. Net/C# sub database and sub table high performance O(1) waterfall flow paging
Frame introduction
According to the Convention, first introduce the protagonists of this issue: ShardingCore A high-performance, lightweight solution for reading and writing separation of tables and databases under ef core, with zero dependency, zero learning cost and zero business code intrusion
The only fully automatic sub table and multi field sub table framework under dotnet has high performance, zero dependency, zero learning cost, zero business code intrusion, and supports read-write separation, dynamic sub table and sub library. The same route can be completely customized
Your star and praise are the biggest motivation for me to stick to it. Let's work together net ecology provides a better solution
Project address
- github address https://github.com/dotnetcore/sharding-core
- gitee address https://gitee.com/dotnetchina/sharding-core
background
In the actual battle of optimizing page paging of waterfall flow on the app side under a large amount of data, there is a large amount of data, and the front end needs to be displayed in the form of waterfall flow. Our simplest is to take the articles published by users as an example. Assuming that we have a large number of articles and posts, and the demand needs to be displayed to users in reverse order according to the publishing time of posts, we generally pull and refresh the following on the mobile terminal, To display in the form of pull-up loading, we generally have the following centralized writing method.
General paging operation
select count(*) from article select * from article order by publish_time desc limit 1,20
This operation is generally our normal paging operation. First run total and then get paging. The advantage of this method is to support paging of any rules. The disadvantage is that you need to query twice, count once and limit once. Of course, the amount of data in the later stage is too large, so you only need to count for the first time, However, there is also a problem that if the amount of data is changing all the time, there will be some data of the last time in the next page, because the data is constantly adding, and your page does not keep up with the publishing speed, then it will be sent
Waterfall flow paging
In addition to the above conventional paging operations, we can also carry out specific paging methods for specific order paging to achieve high performance, because based on the premise that we are a large number of waterfall streams, our article assumes that snowflake id is used as the primary key, so our paging can be written as follows
select * from article where id<last_id order by publish_time desc limit 0,20
First of all, let's analyze that this statement is realized by using the inserted data distribution order and the sort you need to query. Because the id will not be repeated and the order and time of snowflake id are consistent, it can be sorted in this way. limit does not need to skip any number each time, but directly obtain the required number, You only need to pass the id of the last query result. This method makes up for the problems caused by the above conventional paging and has very high performance. However, the disadvantages are also obvious. It does not support page skipping and arbitrary sorting. Therefore, this method is very suitable for the waterfall flow sorting of the front-end app at present.
Implementation under fragmentation
First of all, we need to implement this function under sharding. We need to have an id to support sharding and publish_time is divided according to time. Neither of them is indispensable.
principle
Suppose the article table article is published_ Time as the partition field, assuming the talent table, we will have the following table
article_20220101,article_20220102,article_20220103,article_20220104,article_20220105,article_20220106......
Snowflake id auxiliary segmentation
Because the snowflake ID can be used to inverse parse the time, we can perform auxiliary segmentation for snowflake id =, > =, >, < =, <, and contains to narrow the segmentation range
Assuming that our snowflake id is resolved to 2021-01-05 11:11:11, the < less than operation for this snowflake id can be equivalent to x < 2021-01-05 11:11:11. If I ask you what tables we need to query now, it is obvious that [article_20220101, article_20220102, article_20220103, article_20220104, article_20220105], Except 20220106, we all need to inquire.
union all fragmentation mode
If you use the fragmentation mode of union all, you will usually perform union all on all the tables from 20220101 to 20220105, and then filter the mechanical energy. The advantages can be imagined: simple, only one connection is consumed, many sql statements are supported, and the disadvantages are obvious. It is a big problem in the later stage of optimization, and there are problems in the use of cross database
select * from (select * from article_20220101 union all select * from article_20220102 union all select * from article_20220103....) t where id<last_id order by publish_time desc limit 0,20
Streaming slicing, sequential query
If you are aggregating in streaming fragmentation mode, we usually query all tables from 20220101 to 20220105 in parallel, and then sort the priority queue for each query result set. Advantages: simple statement, easy to optimize, controllable performance, support sub database, disadvantages: complex implementation and high connection consumption
select * from article_20220101 where id<last_id order by publish_time desc limit 0,20 select * from article_20220102where id<last_id order by publish_time desc limit 0,20 select * from article_20220103 where id<last_id order by publish_time desc limit 0,20 ......
