1. DML language
Data manipulation language
It is mainly used to insert, modify update and delete
1.1 insertion
1. Basic syntax format
# Insert syntax INSERT INTO Table name (Field name 1,Field name 2 ...) VALUES (Value 1, Value 2 ...);
1.1 it is required that the type of inserted value should be compatible with the type of field
# Insert a piece of data into the beauty table INSERT INTO beauty(id, `name`, sex, borndate, phone, photo, boyfriend_id) VALUES(13, 'perfect','female', '1990-04-23', '18805558888', NULL, 2)

You can see that it has been inserted successfully. The photo field above can be null. We inserted a null.
1.2 data that you do not want to insert can not be written, provided that this field can be null.
# Insert a piece of data into the beauty table INSERT INTO beauty(id, `name`, sex, borndate, phone, boyfriend_id) VALUES(14, 'Perfect 2','female', '1991-04-23', '18866668888', 3)

Which fields can be empty? You can use the desc table name to view.

1.3 when inserting, the order of fields can be arbitrary. However, the order of values must correspond to the order of fields one by one.
INSERT INTO beauty(`name`, sex, id, phone)
VALUES('Perfect 3','female', 15, '18866667777')
We found that the birthday is not inserted, but it is in the data because the default value is set.
1.4 if column names can be omitted, all columns are selected by default, and the order of columns is the order defined in the table
INSERT INTO beauty VALUES(16, 'Perfect 4','female','1993-08-01', '13656561212', NULL, 4)

2. Insertion mode 2
Basic grammar
INSERT INTO beauty SET Field name=value, Field name=value, ...
example:
INSERT INTO beauty SET id=19, `name`='Perfect 5', phone='999'

Similarly, without setting the sex field and birthday field, they are automatically generated. This is the default value set when designing tables.
3. Comparison of two methods
Mode 1 supports multi line insertion, while mode 2 does not
INSERT INTO beauty(`name`, sex, id, phone)
VALUES('Batch 1','female', 20, '11'),('Batch 2','female', 21, '22'),('Batch 3','female', 22, '33')
Method 1 supports sub query, but method 2 does not
INSERT INTO beauty(id, `name`, phone) SELECT 26,'Perfect 6','10010'

1.2 modification
update keyword
1. Modification of single table
Basic format
UPDATE Table name SET Field name=New value,Field name=New value ... [WHERE Conditions]
The set keyword is also used here, but it is used together with the update keyword
# The telephone number of people with batch names is 10086 UPDATE beauty SET phone = 10086 WHERE `name` LIKE '%batch%'

# Modify the record name with the boys table id of 2 to Zhang Fei and the charm value to 10 UPDATE boys SET boyName='Fei Zhang', userCP=10 WHERE id=2
2. Modification of multiple tables
In fact, it is just adding connection conditions.
Basic format
# 92 grammar UPDATE Table 1 alias 1, Table 2 alias 2 SET Alias 1.Field name=value,..., Alias 2.Field name = value... WHERE Connection conditions AND Screening conditions;
# 99 grammar UPDATE Table 1 alias 1 connection type table 2 alias 2 ON Connection conditions SET Alias 1.Field name=value,..., Alias 2.Field name = value... WHERE Screening conditions;
Case 1
UPDATE boys bo JOIN beauty b ON bo.id = b.boyfriend_id SET b.phone = 114 WHERE bo.boyName = 'zhang wuji'
Case 2
# Modify the boyfriend number of women without boyfriend to be Zhang Fei UPDATE boys bo RIGHT JOIN beauty b ON bo.id = b.boyfriend_id SET b.boyfriend_id = 2 WHERE b.id IS NULL
1.3 deletion
1.3.1 deletion method 1
DELETE FROM Table name WHERE Screening conditions
Deletion is based on behavior. All data will be deleted without filtering criteria.
Adding a condition is to delete some rows that meet the condition.
