1, DML operation [ key ]
1.1 add (INSERT)
INSERT INTO Table name (column 1, column 2, column 3...) values (value 1, value 2, value 3...);
1.1.1 add a message
#Add a job information
INSERT INTO t_jobs(JOB_ID,JOB_TITLE,MIN_SALARY,MAX_SALARY) VALUES('JAVA_Le','JAVA_Lecturer',2500,9000);#Add an employee information
INSERT INTO `t_employees`
(EMPLOYEE_ID,FIRST_NAME,LAST_NAME,EMAIL,PHONE_NUMBER,HIRE_DATE,JOB_ID,SALARY,COMMISSION_PCT,MANAGER_ID,DEPARTMENT_ID)
VALUES
('194','Samuel','McCain','SMCCAIN', '650.501.3876', '1998-07-01', 'SH_CLERK', '3200', NULL, '123', '50');1.2 modification (UPDATE)
UPDATE table name SET column 1 = new value 1, column 2 = new value 2,... WHERE condition;
1.2.1 modify a message
#The salary of the employee with modification number 100 is 25000 UPDATE t_employees SET SALARY = 25000 WHERE EMPLOYEE_ID = '100';
#Modify the employee information No. 135 and the position No. is ST_MAN, salary 3500 UPDATE t_employees SET JOB_ID=ST_MAN,SALARY = 3500 WHERE EMPLOYEE_ID = '135';
1.3 DELETE
DELETE FROM table name WHERE condition;
1.3.1 delete a message
#Delete employee number 135 DELETE FROM t_employees WHERE EMPLOYEE_ID='135';
#Delete the employee whose last name is Peter and whose first name is Hall DELETE FROM t_employees WHERE FIRST_NAME = 'Peter' AND LAST_NAME='Hall';
1.4 clear whole table data (TRUNCATE)
TRUNCATE TABLE table name; This syntax is not a DML statement
1.4.1 empty the whole table
#Empty t_countries entire table TRUNCATE TABLE t_countries;
2. Data query [ key ]
2.1 basic structure of database table
Relational structure database is stored in tables, which are composed of "rows" and "columns"
-- Employee table employee employee_id --number first_name --name email --mailbox salary --a monthly salary commission_pct --Commission manager_id --Manager No department_id --department id job_id --Job number
-- Department table department department_id --Department number department_name --Department name -- Worksheet job job_id --work id job_name --Job name job_desc --job content --Manager table manager manager_id --Manager number manager_name --Manager name
2.2 basic query
Syntax: SELECT column name FROM table name
keyword | describe |
|---|---|
SELECT | Specify the columns to query |
FROM | Specify the table to query |
2.2.1 query some columns
#Query the number, name and email address of all employees in the employee table SELECT employee_id,first_name,email FROM t_employees;
2.2.2 query all columns
#Query all information of all employees in the employee table (all columns) SELECT Column names for all columns FROM t_employees; SELECT * FROM t_employees;
2.2.3 calculate the data in the column
#Query the number, name and annual salary of all employees in the employee table SELECT employee_id , first_name , salary*12 FROM t_employees;
Arithmetic operator | describe |
|---|---|
+ | Add two columns |
- | Subtract two columns |
* | Multiply two columns |
/ | Divide two columns |
2.2.4 alias of column
Column as' column name '
#Query the number, name and annual salary of all employees in the employee table (the column names are in Chinese) SELECT employee_id as "number" , first_name as "name" , salary*12 as "Annual salary" FROM t_employees;
2.2.5 de duplication of query results
DISTINCT column name
#Query the ID of all managers in the employee table. SELECT DISTINCT manager_id FROM t_employees;
2.3 Sorting Query
