MySQL Index Optimizing Analysis 3-Single Table Query for SQL Query Optimizing
- 1. Data preparation
- 1.1 Formulation
- 1.2 Setting parameter log_bin_trust_function_creators
- 1.3 Create SQL functions to ensure that each data is different
- 1.4 Create SQL stored procedures
- 1.5 Call Stored Procedures
- 1.6 Batch deletion of all indexes on a table
- 2. Single table index usage and common index invalidation
- 2.1 Index Failure - Case
- 1. Index Full Value Matching
- 2. The Best Left Prefix Rule
- 3. Don't do anything on index columns
- 4. The storage engine cannot use the column on the right of the range condition in the index
- 5. Failure to use indexes when using MySQL is not equal to (!= or <>) results in full table scanning
- 6.is not null can not use index, but is null can use index.
- 7.Like starts with wildcards and underscores ('% abc...','_abc...') when the MySQL index fails, it becomes a full table scan operation.
- 8. String index failure without single quotation mark
- 9. Index Failure Summary
- 2.2 General Suggestions for Index Optimization of Single Table Queries
When index is used in a table, its purpose is to improve the efficiency of SQL query. The first two sections also introduce Mysql database index and the execution plan of SQL query. The question is, how do SQL query statements use index in tables to improve query efficiency?
This section will introduce the index optimization of SQL query statements in detail by comparing and analyzing the different index settings and the implementation of the corresponding SQL query statements.
1. Data preparation
First, the data preparation of the experimental case. Through batch data script, dept and emp data tables are created, and 100,000 and 500,000 pieces of data are inserted respectively.
1.1 Formulation
Firstly, a department table dept and an employee table emp are created. The related fields, attributes and database are set as follows:
CREATE TABLE `dept` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `deptName` VARCHAR(30) DEFAULT NULL, `address` VARCHAR(40) DEFAULT NULL, ceo INT NULL , PRIMARY KEY (`id`) ) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; CREATE TABLE `emp` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `empno` INT NOT NULL , `name` VARCHAR(20) DEFAULT NULL, `age` INT(3) DEFAULT NULL, `deptId` INT(11) DEFAULT NULL, PRIMARY KEY (`id`) #CONSTRAINT `fk_dept_id` FOREIGN KEY (`deptId`) REFERENCES `t_dept` (`id`) ) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
1.2 Setting parameter log_bin_trust_function_creators
If a function is created, if an error is reported: This function has none of DETERMINISTIC...
- Because we open the bin-log too slowly, we have to specify a parameter for our function.
show variables like 'log_bin_trust_function_creators'; set global log_bin_trust_function_creators=1;
After adding parameters, if mysqld restarts, the above parameters will disappear again. Permanent method:
Under windows, my.ini[mysqld] adds:
- log_bin_trust_function_creators=1
Under linux, / etc/my.cnf's [mysqld] adds:
- log_bin_trust_function_creators=1
1.3 Create SQL functions to ensure that each data is different
In order to bulk insert random data into a table, two SQL functions are created to be used when inserting data.
1. Random Generation of String Functions
DELIMITER $$ CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255) BEGIN DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; DECLARE return_str VARCHAR(255) DEFAULT ''; DECLARE i INT DEFAULT 0; WHILE i < n DO SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1)); SET i = i + 1; END WHILE; RETURN return_str; END $$
#If you want to delete a function drop function rand_string;
2. Random Generation of Sector Number Function
#Numbers for random generation DELIMITER $$ CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11) BEGIN DECLARE i INT DEFAULT 0; SET i = FLOOR(from_num +RAND()*(to_num -from_num+1)) ; RETURN i; END$$
#If you want to delete a function drop function rand_num;
1.4 Create SQL stored procedures
The stored procedure is used to insert n pieces of data into the tables created in 1.1. The values of some fields in the tables are randomly generated using the SQL function in 1.3.
