1, Index
1.1 what is an index
How to find the target quickly when the number of databases is huge? The index is used. If a book wants to quickly find the knowledge points it wants, it will first look at the directory, and the index is equivalent to the directory of the book, which is convenient for query.
1.2 characteristics of index
Similar to the book catalog, it can locate quickly and facilitate query
Indexing helps greatly improve database performance
The relationship among tables, data and indexes in the database is similar to the relationship between books, book contents and Book directories on the bookshelf.
2, Indexed data structure
When it comes to speed, adding, deleting, checking and changing, you can certainly think of the data structure. The database is essentially realized by the data structure. So what kind of data structure is suitable for indexing?
First, the binary search number. Its underlying implementation can improve the search efficiency, but when it is a single branch tree, the time complexity is O(N)
The second is AVL tree. AVL tree is an upgraded version of binary tree search number. It solves the problem of single branch tree, but also introduces new problems. After insertion or deletion, the structural rules of AVL tree will be destroyed. The rule is abs (height of left subtree - height of right subtree) < = 1. If the rules are destroyed, they will be adjusted. In this way, each adjustment will be very frequent, Then insertion or deletion becomes inefficient.
Then there is the hash table. The time complexity of the hash table is O(1), which is fast, but the hash table has great limitations. The hash query is key == value, but there are many query methods in the database (< >! =...). Another fatal defect of the hash table is hash conflict.
Then there is the red black tree. After all, the red black tree is the basis of the binary tree, so the query efficiency is determined by the height of the tree, which is equivalent to the number of comparisons. When the data structure is huge, the height will also be higher, the number of comparisons will be more, and the search efficiency will slow down
So the above data structure can be said to be the top stream in the data structure. They can't do it. What data structure does the index in MySQL use???
In fact, the index in MySQL refers to an N-fork search tree!!!
What is an N-ary search tree???
