preface
stay Mybatis source code - execution process of Executor In this article, the first level cache and second level cache in Mybatis will be described in combination with examples and source code.
text
I Display of L1 cache mechanism
In Mybatis, if the same SQL statement is executed multiple times, Mybatis provides a level-1 cache mechanism to improve query efficiency. The L1 cache is enabled by default. If you want to configure it manually, you need to add the following configuration in the Mybatis configuration file.
<settings>
<setting name="localCacheScope" value="SESSION"/>
</settings>localCacheScope can be configured as SESSION (default) or state, with the following meanings.
| Attribute value | meaning |
|---|---|
| SESSION | The L1 cache takes effect in one session. That is, all query statements in a session will share the same L1 cache, and the L1 cache in different sessions will not be shared. |
| STATEMENT | The L1 cache takes effect only for the currently executed SQL statement. After the currently executed SQL statement is executed, the corresponding L1 cache will be emptied. |
The following is an example to demonstrate and illustrate the first level cache mechanism of Mybatis. First, turn on log printing, then turn off L2 cache, and set the scope of L1 cache to SESSION. The configuration is as follows.
<settings>
<setting name="logImpl" value="STDOUT_LOGGING" />
<setting name="cacheEnabled" value="false"/>
<setting name="localCacheScope" value="SESSION"/>
</settings>The mapping interface is shown below.
public interface BookMapper {
Book selectBookById(int id);
}The mapping file is shown below.
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mybatis.learn.dao.BookMapper">
<resultMap id="bookResultMap" type="com.mybatis.learn.entity.Book">
<result column="b_name" property="bookName"/>
<result column="b_price" property="bookPrice"/>
</resultMap>
<select id="selectBookById" resultMap="bookResultMap">
SELECT
b.id, b.b_name, b.b_price
FROM
book b
WHERE
b.id=#{id}
</select>
</mapper>The execution code of Mybatis is as follows.
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
SqlSession sqlSession = sqlSessionFactory.openSession(false);
BookMapper bookMapper = sqlSession.getMapper(BookMapper.class);
System.out.println(bookMapper.selectBookById(1));
System.out.println(bookMapper.selectBookById(1));
System.out.println(bookMapper.selectBookById(1));
}
}In the execution code, the query operation is performed three times in succession. Take a look at the log printing, as shown below.
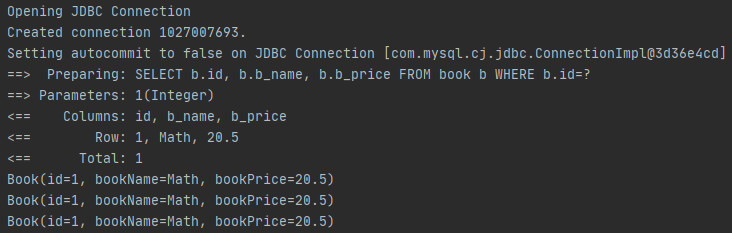
It can be seen that only the first query interacts with the database, and the last two queries are the data queried from the first level cache. Now add the logic of changing data to the mapping interface and mapping file, as shown below.
public interface BookMapper {
Book selectBookById(int id);
//Change book price by id
void updateBookPriceById(@Param("id") int id, @Param("bookPrice") float bookPrice);
}<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mybatis.learn.dao.BookMapper">
<resultMap id="bookResultMap" type="com.mybatis.learn.entity.Book">
<result column="b_name" property="bookName"/>
<result column="b_price" property="bookPrice"/>
</resultMap>
<select id="selectBookById" resultMap="bookResultMap">
SELECT
b.id, b.b_name, b.b_price
FROM
book b
WHERE
b.id=#{id}
</select>
<insert id="updateBookPriceById">
UPDATE
book
SET
b_price=#{bookPrice}
WHERE
id=#{id}
</insert>
</mapper>The operation to be performed is to perform a query operation first, then perform an update operation and commit a transaction, and finally perform a query operation. The execution code is as follows.
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
SqlSession sqlSession = sqlSessionFactory.openSession(false);
BookMapper bookMapper = sqlSession.getMapper(BookMapper.class);
System.out.println(bookMapper.selectBookById(1));
System.out.println("Change database.");
bookMapper.updateBookPriceById(1, 22.5f);
sqlSession.commit();
System.out.println(bookMapper.selectBookById(1));
}
}The execution results are as follows.
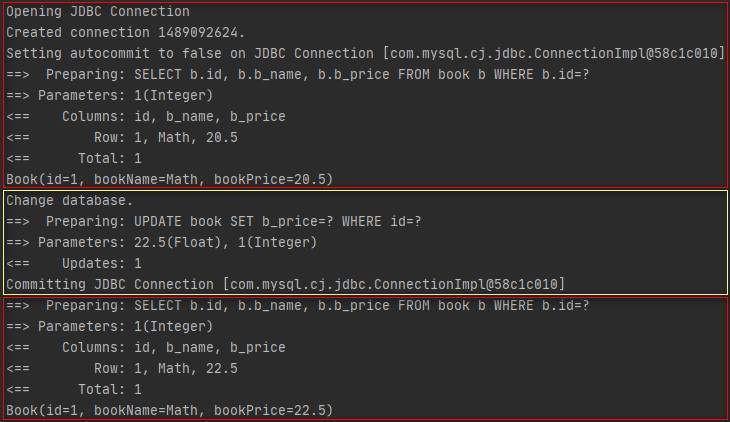
It can be seen from the above results that after the update operation and then the query operation, the data is queried directly from the database, and the first level cache is not used, that is, the first level cache will be invalidated by the addition, deletion and modification of the database in a session.
Now create two sessions in the execution code, first let session 1 perform a query operation, then let session 2 perform an update operation and commit a transaction, and finally let session 1 perform the same query again. The execution code is as follows.
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
SqlSession sqlSession1 = sqlSessionFactory.openSession(false);
SqlSession sqlSession2 = sqlSessionFactory.openSession(false);
BookMapper bookMapper1 = sqlSession1.getMapper(BookMapper.class);
BookMapper bookMapper2 = sqlSession2.getMapper(BookMapper.class);
System.out.println(bookMapper1.selectBookById(1));
System.out.println("Change database.");
bookMapper2.updateBookPriceById(1, 22.5f);
sqlSession2.commit();
System.out.println(bookMapper1.selectBookById(1));
}
}The execution results are as follows.