1. Deleting a single table
Case 1:
# Delete female information with mobile phone number ending in 9 DELETE FROM beauty WHERE phone LIKE '%9';
2. Multi table deletion
# 92 grammar DELETE Table 1 aliases, Table 2 aliases FROM Table 1 alias 1, Table 2 alias 2 WHERE Connection conditions AND Screening conditions # 99 grammar DELETE Table 1 aliases, Table 2 aliases FROM Table 1 alias 1 connection mode table 2 alias 2 ON Connection conditions WHERE Screening conditions
If only the alias of a table is written after delete, only the data of this table will be deleted. If everything is written, it will be deleted.
Case 1:
# Delete Zhang Wuji's girlfriend information DELETE b FROM beauty b, boys bo WHERE b.boyfriend_id = bo.id AND bo.id=1;
# Delete the information of Huang Xiaoming and his girlfriend DELETE b,bo FROM beauty b JOIN boys bo ON b.boyfriend_id = bo.id WHERE bo.`boyName`='Huang Xiaoming'
1.3.2 deletion method 2
TRUNCATE table Table name;
Truncate keyword cannot be filtered. So truncate is to empty the table.
After truncate clears the table, if there is a self adding field in the table, the field will start from 1 again. While delete will not reset the auto increment field and will continue to grow.
truncate delete does not return a value, while delete delete returns several deleted rows.
2. DDL language
Data definition language
Mainly for the management of libraries and tables.
create, modify alter, delete drop
2.1 library management
1. Library creation
Basic format
CREATE DATABASE Library name
example:
CREATE DATABASE books;
Generally, we need to not create if it exists, and only create if it does not exist, plus the IF NOT EXISTS keyword combination
CREATE DATABASE IF NOT EXISTS books;
2. Library modification
Generally speaking, the library will not be modified after it is created. Modifying a library can easily make the entire library unusable.
Before 5.0, there was a command to modify the library name
RENAME DATABASE books TO newBooks;
The latter keyword rename is discarded because it is unsafe.
You can change the character set of the library
ALTER DATABASE books CHARACTER SET utf8mb4;
3. Library deletion
DROP DATABASE books;
Generally, you need to judge whether the database exists before deleting it. If it does not exist, you do nothing. So you won't report an error.
DROP DATABASE IF EXISTS books;
2.2 table management
2.2.1 table creation
Basic format
The column name is the field name
CREATE TABLE Table name( Column name column type [constraint], Column name column type [constraint], Column name column type [constraint], ... Column name column type [constraint] )
CREATE TABLE book( id INT COMMENT 'number', bName VARCHAR(20) COMMENT 'title', price DOUBLE COMMENT 'Price', authorId INT COMMENT 'author id', publishDate DATETIME COMMENT 'Publication time' )
The COMMENT keyword is followed by a COMMENT for the field.
The above is a simple table created by ourselves. In fact, the system will create it for us
CREATE TABLE `book` ( `id` int(11) DEFAULT NULL COMMENT 'number', `bName` varchar(20) DEFAULT NULL COMMENT 'title', `price` double DEFAULT NULL COMMENT 'Price', `authorId` int(11) DEFAULT NULL COMMENT 'author id', `publishDate` datetime DEFAULT NULL COMMENT 'Publication time' ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
The default value, whether it can be null, engine and character set will be added automatically.
Example 2: creating an author table
CREATE TABLE author( id INT COMMENT 'Author number', au_name VARCHAR(20) COMMENT 'Author name', nation VARCHAR(10) COMMENT 'nationality' )
2.2.2 modification of table
You can modify the column name, column type or constraint, column increase or decrease, and table name
1. Modify column names using the change keyword
# Change the publishDate column of the book table to pubDate ALTER TABLE book CHANGE COLUMN publishDate pubDate DATETIME; # The column keyword can be omitted ALTER TABLE book CHANGE publishDate pubDate DATETIME;
Note that when modifying the column name, you must add the type of the column.
