catalogue
Principles for creating indexes
Classification and creation of indexes
Create index by modifying table mode
Specify the index when creating the table
Create unique index by modifying table mode
Specify a unique index when creating a table
Specify the index when creating the table
Delete index by modifying table mode
ACID characteristics of transactions
MySQL transaction isolation level (four types)
Query global transaction isolation level
Query session transaction isolation level
Set global transaction isolation level
Set session transaction isolation level
Control transactions using set settings
Concept of index
Database index
1. Is a sorted list that stores the physical address corresponding to the value of the index value
2. Without scanning the whole table, the required data can be found through the physical address
3. Is a method of sorting the values of one or more columns in a table
4. Additional disk space required
5. An index is like a book's table of contents. You can quickly find the required content according to the page numbers in the table of contents
Function of index
1. After setting the appropriate index, the database can greatly speed up the query speed by using various fast positioning technologies, which is the main reason for creating the index.
2. When the table is large or the query involves multiple tables, using indexes can improve the query speed thousands of times.
3. It can reduce the IO cost of the database, and the index can also reduce the sorting cost of the database.
4. By creating a unique (key) index, you can ensure the uniqueness of each row of data in the data table.
5. You can speed up the connection between tables.
6. When using grouping and sorting, the time of grouping and sorting can be greatly reduced.
Side effects of indexing
1. Indexing requires additional disk space.
For MyISAM engine, index file and data file are separated, and index file is used to save the address of data record. The table data file of InnoDB engine itself is an index file.
2. It takes more time to insert and modify data because the index changes with it.
Principles for creating indexes
Although index can improve the speed of database query, it is not suitable to create index in any case. Because the index itself will consume system resources, when there is an index, the database will first query the index and then locate the specific data row. If the index is not used properly, it will increase the burden of the database.
1. The primary key and foreign key of a table must have an index. Because the primary key is unique, the foreign key is associated with the primary key of the child table, which can be quickly located during query
2. Tables with more than 300 rows of records should have indexes. If there is no index, you need to traverse the table, which will seriously affect the performance of the database.
3. For tables that often connect with other tables, an index should be established on the connection field.
4. Fields with poor uniqueness are not suitable for indexing.
5. Fields that are updated too frequently are not suitable for index creation.
6. The fields that often appear in the where clause, especially the fields of large tables, should be indexed.
7. Indexes should be built on highly selective fields.
8. The index should be built on small fields. For large text fields or even super long fields, do not build an index.
Which fields / scenarios of MySQL optimization are suitable for index creation and which are not
Classification and creation of indexes
First create a database template
(root@localhost) [(none)]> create database xb;
(root@localhost) [(none)]> use xb
Database changed
(root@localhost) [xb]> create table school_db (id int,name varchar(10),phone varchar(11),address varchar(50),remark text);
(root@localhost) [xb]> desc school_db
-> ;
+---------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(10) | YES | | NULL | |
| phone | varchar(11) | YES | | NULL | |
| address | varchar(50) | YES | | NULL | |
| remark | text | YES | | NULL | |
+---------+-------------+------+-----+---------+-------+
Add some data to the table
(root@localhost) [xb]> insert into school_db values (2,'Zhang Sanfeng','138****8008','Jiangsu','love you'); Query OK, 1 row affected (0.00 sec) (root@localhost) [xb]> insert into school_db values (3,'Zhang Min','159****9078','Shanxi','love you'); Query OK, 1 row affected (0.00 sec) (root@localhost) [xb]> insert into school_db values (4,'Zhou Zhiruo','179****6284','Wuhan','love you'); Query OK, 1 row affected (0.00 sec) (root@localhost) [xb]> select * from school_db; +------+-----------+-------------+---------+----------+ | id | name | phone | address | remark | +------+-----------+-------------+---------+----------+ | 1 | zhang wuji | 138****9788 | Jiangsu | love you | | 2 | Zhang Sanfeng | 138****8008 | Jiangsu | love you | | 3 | Zhang Min | 159****9078 | Shanxi | love you | | 4 | Zhou Zhiruo | 179****6284 | Wuhan | love you | +------+-----------+-------------+---------+----------+
General index
The most basic index type has no restrictions such as uniqueness
Create index directly
CREATE INDEX index name ON table name (column name [(length)]);
(column name (length)): length is optional. If the value of length is ignored, the value of the entire column is used as the index. If you specify to use the length characters before the column to create the index, it is helpful to reduce the size of the index file.
It is recommended that index names end with "_index".