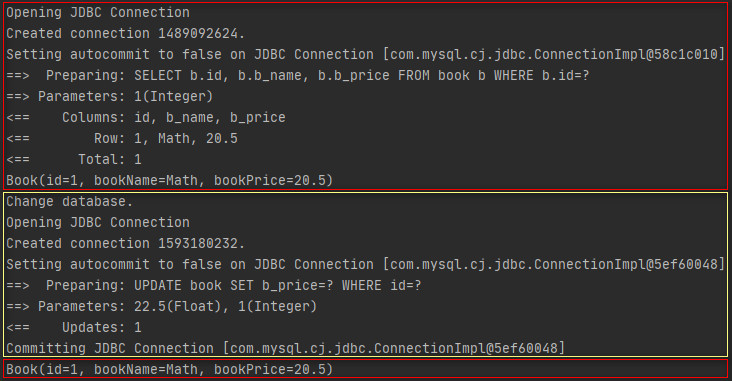
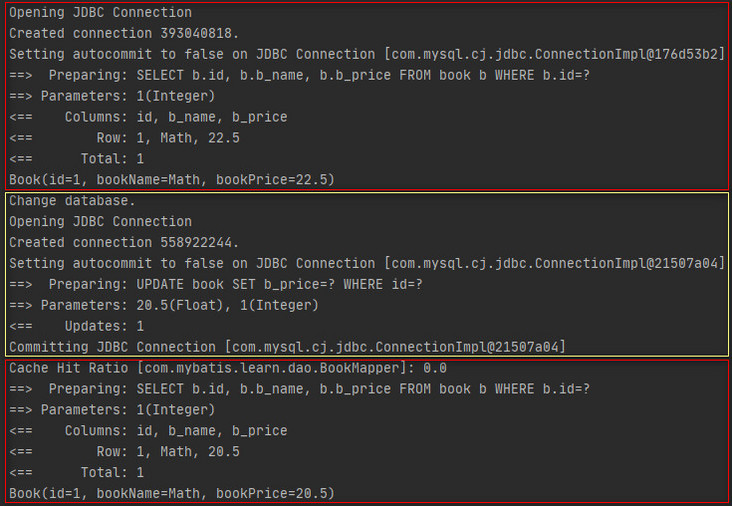
The above results show that the first query of session 1 is the database directly queried, and then session 2 performs an update operation and submits the transaction. At this time, the price of the book with id 1 in the database has been changed to 22.5. Then session 1 makes another query, but the price of the book in the query result is 20.5, Note the second query of session 1 is the query result obtained from the cache. Therefore, it can be seen here that each session in Mybatis will maintain a L1 cache, and the L1 cache between different sessions will not be affected.
At the end of this section, the first level cache mechanism of Mybatis is summarized as follows.
- The first level cache of Mybatis is enabled by default, and the default scope is SESSION, that is, the first level cache takes effect in a SESSION. You can also set the scope to state through configuration to make the first level cache take effect only for the currently executed SQL statements;
- In the same session, adding, deleting and changing operations will invalidate the L1 cache in the session;
- Different sessions hold different L1 caches. The operations in this session will not affect the L1 caches in other sessions.
II Analysis of L1 cache source code
This section will discuss the source code of Mybatis corresponding to the first level cache. stay Mybatis source code - execution process of Executor It has been known in that when the L2 cache is disabled, the call chain is as follows when executing the query operation.

There are two overloaded query() methods in BaseExecutor. Let's look at the implementation of the first query() method, as shown below.
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler) throws SQLException {
//Get Sql statement
BoundSql boundSql = ms.getBoundSql(parameter);
//Generate CacheKey
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
//Call the overloaded query() method
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}In the above query() method, first obtain the SQL statement in the MappedStatement, and then generate a CacheKey. This CacheKey is actually the unique ID of the cache in the primary cache of this session. The CacheKey class diagram is shown below.
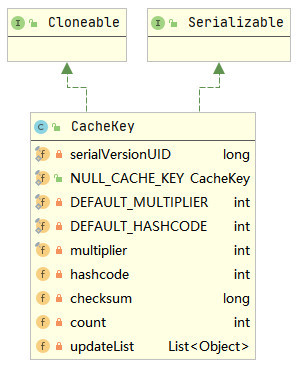
The multiplier, hashcode, checksum, count and updateList fields in the CacheKey are used to determine whether the cachekeys are equal. These fields will be initialized in the constructor of the CacheKey, as shown below.
public CacheKey() {
this.hashcode = DEFAULT_HASHCODE;
this.multiplier = DEFAULT_MULTIPLIER;
this.count = 0;
this.updateList = new ArrayList<>();
}Meanwhile, hashcode, checksum, count and updateList fields will be updated in the update() method of CacheKey, as shown below.
public void update(Object object) {
int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
count++;
checksum += baseHashCode;
baseHashCode *= count;
hashcode = multiplier * hashcode + baseHashCode;
updateList.add(object);
}The main logic is to calculate and update the values of hashcode, checksum and count based on the input parameters of the update() method, and then add the input parameters to the updateList set. At the same time, in the equals() method overridden by CacheKey, two cachekeys are equal only when hashcode, checksum and count are equal, and the elements in the updateList set are all equal.
Go back to the query() method in the BaseExecutor above, where the createCacheKey() method will be called to generate a CacheKey. Part of its source code is as follows.
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject,
RowBounds rowBounds, BoundSql boundSql) {
......
//Create CacheKey
CacheKey cacheKey = new CacheKey();
//Update CacheKey based on id of MappedStatement
cacheKey.update(ms.getId());
//Update CacheKey based on RowBounds offset
cacheKey.update(rowBounds.getOffset());
//Update CacheKey based on limit of rowboundaries
cacheKey.update(rowBounds.getLimit());
//Update CacheKey based on Sql statement
cacheKey.update(boundSql.getSql());
......
//Update CacheKey based on query parameters
cacheKey.update(value);
......
//Update CacheKey based on Environment id
cacheKey.update(configuration.getEnvironment().getId());
return cacheKey;
}Therefore, it can be concluded that the basis for judging whether cachekeys are equal is that mappedstatement ID + rowboundaries offset + rowboundaries limit + SQL + parameter + environment ID are equal.
After obtaining the CacheKey, the overloaded query() method in BaseExecutor will be called, as shown below.