Optimization under flow slicing
At present, ShardingCore adopts streaming aggregation + union all. When and only when the user manually 3 calls UseUnionAllMerge, the fragmented sql will be converted into union all aggregation.
The paging ShardingCore for the above waterfall flow operates like this
- Determine the order of the shard table, that is, because the shard field is publish_time, because the sorting field is publish_ Therefore, the partition table is actually in order, that is [article_20220105, article_20220104, article_20220103, article_20220102, article_20220101],
Because we start n concurrent threads, this sort may not be meaningful, but if we only start and set the concurrency of a single connection, the program will now pass ID < last_ ID is used for table filtering, and then it is obtained from large to small until skip+take, that is, 0 + 20 = 20 pieces of data are met. Then the remaining queries are directly discarded and the results are returned. Then this query is basically the same as a single table query, because it can basically meet the requirements by spanning up to two tables (specific scenarios are not necessarily) - Note: assume last_ The result of ID inverse parsing is 2022-01-04 05:05:05, so you can basically exclude articles_ 20220105: judge the number of concurrent connections. If it is 1, query the article directly_ 20220104, if not, continue to query the article_ 20220103 until the query result is 20. If the number of concurrent connections is 2, if the query [article_20220104, article_20220103] is not satisfied, continue the following two tables until the result is 20 data, so we can clearly understand its working principle and optimize it
explain
- Through the above optimization, the high performance O(1) of streaming aggregate query under sequential query can be guaranteed
- By minimizing the number of client connections, it can be ensured that the client has the above control pieces
- Setting a reasonable primary key can effectively solve our performance optimization under big data fragmentation
practice
ShardingCore has been continuously optimized for fragment query and realized high-performance fragment query aggregation without business code intrusion as far as possible.
