Mybatis source code analysis (2) - loading Configuration
as seen above, the Configuration object holds all the Configuration information of Mybatis, that is, all the information in mybatis-config.xml and mapper.xml
Are available in the Configuration object. So in general, there is only one Configuration object. From the previous article, we learned about mybatis-config.xml and mapper.xml
It is parsed and stored to Configuration through XMLConfigBuilder and XMLMapperBuilder respectively. But there are two questions we need to understand:
- 1. How do XMLConfigBuilder and XMLMapperBuilder parse xml information?
- 2. What is the internal structure of Configuration? How does it store xml information?
then, let's take these two questions to analyze the source code!
I. Configuration property
Configuration contains settings and property information that deeply affect MyBatis behavior The top-level structure of the Configuration document is as follows:
-
configuration
- properties
- settings
- typeAliases (type aliases)
- typeHandlers (type processors)
- objectFactory (object factory)
- plugins (plug-ins)
-
environments (environment configuration)
- Environment (environment variable)
- Transaction manager
- dataSource (data source)
- databaseIdProvider (database vendor ID)
- mappers (mapper)
. An example of a relatively complete configuration of the settings element is as follows:
<settings>
<! -- globally turn on or off any caching that all mappers in the configuration file have configured -- >
<setting name="cacheEnabled" value="true"/>
<! -- global switch for delayed loading. When on, all associated objects delay loading The switch state of the item can be overridden by setting the fetchType property in a specific association >
<setting name="lazyLoadingEnabled" value="true"/>
<! -- allow single statement to return multiple result sets (need driver support) -- >
<setting name="multipleResultSetsEnabled" value="true"/>
<! -- use column labels instead of column names -- >
<setting name="useColumnLabel" value="true"/>
<! -- allows JDBC to support automatic primary key generation, which requires driver support If set to true, this setting forces the use of auto generate primary key. A lt hough some drivers can't support it, they still work normally (such as Derby) -- >
<setting name="useGeneratedKeys" value="false"/>
<! -- specifies how MyBatis should automatically map columns to fields or properties NONE means unmapping automatically; PARTIAL only maps result sets that have no nested result set mapping defined FULL automatically maps any complex result set (nested or not) -- >
<setting name="autoMappingBehavior" value="PARTIAL"/>
<! -- specifies the behavior of discovering unknown columns (or unknown property types) for automatic mapping targets.
NONE: no reaction
WARNING: output reminder log ('org.apache.ibatis.session.AutoMappingUnknownColumnBehavior 'log level must be set to WARN)
Failure: mapping failed (sqlsessionexception thrown) - >
<setting name="autoMappingUnknownColumnBehavior" value="WARNING"/>
<! -- configure the defau lt actuator. SIMPLE is a common executor; REUSE executor reuses prepared statements; BATCH executor reuses statements and performs BATCH update -- >
<setting name="defaultExecutorType" value="SIMPLE"/>
<! -- sets the timeout, which determines the number of seconds the driver waits for a response from the database -- >
<setting name="defaultStatementTimeout" value="25"/>
<! -- sets a prompt value for the fetchSize of the driven resu lt set. This parameter can only be overridden in query settings -- >
<setting name="defaultFetchSize" value="100"/>
<! -- allows paging (RowBounds) in nested statements. Set to false if allowed -- >
<setting name="safeRowBoundsEnabled" value="false"/>
<! -- whether to turn on the mapping of camel case, that is, the similar mapping from the classic database column name a column to the classic Java attribute name aColumn -- >
<setting name="mapUnderscoreToCamelCase" value="false"/>
<! -- mybatis uses the Local Cache mechanism to prevent circular references and speed up repeated nested queries The default is SESSION, which caches all queries executed in a SESSION If the value is set to STATEMENT, the local SESSION is only used for STATEMENT execution, and different calls to the same SqlSession will not share data -- >
<setting name="localCacheScope" value="SESSION"/>
<! -- specifies the JDBC type for NULL when no specific JDBC type is provided for the parameter Some drivers need to specify the JDBC type of the column. In most cases, you can use the general type directly, such as NULL, VARCHAR or other -- >
<setting name="jdbcTypeForNull" value="OTHER"/>
<! -- specifies which object's method triggers a lazy load -- >
<setting name="lazyLoadTriggerMethods" value="equals,clone,hashCode,toString"/>
<! -- specifies the specific implementation of the logs used by MyBatis. If it is not specified, it will be found automatically. >
<setting name="logImpl" value="STDOUT_LOGGING" />
</settings>