Create index
(root@localhost) [xb]> create index phone_index on school_db(phone); (root@localhost) [xb]> select phone from school_db; +-------------+ | phone | +-------------+ | 138****8008 | | 138****9788 | | 159****9078 | | 179****6284 | +-------------+
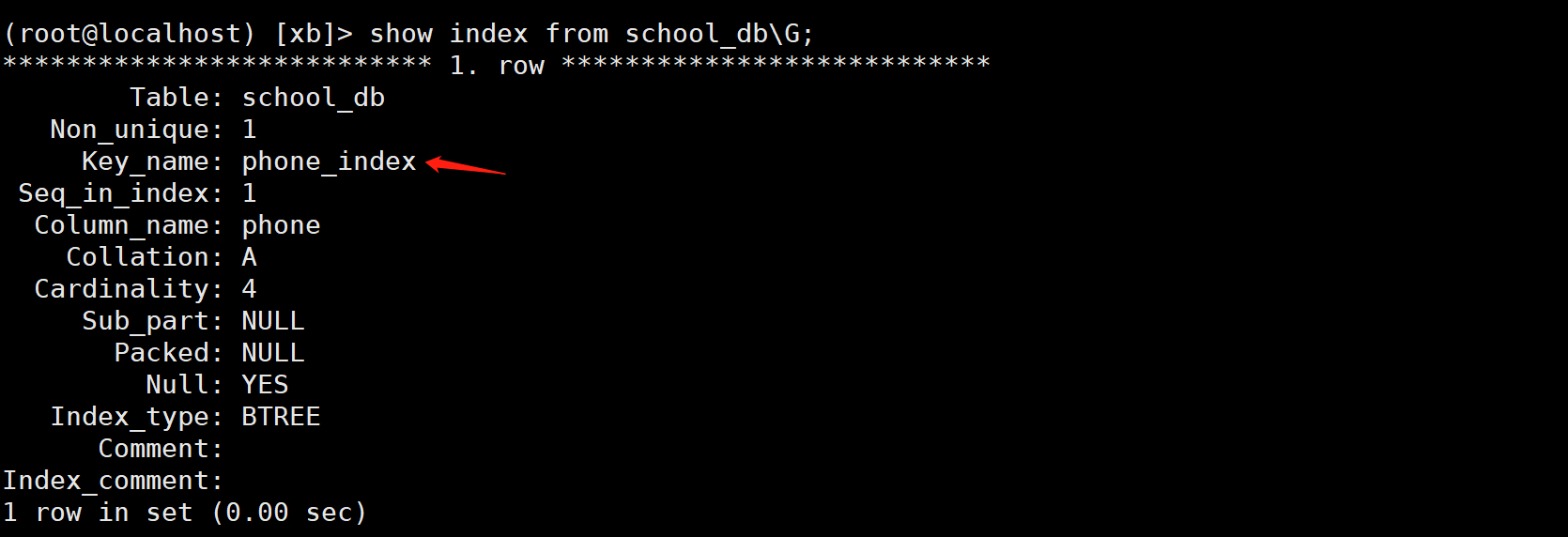
View index
(root@localhost) [xb]> show index from school_db\G;
Create index by modifying table mode
ALTER TABLE Table name ADD INDEX Index name (Listing);
Create index
(root@localhost) [xb]> alter table school_db add index id_index(id);
(root@localhost) [xb]> select id,name from school_db; +------+-----------+ | id | name | +------+-----------+ | 1 | zhang wuji | | 2 | Zhang Sanfeng | | 3 | Zhang Min | | 4 | Zhou Zhiruo | +------+-----------+ 4 rows in set (0.00 sec)
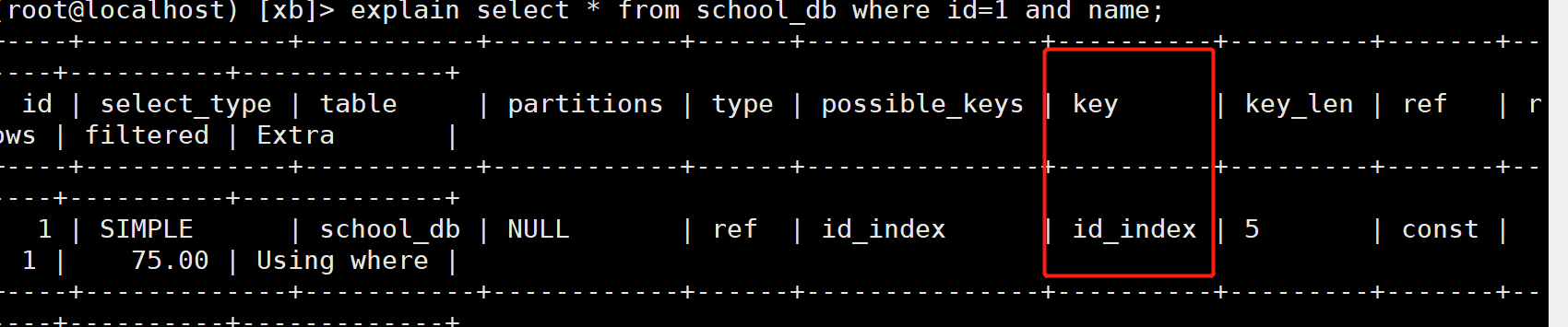
For details, see what we find id based on
(root@localhost) [xb]> explain select * from school_db where id=1;
Specify the index when creating the table
CREATE TABLE Table name ( Field 1 data type,Field 2 data type[,...],INDEX Index name (Listing));
unique index
It is similar to a normal index, but the difference is that each value of a unique index column is unique.
The unique index allows null values (note that it is different from the primary key). If you are creating with a composite index, the combination of column values must be unique. Adding a unique key automatically creates a unique index.
Create unique index directly
CREATE UNIQUE INDEX Index name ON Table name(Listing);
ps:
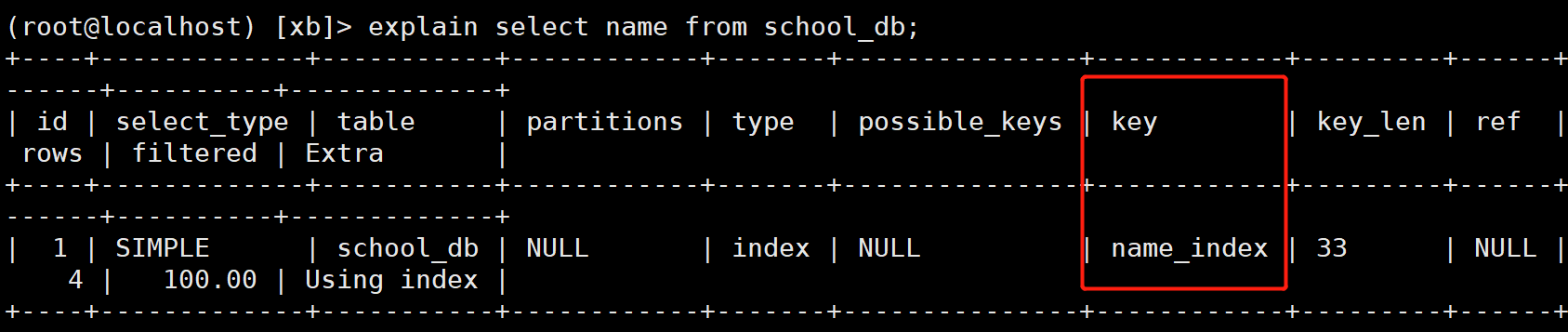
(root@localhost) [xb]> create unique index name_index on school_db(name);
Create unique index by modifying table mode
ALTER TABLE Table name ADD UNIQUE Index name (Listing);
Specify a unique index when creating a table
CREATE TABLE Table name (Field 1 data type,Field 2 data type[,...],UNIQUE Index name (Listing));
primary key
Is a special unique index and must be specified as "PRIMARY KEY".