As mentioned above, the query efficiency of red black tree is determined by the height of the tree. The purpose of N-fork search tree is to reduce the height. When the height is low, the query comparison times are reduced and the efficiency is high.
N-ary search tree is equivalent to B + tree. If you want to understand B + tree, you must first look at B tree.
2.1 B-tree
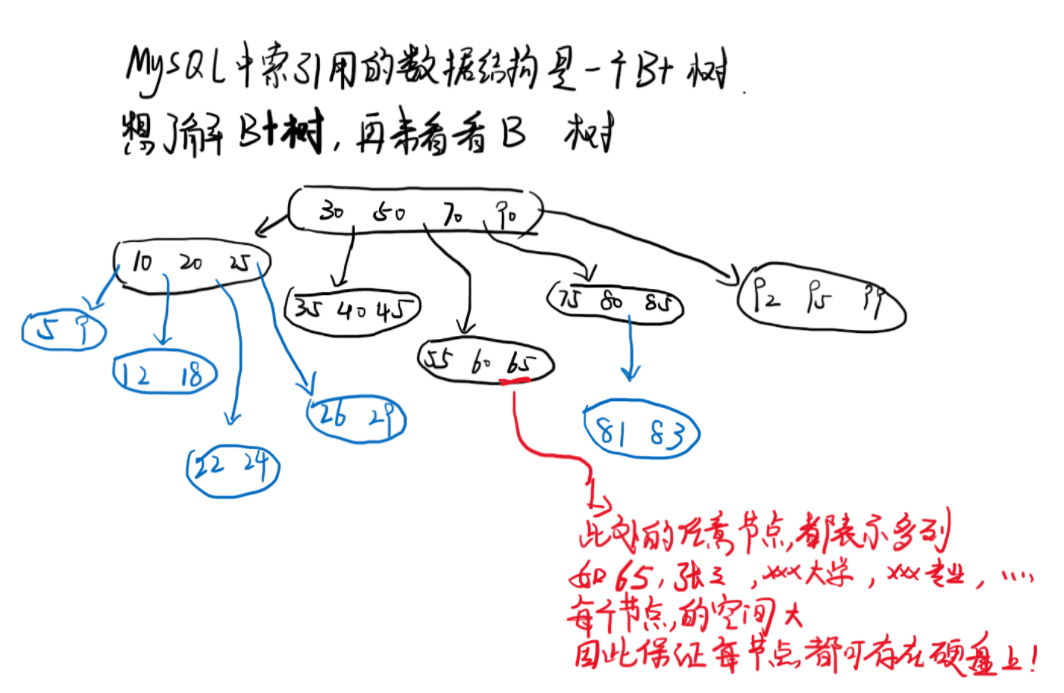
2.2 difference between binary tree and B-tree
Binary tree:
- Each node contains a value
- There are only two branches
- Each node can contain less information
B tree:
- Each node contains multiple values
- There are multiple branches
- Each node contains many columns. Each node occupies a large space, which ensures the number of B. each node must be stored on the hard disk. MySQL has huge data, which is obviously more suitable
It can be seen from the two differences that the B-tree optimizes the height of the binary tree, reduces the number of queries, increases efficiency, and can store the data on the hard disk without disappearing
However, the B-tree can be further improved, and then there is the B + tree:
2.3 B + tree
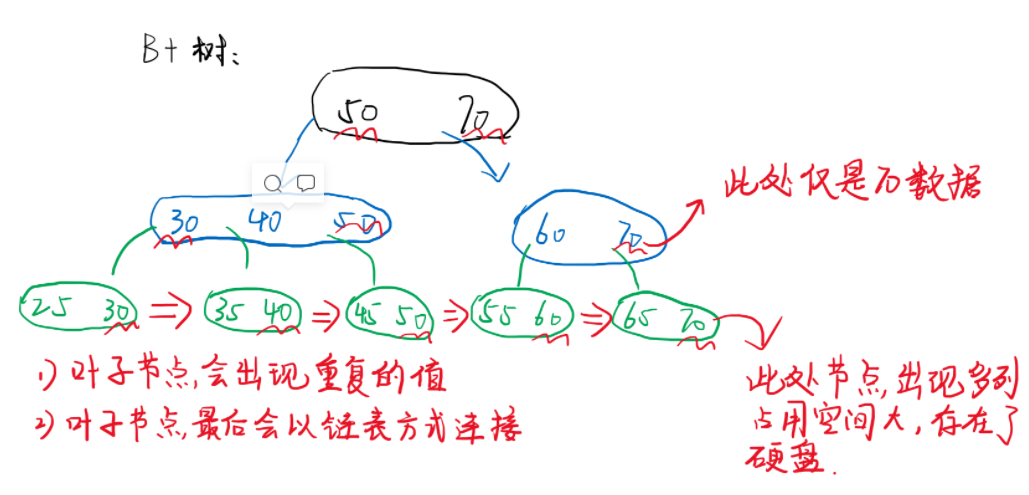 B + tree and B tree change in two aspects
B + tree and B tree change in two aspects
- The values of the non leaf nodes of the B + tree are duplicated. Ensure that the leaf node layer is a complete set of data structures (meaning brought by repetition)
- Finally, all leaf nodes are connected in order by using the linked list method
Advantages of B + tree:
1. Be good at range finding, such as the two boundary values, and find the positions of the two boundary values respectively (ID < 50 and ID > 30)
2. The query will eventually fall on the leaf node layer, and the query speed is stable and fast
3. Because the leaf is the complete set of data, the leaf node is stored on the hard disk and the non leaf node is stored in memory, which further reduces the number of times to read the hard disk!!! (big killer of B + tree)
matters needing attention
1,The index is suitable only when there are many searches 2,The space occupied by the index is not small, and the disk is not recommended 3,The index needs to be distinguished greatly before it is suitable for index making 4,stay MySQL Used in create index Orders, MySQL The bottom layer is automatically created for us B+tree
2.4 non clustered index
Describe how MySQL underlying organizes data.
Non clustered index is to load all data through the structure of "table"
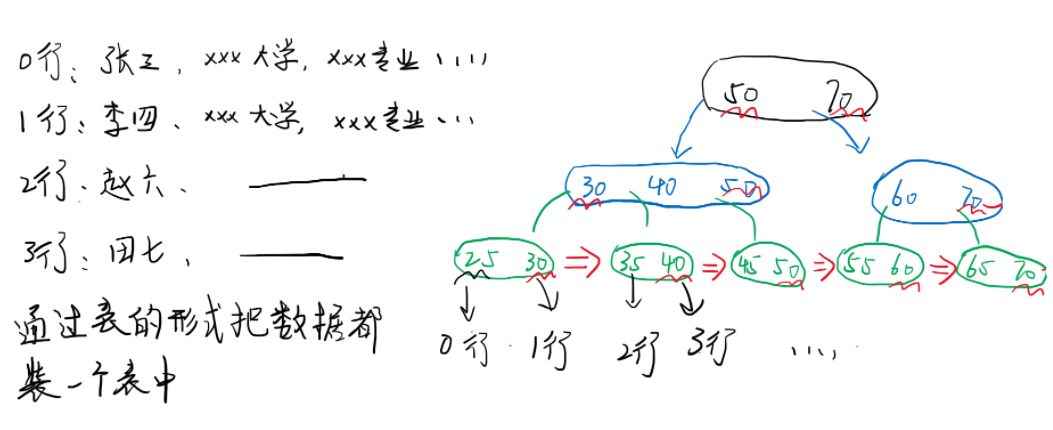
Finally, the data is loaded into a table in the form of a table.
