preface
Querying the same data, after using Order by and limit, may have a hundred times impact on the query results and time-consuming. Optimizing SQL is not only to optimize those slow queries with more than 1 second, but also those with ultra-high frequency of 0.1 second.
Here, I simulated and created a table limit_table
And initialize the data of 100W rows.
-- Table creation
CREATE TABLE `limit_table` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`index_fie_id_a` int(8) NOT NULL,
`fie_id_b` int(8) NOT NULL,
`fie_id_str` varchar(30) DEFAULT NULL,
`created_at` datetime DEFAULT NULL,
`updated_at` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `index_index_fie_id_a` (`index_fie_id_a`) USING BTREE
) ENGINE=InnoDB CHARSET=utf8;
-- Create stored procedure
DELIMITER //
CREATE PROCEDURE add_limit_table()
BEGIN
DECLARE num INT;
SET num = 0;
WHILE
num < 1000000 DO
-- insert data
INSERT INTO limit_table(index_fie_id_a,fie_id_b,created_at) VALUES(CEILING(RAND()*10000),CEILING(RAND()*100000),now());
SET num = num + 1;
END WHILE;
END;
//
-- Execute stored procedure
call add_limit_table();
-- Delete stored procedure
DROP PROCEDURE add_limit_table;
--initialization String character string
UPDATE limit_table set fie_id_str= CONCAT('string',inde_x_fie_id_a,CEILING(RAND()*10));
After data initialization, let's take a look at the query efficiency comparison under different query conditions and sorting conditions
Field index_fie_id_a: int type, with index. There are about 100 duplicates in each data
Field fie_id_b: int type, no index, about 10 duplicates per data
Field fie_id_str: varchar type, without index. There are about 10 duplicates in each data, and the data is based on index_fie_id_a sort generation
Verification scenario
-
No sorting and no query condition Limit 0,5
-- Demo : A SELECT SQL_NO_CACHE * from limit_table LIMIT 5;
-
No sorting and no query condition Limit 50000,5
-- Demo : B SELECT SQL_NO_CACHE * from limit_table LIMIT 50000,5;
-
No sorting, query criteria / int type / no index Limit 0,5
-- Demo : C SELECT SQL_NO_CACHE * from limit_table WHERE fie_id_b = 66666 LIMIT 5;
-
No sorting, query criteria / varchar / no index Limit 0,5
-- Demo : D SELECT SQL_NO_CACHE * from limit_table WHERE fie_id_str = 'string66666' LIMIT 5;
-
No sorting, query criteria / index Limit 0,5
-- Demo : E SELECT SQL_NO_CACHE * from limit_table WHERE index_fie_id_a = 100 LIMIT 5;
-
With sorting / no index and no query condition Limit 0,5
-- Demo : F SELECT SQL_NO_CACHE * from limit_table ORDER BY fie_id_b LIMIT 5;
-
Sort / no index, query criteria / int type / no index Limit 0,5
-- Demo : G; SELECT SQL_NO_CACHE * from limit_table WHERE fie_id_b = 66666 ORDER BY fie_id_str LIMIT 5;
-
Sort / no index, query criteria / varchar type / no index Limit 0,5
-- Demo : H; SELECT SQL_NO_CACHE * from limit_table WHERE fie_id_str = 'string66666' ORDER BY fie_id_b LIMIT 5;
-
With sorting / no index, query criteria / index Limit 0,5
-- Demo : I; SELECT SQL_NO_CACHE * from limit_table WHERE index_fie_id_a = 100 ORDER BY fie_id_b LIMIT 5;
-
With sorting / index and no query condition Limit 0,5
-- Demo : J; SELECT SQL_NO_CACHE * from limit_table ORDER BY index_fie_id_a LIMIT 5;
-
With sorting / index, query criteria / no index Limit 0,5
-- Demo : K1; SELECT SQL_NO_CACHE * from limit_table WHERE fie_id_str = 'string10001' ORDER BY index_fie_id_a LIMIT 5; -- Demo : K2; SELECT SQL_NO_CACHE * from limit_table WHERE fie_id_str = 'string30001' ORDER BY index_fie_id_a LIMIT 5; -- Demo : K3; SELECT SQL_NO_CACHE * from limit_table WHERE fie_id_str = 'string60001' ORDER BY index_fie_id_a LIMIT 5; -- Demo : K4; SELECT SQL_NO_CACHE * from limit_table WHERE fie_id_str = 'string99999' ORDER BY index_fie_id_a LIMIT 5; -- Demo : K5; SELECT SQL_NO_CACHE * from limit_table WHERE fie_id_str = 'string99999' ORDER BY index_fie_id_a desc LIMIT 5; -- Demo : K6; SELECT SQL_NO_CACHE * from limit_table WHERE fie_id_str = 'string99999';
-
With sorting / index, query criteria / index Limit 0,5
-- Demo : L; SELECT SQL_NO_CACHE * from limit_table WHERE index_fie_id_a = 100 ORDER BY index_fie_id_a LIMIT 5;
The analysis data in this paper are based on the search data, which can absolutely cover the number of entries limited by the limit, so as to avoid the situation that the full table scan will affect the query time due to the insufficient number of records.