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler,
CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
//queryStack is a member variable of BaseExecutor
//queryStack is mainly used to prevent the L1 cache from being emptied when calling the query() method recursively
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
//First hit the query result from the L1 cache according to the CacheKey
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
//Handling stored procedure related logic
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//If it is missed, the database will be queried directly
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (BaseExecutor.DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear();
//If the scope of L1 cache is state, the L1 cache needs to be emptied every time query() is executed
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache();
}
}
return list;
}In the above query() method, the query results will be cached according to the CacheKey. If the query results are hit and the statementType on the CURD tag in the mapping file is CALLABLE, the stored procedure related logic will be processed in the handlelocallycachedoutputeparameters () method, and then the hit query results will be returned. If the query results are not hit, The database will be queried directly. The queryStack field of BaseExecutor is also used in the above query() method, which mainly prevents the L1 cache from being deleted before the recursion is terminated when the scope of L1 cache is state and there are recursive calls to the query() method. If there are no recursive calls, the cache will be emptied after each query when the scope of L1 cache is state. Let's take a look at the L1 cache localCache in BaseExecutor, which is actually a perpetual cache. The class diagram is as follows.
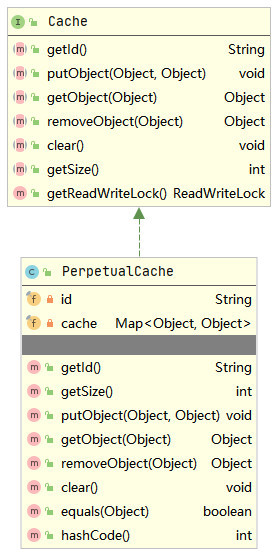
Therefore, the internal of the perpetual cache is mainly based on a Map (actually HashMap) for data storage. Now go back to the query() method of the BaseExecutor above. If the query result is not hit in the L1 cache, the database will be queried directly. The queryFromDatabase() method is as follows.
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//Call doQuery() to query
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
//Add query results to L1 cache
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
//Return query results
return list;
}The logic related to the first level cache in the queryFromDatabase() method is that after querying the database, the query results will be cached in the first level cache with CacheKey as the unique ID.
In Mybatis, if you perform add, change and delete operations and disable the L2 cache, you will call the update() method of BaseExecutor, as shown below.
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource())
.activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
//Empty the cache before performing the operation
clearLocalCache();
return doUpdate(ms, parameter);
}Therefore, the first level cache in Mybatis will be emptied and invalidated after adding, modifying and deleting operations.
Finally, the usage process of L1 cache can be summarized in the following figure.
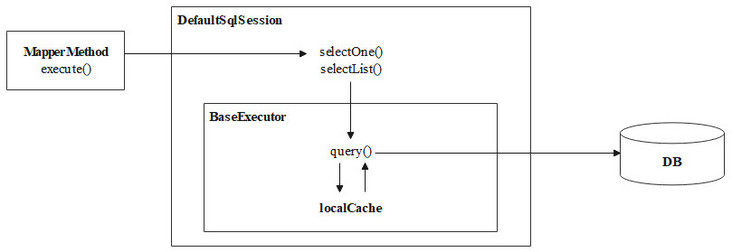
III Display of L2 cache mechanism
The first level cache of Mybatis is shared only in one session, and the first level cache between sessions does not affect each other, while the second level cache of Mybatis can be shared by multiple sessions. This section will analyze the use mechanism of the second level cache in Mybatis in combination with examples. To use L2 cache, you need to change the Mybatis configuration file to enable L2 cache, as shown below.
<settings>
<setting name="logImpl" value="STDOUT_LOGGING" />
<setting name="cacheEnabled" value="true"/>
<setting name="localCacheScope" value="STATEMENT"/>
</settings>In the above configuration file, the scope of L1 cache is also set to state in order to shield the interference of L1 cache on query results in the example. The mapping interface is shown below.
public interface BookMapper {
Book selectBookById(int id);
void updateBookPriceById(@Param("id") int id, @Param("bookPrice") float bookPrice);
}To use L2 cache, you also need to add L2 cache related settings to the mapping file, as shown below.
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mybatis.learn.dao.BookMapper">
<!-- L2 cache related settings -->
<cache eviction="LRU"
type="org.apache.ibatis.cache.impl.PerpetualCache"
flushInterval="600000"
size="1024"
readOnly="true"
blocking="false"/>
<resultMap id="bookResultMap" type="com.mybatis.learn.entity.Book">
<result column="b_name" property="bookName"/>
<result column="b_price" property="bookPrice"/>
</resultMap>
<select id="selectBookById" resultMap="bookResultMap">
SELECT
b.id, b.b_name, b.b_price
FROM
book b
WHERE
b.id=#{id}
</select>
<insert id="updateBookPriceById">
UPDATE
book
SET
b_price=#{bookPrice}
WHERE
id=#{id}
</insert>
</mapper>The meaning of each item of L2 cache related settings will be described at the end of this section.
Scenario 1: create two sessions. Session 1 executes two consecutive queries with the same SQL statement, and session 2 executes one query with the same SQL statement. The execution code is as follows.
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
SqlSession sqlSession1 = sqlSessionFactory.openSession(false);
SqlSession sqlSession2 = sqlSessionFactory.openSession(false);
BookMapper bookMapper1 = sqlSession1.getMapper(BookMapper.class);
BookMapper bookMapper2 = sqlSession2.getMapper(BookMapper.class);
System.out.println(bookMapper1.selectBookById(1));
System.out.println(bookMapper1.selectBookById(1));
System.out.println(bookMapper2.selectBookById(1));
}
}The execution results are as follows.
