Master-slave database theoretical knowledge
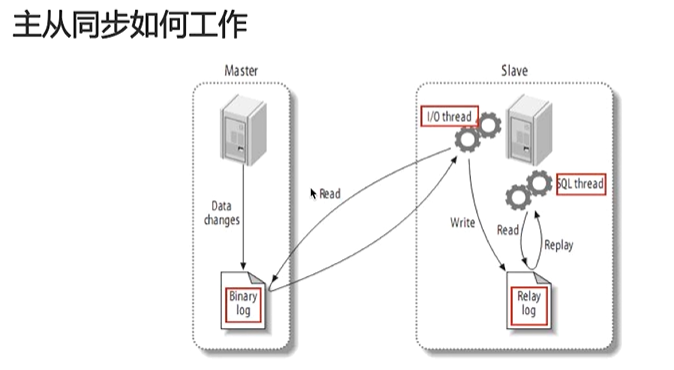
- First step
The master's operations on the data are recorded in the Binary log. Before each transaction updates the data, the master records these changes and writes them to the Binary log serially. After completing the log writing, the master notifies the storage engine to commit the transaction.
The operation of data is called a binary log event. - Step two
slave copies the log events to the relay log. slave will start an I/O thread. The I/O thread will open a normal connection on the master and then start copying the binary log.
slave reads binary logs and events. If it has kept up with the master, it continues to sleep and waits for the master to generate new events. The I/O thread writes these events to the relay log. - Step 3
Slave redo relay log events. The sql thread reads events from the relay log, replays them, and updates the slave data to make it consistent with the data in the master.
Implementation of master-slave configuration at database level
Preparatory work
View database mysql -uroot -p----show database
- Prepare two servers and install mysql (or install two sets of different databases on this machine, and set different ports)
- Configure master server (example: MST lez)
- Open the mysql configuration file
vim /etc/my.cnf
- Add configuration information under [mysqld]
server-id=1 log-bin=master-bin log-bin-index=master-bin.index
- Restart mysql database
service mysqld restart
- View main library
show master status;
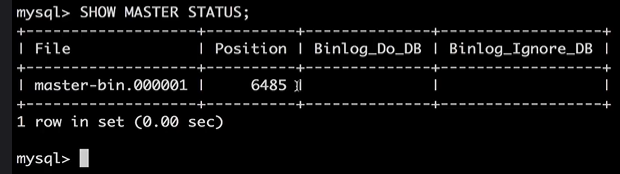
- Configure slave server (example: SLA ubz)
- Open the mysql configuration file
(if you configure MySQL on the same machine, you need to modify the port number of one of the mysql. For example, change the MySQL port of the slave server to 3307; if it is a different server, you don't need to change it.)vim /etc/my.cnf
- Add configuration information under [mysqld]
server-id=2 relay-log=slave-relay-bin relay-log-index=slave-relay-bin.index
- Restart mysql
/etc/init.d/mysql stop #Close mysql /etc/init.d/mysql start #mysql start
-
Associate master and slave servers (as long as the slave knows the master address)
Master server configuration:
## If the slave server connects to the master database with the repl account, Give REPLICATION SLAVE The authority of, And this permission is for all tables of all databases above the main database(*.*), In this way, the authorization is successful. GRANT REPLICATION SLAVE ON *.* TO 'repl'@'slave_ip' IDENTIFIED BY 'repl Password for' ##Refresh primary server mysql flush privileges;
From server configuration:
change master to master_host='master of ip address',master_port=3306,master_user='repl',master_password='repl Password for',master_log_file='master-bin.000001',master_log_pos=0; ## Enable master-slave tracking (enable master-slave synchronization) start slave; ## View related status show slave status \G;
During the first configuration, it seems that there is a duplicate server ID (although the main database has set server id = 1 and server id = 2).
Stop the master-slave synchronization first (in the slave server):
stop slave
Open the slave server configuration file, delete server id = 1 (it should be generated automatically), leave s server id = 2, restart the database, and then start the master-slave synchronization.
be careful:
- Never write data from the database, because it will only be changed unilaterally. The information of the main database has not been changed in time. When the main database changes this information, there will be conflict. Hiding can only write data in the main database.