The query time is as follows:
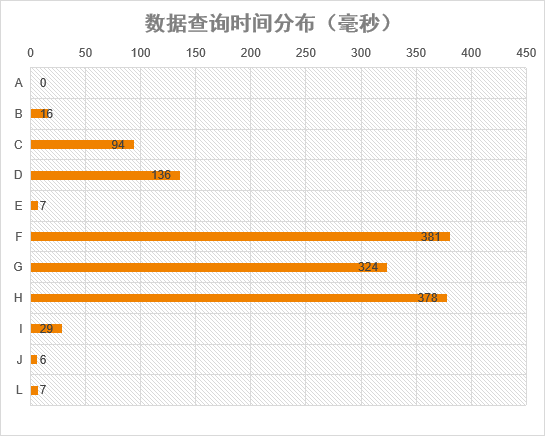
Query result analysis
-
Demo A: there are no query conditions and the number of queries is limited by Limit. This is the fastest when the number of queries is the same, because usually there are two header pointers on B+Tree, one pointing to the root node and the other pointing to the leaf node with the smallest keyword. It can be read in sequence directly, which is efficient and does not waste IO times. Therefore, this query will return data with ID: 1 ~ 5. Number of data retrieval lines: 5;
Ignoring the influence of other factors, the fewer rows of data retrieval, the faster the query. One of the cores of SQL optimization is to reduce the number of data retrieval rows. This is also the main function of index.
-
Demo B: demo B is slower than Demo A, because B needs to retrieve more rows, because it needs to find the 50001st ~ 50005th data from the first one. So when we do the page turning function, deep page turning will greatly reduce your query efficiency! Number of data retrieval lines: 50005;
If the search result of $start is very low, the search result of $start will be rewritten as much as possible, and $start will affect the search result of $start; If it cannot be rewritten, first obtain limit $start,$num or limit $start,1 from the index structure; Then use in operation or limit 0 and $num based on index order for secondary search.