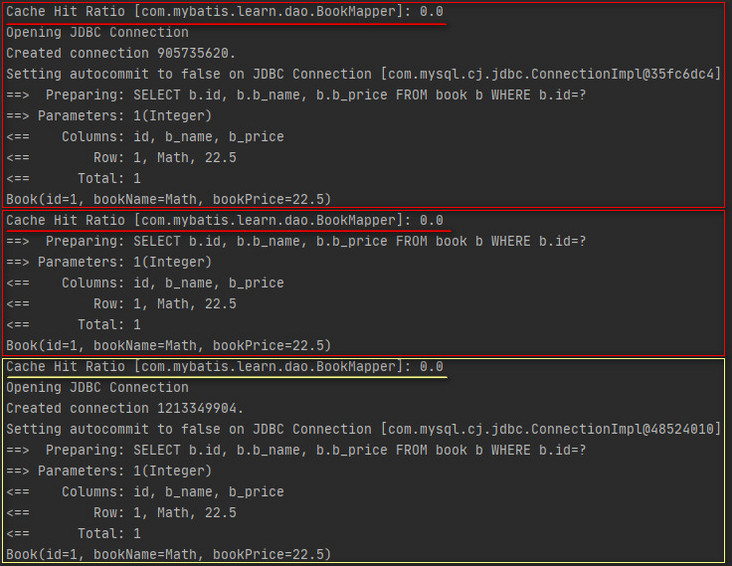
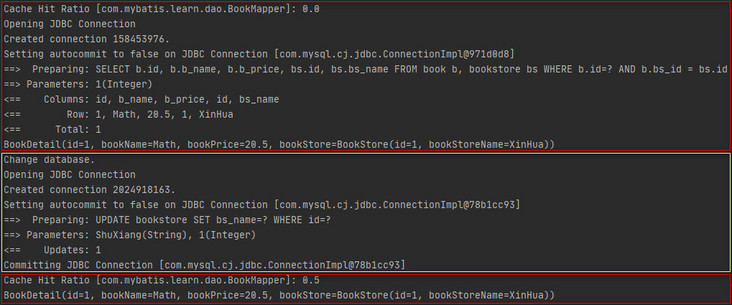
When the L2 cache in Mybatis is enabled, each query will first hit the query results in the L2 cache, and the L1 cache will be used and the database will be queried directly in case of miss. The screenshot of the above results shows that in scenario 1, when the SQL statements are the same, whether it is two consecutive queries in the same session or one query in another session, it is the database of the query, as if the L2 cache does not take effect. In fact, transaction submission is required to cache the query results in the L2 cache, and there is no transaction submission in scenario 1, so there is no content in the L2 cache, Finally, the three queries are the database of direct query. In addition, if it is an add, delete or modify operation, as long as there is no transaction commit, the L2 cache will not be affected.
Scenario 2: create two sessions. Session 1 executes a query and submits a transaction, then session 1 executes another query with the same SQL statement, and then session 2 executes a query with the same SQL statement. The execution code is as follows.
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
SqlSession sqlSession1 = sqlSessionFactory.openSession(false);
SqlSession sqlSession2 = sqlSessionFactory.openSession(false);
BookMapper bookMapper1 = sqlSession1.getMapper(BookMapper.class);
BookMapper bookMapper2 = sqlSession2.getMapper(BookMapper.class);
System.out.println(bookMapper1.selectBookById(1));
sqlSession1.commit();
System.out.println(bookMapper1.selectBookById(1));
System.out.println(bookMapper2.selectBookById(1));
}
}The execution results are as follows.
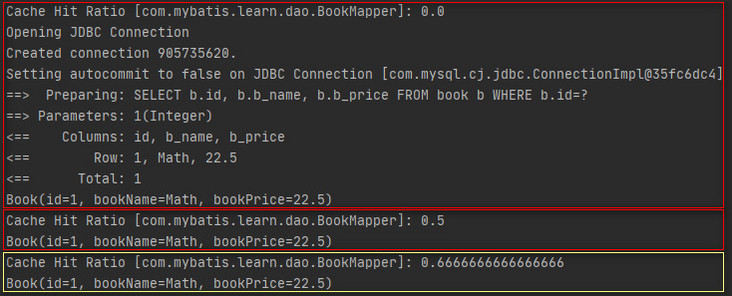
In scenario 2, the transaction is submitted after the first query. At this time, the query results are cached in the L2 cache, so all subsequent queries hit the query results in the L2 cache.
Scenario 3: create two sessions. Session 1 executes a query and commits a transaction, then session 2 executes an update and commits a transaction, and then session 1 executes the same query again. The execution code is as follows.
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
//Set the transaction isolation level to read committed
SqlSession sqlSession1 = sqlSessionFactory.openSession(
TransactionIsolationLevel.READ_COMMITTED);
SqlSession sqlSession2 = sqlSessionFactory.openSession(
TransactionIsolationLevel.READ_COMMITTED);
BookMapper bookMapper1 = sqlSession1.getMapper(BookMapper.class);
BookMapper bookMapper2 = sqlSession2.getMapper(BookMapper.class);
System.out.println(bookMapper1.selectBookById(1));
sqlSession1.commit();
System.out.println("Change database.");
bookMapper2.updateBookPriceById(1, 20.5f);
sqlSession2.commit();
System.out.println(bookMapper1.selectBookById(1));
}
}The execution results are as follows.
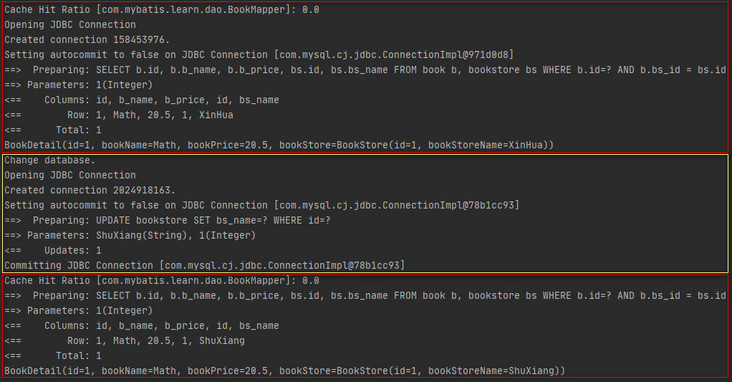
The execution results of scenario 3 show that after the update operation and the transaction is committed, the L2 cache will be emptied, and the same is true for adding and deleting operations.
Scenario 4: create two sessions and two tables. Session 1 first performs a multi table query and submits the transaction, then session 2 performs an update operation to update the data of Table 2 and submit the transaction, and then session 1 performs the same multi table query again. The table creation statement is as follows.
CREATE TABLE book(
id INT(11) PRIMARY KEY AUTO_INCREMENT,
b_name VARCHAR(255) NOT NULL,
b_price FLOAT NOT NULL,
bs_id INT(11) NOT NULL,
FOREIGN KEY book(bs_id) REFERENCES bookstore(id)
);
CREATE TABLE bookstore(
id INT(11) PRIMARY KEY AUTO_INCREMENT,
bs_name VARCHAR(255) NOT NULL
)Add the following data to the book table and the bookstore table.
INSERT INTO book (b_name, b_price, bs_id) VALUES ("Math", 20.5, 1);
INSERT INTO book (b_name, b_price, bs_id) VALUES ("English", 21.5, 1);
INSERT INTO book (b_name, b_price, bs_id) VALUES ("Water Margin", 30.5, 2);
INSERT INTO bookstore (bs_name) VALUES ("XinHua");
INSERT INTO bookstore (bs_name) VALUES ("SanYou")Create the BookStore class, as shown below.
@Data
public class BookStore {
private String id;
private String bookStoreName;
}Create the BookDetail class, as shown below.