check the Configuration source code, and we can easily find the corresponding field properties of the above Configuration:
protected Environment environment; protected boolean safeRowBoundsEnabled = false; protected boolean safeResultHandlerEnabled = true; protected boolean mapUnderscoreToCamelCase = false; protected boolean aggressiveLazyLoading = true; protected boolean multipleResultSetsEnabled = true; protected boolean useGeneratedKeys = false; protected boolean useColumnLabel = true; protected boolean cacheEnabled = true; protected boolean callSettersOnNulls = false; protected String logPrefix; protected Class <? extends Log> logImpl; protected LocalCacheScope localCacheScope = LocalCacheScope.SESSION; protected JdbcType jdbcTypeForNull = JdbcType.OTHER; protected Set<String> lazyLoadTriggerMethods = new HashSet<String>(Arrays.asList(new String[] { "equals", "clone", "hashCode", "toString" })); protected Integer defaultStatementTimeout; protected ExecutorType defaultExecutorType = ExecutorType.SIMPLE; protected AutoMappingBehavior autoMappingBehavior = AutoMappingBehavior.PARTIAL; protected Properties variables = new Properties(); protected ObjectFactory objectFactory = new DefaultObjectFactory(); protected ObjectWrapperFactory objectWrapperFactory = new DefaultObjectWrapperFactory(); protected MapperRegistry mapperRegistry = new MapperRegistry(this); protected boolean lazyLoadingEnabled = false; protected ProxyFactory proxyFactory; protected String databaseId; protected Class<?> configurationFactory; protected final InterceptorChain interceptorChain = new InterceptorChain(); protected final TypeHandlerRegistry typeHandlerRegistry = new TypeHandlerRegistry(); protected final TypeAliasRegistry typeAliasRegistry = new TypeAliasRegistry(); protected final LanguageDriverRegistry languageRegistry = new LanguageDriverRegistry();
the above field attribute corresponds to mybatis-config.xml configuration file, so the field attribute corresponding to mapper.xml is as follows:
protected final Map<String, MappedStatement> mappedStatements = new StrictMap<MappedStatement>("Mapped Statements collection"); protected final Map<String, Cache> caches = new StrictMap<Cache>("Caches collection"); protected final Map<String, ResultMap> resultMaps = new StrictMap<ResultMap>("Result Maps collection"); protected final Map<String, ParameterMap> parameterMaps = new StrictMap<ParameterMap>("Parameter Maps collection"); protected final Map<String, KeyGenerator> keyGenerators = new StrictMap<KeyGenerator>("Key Generators collection"); protected final Map<String, XNode> sqlFragments = new StrictMap<XNode>("XML fragments parsed from previous mappers");
among them, we need to focus on mappedStatements, resultMaps and sqlFragments
- resultMaps: it is not difficult to understand that the information of the resultMap node in mapper.xml is saved
- mappedStatements: save the select/update/insert/delete node information in Mapper configuration file
- sqlFragments: save the sql node information in Mapper configuration file
public V put(String key, V value) { if (containsKey(key)) throw new IllegalArgumentException(name + " already contains value for " + key); if (key.contains(".")) { final String shortKey = getShortName(key); if (super.get(shortKey) == null) { // Deposit abbreviation key super.put(shortKey, value); } else { // If the value stored in the duplicate key is Ambiguity, it will be judged whether the value is Ambiguity when get ting. If yes, an exception will be thrown super.put(shortKey, (V) new Ambiguity(shortKey)); } } // Full name key return super.put(key, value); } public V get(Object key) { V value = super.get(key); if (value == null) { throw new IllegalArgumentException(name + " does not contain value for " + key); } // Judge whether the type is Ambiguity if (value instanceof Ambiguity) { throw new IllegalArgumentException(((Ambiguity) value).getSubject() + " is ambiguous in " + name + " (try using the full name including the namespace, or rename one of the entries)"); } return value; } // Intercept the string after the last "." symbol as shortName private String getShortName(String key) { final String[] keyparts = key.split("\\."); final String shortKey = keyparts[keyparts.length - 1]; return shortKey; }
from the source code, we can see that it rewrites the put and get methods, where the put method deals with the key in three aspects:
- 1. Intercept the string after the last "." symbol as key to store value once
- 2. When the key is duplicate, the stored value is an Ambiguity object. When get gets, it will judge whether the value is not of Ambiguity type. If so, an exception will be thrown
- 3. Directly call super.put(key, value) to store the same value once (at this time, the key does not do any operation processing)
that is, for:
StrictMap.put("com.xxx.selectId","select * from user where id=?")
in this put request, there are two different key s in the StrictMap, but the elements with the same value:
com.xxx.selectId = select * from user where id=? selectId = select * from user where id=?