1. Create stored procedures that insert data into emp tables
DELIMITER $$ CREATE PROCEDURE insert_emp( START INT , max_num INT ) BEGIN DECLARE i INT DEFAULT 0; #set autocommit =0 sets autocommit to 0 SET autocommit = 0; REPEAT SET i = i + 1; INSERT INTO emp (empno, NAME ,age ,deptid ) VALUES ((START+i) ,rand_string(6) , rand_num(30,50),rand_num(1,10000)); UNTIL i = max_num END REPEAT; COMMIT; END$$
#Delete stored procedures DELIMITER ; drop PROCEDURE insert_emp;
2. Create stored procedures that insert data into dept tables
#Execute stored procedures to add random data to dept tables DELIMITER $$ CREATE PROCEDURE `insert_dept`( max_num INT ) BEGIN DECLARE i INT DEFAULT 0; SET autocommit = 0; REPEAT SET i = i + 1; INSERT INTO dept ( deptname,address,ceo ) VALUES (rand_string(8),rand_string(10),rand_num(1,500000)); UNTIL i = max_num END REPEAT; COMMIT; END$$
#delete DELIMITER ; drop PROCEDURE insert_dept;
1.5 Call Stored Procedures
Call the stored procedure in 1.4, pass in setting parameters, and realize the insertion of large amounts of data, as the experimental preparation for the optimization of the SQL index.
#Execute the stored procedure and add 10,000 pieces of data to the dept table DELIMITER ; CALL insert_dept(10000); #Execute stored procedures to add 500,000 pieces of data to emp tables DELIMITER ; CALL insert_emp(100000,500000);
1.6 Batch deletion of all indexes on a table
SQL index optimization involves the creation and deletion of many indexes. Here we create a storage process that can delete the indexes on tables in batches, and call the execution directly when using it.
1. Storage process of creating deleted index
DELIMITER $$ CREATE PROCEDURE `proc_drop_index`(dbname VARCHAR(200),tablename VARCHAR(200)) BEGIN DECLARE done INT DEFAULT 0; DECLARE ct INT DEFAULT 0; DECLARE _index VARCHAR(200) DEFAULT ''; DECLARE _cur CURSOR FOR SELECT index_name FROM information_schema.STATISTICS WHERE table_schema=dbname AND table_name=tablename AND seq_in_index=1 AND index_name <>'PRIMARY' ; DECLARE CONTINUE HANDLER FOR NOT FOUND set done=2 ; OPEN _cur; FETCH _cur INTO _index; WHILE _index<>'' DO SET @str = CONCAT("drop index ",_index," on ",tablename ); PREPARE sql_str FROM @str ; EXECUTE sql_str; DEALLOCATE PREPARE sql_str; SET _index=''; FETCH _cur INTO _index; END WHILE; CLOSE _cur; END$$
2. Executing stored procedures
# View Index SELECT * FROM information_schema.STATISTICS ; # Call the stored procedure to delete the index of the tablename table in the dbname database CALL proc_drop_index("dbname","tablename");
2. Single table index usage and common index invalidation
The general query statement only involves the query of a single table. On the premise of realizing the purpose of query, there are many different choices for the creation of table index and the setting of filter conditions. How should we operate in detail? Notes and general suggestions for using indexing on a single table will be covered in this section.
2.1 Index Failure - Case
In single-table queries, there are several situations where the following indexes are not available. Using indexes makes it possible to avoid these situations as much as possible before implementing query requirements.
1. Index Full Value Matching
1) Cases:
The SQL statements that often appear in SQL queries are as follows:
EXPLAIN SELECT SQL_NO_CACHE \* FROM emp WHERE emp.age=30 ; EXPLAIN SELECT SQL_NO_CACHE \* FROM emp WHERE emp.age=30 and deptid=4; EXPLAIN SELECT SQL_NO_CACHE \* FROM emp WHERE emp.age=30 and deptid=4 AND emp.name = 'abcd' ;
2) Analysis
The three query statements of emp table are filtered by using age, deptid and name fields respectively. Indexing on these fields can be considered to improve query efficiency. However, there are many choices in the way of index creation and the setting of filter conditions.
