method:
<!--Fuzzy query example-->
<select id="getUserListLike" resultType="com.carson.pojo.User">
select * from user where name like "%"#{value}"%";
</select>
Test code:
//Fuzzy query example
@Test
public void getUserListLike(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<User> users = mapper.getUserListLike("Lee");
for (User user : users) {
System.out.println(user);
}
}catch (Exception e){
e.printStackTrace();
}finally {
sqlSession.close();
}
}
7. The difference between #{} and ${} in mybatis
There are two ways to pass parameters to SQL statement in Mapper.xml statement of Mybatis:
Namely: #{} and ${}
- We often use #{}. The general explanation is that this method can prevent SQL injection. In short, the SQL statement of #{} This method is precompiled, which translates the #{} intermediate parameters into strings. For example:
select * from student where student_name = #{name}
After precompiling, it will be dynamically resolved into a parameter marker?:
select * from student where student_name = ?
- When ${} is used for dynamic parsing, the parameter string will be passed in
select * from student where student_name = 'carson'
Summary:
-
#{} This value is obtained after the SQL statement is compiled. It is precompiled. It corresponds to the PreparedStatement in JBDC. When # {} is used, the parameters of the specific SQL statement will be enclosed in single quotes
-
${} This is to compile SQL statements after taking values. mybatis will not modify or escape character conversion, and directly output variable values, that is, it will not quote parameters.
-
#The {} method can prevent SQL injection to a great extent$ Method cannot prevent SQL injection.
-
Don't use ${} if you can use #{}
8. Universal Map
Assuming that there are too many fields or parameters in our entity classes or tables in the database, we should consider using Map!
Examples are as follows:
- Write interface methods (pass Map type parameters)
//Use the universal Map to pass parameters public int addUser2(Map<String,Object> map);
- Write the sql statements in the corresponding mapper configuration file
<!--use map of key Values are passed as parameters,and key The name of the value may not be the same as the field name in the database-->
<insert id="addUser2" parameterType="map">
insert into user values (#{mapId},#{mapName},#{mapPwd});<!-- Pass the key of Map -- >
</insert>
- Write test code
//Add a user (pass the key value of the Map)
@Test
public void addUser2(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
//Create map
Map<String, Object> map = new HashMap<String, Object>();
map.put("mapId",5);
map.put("mapName","mapTest");
map.put("mapPwd","654545");
int affectedRows = mapper.addUser2(map);
if(affectedRows>0){
//Adding, deleting and modifying require transaction processing. Submit the transaction here
sqlSession.commit();
System.out.println("Map Mode increase success!");
}
}catch (Exception e){
//An exception occurred and the transaction was rolled back
sqlSession.rollback();
e.printStackTrace();
}finally{
sqlSession.close();
}
}
Note:
-
Pass parameters from map and directly get the key from sql! [parameterType=“map”]
-
Object transfer parameters, you can directly get the attribute of the object in sql!
[parameterType = "full path of entity object"]
-
If there is only one basic data type parameter, you can get it directly in sql!
[parameterType = "basic data type"] or no parameter type needs to be written.
Suggestion: use Map or annotation for multiple parameters!
Configuration resolution
1. Core profile
-
mybatis-config.xml
-
The mybatis configuration file contains settings and attribute information that will deeply affect the behavior of mybatis
- properties
- settings
- typeAliases
- typeHandlers
- objectFactory (object factory)
- plugins
- environments
- Environment (environment variable)
- Transaction manager
- dataSource
- Environment (environment variable)
- databaseIdProvider (database vendor ID)
- mappers
2. Environment configuration
Mybatis can be configured to adapt to a variety of environments.
However, remember: Although multiple environments can be configured, only one environment can be selected in the configuration file
The default transaction manager of Mybatis is JDBC, and the default data source is pooled (connection pool)
Learn to use and configure multiple operating environments. (change the example environment to test)
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--Originally<environments default="development">
Now pass default Change to test(Corresponding to the changed environment id)-->
<environments default="test">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
<!--Multiple environments can be configured-->
<environment id="test">
<transactionManager type="JDBC"></transactionManager>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true"/>
</dataSource>
</environment>
</environments>
<!--every last Mapper.xml All need to be in mybatis Register in the core configuration file of-->
<mappers>
<!--Path to use/Split-->
<mapper resource="com/carson/dao/UserMapper.xml"/>
</mappers>
</configuration>
3. Properties
We can reference the configuration file through the properties tag.
These properties are externally configurable and dynamically replaceable. They can be configured in a typical Java property file or passed through the child element tag property of the properties element (that is, the key value pair is created by setting the name attribute and value attribute in the above code).
properties reference external configuration file example:
- Write a configuration file (db.properties) in the resources directory
driver=com.mysql.cj.jdbc.Driver url=jdbc:mysql://localhost:3306/mybatis?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true username=root password=root
- In the core configuration file of Mybatis:

Note: as shown in the figure, the element tag position in xml is required. The properties tag element here needs to be placed in the first position in the configuration tag.
- External configuration files can be imported directly
<configuration>
<!--Import external profile-->
<!--Because the configuration file is resources Resource directory,Therefore, the file path does not need to write the full path-->
<properties resource="db.properties"></properties>
<!---------------------------------------------->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!--value Value reads the configuration file directly ${Variable name}The way-->
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
- You can add some attribute configurations.
<configuration>
<!--Import external profile-->
<!--Because the configuration file is resources Resource directory,Therefore, the file path does not need to write the full path-->
<properties resource="db.properties">
<!--stay properties Add some attribute configuration in-->
<property name="username" value="root"/>
<property name="password" value="root"/>
</properties>
<!---------------------------------------------->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!--value Value reads the configuration file directly ${Variable name}The way-->
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
- If the external configuration file has the same field as the property configuration in the property tag, the fields of the external configuration file and their values are preferred.
4. Type aliases
- A type alias is a short name for a Java type
- The meaning of existence is only to reduce the redundancy of class fully qualified names
- Method 1: alias the entity class directly
<!--Entity classes can be aliased, and the order of labels is required-->
<typeAliases>
<!--Alias the entity class directly-->
<typeAlias type="com.carson.pojo.User" alias="user" />
</typeAliases>
- Method 2: you can specify a package name. Mybatis will search for the required Java Bean under the package name, that is, by scanning the package of the entity class, the default alias is the lowercase initial of the class name of this class.
<!--Entity classes can be aliased, and the order of labels is required-->
<typeAliases>
<!--By scanning the package where the entity class is located,Its default alias is the lowercase of the class name of this class-->
<!--The classes under the package here are User, The default alias is:user-->
<package name="com.carson.pojo" />
</typeAliases>
Note:
-
When there are few entity classes, the first type alias is recommended.
-
If there are many entity classes, the second type alias is recommended.
-
The first type of alias can be a DIY alias.
