introduction
Recently, the little ape needs to be on the project according to the requirements of the leaders. The database needs to realize master-slave replication. The necessity and principle of master-slave replication of the database are not explained too much in this paper. Interested children's shoes can refer to some articles on the Internet. The little ape will launch this paper for the whole master-slave replication process.
Master slave replication architecture
Asynchronous backup
MySQL replication by default is asynchronous. The source writes events to its binary log and replicas request them when they are ready. The source does not know whether or when a replica has retrieved and processed the transactions, and there is no guarantee that any event ever reaches any replica. With asynchronous replication, if the source crashes, transactions that it has committed might not have been transmitted to any replica. Failover from source to replica in this case might result in failover to a server that is missing transactions relative to the source.
Synchronous backup
With fully synchronous replication, when a source commits a transaction, all replicas have also committed the transaction before the source returns to the session that performed the transaction. Fully synchronous replication means failover from the source to any replica is possible at any time. The drawback of fully synchronous replication is that there might be a lot of delay to complete a transaction.
Semi synchronous backup
Semisynchronous replication falls between asynchronous and fully synchronous replication. The source waits until at least one replica has received and logged the events (the required number of replicas is configurable), and then commits the transaction. The source does not wait for all replicas to acknowledge receipt, and it requires only an acknowledgement from the replicas, not that the events have been fully executed and committed on the replica side. Semisynchronous replication therefore guarantees that if the source crashes, all the transactions that it has committed have been transmitted to at least one replica.
Compared to asynchronous replication, semisynchronous replication provides improved data integrity, because when a commit returns successfully, it is known that the data exists in at least two places. Until a semisynchronous source receives acknowledgment from the required number of replicas, the transaction is on hold and not committed.
Compared to fully synchronous replication, semisynchronous replication is faster, because it can be configured to balance your requirements for data integrity (the number of replicas acknowledging receipt of the transaction) with the speed of commits, which are slower due to the need to wait for replicas.
more detail we can go the Semisynchronous Replication.
Master slave copy format
statement
When using statement-based binary logging, the source writes SQL statements to the binary log. Replication of the source to the replica works by executing the SQL statements on the replica. This is called statement-based replication (which can be abbreviated as SBR), which corresponds to the MySQL statement-based binary logging format.
rowbase
When using row-based logging, the source writes events to the binary log that indicate how individual table rows are changed. Replication of the source to the replica works by copying the events representing the changes to the table rows to the replica. This is called row-based replication (which can be abbreviated as RBR).
Row-based logging is the default method.
mixed
You can also configure MySQL to use a mix of both statement-based and row-based logging, depending on which is most appropriate for the change to be logged. This is called mixed-format logging. When using mixed-format logging, a statement-based log is used by default. Depending on certain statements, and also the storage engine being used, the log is automatically switched to row-based in particular cases. Replication using the mixed format is referred to as mixed-based replication or mixed-format replication.
environment
Main database: 172.16.101.40
From database: 172.16.101.41
mysql version: 5.7.30
System environment: CentOS 7 six
install
Installation can refer to the ape's Deployment practice of typical traditional projects (jdk, tomcat, mysql, nginx)
Master slave backup
Master database configuration and related operations
[mysqld] ... ... # Master slave copy settings #skip_slave_start, so that the replication process will not start with the start of the database #skip-slave-start # Enable the mysql binlog function server-id = 1 #Unique number of MySQL service. Each MySQL service Id must be unique log-bin = /usr/local/mysql/data/mysql-bin sync_binlog = 1 #The binlog of the control database is brushed to the disk. 0 is not controlled and the performance is the best. 1 is brushed to the log file every time the transaction is submitted. The performance is the worst and the safest binlog_format = mixed #binlog log format, mysql adopts statement by default, and mixed is recommended innodb_file_per_table=1 #Configure independent space for each table expire_logs_days = 7 #binlog expiration cleanup time max_binlog_size = 100m #binlog size of each log file binlog_cache_size = 4m #binlog cache size max_binlog_cache_size= 512m #Maximum binlog cache size binlog-ignore-db=mysql #For databases that do not generate log files, multiple ignored databases can be spliced with commas, or copy this sentence and write multiple lines auto-increment-offset = 1 # Offset from increment auto-increment-increment = 1 # Self increment of self increment slave-skip-errors = all #Skip from library error # binlog records the contents and records each line operated #binlog_format = ROW # For binlog_ When format = row mode, reduce the contents of the log and only record the affected columns #binlog_row_image = minimal
Main database key configuration description
server_id
Server configuration is required for master-slave replication_ id
- Each replica must have a unique server ID, as specified by the server_id system variable. If you are setting up multiple replicas, each one must have a unique server_id value that differs from that of the source and from any of the other replicas. If the replica's server ID is not already set, or the current value conflicts with the value that you have chosen for the source or another replica, you must change it.
log-bin

This file is the specified binlog log file
-
Specifies the base name to use for binary log files. With binary logging enabled, the server logs all statements that change data to the binary log, which is used for backup and replication. The binary log is a sequence of files with a base name and numeric extension. The --log-bin option value is the base name for the log sequence. The server creates binary log files in sequence by adding a numeric suffix to the base name.
-
If you do not supply the --log-bin option, MySQL uses binlog as the default base name for the binary log files. For compatibility with earlier releases, if you supply the --log-bin option with no string or with an empty string, the base name defaults to host_name-bin, using the name of the host machine.
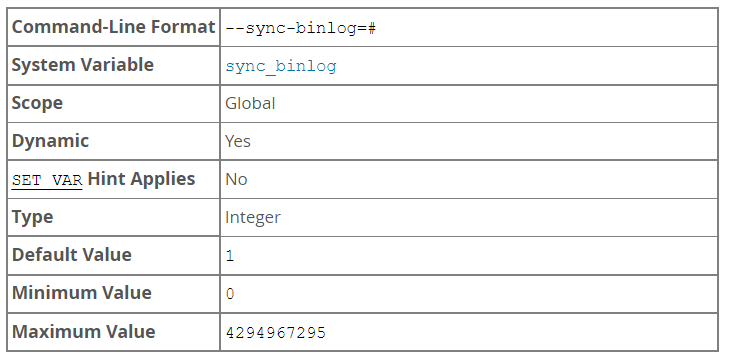
sync_binlog
-
Controls how often the MySQL server synchronizes the binary log to disk.