.
2. XMLConfigBuilder.parse()
. Parse() is mainly used to analyze the information of mybatis-config.xml configuration file. It has no much significance to analyze. I'll give you
public Configuration parse() { if (parsed) { throw new BuilderException("Each XMLConfigBuilder can only be used once."); } parsed = true; parseConfiguration(parser.evalNode("/configuration")); return configuration; } private void parseConfiguration(XNode root) { try { // Resolving the properties node propertiesElement(root.evalNode("properties")); // Resolving typeAliases nodes typeAliasesElement(root.evalNode("typeAliases")); // Parsing plugins nodes pluginElement(root.evalNode("plugins")); // Resolve the objectFactory (database return result set use) node objectFactoryElement(root.evalNode("objectFactory")); objectWrapperFactoryElement(root.evalNode("objectWrapperFactory")); // Parse settings node settingsElement(root.evalNode("settings")); // Analyze the environments node environmentsElement(root.evalNode("environments")); databaseIdProviderElement(root.evalNode("databaseIdProvider")); typeHandlerElement(root.evalNode("typeHandlers")); // Parsing mappers node mapperElement(root.evalNode("mappers")); } catch (Exception e) { throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e); } }
III. XmlMapperBuilder.parse()
. What XmlMapperBuilder.parse() does is to assemble various components (mappers). Let's look at the source code of XmlMapperBuilder.parse():
public void parse() { if (!configuration.isResourceLoaded(resource)) { // Source of analytical method configurationElement(parser.evalNode("/mapper")); configuration.addLoadedResource(resource); bindMapperForNamespace(); } parsePendingResultMaps(); parsePendingChacheRefs(); parsePendingStatements(); } // Core analytical method private void configurationElement(XNode context) { try { // We all know that Mapper's namespace corresponds to Mapper's interface path, so we need to judge the namespace String namespace = context.getStringAttribute("namespace"); if (namespace.equals("")) { throw new BuilderException("Mapper's namespace cannot be empty"); } // Set up namespace for mapperbuilder assistant builderAssistant.setCurrentNamespace(namespace); cacheRefElement(context.evalNode("cache-ref")); cacheElement(context.evalNode("cache")); parameterMapElement(context.evalNodes("/mapper/parameterMap")); // Parsing the resultMap node information resultMapElements(context.evalNodes("/mapper/resultMap")); // Parsing sql node information sqlElement(context.evalNodes("/mapper/sql")); // Parse the select Insert update delete node information buildStatementFromContext(context.evalNodes("select|insert|update|delete")); } catch (Exception e) { throw new BuilderException("Error parsing Mapper XML. Cause: " + e, e); } }
we can see that the core parsing methods are loaded for different nodes respectively. Let's look at the parsing loading of resultMap first:
Load the resultMap node
as officially described: resultMap is the most complex and powerful element (used to describe how to load objects from the database result set) So its resolution complexity is also the most complex. Let's first look at a simple resultMap node configuration:
<resultMap id="selectUserById" type="User"> <id property="id" column="id"/> <result property="name" column="name"/> <result property="phone" column="phone"/> </resultMap>
private ResultMap resultMapElement(XNode resultMapNode, List<ResultMapping> additionalResultMappings) throws Exception { ErrorContext.instance().activity("processing " + resultMapNode.getValueBasedIdentifier()); // Get the ID configuration information in the resultMap node, that is, the id="selectUserById" listed above String id = resultMapNode.getStringAttribute("id", resultMapNode.getValueBasedIdentifier()); // Get the type configuration information in the resultMap node, that is, the type="User" listed above String type = resultMapNode.getStringAttribute("type", resultMapNode.getStringAttribute("ofType", resultMapNode.getStringAttribute("resultType", resultMapNode.getStringAttribute("javaType")))); String extend = resultMapNode.getStringAttribute("extends"); Boolean autoMapping = resultMapNode.getBooleanAttribute("autoMapping"); Class<?> typeClass = resolveClass(type); Discriminator discriminator = null; List<ResultMapping> resultMappings = new ArrayList<ResultMapping>(); resultMappings.addAll(additionalResultMappings); // Get the information of all bytes, i.e. id node, result node, etc List<XNode> resultChildren = resultMapNode.getChildren(); for (XNode resultChild : resultChildren) { if ("constructor".equals(resultChild.getName())) { processConstructorElement(resultChild, typeClass, resultMappings); } else if ("discriminator".equals(resultChild.getName())) { discriminator = processDiscriminatorElement(resultChild, typeClass, resultMappings); } else { ArrayList<ResultFlag> flags = new ArrayList<ResultFlag>(); if ("id".equals(resultChild.getName())) { flags.add(ResultFlag.ID); } // Encapsulate the obtained child node information into the resultMapping object. resultMappings.add(buildResultMappingFromContext(resultChild, typeClass, flags)); } } ResultMapResolver resultMapResolver = new ResultMapResolver(builderAssistant, id, typeClass, extend, discriminator, resultMappings, autoMapping); try { // The MapperBuilderAssistant.addResultMap() method is actually called return resultMapResolver.resolve(); } catch (IncompleteElementException e) { configuration.addIncompleteResultMap(resultMapResolver); throw e; } }
from the source code analysis, the whole analysis process is divided into four steps:
- 1. Get the ID configuration information in the resultMap node, that is, the id="blogPostResult" listed above
- 2. Get the type configuration information in the resultMap node, that is, the type="User" (Class name) listed above
- 3. Encapsulate the obtained sub node information into the resultMapping object.