@Data
public class BookDetail {
private long id;
private String bookName;
private float bookPrice;
private BookStore bookStore;
}Add the selectBookDetailById() method to the BookMapper mapping interface, as shown below.
public interface BookMapper {
Book selectBookById(int id);
void updateBookPriceById(@Param("id") int id, @Param("bookPrice") float bookPrice);
BookDetail selectBookDetailById(int id);
}BookMapper. The XML Mapping file is shown below.
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mybatis.learn.dao.BookMapper">
<cache eviction="LRU"
type="org.apache.ibatis.cache.impl.PerpetualCache"
flushInterval="600000"
size="1024"
readOnly="true"
blocking="false"/>
<resultMap id="bookResultMap" type="com.mybatis.learn.entity.Book">
<result column="b_name" property="bookName"/>
<result column="b_price" property="bookPrice"/>
</resultMap>
<resultMap id="bookDetailResultMap" type="com.mybatis.learn.entity.BookDetail">
<id column="id" property="id"/>
<result column="b_name" property="bookName"/>
<result column="b_price" property="bookPrice"/>
<association property="bookStore">
<id column="id" property="id"/>
<result column="bs_name" property="bookStoreName"/>
</association>
</resultMap>
<select id="selectBookById" resultMap="bookResultMap">
SELECT
b.id, b.b_name, b.b_price
FROM
book b
WHERE
b.id=#{id}
</select>
<insert id="updateBookPriceById">
UPDATE
book
SET
b_price=#{bookPrice}
WHERE
id=#{id}
</insert>
<select id="selectBookDetailById" resultMap="bookDetailResultMap">
SELECT
b.id, b.b_name, b.b_price, bs.id, bs.bs_name
FROM
book b, bookstore bs
WHERE
b.id=#{id}
AND
b.bs_id = bs.id
</select>
</mapper>You also need to add a BookStoreMapper mapping interface, as shown below.
public interface BookStoreMapper {
void updateBookPriceById(@Param("id") int id, @Param("bookStoreName") String bookStoreName);
}You also need to add bookstoremapper XML Mapping file, as shown below.
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mybatis.learn.dao.BookStoreMapper">
<cache eviction="LRU"
type="org.apache.ibatis.cache.impl.PerpetualCache"
flushInterval="600000"
size="1024"
readOnly="true"
blocking="false"/>
<insert id="updateBookPriceById">
UPDATE
bookstore
SET
bs_name=#{bookStoreName}
WHERE
id=#{id}
</insert>
</mapper>After making the above changes, test scenario 4, and the execution code is as follows.
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
//Set the transaction isolation level to read committed
SqlSession sqlSession1 = sqlSessionFactory.openSession(
TransactionIsolationLevel.READ_COMMITTED);
SqlSession sqlSession2 = sqlSessionFactory.openSession(
TransactionIsolationLevel.READ_COMMITTED);
BookMapper bookMapper1 = sqlSession1.getMapper(BookMapper.class);
BookStoreMapper bookStoreMapper = sqlSession2.getMapper(BookStoreMapper.class);
System.out.println(bookMapper1.selectBookDetailById(1));
sqlSession1.commit();
System.out.println("Change database.");
bookStoreMapper.updateBookStoreById(1, "ShuXiang");
sqlSession2.commit();
System.out.println(bookMapper1.selectBookDetailById(1));
}
}The execution results are as follows.
When session 1 executes a multi table query and submits a transaction for the first time, the query results are cached in the secondary cache, and then session 2 performs an update operation on the bookstore table and submits a transaction. However, when session 1 executes the same multi table query for the second time, the query results are called from the secondary cache, resulting in dirty data. In fact, the scope of L2 cache is shared by multiple sessions under the same namespace. The namespace here is the namespace of the mapping file. It can be understood that each mapping file holds a L2 cache, and all operations of all sessions in the mapping file will share the L2 cache. Therefore, in the example of scenario 4, when session 2 performs an update operation on the bookstore table and commits a transaction, it empties the bookstoremapper Second level cache held by XML, bookmapper The L2 cache held by XML does not perceive that the data of the bookstore table has changed, resulting in dirty data hit from the L2 cache when session 1 executes the same multi table query for the second time.
Scenario 5: the operation performed is the same as scenario 4, but in bookstoremapper Make the following changes in the XML file.
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mybatis.learn.dao.BookStoreMapper">
<cache-ref namespace="com.mybatis.learn.dao.BookMapper"/>
<insert id="updateBookStoreById">
UPDATE
bookstore
SET
bs_name=#{bookStoreName}
WHERE
id=#{id}
</insert>
</mapper>The execution code is as follows.
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
//Set the transaction isolation level to read committed
SqlSession sqlSession1 = sqlSessionFactory.openSession(
TransactionIsolationLevel.READ_COMMITTED);
SqlSession sqlSession2 = sqlSessionFactory.openSession(
TransactionIsolationLevel.READ_COMMITTED);
BookMapper bookMapper1 = sqlSession1.getMapper(BookMapper.class);
BookStoreMapper bookStoreMapper = sqlSession2.getMapper(BookStoreMapper.class);
System.out.println(bookMapper1.selectBookDetailById(1));
sqlSession1.commit();
System.out.println("Change database.");
bookStoreMapper.updateBookStoreById(1, "ShuXiang");
sqlSession2.commit();
System.out.println(bookMapper1.selectBookDetailById(1));
}
}The execution results are as follows.
In bookstoremapper The < cache ref > tag is used in XML to reference the namespace com mybatis. learn. dao. The mapping file of bookmapper uses the second level cache, so it is equivalent to bookmapper XML Mapping file and bookstoremapper The XML Mapping file holds the same L2 cache, and session 2 is in BookStoreMapper.xml After the update operation is performed in the XML Mapping file and the transaction is committed, the secondary cache will be emptied, so that the second time session 1 executes the same multi table query, it will query the data from the database.
Now a summary of Mybatis's L2 caching mechanism is shown below.
- The L2 cache in Mybatis is enabled by default. You can add < setting name = "cacheenabled" value = "false" / > in < Settings > in the Mybatis configuration file to close the L2 cache;
- The scope of the L2 cache in Mybatis is shared by multiple sessions under the same namespace. The namespace here is the namespace of the mapping file, that is, after different sessions use the SQL statements in the same mapping file to perform operations on the database and commit transactions, the L2 cache held by the mapping file will be affected;
- After the query operation is performed in Mybatis, the transaction needs to be committed to cache the query results into the secondary cache;
- After performing add, delete or change operations in Mybatis and submitting transactions, the corresponding L2 cache will be emptied;
- In Mybatis, you need to add a < cache > tag in the mapping file to configure the L2 cache for the mapping file. You can also add a < cache ref > tag in the mapping file to reference the L2 cache of other mapping files to achieve the effect that multiple mapping files hold the same L2 cache.