-
The second type of alias cannot be DIY alias; If you have to change it, you need to add annotations on the entity class. Namely:
@Alias("user") public class User{...}
Note: here are some built-in type aliases for common Java types
| Category alias | Mapping corresponding type |
|---|---|
| _byte | byte |
| _long | long |
| _short | short |
| _int | int |
| _double | double |
| _float | float |
| _boolean | boolean |
| string | String |
| byte | Byte |
| long | Long |
| short | Short |
| int | Integer |
| double | Double |
| float | Float |
| boolean | Boolean |
| date | Date |
| decimal | BigDecimal |
| object | Object |
| map | Map |
| hashmap | HashMap |
| list | List |
| arraylist | ArrayList |
| collection | Collection |
| iterator | Iterator |
| ... |
That is, the default alias of the basic data type is:_ Basic type
The default alias of the wrapper type is: the lowercase form of the wrapper type
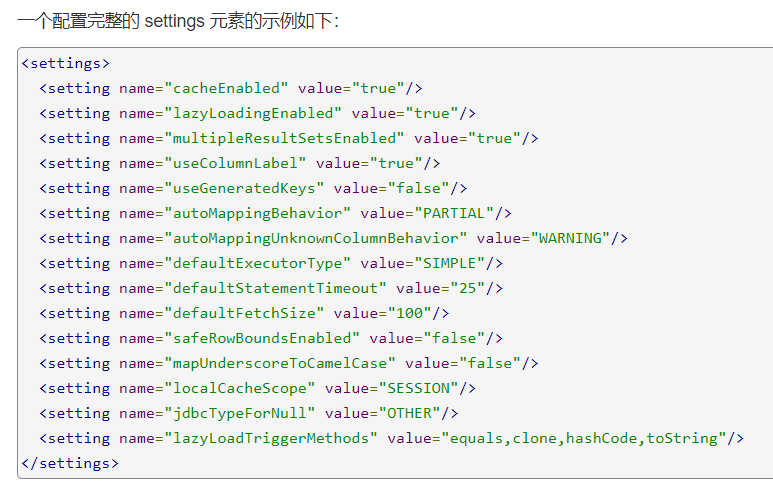
5. Setting
These are extremely important tuning settings in Mybatis, which change the runtime behavior of Mybatis.


Example:
6. Other configurations
- typeHandlers
- objectFactory (object factory)
- plugins
- mybatis-generator-core
- mybatis-plus
- General mapper
7. Mappers
MapperRegistry: register and bind our Mapper file;
- Method 1: [recommended]
<!--every last Mapper.xml All need to be in mybatis Register in the core configuration file of-->
<mappers>
<!--Path to use/Split-->
<mapper resource="com/carson/dao/UserMapper.xml"/>
</mappers>
- Mode 2:
<!--every last Mapper.xml All need to be in mybatis Register in the core configuration file of-->
<mappers>
<mapper class="com.carson.dao.UserMapper"/>
</mappers>
Note:
- Interface and its Mapper configuration file must have the same name
- Interface and its Mapper configuration file must be under the same package.
- Method 3: use scan package for injection binding
<!--every last Mapper.xml All need to be in mybatis Register in the core configuration file of-->
<mappers>
<package name="com.carson.dao"/>
</mappers>
Note:
- Interface and its Mapper configuration file must have the same name
- Interface and its Mapper configuration file must be under the same package.
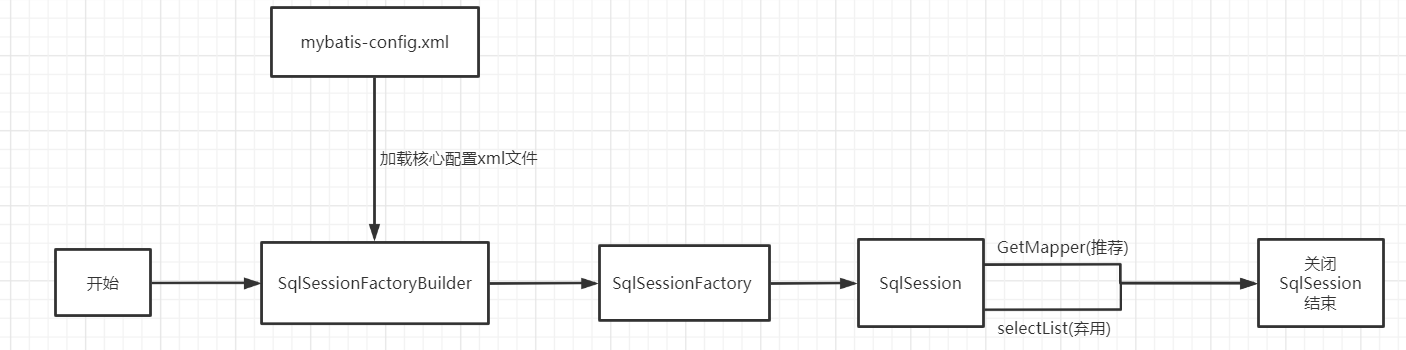
8. Life cycle and scope
Life cycle and scope are crucial, that is, wrong use can lead to very serious concurrency problems.
SqlSessionFactoryBuilder:
- SqlSessionFactoryBuilder once SqlSessionFactory is created, SqlSessionFactoryBuilder is no longer needed.
- Local variables.
SqlSessionFactory:
- Equivalent to one: database connection pool
- Once SqlSessionFactory is created, it should always exist during the running of the application. There is no reason to discard it or recreate a SqlSessionFactory
- Therefore, the best scope of SqlSessionFactory is the application scope.
- The simplest is to use singleton mode or static singleton mode.
SqlSession:
- It is equivalent to a request to connect to the connection pool!
- The instance of SqlSession is not thread safe, so it cannot be shared. Its best scope is the request or method scope.
- Close it immediately after use, otherwise the resources will be occupied!
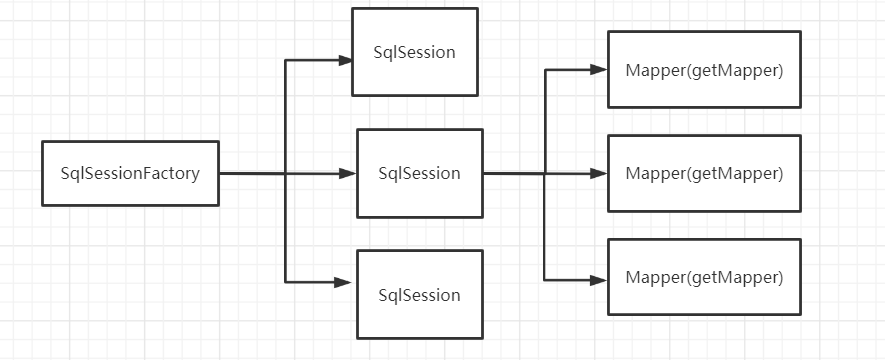
Each Mapper can represent a specific business.
Inconsistency between entity class attribute name and database table field name
1. Problems
Fields in the database:
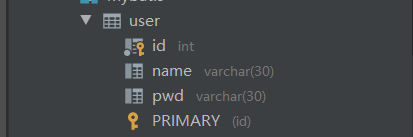
Fields in entity class:
public class User{
private int id;
private String name;
private String password;
......
}
Mapper.xml file:
<mapper namespace="com.carson.dao.UserMapper">
<select id="getUserById" parameterType="int" resultType="com.carson.pojo.User">
select * from user where id = #{id};
</select>
</mapper>
Test code:
//Query user by id (pass user parameters)
@Test
public void getUserById(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.getUserById(1);
System.out.println(user);
}catch (Exception e){
e.printStackTrace();
}finally {
sqlSession.close();
}
}
Execution result: (there is a problem with the output due to the mismatch between pwd and password)

resolvent:
- Alias fields in SQL statements
<mapper namespace="com.carson.dao.UserMapper">
<select id="getUserById" parameterType="int" resultType="user">
select id,name,pwd as password from user where id = #{id};
</select>
</mapper>
- Result set mapping
<mapper namespace="com.carson.dao.UserMapper">
<!--Result set mapping id:Identification name type:Need to map pojo-->
<resultMap id="userMap" type="User">
<!--column:Fields in the database property:Properties in entity classes-->
<!--Fields that do not require result field mapping do not need to be written result Label mapping-->
<result column="pwd" property="password"></result>
</resultMap>
<select id="getUserById" parameterType="int" resultMap="userMap">
select * from user where id = #{id};
</select>
</mapper>
Then use the resultMap attribute in the statement using it (note that the resultType attribute is removed)
<select id="getUserById" parameterType="int" resultMap="userMap">
select * from user where id = #{id};
</select>
2. Result set mapping
- The resultMap element is the most important and powerful tag element in Mybatis
- By default, MyBatis will automatically create a ResultMap behind the scenes, and then map columns to JavaBean properties according to property names.