2. Modify the type or constraint of the column and use the modify keyword
ALTER TABLE book MODIFY COLUMN pubDate TIMESTAMP;
3. Add new column add
ALTER TABLE author ADD COLUMN annual DOUBLE COMMENT 'Annual salary';
4. Delete column drop
ALTER TABLE author DROP COLUMN annual;
5. Modify table name rename to
ALTER TABLE author RENAME TO book_author;
You can see that one operation is one keyword. column can not be added to change, and some others need to be added. Suggestions are added.
2.2.3 deletion of table
DROP TABLE IF EXISTS book_author;
Some general statements:
DROP DATABASE IF EXISTS Old library name; CREATE DATABASE New library name; DROP TABLE IF EXISTS Old table name; CREATE TABLE New table name(...);
2.2.4 reproduction of tables
Create a table first
DROP TABLE IF EXISTS author; CREATE TABLE author( id INT COMMENT 'Author number', au_name VARCHAR(20) COMMENT 'Author name', nation VARCHAR(10) COMMENT 'nationality' )
Insert some data
INSERT INTO author VALUES (1, 'Spring trees on trees', 'Japan'), (2, 'Mo Yan', 'Chinese Mainland'), (1, 'tengger ', 'Russia'), (1, 'leo tolstoy ', 'Russia'), (1, 'Jin Yong', 'Taiwan, China');
1. Copy only the structure of the table
CREATE TABLE author_copy LIKE author;
It's very simple. Just use the like keyword.
2. Copy table structure and data
CREATE TABLE author_copy2 SELECT * FROM author;
This can be done using subqueries.
If you modify the sub query statement, you can copy part of the data.
CREATE TABLE author_copy3 SELECT * FROM author WHERE nation LIKE '%China%';
You can also do this:
CREATE TABLE author_copy4 SELECT id, au_name FROM author WHERE 1=2;
If you set a condition that no one can meet, the data will not be copied. At the same time, the field behind select writes the column name you need, which realizes the effect of copying only some fields without copying the data.
2.3 data type
1. Numerical type
integer
Tinyint, 1 byte occupied, unsigned 0-255, signed - 128-127
Smallint, 2 bytes
Mediumint, 3 bytes
Int and Integer occupy 4 bytes
Bigint takes 8 bytes
The above are divided into signed and unsigned.
How to set whether there is a symbol?
The default is signed.
CREATE TABLE int_test( t1 INT COMMENT 't1 The default is signed', t2 INT UNSIGNED COMMENT 't2 Is an unsigned number' )
A warning will appear on how to insert a negative number into an unsigned field. The minimum critical value of 0 will be inserted by default
What if the inserted value exceeds the maximum value of int? A warning also appears, which defaults to the maximum threshold for inserting int.
If the length of int is not set when creating a table, it will have a default value of 11 for signed and 10 for unsigned
This length is not an int range, but the width of the display. The width is not filled with 0 in combination with the zerofill keyword. Once filled with 0, it does not support signed.
DROP TABLE IF EXISTS int_test; CREATE TABLE int_test( t1 INT(8) ZEROFILL COMMENT '0 Fill automatically becomes unsigned', t2 INT UNSIGNED COMMENT 't2 Is an unsigned number' ); INSERT INTO int_test VALUES(1,5);
Decimal: fixed point number, floating point number
-
Floating point number:
M. D can be omitted.
D means to keep several digits after the decimal point
M means total length
Out of range, a critical value is inserted
float(M, D) occupies 4 bytes
double(M, D) takes 8 bytes
Omitting m and D from floating-point numbers will adapt the values of M and d according to the inserted values.
-
Fixed point type:
DEC(M, D) occupies M+2 bytes, and the maximum storage range is the same as double.