Syntax: SELECT column name FROM table name ORDER BY [sort rule]
Sorting rules | describe |
|---|---|
ASC | Sort the front row in ascending order |
DESC | Sort the front row in descending order |
2.3.1 sorting by single column
#Query employee's number, name and salary. Sort by salary in descending order. SELECT employee_id , first_name , salary FROM t_employees ORDER BY salary DESC;
2.3.2 sorting by multiple columns
#Query employee's number, name and salary. Sort by salary level in ascending order (if the salary is the same, sort by number in ascending order). SELECT employee_id , first_name , salary FROM t_employees ORDER BY salary DESC , employee_id ASC;
2.4 query criteria
Syntax: SELECT column name FROM table name WHERE conditions
keyword | describe |
|---|---|
WHERE conditions | In the query results, filter the query results that meet the criteria. The criteria are Boolean expressions |
2.4.1 equivalence judgment (=)
#Query employee information (number, name, salary) with salary of 11000 SELECT employee_id , first_name , salary FROM t_employees WHERE salary = 11000;
2.4.2 logical judgment (and, or, not)
#Query employee information (number, name, salary) with salary of 11000 and commission of 0.30 SELECT employee_id , first_name , salary FROM t_employees WHERE salary = 11000 AND commission_pct = 0.30;
2.4.3 unequal judgment (>, <, > =, < =,! =, < >)
#Query the employee information (number, name, salary) whose salary is between 6000 and 10000 SELECT employee_id , first_name , salary FROM t_employees WHERE salary >= 6000 AND salary <= 10000;
2.4.4 between and
#Query the employee information (number, name, salary) whose salary is between 6000 and 10000 SELECT employee_id , first_name , salary FROM t_employees WHERE salary BETWEEN 6000 AND 10000; #Closed interval, including two values of interval boundary
2.4.5 NULL value judgment (IS NULL, IS NOT NULL)
- IS NULL Column name IS NULL
- IS NOT NULL Column name IS NOT NULL
#Query employee information without commission (No., name, salary, commission) SELECT employee_id , first_name , salary , commission_pct FROM t_employees WHERE commission_pct IS NULL;
2.4.6 enumeration query (IN (value 1, value 2, value 3))
#Query employee information (number, name, salary, department number) with department numbers of 70, 80 and 90 SELECT employee_id , first_name , salary , department_id FROM t_employees WHERE department_id IN(70,80,90); Note: in The query efficiency is low and can be spliced through multiple conditions.
2.4.7 fuzzy query
- LIKE _ (single arbitrary character) Column name LIKE 'Zhang'
- LIKE% (any character of any length) Column LIKE 'Zhang%'
- Note: fuzzy query can only be used in combination with LIKE keyword
#Query employee information (number, name, salary, department number) whose name starts with "L" SELECT employee_id , first_name , salary , department_id FROM t_employees WHERE first_name LIKE 'L%'; #Query the employee information (number, name, salary, department number) whose name starts with "L" and length is 4 SELECT employee_id , first_name , salary , department_id FROM t_employees WHERE first_name LIKE 'L___';
2.4.8 branch structure query
CASE
WHEN Condition 1 THEN Result 1
WHEN Condition 2 THEN Result 2
WHEN Condition 3 THEN Result 3
ELSE result
END- Note: by using CASE END for condition judgment, a value is generated for each data.
- Experience: similar to switch in Java.