A table can only have one primary key. Empty values are not allowed. Adding a primary key automatically creates a primary key index.
Specify when creating a table
CREATE TABLE Table name ([...],PRIMARY KEY (Listing));
Create by modifying the table
ALTER TABLE Table name ADD PRIMARY KEY (Listing);
Composite index
It can be an index created on a single column or an index created on multiple columns. The leftmost principle needs to be met. Because the where conditions of the select statement are executed from left to right, the field order used by the where conditions must be consistent with the sorting in the composite index when using the select statement for query, otherwise the index will not take effect.
format
CREATE TABLE Table name (Column name 1 data type,Column name 2 data type,Column name 3 data type,INDEX Index name (Column name 1,Column name 2,Column name 3)); select * from Table name where Column name 1='...' AND Column name 2='...' AND Column name 3='...';
Example
create table amd1 (id int not null,name varchar(20),cardid varchar(20),index index_amd (id,name)); Query OK, 0 rows affected (0.01 sec) (root@localhost) [xb]> show create table amd1;
Insert a piece of data
(root@localhost) [xb]> insert into amd1 values(1,'zhangsan','123123'); (root@localhost) [xb]> explain select * from amd1 where name='zhangsan' and id=1; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------+ | 1 | SIMPLE | amd1 | NULL | ref | index_amd | index_amd | 67 | const,const | 1 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------+
The order of fields created by a composite index is the order in which it triggers the query of the index
Full text index (FULLTEXT)
It is suitable for fuzzy query and can be used to retrieve text information in an article.
Before MySQL version 5.6, FULLTEXT index can only be used for MyISAM engine. After version 5.6, innodb engine also supports FULLTEXT index. Full TEXT indexes can be created on columns of type CHAR, VARCHAR, or TEXT. Only one full-TEXT index is allowed per table.
Create index directly
CREATE FULLTEXT INDEX Index name ON Table name (Listing);
Example
create fulltext index remark_index on school_db(remark);
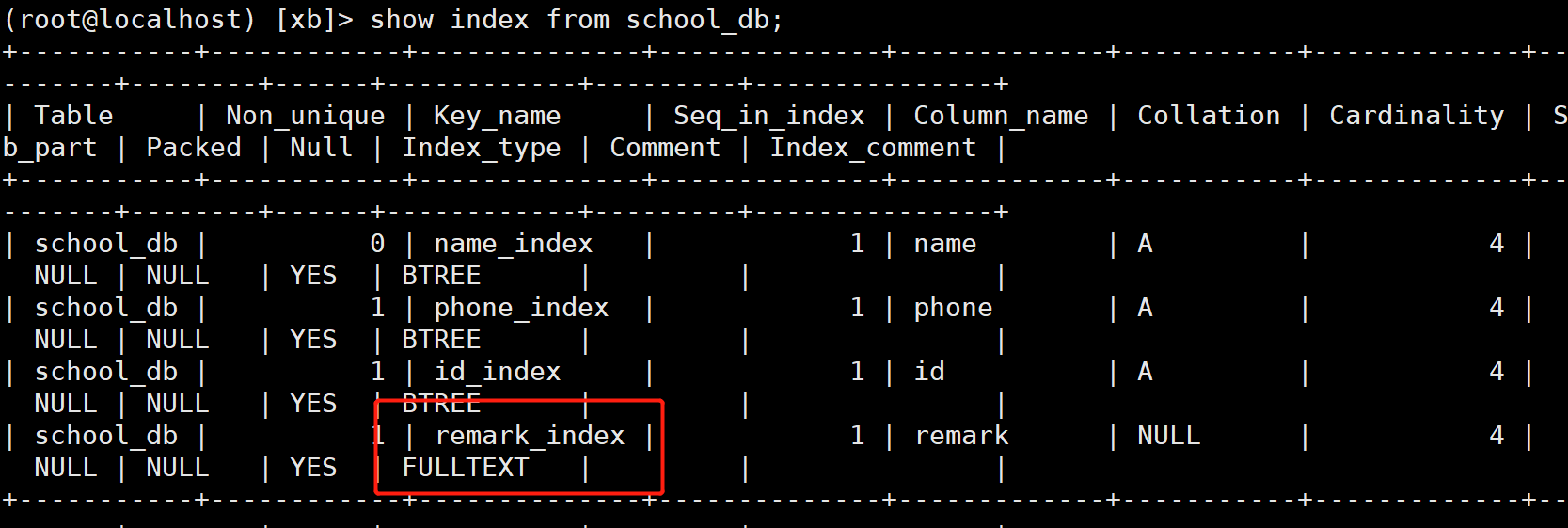
Modify table creation
ALTER TABLE Table name ADD FULLTEXT Index name (Listing);
Specify the index when creating the table
CREATE TABLE Table name (Field 1 data type[,...],FULLTEXT Index name (Listing));
Using full-text index queries
SELECT * FROM Table name WHERE MATCH(Listing) AGAINST('Query content');(root@localhost) [xb]> select * from school_db where match(remark) against('love you');
+------+-----------+-------------+---------+----------+
| id | name | phone | address | remark |
+------+-----------+-------------+---------+----------+
| 1 | zhang wuji | 138****9788 | Jiangsu | love you |
| 2 | Zhang Sanfeng | 138****8008 | Jiangsu | love you |
| 3 | Zhang Min | 159****9078 | Shanxi | love you |
| 4 | Zhou Zhiruo | 179****6284 | Wuhan | love you |
+------+-----------+-------------+---------+----------+
4 rows in set (0.00 sec)
(root@localhost) [xb]> explain select * from school_db where match(remark) against('love you');
+----+-------------+-----------+------------+----------+---------------+--------------+---------+-------+------+----------+-------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+----------+---------------+--------------+---------+-------+------+----------+-------------------------------+
| 1 | SIMPLE | school_db | NULL | fulltext | remark_index | remark_index | 0 | const | 1 | 100.00 | Using where; Ft_hints: sorted |
+----+-------------+-----------+------------+----------+---------------+--------------+---------+-------+------+----------+-------------------------------+
1 row in set, 1 warning (0.00 sec)
View index
show index from table name;
show index from table name \ G; Vertical display of table index information
show keys from table name;
show keys from table name \ G;
The meaning of each field is as follows:
Table Name of the table
Non_unique 0 if the index content is unique; 1 if it can not be unique.