DECIMAL(M, D) is the complete expression of dec
If M and D are omitted for fixed-point type, M is 10 and D is 0 by default
2. Character type
-
Short text char, varchar
char(M) M is the maximum number of characters, and the value is 0-255
char is a fixed length character. If the number of characters is determined, it can be used, which is more efficient than varchar. The default M is 1
varchar(M) M is the maximum number of characters, and the value is 0-65535
varchar is a variable length character. The number of characters is not fixed and can be used. It occupies a relatively low space. M cannot be omitted. There is no default value
CREATE TABLE str_test( sex CHAR(1) COMMENT 'Gender', name VARCHAR(10) COMMENT 'full name' )
-
Long text, blob (long binary data)
-
Enum enum
CREATE TABLE enum_test(
sex ENUM('0', '1', '2') COMMENT 'Enumeration type, value 0,1 female,2 Third sex'
);INSERT INTO enum_test VALUES('1'),('0'),('2');An enumeration type can only insert a specified number. However, if the inserted '3' will insert the critical value '2', the insertion of other values will not succeed.
-
The set collection type is similar to enum, which can save 0-64 members. The difference between enum and set is that set can select multiple members at a time, while enum can only select one
The number of members in the set is different, and the occupied bytes are also different. It is not case sensitive
1 for 1-8, 2 for 8-16, 3 for 17-24, 4 for 25-32 and 8 for 33-64
CREATE TABLE set_test(
sex SET('0', '1', '2', '3', '4', '5') COMMENT 'Set type, with 6 values'
);
INSERT INTO set_test VALUES('0');
INSERT INTO set_test VALUES('0,1,4');
3. Date type
date occupies 4 bytes. The minimum value is 1000-01-01 and the maximum value is 9999-12-31
datetime takes 8 bytes. The minimum value is 1000-01-01 00:00:00 and the maximum value is 9999-12-31
timestamp takes up 4 bytes. The minimum value is 1970011080001 and the maximum value is sometime in 2038
time takes up 3 bytes minimum value - 838:59:59 maximum value 838:59:59
year occupies 1 byte minimum 1901 maximum 2155
timestamp supports a smaller time range, which is related to the actual time zone and can better reflect the actual date, while datetime can only reflect the local time zone at the time of insertion
The timestamp attribute is greatly affected by the mysql version and sqlMode
CREATE TABLE time_test( date DATETIME COMMENT 'datetime type', time TIMESTAMP COMMENT 'Timestamp type' );
INSERT INTO time_test VALUES(NOW(), NOW());

View current time zone:
SHOW VARIABLES LIKE 'time_zone';

Ha ha, I found the system time zone...
Change time zone:
SET time_zone = '+8:00';
View again:
SHOW VARIABLES LIKE 'time_zone';

2.4 common constraints
Constraint is a restriction on the data in the table in order to ensure the reliability and accuracy of the data.
There are six constraints.
NOT NULL is a non NULL constraint. The value of this field cannot be null.
Default default constraint sets the default value for this field. If you do not actively insert data, the default value will be automatically used
Primary key is a primary key constraint to ensure that the value of this field is unique and non empty
Unique unique constraint, but can be empty
Check check constraint (mysql does not support it, but syntax supports it, but it has no effect)
Foreign key constraint is used to restrict the relationship between two tables and ensure that the value of this field must come from the associated field of the main table [add foreign key constraint from the table and reference the value of the main table]
The time to add constraints. Because constraints work on the entire table, constraints must be added when they are created.
1. When creating a table
2. When modifying a table (it can be modified if it is created but there is no data)
If there is data, only some constraints can be added and modified.
Constraints are column level constraints and table level constraints.
For fields, it is column level constraints, and for the whole table, it is table level constraints.