-
sync_binlog=0: Disables synchronization of the binary log to disk by the MySQL server. Instead, the MySQL server relies on the operating system to flush the binary log to disk from time to time as it does for any other file. This setting provides the best performance, but in the event of a power failure or operating system crash, it is possible that the server has committed transactions that have not been synchronized to the binary log.
-
sync_binlog=1: Enables synchronization of the binary log to disk before transactions are committed. This is the safest setting but can have a negative impact on performance due to the increased number of disk writes. In the event of a power failure or operating system crash, transactions that are missing from the binary log are only in a prepared state. This permits the automatic recovery routine to roll back the transactions, which guarantees that no transaction is lost from the binary log.
-
sync_binlog=N, where N is a value other than 0 or 1: The binary log is synchronized to disk after N binary log commit groups have been collected. In the event of a power failure or operating system crash, it is possible that the server has committed transactions that have not been flushed to the binary log. This setting can have a negative impact on performance due to the increased number of disk writes. A higher value improves performance, but with an increased risk of data loss.
innodb_file_per_table
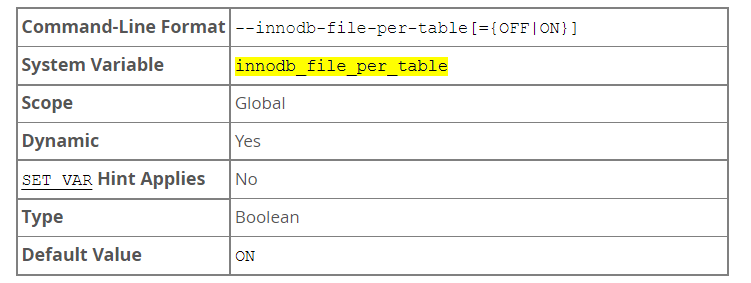
- When a table that resides in a file-per-table tablespace is truncated or dropped, the freed space is returned to the operating system. Truncating or dropping a table that resides in the system tablespace only frees space in the system tablespace. Freed space in the system tablespace can be used again for InnoDB data but is not returned to the operating system, as system tablespace data files never shrink.
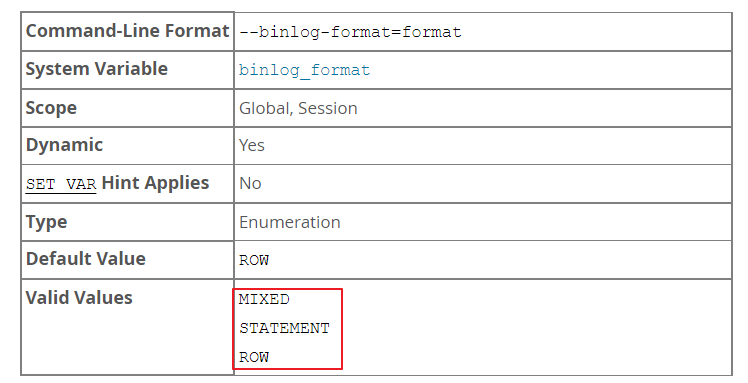
binlog-format
Log type
-
Replication works because events written to the binary log are read from the source and then processed on the replica. The events are recorded within the binary log in different formats according to the type of event. The different replication formats used correspond to the binary logging format used when the events were recorded in the source's binary log. The correlation between binary logging formats and the terms used during replication are:
-
When using statement-based binary logging, the source writes SQL statements to the binary log. Replication of the source to the replica works by executing the SQL statements on the replica. This is called statement-based replication (which can be abbreviated as SBR), which corresponds to the MySQL statement-based binary logging format.
-
When using row-based logging, the source writes events to the binary log that indicate how individual table rows are changed. Replication of the source to the replica works by copying the events representing the changes to the table rows to the replica. This is called row-based replication (which can be abbreviated as RBR).
-
Row-based logging is the default method.
-
You can also configure MySQL to use a mix of both statement-based and row-based logging, depending on which is most appropriate for the change to be logged. This is called mixed-format logging. When using mixed-format logging, a statement-based log is used by default. Depending on certain statements, and also the storage engine being used, the log is automatically switched to row-based in particular cases. Replication using the mixed format is referred to as mixed-based replication or mixed-format replication.
Advantages and disadvantages of each mode
Advantages of SBR:
- Mature technology
binlog file is small
binlog contains all database change information, which can be used to audit the security of the database
binlog can be used for real-time restore, not just for replication
The master-slave version can be different, and the slave server version can be higher than the master server version
Disadvantages of SBR:
- Not all UPDATE statements can be copied, especially when uncertain operations are included.