Key_name The name of the index.
Seq_in_index Column ordinal in index, starting from 1. limit 2,3
Column_name Column name.
Collation How columns are stored in the index. In MySQL, there are values' A '(ascending) or NULL (no classification).
Cardinality An estimate of the number of unique values in the index.
Sub_part If the column is only partially indexed, the number of characters indexed (zhangsan). NULL if the entire column is indexed.
Packed Indicates how keywords are compressed. NULL if not compressed.
NULL If the column contains NULL, it contains YES. If not, the column contains NO.
Index_type Used indexing methods (BTREE, FULLTEXT, HASH, RTREE).
Comment remarks.
Delete index
Delete index directly
DROP INDEX Index name ON Table name;
Example:
(root@localhost) [xb]> drop index id_index on school_db; (root@localhost) [xb]> drop index phone_index on school_db;
Now there are only two indexes left
Delete index by modifying table mode
ALTER TABLE Table name DROP INDEX Index name;
Example:
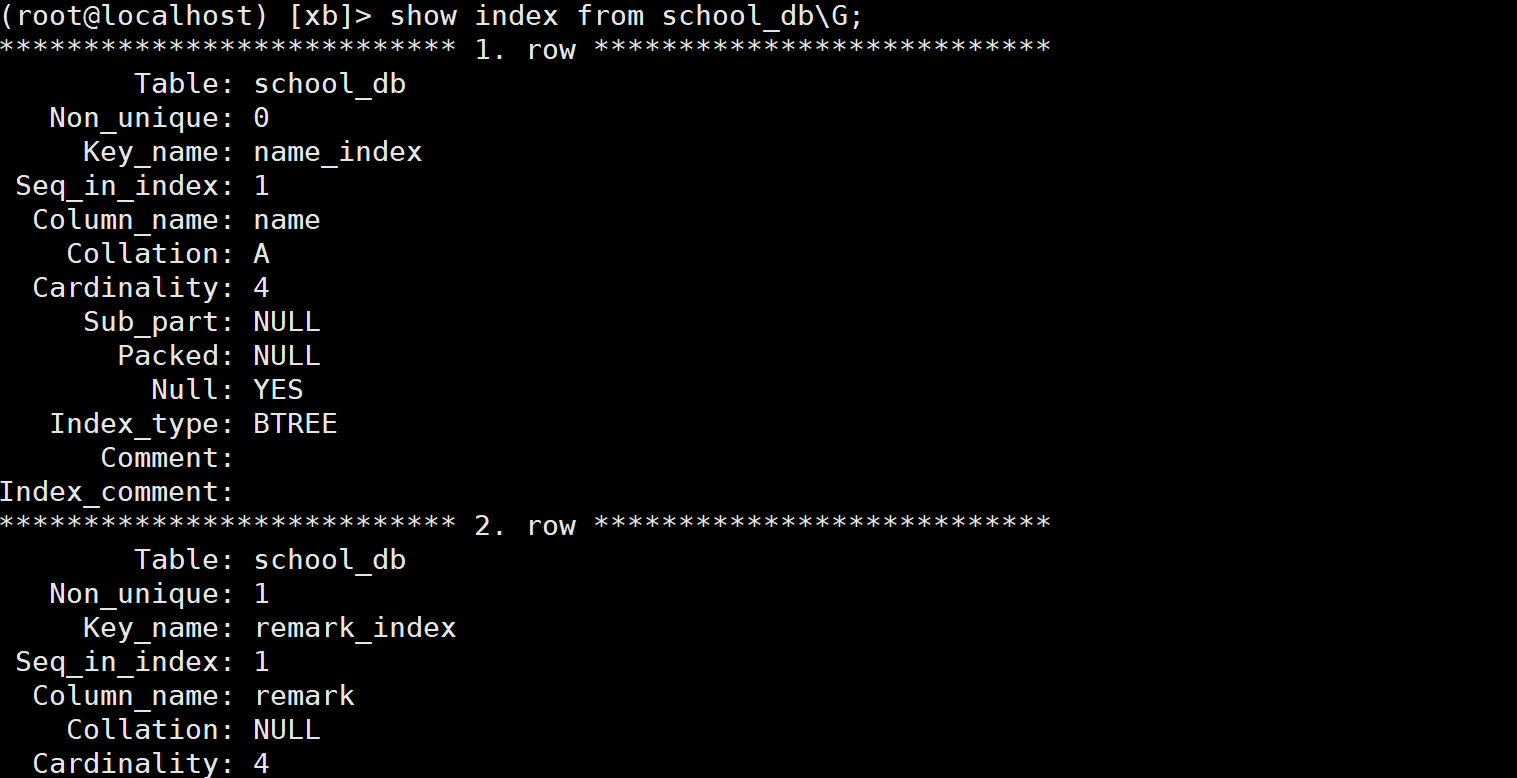
(root@localhost) [xb]> alter table school_db drop index name_index ;
(root@localhost) [xb]> show index from school_db\G;
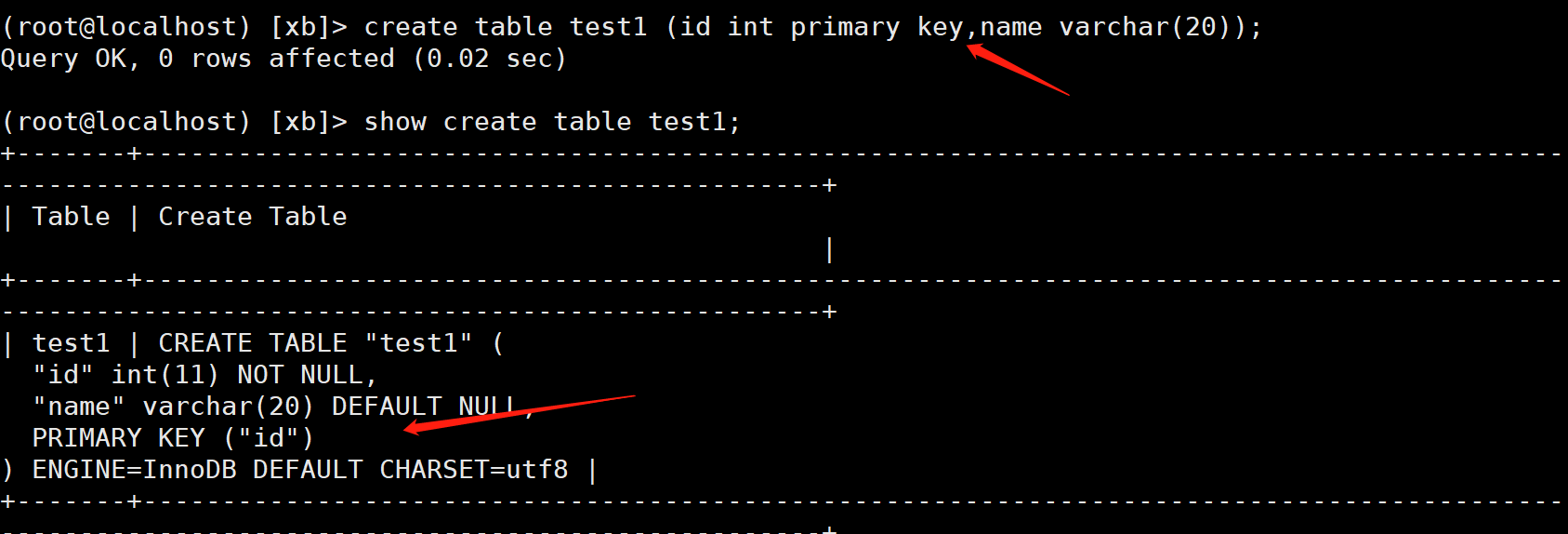
Delete primary key index
ALTER TABLE Table name DROP PRIMARY KEY;
Example:
(root@localhost) [xb]> alter table test1 drop primary key;
MySQL transaction
concept
MySQL transactions are mainly used to process data with large amount of operations and high complexity. For example, in the personnel management system, to delete a person, you need to delete both the basic data of the person and the information related to the person, such as mailbox, article, etc. In this way, these database operation statements constitute a transaction!
1. Transaction is a mechanism and an operation sequence, which contains a set of database operation commands, and all commands are submitted or revoked to the system as a whole, that is, this set of database commands are either executed or not executed.
2. Transaction is an inseparable work logic unit. When performing concurrent operations on the database system, transaction is the smallest control unit.
3. Transactions are applicable to the scenario of database systems operated by multiple users at the same time, such as banks, insurance companies and securities trading systems.
4. Transaction is to ensure data consistency through transaction integrity.
To put it bluntly, the so-called transaction is a sequence of operations. These operations are either executed or not executed. It is an inseparable work unit.
ACID characteristics of transactions
ACID refers to the four characteristics that a transaction should have in a reliable database management system (DBMS):
Atomicity
Consistency
Isolation
Durability
These are several characteristics of a reliable database.
Atomicity
A transaction is an inseparable work unit. Operations in a transaction either occur or do not occur.
1) A transaction is a complete operation, and the elements of a transaction are inseparable.
2) All elements in a transaction must be committed or rolled back as a whole.