Column level constraints: all six constraints can be written, but foreign key constraints and check constraints have no effect
Table level constraint: all other constraints are supported except non empty and default
2.4.1 adding constraints
Recreate a library to test
CREATE DATABASE students CHARACTER SET 'utf8mb4';
First create a major curriculum
CREATE TABLE major( id INT PRIMARY KEY COMMENT 'Primary key', majorName VARCHAR(20) COMMENT 'Professional name' )
Then create the student table
DROP TABLE IF EXISTS stuinfo; CREATE TABLE stuinfo( id INT PRIMARY KEY COMMENT 'Primary key',#Primary key stuName VARCHAR(20) NOT NULL UNIQUE COMMENT 'Student name non empty constraint',#Non empty gender CHAR(1) CHECK(gender='male' OR gender ='female') ,#inspect seat INT UNIQUE ,#only age INT DEFAULT 18 ,#Default constraint majorId INT REFERENCES major(id) #Foreign key );
Some of the above comments are added with comments, and some are not, because adding them will report an error. I don't know why.
View index:
SHOW INDEX FROM stuinfo;
Primary key, foreign key and unique key will generate index by default
The stuinfo table created above has only column level constraints. Let's try table level constraints
DROP TABLE IF EXISTS stuinfo;
CREATE TABLE stuinfo(
id INT COMMENT 'Primary key',
stuName VARCHAR(20) COMMENT 'Student name',
seat INT COMMENT 'Seat number',
age INT COMMENT 'Age',
gender CHAR(1) COMMENT 'Gender',
majorid INT COMMENT 'Major courses id',
# Table level constraints (non empty and default are not supported)
CONSTRAINT pk PRIMARY KEY(id),
CONSTRAINT uq UNIQUE(seat),
CONSTRAINT ck CHECK(gender ='male' OR gender = 'female'),
CONSTRAINT fk_stuinfo_major FOREIGN KEY(majorid) REFERENCES major(id)
)View index
SHOW INDEX FROM stuinfo;

You can see that the alias of the primary key has no effect.
Table level constraint basic format:
# Add after field [CONSTRAINT Constraint name] constraint type(Field name)
CONSTRAINT can not be written, that is, it cannot afford the CONSTRAINT name.
2.4.2 primary key, unique key and foreign key
Comparison between primary key and unique:
1. Uniqueness can be guaranteed, but the primary key must be non empty, and the unique constraint can be null, but there can only be one null at most.
2. There can only be 1 primary key and multiple unique key constraints. That is, multiple fields can be constrained with a single key.
3. A combination of primary and unique key runs.
DROP TABLE IF EXISTS stuinfo;
CREATE TABLE stuinfo(
id INT COMMENT 'Primary key',
stuName VARCHAR(20) COMMENT 'Student name',
seat INT COMMENT 'Seat number',
age INT COMMENT 'Age',
gender CHAR(1) COMMENT 'Gender',
majorid INT COMMENT 'Major courses id',
# Table level constraints (non empty and default are not supported)
CONSTRAINT pk PRIMARY KEY(id, stuName), # Combined primary key
CONSTRAINT uq UNIQUE(seat),
CONSTRAINT ck CHECK(gender ='male' OR gender = 'female'),
CONSTRAINT fk_stuinfo_major FOREIGN KEY(majorid) REFERENCES major(id)
);
SHOW INDEX FROM stuinfo;
It looks like two primary keys here, but it's actually one. Combined primary key means that these multiple fields cannot be identical. Combined primary keys are not recommended.
Foreign key:
1. Requires foreign key relationships to be set in the slave table
2. The type of the foreign key column of the slave table and the type of the associated column of the master table shall be consistent or compatible
3. It is required that the associated column of the main table must be a key (usually a primary key (unique key and foreign key are OK))
4. When inserting data, insert the master table first and then the slave table. When deleting data, just the opposite, insert the slave table first and then the master table.
2.4.3 adding and deleting constraints when modifying tables
Since you are modifying a table, you need to use alter table
1. Add a non empty constraint
DROP TABLE IF EXISTS stuinfo; CREATE TABLE stuinfo( id INT, stuname VARCHAR(20), seat INT, age INT, major INT );
# stuname adds a non empty constraint ALTER TABLE stuinfo MODIFY COLUMN stuname VARCHAR(20) NOT NULL;
Delete non empty constraint?