- The mysql version of the master database can be different from that of the slave database. However, the slave database version must be higher than the master database.
Implementation of read-write separation at the code level (no need to change the existing code)
Idea:
Select data from at least two data sources, and select different data sources according to different needs, that is, select the master library when writing and the slave library when reading. The entry point is DataSource.
AbstractRoutingDataSource meets the requirements and can be routed to different DataSource functions. It inherits AbstractDataSource and indirectly inherits DataSource.
We create an implementation class of AbstractRoutingDataSource, DynamicDataSource, and override determineCurrentLookupKey, which will return different keys according to different requirements.
public class DynamicDataSource extends AbstractRoutingDataSource{
@Override
protected Object determineCurrentLookupKey(){
return DynamicDataSourceHolder.getDbType();
}
}
This time, the class DynamicDataSourceHolder is redefined so that it can retain the key through DynamicDataSourceHolder Getdbtype() returns key.
public class DynamicDataSourceHolder{
private static ThreadLocal<String> contextHolder = new ThreadLocal<>();
private static final String DB_MASTER = "master";
private static final String DB_SLAVE = "slave";
public static String getDbType(){
String db = contextHolder.get();
if(db == null){
db = DB_MASTER;
}
return db;
}
//Set thread DBType
public static void setDbType(String str){
//The data source used is str
contextHolder.set(str);
}
//clear; line type
public static void clearDBType(){
contextHolder.remove();
}
}
Then set up the interceptor in mybatis
Why set a Mabatis level Interceptor here?
This is because the route needs to be used after the route is completed. The route needs to rely on the interceptor. The interceptor will intercept the Sql information passed by Mabatis. For example, if update and insert are passed, the written data source will be used, and if query or select, the read data source will be used.
@Intercepts({
@Signature(type = Excutor.class,method="update",args={MappedStatement.class,Object.class}),
@Signature(type = Excutor.class,method="query",args={MappedStatement.class,Object.class,RowBounds.class,ResultHandler.class})
})
public class DynamicDataSourceInterceptor implement Interceptor{
//Regular. Judge whether it starts with insert, delete and update. If so, use the main library, \ \ u0020 represents a space
private static final String REGEX = ".*insert\\u0020.*|.*delete\\u0020.*|.*update\\u0020.*";
//This is the main interception method
@Override
public Object intercept(Invocation invocation) throw Throwable{
//Judge whether the current Transaction is a Transaction, that is, whether the @ Transaction annotation is used. If so, it will return true
boolean synchronizationActive = TrasactionSynchronizationManager.isActualTransactionActive();
if(synchronizationActive != true){
//Parameters obtained for these operations
Obejct[] obejcts = invocation.getArgs();
//The first parameter often carries operations, such as insert, select, update, delete and so on
//From MappedStatement
MappedStatement ms = (MappedStatement) obejcts[0];
//lookupkey is used to determine the location of AbstractRoutingDataSource
String lookupkey;
//Reading method
if(ms.getSqlCommandType().equals(SqlCommandType.SELECT)){
//If the selectKey is the auto increment query primary key (SELECT LAST_INSERT_ID()) method
//(similar to USE GENERATOR KEY = TUYE, which means that if it is just created, it is queried with the main database), the main database is used
//That is, after inserting a piece of data, it starts reading. At this time, the reading uses the master library instead of the slave library
if(ms.getId().contains(SelectKeyGenerator.SELECT_KEY_SUFFIX)){
lookupKey = DynamicDataSourceHolder.DB_MASTER;
}else{
BoundSql boundSql = ms.getSqlSource().getBoundSql(objects[1]);
//Replace all tabs and line breaks in sql with spaces
String sql = boundSql.getSql().toLowerCase(Locale.CHINA).replaceAll("[\\t\\n\\r]"," ");
//If it starts with insert, delete and update, the main database is used
if(sql.matches(REGEX)){
lookupKey = DynamicDataSourceHolder.DB_MASTER;
}else{
lookupKey = DynamicDataSourceHolder.DB_SLAVE;
}
}
}
}else{
lookupKey = DynamicDataSourceHolder.DB_MASTER;
}
//Finally decide which data source to use
DynamicDataSourceHolder.setDbType(lookupKey);
return invocation.proceed();
}
//Return the encapsulated object / proxy object, that is, weave a coat outside the class to be intercepted, and return
//That is, does it return the body or the woven coat
@Override
public Object plugin(Object target){
//org.apache.ibatis.executor.Executor is used to support a series of curd operations
//It means that when the object we intercept is of the type of Executor, we intercept it,
//That is, package the interceptor inside. If it is not, it will not be intercepted
if(target instanceof Executor){
return Plugin.wrap(taeget,this);
}else{
return target;
}
}
}
Next, configure the interceptor in the configuration of mybatis (mybatis-config.xml).
