MySQL advanced supplement
insert
INSERT is used when inserting data into the table. In MySQL, it is data that can be inserted (lookup result table), but the order type of each column of the result table must be the same as that of each column of the table to be inserted, such as:
--Create a file named jstudents Tables, storage id And name information create table students (id int,name varchar(50)); --stay students Insert in table staff In table id And name information insert into students select id,name from staff; --stay students Insert in table staff In table id Information, and each piece of information name Set as default insert into students select id,null from staff; --Or: insert into students(id) select id from staff;
Aggregate query
The previous query mentioned column and column operation, while aggregate query is the operation between rows. For example, in the previous score table, calculating everyone's total score is the query between columns, while calculating the total score of each subject is the query between rows, so aggregate function is required.
Common aggregate functions:
COUNT
count returns the number of query data (how many rows there are)
--Count the number of data in this table select count(*) from students; --Statistical table name How many pieces of data (not included) null) select count(name) from students; --Statistical table id How many pieces of data (not included) null) select count(id) from students; --Query this table id<1 How many students are there select count(id) from students where id<1;
SUM
Sum returns the sum of query data
--Statistical table id Column sum(barring null) select sum(id) from students; --Statistical table id column id<4 Sum of (excluding) null) select sum(id) from students where id<4;
AVG
avg returns the average value of query data
--Statistics in this table id Column average (excluding null) select avg(id) from students; --Statistics in this table ld column id<4 Average of (excluding null) select avg(id) from students where id<4;
MAX
max returns the maximum value of query data
--Statistics in this table id Column maximum select max(id) from students; --Statistics in this table ld column id Not equal to the maximum of 4 select max(id) from students where id != 4;
MIN
min returns the minimum value of query data
--Statistics in this table id Column minimum select min(id) from students; --Statistics in this table ld column id Not equal to the minimum value of 1 select min(id) from students where id != 1;
GROUP BY
group groups about a column
--Create a file named staff2 The table has a self incrementing primary key id,full name name,position role,wages salary create table staff2(id int primary key auto_increment,name varchar(20),role varchar(29),salary int); --Insert some data insert into staff2 values (null,'TOM1','CAT',8000), (null,'JERRY1','MOUTH',3000), (null,'TOM2','CAT',9000), (null,'JERRY2','MOUTH',4000), (null,'TOM3','CAT',10000), (null,'JERRY3','MOUTH',5000); --Find the average salary for each position select role,avg(salary) from staff2 group by role; select role,avg(salary),count(*),sum(salary) from staff2 group by role;
HAVING
If conditional filtering is required after grouping, use HAVING instead of WHERE
--Find positions with an average salary of more than 5000 select role,avg(salary) from staff2 group by role having avg(salary)>5000;
Joint query
Joint query can also be understood as multi table query. In actual development, data often comes from different tables, so joint query will be used
The performance of multi table query is very low, especially when there are many table contents
In multi table query, the data of two tables (or multiple tables) will be arranged and combined. This is called Cartesian product. For example:
When querying two tables A and B, the number of columns in the result table is the number of columns in table A + the number of columns in table B, and the number of rows is the number of rows in table A × Number of rows in table b
Similarly, the number of columns in the three tables is the number of columns in the AB result table + the number of columns in the C table, and the number of rows is the number of rows in the AB result table × Number of rows in table C
--Create a people Table and one city surface create table people(people_id int,name varchar(50),city_id int); create table city(id int,city_name varchar(50)); --Insert relevant information into two tables insert into people values (1,'people1',1),(2,'people2',1),(3,'people3',1),(4,'people4',2),(5,'people5',2),(6,'people6',2); insert into city values (1,'city1'),(2,'city2'); --View the Cartesian product of two tables(We find that there is too much unnecessary information in this table: there is in the result table people In the table cityid Not equal to city In the table city Information about) select * from people, city; --In the above query result table, there are two duplicate columns, namely city_id And id Column, so we can write it like this select people.people_id, people.name, city.id, city.city_name from people, city;
Inner connection
Find records that meet the requirements for two tables, as shown in the figure:
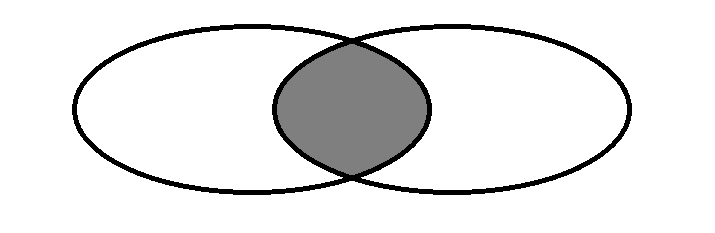
--View the consolidated table of two tables without redundant information select people.people_id, people.name, city.id, city.city_name from people, city where people.city_id = city.id; select people.people_id, people.name, city.id, city.city_name from people join city on people.city_id = city.id; --see people_id=1 The city where people live select people.people_id, people.name, city.id, city.city_name from people, city where people.city_id = city.id and people.people_id = 1; select people.people_id, people.name, city.id, city.city_name from people join city on people.city_id = city.id and people.people_id = 1;
External connection
insert into people values (7,'people7',3),(8,'people8',3); insert into city values (4,'city4');
Left outer connection: find records based on the left table. If the records in the right table do not conform to the left table, they will not be displayed, and all the records in the left table will be displayed, as shown in the figure:
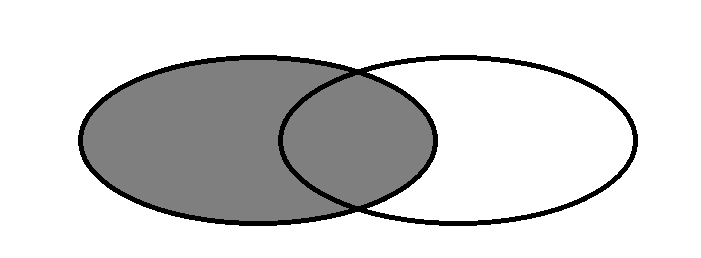
select people.name, city.city_name from people left join city on people.city_id = city.id;
Similarly, the right table will display all the links outside the right, as shown in the figure:
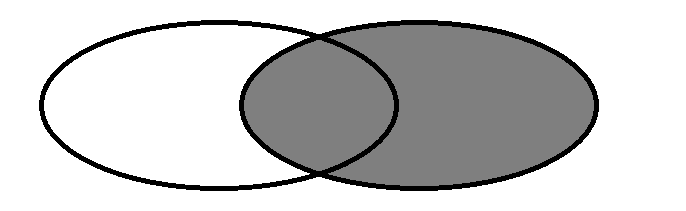
select people.name, city.city_name from people right join city on people.city_id = city.id;
Self linking: some queries want to compare rows and row data according to certain conditions
It can be understood as filtering in the Cartesian product result table of A and A
Subquery: it can be understood as nested query, that is, search in the search result table, or use the query result as a condition
--Take the query result as a condition. At this time, the result table in parentheses has only one row select * from staff2 where name =(select name from staff2 where salary = 8000); --At this time, the result table in parentheses has multiple rows, otherwise it can be used not in select * from staff2 where name in(select name from staff2 where salary > 8000); --If you want to query in the result table, the result table must have an alias select * from (select * from staff2 where salary > 8000) as qqq where role = 'CAT';