Next, I will show you the fragmentation function of the only fully automatic routing, multi field fragmentation, code intrusion free and high-performance sequential query framework under dotnet in the field of traditional database. If you have used it, I believe you will fall in love with it.
Step 1: install dependency
# ShardingCore core framework version 6.4.2.4+ PM> Install-Package ShardingCore # The latest version of mysql community driver efcore6 is selected for the database driver PM> Install-Package Pomelo.EntityFrameworkCore.MySql
Step 2: add object and context
Many friends asked me if I must use the fluent API to use the ShardingCore. I only use dbset+attribute for personal preference
//Article table
[Table(nameof(Article))]
public class Article
{
[MaxLength(128)]
[Key]
public string Id { get; set; }
[MaxLength(128)]
[Required]
public string Title { get; set; }
[MaxLength(256)]
[Required]
public string Content { get; set; }
public DateTime PublishTime { get; set; }
}
//dbcontext
public class MyDbContext:AbstractShardingDbContext,IShardingTableDbContext
{
public MyDbContext(DbContextOptions<MyDbContext> options) : base(options)
{
//Do not add methods that will cause the model of effcore to load in advance, such as database xxxx
}
public IRouteTail RouteTail { get; set; }
public DbSet<Article> Articles { get; set; }
}
Step 3: add article route
public class ArticleRoute:AbstractSimpleShardingDayKeyDateTimeVirtualTableRoute<Article>
{
public override void Configure(EntityMetadataTableBuilder<Article> builder)
{
builder.ShardingProperty(o => o.PublishTime);
}
public override bool AutoCreateTableByTime()
{
return true;
}
public override DateTime GetBeginTime()
{
return new DateTime(2022, 3, 1);
}
}
So far, Article basically supports the talent table
Step 4: add query configuration to let the framework know that we are dividing tables in order and define the order of dividing tables
public class TailDayReverseComparer : IComparer<string>
{
public int Compare(string? x, string? y)
{
//By default, the program uses positive order, that is, sorting by positive time order. We need to use reverse order, so we can directly call the native comparator and multiply it by negative one
return Comparer<string>.Default.Compare(x, y) * -1;
}
}
//The review condition that the current query meets must be a query of a single sharding object, which can be join ed to a common non sharding table