3) If any element in the transaction fails, the entire transaction fails.
Case:
When A transfers 100 yuan to B, A only executes the deduction statement and submits it. At this time, if there is A sudden power failure, account A has been deducted, but account B has not received the increase,
Disputes will arise in life. In this case, transaction atomicity is required to ensure that transactions are either executed or not executed.
uniformity
It means that the integrity constraint of the database is not destroyed before the transaction starts and after the transaction ends.
1) When the transaction completes, the data must be in a consistent state.
2) Before the transaction starts, the data stored in the database is in a consistent state.
3) In an ongoing transaction, data may be in an inconsistent state.
4) When the transaction completes successfully, the data must return to the known consistent state again.
Case: for example, A has 1000 yuan, A transfers 100 yuan to B, A subtracts 100 yuan, and B adds 100 yuan, but the total amount of money remains the same
Isolation
In a concurrent environment, when different transactions manipulate the same data at the same time, each transaction has its own complete data space.
1) All concurrent transactions that modify data are isolated from each other, indicating that the transaction must be independent and should not depend on or affect other transactions in any way.
2) A transaction that modifies data can access the data before another transaction that uses the same data starts, or after another transaction that uses the same data ends.
The execution of one transaction cannot be disturbed by other transactions
The interaction between transactions can be divided into several types:
① . dirty reading (reading uncommitted data): dirty reading refers to reading uncommitted data from other transactions. Uncommitted means that these data may be rolled back,
That is, it may not be stored in the database, that is, non-existent data. The data that is read and must eventually exist is dirty reading
Case 1
For example, transaction B modifies data X during execution. Before committing, transaction A reads x, but transaction B rolls back, so transaction A forms A dirty read.
In other words, the data read by the current transaction is the data that other transactions want to modify but failed to modify.
② . non repeatable reading (read multiple times before and after, and the data content is inconsistent): two identical queries in a transaction return different data. This is caused by the submission of other transaction modifications in the system during query.
Case list
Transaction A obtains A row of record row1 for the first query. After transaction B commits the modification, transaction A obtains row1 for the second query, but the column content has changed.
select * from member;
1 zhangsan 20 points
select * from Member;
1 zhangsan 30 points
③ Phantom read (read several times before and after, and the total amount of data is inconsistent): a transaction modifies the data in a table, which involves all data rows in the table.