At this point, how should the index be established?
3) Establishing Full Value Index
Full-valued index here refers to the establishment of a composite index for all filtered fields in a query, that is, an index contains multiple columns.
CREATE INDEX idx_age_deptid_name ON emp(age,deptid,NAME);
Before indexing:
After indexing:

4. Conclusion:
In the query, without considering the performance of addition and deletion, the query performance can be maximized by establishing an index for all fields in the filter condition. However, it should be noted that the query filtering conditions corresponding to full-valued index must satisfy some restrictive requirements.
2. The Best Left Prefix Rule
In the case of full-value index, if the sql that often appears in the system is as follows:
# 1. Establishing composite index on age, deptid and NAME CREATE INDEX idx_age_deptid_name ON emp(age,deptid,NAME); # 2. View the execution plans for the following two queries EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 AND emp.name = 'abcd' # perhaps EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.deptid=1 AND emp.name = 'abcd'
Note that the screening conditions:
- 1) Not using all index columns
- 2) The first index age is not used in the order of index columns.
Can the original full-value index: idx_age_deptid_name still work properly?
The answer is No. If multiple columns are indexed, the left-most prefix rule should be followed:
- Refers to a query that starts at the top left column of an index and does not skip columns in the index.
Case 1
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 AND emp.name = 'abcd'

1) As you can see from the key field, the full-value index idx_age_deptid_name is used.
2) Although the index can be used normally, only part of it is used:
- age filtering condition, but lack of deptid field filtering condition
- The key_len field value is only: 5, that is, only a single value index age is used.
Case 2
There is no age field in the query condition, resulting in the full-value index idx_age_deptid_name not being used.
Conclusion: Leftmost prefix rule
Filtering conditions to use the index must be in accordance with the order in which the index was built, and in turn meet. Once a field is skipped, the fields behind the index can not be used. (Note: Ordinary order can be disrupted, but not missing)
Question: How does full-value index work?
Similar to a layer-by-layer network, the target records are queried first by the upper age index, then by the lower depted index, and finally by the name index.
3. Don't do anything on index columns
Do not do any operations on the index column (calculation, function, automatic or manual) type conversion, otherwise the index will fail and turn to full table scan.
Which of the following two sql is better?
# 1. Establishing a single-valued index on NAME CREATE INDEX idx_name ON emp(NAME); # 2. View the execution plans for the following two queries EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.name LIKE 'abc%' EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE LEFT(emp.name,3) = 'abc'
The first is: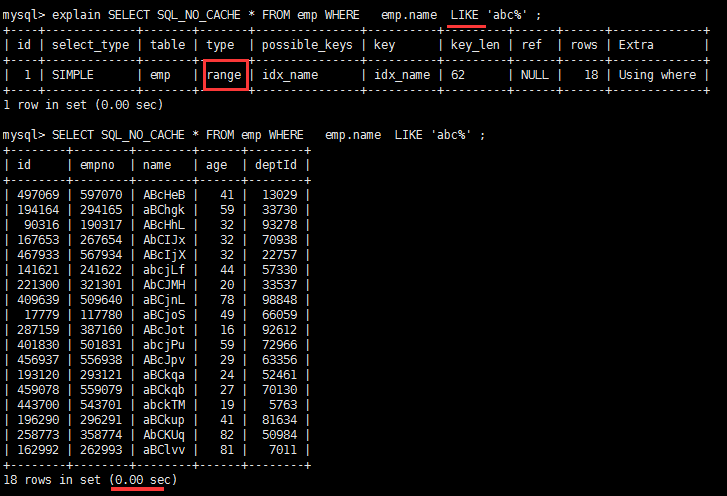
Use emp. name LIKE'abc%': The query type is range, using the index idx_name on the name field.
range query type:
- Retrieve only rows of a given range and use an index to select rows. The key column shows which index is used.