public class ArticleEntityQueryConfiguration:IEntityQueryConfiguration<Article>
{
public void Configure(EntityQueryBuilder<Article> builder)
{
//Set the default sorting order of the frame for articles. The reverse order is set here
builder.ShardingTailComparer(new TailDayReverseComparer());
////The following settings have the same effect as the above, so that the framework really uses reverse order for the suffix sorting of Article
//builder.ShardingTailComparer(Comparer<string>.Default, false);
//Briefly explain the meaning of the following configuration
//In the first parameter table name, which attribute of Article is sorted in order is the same as that of Tail by day. PublishTime is used here
//The second parameter indicates whether the property PublishTime asc is consistent with the ShardingTailComparer configured above. true indicates consistent. Obviously, this is the opposite, because the tail sorting is set to reverse by default
//The third parameter indicates whether it is the Article attribute. It is also possible to set the name here, because the select ion of anonymous objects is considered
builder.AddOrder(o => o.PublishTime, false,SeqOrderMatchEnum.Owner|SeqOrderMatchEnum.Named);
//The id used here for demonstration is a simple time format, so it is the same as the time configuration
builder.AddOrder(o => o.Id, false,SeqOrderMatchEnum.Owner|SeqOrderMatchEnum.Named);
//Here, you can set the sorting method if there is no order with the above configuration by default in this query
//The first parameter indicates whether it is the same as the ShardingTailComparer configuration. Currently, the configuration is in reverse order, that is, query from the latest time. If it is false, query from the earliest time
//The fuse is configured later, which is to review the fusing conditions. For example, only one of FirstOrDefault needs to be met to fuse
builder.AddDefaultSequenceQueryTrip(true, CircuitBreakerMethodNameEnum.Enumerator, CircuitBreakerMethodNameEnum.FirstOrDefault);
//What is configured here is the limit of the number of connections opened by default when using the sequential query configuration. At the beginning of startup, you can set the number of threads of the current cpu by default. It is optimized to only need one thread. Of course, if it is cross table, it is serial execution