At the same time, another transaction also modifies the data in the table. This modification is to insert a new row of data into the table. Then, the user who operates the previous transaction will find that there are no modified data rows in the table,
It's like an illusion.
Case list
Suppose that transaction A has changed the contents of some rows but has not yet committed, then transaction B inserts the same record row as the record before transaction A changes, and commits it before transaction A commits,
At this time, when querying in transaction A, you will find that it seems that the changes just made have no effect on some data, but in fact transaction B has just been inserted, which makes the user feel very magical and illusion. This is called phantom reading
select * from member;
Six records were queried
alter table member change
select * from member;
10 records were queried (6 data were updated and 4 data were not updated)
④ Lost update: two transactions read the same record at the same time. A modifies the record first, and B also modifies the record (B does not know that a has modified it). After B submits the data, B's modification result overwrites a's modification result.
Case list
A 30 - > 40 transactions are completed first
B Complete after 30 - > 50 transactions
The transaction result of B will overwrite the transaction result of A, and the final value is 50
persistence
After the transaction is completed, the changes made by the transaction to the database will be permanently saved in the database and will not be rolled back.
It means that the result of transaction processing is permanent regardless of whether the system fails or not.
Once the transaction is committed, the effect of the transaction will be permanently retained in the database.
MySQL transaction isolation level (four types)
(1) Read uncommitted: read uncommitted data: dirty reads are not resolved
Dirty reading is allowed. As long as other transactions modify the data, even if it is not committed, this transaction can see the modified data value. That is, the number of uncommitted transaction modifications in other sessions may be read.
(2) Read committed: read committed data: dirty reads can be resolved
Only submitted data can be read. Most databases such as Oracle are at this level by default (no repeated reading).
(3) repeatable read: it can solve dirty reads and non repeatable reads - mysql default
Repeatable. No matter whether other transactions modify and commit data, the data values seen in this transaction are always unaffected by other transactions
(4) serializable: serialization: it can solve dirty reads, non repeatable reads and virtual reads - equivalent to locking tables
For fully serialized reads, table level shared locks need to be obtained for each read, and reads and writes will block each other.
The default transaction level of mysql is repeatable read, while Oracle and SQL Server are read committed.
//The scope of transaction isolation level is divided into two types:
Global level: valid for all sessions
Session level: | only valid for the current session
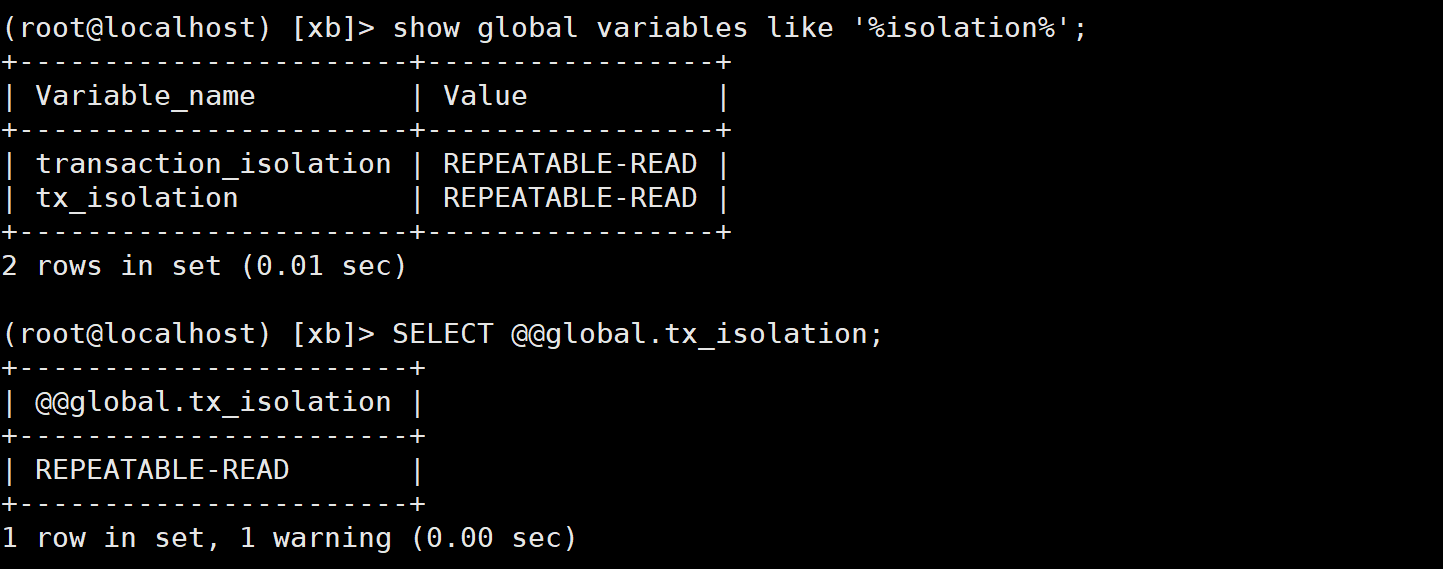
Query global transaction isolation level
show global variables like '%isolation%'; SELECT @@global.tx_isolation;
Query session transaction isolation level
show session variables like '%isolation%'; SELECT @@session.tx_isolation; SELECT @@tx_isolation;
Set global transaction isolation level
set global transaction isolation level read committed;
Set session transaction isolation level
set session transaction isolation level read committed;
Transaction control statement
BEGIN or START TRANSACTION: explicitly start a transaction.
COMMIT or COMMIT WORK: COMMIT the transaction and make all changes made to the database permanent.
ROLLBACK or ROLLBACK WORK: ROLLBACK will end the user's transaction and undo all uncommitted changes in progress.
SAVEPOINT S1: using SAVEPOINT allows you to create a rollback point in a transaction. There can be multiple savepoints in a transaction; "S1" stands for the rollback point name.
ROLLBACK TO [SAVEPOINT] S1: rollback the transaction to the marked point.