ALTER TABLE stuinfo MODIFY COLUMN stuname VARCHAR(20);
2. Add default constraint
# Add default constraint ALTER TABLE stuinfo MODIFY COLUMN age INT DEFAULT 18;
Delete default constraint
ALTER TABLE stuinfo MODIFY COLUMN age INT;
3. Add primary key
# Add primary key ALTER TABLE stuinfo MODIFY COLUMN id INT PRIMARY KEY; # The second method is because the primary key supports column level constraints and table level constraints ALTER TABLE stuinfo ADD PRIMARY KEY(id);
Delete primary key
ALTER TABLE stuinfo DROP PRIMARY KEY;
4. Add unique key
# Add unique key ALTER TABLE stuinfo MODIFY COLUMN seat INT UNIQUE; # The second method is because the unique key supports column level constraints and table level constraints ALTER TABLE stuinfo ADD UNIQUE(seat);
Delete unique key
ALTER TABLE stuinfo DROP INDEX seat;
seat is the name of the unique key, which can be found through the show index from table name. Check and confirm after deletion
5. Add foreign key
ALTER TABLE stuinfo ADD FOREIGN KEY(major) REFERENCES major(id); # You can also add a name ALTER TABLE stuinfo ADD CONSTRAINT fk_stuinfo_major FOREIGN KEY(major) REFERENCES major(id);
Delete foreign key
ALTER TABLE stuinfo DROP FOREIGN KEY fk_stuinfo_major;
Foreign key names also need to be found.
Added format:
1,Column level constraint ALTER TABLE Table name MODIFY COLUMN Field name type new constraint; 2,Table level constraints ALTER TABLE Table name ADD [CONSTRAINT Constraint name] new constraint(Field name) [Foreign key reference];
2.4.4 identification column (self added column)
Auto incrementing columns do not need to manually insert values. The system provides default sequence values
CREATE TABLE tab_identity( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(20) );
Set the primary key as auto above_ Increment is self growing, so you don't have to write the value of id field when inserting data.
INSERT INTO tab_identity VALUES(NULL, 'john');
Take a look at the system variables
SHOW VARIABLES LIKE '%AUTO_INCREMENT%';
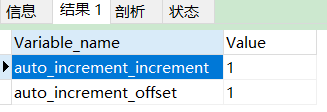
auto_increment_increment is the step size, auto_increment_offset is the offset, the starting value.
Set auto_increment_increment step
SET auto_increment_increment = 3;
However, mysql does not support setting auto_increment_offset .
Although direct setting is not supported, you can specify the id when inserting the first piece of data. The latter value will grow on the specified value.
In other words, one day in the middle, the data specifies the id, and the subsequent data uses the automatic id.
The identification column is not necessarily a primary key, but it must be a key
A table can only have one self incrementing column. The type of this self incrementing column must be numeric.
Set identity column when modifying table
DROP TABLE IF EXISTS tab_identity; CREATE TABLE tab_identity( id INT, name VARCHAR(20) ); ALTER TABLE tab_identity MODIFY COLUMN id INT PRIMARY KEY AUTO_INCREMENT;
delete
ALTER TABLE tab_identity MODIFY COLUMN id INT;
3. TCL language
transaction controller language
Transaction control language
3.1 transactions
Why transactions are needed?
When some operations cannot be completed in one step, for example, multiple sql statements need to be executed before an operation is completed. In order to ensure the consistency of the operation, that is, if the operation is successful, all these sql statements should be successful. If one sql fails, it means that the operation fails, and other successful sql statements should also fall back, Should not be executed successfully.
That is, the success and failure of multiple sql statements are bound together, either all succeed or all fail. This is a transaction.