- Design idea of ResultMap: for simple statements, there is no need to configure explicit result mapping, while for more complex statements, it is only necessary to describe their relationship.
- The best thing about ResultMap is that although you already know it well, you don't need to use them explicitly at all.
- For more information, please refer to: Official documents
journal
1. Log factory
If an error occurs in a database operation and needs to be checked. Log is the best tool.
Previous troubleshooting methods: print printout or debug
Current troubleshooting method: log factory

- LOG4J [ key points ]
- STDOUT_LOGGING [key points]
- SLF4J
- JDK_LOGGING
- COMMONS_LOGGING
- NO_LOGGING
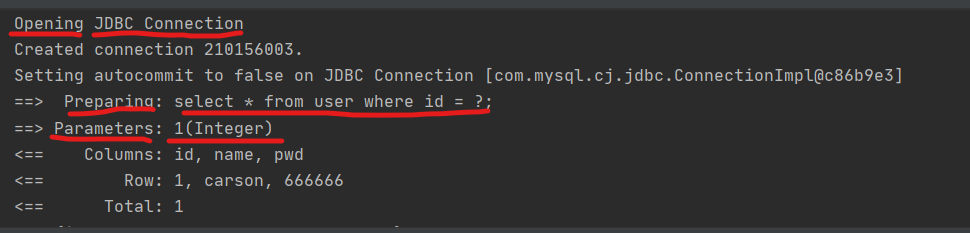
The specific log implementation used in mybatis is set in the setting tag in the core setting file of mybatis.
To configure stdout in the core configuration file of mybaits_ Taking logging (standard log output) as an example:
<!--Set log factory-->
<settings>
<!--The implementation of the standard log factory notes that the string cannot contain spaces-->
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
2.LOG4J
What is LOG4J?
-
Log4j is an external class, so using log4j requires a package guide.
-
Log4j yes Apache By using Log4j, we can control the destination of log information delivery Console , documents GUI Components, etc.
-
You can control the output format of each log;
-
By defining the level of each log information, we can carefully control the log generation process.
-
You can use a configuration file To flexibly configure without modifying the application code.
Preparation for use:
- Import Log4j packages first:
<dependencies>
<!--introduce LOG4J Log dependency-->
<!-- https://mvnrepository.com/artifact/log4j/log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
- Write a configuration file, log4j.properties:
Since Log4j can control the destination of log information transmission is / console / file / GUI components, etc; Here, take the configuration file of log output to console and file as an example:
#Output the log information with the level of DEBUG to the two destinations of console and file. The definitions of console and file are in the following code
log4j.rootLogger=DEBUG,console,file
#Settings related to console output
log4j.appender.console = org.apache.log4j.ConsoleAppender
log4j.appender.console.Target = System.out
log4j.appender.console.Threshold=DEBUG
log4j.appender.console.layout = org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern = [%c]-%m%n
#Settings related to file output
log4j.appender.file = org.apache.log4j.RollingFileAppender
#File location for log file output
log4j.appender.file.File = ./log/carson.log
log4j.appender.file.MaxFileSize=10mb
log4j.appender.file.Threshold = DEBUG
log4j.appender.file.layout = org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern = [%p][%d{yy-MM-dd}][%c]%m%n
#Log output level (output only after setting DEBUG level)
log4j.logger.org.mybatis = DEBUG
log4j.logger.java.sql = DEBUG
log4j.logger.java.sql.Statement=DEBUG
log4j.logger.java.sql.ResultSet=DEBUG
log4j.logger.java.sql.PreparedStatement = DEBUG
- Configure log4j as the implementation of log
<!--Set log factory-->
<settings>
<!--to configure LOG4J Note that the string cannot have spaces for log implementation-->
<setting name="logImpl" value="LOG4J"/>
</settings>
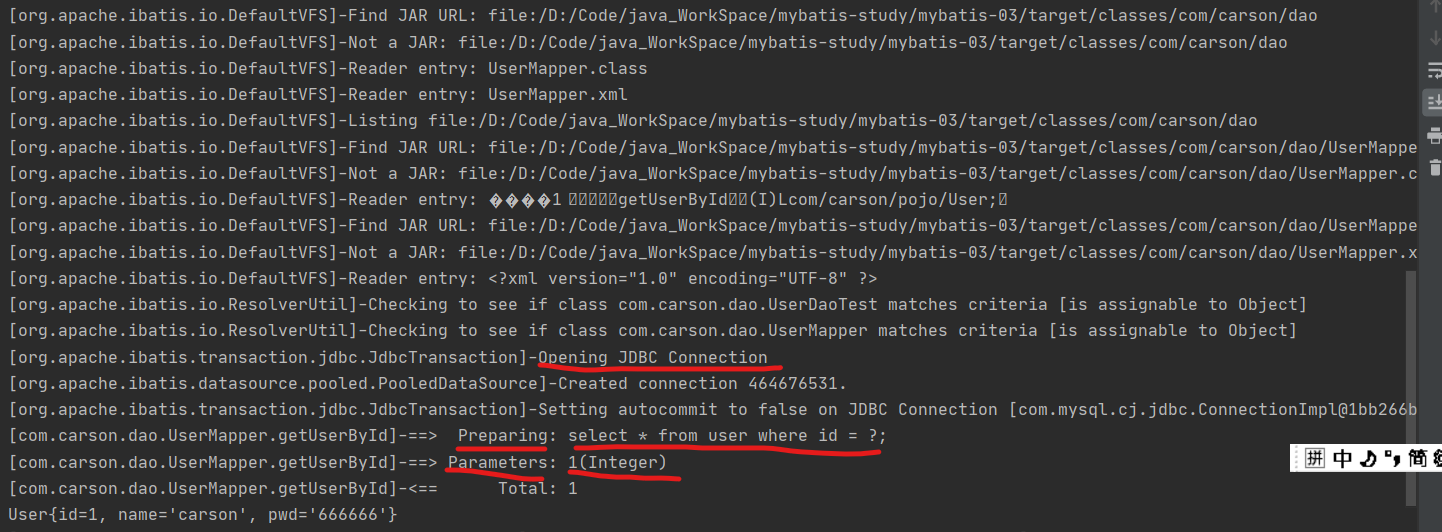
- Run test code:
Simple use of LOG4J:
-
In the class to use LOG4J, import the package
import org.apache.log4j.Logger
-
Instantiate the log object. The parameter is: class of the current class
//Instantiate the log object. The parameter of Logger.getLogger is the class of the current class
static Logger logger = Logger.getLogger(UserDaoTest.class);
- Run test code:
package com.carson.dao;
import com.carson.pojo.User;
import com.carson.utils.MybatisUtils;
import org.apache.ibatis.session.SqlSession;
import org.apache.log4j.Logger;
import org.junit.Test;
public class UserDaoTest {
//Instantiate log object
static Logger logger = Logger.getLogger(UserDaoTest.class);
/*Method of testing log4j log*/
@Test
public void log4jTest(){
logger.info("info:Entered Log4j Test method of");
logger.debug("debug:Entered Log4j Test method of");
logger.error("error:Entered Log4j Test method of");
}
}

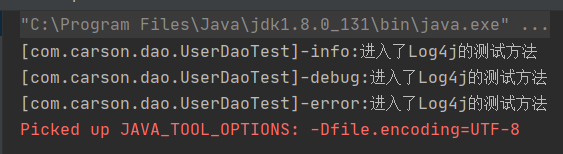
Log level (category):
That is, the level of each log information (such as * * debug/error/info * *)
We can carefully control the log generation process, that is, we can control the output of different levels of log information.