Test commit transaction
(root@localhost) [xb]> select * from school_db; #raw data +------+-----------+-------------+---------+----------+-------+ | id | name | phone | address | remark | money | +------+-----------+-------------+---------+----------+-------+ | 1 | zhang wuji | 138****9788 | Jiangsu | love you | 50 | | 2 | Zhang Sanfeng | 138****8008 | Jiangsu | love you | 100 | | 3 | Zhang Min | 159****9078 | Shanxi | love you | 100 | | 4 | Zhou Zhiruo | 179****6284 | Wuhan | love you | 100 | +------+-----------+-------------+---------+----------+-------+ 4 rows in set (0.00 sec) (root@localhost) [xb]> begin; #Start transaction Query OK, 0 rows affected (0.00 sec) (root@localhost) [xb]> update school_db set money=money+100 where name='zhang wuji'; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 (root@localhost) [xb]> select * from school_db; #Data after transaction +------+-----------+-------------+---------+----------+-------+ | id | name | phone | address | remark | money | +------+-----------+-------------+---------+----------+-------+ | 1 | zhang wuji | 138****9788 | Jiangsu | love you | 150 | | 2 | Zhang Sanfeng | 138****8008 | Jiangsu | love you | 100 | | 3 | Zhang Min | 159****9078 | Shanxi | love you | 100 | | 4 | Zhou Zhiruo | 179****6284 | Wuhan | love you | 100 | +------+-----------+-------------+---------+----------+-------+ 4 rows in set (0.00 sec) (root@localhost) [xb]> commit; #Commit transaction Query OK, 0 rows affected (0.00 sec)
Exit and re-enter

Look at the data again, there is no change
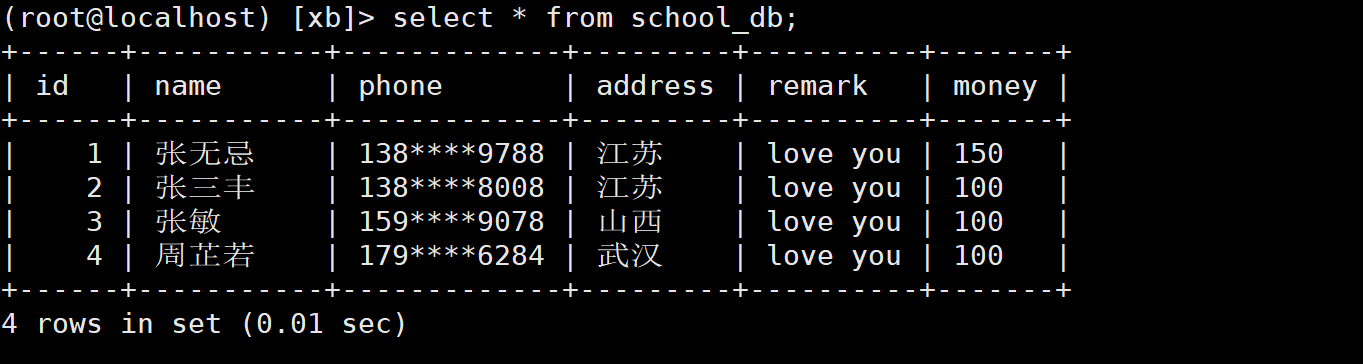
Test rollback transaction
(root@localhost) [xb]> begin; Query OK, 0 rows affected (0.00 sec) (root@localhost) [xb]> update school_db set money=money+100 where name='Zhang Min'; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 (root@localhost) [xb]> savapoint s1; #Rollback point 1 ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'savapoint s1' at line 1 (root@localhost) [xb]> select * from school_db; +------+-----------+-------------+---------+----------+-------+ | id | name | phone | address | remark | money | +------+-----------+-------------+---------+----------+-------+ | 1 | zhang wuji | 138****9788 | Jiangsu | love you | 150 | | 2 | Zhang Sanfeng | 138****8008 | Jiangsu | love you | 100 | | 3 | Zhang Min | 159****9078 | Shanxi | love you | 200 | | 4 | Zhou Zhiruo | 179****6284 | Wuhan | love you | 100 | +------+-----------+-------------+---------+----------+-------+ 4 rows in set (0.00 sec) (root@localhost) [xb]> SAVEPOINT S1; Query OK, 0 rows affected (0.00 sec) (root@localhost) [xb]> update school_db set money=money-70 where name='Zhou Zhiruo'; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 (root@localhost) [xb]> savepoint s2; #Rollback point 2 Query OK, 0 rows affected (0.00 sec) (root@localhost) [xb]> select * from schoo_db; ERROR 1146 (42S02): Table 'xb.schoo_db' doesn't exist (root@localhost) [xb]> select * from school_db; +------+-----------+-------------+---------+----------+-------+ | id | name | phone | address | remark | money | +------+-----------+-------------+---------+----------+-------+ | 1 | zhang wuji | 138****9788 | Jiangsu | love you | 150 | | 2 | Zhang Sanfeng | 138****8008 | Jiangsu | love you | 100 | | 3 | Zhang Min | 159****9078 | Shanxi | love you | 200 | | 4 | Zhou Zhiruo | 179****6284 | Wuhan | love you | 30 | +------+-----------+-------------+---------+----------+-------+ 4 rows in set (0.00 sec) (root@localhost) [xb]> insert into school_db values(5,'Asso','124****1326','Ionia','The wind also has a way home',500); Query OK, 1 row affected (0.00 sec) (root@localhost) [xb]> savepoint s3; #Rollback point 3 Query OK, 0 rows affected (0.00 sec) (root@localhost) [xb]> select * from school_db; +------+-----------+-------------+--------------+-----------------+-------+ | id | name | phone | address | remark | money | +------+-----------+-------------+--------------+-----------------+-------+ | 1 | zhang wuji | 138****9788 | Jiangsu | love you | 150 | | 2 | Zhang Sanfeng | 138****8008 | Jiangsu | love you | 100 | | 3 | Zhang Min | 159****9078 | Shanxi | love you | 200 | | 4 | Zhou Zhiruo | 179****6284 | Wuhan | love you | 30 | | 5 | Asso | 124****1326 | Ionia | The wind also has a way home | 500 | +------+-----------+-------------+--------------+-----------------+-------+ 5 rows in set (0.00 sec)
Back to rollback point 1
(root@localhost) [xb]> rollback to savepoint s1; Query OK, 0 rows affected (0.00 sec) (root@localhost) [xb]> select * from school_db; +------+-----------+-------------+---------+----------+-------+ | id | name | phone | address | remark | money | +------+-----------+-------------+---------+----------+-------+ | 1 | zhang wuji | 138****9788 | Jiangsu | love you | 150 | | 2 | Zhang Sanfeng | 138****8008 | Jiangsu | love you | 100 | | 3 | Zhang Min | 159****9078 | Shanxi | love you | 200 | | 4 | Zhou Zhiruo | 179****6284 | Wuhan | love you | 100 | +------+-----------+-------------+---------+----------+-------+ 4 rows in set (0.00 sec)
Back to rollback point 2