The most typical practical problem is the transfer. A transfers 500 yuan to B. A needs to deduct the money and B needs to increase the money. If B fails to increase the money, a succeeds in deducting the money, that's not a problem. That is, a deduction and B addition must all succeed or fail, which is reasonable.
Storage engine: the data in mysql is stored in files with various technologies.
show engines to view the storage engines supported by mysql.

You can see a lot. InnoDB, myisam and memory are used most. However, only InnoDB supports transactions. The default storage engine is InnoDB
3.1.1 transaction attribute acid
1. Atomicity
Atomicity means that a transaction is an indivisible work unit, and all operations in the transaction are either sent or not sent.
2. Consistency
Transactions must transition the database from one consistency state to another.
3. Isolation
The execution of a transaction cannot be interfered by other transactions. The operations and data used within a transaction are isolated from other concurrent transactions, and the concurrent transactions cannot interfere with each other
4. Persistence durability
Once a transaction is committed, its changes to the data in the database are permanent. Other subsequent operations and database failures should not have any impact on it.
3.1.2 transaction creation
Implicit transaction: there are no obvious open and end marks, and the automatic submission function is turned on
For example, insert, update, delete and other common statements
Explicit transaction: with obvious start and end.
If necessary, turn off the auto submit function. set autocomit=0
Turning off auto submit is only valid for the current reply.
You can check whether automatic submission is enabled by viewing variables. On means on and off means off
SHOW VARIABLES LIKE 'autocommit';
Step 1: start the transaction
SET autocommit = 0; START TRANSACTION; # Optional
Step 2: write sql statements in the transaction (select, insert, update, delete)
sql statements in transactions refer to operations on table data. There is no transaction for database operation and table operation.
Step 3: end the transaction
COMMIT; # Commit transaction ROLLBACK; # Rollback transaction
See example:
First create a table to test.
DROP TABLE IF EXISTS account; CREATE TABLE account( id INT PRIMARY KEY auto_increment, username VARCHAR(20), balance DOUBLE ); INSERT INTO account VALUES(NULL, 'zhang wuji', 1000),(NULL, 'Zhao Min', 10000);
# Open transaction SET autocommit = 0; START TRANSACTION; # Write a set of sql UPDATE account SET balance = 2000 WHERE username = 'zhang wuji'; UPDATE account SET balance = 9000 WHERE username = 'Zhao Min'; # End transaction COMMIT;
Try rollback
# Open transaction SET autocommit = 0; START TRANSACTION; # Write a set of sql UPDATE account SET balance = 1000 WHERE username = 'zhang wuji'; UPDATE account SET balance = 10000 WHERE username = 'Zhao Min'; # End transaction ROLLBACK;
It was found that the database data did not change.
In fact, before the end of the transaction, the changes to the data are only saved in memory and not merged into the database file. Only commit can synchronize data. If it is a rollback, all the data in memory will be invalidated. If it is not merged, the database will not be modified.
Think about it: if you run multiple transactions at the same time, what problems will occur when these transactions access the same data in the database?
This means that the data operated between transactions is not isolated, and it also means that the data is unreliable.
1. Dirty read: for two transactions T1,T2, T1 reads the data updated by T2 but not committed, and then T2 rolls back, indicating that the data read before T1 is invalid data.
2. Non repeatable reading (the data read multiple times by the same transaction is different): T1 reads a field, then T2 updates the field, T1 reads it again, and the value is different.
3. Phantom reading (for insertion): T1 reads a field from a table, then T2 inserts a new row, and then T1 reads it again, there will be several more rows
Avoid the above situation by setting the isolation level.
Oracle supports two transaction isolation levels: read committed (default) and Serializable
mysql supports four types:
Read uncommitted: dirty, unrepeatable, unreal
Read committed, non repeatable or unreal reading occurs
Repeattake read (repeatable, default), unreal read appears
Serializable does not cause concurrency problems.