Finally, the < cache > tag and < cache ref > tag are described.
The < cache > tag is shown below.
| attribute | meaning | Default value |
|---|---|---|
| eviction | Cache obsolescence policy. LRU indicates that the one with the least recent use frequency is preferred to be eliminated; FIFO means that those cached first will be eliminated first; SOFT means elimination based on SOFT reference rules; WEAK means elimination based on WEAK reference rules | LRU |
| flushInterval | Cache refresh interval. Unit: ms | Empty means it will never expire |
| type | Type of cache | PerpetualCache |
| size | Maximum number of cached objects | 1024 |
| blocking | Whether to block in case of cache miss | false |
| readOnly | Whether the objects in the cache are read-only. If it is set to true, the cache object is read-only. When the cache is hit, the cached object will be returned directly. The performance is faster, but the thread is unsafe; When it is set to false, it indicates that the cache object is readable and writable. When the cache is hit, the cached object will be cloned and then the cloned object will be returned. The performance is slower, but the thread is safe | false |
The < cache ref > tag is shown below.
| attribute | meaning |
|---|---|
| namespace | The namespace of other mapping files. After setting, the current mapping file will hold the same L2 cache as other mapping files |
IV Creation of L2 cache
stay Mybatis source code - load mapping file and dynamic agent It has been known in that the configurationElement() method of XMLMapperBuilder will parse the contents of the mapping file and enrich it into the Configuration, but Mybatis source code - load mapping file and dynamic agent The < cache > tag and < cache ref > tag of the resolution mapping file are not described in this section, so this section will supplement this part. The configurationElement() method is as follows.
private void configurationElement(XNode context) {
try {
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.isEmpty()) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
//Resolve < cache ref > tags
cacheRefElement(context.evalNode("cache-ref"));
//Resolve < cache > tags
cacheElement(context.evalNode("cache"));
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
resultMapElements(context.evalNodes("/mapper/resultMap"));
sqlElement(context.evalNodes("/mapper/sql"));
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '"
+ resource + "'. Cause: " + e, e);
}
}In the configurationElement() method, the < cache ref > tag will be parsed first, and then the < cache > tag. Therefore, a guess is made here: if both < cache ref > and < cache > tags exist in the mapping file, the L2 cache configured by the < cache > tag will overwrite the L2 cache referenced by < cache ref >. First analyze the < cache > tag parsing. The cacheElement() method is as follows.
private void cacheElement(XNode context) {
if (context != null) {
//Gets the value of the type attribute of the < cache > tag
String type = context.getStringAttribute("type", "PERPETUAL");
Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type);
//Gets the eviction attribute value of the < cache > tag
String eviction = context.getStringAttribute("eviction", "LRU");
Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction);
//Gets the value of the flushInterval attribute of the < cache > tag
Long flushInterval = context.getLongAttribute("flushInterval");
//Gets the size attribute value of the < cache > tag
Integer size = context.getIntAttribute("size");
//Get the readOnly attribute value of the < cache > tag and invert it
boolean readWrite = !context.getBooleanAttribute("readOnly", false);
//Gets the value of the blocking attribute of the < cache > tag
boolean blocking = context.getBooleanAttribute("blocking", false);
Properties props = context.getChildrenAsProperties();
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
}
}The cacheElement() method is tracked in one step, and the parsed content of each attribute can be referred to the following figure.
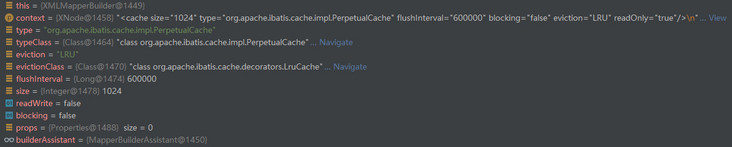
The actual creation of Cache is in the useNewCache() method of MapperBuilderAssistant, and the implementation is as follows.
public Cache useNewCache(Class<? extends Cache> typeClass,
Class<? extends Cache> evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props) {
Cache cache = new CacheBuilder(currentNamespace)
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
.clearInterval(flushInterval)
.size(size)
.readWrite(readWrite)
.blocking(blocking)
.properties(props)
.build();
configuration.addCache(cache);
currentCache = cache;
return cache;
}In MapperBuilderAssistant's useNewCache() method, you first create CacheBuilder, then call CacheBuilder's build() method to build Cache. The cachebuilder class diagram is shown below.

The constructor for CacheBuilder is shown below.
public CacheBuilder(String id) {
this.id = id;
this.decorators = new ArrayList<>();
}Therefore, it can be seen that the id field of the CacheBuilder is actually the namespace of the current mapping file. In fact, it can be roughly guessed here that the only identification of the secondary Cache built by the CacheBuilder in the Configuration is the namespace of the mapping file. In addition, the implementation in CacheBuilder is the Class object of perpetual Cache, and the decorators collection contains the Class object of LruCache. Let's take a look at the build() method of CacheBuilder, as shown below.
public Cache build() {
setDefaultImplementations();
//Create a perpetual Cache as the underlying Cache object
Cache cache = newBaseCacheInstance(implementation, id);
setCacheProperties(cache);
if (PerpetualCache.class.equals(cache.getClass())) {
//Adds a decorator related to the Cache obsolescence policy to the underlying Cache object
for (Class<? extends Cache> decorator : decorators) {
cache = newCacheDecoratorInstance(decorator, cache);
setCacheProperties(cache);
}
//Continue adding decorators
cache = setStandardDecorators(cache);
} else if (!LoggingCache.class.isAssignableFrom(cache.getClass())) {
cache = new LoggingCache(cache);
}
return cache;
}The build() method of CacheBuilder will first create a PerpetualCache object as the basic cache object, and then add a corresponding decorator for the basic cache object according to the cache elimination strategy. For example, if the value of the eviction attribute in the < cache > tag is LRU, the corresponding decorator is LruCache. The corresponding decorator is different according to the value of the eviction attribute, The following figure shows all the decorators provided by Mybatis for the cache obsolescence policy.