(root@localhost) [xb]> rollback to savepoint s2; Query OK, 0 rows affected (0.00 sec) (root@localhost) [xb]> select * from school_db; +------+-----------+-------------+---------+----------+-------+ | id | name | phone | address | remark | money | +------+-----------+-------------+---------+----------+-------+ | 1 | zhang wuji | 138****9788 | Jiangsu | love you | 150 | | 2 | Zhang Sanfeng | 138****8008 | Jiangsu | love you | 100 | | 3 | Zhang Min | 159****9078 | Shanxi | love you | 200 | | 4 | Zhou Zhiruo | 179****6284 | Wuhan | love you | 30 | +------+-----------+-------------+---------+----------+-------+ 4 rows in set (0.00 sec)
Control transactions using set settings
SET AUTOCOMMIT=0; # Disable automatic submission
SET AUTOCOMMIT=1; # Enable automatic submission. Mysql defaults to 1
SHOW VARIABLES LIKE 'AUTOCOMMIT'; # View the autocommit value in Mysql
If Auto commit is not enabled, all mysql operations connected to the current session will be treated as a transaction until you enter rollback commit; The current transaction is over.
Before the end of the current transaction, the operation results of any current session cannot be read when a new mysql connection is made.
If Auto commit is enabled, mysql will treat each sql statement as a transaction, and then automatically commit.
Of course, whether it is turned on or not, begin; commit|rollback; Are independent affairs.
Example:
(root@localhost) [xb]> select * from school_db; +------+-----------+-------------+---------+----------+-------+ | id | name | phone | address | remark | money | +------+-----------+-------------+---------+----------+-------+ | 1 | zhang wuji | 138****9788 | Jiangsu | love you | 150 | | 2 | Zhang Sanfeng | 138****8008 | Jiangsu | love you | 100 | | 3 | Zhang Min | 159****9078 | Shanxi | love you | 100 | | 4 | Zhou Zhiruo | 179****6284 | Wuhan | love you | 100 | +------+-----------+-------------+---------+----------+-------+ 4 rows in set (0.00 sec) (root@localhost) [xb]> set autocommit=1; Query OK, 0 rows affected (0.00 sec) (root@localhost) [xb]> show values like 'autocommit'; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'values like 'autocommit'' at line 1 (root@localhost) [xb]> show variables like 'autocommit'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | autocommit | ON | +---------------+-------+ 1 row in set (0.00 sec) (root@localhost) [xb]> update school_db set money=money+50 where name='Zhang Min'; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 (root@localhost) [xb]> select * from school_db; +------+-----------+-------------+---------+----------+-------+ | id | name | phone | address | remark | money | +------+-----------+-------------+---------+----------+-------+ | 1 | zhang wuji | 138****9788 | Jiangsu | love you | 150 | | 2 | Zhang Sanfeng | 138****8008 | Jiangsu | love you | 100 | | 3 | Zhang Min | 159****9078 | Shanxi | love you | 150 | | 4 | Zhou Zhiruo | 179****6284 | Wuhan | love you | 100 | +------+-----------+-------------+---------+----------+-------+ 4 rows in set (0.00 sec)
Exit and re-enter to view
(root@localhost) [xb]> select * from school_db; +------+-----------+-------------+---------+----------+-------+ | id | name | phone | address | remark | money | +------+-----------+-------------+---------+----------+-------+ | 1 | zhang wuji | 138****9788 | Jiangsu | love you | 150 | | 2 | Zhang Sanfeng | 138****8008 | Jiangsu | love you | 100 | | 3 | Zhang Min | 159****9078 | Shanxi | love you | 150 | | 4 | Zhou Zhiruo | 179****6284 | Wuhan | love you | 100 | +------+-----------+-------------+---------+----------+-------+ 4 rows in set (0.00 sec)
Submitted successfully.
summary
Index: acceleration - "easy for client to obtain data (improve user experience) + reduce the pressure on mysql server
Index is a kind of MySQL optimization (consider from two directions: 1. Which fields / scenarios are suitable for index creation 2. Which fields / scenarios are not suitable)
Index type:
① General index
② Unique index
③ Primary key index
④ Composite index
⑤ Full text index
Transaction characteristics (ACID) several ways
Atomicity (as a whole, either all or none)
Consistency requires the integrity and consistency of data before and after a transaction
Isolation requires that multiple transactions do not depend on each other (4 impacts, 4 isolation levels)
Persistence will be permanently saved after the transaction is committed and cannot be rolled back
Data inconsistency (four types)
(1) Read uncommitted: read uncommitted data: dirty reads are not resolved
Dirty reading is allowed. As long as other transactions modify the data, this transaction can see the modified data value even if it is not committed. That is, it is possible to read the modified data of uncommitted transactions in other sessions.
(2) Read committed: read committed data: dirty reads can be resolved
Only submitted data can be read. Most databases such as Oracle are at this level by default (no repeated reading).
(3) repeatable read: it can solve dirty reads and non repeatable reads - mysql default
Repeatable. Data values seen in this transaction are always unaffected by other transactions, regardless of whether other transactions modify and commit data
(4) serializable: serialization: it can solve dirty reads, non repeatable reads and virtual reads - equivalent to locking tables
For fully serialized reads, table level shared locks need to be obtained for each read, and reads and writes will block each other.