#Query employee information (No., name, salary, salary level < corresponding condition expression generation >)
SELECT employee_id , first_name , salary , department_id ,
CASE
WHEN salary>=10000 THEN 'A'
WHEN salary>=8000 AND salary<10000 THEN 'B'
WHEN salary>=6000 AND salary<8000 THEN 'C'
WHEN salary>=4000 AND salary<6000 THEN 'D'
ELSE 'E'
END as "LEVEL"
FROM t_employees;2.5 time query
Syntax: SELECT Time function ([parameter list])
Time function | describe |
|---|---|
SYSDATE() | Current system time (day, month, year, hour, minute, second) |
CURDATE() | Get current date |
CURTIME() | Get current time |
WEEK(DATE) | Gets the week ordinal of the year with the specified date |
YEAR(DATE) | Gets the year of the specified date |
HOUR(TIME) | Gets the hour value for the specified time |
MINUTE(TIME) | Gets the minute value of the time |
DATEDIFF(DATE1,DATE2) | Gets the number of days between DATE1 and DATE2 |
ADDDATE(DATE,N) | Calculate DATE plus N days later |
2.5.1 obtaining the current system time
#Query current time SELECT SYSDATE();
#Query current time SELECT NOW();
#Get current date SELECT CURDATE();
#Get current time SELECT CURTIME();
2.6 string query
Syntax: SELECT String function ([parameter list])
String function | explain |
|---|---|
CONCAT(str1,str2,str...) | Concatenate multiple strings |
INSERT(str,pos,len,newStr) | Replace the contents of len length from the specified pos position in str with newStr |
LOWER(str) | Converts the specified string to lowercase |
UPPER(str) | Converts the specified string to uppercase |
SUBSTRING(str,num,len) | Specify the str string to the num position and start intercepting len contents |
2.6.1 string application
#Splicing content
SELECT CONCAT('My','S','QL');#String substitution
SELECT INSERT('This is a database',3,2,'MySql');#The result is that this is a MySql database#Convert specified content to lowercase
SELECT LOWER('MYSQL');#mysql#Convert specified content to uppercase
SELECT UPPER('mysql');#MYSQL#Specified content interception
SELECT SUBSTRING('JavaMySQLOracle',5,5);#MySQL2.7 aggregate function
Syntax: SELECT Aggregate function (column name) FROM table name
Aggregate function | explain |
|---|---|
SUM() | Find the sum of single column results in all rows |
AVG() | average value |
MAX() | Maximum |
MIN() | minimum value |
COUNT() | Find the total number of rows |
2.7.1 single column sum
#Count the total monthly salary of all employees SELECT sum(salary) FROM t_employees;
2.7.2 single column average
#Calculate the average monthly salary of all employees SELECT AVG(salary) FROM t_employees;
2.7.3 maximum value of single column
#Count the highest monthly salary of all employees SELECT MAX(salary) FROM t_employees;
2.7.4 minimum value of single column
#Count the lowest monthly salary of all employees SELECT MIN(salary) FROM t_employees;
2.7.5 total number of head offices
#Count the total number of employees SELECT COUNT(*) FROM t_employees;
#Count the number of employees with commission SELECT COUNT(commission_pct) FROM t_employees;
2.8 group query
Syntax: SELECT column name FROM table name WHERE condition GROUP BY (column);
keyword | explain |
|---|---|
GROUP BY | Grouping basis must take effect after WHERE |
2.8.1 query the total number of people in each department
#Idea: #1. Grouping by department number (grouping by department_id) #2. count the number of people in each department SELECT department_id,COUNT(employee_id) FROM t_employees GROUP BY department_id;
2.8.2 query the average salary of each department
#Idea: #1. Group by department number (grouping by department_id). #2. Average wage statistics (avg) for each department. SELECT department_id , AVG(salary) FROM t_employees GROUP BY department_id
2.8.3 query the number of people in each department and position
#Idea: #1. Group by department number (grouping by department_id). #2. Group by position name (by job_id). #3. count the number of people for each position in each department. SELECT department_id , job_id , COUNT(employee_id) FROM t_employees GROUP BY department_id , job_id;
2.8.4 common problems
#Query each department id, total number of people and first_name SELECT department_id , COUNT(*) , first_name FROM t_employees GROUP BY department_id; #error
2.9 group filtering query
Syntax: SELECT column name FROM table name WHERE condition GROUP BY group column HAVING filter rules
keyword | explain |
|---|---|
HAVING filter rules | Filter rule definitions filter grouped data |
2.9.1 maximum wage of statistical department
#Statistics on the maximum wages of departments 60, 70 and 90 #Idea: #1). Determine grouping basis (department_id) #2). For the grouped data, filter out the information with department numbers of 60, 70 and 90 #3). max() function processing SELECT department_id , MAX(salary) FROM t_employees GROUP BY department_id HAVING department_id in (60,70,90) # group determines the grouping basis department_id #having filtered out 60 70 90 departments #select to view the department number and max function.