Replication can also be problematic when calling UDF s with uncertainties
Statements that use the following functions cannot also be copied: - LOAD_FILE()
- UUID()
- USER()
- FOUND_ROWS()
- SYSDATE() (unless the -- sysdate is now option is enabled at startup)
INSERT... SELECT generates more row level locks than RBR
When copying an UPDATE that requires a full table scan (no index is used in the WHERE statement), more row level locks are required than RBR requests
With auto_ For the InnoDB table of the increment field, the INSERT statement blocks other INSERT statements
For some complex statements, the resource consumption on the slave server will be more serious, while in RBR mode, it will only affect the changed record
When a stored function (not a stored procedure) is called, it will also execute the NOW() function. This can be said to be a bad thing or a good thing
The determined UDF also needs to be executed on the slave server
The data table must be almost consistent with the primary server, otherwise it may cause replication errors
Executing complex statements will consume more resources if there is an error
Advantages of RBR:
- Any situation can be replicated, which is the most secure and reliable for replication
The replication technology is the same as that of most other database systems
In most cases, if the table on the slave server has a primary key, the replication will be much faster
Fewer row locks when copying the following statements: - INSERT ... SELECT
- Include auto_ INSERT for the increment field
- UPDATE or DELETE statements that do not attach conditions or modify many records
Fewer locks when executing INSERT, UPDATE and DELETE statements
It is possible to use multithreading to perform replication from the server
Disadvantages of RBR:
- binlog is much larger
During complex rollback, binlog will contain a large amount of data
When the UPDATE statement is executed on the master server, all changed records will be written to the binlog, while the SBR will only be written once, which will lead to frequent concurrent writes to the binlog
Large BLOB values generated by UDF will slow down replication
You can't see what statements are copied and written from binlog
When executing a stacked SQL statement on a non transaction table, it is best to use SBR mode, otherwise it is easy to cause data inconsistency between the master and slave servers
expire-logs-days

- Specifies the number of days before automatic removal of binary log files. expire_logs_days is deprecated, and you should expect it to be removed in a future release. Instead, use binlog_expire_logs_seconds, which sets the binary log expiration period in seconds. If you do not set a value for either system variable, the default expiration period is 30 days. Possible removals happen at startup and when the binary log is flushed.
max_binlog_size

-
If a write to the binary log causes the current log file size to exceed the value of this variable, the server rotates the binary logs (closes the current file and opens the next one). The minimum value is 4096 bytes. The maximum and default value is 1GB. Encrypted binary log files have an additional 512-byte header, which is included in max_binlog_size.
-
A transaction is written in one chunk to the binary log, so it is never split between several binary logs. Therefore, if you have big transactions, you might see binary log files larger than max_binlog_size.
-
If max_relay_log_size is 0, the value of max_binlog_size applies to relay logs as well.
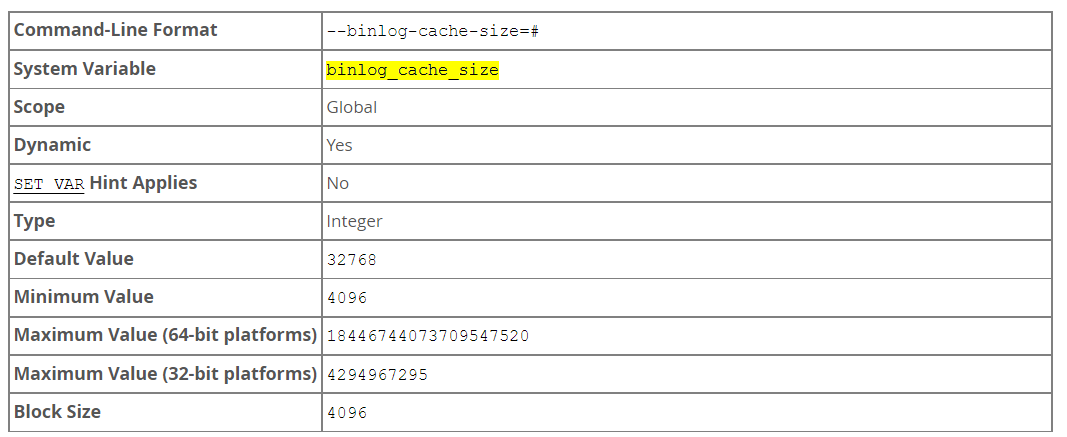
binlog_cache_size
-
The size of the memory buffer to hold changes to the binary log during a transaction. The value must be a multiple of 4096.
-
When binary logging is enabled on the server (with the log_bin system variable set to ON), a binary log cache is allocated for each client if the server supports any transactional storage engines. If the data for the transaction exceeds the space in the memory buffer, the excess data is stored in a temporary file. When binary log encryption is active on the server, the memory buffer is not encrypted, but (from MySQL 8.0.17) any temporary file used to hold the binary log cache is encrypted. After each transaction is committed, the binary log cache is reset by clearing the memory buffer and truncating the temporary file if used.
-
If you often use large transactions, you can increase this cache size to get better performance by reducing or eliminating the need to write to temporary files. The Binlog_cache_use and Binlog_cache_disk_use status variables can be useful for tuning the size of this variable. See Section 5.4.4, "The Binary Log".
-
binlog_cache_size sets the size for the transaction cache only; the size of the statement cache is governed by the binlog_stmt_cache_size system variable.
max_binlog_cache_size
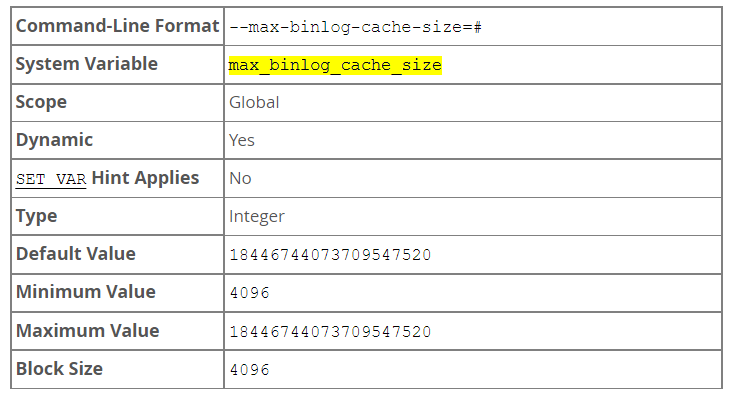
-
If a transaction requires more than this many bytes of memory, the server generates a Multi-statement transaction required more than 'max_binlog_cache_size' bytes of storage error. The minimum value is 4096. The maximum possible value is 16EiB (exbibytes). The maximum recommended value is 4GB; this is due to the fact that MySQL currently cannot work with binary log positions greater than 4GB. The value must be a multiple of 4096.
-
max_binlog_cache_size sets the size for the transaction cache only; the upper limit for the statement cache is governed by the max_binlog_stmt_cache_size system variable.