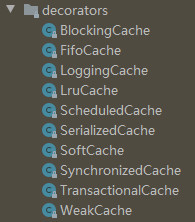
In the build() method of CacheBuilder, after adding decorators for the cache obsolescence policy for the PerpetualCache, the standard decorators will continue to be added. The standard decorators defined in Mybatis include ScheduledCache, SerializedCache, LoggingCache, synchronized cache and BlockingCache, with the meanings shown in the following table.
| Decorator | meaning |
|---|---|
| ScheduledCache | Provides the function of regular cache refresh. This decorator will be added when the < cache > tag sets the value of the flushInterval attribute |
| SerializedCache | Provides cache serialization function. This decorator will be added when the readOnly attribute of < cache > tag is set to false |
| LoggingCache | Provide log function, and the decorator will be added by default |
| SynchronizedCache | Synchronization function is provided, and the decorator will be added by default |
| BlockingCache | Blocking function is provided. This decorator will be added when the blocking attribute of < cache > tag is set to true |
The following is an example of a < cache > tag.
<cache eviction="LRU"
type="org.apache.ibatis.cache.impl.PerpetualCache"
flushInterval="600000"
size="1024"
readOnly="false"
blocking="true"/>The generated L2 cache objects are as follows.
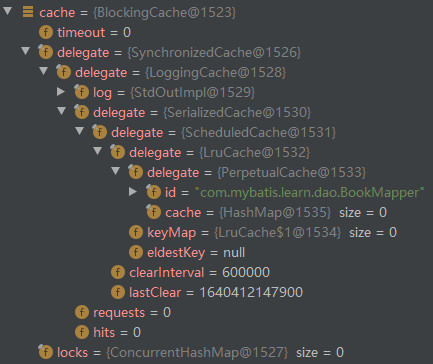
The whole decoration chain is shown in the figure below.

Now go back to the useNewCache() method of MapperBuilderAssistant. After building the L2 cache object, it will be added to Configuration. The addCache() method of Configuration is as follows.
public void addCache(Cache cache) {
caches.put(cache.getId(), cache);
}This confirms the previous conjecture that the only identifier of the L2 Cache in the Configuration is the namespace of the mapping file.
Now let's analyze the < cache ref > tag parsing by the configurationElement() method in xmlmaperbuilder. The cacheRefElement() method is as follows.
private void cacheRefElement(XNode context) {
if (context != null) {
//Establish a mapping relationship between the current mapping file namespace and the referenced mapping file namespace in the cacheRefMap of Configuration
configuration.addCacheRef(builderAssistant.getCurrentNamespace(), context.getStringAttribute("namespace"));
CacheRefResolver cacheRefResolver = new CacheRefResolver(builderAssistant, context.getStringAttribute("namespace"));
try {
//CacheRefResolver will get the secondary cache of the referenced mapping file from the Configuration and assign it to the currentCache of 'MapperBuilderAssistant'
cacheRefResolver.resolveCacheRef();
} catch (IncompleteElementException e) {
configuration.addIncompleteCacheRef(cacheRefResolver);
}
}
}The cacheRefElement() method will first establish a mapping relationship between the current mapping file namespace and the referenced mapping file namespace in the cacheRefMap of Configuration, and then obtain the secondary cache of the referenced mapping file from Configuration through CacheRefResolver and assign it to the currentCache of MapperBuilderAssistant, The currentCache field will be passed to MappedStatement when MapperBuilderAssistant builds MappedStatement. If the < cache > tag still exists in the mapping file, MapperBuilderAssistant will reassign the L2 cache configured by the < cache > tag to currentCache to overwrite the L2 cache referenced by the < cache ref > tag, Therefore, when there are both < cache ref > tags and < cache > tags in the mapping file, only the L2 cache configured by the < cache > tag will take effect.
V Source code analysis of L2 cache
This section will discuss the source code of Mybatis corresponding to the L2 cache. After the L2 cache is enabled in Mybatis, the call chain is as follows when performing query operations.

There are two overloaded query() methods in the cacheingexecution. Let's look at the first query() method, as shown below.
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject,
RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
//Get Sql statement
BoundSql boundSql = ms.getBoundSql(parameterObject);
//Create CacheKey
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}Continue to look at the overloaded query() method, as shown below.
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds,
ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
//Get the L2 cache from the MappedStatement
Cache cache = ms.getCache();
if (cache != null) {
//Clear L2 cache (if needed)
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
//Handling stored procedure related logic
ensureNoOutParams(ms, boundSql);
//Hit query results from L2 cache according to CacheKey
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
//If the cache is not hit, query the database
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
//Cache the query results from the database into the L2 cache
tcm.putObject(cache, key, list);
}
//Return query results
return list;
}
}
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}The overall execution process of the above query() method is relatively simple, which can be summarized as follows: first hit the query result from the Cache, return the hit query result, and directly query the database and Cache the query result into the secondary Cache if it fails to hit the query result. However, when the query result is hit from the L2 Cache according to the CacheKey, it is not directly through the getObject() method of the Cache, but through the getObject() method of the tcm. If it is reasonable to speculate, it should be that the tcm holds the reference of the L2 Cache. When the query result needs to be hit from the L2 Cache, the tcm forwards the request to the L2 Cache. In fact, the TransactionalCacheManager object held by tcm for the cacheingexecution needs to be forwarded to the L2 Cache through the TransactionalCacheManager because the L2 Cache will be updated only when the transaction is committed. Associating with the examples of scenario 1 and scenario 2 in Section 3, the transaction submission function is required to Cache query results into the secondary Cache, which is actually implemented with the help of TransactionalCacheManager. Therefore, the TransactionalCacheManager is described below. First, the class diagram of TransactionalCacheManager is shown below.

A Map is held in the TransactionalCacheManager. The key of the Map is Cache and the value is TransactionalCache, that is, a L2 Cache corresponds to a TransactionalCache. Continue to look at the getObject() method of TransactionalCacheManager, as shown below.
public Object getObject(Cache cache, CacheKey key) {
return getTransactionalCache(cache).getObject(key);
}
private TransactionalCache getTransactionalCache(Cache cache) {
return transactionalCaches.computeIfAbsent(cache, TransactionalCache::new);
}From the above code, we can know that a L2 cache corresponds to a TransactionalCache, and the TransactionalCache holds a reference to this L2 cache. When calling the getObject() method of TransactionalCacheManager, TransactionalCacheManager will forward the call request to TransactionalCache. Next, analyze TransactionalCache, and the class diagram is as follows.
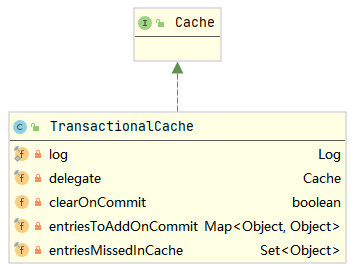
Continue to look at the getObject() method of TransactionalCache, as shown below.