2.10 restricted query
SELECT column name FROM table name LIMIT start line, number of query lines
keyword | explain |
|---|---|
LIMIT offset_start,row_count | Limit the number of starting rows and total rows of query results |
2.10.1 query the first 5 lines of records
#Query all the information of the top five employees in the table SELECT * FROM t_employees LIMIT 0,5;
2.10.2 query range record
#In the query table, start from the fourth item and query 10 rows SELECT * FROM t_employees LIMIT 3,10;
2.10.3 typical application of limit
Pagination query: 10 items are displayed on one page, and a total of three pages are queried
#Idea: the first page starts from 0 and displays 10 items SELECT * FROM LIMIT 0,10; #The second page starts with Article 10 and displays 10 articles SELECT * FROM LIMIT 10,10; #The third page starts with 20 items and displays 10 items SELECT * FROM LIMIT 20,10;
2.11 query summary
2.11.1 SQL statement writing sequence
2.11.2 SQL statement execution sequence
1.FROM : Specify data source table 2.WHERE : Filter the query data for the first time 3.GROUP BY : grouping 4.HAVING : Filter the grouped data for the second time 5.SELECT : Query the value of each field 6.ORDER BY : sort 7.LIMIT : Qualified query results
2.12 sub query (judged as condition)
SELECT column name FROM table name Where condition (subquery result)
2.12.1 query employee information whose salary is greater than Bruce
#1. First query Bruce's salary (one row and one column) SELECT SALARY FROM t_employees WHERE FIRST_NAME = 'Bruce';#The salary is 6000 #2. Query employee information whose salary is greater than Bruce's SELECT * FROM t_employees WHERE SALARY > 6000; #3. Integrate 1 and 2 statements SELECT * FROM t_employees WHERE SALARY > (SELECT SALARY FROM t_employees WHERE FIRST_NAME = 'Bruce' );
- Note: take the results of sub query "one row, one column" as the criteria of external query for the second query
- Only the results of one row and one column obtained by the sub query can be used as the equivalent judgment condition or unequal judgment condition of the external query
2.13 sub query (as enumeration query criteria)
SELECT column name FROM table name Where column name In (sub query result);
2.13.1 query employee information of the same department named 'King'
#Idea: #1. First query the department number of 'King' (multiple lines and single column) SELECT department_id FROM t_employees WHERE last_name = 'King'; //Department No.: 80, 90 #2. Query the employee information of departments 80 and 90 SELECT employee_id , first_name , salary , department_id FROM t_employees WHERE department_id in (80,90); #3.SQL: Consolidation SELECT employee_id , first_name , salary , department_id FROM t_employees WHERE department_id in (SELECT department_id cfrom t_employees WHERE last_name = 'King'); #N rows and one column
2.13.2 information about the owner of the Department whose salary is higher than 60
#1. Query 60 Department owner's salary (multiple rows and columns) SELECT SALARY from t_employees WHERE DEPARTMENT_ID=60; #2. Query the information of employees whose wages are higher than 60 Department owners (higher than all) select * from t_employees where SALARY > ALL(select SALARY from t_employees WHERE DEPARTMENT_ID=60); #. Query the information of employees whose wages are higher than 60 departments (higher part) select * from t_employees where SALARY > ANY(select SALARY from t_employees WHERE DEPARTMENT_ID=60);
2.14 sub query (as a table)
SELECT column name FROM (result set of subquery) WHERE conditions;
2.14.1 query the information of the top 5 employees in the employee table
#Idea: #1. Sort the salaries of all employees first (temporary table after sorting) select employee_id , first_name , salary from t_employees order by salary desc #2. Query the first 5 rows of employee information in the temporary table select employee_id , first_name , salary from (cursor) limit 0,5; #SQL: merging select employee_id , first_name , salary from (select employee_id , first_name , salary from t_employees order by salary desc) as temp limit 0,5;
- Take the results of the sub query "multi row and multi column" as a table of the external query for the second query.