2.5 clustering index
The data itself is organized by B + tree, and each leaf node stores a complete record.
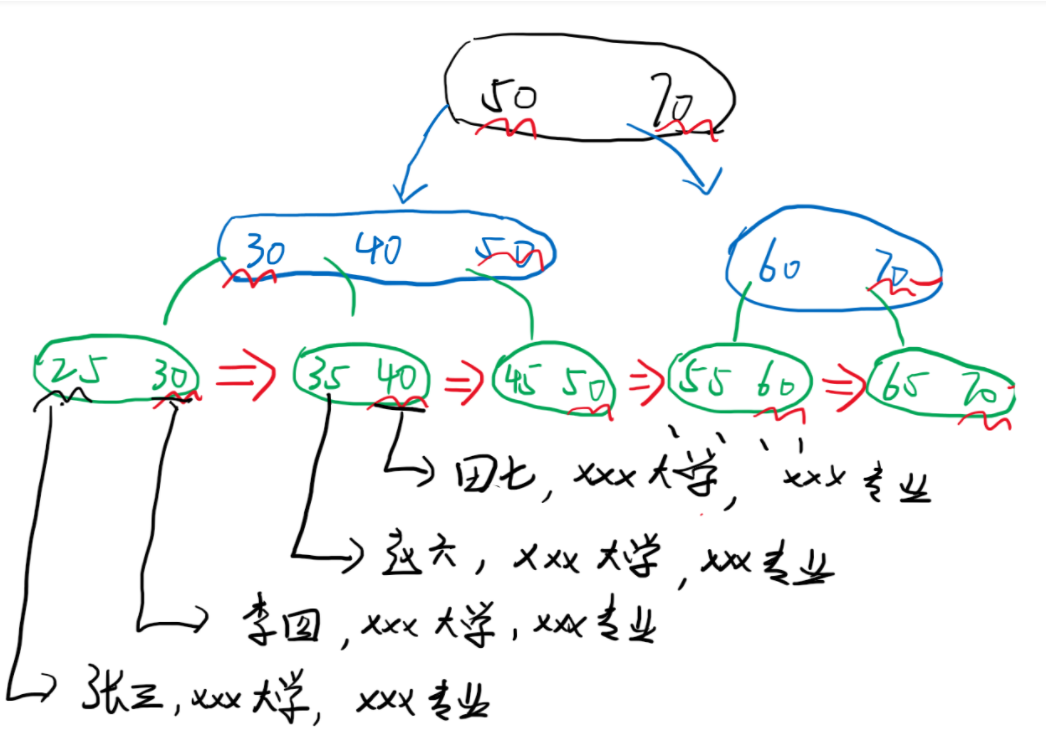
Clustering and non clustering ultimately make the clustered index more efficient, because non clustering needs to build a table and put the data into the table, which slows down the speed. However, non clustering has the advantage that it stores data through each row, so its disk fragments are less and save space.
3, Business
3.1 what is a transaction
Generally, people are sensitive about money. If others transfer 200 to you, then other people's account will be - 200. At this time, if the server is disconnected, you will not receive other people's 200 yuan. This phenomenon will cause a social panic. It is a serious phenomenon. In order to solve this phenomenon, SQL uses transaction control to ensure that either all execution is successful or all execution is successful Execution failed.
3.2 concept of transaction
Transaction refers to a logical group of operations. Each unit of this group of operations either succeeds or fails. There can be transactions in different environments. Corresponding in the database, it is the database transaction.
3.3 characteristics of transactions
Atomicity: a series of operations are packaged together to form a whole, which is either completed or failed. such as: A account-200,B account+200,If the database crashes halfway, atomicity will return the operation in the intermediate state (operation name: rollback). Atomicity will record the intermediate operation. When the database crashes, it is returning the previous operation, so as to achieve either full success or complete failure. Consistency: before and after the transaction is executed, the data in the current table is in a reasonable state. Persistence: the data of transaction operations are operated on the hard disk, which is a persistent storage. Isolation: multiple transactions, problems arising from concurrent execution!!!