builder.AddConnectionsLimit(1, LimitMethodNameEnum.Enumerator, LimitMethodNameEnum.FirstOrDefault);
}
}
Step 5: add configuration to route
public class ArticleRoute:AbstractSimpleShardingDayKeyDateTimeVirtualTableRoute<Article>
{
//Omit
public override IEntityQueryConfiguration<Article> CreateEntityQueryConfiguration()
{
return new ArticleEntityQueryConfiguration();
}
}
Step 6: startup configuration
var builder = WebApplication.CreateBuilder(args);
// Add services to the container.
ILoggerFactory efLogger = LoggerFactory.Create(builder =>
{
builder.AddFilter((category, level) => category == DbLoggerCategory.Database.Command.Name && level == LogLevel.Information).AddConsole();
});
builder.Services.AddControllers();
builder.Services.AddShardingDbContext<MyDbContext>()
.AddEntityConfig(o =>
{
o.CreateShardingTableOnStart = true;
o.EnsureCreatedWithOutShardingTable = true;
o.AddShardingTableRoute<ArticleRoute>();
})
.AddConfig(o =>
{
o.ConfigId = "c1";
o.UseShardingQuery((conStr, b) =>
{
b.UseMySql(conStr, new MySqlServerVersion(new Version())).UseLoggerFactory(efLogger);
});
o.UseShardingTransaction((conn, b) =>
{
b.UseMySql(conn, new MySqlServerVersion(new Version())).UseLoggerFactory(efLogger);
});
o.AddDefaultDataSource("ds0", "server=127.0.0.1;port=3306;database=ShardingWaterfallDB;userid=root;password=root;");
o.ReplaceTableEnsureManager(sp => new MySqlTableEnsureManager<MyDbContext>());
}).EnsureConfig();
var app = builder.Build();
app.Services.GetRequiredService<IShardingBootstrapper>().Start();
using (var scope = app.Services.CreateScope())
{
var myDbContext = scope.ServiceProvider.GetRequiredService<MyDbContext>();
if (!myDbContext.Articles.Any())
{
List<Article> articles = new List<Article>();
var beginTime = new DateTime(2022, 3, 1, 1, 1,1);
for (int i = 0; i < 70; i++)
{
var article = new Article();
article.Id = beginTime.ToString("yyyyMMddHHmmss");
article.Title = "title" + i;
article.Content = "content" + i;
article.PublishTime = beginTime;
articles.Add(article);
beginTime= beginTime.AddHours(2).AddMinutes(3).AddSeconds(4);
}
myDbContext.AddRange(articles);
myDbContext.SaveChanges();
}
}
app.MapControllers();
app.Run();
Step 7: write a query expression