- Note: as a temporary table, the sub query is given a temporary table name
2.15 consolidated query (understand)
- SELECT * FROM table name 1 UNION SELECT * FROM table Name2
- SELECT * FROM table name 1 UNION ALL SELECT * FROM table Name2
2.15.1 results of merging two tables (removing duplicate records)
#Merge the results of two tables to remove duplicate records SELECT * FROM t1 UNION SELECT * FROM t2;
2.15.2 results of merging two tables (keep duplicate records)
#Merge the results of two tables without removing duplicate records (show all) SELECT * FROM t1 UNION ALL SELECT * FROM t2;
2.16 table connection query
SELECT column name FROM table 1 Connection mode Table 2 ON connection condition
2.16.1 INNER JOIN ON
#1. Query all employees with departments (excluding employees without departments) SQL standard SELECT * FROM t_employees INNER JOIN t_jobs ON t_employees.JOB_ID = t_jobs.JOB_ID #2. Query the information of all employees with departments (excluding employees without departments) MYSQL SELECT * FROM t_employees,t_jobs WHERE t_employees.JOB_ID = t_jobs.JOB_ID
- Experience: in MySql, the second method can also be used as internal connection query, but it does not meet the SQL standard
- The first belongs to SQL standard, which is common with other relational databases
2.16.2 three table connection query
#Query the job number, name, department name and country ID of all employees SELECT * FROM t_employees e INNER JOIN t_departments d on e.department_id = d.department_id INNER JOIN t_locations l ON d.location_id = l.location_id
2.16.3 LEFT JOIN ON
#Query all employee information and the corresponding department name (employees without departments are also in the query results, and the Department name is filled with NULL) SELECT e.employee_id , e.first_name , e.salary , d.department_name FROM t_employees e LEFT JOIN t_departments d ON e.department_id = d.department_id;
- Note: the left outer connection takes the left table as the main table, matches to the right in turn, matches to, and returns the result
- If no match is found, NULL value filling is returned
2.16.4 RIGHT JOIN ON
#Query all department information and all employee information in this department (departments without employees are also in the query results, and the employee information is filled in with NULL) SELECT e.employee_id , e.first_name , e.salary , d.department_name FROM t_employees e RIGHT JOIN t_departments d ON e.department_id = d.department_id;
- Note: the right outer connection takes the right table as the main table, matches to the left in turn, matches to, and returns the result
- If no match is found, NULL value filling is returned
3, Database advanced
3.1 stored procedure
MySQL version 5.0 supports stored procedures. The idea of stored procedure is very simple, that is, code encapsulation and reuse at the level of database SQL language. Stored Procedure is a database object that stores complex programs in a database for external programs to call. Stored Procedure is a set of SQL statements to complete specific functions. It is compiled, created and saved in the database. Users can call and execute it by specifying the name of the Stored Procedure and giving parameters (when necessary).
DELIMITER $$or DELIMITER / / this indicates that the ending symbol of the current sql statement is not; Instead, it becomes the specified $$or / / because during the creation of stored procedures, we will have; Represents the end of a line of statements
3.1.1 creating stored procedures
CREATE
[DEFINER = { user | CURRENT_USER }]
PROCEDURE sp_name ([proc_parameter[,...]])
[characteristic ...] routine_body
proc_parameter:
[ IN | OUT | INOUT ] param_name type
characteristic:
COMMENT 'string'
| LANGUAGE SQL
| [NOT] DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
routine_body:
Valid SQL routine statement
[begin_label:] BEGIN
[statement_list]
......