-
The visibility to sessions of max_binlog_cache_size matches that of the binlog_cache_size system variable; in other words, changing its value affects only new sessions that are started after the value is changed.
binlog-ignore-db

-
The effects of this option depend on whether the statement-based or row-based logging format is in use, in the same way that the effects of --replicate-ignore-db depend on whether statement-based or row-based replication is in use. You should keep in mind that the format used to log a given statement may not necessarily be the same as that indicated by the value of binlog_format. For example, DDL statements such as CREATE TABLE and ALTER TABLE are always logged as statements, without regard to the logging format in effect, so the following statement-based rules for --binlog-ignore-db always apply in determining whether or not the statement is logged.
-
Statement-based logging. Tells the server to not log any statement where the default database (that is, the one selected by USE) is db_name.
-
When there is no default database, no --binlog-ignore-db options are applied, and such statements are always logged. (Bug #11829838, Bug #60188)
-
Row-based format. Tells the server not to log updates to any tables in the database db_name. The current database has no effect.
-
When using statement-based logging, the following example does not work as you might expect. Suppose that the server is started with --binlog-ignore-db=sales and you issue the following statements:
auto_increment_offset&auto_increment_increment

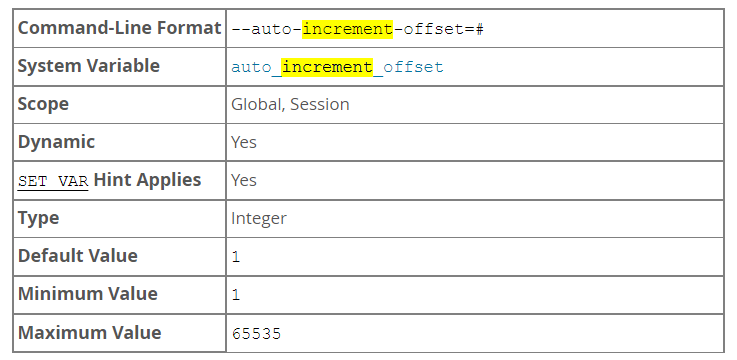
-
auto_increment_increment and auto_increment_offset are intended for use with circular (source-to-source) replication, and can be used to control the operation of AUTO_INCREMENT columns. Both variables have global and session values, and each can assume an integer value between 1 and 65,535 inclusive. Setting the value of either of these two variables to 0 causes its value to be set to 1 instead. Attempting to set the value of either of these two variables to an integer greater than 65,535 or less than 0 causes its value to be set to 65,535 instead. Attempting to set the value of auto_increment_increment or auto_increment_offset to a noninteger value produces an error, and the actual value of the variable remains unchanged.
-
auto_increment_offset determines the starting point for the AUTO_INCREMENT column value. Consider the following, assuming that these statements are executed during the same session as the example given in the description for auto_increment_increment:
View more configurations
More configurations can be viewed replication configuration of mysql.