<plugins> <plugin interceptor="com....DynamicDataSourceInterceptor"></plugin> </plugins>
The last step is in spring Dao Reconfigure DataSource in XML

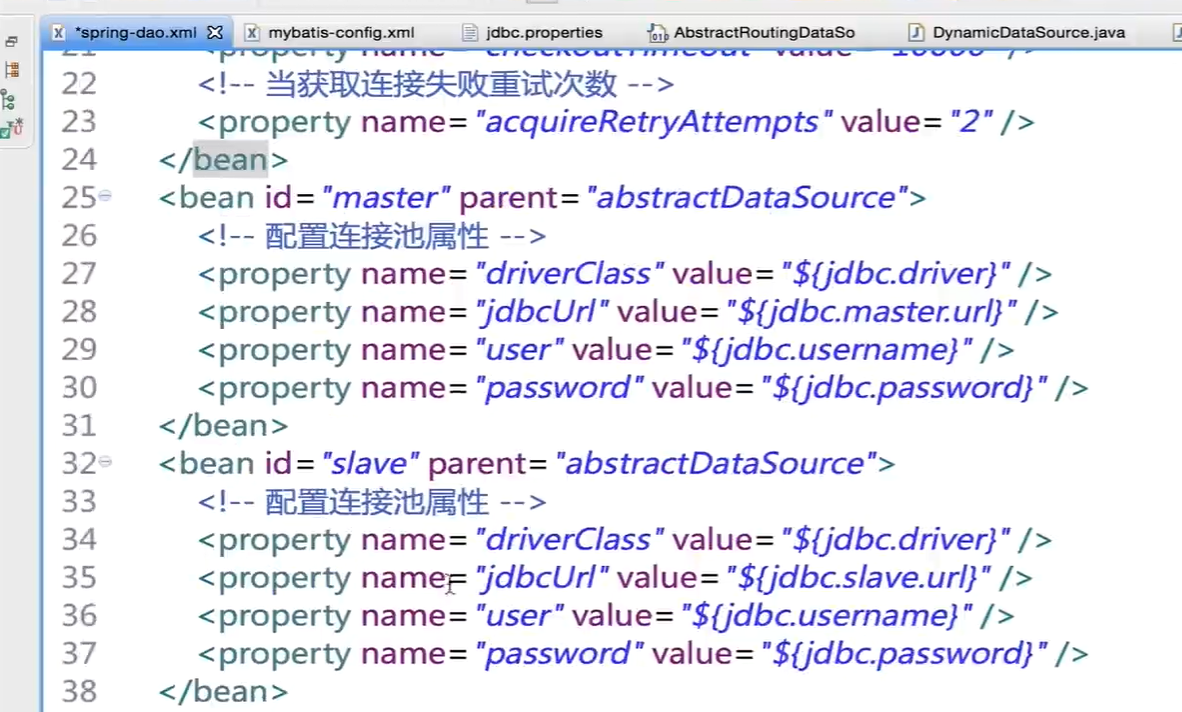