logger.info("info:Entered Log4j Test method of");
logger.debug("debug:Entered Log4j Test method of");
logger.error("error:Entered Log4j Test method of");
paging
Why paging? ------> Reduce data processing
Paging with Limit
grammar: SELECT * FROM user limit startIndex,pageSize; select * from user limit 3; #One parameter is [0,n]
Paging with limit in mybatis:
- Interface
//limit implements paging public List<User> getUserByLimit(Map<String,Integer> map);
- Mapper.xml
<!--limit Implement paging-->
<select id="getUserByLimit" parameterType="map" resultMap="userMap">
select * from user limit #{startIndex},#{pageSize};
</select>
- test
//limit paging test method
@Test
public void getUserByLimit(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
//Build map
HashMap<String, Integer> map = new HashMap<String, Integer>();
map.put("startIndex",1);
map.put("pageSize",4);
List<User> userList = mapper.getUserByLimit(map);
for (User user : userList) {
System.out.println(user);
}
}catch(Exception e){
e.printStackTrace();
}finally{
sqlSession.close();
}
}
RowBounds paging
Paging is no longer implemented using SQL.
- Interface:
//RowBounds implements paging public List<User> getUserByRowBounds();
- Mapper.xml
<!--RowBounds Implement paging-->
<select id="getUserByRowBounds" resultMap="userMap">
select * from user;
</select>
- Test:
//RowBounds implements paging
@Test
public void getUserByRowBounds(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
//RowBounds implementation
RowBounds rowBounds = new RowBounds(1, 4);
//Paging through java code level
List<User> userList = sqlSession.selectList("com.carson.dao.UserMapper.getUserByRowBounds", null, rowBounds);
for (User user : userList) {
System.out.println(user);
}
sqlSession.close();
}
The paging plug-in implements paging
Just know!
Using annotation development
- Annotation is implemented on the interface:
public interface UserMapper {
//Query all users with annotations
@Select("select * from user")
public List<User> getUsers();
}
- Bind the interface in the core configuration file of Mybatis
<!--Binding interface-->
<mappers>
<mapper class="com.carson.dao.UserMapper"/>
</mappers>
- Write test code:
@Test
public void test(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
//The bottom layer mainly applies reflection
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<User> users = mapper.getUsers();
for (User user : users) {
System.out.println(user);
}
}catch (Exception e){
e.printStackTrace();
}finally{
sqlSession.close();
}
}
be careful:
-
Using annotations does not require writing the corresponding xml file of the interface.
-
Essence: reflection mechanism implementation
-
Using annotations to map simple statements makes the code simpler. However, for complex statements, Java annotations are inadequate and will appear more chaotic.
-
Therefore, if you need to do complex things, it is best to use XML to map statements.
Mybatis execution process
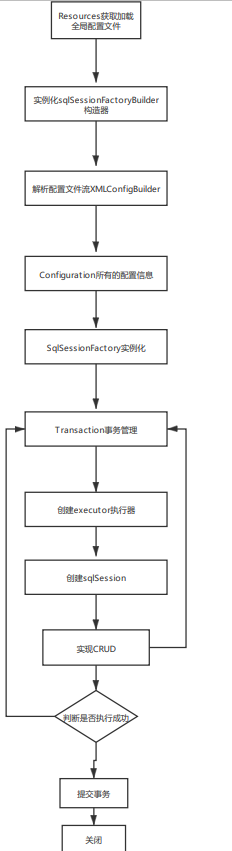
CRUD
- Automatic transaction submission can be set when the tool class is created. (transactions are managed by the driver)
//Set true to auto commit transactions
public static SqlSession getSqlSession(){
return sqlSessionFactory.openSession(true);
}
- Write the interface and add comments
public interface UserMapper {
//Query all users with annotations
@Select("select * from user")
public List<User> getUsers();
//Query feature id user with annotation (simple data type requires @ Param)
@Select("select * from user where id = #{id}")
public User getUserById(@Param("id") int id);
//Annotation adding user (complex data type does not need @ Param)
@Insert("insert into user values(#{id},#{name},#{password})")
public int addUser(User user);
//Annotation updates a user's information
@Update("update user set name=#{name},pwd=#{password} where id=#{id}")
public int updateUser(User user);
//Annotation delete a user according to id (simple data type requires @ Param)
@Delete("delete from user where id=#{uid}")
public int delUser(@Param("uid")int id);
}
- Note that the interface is bound in the core configuration file
<!--Binding interface-->
<mappers>
<mapper class="com.carson.dao.UserMapper"/>
</mappers>
- Write test code to test.
Comments about @ Param:
- For parameters of basic type or String type, this annotation needs to be added in front of the formal parameter.
- This annotation is not required for data of reference type.
- If there is only one basic type parameter, it can be ignored, but it is recommended to write it.
- What we refer to in SQL is the attribute name set in @ Param here.
Lombok
- java library plugin
- build tools
- with one annotation your class
- You don't need to write some Getter and Setter methods anymore, and you can add an annotation to realize them.
- That is, lazy plug-ins.
Use steps:
- Search and install the Lombok plug-in in the IDEA
- Import the jar package of Lombok in the project
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
</dependency>
- Just annotate the entity class.
@Data @AllArgsConstructor @NoArgsConstructor ......
Many to one processing
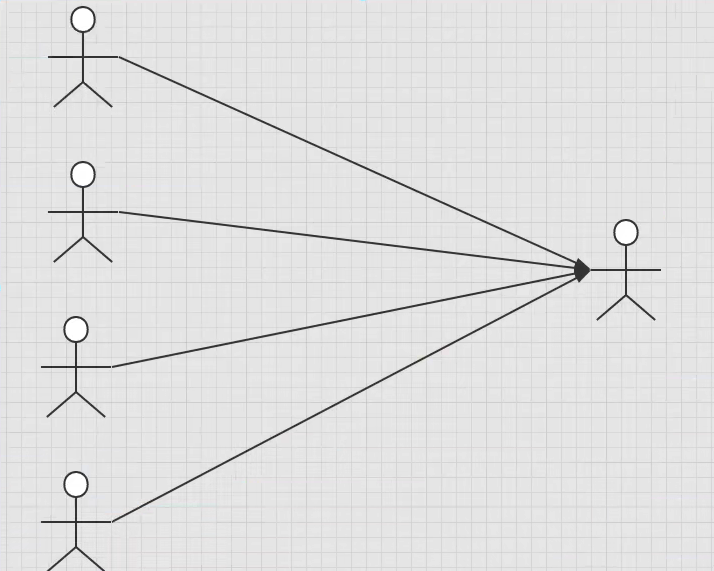
- Multiple student objects correspond to one teacher object
- For students, multiple students are associated with a teacher. [many to one]
- For teachers, a teacher has many students. [one to many]
Test environment construction
- Create corresponding database tables and fields: (the tid field of student table refers to the id field of teacher table)
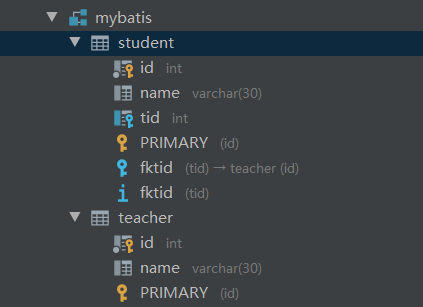
- New entity class
public class Teacher {
private int id;
private String name;
.......