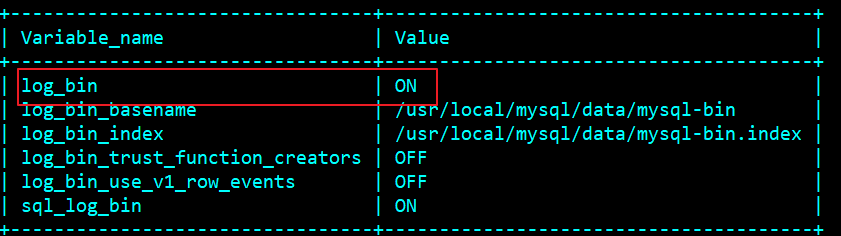
Restart the main database and check whether the binlog configuration is effective
service mysql restart
show variables like '%log_bin%';
show variables like '%server_id%';
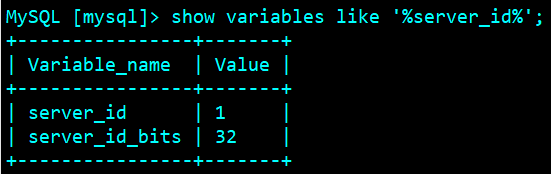
Whether other parameters are effective can also be queried by referring to the above method
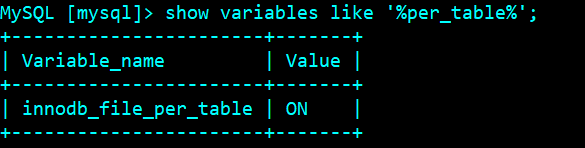
Create the required user from the node
grant replication slave on *.* to 'repl_user'@'172.16.101.%' identified by 'repl_user123456'; flush privileges;
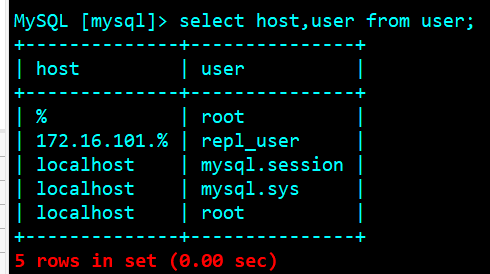
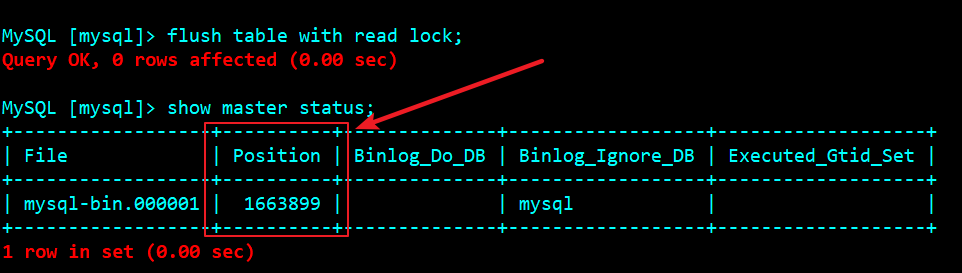
Master database lock table and backup
Lock table
flush table with read lock;
View backup location
show master status;
backups
Create backup folder for main library
mkdir -p /usr/local/mysql/server/backup
To prevent unexpected errors, you need to configure relevant permissions, which are omitted here
Execute backup command
#Backup and compress mysqldump -uroot -p -A -B |gzip >/usr/local/mysql/server/backup/mysql_bak.$(date +%F).sql.gz

If you have questions about the above parameters, you can refer to the following commands
mysqldump --help
Transfer backup files
#Copy to slave library with scp scp /usr/local/mysql/server/backup/mysql_bak.2022-02-13.sql.gz root@172.16.101.41:/root/

Unlock
unlock tables;
Slave library configuration and operation
Restore backup database
mysql -uroot -p < mysql_bak.2022-02-13.sql
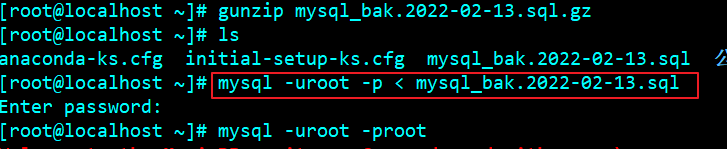
Configuration from library
my.cnf modification
[mysqld] ... ... server-id=2 relay-log = /usr/local/mysql/data/relay-log relay-log-index = /usr/local/mysql/data/relay-log.index sync_relay_log =1 sync_relay_log_info = 1 innodb_file_per_table=1 replicate-wild-ignore-table=mysql.% replicate-wild-ignore-table=test.% replicate-wild-ignore-table=information_schema.% #No cascading, no opening required #log-bin=/usr/local/mysql/data/mysql-bin #replicate-do-db =lgry-vue
Configure master library information
CHANGE MASTER TO MASTER_HOST = '172.16.101.40', MASTER_USER = 'repl_user', MASTER_PASSWORD = 'repl_user123456', MASTER_PORT = 28000, MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=1663899, MASTER_RETRY_COUNT = 60, MASTER_HEARTBEAT_PERIOD = 10000;
Enable slave Library Service
start slave;
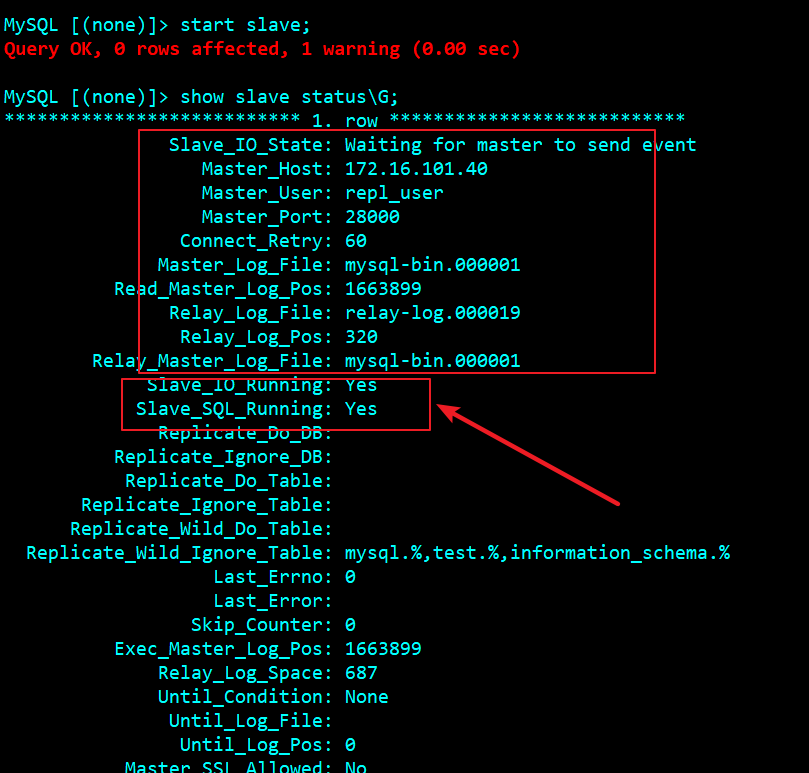
test
Initial state
Main library status
Slave library status

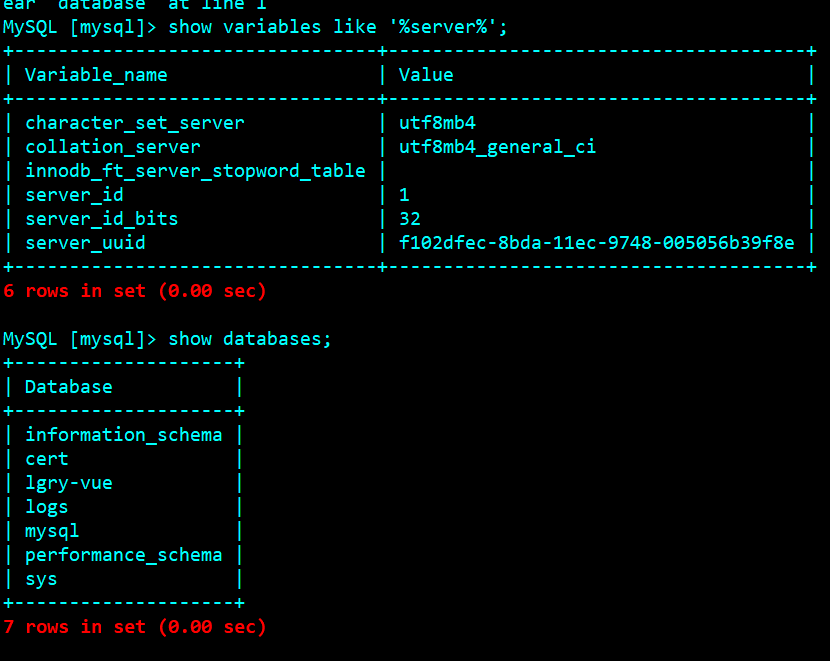
Establish test library from main library

View from library
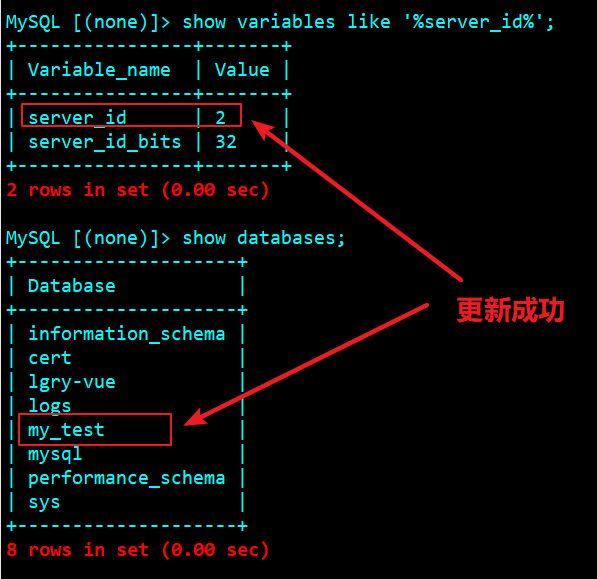
enclosure
For mysql production environment, the configuration file is the core, so ape will make a record of his configuration file in this project for future projects.