public async Task<IActionResult> Waterfall([FromQuery] string lastId,[FromQuery]int take)
{
Console.WriteLine($"-----------Start query,lastId:[{lastId}],take:[{take}]-----------");
var list = await _myDbContext.Articles.WhereIf(o => String.Compare(o.Id, lastId) < 0,!string.IsNullOrWhiteSpace(lastId)).Take(take)..OrderByDescending(o => o.PublishTime)ToListAsync();
return Ok(list);
}
Run program
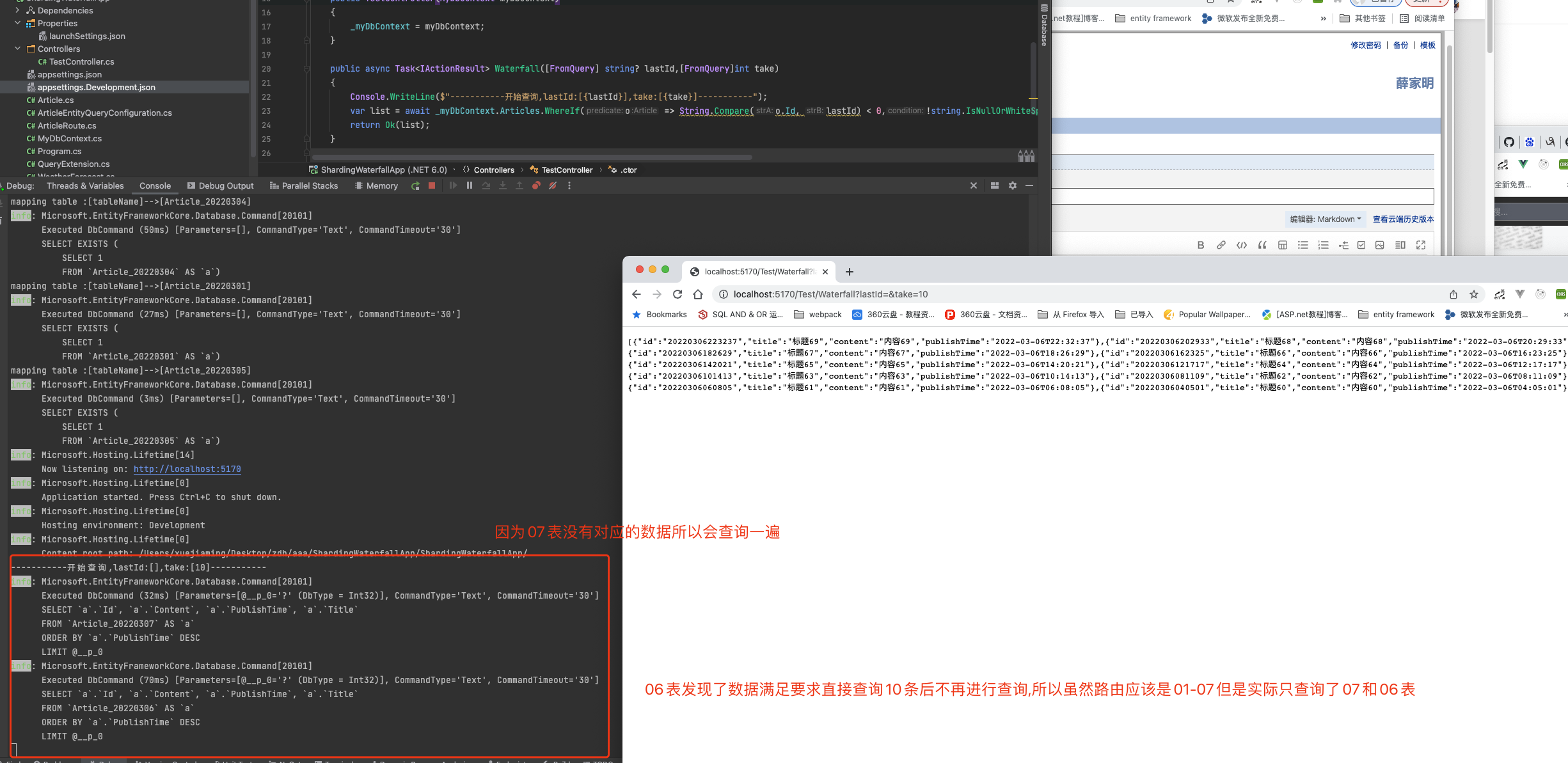
Because there is no table 07, this query will query tables 07 and 06, and then we will perform the next page to pass in the last id
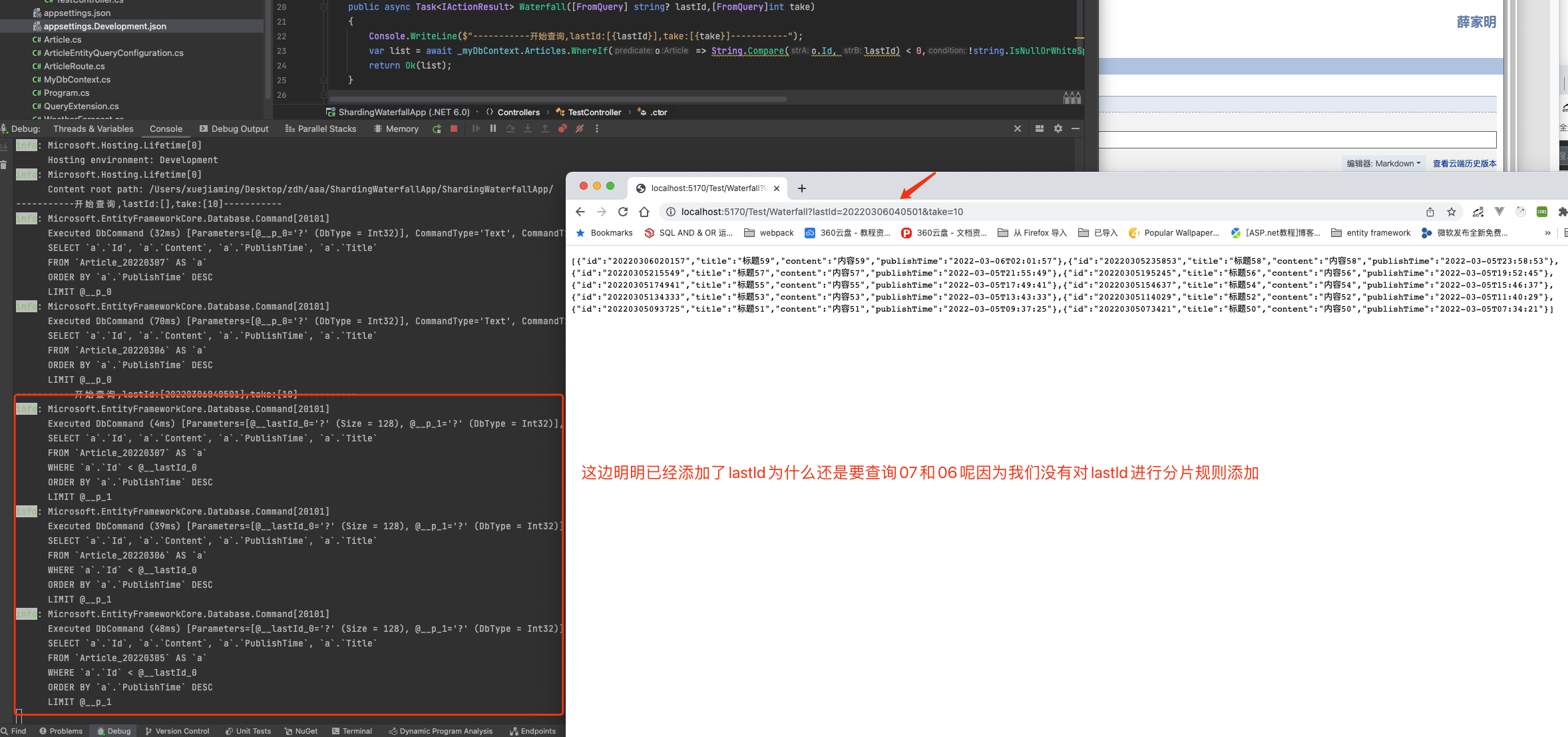
Because there is no right to article ID is used to write partition routing rules, so there is no way to filter ID. next, we configure the partition rules of ID
First, code ArticleRoute
public class ArticleRoute:AbstractSimpleShardingDayKeyDateTimeVirtualTableRoute<Article>
{
public override void Configure(EntityMetadataTableBuilder<Article> builder)
{
builder.ShardingProperty(o => o.PublishTime);
builder.ShardingExtraProperty(o => o.Id);
}
public override bool AutoCreateTableByTime()
{
return true;
}
public override DateTime GetBeginTime()
{
return new DateTime(2022, 3, 1);
}
public override IEntityQueryConfiguration<Article> CreateEntityQueryConfiguration()
{
return new ArticleEntityQueryConfiguration();
}
public override Expression<Func<string, bool>> GetExtraRouteFilter(object shardingKey, ShardingOperatorEnum shardingOperator, string shardingPropertyName)
{
switch (shardingPropertyName)
{
case nameof(Article.Id): return GetArticleIdRouteFilter(shardingKey, shardingOperator);
}
return base.GetExtraRouteFilter(shardingKey, shardingOperator, shardingPropertyName);
}
/// <summary>
///Routing of article id
/// </summary>
/// <param name="shardingKey"></param>
/// <param name="shardingOperator"></param>
/// <returns></returns>
private Expression<Func<string, bool>> GetArticleIdRouteFilter(object shardingKey,
ShardingOperatorEnum shardingOperator)
{
//Convert the split table field to order number
var id = shardingKey?.ToString() ?? string.Empty;
//Determine whether the order number is the format we meet
if (!CheckArticleId(id, out var orderTime))
{
//If the format is different, it will directly return false. Because this query is linked by and, this query will not go through any route, which can effectively prevent malicious attacks
