Discover slow queries
How to quickly locate and execute slow sentences from a large project is a problem to be solved in this chapter.
1. Definition of slow query
What kind of query is slow query, is there a quantitative standard?
Slow Query Definition
Slow query refers to sql statements whose execution time exceeds that of slow query.
Ways to View Slow Query Time
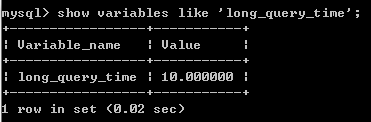
- show variables like 'long_query_time';
show variables like 'long_query_time';
You can display the current slow query time. MySql defaults to 10 seconds for slow queries
The definition of slow query can be modified by the following statement
- set global long_query_time=1;
set global long_query_time=1;
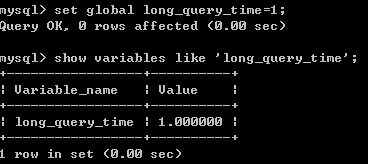
(If your mysql is cached, you need to re-enter the command-line window to detect changes)
It should be noted that this statement intentionally prefixes the variable with global, indicating that this setting is valid for the entire Mysql, while by default the modifier before the variable is session, that is, only valid for the current window.
This is just the beginning. Next, we will prepare data for the occurrence of slow queries, that is, to create a large table.
2. Slow query data preparation
To discover slow queries, slow queries must first occur. Slow queries cannot occur in a table of ordinary orders of magnitude unless you define slow queries in milliseconds. So we have to create a large scale table manually. Here we choose to create a 400,000 scale table. (Students can also create a million scale if your computer is very good. But in general, 100,000-level data can show slow queries.
1) Create a database
Create database bigTable default character set GBK; 2) Create tables
Department chart
CREATE TABLE dept(
id int unsigned primary key auto_increment,
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
) ENGINE=INNODB DEFAULT CHARSET=GBK ;Employee List
CREATE TABLE emp
(
id int unsigned primary key auto_increment,
empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*number*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*Name*/
job VARCHAR(9) NOT NULL DEFAULT "",/*work*/
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*mgr*/
hiredate DATE NOT NULL,/*Initiation time*/
sal DECIMAL(7,2) NOT NULL,/*salary*/
comm DECIMAL(7,2) NOT NULL,/*dividend*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*Department Number*/
)ENGINE=INNODB DEFAULT CHARSET=GBK ;3) Create functions
Functions are used to generate data randomly, ensuring that each data is different
Function 1 Creation#
Create a function that randomly generates strings. This function receives an integer
delimiter $$#Define a new command termination compliance
create function rand_string(n INT)
returns varchar(255) #This function returns a string
begin
#Chars_str defines a variable chars_str of varchar(100) type with the default value of'abcdefghijklmnopqrstuvwxyz ABCDEFJHIJKLMNOPQRSTUVWXYZ'.
declare chars_str varchar(100) default
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end $$Function 2 Creation
Sector Number for Random Generation
create function rand_num( )
returns int(5)
begin
declare i int default 0;
set i = floor(10+rand()*500);
return i;
end $$4) Create stored procedures
Stored procedure I#
This stored procedure is used to insert large amounts of data into emp tables
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
#set autocommit =0 hold autocommit Set to0
set autocommit = 0;
repeat
set i = i + 1;
insert into emp (empno, ename ,job ,mgr ,hiredate ,sal ,comm ,deptno ) values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
commit;
end $$Execute stored procedures to add 400,000 pieces of data to emp tables
call insert_emp(100001,400000); Query found that Emp table inserts 400,000 records
Stored Procedure II#
Add random data to dept table
create procedure insert_dept(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i + 1;
insert into dept (deptno ,dname,loc ) values ((start+i) ,rand_string(10),rand_string(8));
until i = max_num
end repeat;
commit;
end $$Executing stored procedure 2
delimiter ;
call insert_dept(100,10); 3. Record slow queries
At this point we already have the cost of making slow queries happen. Execute the following statement, and you will know what is slow! Check! Ask!
select empno from emp where ename='';
A query statement that obviously could not find the result was executed for nearly three seconds.
At this point, as a DBA, it should record this sql statement in notebook or notebook? Don't think too much, don't remember by yourself. MySQL Provides a slow query log function, automatically help you record slow query statements.
1) Log sql for slow queries
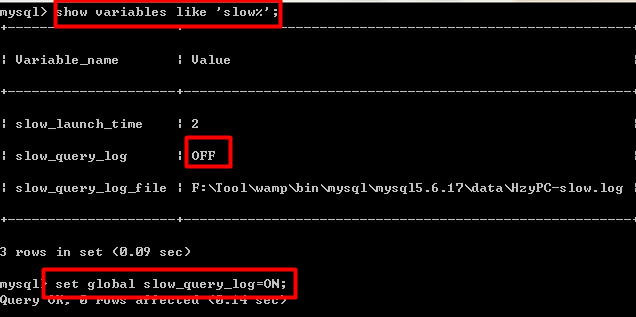
First you need to open the slow query log file logger
Use
show variables like 'slow%';You will find that the slow query logger is turned off by default
Use
set global slow_query_log=ON;Open it
At this point, you will find that a log file named after your local name appears in the data folder in the mysql installation directory.
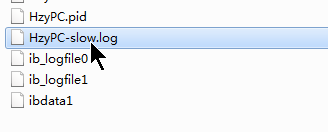
At this point, the slow query operation is executed again.
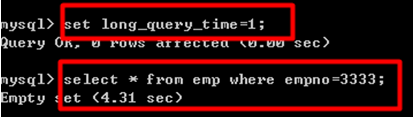
Open the log file and find a record

Later, you can find slow query statements by checking log files regularly.
Be careful:
After finding the slow query statement, we should confirm the slow query by repeatedly using the select statement. Note that only the select statement can be used. Even if the original statement is delete or update, we should use the select instead, because only the select will not get dirty. data base
2) Another way to find slow query statements
If you use it hibernate For J2ee development, you can use a few ways.
Operating on the page, when you find that the response of an operation is slow, look at the Eclipse console Hibernate output sql statement, which is a slow query statement.