master profile
[client] # Client settings, that is, the default connection parameters of the client port = 28000 # Default connection port socket = /usr/local/mysql/data/mysql.sock # Socket socket for local connection. mysqld daemon generates this file default-character-set=utf8mb4 #set client security ssl transmition protocol ssl-ca=/usr/local/mysql/data/cert/ca.pem ssl-cert=/usr/local/mysql/data/cert/client-cert.pem ssl-key=/usr/local/mysql/data/cert/client-key.pem [mysql] socket=/usr/local/mysql/data/mysql.sock # set mysql client default chararter default-character-set=utf8mb4 [mysqldump] max_allowed_packet = 64M [mysqld_safe] open_files_limit = 8192 # You possibly have to adapt your O/S settings as well user = mysql log-error = /usr/local/mysql/logs/error.log [mysqld] # Basic settings of server # Basic settings #user = root #server-id = 1 # Unique number of MySQL service. Each MySQL service Id must be unique port = 28000 # MySQL listening port basedir = /usr/local/mysql # MySQL installation root directory datadir = /usr/local/mysql/data # Location of MySQL data file tmpdir = /usr/local/mysql/tmp # Temporary directories, such as load data infile, will be used log-error = /usr/local/mysql/logs/error.log # Database error log file slow_query_log_file = /usr/local/mysql/logs/slow_query.log # Slow query log file socket = /usr/local/mysql/data/mysql.sock # Specify a socket file for local communication between MySQL client program and server pid-file = /usr/local/mysql/data/localhost.pid # Directory of pid file skip_name_resolve = 1 # Only the IP address can be used to check the login of the client without using the host name character-set-server = utf8mb4 # The default character set of the database. The mainstream character set supports some special emoticons (special emoticons occupy 4 bytes) transaction_isolation = READ-COMMITTED # Transaction isolation level. The default is repeatable read. MySQL is repeatable read by default collation-server = utf8mb4_general_ci # The database character set corresponds to some sorting rules. Note that it corresponds to character set server #init_connect='SET NAMES utf8mb4' # Set the character set when the client connects to mysql to prevent garbled code lower_case_table_names = 1 # Whether it is sensitive to the case of sql statements. 1 means insensitive max_connections = 400 # maximum connection max_connect_errors = 1000 # Maximum number of wrong connections explicit_defaults_for_timestamp = true # TIMESTAMP if the declaration NOT NULL is not displayed, NULL value is allowed max_allowed_packet = 128M # The size of the SQL packet sent. If there is a BLOB object, it is recommended to modify it to 1G interactive_timeout = 1880000 # MySQL connection will be forcibly closed after it is idle for more than a certain time (unit: seconds) wait_timeout = 1880000 # MySQL default wait_ The timeout value is 8 hours, interactive_ The timeout parameter needs to be configured at the same time to take effect tmp_table_size = 16M # The maximum value of the internal memory temporary table is set to 128M; For example, a temporary table may be used when a large amount of data is group by and order by; If this value is exceeded, it will be written to the disk and the system IO pressure will increase max_heap_table_size = 128M # Defines the size of the memory table that users can create query_cache_size = 0 # Disable the function of caching query result set of mysql; In the later stage, test and decide whether to open it according to the business situation; In most cases, close the following two items query_cache_type = 0 ## Set sqlmode. By default, mysql5 All boards above 7.5 have sqlmode, while ONLY_FULL_GROUP_BY is the default. If it is not configured, there will be an error that the fields queried after select do not appear in group by #nested exception is java.sql.SQLSyntaxErrorException: Expression #2 of SELECT list is not in GROUP BY clause and # contains nonaggregated column 'wlhy_xysk.s.vehicle_license_no' which is not functionally dependent on columns in GROUP BY clause; sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION' #set mysql server ssl security transmition protocol ssl-ca=/usr/local/mysql/data/cert/ca.pem ssl-cert=/usr/local/mysql/data/cert/server-cert.pem ssl-key=/usr/local/mysql/data/cert/server-key.pem #Threads_created: the number of threads created, # 1G ---> 8 # 2G ---> 16 # 3G ---> 32 thread_cache_size = 8 # The memory setting allocated by the user process. Each session will allocate the memory size set by the parameter key_buffer_size = 256M #key_buffer_size specifies the size of the index buffer, which determines the speed of index processing read_buffer_size = 2M # MySQL read in buffer size. The request for sequential scanning of the table will allocate a read in buffer, and MySQL will allocate a memory buffer for it. read_rnd_buffer_size = 8M # Random read buffer size of MySQL sort_buffer_size = 8M # Buffer size used by MySQL to perform sorting binlog_cache_size = 1M # When a transaction is not committed, the generated log is recorded in the Cache; When the transaction needs to be committed, the log is persisted to disk. Default binlog_cache_size 32K back_log = 130 # How many requests can be stored in the stack in a short time before MySQL temporarily stops responding to new requests; Official recommendation back_log = 50 + (max_connections / 5), and the number of capping is 900 skip-external-locking #Skip external locks. If a polymorphic server wants to open the external locking feature, it can comment directly. If it is a single server, it can be opened directly #skip-grant-tables # log setting #log_error = /usr/local/mysql/data/logs/error.log # Database error log file slow_query_log = 1 # Slow query sql log settings long_query_time = 1 # Slow query time; If it exceeds 1 second, it is a slow query #slow_query_log_file = /usr/local/mysql/data/logs/slow_query.log # Slow query log file log_queries_not_using_indexes = 1 # Check sql that is not used to index log_throttle_queries_not_using_indexes = 5 # Used to indicate the number of SQL statements that are