- 4. The MapperBuilderAssistant.addResultMap() method is called to save the data obtained in the above three steps to the Configuration.
There are two key objects: ResultMapping and MapperBuilderAssistant. Mapperbuilder assistant runs through the whole Mapper analysis, so we will not analyze it first. Let's take a look at ResultMapping. The field properties in the source code are as follows:
ResultMapping class properties
private Configuration configuration; private String property; private String column; private Class<?> javaType; private JdbcType jdbcType; private TypeHandler<?> typeHandler; private String nestedResultMapId; private String nestedQueryId; private Set<String> notNullColumns; private String columnPrefix; private List<ResultFlag> flags; private List<ResultMapping> composites; private String resultSet; private String foreignColumn; private boolean lazy;
ResultMap class properties
private String id; private Class<?> type; private List<ResultMapping> resultMappings; private List<ResultMapping> idResultMappings; private List<ResultMapping> constructorResultMappings; private List<ResultMapping> propertyResultMappings; private Set<String> mappedColumns; private Discriminator discriminator; private boolean hasNestedResultMaps; private boolean hasNestedQueries; private Boolean autoMapping;
. Its relationship with resultmap is as follows:
- 1. ResultMap is composed of id, type and a large number of ResultMapping objects.
- 2. The ResultMapping object is the corresponding relationship between the result set (database operation result set) and the java Bean object attributes That is, a ResultMapping object corresponds to a field property in a bean object.
- 3. The ResultMap object is the corresponding relationship between the result set and the java Bean object. That is, a ResultMap object corresponds to a bean object.
Load select Insert update delete node
Let's first look at the configuration of a simple select node element:
<select id="selectPerson" parameterType="int" resultType="hashmap"> SELECT * FROM PERSON WHERE ID = #{id} </select>
let's analyze how it is actually loaded. Let's analyze the source code of the method buildStatementFromContext() to load these four nodes:
private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) { for (XNode context : list) { // Create XMLStatementBuilder final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId); try { // Load through the parseStatementNode() method of XMLStatementBuilder. statementParser.parseStatementNode(); } catch (IncompleteElementException e) { configuration.addIncompleteStatement(statementParser); } } }
we can see that an XMLStatementBuilder object is created inside it, and then it is loaded by calling its parseStatementNode(). After careful discovery, we can see the three relationship construction parameters needed to create the XMLStatementBuilder object: configuration, builder assistant (familiar or not, mapperbuilder assistant), context (node information)
XMLStatementBuilder.parseStatementNode()
The parseStatementNode() method is the core of loading the information of select|insert|update|delete node. Then we will analyze its internal implementation in depth:
// Some relatively unimportant code is omitted public void parseStatementNode() { // We should be familiar with the following configuration information String id = context.getStringAttribute("id"); String parameterMap = context.getStringAttribute("parameterMap"); String parameterType = context.getStringAttribute("parameterType"); Class<?> parameterTypeClass = resolveClass(parameterType); String resultMap = context.getStringAttribute("resultMap"); String resultType = context.getStringAttribute("resultType"); Class<?> resultTypeClass = resolveClass(resultType); // Read < include > information XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant); includeParser.applyIncludes(context.getNode()); // Each < select / >, < update / >, < insert / >, < delete / > is loaded (through the createSqlSource() method) as a dynamicsqlsource (the most commonly used subclass of sqlsource): the internal existence of getBoundSql() method will read the content of the mapping statement from the XML file and encapsulate it as BoundSql. String lang = context.getStringAttribute("lang"); LanguageDriver langDriver = getLanguageDriver(lang); SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass); ..... // Add MappedStatement information through MapperBuilderAssistant's addMappedStatement(). builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType, fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass, resultSetTypeEnum, flushCache, useCache, resultOrdered, keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets); }
According to the source code, we can roughly divide the whole process into four parts:
- 1. Read the attribute information of the select Insert update delete node, such as: id, resultMap, etc
- 2. Process the < include > node information, and replace the < include > in SQl with the real SQLs through the XMLIncludeTransformer.applyIncludes() method
- 3. Load (pass) the internal information (i.e. SQL statement) of each select|insert|update|delete node into a SqlSource through the LanguageDriver.createSqlSource() method: the internal getBoundSql() method will replace the SQL (mainly replace {} and ${}) and encapsulate it as BoundSql.