}
public class Student {
private int id;
private String name;
//Because there is a foreign key association between fields in the data table
//Entity classes also need to be associated to keep data safe and clean
//Therefore, students need to associate a teacher object
private Teacher teacher;
......
}
- Establish Mapper interface
public interface TeacherMapper {
//Annotations are used for simple sql and xml configuration files are used for complex sql
//Use simple annotations to query teachers with a specific id
@Select("select * from teacher where id=#{tid}")
public Teacher getTeacherById(@Param("tid")int id);
}
public interface StudentMapper {
}
- Create Mapper.xml file corresponding to the interface
- Bind Mapper interface or xml file in the core configuration file [there are many methods, you can choose]
<!--Core profile binding interface-->
<mappers>
<mapper class="com.carson.dao.TeacherMapper"/>
<mapper class="com.carson.dao.StudentMapper"/>
</mappers>
- Write test code to test.
Nested processing by query
Features: simple SQL and complex label writing. (similar to subquery in SQL)
<!--Query all students' information and corresponding teacher information
thinking:(SQL Idea of nested query)Write three labels
1 Query the information of all students
2 According to the students found tid information,Query the corresponding teacher information-->
<select id="getStudents" resultMap="StudentMap">
select * from student
</select>
<resultMap id="StudentMap" type="Student">
<result property="id" column="id"/>
<result property="name" column="name"/>
<!--Complex properties,We need to deal with it separately
object: association aggregate: collection
here javaType Indicates the type of object, select Property is equivalent to nesting a query statement
-->
<association property="teacher" column="tid" javaType="Teacher" select="getTeachers" />
</resultMap>
<select id="getTeachers" resultType="Teacher">
select * from teacher
</select>
Nesting according to results (recommended)
Features: complex SQL and simple label writing. (similar to join table query in SQL)
<!--Nested query by result-->
<select id="getStudents2" resultMap="StudentMap2">
select s.id sid,s.name sname,t.name tname from student s,teacher t where s.tid = t.id
</select>
<resultMap id="StudentMap2" type="Student">
<result property="name" column="sname" />
<result property="id" column="sid"/>
<!--Complex objects are handled separately,object:association aggregate:collection-->
<association property="teacher" javaType="Teacher">
<result property="name" column="tname"/>
</association>
</resultMap>
One to many processing
For example: a teacher has multiple students!
For teachers, it is a one to many relationship!
Test environment construction
-
Database tables and fields are the same as above.
-
Entity class
public class Student {
private int id;
private String name;
private int tid;
......
}
public class Teacher {
private int id;
private String name;
//A teacher has many students
private List<Student> students;
......
}
- Establish Mapper interface
public interface TeacherMapper {
//Test get all teachers
public List<Teacher> getTeacher();
}
- Create Mapper.xml file corresponding to the interface
<!--namespace Indicates the interface implemented-->
<mapper namespace="com.carson.dao.TeacherMapper">
<!--Test get all teachers-->
<select id="getTeacher" resultType="Teacher">
select * from teacher
</select>
</mapper>
- Bind Mapper interface or xml file in the core configuration file [there are many methods, you can choose]
<!--Core profile binding interface-->
<mappers>
<mapper class="com.carson.dao.TeacherMapper"/>
<mapper class="com.carson.dao.StudentMapper"/>
</mappers>
- Write test code to test.
Nested processing by query:
<!--Nested processing by query-->
<select id="getTeacher2" resultMap="TeacherMap2">
select * from teacher
</select>
<resultMap id="TeacherMap2" type="Teacher">
<result property="id" column="id"/>
<result property="name" column="name"/>
<!--Complex objects,It needs to be handled separately,object:association aggregate:collection
javaType: Specifies the type of the property
ofType: Represents generic information in a collection-->
<collection property="students" javaType="ArrayList" ofType="Student" column="id" select="getStudent"/>
</resultMap>
<select id="getStudent" resultType="Student">
select * from student where tid=#{tid}
</select>
Nesting according to results (recommended)
<!--Nested query by result-->
<select id="getTeacher" resultMap="TeacherMap">
select s.id sid,s.name sname,t.name tname,t.id tid from student s,teacher t where s.tid=t.id and t.id=#{tid}
</select>
<resultMap id="TeacherMap" type="Teacher">
<result property="id" column="tid"/>
<result property="name" column="tname"/>
<!--Complex objects,It needs to be handled separately,object:association aggregate:collection
javaType: Specifies the type of the property
ofType: Represents generic information in a collection-->
<collection property="students" ofType="Student">
<result property="id" column="sid"/>
<result property="name" column="sname"/>
<result property="tid" column="tid"/>
</collection>
</resultMap>
Summary:
-
association: association [many to one]
-
Set: collection [one to many]
-
About javaType and ofType
- javaType is used to specify the type of attribute in the entity class
- ofType is used to specify the pojo type mapped to the collection, that is, the constraint type in the generic type
Note:
- Ensure the readability of SQL and make it easy to understand as much as possible
- Note the problems of one to many and many to one, attribute names and fields.
- Nested processing by query
- Nesting according to results * * (recommended)**
Dynamic SQL
What is dynamic SQL: dynamic SQL refers to generating different SQL statements according to different conditions.
The essence of dynamic SQL: the essence is still SQL statements, but logical code can be executed at the SQL level.
If you have used JSTL or any text processor based on XML like language, you may feel familiar with dynamic SQL elements. In previous versions of MyBatis, it took time to understand a large number of elements.
MyBatis 3 replaces most of the previous elements and simplifies the types of elements. Now there are fewer types of elements to learn than half of the original.