allowed to be recorded to the slow log and do not use the index per minute. The default value is 0, which means there is no limit min_examined_row_limit = 100 # The number of retrieved rows must reach this value before it can be recorded as a slow query. The SQL returned by the query check that is less than the row specified by this parameter will not be recorded in the slow query log expire_logs_days = 7 # The expiration time of MySQL binlog log files, which will be automatically deleted after expiration # Master slave copy settings #skip_slave_start, so that the replication process will not start with the start of the database skip-slave-start # Enable the mysql binlog function server-id = 1 #Unique number of MySQL service. Each MySQL service Id must be unique log-bin = /usr/local/mysql/data/mysql-bin sync_binlog = 1 #The binlog of the control database is brushed to the disk. 0 is not controlled and the performance is the best. 1 is brushed to the log file every time the transaction is submitted. The performance is the worst and the safest binlog_format = mixed #binlog log format, mysql adopts statement by default, and mixed is recommended innodb_file_per_table=1 #Configure independent space for each table expire_logs_days = 7 #binlog expiration cleanup time max_binlog_size = 100m #binlog size of each log file binlog_cache_size = 4m #binlog cache size max_binlog_cache_size= 512m #Maximum binlog cache size binlog-ignore-db=mysql #For databases that do not generate log files, multiple ignored databases can be spliced with commas, or copy this sentence and write multiple lines auto-increment-offset = 1 # Offset from increment auto-increment-increment = 1 # Self increment of self increment slave-skip-errors = all #Skip from library error # binlog records the contents and records each line operated #binlog_format = ROW # For binlog_ When format = row mode, reduce the contents of the log and only record the affected columns #binlog_row_image = minimal # Innodb settings innodb_open_files = 500 # Limit the data of the tables that Innodb can open. If there are too many tables in the library, please add this. This value defaults to 300 innodb_buffer_pool_size = 64M # InnoDB uses a buffer pool to store indexes and original data, generally 60% - 70% of the physical storage; The larger you set here, the less disk I/O you need to access the data in the table innodb_log_buffer_size = 2M # This parameter determines the amount of memory used to write log files, in M. Larger buffers can improve performance, but unexpected failures will lose data. MySQL developers recommend setting it between 1 and 8M innodb_flush_method = O_DIRECT # O_DIRECT reduces conflicts between the operating system level VFS cache and Innodb's own buffer cache innodb_write_io_threads = 2 # The CPU multi-core processing capacity setting is adjusted according to the reading and writing ratio. The best number of cores is the number of CPUs innodb_read_io_threads = 2 innodb_lock_wait_timeout = 120 # The number of timeout seconds that InnoDB transactions can wait for a lock before being rolled back. InnoDB automatically detects transaction deadlocks in its own lock table and rolls back transactions. InnoDB noticed the lock settings with the LOCK TABLES statement. The default value is 50 seconds innodb_log_file_size = 32M # This parameter determines the size of the data log file. A larger setting can improve performance, but it will also increase the time required to recover the failed database
slave profile
[client] # Client settings, that is, the default connection parameters of the client port = 28000 # Default connection port socket = /usr/local/mysql/data/mysql.sock # Socket socket for local connection. mysqld daemon generates this file default-character-set=utf8mb4 #set client security ssl transmition protocol ssl-ca=/usr/local/mysql/data/cert/ca.pem ssl-cert=/usr/local/mysql/data/cert/client-cert.pem ssl-key=/usr/local/mysql/data/cert/client-key.pem [mysql] socket=/usr/local/mysql/data/mysql.sock # set mysql client default chararter default-character-set=utf8mb4 [mysqldump] max_allowed_packet = 64M [mysqld_safe] open_files_limit = 8192 # You possibly have to adapt your O/S settings as well user = mysql log-error = /usr/local/mysql/logs/error.log [mysqld] # Basic settings of server # Basic settings #user = root #server-id = 1 # Unique number of MySQL service. Each MySQL service Id must be unique port = 28000 # MySQL listening port basedir = /usr/local/mysql # MySQL installation root directory datadir = /usr/local/mysql/data # Location of MySQL data file tmpdir = /usr/local/mysql/tmp # Temporary directories, such as load data infile, will be used socket = /usr/local/mysql/data/mysql.sock # Specify a socket file for local communication between MySQL client program and server pid-file = /usr/local/mysql/data/localhost.pid # Directory of pid file skip_name_resolve = 1 # Only the IP address can be used to check the login of the client without using the host name character-set-server = utf8mb4 # The default character set of the database. The mainstream character set supports some special emoticons (special emoticons occupy 4 bytes) transaction_isolation = READ-COMMITTED # Transaction isolation level. The default is repeatable read. MySQL is repeatable read by default collation-server = utf8mb4_general_ci # The database character set corresponds to some sorting rules. Note that it corresponds to character set server #init_connect='SET NAMES utf8mb4' # Set the character set when the client connects to mysql to prevent garbled code lower_case_table_names = 1 # Whether it is sensitive to the case of sql statements. 