return tail => false;
}
//tail of current time
var currentTail = TimeFormatToTail(orderTime);
//Because the table is divided by month, the time of the next month is obtained to determine whether the id is created at the critical point
//var nextMonthFirstDay = ShardingCoreHelper.GetNextMonthFirstDay(DateTime.Now);// This is wrong
var nextMonthFirstDay = ShardingCoreHelper.GetNextMonthFirstDay(orderTime);
if (orderTime.AddSeconds(10) > nextMonthFirstDay)
{
var nextTail = TimeFormatToTail(nextMonthFirstDay);
return DoArticleIdFilter(shardingOperator, orderTime, currentTail, nextTail);
}
//Because the table is divided by month, the time at the beginning of this month is obtained to judge whether the id is created at the critical point
//if (orderTime.AddSeconds(-10) < ShardingCoreHelper. Getcurrentmonthfirstday (datetime. Now)) / / this is an error
if (orderTime.AddSeconds(-10) < ShardingCoreHelper.GetCurrentMonthFirstDay(orderTime))
{
//Last month tail
var previewTail = TimeFormatToTail(orderTime.AddSeconds(-10));
return DoArticleIdFilter(shardingOperator, orderTime, previewTail, currentTail);
}
return DoArticleIdFilter(shardingOperator, orderTime, currentTail, currentTail);
}
private Expression<Func<string, bool>> DoArticleIdFilter(ShardingOperatorEnum shardingOperator, DateTime shardingKey, string minTail, string maxTail)
{
switch (shardingOperator)
{
case ShardingOperatorEnum.GreaterThan:
case ShardingOperatorEnum.GreaterThanOrEqual:
{
return tail => String.Compare(tail, minTail, StringComparison.Ordinal) >= 0;
}
case ShardingOperatorEnum.LessThan:
{
var currentMonth = ShardingCoreHelper.GetCurrentMonthFirstDay(shardingKey);
//At the critical value o = > o.time < [2021-01-01 00:00:00] tail 20210101 should not be returned
if (currentMonth == shardingKey)
return tail => String.Compare(tail, maxTail, StringComparison.Ordinal) < 0;
return tail => String.Compare(tail, maxTail, StringComparison.Ordinal) <= 0;
}
case ShardingOperatorEnum.LessThanOrEqual:
return tail => String.Compare(tail, maxTail, StringComparison.Ordinal) <= 0;
case ShardingOperatorEnum.Equal:
{
var isSame = minTail == maxTail;
if (isSame)
{
return tail => tail == minTail;
}
else
{
return tail => tail == minTail || tail == maxTail;
}
}
default:
{
return tail => true;