- if
- choose (when, otherwise)
- trim (where, set)
- foreach
Test environment construction
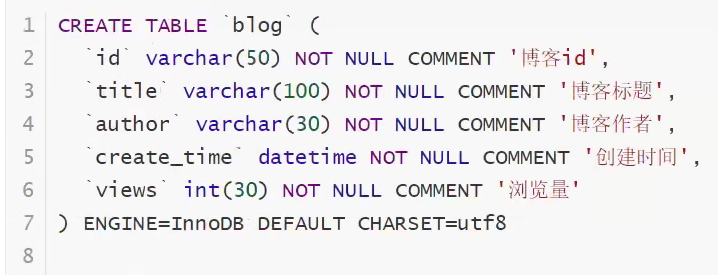
Required database tables:
The required tool class for generating UUID:
package com.carson.utils;
import org.junit.Test;
import java.util.UUID;
//Suppression warning
@SuppressWarnings("all")
public class IDutils {
public static String getId(){
//Create UUID and return it as record id to ensure the uniqueness of each record
return UUID.randomUUID().toString().replaceAll("-","");
}
//Test whether UUID can be generated correctly
@Test
public void test(){
System.out.println(IDutils.getId());
System.out.println(IDutils.getId());
System.out.println(IDutils.getId());
}
}
Create a maven foundation project:
- Add resource export configuration in maven's pom.xml:
<!--newly build maven project,Add the following resources to export the configuration,Prevent resource export failure-->
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
<resource>
<directory>src/main/java/com/carson/dao</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
</resources>
</build>
- Write the core configuration file of mybatis
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!--configuration Core profile-->
<configuration>
<!--Import external profile-->
<!--Because the configuration file is resources Under resource directory,Therefore, the file path does not need to write the full path-->
<properties resource="db.properties"/>
<!--Set log factory-->
<settings>
<!--Configure as standard log output-->
<setting name="logImpl" value="STDOUT_LOGGING"/>
<!--Whether to enable automatic hump naming mapping
That is, from the classic database column name A_COLUMN Map to classic Java Attribute name aColumn
-->
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
<!--Entity classes can be aliased, and the order of labels is required-->
<typeAliases>
<!--By scanning the package where the entity class is located,Its default alias is the lowercase of the class name of this class-->
<!--The classes under the package here are User, The default alias is:user-->
<package name="com.carson.pojo" />
</typeAliases>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/><!--transaction management JDBC-->
<dataSource type="POOLED">
<!--value Value reads the configuration file directly ${Variable name}The way-->
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<!--Core profile binding interface-->
<mappers>
<mapper class="com.carson.dao.BlogMapper"/>
</mappers>
</configuration>
- Writing entity classes
package com.carson.pojo;
import java.util.Date;
public class Blog {
private String id;
private String title;
private String author;
private Date createTime;//The attribute name and data field are inconsistent, and hump mapping is enabled in the core configuration file
private int views;
public Blog() {
}
public Blog(String id, String title, String author, Date createTime, int views) {
this.id = id;
this.title = title;
this.author = author;
this.createTime = createTime;
this.views = views;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public Date getCreateTime() {
return createTime;
}
public void setCreateTime(Date createTime) {
this.createTime = createTime;
}
public int getViews() {
return views;
}
public void setViews(int views) {
this.views = views;
}
@Override
public String toString() {
return "Blog{" +
"id='" + id + '\'' +
", title='" + title + '\'' +
", author='" + author + '\'' +
", createTime=" + createTime +
", views=" + views +
'}';
}
}
- Write the Mapper interface and Mapper.xml file corresponding to the entity class
public interface BlogMapper {
//insert data
public int addBlog(Blog blog);
}
<mapper namespace="com.carson.dao.BlogMapper">
<!--insert data-->
<insert id="addBlog" parameterType="Blog">
insert into blog values(#{id},#{title},#{author},#{createTime},#{views})
</insert>
</mapper>
- Write test code to insert data
public class DaoTest {
//Test insert data
public static void main(String[] args) {
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
//create a blog object
Blog blog = new Blog();
blog.setId(IDutils.getId());//Set the ID to UUID to ensure uniqueness
blog.setTitle("Mybatis such easy!");
blog.setAuthor("Carson");
blog.setCreateTime(new Date());
blog.setViews(9999);
int affectedRows = mapper.addBlog(blog);
if(affectedRows>0){
System.out.println("Insert data succeeded");
}
blog.setId(IDutils.getId());
blog.setViews(1000);
blog.setTitle("JAVA such easy!");
affectedRows = mapper.addBlog(blog);
if(affectedRows>0){
System.out.println("Insert data succeeded");
}
blog.setId(IDutils.getId());
blog.setViews(9999);
blog.setTitle("Spring such easy!");
affectedRows = mapper.addBlog(blog);
if(affectedRows>0){
System.out.println("Insert data succeeded");
}
blog.setId(IDutils.getId());
blog.setViews(9999);
blog.setTitle("So is microservice easy!");
affectedRows = mapper.addBlog(blog);
if(affectedRows>0){
System.out.println("Insert data succeeded");
}
}catch (Exception e){
e.printStackTrace();
}finally {
sqlSession.close();
}
}
}
Therefore, the data sharing of SQL script can also be realized by using Java script.
IF statement of dynamic SQL
Requirement: the method returns specific records when passing in parameters, and all records when no data is passed in
resolvent:
Method 1: Rewrite multiple methods in the interface (i.e. methods with input parameters and methods without input parameters)
Method 2: use IF statement of dynamic SQL to solve the problem. (the test attribute corresponds to a statement expression)
- What dynamic SQL usually needs to do is to decide whether to add some conditions to the where clause according to the conditions
- Write Mapper interface method:
//IF statement of dynamic SQL to query blog records public List<Blog> queryBlogIF(Map map);
- Write Mapper.xml file corresponding to the interface:
<!--dynamic SQL of IF Statement to query blog records-->
<select id="queryBlogIF" parameterType="map" resultType="blog">
select * from blog where 1=1
<if test="title != null">
and title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</select>
- Write test code:
//Dynamic SQL query blog record
@Test
public void queryBlogIF(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
Map map = new HashMap();
//map.put("title","Mybatis so easy!");
//map.put("author","Carson");
List<Blog> blogs = mapper.queryBlogIF(map);
for (Blog blog : blogs) {
System.out.println(blog);
}
}catch (Exception e){
e.printStackTrace();
}finally {
sqlSession.close();
}
}
trim (where, set) of dynamic SQL
where
-
Problems encountered when not using the where tag
-
<select id="queryBlogIF" resultType="blog"> SELECT * FROM blog WHERE <if test="state != null"> state = #{state} </if> <if test="title != null"> AND title like #{title} </if> </select> -
What happens if there are no matching conditions? Finally, the SQL will become as follows: (query failed)
-
SELECT * FROM blog WHERE
-
What if only the second condition matches? This SQL will look like this: (query failed)
-
SELECT * FROM blog WHERE AND title like 'someTitle'
-
After using the where tag
-
The where element inserts the "where" clause only if the child element returns content. Moreover, if the child elements of where start with "AND" OR ", the where element will also remove them.
-
<!--dynamic SQL of where Tag to query blog records--> <select id="queryBlogWhere" parameterType="map" resultType="blog"> select * from blog <where> <if test="title != null"> title = #{title} </if> <if test="author != null"> and author = #{author} </if> </where> </select> -
When the first condition is matched, the SQL will eventually become as follows:
-
select * from blog WHERE title = ?
-
When the second condition is matched, it will automatically remove and, so the SQL will eventually become as follows:
-
select * from blog WHERE author = ?
-
When the first and second matching conditions are not met, the where clause will not be inserted, and the SQL will become like this:
-
select * from blog
-
Customize the function of the where element by customizing the trim element
-
The user-defined trim elements equivalent to the where element are:
-
<trim prefix="WHERE" prefixOverrides="AND |OR "> ... </trim>
-
The prefixOverrides property ignores text sequences separated by pipe characters (note that spaces in prefixOverrides are necessary). The above example will remove all the contents specified in the prefixOverrides attribute and insert the contents specified in the prefix attribute.
-
Therefore, the equivalent form of the above sql is:
-
<select id="queryBlogWhere" parameterType="map" resultType="blog"> select * from blog <trim prefix="where" prefixOverrides="AND | OR"> <if test="title != null"> title = #{title} </if> <if test="author != null"> and author = #{author} </if> </trim> </select>
-
SET
-
A similar solution to SQL statements for dynamic updates is called the SET tag. The SET element can be used to dynamically include columns that need to be updated and ignore other columns that do not need to be updated. The SET element dynamically inserts the SET keyword at the beginning of the line and deletes the extra comma. For example:
-
<!--dynamic SQL of SET To modify blog records--> <update id="updateBlogBySet" parameterType="map"> update blog <set> <if test="title != null"> title = #{title}, </if> <if test="author != null"> author = #{author} </if> </set> where id = #{id} </update> -
When both conditions are met, the output sql statement is:
-
update blog SET title = ?, author = ? where id = ?
-
When the first condition is met, the comma will be removed automatically, so the output sql statement is:
-
update blog SET title = ? where id = ?