4, JDBC
4.1 what is JDBC
JDBC is the database API in java, that is, JDBC operates the database through java code. Because the database supports multiple programming, that is, different databases support APIs in different languages, and the database is also divided into multiple databases and multiple APIs. If you operate different databases through code to complete the same function, you have to write codes in multiple languages. The development cost is high, the learning cost is high, and the time cost is high. Therefore, in order to solve the appeal problem, It is to abstract and encapsulate various APIs of various databases into one layer to encapsulate a set of unified APIs. Then JDBC is the API provided by the java language standard library.
4.2 working principle of JDBC
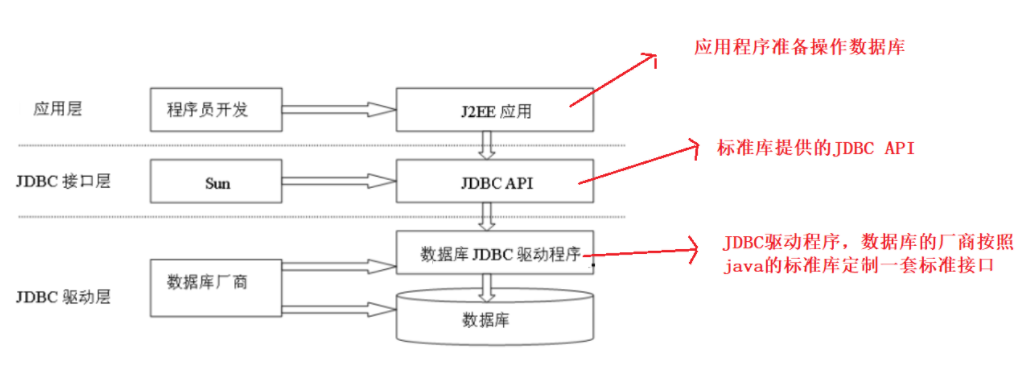
JDBC advantages:
1,Java Language access database operation is completely oriented to abstract interface programming 2,The development of database applications is not limited to the specific database manufacturers API 3,The portability of the program is greatly enhanced
4.3 implementation of JDBC
1. Add operation:
public static void testInsert() throws SQLException {
//DataSource is the interface of the standard library. MYsqlDataSource() is the driver of MySQL JDBC
DataSource dataSource=new MysqlDataSource();
//1. Set IP and port, represented by URL,
//1).setURL belongs to the method of MySQLDataSource, which is used for downward transformation
((MysqlDataSource)dataSource).setURL("jdbc:mysql://127.0.0.1:3306/java101?characterEncoding=utf8&useSSL=false");
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("0123456789");
//3. Connect to the database
Connection connection=dataSource.getConnection();
//4. Let the user enter id and name
Scanner scanner=new Scanner(System.in);
System.out.println("Please enter student number:");
int id=scanner.nextInt();
System.out.println("Please enter your name");
String name=scanner.next();
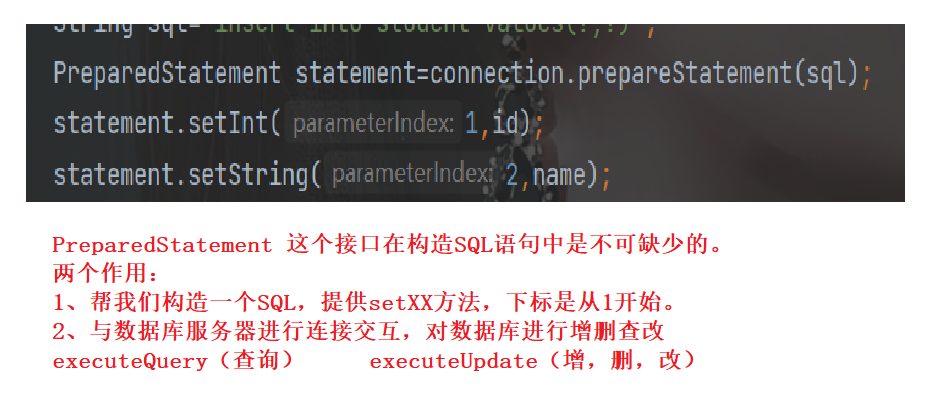
//5. Construct an SQL statement to prepare for insertion
String sql="insert into student values(?,?)";
PreparedStatement statement=connection.prepareStatement(sql);//Connect and interact with the database server
statement.setInt(1,id);//The setXXX method is provided, and the subscript starts from 1
statement.setString(2,name);
System.out.println("sql:"+ statement);
//executeUpdate() to change the database add, change and delete operations
int ret=statement.executeUpdate();
System.out.println("ret:"+ ret);
//Release resources
statement.close();
connection.close();
}

2. The deletion operation is different from the addition operation. I don't understand it, so I won't repeat it:
public static void testDelete() throws SQLException {
DataSource dataSource=new MysqlDataSource();
((MysqlDataSource)dataSource).setURL("jdbc:mysql://127.0.0.1:3306/java101?characterEncoding=utf8&useSSL=false");
