I Load from relational database
1. Description:
In the project, we extract relevant data from the relational database (MySQL) and import it into neo4j through jdbc. If the data source is a non relational database, we will also clean it into the style of relational database through script, and then import neo4j from mysql. Of course, we can also integrate data from other relational databases supported by neo4j, At the beginning of our project, we used pg, and later turned to MySQL. The following content is also mainly mysql.
2. Installation method:
To import data through the apoc jdbc connection in neo4j, you need to load two jar packages, one is the apoc Library of neo4j, and the other is the MySQL driver. Neo4j's apoc library integrates many functions and processes, which can help complete many different tasks in the fields of data integration, graphic algorithm or data conversion. Suggested collection website: https://neo4j.com/labs/apoc/4.3/introduction/ , the following chapters will describe in detail the syntax often used in the actual project apoc.
You need to put the corresponding jar package under the plugin file of neo4j. The general jdbc jar package can be downloaded from the official website.
(1) mysql driver
Download from MySQL official website: https://dev.mysql.com/downloads/connector/j/
After downloading the zip package, unzip it: take out the jar package and put it under the plugin file of neo4j:
(2) apoc library installation
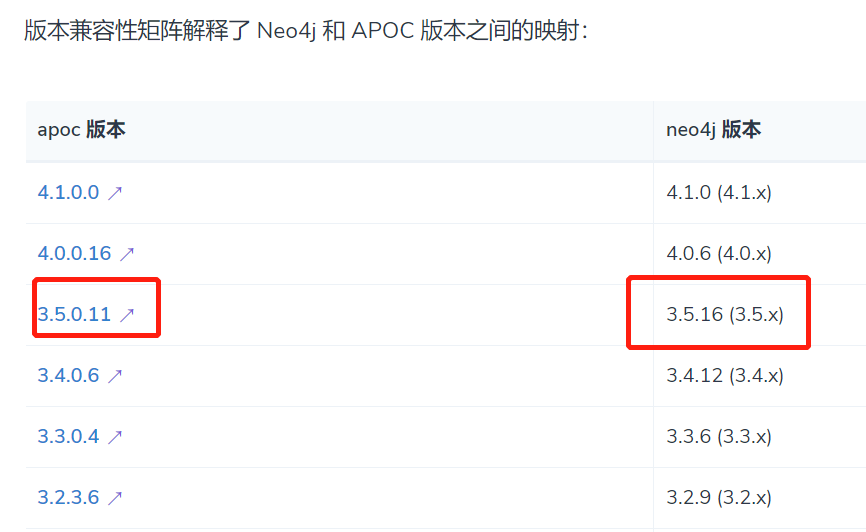
The apoc Library of the corresponding version needs to be downloaded according to different versions of neo4. We use the 3.5x neo4j here, so the apoc of 3.5.0.11 is downloaded, which is also placed in the plugin file of neo4j: download website: https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/3.5.0.11
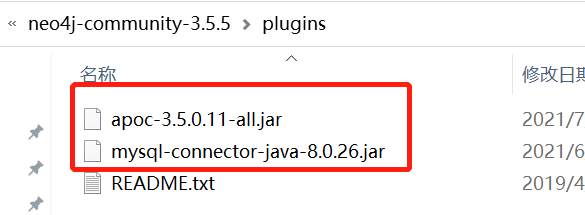
After downloading, restart neo4j
3. Practice and know
Description: establish entity 1: Student, entity 2: Course. The relationship between the two is ELECTIVE: Electronic
Note: generally, the entity is named by hump, then the relationship name is all capitalized, and multiple words are used_ Connection, such as PART_OF
(1) In order to make the loading faster, it is recommended to establish an index in neo4j first. In this way, loading data, especially a large amount of data, is much faster than not adding an index. For example, in the previous project, there was an entity import of hundreds of thousands of data. If the index is not added, it may take about half an hour, but adding the index will be completed in a few minutes.
create index on :Course(id); create index on :Student(id)
(2) In the project, we wrote a python script to automatically import neo4j the data table in mysql. We have specified specifications for entity and relational tables in mysql. For example, an entity table is named after a type name, and then a separate table, relational table, is generally the associated id field of two entities. In practice, our data is collected from different sites, Moreover, the time used by different sites is basically the time of the local server, and we have the scheme design of real-time graph entry and periodic script graph entry, so if there is real-time graph entry data in the relational table, we need to add update_time and source fields (the chapter on real-time and periodic scheme design will be shown later. You can see this chapter in detail later, which will not be expanded here).