Query isolation level
select @@tx_isolation;
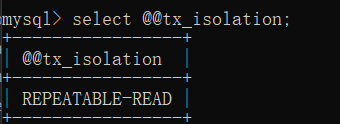
Sets the isolation level of the current reply
set session transaction isolation level read uncommitted;
Serializable serialization can avoid all concurrency problems, but it is very inefficient.
savepoint node name to save the node.
SET autocommit=0;START TRANSACTION;DELETE FROM account WHERE id = 1;INSERT INTO account VALUES(null, 'aaa', 111111);SAVEPOINT a; # Set save point, match rollback use DELETE FROM account WHERE id = 2;ROLLBACK TO a; # Rollback to savepoint a
3.1.3 delete and truncate
The difference between delete and truncate in transaction usage
USE test;SET autocommit = 0;START TRANSACTION;DELETE FROM account;ROLLBACK;
Use delete to roll back successfully in a transaction.
USE test;SET autocommit = 0;START TRANSACTION;TRUNCATE TABLE account;ROLLBACK;
Cannot roll back in a transaction using truncate, that is, truncate does not support transactions.
3.2 view
A view is a virtual table, which is used as an ordinary table. Data generated dynamically through ordinary tables.
View: only save sql logic, not query results.
The same query results are used in multiple places, and the sql used in the query results is complex.
Case:
# Query the student name and major name surnamed Zhang SELECT stuname,majorname FROM stuinfo s JOIN major m ON s.major=m.idWHERE s.stuName LIKE 'Zhang%';
Through view approach
#Create view CREATE VIEW v1ASSELECT stuname,majorname FROM stuinfo s JOIN major m ON s.major=m.id;# Use the view SELECT * FROM v1 WHERE stuname LIKE 'sheet%';
view a chart
DESC View name;# Or SHOW CREATE VIEW view name;
3.2.1 creating views
CREATE VIEW View name AS Query statement;
example
# Query the employee name, department name and type of work information of a contained in the name SELECT e.last_name, d.department_name, j.job_titleFROM employees e JOIN departments d ON e.department_id = d.department_id JOIN jobs j ON j.job_id = e.job_id;
Encapsulate into view
#Create viewcreate view v1aselect e.last_ name, d.department_ name, j.job_ titleFROM employees e JOIN departments d ON e.department_ id = d.department_ id JOIN jobs j ON j.job_ id = e.job_ id;
use
SELECT * FROM v1 WHERE last_name LIKE '%a%'
3.2.2 view modification
Method 1: modify if the entity exists, and create if it does not exist
CREATE OR REPLACE VIEW View name AS Query statement;
Mode 2:
ALTER VIEW View name AS Query statement;
3.2.3 deletion of view
DROP VIEW view name, view name,..., view name;
The above statement shows that multiple views can be deleted at a time.
3.2.4 view update
#Create viewcreate or replace view myv1asselect last_ name,email FROMemployees; SELECT * FROM myV1;
When updating the view, you can insert data [modify, add and delete are the same]
Data modification [add, delete, modify] is called update
INSERT INTO myV1 VALUES('aaaa', 'fasdf');Note that not all views can be updated. You can update only if the original table field also exists.
When the view is updated, the original table is updated synchronously.
Views with the following characteristics cannot be updated:
1. sql statements containing the following keywords: grouping function, distinct, group by, having, union all
The main reason is that the contents of the views generated by these sql do not exist in the original table, and the views will not store data in essence. To update the view, you still need to update the data in the original table. If there are no original tables, the view cannot be updated.
2. Constant view
3. select contains subqueries
4. from a view that cannot be updated
5. The subquery of the where clause references the table in the from clause
3.2.5 comparison between view and table
1. Created differently
The table keyword is used for the table, and the view keyword is used for the view
2. The table is real. The view is virtual, and the view only saves logic.
3. Generally, views cannot be added, deleted or modified, while tables can. The essence of view is to facilitate query.