1 means insensitive max_connections = 400 # maximum connection max_connect_errors = 1000 # Maximum number of wrong connections explicit_defaults_for_timestamp = true # TIMESTAMP if the declaration NOT NULL is not displayed, NULL value is allowed max_allowed_packet = 128M # The size of the SQL packet sent. If there is a BLOB object, it is recommended to modify it to 1G interactive_timeout = 1880000 # MySQL connection will be forcibly closed after it is idle for more than a certain time (unit: seconds) wait_timeout = 1880000 # MySQL default wait_ The timeout value is 8 hours, interactive_ The timeout parameter needs to be configured at the same time to take effect tmp_table_size = 16M # The maximum value of the internal memory temporary table is set to 128M; For example, a temporary table may be used when a large amount of data is group by and order by; If this value is exceeded, it will be written to the disk and the system IO pressure will increase max_heap_table_size = 128M # Defines the size of the memory table that users can create query_cache_size = 0 # Disable the function of caching query result set of mysql; In the later stage, test and decide whether to open it according to the business situation; In most cases, close the following two items query_cache_type = 0 ## Set sqlmode. By default, mysql5 All boards above 7.5 have sqlmode, while ONLY_FULL_GROUP_BY is the default. If it is not configured, there will be an error that the fields queried after select do not appear in group by #nested exception is java.sql.SQLSyntaxErrorException: Expression #2 of SELECT list is not in GROUP BY clause and # contains nonaggregated column 'wlhy_xysk.s.vehicle_license_no' which is not functionally dependent on columns in GROUP BY clause; sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION' #set mysql server ssl security transmition protocol ssl-ca=/usr/local/mysql/data/cert/ca.pem ssl-cert=/usr/local/mysql/data/cert/server-cert.pem ssl-key=/usr/local/mysql/data/cert/server-key.pem #Threads_created: the number of threads created, # 1G ---> 8 # 2G ---> 16 # 3G ---> 32 thread_cache_size = 8 # The memory setting allocated by the user process. Each session will allocate the memory size set by the parameter key_buffer_size = 256M #key_buffer_size specifies the size of the index buffer, which determines the speed of index processing read_buffer_size = 2M # MySQL read in buffer size. The request for sequential scanning of the table will allocate a read in buffer, and MySQL will allocate a memory buffer for it. read_rnd_buffer_size = 8M # Random read buffer size of MySQL sort_buffer_size = 8M # Buffer size used by MySQL to perform sorting binlog_cache_size = 1M # When a transaction is not committed, the generated log is recorded in the Cache; When the transaction needs to be committed, the log is persisted to disk. Default binlog_cache_size 32K back_log = 130 # How many requests can be stored in the stack in a short time before MySQL temporarily stops responding to new requests; Official recommendation back_log = 50 + (max_connections / 5), and the number of capping is 900 skip-external-locking #Skip external locks. If a polymorphic server wants to open the external locking feature, it can comment directly. If it is a single server, it can be opened directly #skip-grant-tables # log setting log-error = /usr/local/mysql/logs/error.log # Database error log file slow_query_log = 1 # Slow query sql log settings long_query_time = 1 # Slow query time; If it exceeds 1 second, it is a slow query slow_query_log_file = /usr/local/mysql/logs/slow_query.log # Slow query log file log_queries_not_using_indexes = 1 # Check sql that is not used to index log_throttle_queries_not_using_indexes = 5 # Used to indicate the number of SQL statements that are allowed to be recorded to the slow log and do not use the index per minute. The default value is 0, which means there is no limit min_examined_row_limit = 100 # The number of retrieved rows must reach this value before it can be recorded as a slow query. The SQL returned by the query check that is less than the row specified by this parameter will not be recorded in the slow query log expire_logs_days = 7 # The expiration time of MySQL binlog log files, which will be automatically deleted after expiration # Master slave copy settings server-id=2 relay-log = /usr/local/mysql/data/relay-log relay-log-index = /usr/local/mysql/data/relay-log.index sync_relay_log =1 sync_relay_log_info = 1 innodb_file_per_table=1 replicate-wild-ignore-table=mysql.% replicate-wild-ignore-table=test.% replicate-wild-ignore-table=information_schema.% #No cascading, no opening required #log-bin = /usr/local/mysql/data/mysql-bin #master-host = 172.16.101.40 #master-user=repl_user #master-pass=repl_user123456 #master-port = 28000 #MASTER_LOG_FILE='mysql-bin.000001', #MASTER_LOG_POS=1663899; #master-connect-retry=60 #replicate-do-db =lgry-vue # Innodb settings innodb_open_files = 500 # Limit the data of the tables that Innodb can open. If there are too many tables in the library, please add this. This value defaults to 300 innodb_buffer_pool_size = 64M # InnoDB uses a buffer pool to store indexes and original data, generally 60% - 70% of the physical storage; The larger you set here, the less disk I/O you need to access the data in the table innodb_log_buffer_size = 2M # This parameter determines the amount of memory used to write log files, in M. Larger buffers can improve performance, but unexpected failures will lose data. MySQL developers recommend setting it between 1 and 8M innodb_flush_method = O_DIRECT # O_DIRECT reduces conflicts between the operating system level VFS cache and Innodb's own buffer cache innodb_write_io_threads = 2 # The CPU multi-core processing capacity setting is adjusted according to the reading and writing ratio. The best number of cores is the number of CPUs innodb_read_io_threads = 2 innodb_lock_wait_timeout = 120 # The number of timeout seconds that InnoDB transactions can wait for a lock before being rolled back. InnoDB automatically detects transaction deadlocks in its own lock table and rolls back transactions. InnoDB noticed the lock settings with the LOCK TABLES statement. The default value is 50 seconds innodb_log_file_size = 32M # This parameter determines the size of the data log file. A larger setting can improve performance, but it will also increase the time required to recover the failed database
Reference articles
https://blog.51cto.com/superpcm/2094958
https://blog.csdn.net/daicooper/article/details/79905660