@Override
public Object getObject(Object key) {
//Hit query results in L2 cache
Object object = delegate.getObject(key);
if (object == null) {
//If a miss occurs, the CacheKey is added to entriesMissedInCache
//Used to count the hit rate
entriesMissedInCache.add(key);
}
if (clearOnCommit) {
return null;
} else {
return object;
}
}Here we can know that when the CacheKey hits the query result in the cacheingexecution, the cacheingexecution actually sends the request to the TransactionalCacheManager, which forwards the request to the TransactionalCache corresponding to the L2 cache, and then the TransactionalCache finally passes the request to the L2 cache. In the above getObject() method, if clearOnCommit is true, null will be returned regardless of whether the query result is hit in the L2 cache. Where will clearOnCommit be set to true? In fact, in the flushcacheifrequired () method of cacheingexector, this method will be called in the query() method analyzed above, Take a look at the implementation of flushCacheIfRequired(), as shown below.
private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
if (cache != null && ms.isFlushCacheRequired()) {
tcm.clear(cache);
}
}When you call the clear() method of TransactionalCacheManager, you will eventually call the clear() method of TransactionalCache, as shown below.
@Override
public void clear() {
clearOnCommit = true;
entriesToAddOnCommit.clear();
}Now continue to analyze why transaction commit is required to cache query results into the L2 cache. After the results are queried from the database, the cacheingexecution will call the putObject() method of TransactionalCacheManager to try to cache the query results into the secondary cache. We already know that if the transaction is not committed, the query results cannot be cached into the secondary cache, and the query results must be temporarily stored somewhere before the transaction is committed, To figure out this logic, first look at the putobject () method of TransactionalCacheManager, as shown below.
public void putObject(Cache cache, CacheKey key, Object value) {
getTransactionalCache(cache).putObject(key, value);
}Continue to look at the putObject() method of TransactionalCache, as shown below.
@Override
public void putObject(Object key, Object object) {
entriesToAddOnCommit.put(key, object);
}It is clear from here that the query results will be temporarily stored in the entriesToAddOnCommit of the TransactionalCache before the transaction is committed. Next, continue to analyze how to flush the query results temporarily stored in entriesToAddOnCommit to the L2 cache during transaction submission. The commit() method of DefaultSqlSession is as follows.
@Override
public void commit() {
commit(false);
}
@Override
public void commit(boolean force) {
try {
executor.commit(isCommitOrRollbackRequired(force));
dirty = false;
} catch (Exception e) {
throw ExceptionFactory.wrapException(
"Error committing transaction. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}In the commit() method of DefaultSqlSession, the commit() method of cacheingexecution will be called, as shown below.
@Override
public void commit(boolean required) throws SQLException {
delegate.commit(required);
//Call the commit() method of TransactionalCacheManager
tcm.commit();
}In the commit() method of cacheingexector, the commit() method of TransactionalCacheManager will be called, as shown below.
public void commit() {
for (TransactionalCache txCache : transactionalCaches.values()) {
//Call the commit() method of TransactionalCache
txCache.commit();
}
}Continue to look at the commit() method of TransactionalCache, as shown below.
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
flushPendingEntries();
reset();
}
private void flushPendingEntries() {
//Cache all query results temporarily stored in entriesToAddOnCommit into the L2 cache
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}So far, we can see that when calling the commit() method of SqlSession, it will be passed all the way to the commit() method of TransactionalCache, and finally call the flushPendingEntries() method of TransactionalCache to brush all the temporary query results into the L2 cache.
When the add, delete and change operations are performed and the transaction is committed, the L2 cache will be emptied. This is because the add, delete and change operations will eventually call the update() method of cachingeexecutor, and the update() method will call the flushCacheIfRequired() method, It is known that in the flushCacheIfRequired() method, if the flushCacheRequired field of the MappedStatement corresponding to the executed method is true, the clearOnCommit field in the TransactionalCache will be finally set to true, and then the L2 cache will be emptied when the transaction is committed. When loading the mapping file, there is the following line of code when parsing the CURD label as MappedStatement.
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);That is, if the flushCache attribute is not explicitly set in the CURD tag, a default value will be given to the flushCache field, and the default value is true under the non query tag. Therefore, you can know here that if it is an add, delete or change operation, the clearOnCommit field in TransactionalCache will be set to true, Thus, when a transaction is committed, the L2 cache will be emptied in the commit() method of TransactionalCache.
Here, the source code analysis of L2 cache ends. The usage process of L2 cache can be summarized in the following figure.
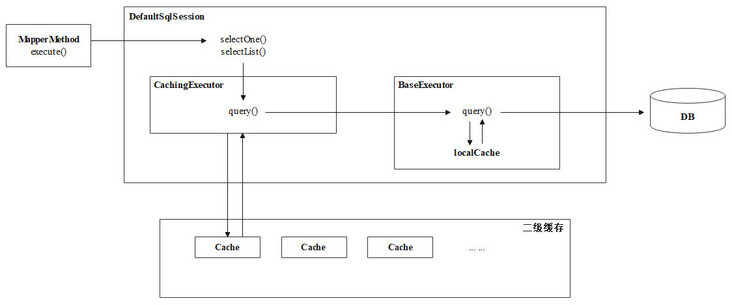
summary
The first level cache of Mybatis is summarized as follows.
- The first level cache of Mybatis is enabled by default, and the default scope is SESSION, that is, the first level cache takes effect in a SESSION. You can also set the scope to state through configuration to make the first level cache take effect only for the currently executed SQL statements;
- In the same session, adding, deleting and changing operations will invalidate the L1 cache in the session;
- Different sessions hold different L1 caches. The operations in this session will not affect the L1 caches in other sessions.
The L2 cache of Mybatis is summarized as follows.
- The L2 cache in Mybatis is enabled by default. You can add < setting name = "cacheenabled" value = "false" / > in < Settings > in the Mybatis configuration file to close the L2 cache;
- The scope of the L2 cache in Mybatis is shared by multiple sessions under the same namespace. The namespace here is the namespace of the mapping file, that is, after different sessions use the SQL statements in the same mapping file to perform operations on the database and commit transactions, the L2 cache held by the mapping file will be affected;
- After the query operation is performed in Mybatis, the transaction needs to be committed to cache the query results into the secondary cache;
- After performing add, delete or change operations in Mybatis and submitting transactions, the corresponding L2 cache will be emptied;
- In Mybatis, you need to add a < cache > tag in the mapping file to configure the L2 cache for the mapping file. You can also add a < cache ref > tag in the mapping file to reference the L2 cache of other mapping files to achieve the effect that multiple mapping files hold the same L2 cache.