For example: for the next page operation, let the front end pass the maximum ID of the current page, and then add a weher condition in the background. If the user manually enters the page number to skip the page, you can first find out the minimum primary key ID value of the page with the query page, and then query the data of the page. -
Demo C & Demo D: demo C will be so much faster than Demo D. if there is no index, ignore the data distribution (assuming that the data fie_id_str of ID 1 ~ 5 is equal to 'string66666', which is an extreme case, which we will not consider). In terms of data operation and comparison, integer will be much faster than varchar thanks to the native support. Number of data retrieval lines: > = 5 and < total records;
Because the comparison will start from the leaf node with the smallest primary key ID, you can stop retrieving data after meeting the Limit of 5 rows of data. Therefore, the number of data retrieval rows is unknown. Unless there are less than 5 pieces of data that meet the requirements, the data of the whole table will be retrieved
-
Demo E: this field is indexed, so take the primary key ID corresponding to 5 rows of data according to the non clustered index order, and then query the data back to the table according to the primary key ID. Demo E will be slower than Demo A for two main reasons: 1. Increase IO times for back table query; 2. The primary key IDs of the data are discontinuous, and multiple pages need to be loaded from the disk to memory. Number of data retrieval lines: 5
-
Demo F: the sorting field has no index and no query criteria, so no index can be used to scan the whole table. Slow enough to fly, this is absolutely the wrong way to play. Data retrieval rows: total records
-
Demo G & Demo H: both of them scan the whole table according to the where condition, and then sort the qualified data. Therefore, demo G & Demo H is slower than demo C & demo D. Demo G is faster than Demo H because of the advantage of character type. At the same time, demo G is a little faster than Demo F, indicating that sorting under the same character type will be slower than comparison judgment. Data retrieval rows: total records
Careful students found that I used the str field in the database in the sorting field when querying Demo G cases. If my sorting field is completely consistent with the where query condition field, and the query condition is' = ', it can be understood that 5 rows of records are retrieved without sorting. So you may not need to scan the whole table!!!
-
Demo I: relatively fast, because the query criteria have indexes. However, because the sorting field has no index, you need to find out all the qualified data and then sort. Data retrieval rows: the total number of records that meet the where criteria
-
Demo J: demo J is similar to Demo E, but it is faster than Demo E because there is no need to judge and compare, and there are no query conditions like Demo A. At the same time, because the back table query is not continuous with the primary key ID, it will be slower than Demo A. Number of data retrieval lines: 5
-
Demo L: the where condition has an index and the sorting fields are the same. It can be ignored when the judgment condition is' = '. So refer to Demo E. Number of data retrieval lines: 5
Query condition has no index but sorting has index
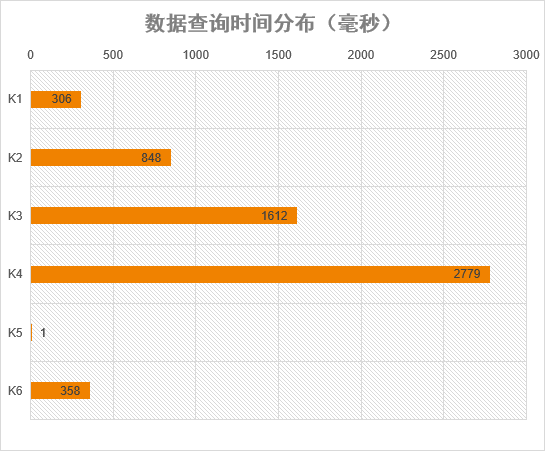
Query result analysis

- Demo K1 ~ Demo K4: This is very interesting because the where condition has no index and the sorting field has an index. The optimizer will choose to use the index. So the nightmare came. The query time fluctuated greatly. It all depends on which part of the index field the data in your where condition exists. Fie in Demo K4_ id_ STR = data of 'string90001', according to index_fie_id_a is in the very backward part after sorting, so the query is time-consuming and directly slow.
- Demo K5: I didn't modify the query criteria and sorting fields, but changed the sorting from ASC to DESC, so fie_id_str = 'string99999' is in the front position in an instant, and the query time is 2700 times shorter.
- Demo K6: I directly removed the sorting and Limit. The full table matching search does not go through the index, but is much more reliable than when there is an index. As mentioned before, the back table and primary key ID s are not continuous, resulting in the need to load an entire page of data for each record.
summary
- int type comparison judgment will be faster than varchar, and many databases will use 1 / 2 instead of male / female;
- Deep paging needs to be optimized;
- It is very necessary to index common query fields;
- MySQL optimizer may not give you the best results. But if the result is not ideal, there must be a problem with your index or SQL writing. With our technical skills, don't doubt the optimizer;
- When there is no query condition or no index in the query condition, it is strictly prohibited to use non index field sorting;
- Query / sort by primary key. Try to rely on primary key to avoid back table query;
- If there is no index in the query criteria, be careful to sort with the indexed fields;
- When the amount of data to be queried is known, using Limit can effectively improve the query efficiency;