END [end_label]DELIMITER $$
CREATE PROCEDURE pro_test1()
BEGIN
INSERT INTO t2(tname) VALUES('haha');
UPDATE t1 SET tname='jack1' WHERE tid=1;
SELECT * FROM t1;
END $$
call pro_test1()3.1.2 stored procedure parameters
IN | OUT | INOUT type name type
Use of in parameter
DELIMITER $$
CREATE PROCEDURE pro_test2(IN t2_name VARCHAR(20) , IN t1_id INT)
BEGIN
INSERT INTO t2(tname) VALUES(t2_name);
UPDATE t1 SET tname='jack1' WHERE tid=t1_id;
SELECT * FROM t1;
END $$
CALL pro_test2('hehe',2)Use of out parameter
DELIMITER $$
CREATE PROCEDURE pro_test3(OUT tname VARCHAR(20))
BEGIN
SET tname = 'xixi';
END $$
CALL pro_test3(@tname);
SELECT @tname;Use of inout parameters; Try to use in and out separately instead of inout
DELIMITER $$
CREATE PROCEDURE pro_test4(INOUT tname VARCHAR(20))
BEGIN
SELECT tname;
SELECT CONCAT(tname,"hello") INTO tname;
END $$
SET @tname='jack';
CALL pro_test4(@tname);
SELECT @tname;3.1.3 stored procedure variables
Local variable DECLARE var_name[, var_name] … type [DEFAULT value];
set and default values
declare num2 int default 100;
select num2;
DELIMITER $$
CREATE PROCEDURE pro_test5()
BEGIN
DECLARE num INT DEFAULT 100;
SELECT num;
set num = 200;
select num;
END $$
CALL pro_test5Assignment using into
DELIMITER $$
CREATE PROCEDURE pro_test6()
BEGIN
DECLARE num INT DEFAULT 100;
SELECT num;
SELECT tid INTO num FROM t1 WHERE tname='jack';
SELECT num;
END $$
CALL pro_test6User variable @ variable name can be used directly without declaration; Similar to Java global variables
DELIMITER $$
CREATE PROCEDURE pro_test7()
BEGIN
SET @param_t1 = 300;
SELECT @param_t1;
SELECT tid INTO @param_t1 FROM t1 WHERE tname='jack';
SELECT @param_t1;
END $$
CALL pro_test7System variable @@ variable name
According to the scope of system variables, they are divided into global variables and session variables@(symbol) global variable(@@global.) stay MySQL When starting, the server automatically initializes the global variable to the default value; The default values of global variables can be changed by MySQL configuration file(my.ini,my.cnf)To change. Session variable(@@session.) Each time a new connection is established, the MySQL To initialize; MYSQL The values of all current global variables will be copied as session variables (that is, if the values of session variables and global variables have not been changed manually after the session is established, the values of all these variables are the same). The difference between global variables and session variables: the modification of global variables will affect the whole server, but the modification of session variables will only affect the current session.
3.1.4 conditional statements
If then else statement
IF expression THEN statements; END IF; ---------------------------------------- IF expression THEN statements; ELSE else-statements; END IF; ---------------------------------------- IF expression THEN statements; ELSEIF elseif-expression THEN elseif-statements; ... ELSE else-statements; END IF;
DELIMITER $$
CREATE PROCEDURE pro_test8(IN tid INT)
BEGIN
IF tid = 1 THEN
INSERT INTO t1(tname) VALUES('tom');
END IF;
END $$
CALL pro_test8(1);
-----------------------------------------------------------------
DELIMITER $$
CREATE PROCEDURE pro_test8(IN tid INT)
BEGIN
IF tid = 1 THEN
INSERT INTO t1(tname) VALUES('tom');
ELSE
SELECT CONCAT(tid,'xixi');
END IF;
END $$
CALL pro_test8(2);
---------------------------------------------------------------------
DELIMITER $$
CREATE PROCEDURE pro_test8(IN tid INT)
BEGIN
IF tid = 1 THEN
INSERT INTO t1(tname) VALUES('tom');
ELSEIF tid = 2 THEN
SELECT CONCAT(tid,'xixi');
ELSEIF tid = 3 THEN
SELECT CONCAT(tid,'xxxxxx');
END IF;
END $$
CALL pro_test8(3);3.1.5 circular statements
WHILE......DO......END WHILE REPEAT......UNTIL END REPEAT LOOP......END LOOP GOTO does not recommend
WHILE......DO......END WHILE
DELIMITER $$
CREATE PROCEDURE pro_test9(IN number INT)
BEGIN
-- What conditions are met to continue the cycle
WHILE number > 0 DO
SELECT number;
SET number=number-1;
END WHILE;
END $$
CALL pro_test9(6);REPEAT......UNTIL END REPEAT
DELIMITER $$
CREATE PROCEDURE pro_test10(IN number INT)
BEGIN
REPEAT
INSERT INTO t1(tname) VALUES(CONCAT('aa',number));
SET number=number-1;
UNTIL number < 0 -- There is no need to add a semicolon here. What conditions do you meet to exit the loop
END REPEAT;
END $$
CALL pro_test10(6);LOOP...LEAVE...END LOOP
DELIMITER $$
CREATE PROCEDURE pro_test11()
BEGIN
BEGIN
DECLARE i INT DEFAULT 0;
loop_x : LOOP
INSERT INTO t1(tname) VALUES(CONCAT('bb',i));
SET i=i+1;
IF i > 5 THEN
LEAVE loop_x;
END IF;
END LOOP;
END;
END $$
CALL pro_test113.1.6 branch statements
DELIMITER $$
CREATE PROCEDURE pro_test12(IN var INT)
BEGIN
CASE var
WHEN 1 THEN
SELECT 'a';
WHEN 2 THEN
SELECT 'b';
ELSE
SELECT 'c';
END CASE;
END $$
CALL pro_test12(2);3.2 function (understand)
Custom functions have the same meaning as built-in functions such as concat
CREATE FUNCTION func_name ([param_name type[,...]])