(2.1) entity data
mysql data:

Execute statement:
WITH "jdbc:mysql://localhost:3306/neo4j? User = root & password = 123456 "as connstr / / MySQL connection string
WITH 'select * from student' as query,connstr //select statement
CALL apoc.periodic.iterate(//CALL apoc.periodic.iterate batch submission. If the data is large, batch submission is recommended
"call apoc.load.jdbc($connstr,$query) yield row",
//Map each row of records in MySQL into a map. The null value is assigned as an empty string. It is best not to enter the null value of the connection id in mysql, especially when establishing a relationship, otherwise when establishing a relationship, if it is null, all entities under the entity type will be associated, resulting in an error
'with apoc.map.fromPairs([key in keys(row)|[key,case row[key] when null then "" else trim(toString(row[key]))end]]) as row
merge (n:Student{id:row.id}) set n=row
',
{batchSize:1000,//batchSize is submitted every 1000 times in turn, which can be set according to your own needs
params:{connstr:connstr,query:query}}
//params:{connstr:connstr,query:query} pass parameter, APOC periodic. Iterate can only be referenced
)yield batch,operations return batch,operationsExecution results:
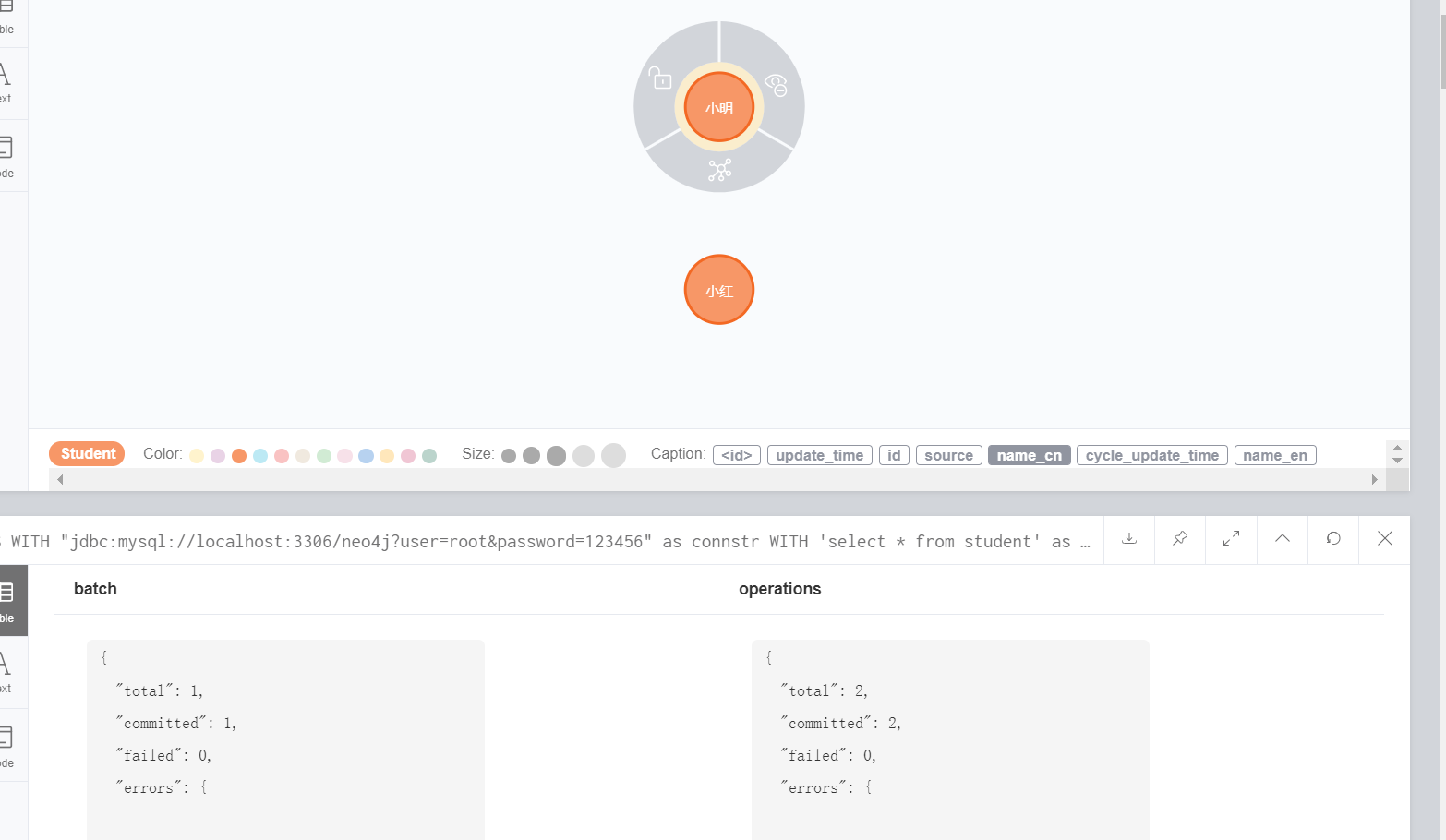
(2.2) relationship data
mysql data:

Execute statement:
//mysql connection string
WITH "jdbc:mysql://localhost:3306/neo4j?user=root&password=123456" as connstr
//select statement
WITH 'select * from student_course_rlt' as query,connstr
//CALL apoc.periodic.iterate batch submission. If the data is large, batch submission is recommended
CALL apoc.periodic.iterate(