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("0123456789");
Connection connection=dataSource.getConnection();
Scanner scanner=new Scanner(System.in);
System.out.println("Please enter the to delete id");
int id=scanner.nextInt();
//Construct sql
String sql="delete from student where id=?";
PreparedStatement statement=connection.prepareStatement(sql);
statement.setInt(1,id);
System.out.println("sql:" + statement);
//Execute sql
int ret = statement.executeUpdate();
System.out.println("ret:" + ret);
//Release resources
statement.close();
connection.close();
}
3. The modification operation is the same as the previous addition and deletion operations
public static void testUpdate() throws SQLException {
DataSource dataSource=new MysqlDataSource();
((MysqlDataSource)dataSource).setURL("jdbc:mysql://127.0.0.1:3306/java101?characterEncoding=utf8&useSSL=false");
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("0123456789");
Connection connection=dataSource.getConnection();
Scanner scanner=new Scanner(System.in);
System.out.println("Please enter the you want to modify id");
int id=scanner.nextInt();
System.out.println("Please enter the name you want to modify");
String name=scanner.next();
//Construct sql
String sql="Update student set id=? where name=?";
PreparedStatement statement=connection.prepareStatement(sql);
statement.setInt(1,id);
statement.setString(2,name);
System.out.println("sql:"+statement);
//Execute sql
int ret= statement.executeUpdate();
System.out.println("ret:" + ret);
//Release resources
statement.close();
connection.close();
}
4. The query operation is different from the previous one:
public static void testSelect() throws SQLException {
DataSource dataSource=new MysqlDataSource();
((MysqlDataSource)dataSource).setURL("jdbc:mysql://127.0.0.1:3306/java101?characterEncoding=utf8&useSSL=false");
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("0123456789");
Connection connection=dataSource.getConnection();
String sql="select * from student";
PreparedStatement statement= connection.prepareStatement(sql);
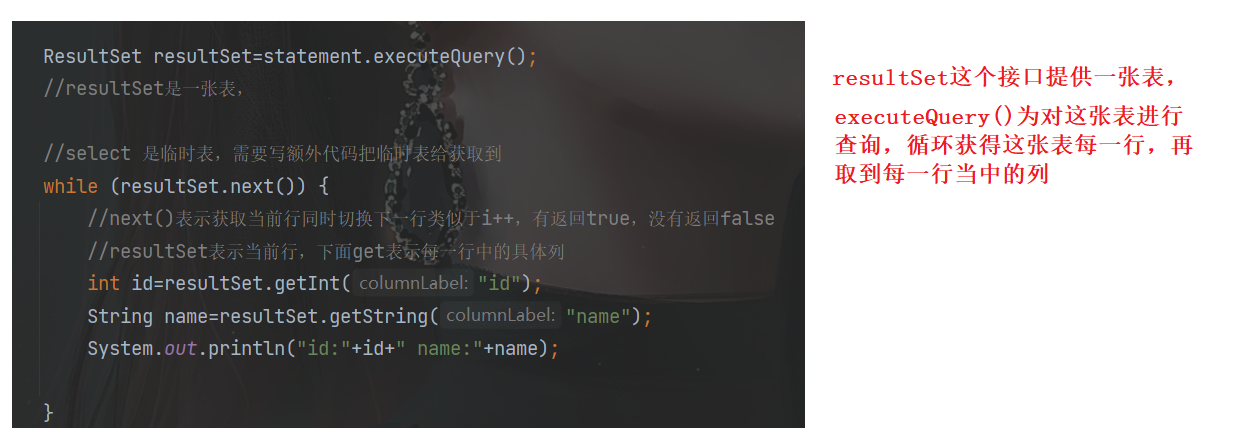
// Because the table finally presented by select is a temporary table, you need to write additional code to report the temporary table to get it
ResultSet resultSet=statement.executeQuery();
//resultSet is a table,
while (resultSet.next()) {
//next() means to get the current row and switch to the next row at the same time, which is similar to i + +. It returns true but not false
//resultSet represents the current row, and get below represents the specific column in each row
int id=resultSet.getInt("id");
String name=resultSet.getString("name");
System.out.println("id:"+id+" name:"+name);
}
//Release resources
resultSet.close();
statement.close();
connection.close();
}

According to the review of each module, the index and tree are still very abstract to me, I don't understand / (o) / ~ ~ I hope to get the guidance of the master!