- In general, there are queries between,<,>, in and so on in your where statement.
- This range scan index scan is better than full table scan All because it only needs to start at one point of the index and end at another point without scanning all the indexes.
The second is:
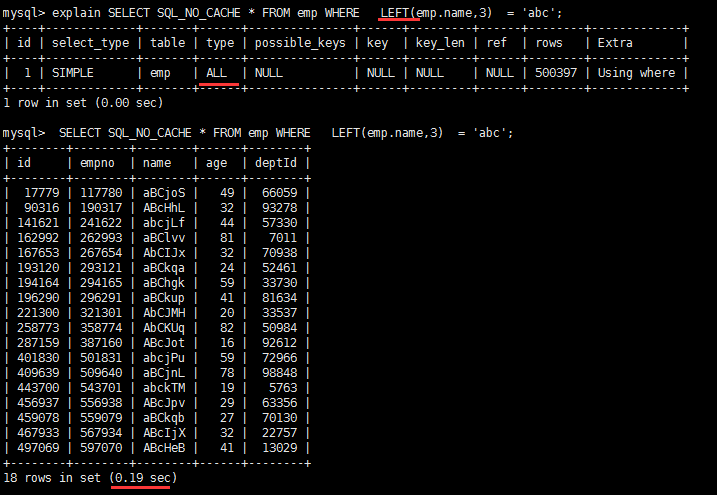
Use function to filter LEFT(emp.name,3) ='abc': The query type is ALL, that is, full table scan.
4. The storage engine cannot use the column on the right of the range condition in the index
1) If the sql that often appears in the system is as follows:
# 1. Establishing composite index on age, deptid and NAME CREATE INDEX idx_age_deptid_name ON emp(age,deptid,NAME); # 2. View the execution plan for the following queries EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 AND emp.deptId>20 AND emp.name = 'abc' ;
2) Is the index idx_age_deptid_name still working properly?

key_len is 10: Only the first two age and depted indexes are used, and the column of the string attribute name is not used. MySQL believes that it must check rows: 13534 when executing a query.
3) If such sql occurs more frequently, it should be established:
# Create composite index on age, NAME, depted create index idx_age_name_deptid on emp(age,name,deptid); # drop index idx_age_name_deptid on emp
4) Effect:
key_len is 72:age, NAME, depted. All three indexes are used. MySQL believes that it must check rows: 1 when executing a query.
5. Failure to use indexes when using MySQL is not equal to (!= or <>) results in full table scanning
Case:
CREATE INDEX idx_name ON emp(NAME) EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.name <> 'abc'
The implementation plan is as follows: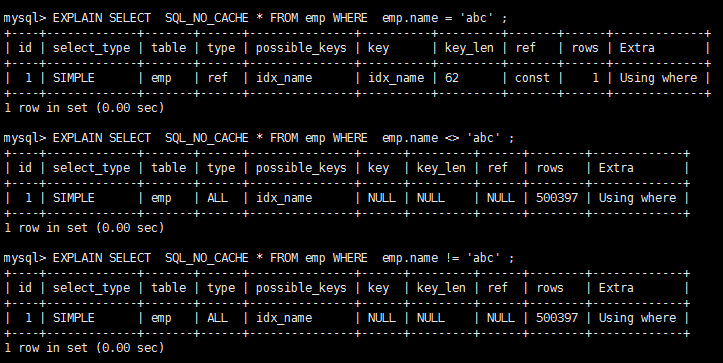
As you can see, when unequal sign is used, the index will fail and full table scan will be used.
6.is not null can not use index, but is null can use index.