-
-
Custom trim element equivalent to set element
-
The suffix value setting is overridden and the prefix value is customized.
-
<trim prefix="SET" suffixOverrides=","> ... </trim>
-
Therefore, the equivalent form of the above sql is:
-
<update id="updateBlogBySet" parameterType="map"> update blog <trim prefix="SET" suffixOverrides=","> <if test="title != null"> title = #{title}, </if> <if test="author != null"> author = #{author}, </if> </trim> where id = #{id} </update>
-
choose (when, otherwise) of dynamic SQL
Sometimes, we don't want to use all the conditions, but just want to choose one from multiple conditions. In this case, MyBatis provides a choose element, which is a bit like a switch statement in Java.
-
<!--dynamic SQL of choose,when,otherwise Query blog records--> <select id="queryBlogChoose" parameterType="map" resultType="blog"> select * from blog <where> <choose> <when test="title != null"> title = #{title} </when> <when test="author != null"> and author = #{author} </when> <otherwise> and views = #{views} </otherwise> </choose> </where> </select>-
When all three parameters exist, * * select the first one to execute, * * the output sql is:
-
select * from blog WHERE title = ?
-
When only the third parameter exists, only the default will be used. The output sql is:
-
select * from blog WHERE views = ?
-
That is, choose will insert a qualified statement from top to bottom
-
SQL fragment
Sometimes, we may extract some common function code parts for reuse!
- Extract common parts using sql tags.
<!--extract SQL Fragment to query blog records-->
<sql id="if-title-author">
<if test="title != null">
title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</sql>
- Use the include tag reference where necessary.
<!--SQL Fragment test-->
<select id="queryBlogBySql" parameterType="map" resultType="blog">
select * from blog
<where>
<include refid="if-title-author"></include>
</where>
</select>
matters needing attention:
- It is best to define SQL fragments based on a single table!
- Do not include the where tag in the extracted common code! Because it will limit scalability!
foreach of dynamic SQL
A common usage scenario for dynamic SQL is to traverse a collection (especially when building IN conditional statements).
- Write interface method:
//Implementation of dynamic SQL foreach to query blog records public List<Blog> queryBlogForeach(Map map);
- Write interface configuration file:
<!--dynamic SQL of foreach Query blog records
collection:Corresponding set name
open:Corresponding start symbol
close:Corresponding end symbol
seperator:Corresponding separator
index:Sequence number of corresponding iteration
item:Specific value of corresponding iteration
-->
<select id="queryBlogForeach" parameterType="map" resultType="blog">
select * from blog
<where>
id in
<foreach collection="ids" open="(" close=")" separator="," item="id">
#{id}
</foreach>
</where>
</select>
The corresponding output sql is:
select * from blog WHERE id in ( ? , ? , ? )
- Write test code:
//queryBlogForeach
@Test
public void queryBlogForeach(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
//Define a collection and add data
ArrayList<String> ids = new ArrayList<String>();
ids.add("58ee7492a6974aafa6a7712226d57188");
ids.add("6a1900626bd149bc98e48f246e2e21fb");
ids.add("b56e45facb67420e84c275cf0f39e043");
//Omnipotent map
Map map = new HashMap();
map.put("ids",ids);//The key name is ids, and the value corresponds to the set ids
List<Blog> blogs = mapper.queryBlogForeach(map);
for (Blog blog : blogs) {
System.out.println(blog);
}
}catch (Exception e){
e.printStackTrace();
}finally {
sqlSession.close();
}
}
Summary
- Dynamic SQL is splicing SQL statements. We just need to ensure the correctness of SQL and arrange and combine them according to the format of SQL.
- First write a complete SQL on the mysql console to verify the correctness of the SQL, and then splice the corresponding dynamic SQL
Cache (understand)
brief introduction
-
What is a cache?
- There is temporary data in memory.
- Caching refers to query caching.
- The data frequently queried by the user is placed in the cache (memory). When the user queries the data, it does not need to query from the disk (relational database data file), but from the cache, so as to improve the query efficiency and solve the performance problem of high concurrency system [read-write separation, master-slave replication]
-
Why cache?
- Reduce the number of interactions with the database, reduce system overhead and improve system efficiency.
- When querying the same data, directly go to the cache instead of the database.
- Improve query efficiency.
-
What kind of data is suitable for caching? What kind of data is not suitable for caching?
- Frequently queried and infrequently changed data [suitable for caching]
- Infrequently queried and frequently changed data [not suitable for caching]
Mybatis cache
- Mybatis includes a very powerful query caching feature that makes it easy to customize and configure caching
- Using cache can greatly improve query efficiency.
- Mybatis defines two levels of cache by default: L1 cache and L2 cache.
- By default, only L1 cache is on. (SqlSession level cache, also known as local cache)
- L2 cache needs to be manually enabled and configured. (namespace level based caching)
- In order to improve scalability, Mybatis defines the Cache interface Cache, which can be used to customize the L2 Cache by implementing the Cache interface.
L1 cache
-
The first level cache is also called local cache.
- On by default.
- The data queried during the same session with the database will be placed in the local cache.
- If you need to get the same data in the future, you can get it directly from the cache. You don't have to query the database.
- The results of all select statements in the mapping statement file will be cached.
- All insert, update, and delete statements in the mapping statement file flush the cache.
- The cache will use the least recently used (LRU) algorithm to clear the unnecessary cache.
- The cache does not refresh regularly (that is, there is no refresh interval).
-
L1 query cache test:
- Open the log. (easy to view output information)
<!--Configure as standard log output--> <setting name="logImpl" value="STDOUT_LOGGING"/>
- The test queries the same record twice in an sqlSession.
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
//Query the same user information
User user = mapper.queryUserByID(1);
System.out.println(user);
System.out.println("===============================");
//Query the same user information
User user1 = mapper.queryUserByID(1);
System.out.println(user1);
System.out.println(user==user1);
}catch(Exception e){
e.printStackTrace();
}finally {
sqlSession.close();
}
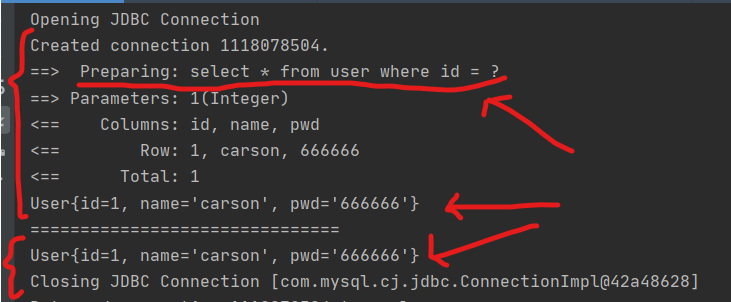
- View the log output (only one sql statement is executed, indicating that the content of the second query is obtained from the cache)
-
L1 cache refresh test (adding, deleting and modifying will refresh the cache)
- The test adds an update operation between two queries of the same record:
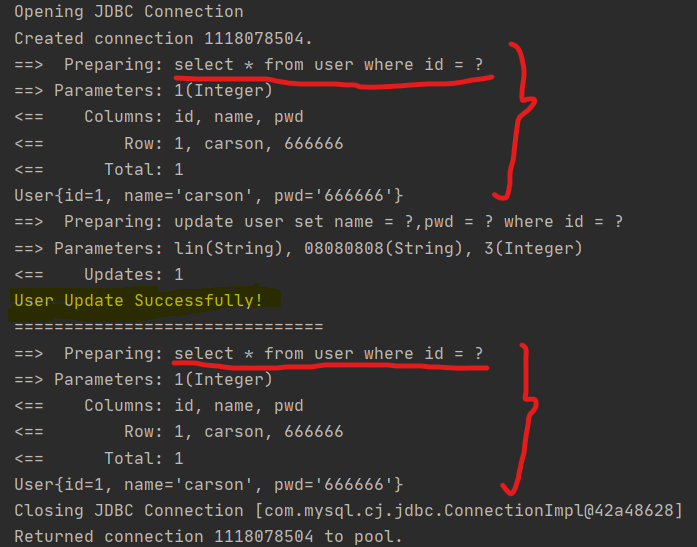
SqlSession sqlSession = MybatisUtils.getSqlSession(); try{ UserMapper mapper = sqlSession.getMapper(UserMapper.class); //Query the same user information User user = mapper.queryUserByID(1); System.out.println(user); //Update a user information in the middle of the test int affectedRows = mapper.updateUser(new User(3,"lin","08080808")); if(affectedRows > 0){ System.out.println("User Update Successfully!"); } System.out.println("==============================="); //Query the same user information User user1 = mapper.queryUserByID(1); System.out.println(user1); System.out.println(user==user1); }catch(Exception e){ e.printStackTrace(); }finally { sqlSession.close(); }- View the log output (because the update statement is added, the cache will be updated, so the data will be queried from the database when querying the same record twice)
L1 cache invalidation:
- Query different records.