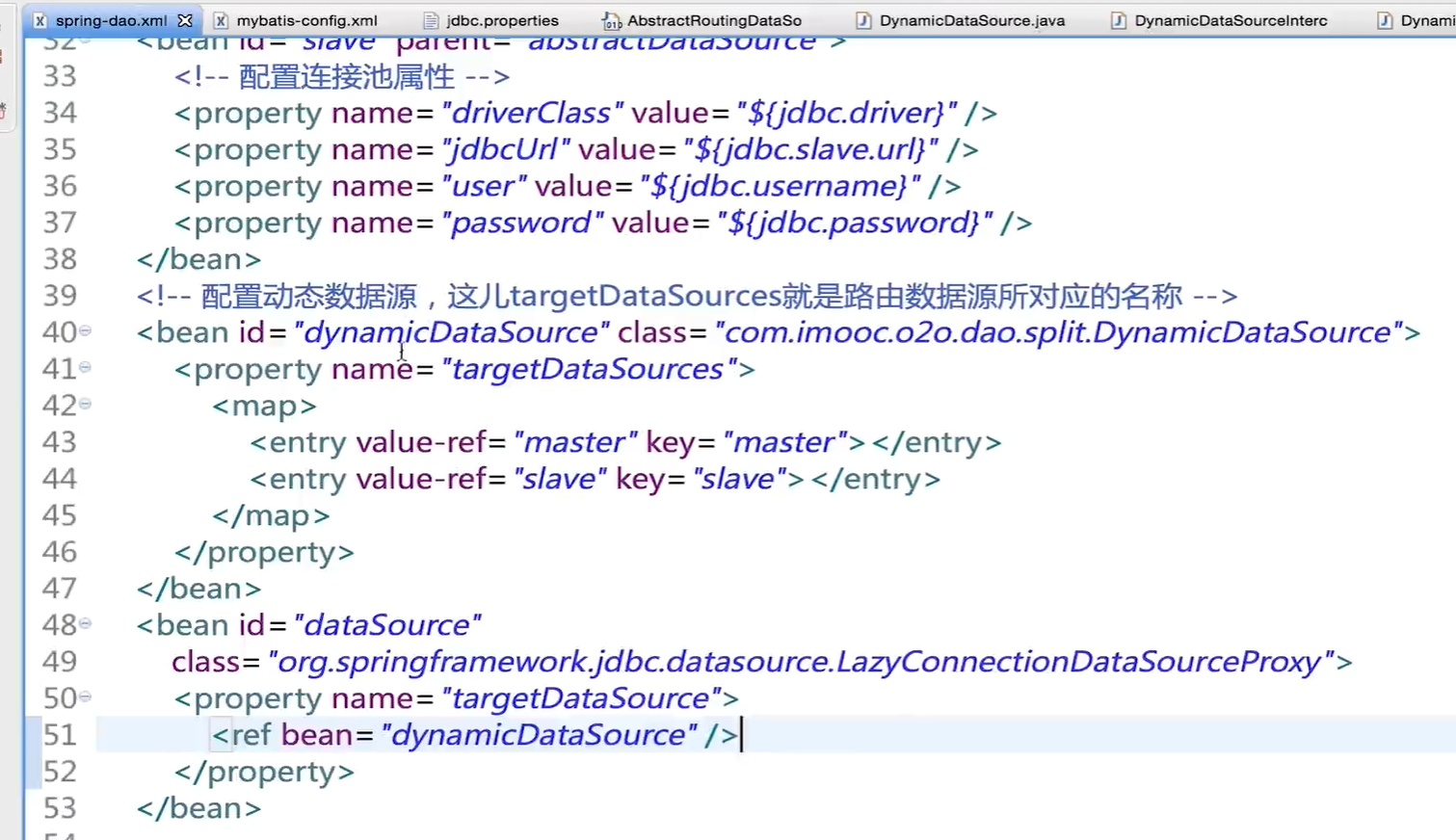
Since mybatis only decides to use its data source after generating sql statements, it needs to introduce a lazy loaded ConnectionDataSourceProxy.