Which of the following sql statements can be used for indexing:
UPDATE emp SET age =NULL WHERE id=123456; EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE age IS NULL; EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE age IS NOT NULL;
The implementation plan is as follows: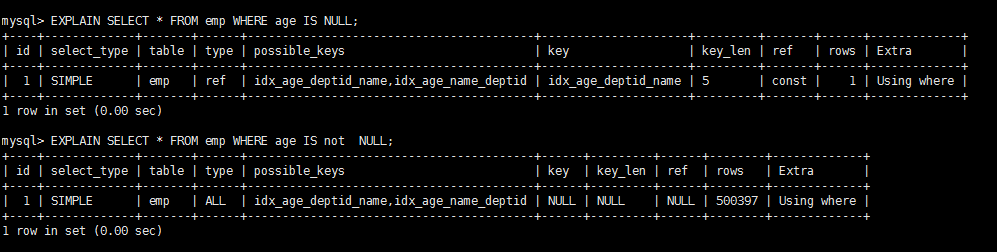
7.Like begins with wildcards and underscores ('% abc...' '_abc...' ) The mysql index fails and becomes a full table scan operation
Direct picture above: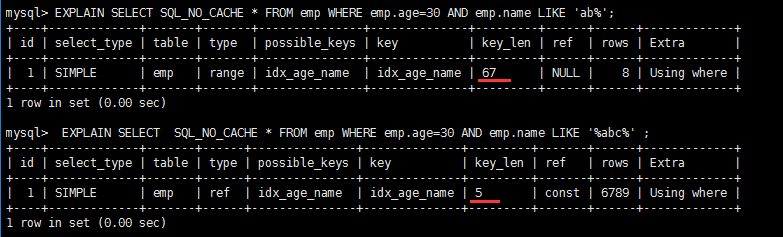
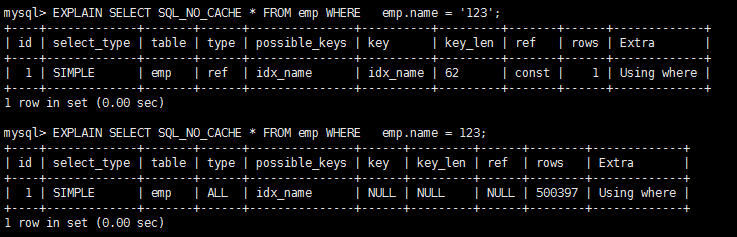
8. String index failure without single quotation mark
Figure: 123 numeric type converts to string'123', which involves automatic type conversion and leads to index failure.
9. Index Failure Summary
Suppose there is a composite index: index(a,b,c)
| Where statement | Is Index Used (Y/N) |
|---|---|
| where a = 3 | Y, used to a |
| where a = 3 and b = 5 | Y, for a, b |
| where a = 3 and b = 5 and c = 4 | Y, for a,b,c |
| Where B = 3 or where b = 3 and c = 4 or where c = 4 | N |
| where a = 3 and c = 5 | Use a, but c can't, b interrupts |
| where a = 3 and b > 4 and c = 5 | When using a and b, c can't be used in scope, B is broken. |
| where a is null and b is not null | is null supports indexing, but is not null does not, so a can use indexing, but b cannot. |
| where a <> 3 | Can't use index |
| where abs(a) =3 | Can't use index |
| where a = 3 and b like 'kk%' and c = 4 | Y, for a,b,c |
| where a = 3 and b like '%kk' and c = 4 | Y, only use a |
| where a = 3 and b like '%kk%' and c = 4 | Y, only use a |
| where a = 3 and b like 'k%kk%' and c = 4 | Y, for a,b,c |
2.2 General Suggestions for Index Optimization of Single Table Queries
1) For single-key indexes, try to choose indexes that are more filterable for the current query:
- Without sorting and grouping, look at type,key,key_len,rows
- When grouping and sorting are available, look at Extra to see if additional sorting is used
2) When choosing composite index, the most filterable fields in Query are in the order of index fields, the better the position is: the leftmost prefix rule, such as id and age fields.
3) When choosing a composite index, try to select an index that can contain more fields in the where sentence of the current query: the full value matching of the index
4) When choosing a composite index, if a range query may occur in a field, try to put the field at the end of the index order.
5) When writing sql statements, try to avoid index invalidation