RETURNS type
[characteristic ...]
BEGIN
routine_body
END;
(1)func_name : The name of the storage function.
(2)param_name type: Optional, specify the parameters of the storage function.
(3)RETURNS type: Specifies the type of the return value.
(4)characteristic: Optional to specify the properties of the storage function.
(5)routine_body: SQL Code content.
Call function
SELECT func_name([parameter[,...]]);DELIMITER //
CREATE FUNCTION fc_test(id INT)
RETURNS VARCHAR(20)
BEGIN
SELECT tname INTO @name FROM t1 WHERE tid=id;
RETURN @name;
END //
SELECT fc_test(2);3.3 Trigger (understand)
3.3.1 cascade operation of main and foreign keys
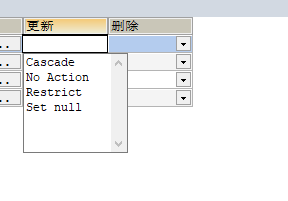
When Cascade updates / deletes records on the main table, it will synchronously update/delete the matching records of the sub table No Action if there are matching records in the child table, the update/delete operation on the candidate key corresponding to the parent table is not allowed Both Restrict and no action check foreign key constraints immediately Set null when updating / deleting records on the main table, set the columns of matching records on the sub table to null
Note: the trigger will not be affected by the foreign key cascade behavior, that is, the trigger will not be triggered
NULL,RESTRICT,NO ACTION Delete: the primary table can be deleted only when the slave table record does not exist. Delete the slave table and leave the master table unchanged Update: the master table can be updated only when the slave table record does not exist. Update the slave table, and the master table remains unchanged CASCADE Delete: when deleting the primary table, the secondary table is automatically deleted. Delete the slave table and leave the master table unchanged Update: the slave table is automatically updated when the master table is updated. Update the slave table, and the master table remains unchanged SET NULL Delete: when the primary table is deleted, the value of the secondary table is automatically updated NULL. Delete the slave table and leave the master table unchanged Update: when the master table is updated, the value of the slave table is automatically updated NULL. Update the slave table, and the master table remains unchanged
3.3.2 Trigger
A trigger is a database object related to a table. It is triggered when the defined conditions are met and executes the statement set defined in the trigger. This feature of trigger can help the application to ensure the integrity of data on the database side.