- 4. Add MappedStatement information to Configuration through the addMappedStatement() method of MapperBuilderAssistant.
public SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) { XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType); return builder.parseScriptNode(); }
its internal is to create SqlSource through XMLScriptBuilder.parseScriptNode() method, and continue to query the internal source code of the method:
public SqlSource parseScriptNode() { // Load one SQL content into two sqlnodes List<SqlNode> contents = parseDynamicTags(context); // Combining multiple sqlnodes into a single SqlNode through the combination mode MixedSqlNode rootSqlNode = new MixedSqlNode(contents); SqlSource sqlSource = null; if (isDynamic) { // Create a dynamic SqlSource sqlSource = new DynamicSqlSource(configuration, rootSqlNode); } else { // Create the original (static) SqlSource sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType); } return sqlSource; }
<select id="selectStudents" parameterType="int" resultType="hashmap"> select stud_id as studId, name, phone from students <where> name = #{name} <if test="phone != null"> AND phone = #{phone} </if> </where> </select>
? If we divide some key points, is it relatively good to parse them? So there are IfSqlNode, WhereSqlNode, etc. you can understand that IfSqlNod is used for storage without looking at it:
<if test="phone != null"> AND phone = #{phone} </if>
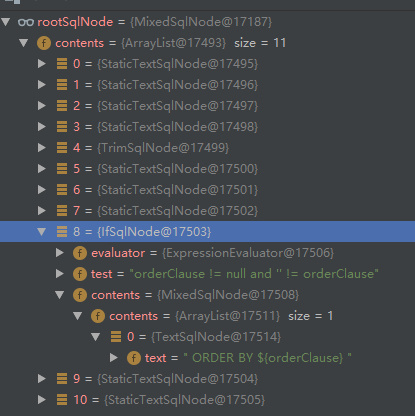
when we get BoundSql, IfSqlNode will judge whether the condition is met. So the whole SqlNode system is huge, and they have different responsibilities. From the above we can see that SqlNode is used as the parameter to create DynamicSqlSource object Let's look at the DynamicSqlSource source source code. See how it gets BoundSql:
public class DynamicSqlSource implements SqlSource { private Configuration configuration; // Stored SQL fragment information private SqlNode rootSqlNode; public DynamicSqlSource(Configuration configuration, SqlNode rootSqlNode) { this.configuration = configuration; this.rootSqlNode = rootSqlNode; } public BoundSql getBoundSql(Object parameterObject) { DynamicContext context = new DynamicContext(configuration, parameterObject); // When every SqlNode's apply method is called, the parsed sql is added to the context, and finally the complete sql is obtained through context.getSql() rootSqlNode.apply(context); SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration); Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass(); SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings()); BoundSql boundSql = sqlSource.getBoundSql(parameterObject); for (Map.Entry<String, Object> entry : context.getBindings().entrySet()) { boundSql.setAdditionalParameter(entry.getKey(), entry.getValue()); } return boundSql; } }
. One might ask, when will getBoundSql() be called Let me explain in advance: when we request Mapper interface (that is, when a SqlSession session accesses the database), we will call to.
// A complete sql. At this time, the sql is JDBC, that is, select * from user where id =? private String sql; // parameter list private List<ParameterMapping> parameterMappings; private Object parameterObject; private Map<String, Object> additionalParameters; private MetaObject metaParameters;
at this point, the process of loading the select|insert|update|delete node is very clear. But we still have a mapperbuilder assistant that hasn't been resolved. In fact, MapperBuilderAssistant is the assistant of MapperBuilderXml.
MapperBuilderXml objects are responsible for reading Configuration from XML, while MapperBuilderAssistant is responsible for creating objects and loading them into Configuration.
IV. personal summary
the loading of the whole Configuration is mainly divided into two parts:
- 1. Loading of mybatis-config.xml
- 2. Loading mapper.xml
. The following sequence diagram describes the loading process:

!
This article is based on the platform of blog one article multiple sending OpenWrite Release!