- Adding, deleting and modifying may change the original data, so the cache will be refreshed!
- Query different Mapper.xml files.
- Manually clean up the cache.
//Manual request cache sqlSession.clearCache();
Summary:
- The L1 cache is enabled by default and is only valid in one sqlSession, that is, the interval from getting the connection to closing the connection.
- The first level cache is essentially a Map.
L2 cache
- L2 cache is also called global cache. The scope of L1 cache is too low, so L2 cache was born.
- L2 cache is a cache based on namespace level, that is, a namespace corresponds to a L2 cache.
- Working mechanism:
- When a session queries a piece of data, the data will be placed in the first level cache of the current session;
- If the current session is closed, the L1 cache corresponding to the session is gone; But what we want is that the session is closed and the data in the L1 cache is saved to the L2 cache;
- With the new session query information, you can get the content from the L2 cache.
- The data found by different mapper interfaces will be placed in their corresponding cache (map).
Steps:
- Explicitly turn on global cache:
<!--Explicitly turn on global cache(The default global cache is on)--> <setting name="cacheEnabled" value="true"/>
- To enable global L2 caching, simply add a line to the Mapper configuration file:
<cache/>
You can also customize parameters:
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
- Testing.
//Create two sqlsessions SqlSession sqlSession = MybatisUtils.getSqlSession(); SqlSession sqlSession2 = MybatisUtils.getSqlSession(); //Create two mapper s accordingly UserMapper mapper = sqlSession.getMapper(UserMapper.class); UserMapper mapper2 = sqlSession2.getMapper(UserMapper.class); //sqlsession execution method User user = mapper.queryUserByID(1); System.out.println(user); sqlSession.close(); //sqlSession2 execution method User user2 = mapper2.queryUserByID(1); System.out.println(user2); //Are the objects the same System.out.println(user==user2);
Note: problems encountered during configuration:
Caused by: java.io.NotSerializableException: com.carson.pojo.User
Two solutions:
- The entity class needs to be serialized: (involving io cache or network transmission. That is, the entity class needs to implement the Serializable interface):
public class User implements Serializable {...}
- Set the configuration property readonly to true:
<!--Enable global L2 cache--> <cache readOnly="true"/>
Summary:
- As long as the L2 cache is enabled, it is valid under the same Mapper.
- All cached data will be placed in the first level cache first;
- Only when the session is closed or committed will the cached data be submitted to the L2 cache!
Cache principle
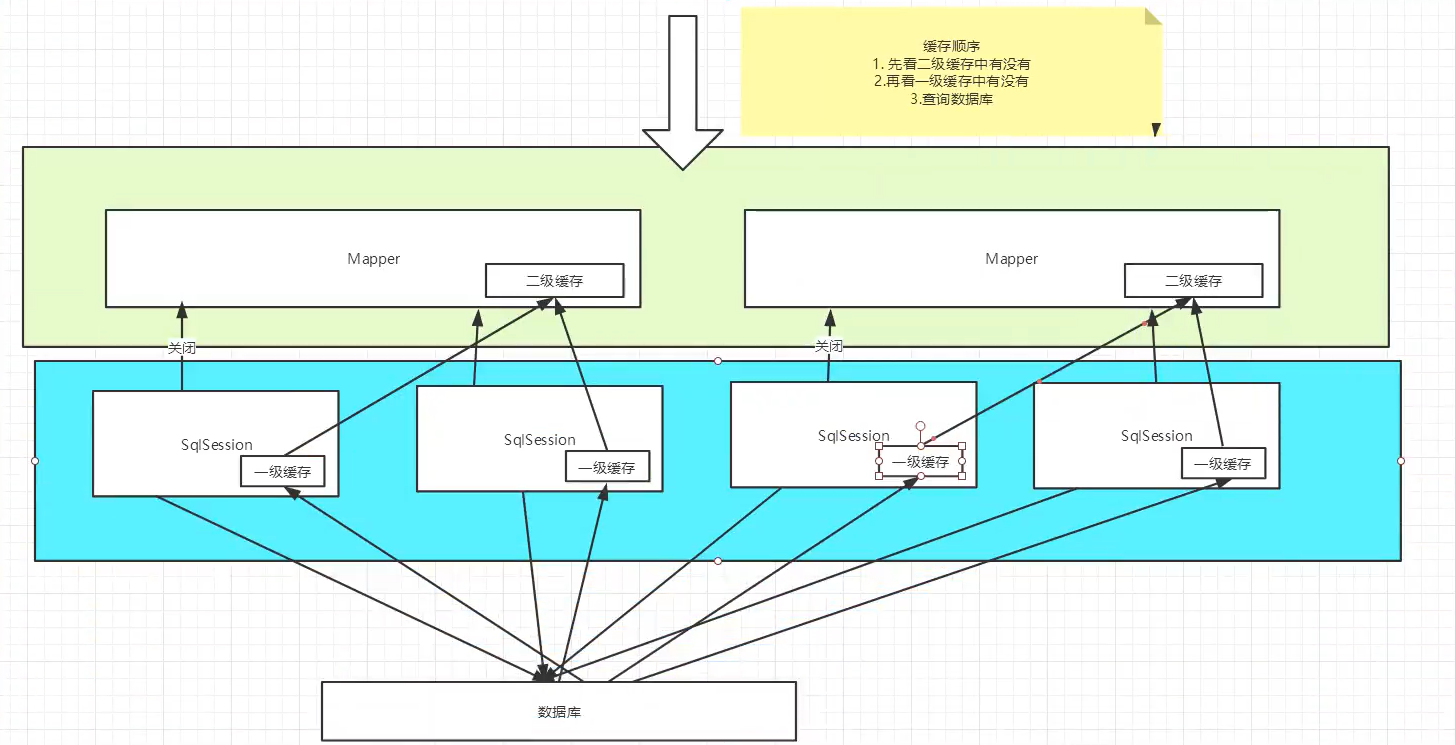
Custom cache ehcache
EhCache A widely used open source Java Distributed cache, fast and lean, mainly for general cache
Just know, skip it for the time being. redis (k-v non relational database) is used for caching in work.
Creation is not easy! Welcome comments / likes!!!