CREATE TRIGGER trigger_name trigger_time trigger_event ON tb_name FOR EACH ROW trigger_stmt
trigger_name: The name of the trigger
tirgger_time: Trigger time is BEFORE perhaps AFTER
trigger_event: Trigger event, for INSERT,DELETE perhaps UPDATE
tb_name: Indicates the table on which the trigger is created
trigger_stmt: The program body of the trigger can be a SQL Statement or use BEGIN and END Contains multiple statements
So it can be said MySQL Create the following six triggers:
BEFORE INSERT,BEFORE DELETE,BEFORE UPDATE
AFTER INSERT,AFTER DELETE,AFTER UPDATE
BEFORE and AFTER Parameter specifies when execution is triggered, before or after the event
FOR EACH ROW Indicates that the trigger event will be triggered if the operation on any record meets the trigger event
CREATE TRIGGER Trigger Name BEFORE|AFTER Trigger event
ON Table name FOR EACH ROW
BEGIN
Execution statement list
END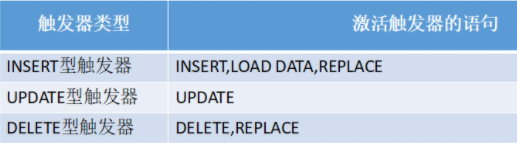
DELIMITER $$
CREATE TRIGGER tri_test1 AFTER DELETE
ON t1 FOR EACH ROW
BEGIN
INSERT INTO t2(tname) VALUES('ssss');
END$$
SELECT * FROM t1;
SELECT * FROM t2;
UPDATE t1 SET tname = 'aaa' WHERE tid = 1;
DELETE FROM t1 WHERE tid=1;3.4 view (understanding)
A view is a virtual table, which is the query result of sql, and its content is defined by the query. Like a real table, a view contains a series of named column and row data, which is generated dynamically when using the view. The data change of the view will affect the base table, and the data change of the base table will also affect the view 1) Simple: users using the view do not need to care about the structure, association conditions and filter conditions of the corresponding table. For users, it is already the result set of filtered composite conditions. 2) Security: users using the view can only access the result set they are allowed to query. The permission management of the table cannot be limited to a row or a column, but it can be simply realized through the view. 3) Data independence: once the view structure is determined, the impact of table structure changes on users can be shielded. Adding columns to the source table has no impact on the view; If the column name of the source table is modified, it can be solved by modifying the view without affecting visitors. In a word, most of the views are used to ensure data security and improve query efficiency.
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]CREATE VIEW view_test1 AS SELECT * FROM t1; CREATE VIEW view_test2 AS SELECT employee_id,first_name,manager_name FROM employee LEFT JOIN manager ON employee.`manager_id` = manager.`manager_id`;
3.5 indexes and constraints
3.5.1 constraints
Function: it is implemented to ensure the integrity of data. It is extracted from a set of mechanisms. It has different tools (constraints) according to the implementation of different databases;
1,Non empty constraint: not null; Indicates that a column cannot be stored NULL value 2,Unique constraint: unique(); unique Constraint fields must be unique, but null except; 3,Primary key constraint: primary key(); Primary key constraint=not null + unique,Ensuring that a column (or a combination of two columns and multiple columns) has a unique identification helps to find a specific record in the table more easily and quickly. 4,Foreign key constraints: foreign key ;Ensure referential integrity of data in one table matching values in another table. 5,Self increasing constraint: auto_increment 6,Default constraint: default Given default value 7,Checking constraints: check Ensure that the values in the column meet the specified criteria.
3.5.2 index
Function: * * quickly locate specific data, improve query efficiency, ensure data uniqueness, and quickly locate specific data** It can accelerate the connection between tables and realize the referential integrity between tables. When using grouping and sorting statements for data retrieval, it can significantly reduce the time of grouping and sorting and optimize the search in full-text search fields;
1,Primary key index( primary key); 2,Unique index( unique); 3,General index( index); 4,Full text index( full text); Full text indexing is MyISAM Is a special index type, which searches for keywords in text and is mainly used for full-text retrieval. MySQL InnoDB From 5.6 Full text indexing is supported at first, but InnoDB Chinese, Japanese, etc. are not supported internally because these languages do not have separators. You can use plug-ins to assist in the full-text indexing of Chinese, Japanese, etc. SHOW INDEX FROM table_name; Index fields should be numeric (simple data type) as much as possible Try not to let the default value of the field be NULL Use unique index Use composite index instead of multiple column indexes Pay attention to repetition/Redundant index, unused index
Do not use index
1.Columns rarely used in queries should not be indexed,If the index is established, it will be reduced mysql Performance and increased space requirements. 2.Columns with little data should not be indexed,For example, a gender field 0 or 1,In query,The data of the result set accounts for a large proportion of the data rows in the table,mysql There are many lines to scan,Add index,It doesn't improve efficiency 3.Defined as text and image and bit Columns of data type should not be indexed, 4.When the table is modified(UPDATE,INSERT,DELETE)Operation is much larger than retrieval(SELECT)Index should not be created during operation,These two operations are mutually exclusive
Done~