}
}
}
private bool CheckArticleId(string orderNo, out DateTime orderTime)
{
//yyyyMMddHHmmss
if (orderNo.Length == 14)
{
if (DateTime.TryParseExact(orderNo, "yyyyMMddHHmmss", CultureInfo.InvariantCulture,
DateTimeStyles.None, out var parseDateTime))
{
orderTime = parseDateTime;
return true;
}
}
orderTime = DateTime.MinValue;
return false;
}
}
Complete routing: multi field fragmentation for Id and sorting greater than or less than is supported
The above is the optimization of multi field segmentation. For details, click here . Net, you have to look at the solution of table and database segmentation - multi field segmentation
Let's continue to look at the results
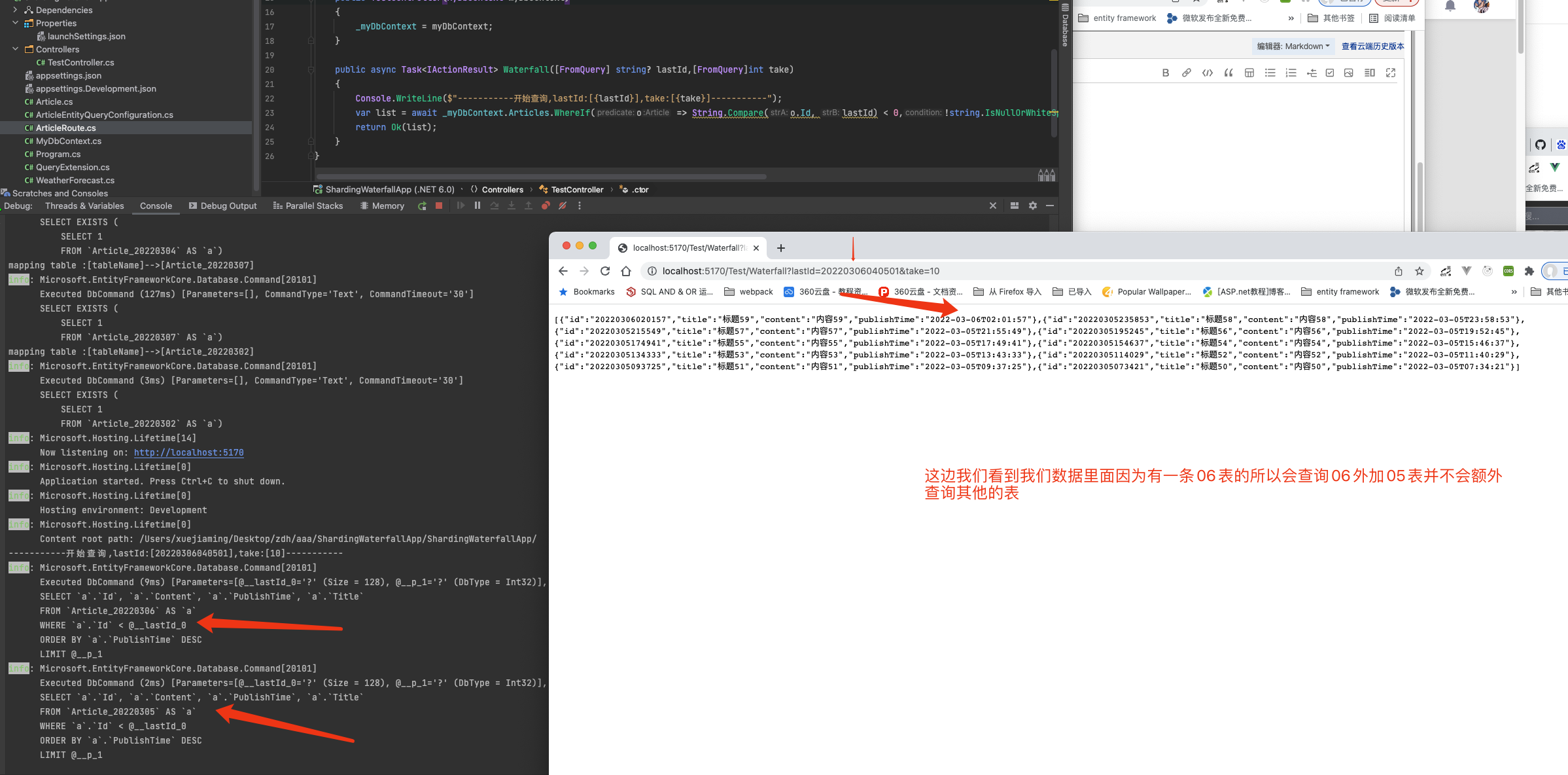
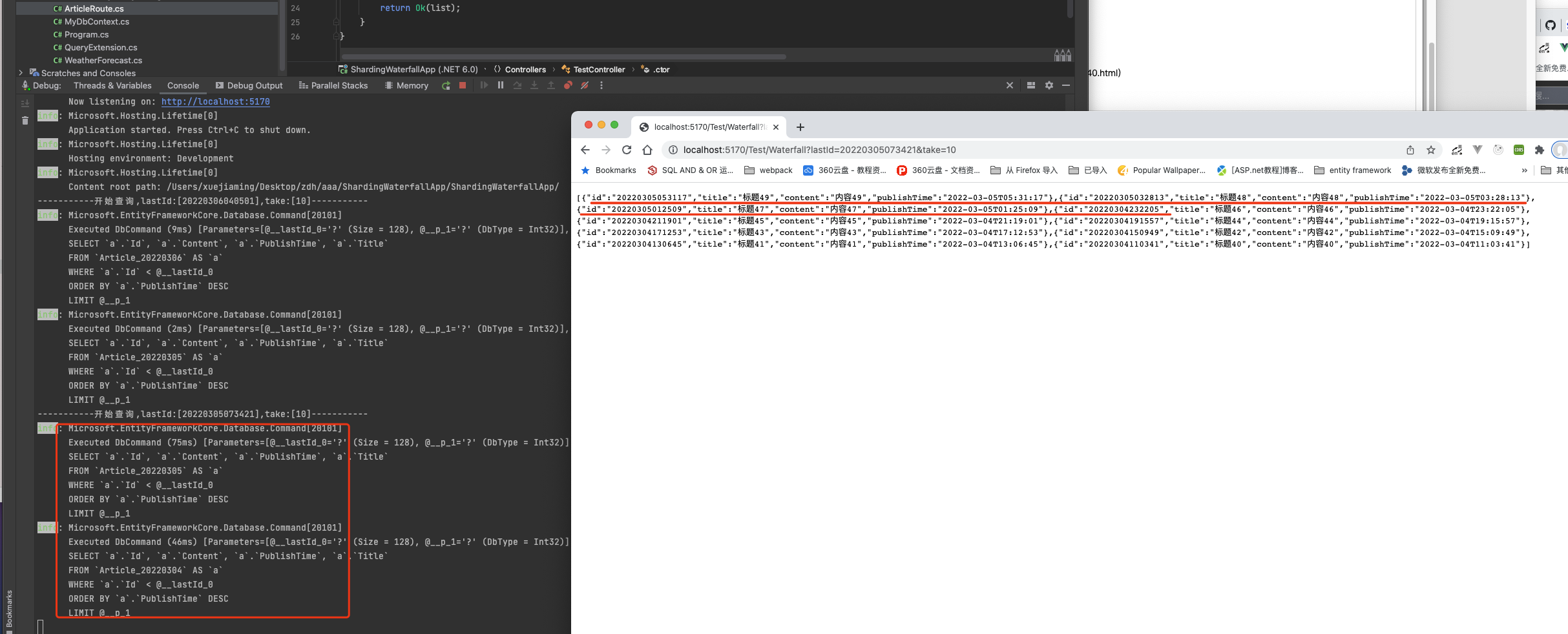
The same is true on page three
summary
Although the current framework is a very young framework, I believe I should optimize its performance in the field of sharding net can't find the second one under all the existing frameworks, and the whole framework also supports union all aggregation, which can meet the query of special statements listed in group+first, and has high performance. One is not only fully automatic fragmentation, but also a high-performance framework, which has a lot of characteristic performance, and the goal is to drain the last bit of performance of client fragmentation.
MAKE DOTNET GREAT AGAIN
Last last
As a dotnet programmer, I believe that in the past, our partition selection scheme did not have a good partition selection except mycat and shardingsphere proxy, but I believe it passed ShardingCore By analyzing the principle of, you can not only understand the knowledge points of fragmentation under big data, but also participate in it or realize one by yourself. I believe that only by understanding the principle of fragmentation, dotnet will have better talents and future. We need not only elegant packaging, but also understanding the principle.
I believe that the ecology of dotnet will gradually grow in the future, coupled with this almost perfect grammar
Your support is the biggest driving force for open source authors to persist
- Github ShardingCore
- Gitee ShardingCore
QQ group: 771630778
Personal QQ: 326308290 (welcome technical support to provide your valuable opinions)
Personal email: 326308290@qq.com