"call apoc.load.jdbc($connstr,$query) yield row",
//Map each row of records in MySQL into a map. The null value is assigned as an empty string. It is best not to enter the null value of the connection id in mysql, especially when establishing a relationship, otherwise when establishing a relationship, if it is null, all entities under the entity type will be associated, resulting in an error
'with apoc.map.fromPairs([key in keys(row)|[key,case row[key] when null then "" else trim(toString(row[key]))end]]) as row
match (n:Student{id:row.student_id}),(m:Course{id:row.course_id})
merge (n)-[r:ELECTIVE]->(m) set r=row
',
//batchSize is submitted every 1000 times in turn, which can be set according to your own needs
//params:{connstr:connstr,query:query} pass parameter, APOC periodic. Iterate can only be referenced
{batchSize:1000,params:{connstr:connstr,query:query}}
)yield batch,operations return batch,operationsThe execution results are:
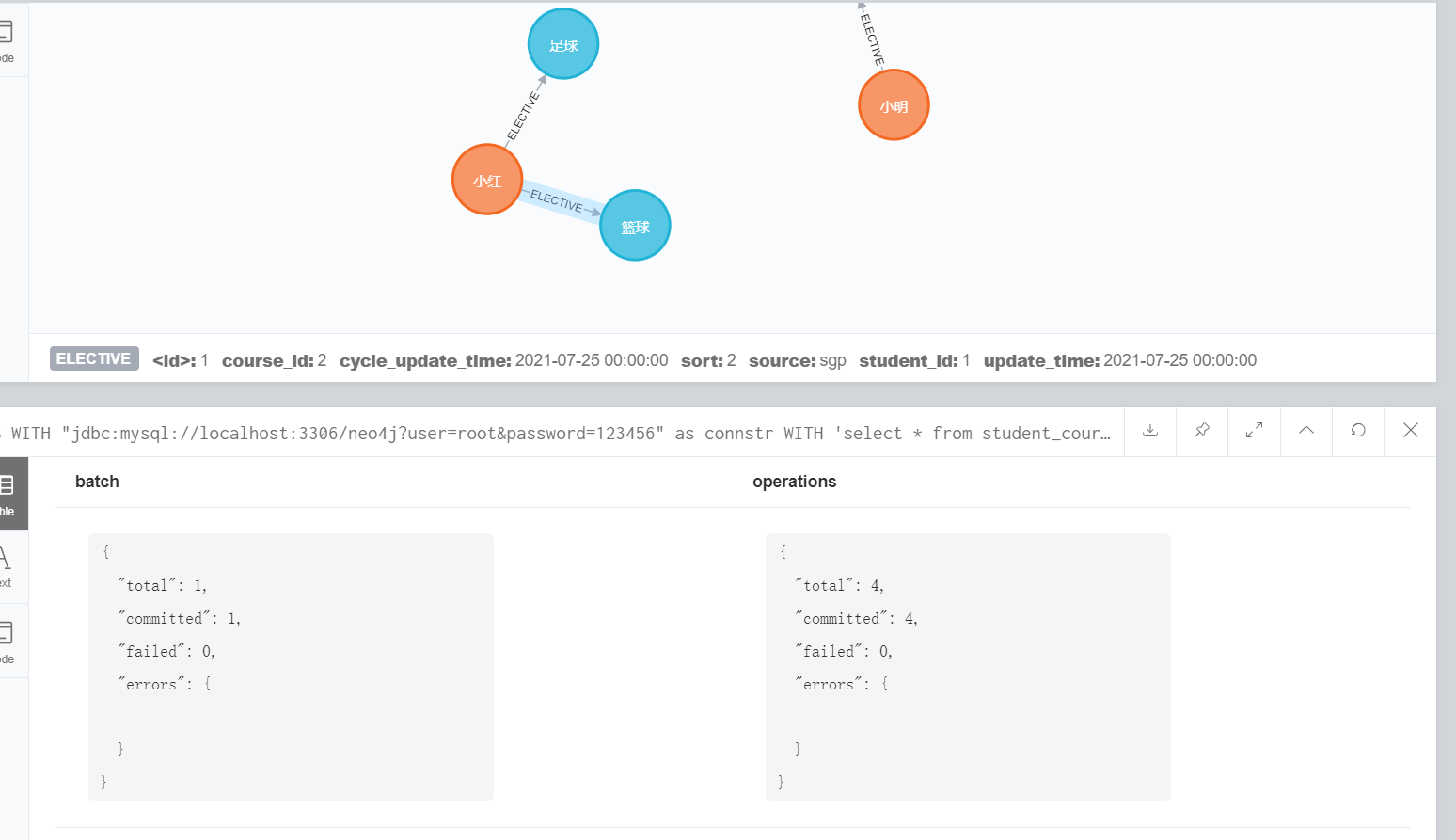
II Pull and load data in Code:
1. Description:
In the actual project, in addition to the data obtained from the relational database, sometimes the data is obtained from other people's interfaces or messages. If you don't want to go through the database landing, you want to directly pull the data and directly enter the diagram in batch. In the project, we use the spring boot framework to integrate with neo4j. Here is a painful and fulfilling experience. We can skip what we don't want to see: we have no experience, have no knowledge of neo4j, and realize the online requirements step by step. There are many holes in the process. Sometimes we think we can't pass it, but we stick to it, overcome it with the team, and quote a jar package for the first time, The framework of the first version of the old and neo4j jar packages is referenced from git. The runtime is OK, but if the project is started for a long time, if it is more concurrent and runs for a long time, it will report a session error. I have tried many methods, but they can't. I don't think it should be so immature. I just change a new jar package. This error is good, Sometimes it's so incredible, ha ha, but after introducing the jar package, we adopt the bean session. At this time, we will also encounter a problem. If an interface occupies this session for too long, it will affect the performance of other interfaces. Even if the interface queries neo4j for too long, the session will throw an error directly, As a result, the entire package must be restarted. Therefore, we solved this situation by optimizing the writing of cypher as much as possible and shortening the execution time. If there are no performance requirements for long cypher, it will be executed in segments to ensure that each interface or task can be completed in as short a time as possible and avoid occupying sessions, but this can only be a temporary scheme. Later, This problem is solved by configuring transactionConfig and driver config. When the query exceeds the specified time, the session closes and does not occupy the same session. Different session interfaces will not occupy each other. The effect is still very good. See the following for the specific configuration.
2. Installation method:
To be continued......